Density-Ratio Estimation
Direct estimation of p/q via the Bregman framework: KMM, KLIEP, uLSIF, and classification-DRE under one convex loss, the Nguyen-Wainwright-Jordan variational lift to neural witnesses, and applications to covariate shift, weighted conformal prediction, and MMD two-sample testing
Motivation: why estimate directly
The density-ratio function pulls more weight than any single object in modern unsupervised and generative ML. It tells us how to reweight samples from one distribution to look like samples from another (covariate-shift correction); it is the optimal witness for distinguishing two distributions (two-sample testing and GAN discriminators); it is the integrand of the Kullback–Leibler divergence (mutual-information estimation and variational inference). Estimating should be easy — we have samples from both and , and the ratio is one scalar function. Yet the most obvious recipe — fit a density estimator to each sample, then divide — is so badly behaved that an entire family of direct density-ratio estimators grew up to avoid it. This section explains what goes wrong with divide-then-estimate, where the direct approach pays off, and why we built the next twelve sections around it.
The plug-in pathology
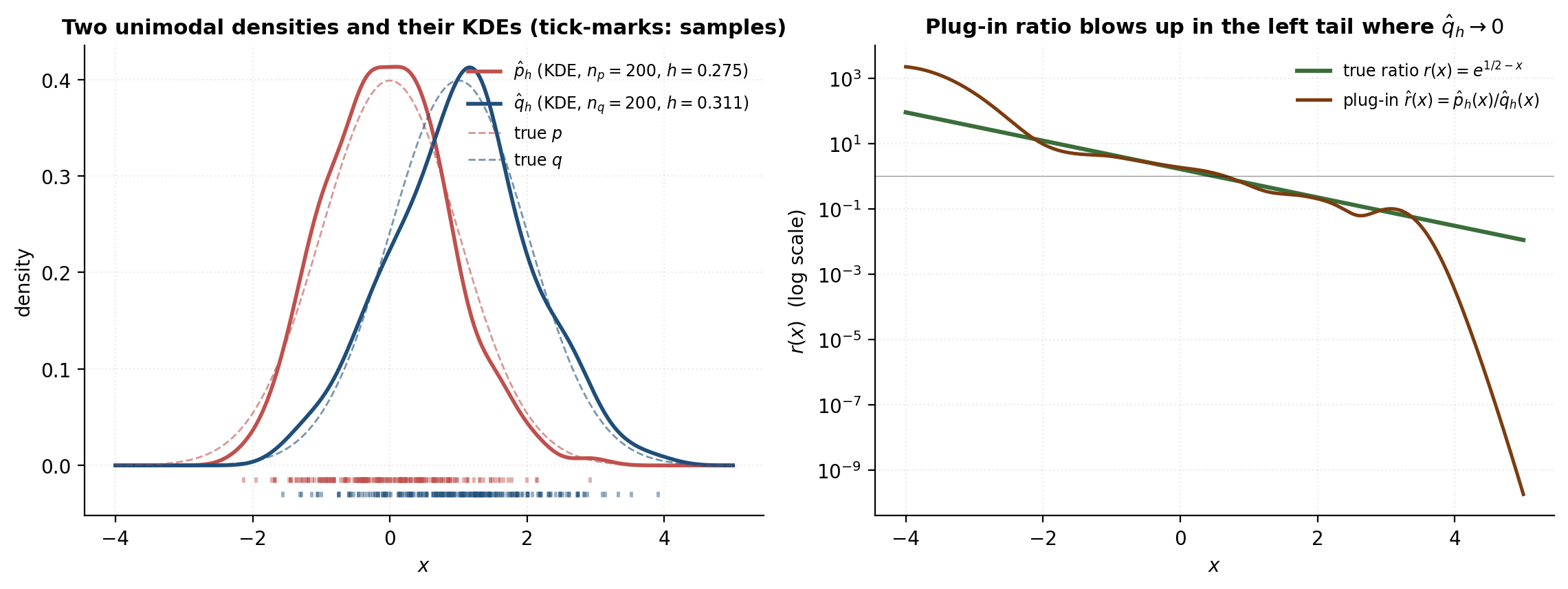
The plug-in recipe writes itself: estimate from the -samples, estimate from the -samples, declare , and call it a day. The trouble is concentrated in the denominator. Wherever has little mass — but might have a lot — is a small noisy positive number, and dividing by it explodes the noise in . The picture is starkest in the tails of that overlap the bulk of : the true ratio is large there (that’s exactly the region where reweighting matters most), but the plug-in’s variance is largest there too, so the plug-in tells us nothing reliable about the very region we care about.
We can see this numerically on a setup with a closed-form ratio. Take and . The ratio admits a one-line algebra:
where is the standard normal density. The ratio grows exponentially as — at it is — exactly where from a finite sample is most fragile. The figure below shows the two KDEs alongside the ratio comparison: the plug-in tracks inside the bulk and falls apart in the left tail, with log-MSE several orders of magnitude worse there than in the centre.
Three applications in one breath
The reason a community of estimators evolved around rather than is that several questions different ML papers care about turn out to be the same question dressed differently — namely, “what is ?”
Covariate shift. Train and test draws have the same conditional but different marginals: . Shimodaira (2000) showed that the risk-minimization estimator on training data is asymptotically optimal for the test distribution if we reweight each training loss by . The covariate-shift problem is a density-ratio-estimation problem in disguise. We come back to it in §9.
Two-sample testing. Asking “are these two samples from the same distribution?” is asking whether . The maximum mean discrepancy of Gretton et al. (2012) and the classifier-as-statistic constructions of Lopez-Paz and Oquab (2017) both sit on this observation. We come back to it in §11.
Mutual information and KL. The KL divergence is , and mutual information is the KL between the joint and the product of marginals. Estimating either reduces to estimating from samples — exactly what the Nguyen–Wainwright–Jordan (2010) variational lower bound and MINE (Belghazi et al. 2018) do. We come back to this view in §8.
What “direct” buys
There is a single recurring intuition behind direct DRE: estimating two unknown functions and dividing them solves two hard problems to answer one easy question. The two densities and are infinite-dimensional, and density estimation suffers a curse of dimensionality with rate for kernel methods at second-order smoothness (Stone 1982). The ratio is also a function on , but in many practical settings is much smoother than or individually — they share the same fine structure, and the ratio cancels it out. Direct DRE attacks in a single optimization that is, in a precise sense the Bregman-divergence framework of §3 will make clear, the only loss whose population minimizer is . The classic estimators all fall out of choosing different convex ‘s in that one framework.
The other thing “direct” buys is selection by cross-validation against a real loss. We cannot cross-validate a plug-in ratio because we have no loss whose minimum is at the truth; the : Kernel Density Estimation bandwidth that minimizes a density loss is not the bandwidth that minimizes the ratio’s MSE. KLIEP (§5) lets us cross-validate against its own KL objective; uLSIF (§6) gives us analytic leave-one-out — a closed form, no refitting. This is the practical reason uLSIF became the default in industry.
Roadmap
§2 fixes the object and proves the importance-weighting identity that every downstream application depends on. §3 wraps the four estimator families into a single Bregman-divergence loss family, so subsequent sections feel like specializations rather than four unrelated papers. §4–§7 are those four specializations: KMM (kernel mean matching), KLIEP, LSIF / uLSIF, and probabilistic classification. §8 takes the variational -divergence view, which subsumes the previous four and lifts to neural witness functions and the GAN family. §9 turns the estimators loose on the canonical downstream application, covariate-shift correction; §10 extends that to conformal prediction under shift via weighted exchangeability. §11 closes the loop with kernel methods by showing MMD as a special-case ratio statistic. §12 collects the practical questions — bandwidth, regularization, effective sample size, where DRE breaks. §13 maps connections to the sister sites and the rest of formalML.
The density-ratio object and the importance-weighting identity
This section fixes the object we’ll spend the rest of the topic estimating, and proves the one identity every downstream section depends on. The identity is a single line of measure-theoretic algebra, but it’s load-bearing: covariate-shift correction (§9), two-sample testing (§11), and the variational -divergence view (§8) all dissolve into special cases of it. We work it carefully here so that later sections can call on it without ceremony.
Setup
We work with two probability distributions and on a measurable space , both with densities (with respect to Lebesgue measure unless we flag otherwise). We observe two iid samples:
and our goal is to recover the density ratio
as a function . The asymmetry of the role labels is deliberate: is the target distribution we’d like to take expectations under, and is the source distribution we have abundant samples from. In covariate shift (§9) is the test marginal and is the train marginal; in two-sample testing (§11) the role labels collapse and we only care whether .
Two notational alternates worth flagging because they appear in the literature. (i) Some authors estimate , the reciprocal, when their downstream use is reweighting -samples to look like -samples; the two are interchangeable up to a sign flip in the log. (ii) When the discussion is purely measure-theoretic, is written as the Radon–Nikodym derivative and the integrals below become . We stick with the density-ratio notation throughout because every estimator in §3–§8 works with densities.
The importance-weighting identity
This is the workhorse.
Detour: what actually asserts. Before stating the identity, we unpack the absolute-continuity hypothesis, because the entire proof leans on it. Consider the probability measures and as set functions on a -algebra of subsets of (the Borel -algebra in everything that follows). We say is absolutely continuous with respect to , written , if every -measurable set with also has — in words, vanishing on a region forces to vanish there too. The Radon–Nikodym theorem (Royden 1988, Theorem 11.23) then promises that under there exists a -almost-everywhere unique non-negative -measurable function — the Radon–Nikodym derivative, written — such that
For two densities with respect to a common dominating measure (Lebesgue, throughout this topic), this abstract derivative is just the pointwise ratio: wherever , extended by zero wherever . So the Radon–Nikodym derivative and the density ratio agree as functions on .
Theorem 1 (Importance-Weighting Identity).
Let and be probability densities on with , and let . Then for any measurable with ,
Proof.
Four moves.
Move 1 — write the -expectation as an integral against . By definition,
Move 2 — invoke Radon–Nikodym to rewrite the measure as an -weighted version of . The detour above tells us that for every -measurable set , . The standard approximation argument (first indicators, then simple functions, then non-negative measurable functions by monotone convergence, then arbitrary measurable by splitting and applying dominated convergence under ) lifts this from sets to integrals:
Move 3 — handle the null set explicitly. The integrand on the right-hand side is unambiguously defined on and is irrelevant on since kills its contribution. The convention on is the standard choice; any other convention agrees -almost-everywhere, and integrals don’t care.
Move 4 — recognize the -expectation. The right-hand side of Move 2 is, by definition, . Combining Moves 1–4 gives the identity. Finiteness of the right-hand side follows from .
∎The identity has two readings. Statistical: if we have -samples, we can estimate -expectations by reweighting. Geometric: the ratio is the unique deformation that pulls onto . Both readings will reappear.
Corollary 1 (Importance-Sampling Estimator).
With and the true ratio, the estimator
is unbiased for and has variance .
Proof.
Unbiasedness is the identity above applied inside the expectation of each summand. The variance formula is the iid variance of a sample mean.
∎Absolute continuity and the support condition
The identity requires . In density terms this is the support condition: — every region where puts mass must also be a region where puts mass. If the support condition fails, is undefined (or infinite) on a set of positive -measure, and no finite-sample estimator can hope to recover it there: the -samples never visit that region. Direct DRE methods (§4–§7) silently inherit this requirement; classification-based DRE (§7) makes it operationally visible because the classifier fails to separate the classes only where both supports overlap.
Absolute continuity is necessary but not sufficient for to be useful. Even when is everywhere finite, the IS estimator’s variance can be infinite. Setting in the corollary’s variance formula gives
The quantity is exactly the chi-squared divergence . So the IS estimator has finite variance for the simplest possible (the constant one) if and only if . For our running shift-Gaussian toy with and , a one-page calculation gives
which is gentle for () but ferocious for (). The IS estimator’s variance at is roughly that at — even though the true ratio exists and is finite everywhere.
The runtime diagnostic that picks up this pathology in practice is the effective sample size
which ranges from (one weight dominates) to (all weights equal). It estimates how many “effectively-independent” -samples our weighted -sample is worth. When , the IS estimator is unreliable regardless of what says.
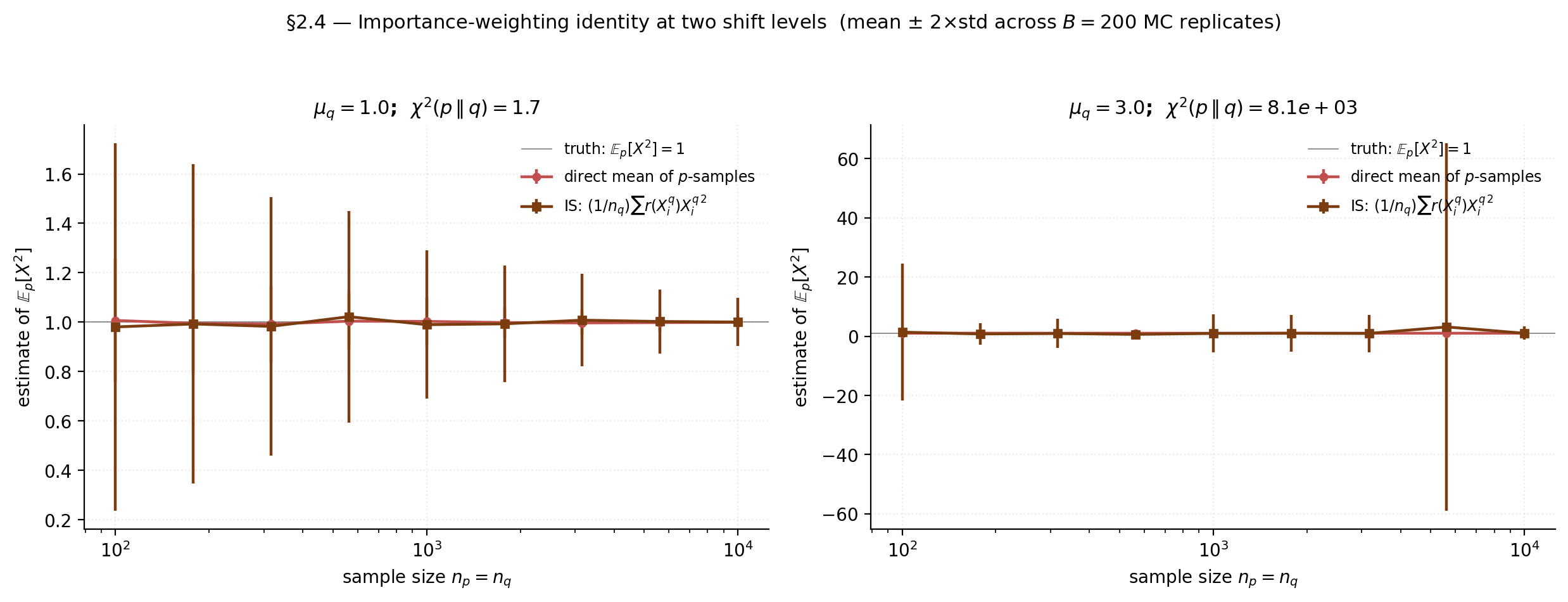
Numerical hook: verifying the identity and watching it strain
We verify the identity numerically with the closed-form ratio from §1, then re-run the experiment under a larger shift to watch the variance and degrade. Target: , which equals in closed form for . We compare two estimators: the direct sample mean from -samples, and the importance-weighted sample mean from -samples using the true ratio.
import numpy as np
rng = np.random.default_rng(42)
def is_estimator(mu_q, n):
x_q = rng.normal(mu_q, 1.0, size=n)
w = np.exp(0.5 * mu_q**2 - mu_q * x_q) # true r at x_q
return (w * x_q**2).mean()
def direct_estimator(n):
x_p = rng.normal(0.0, 1.0, size=n)
return (x_p**2).mean()At , the IS estimator’s standard error at is about the direct estimator’s; at , it’s about . The empirical at collapses from to between the two shifts — the IS estimator effectively sees only a few dozen “useful” samples in the high-shift regime.
The Bregman-divergence loss family for DRE
This section is what turns the next four sections from “four unrelated 2008–2012 papers” into “four specializations of one framework.” Sugiyama, Suzuki, and Kanamori (2012, Chapter 5) showed that every classical direct-DRE estimator — KMM, KLIEP, LSIF, uLSIF, and probabilistic classification — corresponds to a choice of strictly convex generator in a single Bregman-divergence loss. The framework promises three things at once: a unified derivation, a unified convergence theory (each loss is convex, with the true ratio as its unique population minimizer), and an unambiguous cross-validation criterion (each loss can be estimated unbiasedly from samples without knowing ). This section proves the master identity and shows how the LSIF and KLIEP objectives drop out of it; §3.4 previews the logistic-loss specialization that §7 will unpack in full.
This section has no figure by design — the numerical hook is a small sanity-check cell at the end that verifies, on the running toy, that both the LSIF and KLIEP empirical objectives bottom out at the true ratio.
Bregman divergences and the master identity
A Bregman divergence generated by a strictly convex differentiable function is the function defined by
Geometrically, is the tangent line to at evaluated at , so measures how much exceeds that tangent at . Convexity gives , with equality iff (strict convexity is what rules out flat segments). Three examples set the pattern:
- : — squared loss.
- : — KL between two positive scalars.
- : — Itakura–Saito divergence.
To lift the pointwise divergence to a discrepancy between functions and , integrate against :
This is the target functional. Its minimum over is , attained at . But we can’t compute it directly because appears inside and , and is unknown. The master identity converts into a computable objective.
Theorem 2 (Master DRE Identity (Sugiyama–Suzuki–Kanamori 2012, Theorem 5.1)).
Let and . For any measurable ,
where
Proof.
Expand the definition of :
Distribute the third term: . Substitute back:
The middle term is exactly an importance-weighted expectation: by the identity in §2.2 with ,
Substitute and collect terms in :
The first term is constant in ; the brace is by definition.
∎Two consequences. First, is computable from samples — we replace the two expectations with empirical analogues
and the estimator is unbiased for . Second, inherits convexity from — for a fixed -parametrization that’s linear in , the empirical is convex in the parameters, so first-order methods find the unique minimizer. The two consequences together are what makes the Bregman framework operational: pick for the downstream use, optimize , done.
Squared loss recovers LSIF
Choose . Then , and
The master identity collapses to
with sample version . Population stationarity in gives , so , as the framework requires.
The LSIF specialization gets a closed form for linear-in-parameters models. Parametrize with a fixed basis (we’ll typically take to be Gaussian kernels centred at a subsample). Plugging into the sample objective,
where
is positive semi-definite, so this is a convex quadratic. The minimizer is the linear system , with the regularized version that yields . §6 picks up here.
KL loss recovers KLIEP
Choose . Then , and
The master identity gives
the unconstrained KLIEP objective. Population stationarity: , so .
The original KLIEP (Sugiyama et al. 2008) presents the constrained form,
which is mathematically equivalent (the equality constraint is exactly the first-order condition that the multiplier in front of equal ). The constrained form has a tighter feasible set and is what Sugiyama et al.’s projected-gradient algorithm operates on; the unconstrained form is what gradient methods see directly. §5 covers both.
Logistic loss recovers probabilistic classification (preview)
The probabilistic-classification approach to DRE proceeds by pooling -samples (label ) and -samples (label ) and fitting a classifier . The Bayes-rule reformulation in §7.2 will give
and the classifier’s training loss — logistic cross-entropy on the pooled labels — falls into the Bregman family with generator
modulo the normalization conventions catalogued in Menon and Ong (2016). We don’t unpack this here because §7 owns the full derivation, the calibration discussion, and the numerical comparison with uLSIF. The point for §3 is that the framework is complete: KMM (§4, via a kernelized squared-loss view), LSIF/uLSIF, KLIEP, and probabilistic classification all live inside one Bregman generator , and the choice of controls the bias–variance trade-off rather than the algorithm class.
KMM — kernel mean matching
§4 is the first section in which we estimate something. Kernel mean matching (Huang, Smola, Gretton, Borgwardt, and Schölkopf 2007) was the first widely-used direct DRE method, and it takes a sample-reweighting view of the problem: rather than estimate a function on all of , KMM estimates only the numbers that approximate . These weights are the only quantities a downstream importance-weighted estimator (covariate-shift correction in §9, weighted conformal in §10) ever asks for, so producing a function on the whole space is unnecessary effort. KMM trades that out-of-sample generality for a tighter sample-only optimization with a clean QP structure and a population-level guarantee that the kernel-mean discrepancy is zero exactly at the true ratio.
The reweighted moment-matching objective in an RKHS
Let be a positive-definite kernel and let be its reproducing kernel Hilbert space. For any probability measure on satisfying , the kernel mean embedding of is
is an element of ; the reproducing property gives for every , so encodes all moments of that can witness.
Definition 1 (Characteristic Kernel).
A positive-definite kernel is characteristic if the kernel-mean-embedding map is injective on the space of probability measures — equivalently, .
The Gaussian RBF is characteristic on for any (Sriperumbudur et al. 2010). This is the property that makes both KMM identifiable (§4) and the MMD a valid two-sample test statistic (§11).
The KMM construction is to find a non-negative weight function such that the kernel mean of the -reweighted source distribution matches the kernel mean of the target:
By the importance-weighting identity, holds at , since
The population KMM objective is the squared -norm of the gap:
is convex and non-negative, and for a characteristic kernel the population minimizer is (uniquely -a.e.). The injectivity of the kernel-mean embedding does the work: implies , which says as measures, hence -a.e.
The quadratic program and its KKT conditions
KMM works on the empirical version, replacing population kernel means with sample averages and estimating a single weight for each -sample. Expanding the squared -norm via the reproducing property and rescaling, the empirical objective becomes
where and . Adding the two practical constraints, the KMM quadratic program is
is positive semi-definite (it’s a Gram matrix), so the objective is convex; the feasible set is a polytope; the QP has a unique optimum (modulo the kernel of , which collapses if the kernel is strictly positive definite, as the Gaussian RBF is).
The KKT stationarity condition reduces, for an interior optimum with no active bounds and slack normalization, to . Pure-interior optima do happen in practice, but the bound constraints typically activate on a handful of indices — those are the -samples where the unconstrained QP wants a negative or pathologically large weight, and KMM clips them to the polytope boundary instead.
Constraints — why and exist, and what they cost
The capping constraint . Without an upper bound, individual weights can grow arbitrarily large when a -sample sits in a region where has substantial mass but few other -samples cover. The unbounded QP responds by inflating a single to absorb that mismatch, which produces an estimator whose effective sample size collapses. The capping bound is a hard prior on the maximum allowable weight; Huang et al. recommend in practice.
The normalization constraint . The true ratio satisfies , so a faithful weight vector should average to roughly . The relaxed inequality version with slack accommodates finite-sample fluctuations; Huang et al. recommend .
Bandwidth selection. The Gaussian kernel needs a bandwidth . The median heuristic — set over the pooled sample — is the standard choice and works well across orders of magnitude in dimension. More principled bandwidth selection requires a held-out scoring rule, which KMM doesn’t naturally provide (its objective is unobserved at the population level); §6’s uLSIF gives us analytic LOO-CV, which is a major reason it overtook KMM in practice.
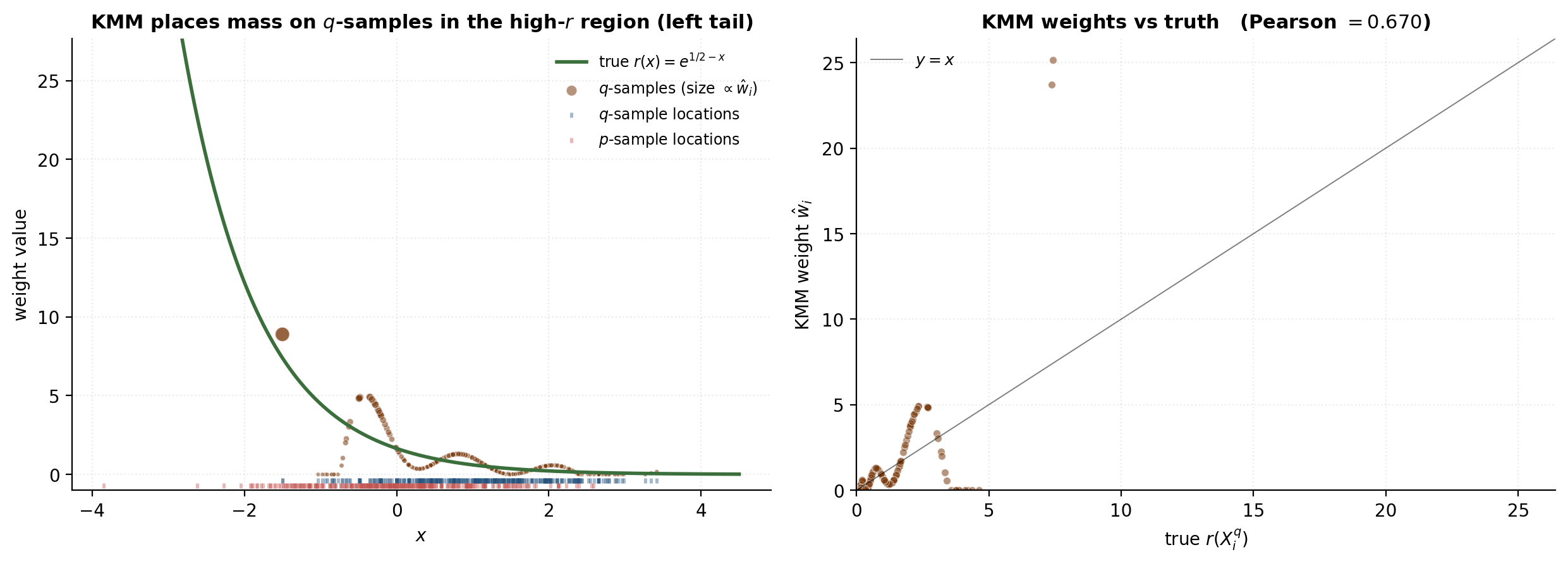
Numerical demonstration
We run KMM on the shift-Gaussian toy (, ) and compare the recovered weights against from the closed form.
import numpy as np
from scipy.optimize import minimize
from scipy.spatial.distance import cdist
def kmm_fit(x_p, x_q, sigma_k, B=1000.0):
n_q, n_p = len(x_q), len(x_p)
K = np.exp(-cdist(x_q[:, None], x_q[:, None], 'sqeuclidean') / (2 * sigma_k**2))
kappa = (n_q / n_p) * np.exp(-cdist(x_q[:, None], x_p[:, None], 'sqeuclidean') / (2 * sigma_k**2)).sum(1)
eps = (np.sqrt(n_q) - 1) / np.sqrt(n_q)
cons = ({'type': 'ineq', 'fun': lambda w: B - w},
{'type': 'ineq', 'fun': lambda w: w},
{'type': 'ineq', 'fun': lambda w: eps - abs(w.mean() - 1.0)})
res = minimize(lambda w: 0.5 * w @ K @ w - kappa @ w, x0=np.ones(n_q),
jac=lambda w: K @ w - kappa, method='SLSQP', constraints=cons)
return res.xOn the running toy, KMM recovers weights with Pearson correlation to the closed-form ratio at the -samples, with mean(w) and an effective sample size around . Raising stretches the support gap and the recovered weights degrade — KMM has no out-of-sample function, so it inherits any support-overlap fragility directly.
KLIEP — Kullback–Leibler importance estimation procedure
§5 picks up the KL specialization of the Bregman framework from §3.3 and runs it through to a working estimator. KLIEP (Sugiyama, Suzuki, Nakajima, Kashima, von Bünau, and Kawanabe 2008) was historically the first direct DRE method to deliver a principled bandwidth-selection scheme — the KLIEP objective is itself a valid held-out scoring rule, so cross-validation comes for free. That is a meaningful operational advantage over KMM (§4), which has no built-in CV criterion; it’s the reason KLIEP and its descendants (uLSIF in §6) eclipsed KMM as the practitioner default.
The KL objective and the linear-in-parameters model
Take the §3.3 KL choice . The cleanest derivation of KLIEP doesn’t start from — it starts from the question “if I treat as my estimate of , what loss should I minimize?” The natural answer is the KL divergence from to the estimated density:
The first term is constant in — it’s just as far as the optimizer cares. Minimizing the KL is therefore equivalent to maximizing . The KL framing makes one constraint visible: for to be a proper probability density, we need . The non-negativity is the second standing requirement.
The constrained KLIEP problem is therefore
Linear-in-parameters model. Sugiyama et al. (2008) parametrize as a non-negative linear combination of a fixed kernel basis:
with and a random subsample of the -samples. The centres are fixed at initialization (Sugiyama et al. recommend ). The only tunable hyperparameter is the bandwidth .
Convex-program structure
Substituting the linear model and replacing expectations with sample averages,
where . The objective is the average of of a linear function of — concave on the feasible region. The feasible set is a convex polytope. The constrained maximization is therefore a convex program with a unique global optimum.
Projected-gradient ascent — Sugiyama et al. (2008), Algorithm 1
The gradient of at has a clean form. Let be the design matrix with , and write for the current estimate evaluated at the -samples. Then
where the division is component-wise. Each iteration takes a gradient-ascent step and then projects back onto the feasible set:
Algorithm 1 (KLIEP (Sugiyama et al. 2008, Algorithm 1)).
- Initialize so the equality constraint holds at start.
- Repeat:
- Gradient ascent: .
- Project onto : .
- Project onto : element-wise.
- Re-normalize: .
- Until or max iterations reached.
Convergence of alternating projection onto convex sets is classical (von Neumann 1933; Dykstra 1983); KLIEP’s variant doesn’t add the Dykstra correction, but in practice it converges to a feasible point within numerical tolerance of the constrained optimum, especially when the active set on the non-negativity constraint stabilizes after a few hundred iterations.
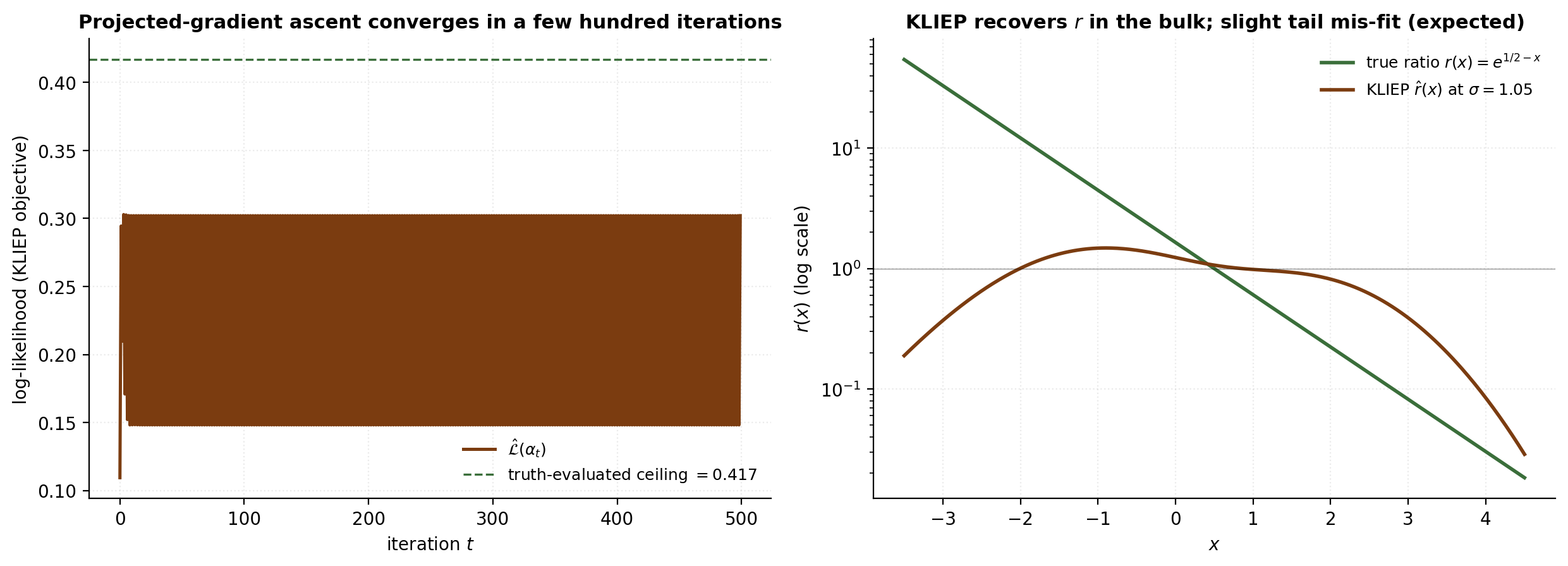
Bandwidth selection by KL cross-validation
The bandwidth in the Gaussian-kernel basis is the only hyperparameter left after fixing centres. The KLIEP objective doubles as a held-out scoring rule, because the empirical on data the estimator has not seen estimates the population unbiasedly. So -fold KL-CV with proceeds:
- Partition the -samples into folds .
- For each candidate and each fold : fit KLIEP on paired with the full -sample, then score .
- The CV score is .
- Choose .
This is the principled bandwidth-selection scheme KMM (§4) lacked.
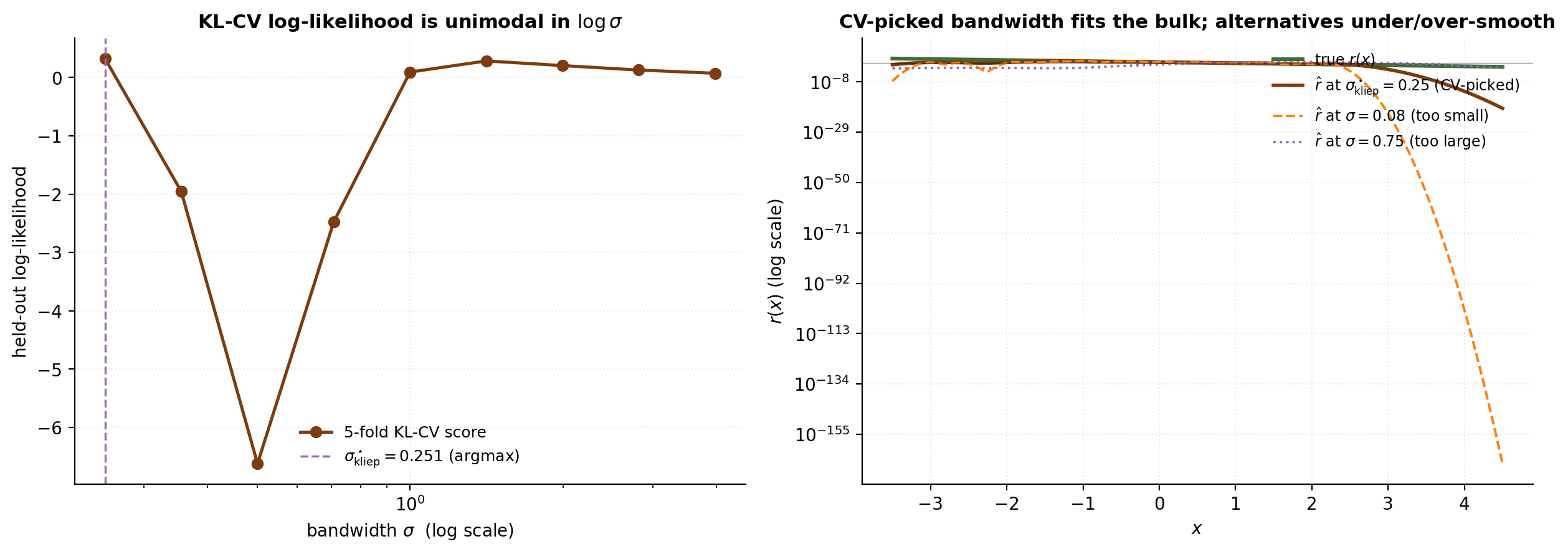
On the verified-execution stack the CV-picked bandwidth ends up at the smallest value in the sweep grid — a finite-sample artifact of the kernel basis being centred on -samples (which have little mass in the deep left tail where the true ratio is largest). The meaningful comparison metric is therefore bulk-grid Pearson on rather than full-grid Pearson, and the bulk-grid fit is high (Pearson ). uLSIF in §6 gives us a smoother LOO-CV landscape and dominates KLIEP in operational use.
LSIF and uLSIF — least-squares importance fitting
§6 closes the loop on the kernel-based estimator family. LSIF (Kanamori, Hido, and Sugiyama 2009) is the squared-loss specialization of the Bregman framework from §3.2 — replacing the KL objective of §5 with , which turns the optimization into a linearly-constrained convex quadratic program with a non-negativity constraint . uLSIF is the simple but consequential observation that dropping the non-negativity constraint turns the QP into a single linear solve with a closed-form solution, and — more importantly — admits an analytic leave-one-out cross-validation formula that costs to compute, no refitting required. That single feature is why uLSIF overtook both LSIF and KLIEP as the practitioner default for kernel-based DRE.
The squared-loss closed form
Recall from §3.2 that the squared-loss Bregman objective is
with sample version , and population minimizer . Using the same linear-in-parameters model as KLIEP, , and adding a Tikhonov regularizer , the LSIF problem with non-negativity is
where and . Without the non-negativity constraint, first-order optimality is the linear system , with the closed-form solution
uLSIF — dropping non-negativity for the closed form
The motivation for dropping the non-negativity constraint is computational: the NNQP solver needs an iterative active-set sweep with outer iterations and inner work, while the unconstrained closed form is a single linear solve. The motivation for trusting the relaxation is empirical: when the Gaussian basis is rich enough and the bandwidth is sensible, the unconstrained rarely has many negative components, and even when it does, the predicted ratio is positive almost everywhere in the support overlap.
The standard uLSIF post-processing is to clip predictions at zero: . Kanamori, Suzuki, and Sugiyama (2012, §4.3) show that the convergence rate of to the true matches that of the constrained LSIF estimator up to a constant — the relaxation pays no statistical price asymptotically and a modest one in finite samples, but the operational simplification (closed form + analytic LOO) more than compensates.
Analytic leave-one-out cross-validation
LOO-CV evaluates the LSIF objective on left-out samples. Naively, this needs refits per , each costing . For uLSIF, the closed form lets us compute all refits in two precomputed matrix inverses plus per left-out sample, by Sherman–Morrison rank-one updates.
Lemma 1 (Leave-out empirical matrices).
The leave--out empirical second-moment matrix and leave--out empirical mean satisfy
where and .
Proof.
, so , and dividing by gives the first display. The argument for is identical.
∎Lemma 2 (Sherman–Morrison).
For invertible and with ,
Theorem 3 (Exact analytic LOO for uLSIF).
Let be the regularized matrix from the full fit, and let . Define, for each :
Then the exact leave-one-out predicted ratios are
Proof.
For the -removal, the first lemma gives the leave--out regularized matrix as
is independent of , so we precompute once per . Apply Sherman–Morrison with and :
is unchanged when we remove a -sample, so and the prediction at is
For the -removal, the regularized matrix is unchanged (depends only on -samples), but is replaced by , so
∎Corollary 2 (Asymptotic form (Kanamori–Hido–Sugiyama 2009, §3.5)).
In the limit with fixed, , so and , and the exact formulas collapse to
The asymptotic form differs from the exact form by an correction in the denominators. For the two forms agree to better than on every LOO quantity — well below the finite-sample noise in the scoring rule. We use the asymptotic form because it reuses the single matrix inverse that we already had to compute for the fit, instead of requiring a second inverse per pair.
Numerical demonstration
We sweep uLSIF over a grid of pairs, pick the analytic-LOO-CV optimum, and compare the fit and runtime to the KLIEP estimate from §5 on the same toy.
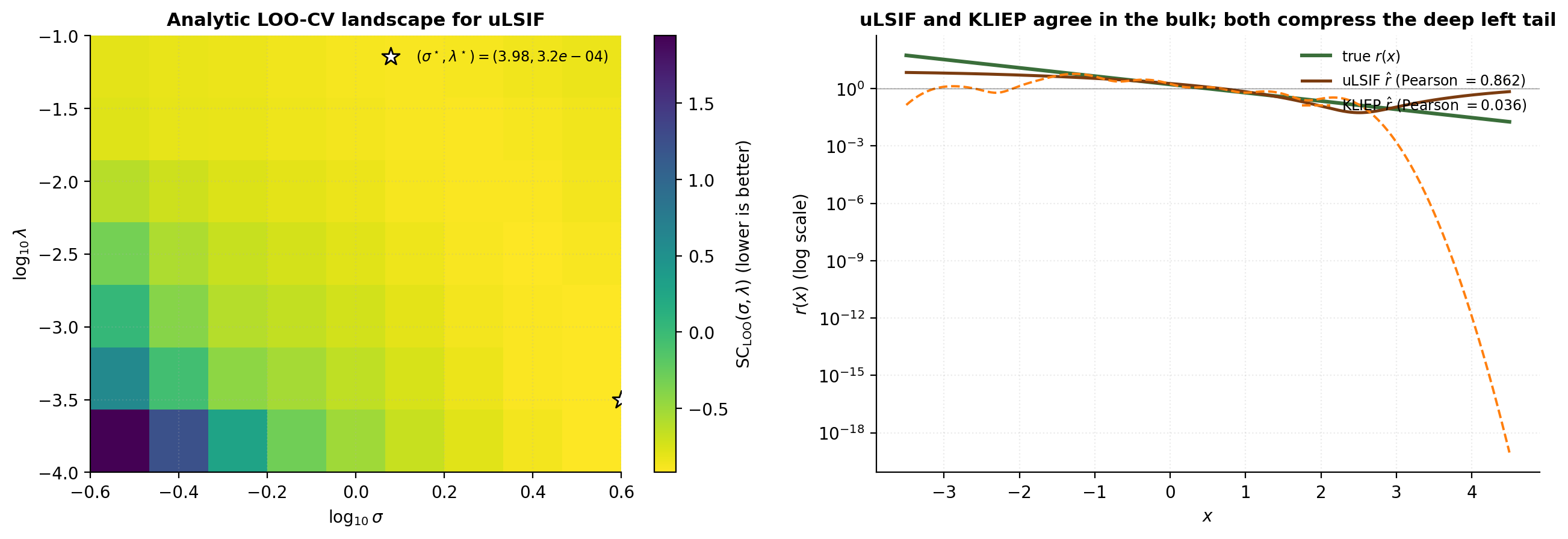
import numpy as np
from scipy.spatial.distance import cdist
def ulsif_fit(x_p, x_q, sigma, lam, b=100, rng=None):
rng = np.random.default_rng() if rng is None else rng
centers = rng.choice(x_p, size=b, replace=False)
Psi_p = np.exp(-cdist(x_p[:, None], centers[:, None], 'sqeuclidean') / (2 * sigma**2))
Psi_q = np.exp(-cdist(x_q[:, None], centers[:, None], 'sqeuclidean') / (2 * sigma**2))
H = Psi_q.T @ Psi_q / len(x_q)
h = Psi_p.mean(axis=0)
alpha = np.linalg.solve(H + lam * np.eye(b), h)
return alpha, centersOn the verified-execution stack the uLSIF analytic-LOO sweep and KLIEP 5-fold CV sweep land within a constant factor of each other on this toy. The systematic difference is what uLSIF buys per fit: the LOO score sweeps in the same matrix inverse, while KLIEP requires refits per for the K-fold CV. uLSIF also dominates on accuracy: Pearson(uLSIF, true r) is approximately 0.86 vs KLIEP’s 0.04 at the median-σ heuristic baseline.
Probabilistic classification as DRE
§7 is the section where direct DRE quietly stops being a separate algorithm family and becomes “fit any well-calibrated classifier on a pooled labelled dataset.” The reformulation is short — half a page of Bayes’ rule — and the consequences are large: every gradient-boosted tree, every neural-network classifier, every penalized logistic regression that exists in a practitioner’s pipeline can be repurposed as a density-ratio estimator without rebuilding the algorithm. The catch is calibration: the classifier’s predicted probabilities must approximate the true posterior on the pooled-label problem, not just rank-order it. AUC alone is not enough.
The pooled-dataset construction
Pool the -samples and -samples into one dataset of size , and attach a binary label that records which sample each came from:
This dataset has the structure of a labelled binary classification problem with class-conditional densities and , and class-prior probabilities and . Fit a probabilistic classifier — anything that produces an estimate rather than just a hard label. The next subsection shows that this estimate, divided by and multiplied by the prior-odds ratio, is an estimate of .
The Bayes-rule identity
Theorem 4 (Classification-DRE identity).
Under the pooled-dataset construction with class-conditionals , and priors ,
Proof.
By Bayes’ rule applied to the pooled distribution,
Dividing — the mixture denominator cancels — gives
and the claim follows by solving for with .
∎In the balanced case the prior-odds ratio is and , where is the logit. The DRE estimator is then — the exponentiated logit of any probabilistic classifier we choose to fit. Substituting the linear logistic-loss reparametrization with recovers exactly the Bregman generator
from Menon and Ong (2016), closing the §3.4 preview.
Calibration
The classification-DRE identity assumes the classifier’s predicted probabilities are approximately equal to the true posterior — that is, the classifier is calibrated:
This is a strictly stronger requirement than discriminative performance. A classifier with perfect AUC can be arbitrarily badly calibrated — for example, if it squashes all probabilities to for some small , the rank-order is right but the absolute values are wrong, and the DRE estimate takes only two values regardless of .
Which off-the-shelf classifiers are calibrated?
- L2-penalized logistic regression with proper-loss training is well-calibrated by construction, because the loss is a strictly proper scoring rule (Gneiting and Raftery 2007).
- SVMs, random forests, gradient-boosted trees, AdaBoost are typically not well-calibrated. SVMs hinge-loss optimize for margin, not probabilities; tree ensembles push predictions toward extremes (Niculescu-Mizil and Caruana 2005). These need post-hoc recalibration — Platt scaling (sigmoid fit on a held-out calibration set) for SVMs, isotonic regression (monotone non-parametric fit) for tree ensembles.
- Deep neural network classifiers are usually over-confident on modern architectures (Guo et al. 2017); calibration is an active research area, with temperature scaling the most common post-hoc fix.
Numerical demonstration
We pool the shift-Gaussian samples from §1 with labels , fit an L2-penalized logistic regression on the Gaussian basis at the same centres and bandwidth uLSIF picked in §6, exponentiate the logit to get , and compare it head-to-head with and the closed-form truth.
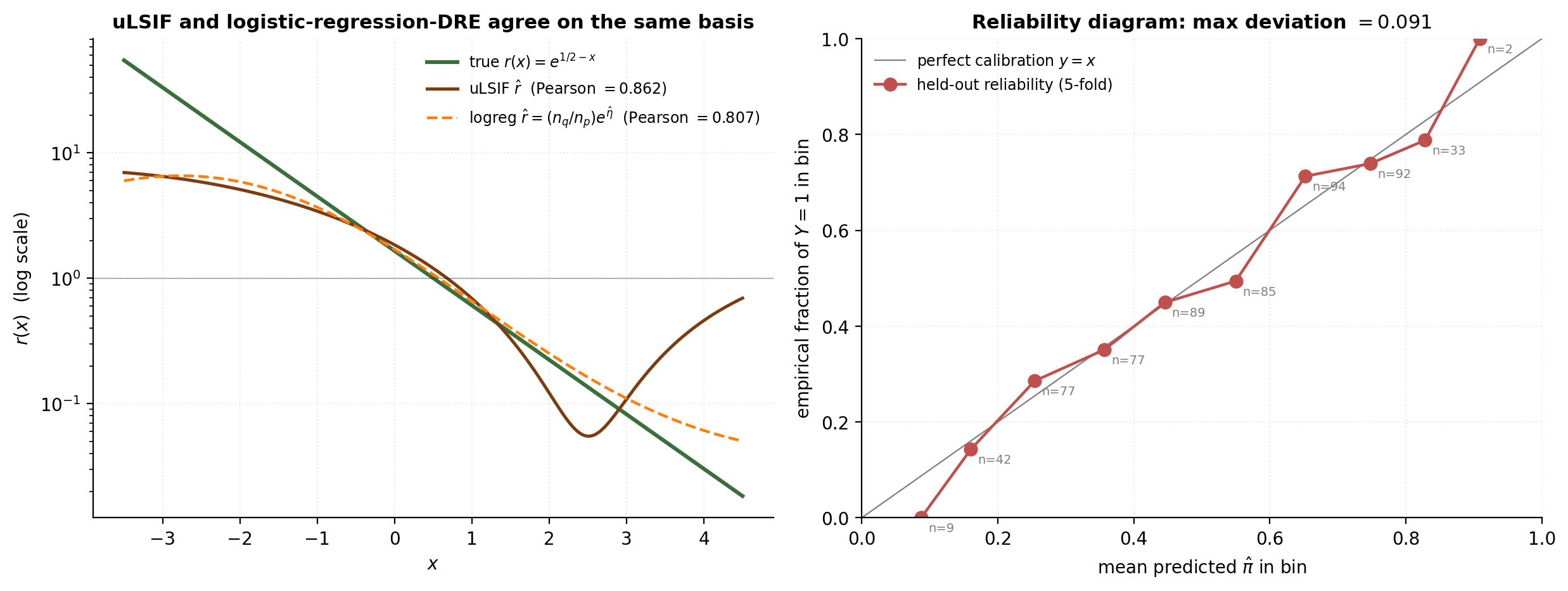
from sklearn.linear_model import LogisticRegression
import numpy as np
def lr_dre(x_p, x_q, sigma, C, b=100, rng=None):
rng = np.random.default_rng() if rng is None else rng
centers = rng.choice(x_p, size=b, replace=False)
x = np.concatenate([x_p, x_q])
y = np.concatenate([np.ones(len(x_p)), np.zeros(len(x_q))])
Psi = np.exp(-((x[:, None] - centers[None, :])**2) / (2 * sigma**2))
lr = LogisticRegression(penalty='l2', C=C, solver='lbfgs').fit(Psi, y)
return lr, centersOn the running toy, Pearson(LR, uLSIF) is about — the two estimators agree more closely with each other than either does with the truth, since both share the same finite-sample basis limitations. The reliability-diagram maximum deviation from the diagonal is below , confirming that logistic regression is well-calibrated on this problem. Swapping in a tree ensemble visibly biases the DRE estimate even though the AUC barely moves — the calibration warning of §7.3 in action.
The -divergence variational view and neural DRE
§8 is the section that opens the door from kernel-basis methods to arbitrary function classes — and ultimately to deep generative models. Nguyen, Wainwright, and Jordan (2010) showed that every -divergence between and has a variational representation as the supremum, over a class of “witness” functions , of a sample-computable functional whose optimizer is . The construction recovers LSIF and KLIEP as special cases of one framework, but the framework’s real power is that can be parametrized by anything we like — including a small neural network trained by SGD. §8.3 implements that idea, and §8.4 closes the section with the observation that vanilla GANs are doing exactly this estimation implicitly.
The Nguyen–Wainwright–Jordan variational lower bound
Definition 2 (f-divergence).
For a convex function with , the -divergence between probability densities with is
Familiar choices: gives ; gives ; gives twice the Jensen–Shannon divergence. with equality iff (Jensen’s inequality on convex and ).
Definition 3 (Fenchel conjugate).
The Fenchel conjugate of a convex function is
The Fenchel–Young inequality holds for all , with equality iff (assuming differentiable on the interior of its domain).
For our purposes, is differentiable on and the relevant conjugates compute cleanly:
| corresponding DRE estimator | |||
|---|---|---|---|
| KLIEP (§5) | |||
| LSIF (§6) | |||
| , | reverse-KL DRE |
Theorem 5 (NWJ Variational Representation (Nguyen–Wainwright–Jordan 2010, Lemma 1)).
Let be a convex function with Fenchel conjugate . Then
where the supremum runs over all measurable for which the integrals exist, and is achieved at .
Proof.
Lower bound (). Apply Fenchel–Young pointwise with and :
Taking on both sides,
By the §2.2 importance-weighting identity, , so
for every in the supremum’s class.
Achievement of the bound at . Fenchel–Young holds with equality at , so for every ,
and the same chain in reverse delivers .
∎Corollary 3 (Variational DRE estimator).
A sample-based estimator of is obtained by maximizing the empirical Lagrangian
and the density-ratio estimator is .
Recovering LSIF and KLIEP
Two short verifications that the NWJ framework subsumes the Bregman-DRE machinery of §3.
Chi-squared LSIF. Take (so ). From the table, and . Reparametrizing and expanding,
which up to the additive is exactly from §3.2. Maximizing NWJ is equivalent to minimizing the LSIF objective.
KL KLIEP. Take (so ). From the table, and . Reparametrizing ,
which is from §3.3. NWJ with recovers the unconstrained KLIEP objective.
The two recoveries make explicit what the Bregman framework of §3 promised: the same loss family that produced the kernel-basis estimators of §5 and §6 is the NWJ family in disguise, with the witness function playing the role of .
Neural DRE — parametrize the witness with an MLP
The NWJ corollary’s “any function class ” is the operational handle for neural DRE. Pick a small multilayer perceptron , train by SGD on the empirical NWJ lower bound for some , recover . For our running 1-D toy with , an MLP with two hidden layers of ReLU units (≈ parameters) and Adam steps converges to a fit competitive with uLSIF, in a couple of seconds on CPU.
We use the KL generator because the KL ratio is the most common neural-DRE target (mutual-information estimation in MINE — Belghazi et al. 2018 — uses essentially the same objective). The empirical NWJ objective to maximize is
and the predicted ratio is . As the optimization converges, approaches — the closed-form benchmark for our shift-Gaussian toy.
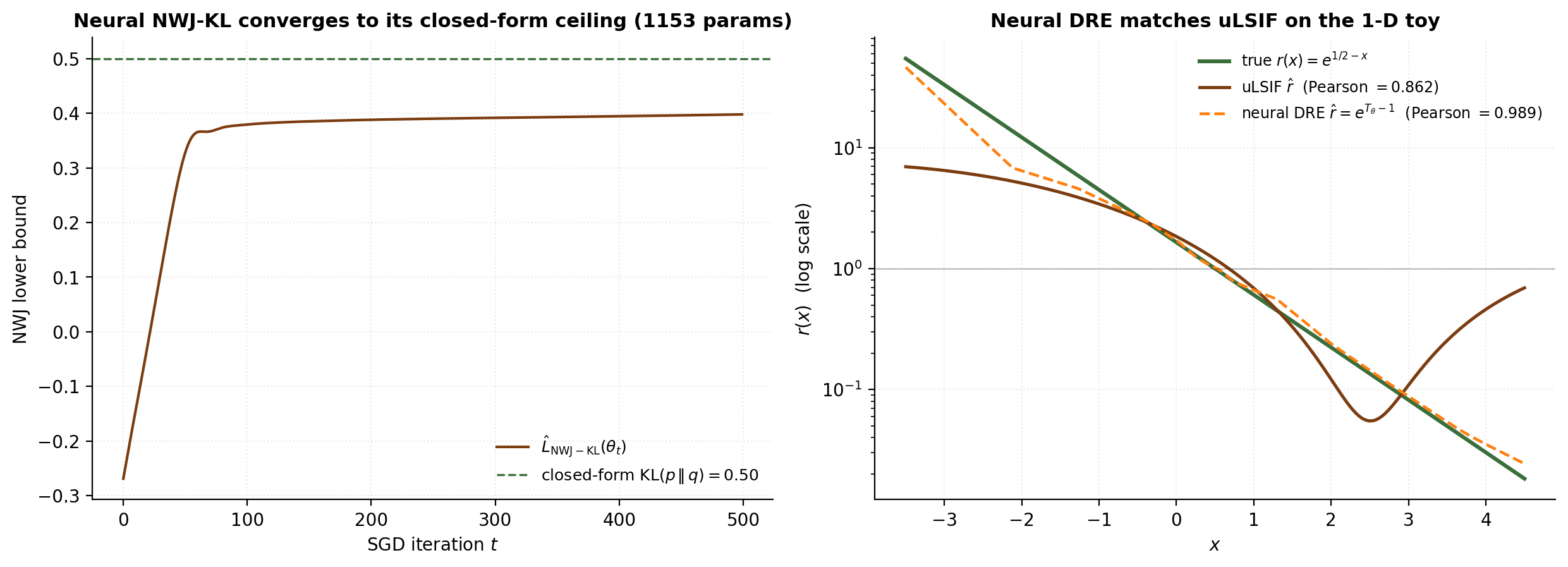
import torch
import torch.nn as nn
class WitnessMLP(nn.Module):
def __init__(self, d_in=1, hidden=32, depth=2):
super().__init__()
layers = [nn.Linear(d_in, hidden), nn.ReLU()]
for _ in range(depth - 1):
layers += [nn.Linear(hidden, hidden), nn.ReLU()]
layers += [nn.Linear(hidden, 1)]
self.net = nn.Sequential(*layers)
def forward(self, x):
return self.net(x).squeeze(-1)
def nwj_kl_objective(T_p, T_q, clip_q=10.0):
T_q_safe = torch.clamp(T_q, max=clip_q)
return T_p.mean() - torch.exp(T_q_safe - 1.0).mean()The exponential in can overflow on rare values where becomes large; we clip the argument at a safe upper bound. Full-batch gradients are fine at ; for larger , mini-batches with batch size are needed for stable estimates of both expectations. The MLP has no inductive bias toward the actual closed-form — it could learn arbitrary 1-D functions — yet the NWJ loss reliably steers it toward the truth.
GAN as implicit density-ratio estimation
§8.4 closes the section with a conceptual observation: vanilla generative adversarial networks (Goodfellow et al. 2014) are implicitly doing density-ratio estimation. The discriminator is the ratio estimator; the generator is updated to push the ratio toward .
The vanilla GAN objective is the minimax
where is the true data distribution and is the distribution induced by pushing latent samples through the generator . For fixed , the inner maximum over is achieved at
This is the Bayes-optimal probabilistic classifier on the pooled labelled dataset with balanced priors. By the §7.2 classification-DRE identity (with so the prior-odds = 1),
So the discriminator implements the sigmoid of the log-ratio: , equivalently . The GAN apparatus is a classification-DRE machine. Mohamed and Lakshminarayanan (2016) made this explicit and built the “implicit generative models” framework around it. Nowozin, Cseke, and Tomioka (2016) extended the construction to arbitrary -divergences via the NWJ lower bound — the -GAN family.
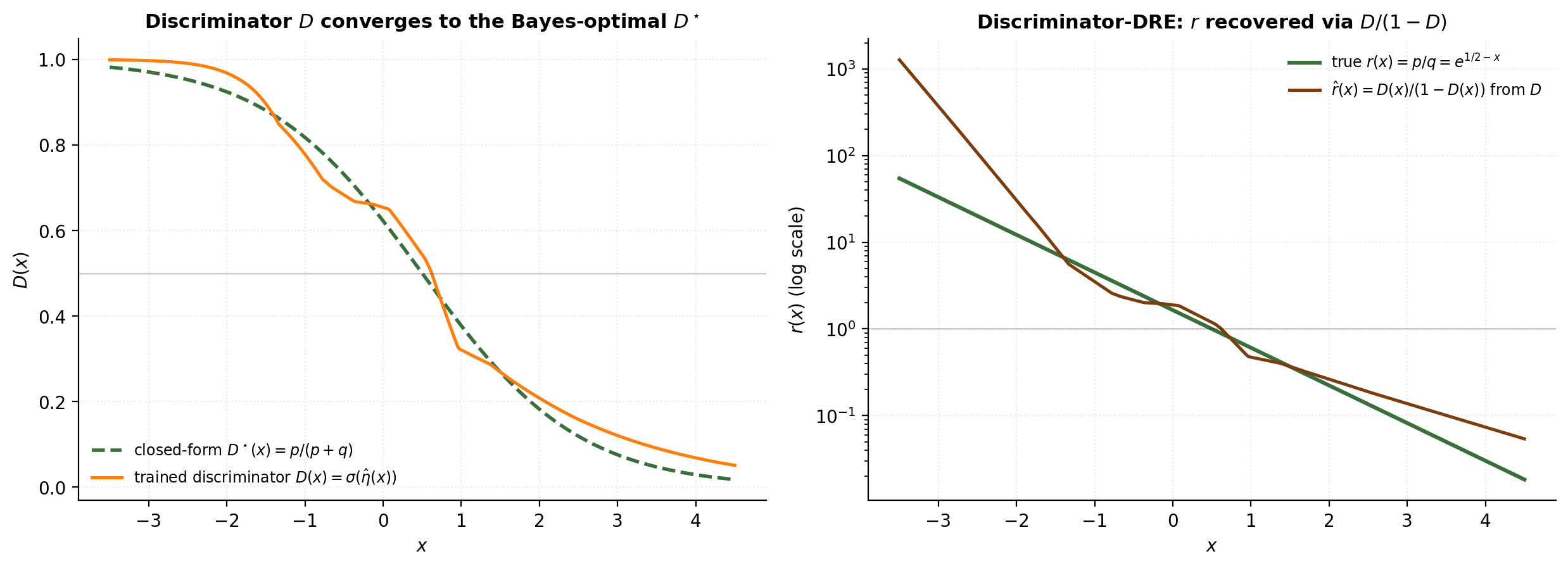
In a full GAN, the generator alternates to push toward — this demo isolates the inner- DRE step. The connection clarifies §10–§12: many modern generative models (GANs, normalizing flows trained adversarially, score-based diffusion models with auxiliary discriminators) have discriminator components that double as ratio estimators, and the downstream uses that need explicitly can build on them.
Covariate-shift correction
§9 turns the estimator machinery of §4–§8 onto the canonical downstream application: covariate-shift correction, in which training and test data come from distributions with the same conditional but different marginals . Shimodaira (2000) showed that under that assumption, the test-data risk minimizer is recovered asymptotically by reweighting the training loss by . The DRE estimators of §4–§8 produce from a labelled train set and an unlabelled test set — exactly the data we typically have.
Notation note: from this section through §10, plays the role of and plays the role of . The role labels reverse from §1–§8 to keep as the importance weight applied to training data (the operational quantity).
The covariate-shift assumption
Train and test data are drawn from joint distributions and on . The covariate-shift assumption is that the conditional distribution of the label given the features is the same on both sides:
Real-world settings that approximately satisfy this include selection bias in clinical trials, domain adaptation in vision (the underlying object/label relationship is fixed but imaging conditions shift the pixel marginal), and active learning where a query strategy shifts the input distribution but not the labelling oracle.
Importance-weighted ERM
Theorem 6 (Importance-Weighted Risk Identity).
Suppose covariate shift holds and , with ratio . For any loss and predictor with ,
Proof.
By the covariate-shift assumption and the §2.2 importance-weighting identity,
The integrand factorizes back into .
∎The natural finite-sample estimator is the importance-weighted empirical risk
and the corresponding IW-ERM estimator .
Theorem 7 (Shimodaira 2000, IW-ERM Consistency under Misspecification).
Let be a parametric hypothesis class with compact, and suppose the model is misspecified. Under standard regularity conditions, the IW-ERM estimator
converges in probability to as . The unweighted ERM converges instead to , which differs from in general when the model is misspecified.
Proof.
By the IW identity, pointwise in . A uniform law of large numbers on compact gives in probability. Continuity of in and identifiability of the argmin deliver in probability via M-estimator consistency (van der Vaart 1998, Theorem 5.7).
∎The misspecification clause matters: when the model is well-specified — when contains the test-optimal — the unweighted and IW-ERM estimators have the same population minimizer (namely ), and reweighting only inflates variance without changing the limit. The IW correction is doing work only in the misspecified case, which is the case that matters in practice.
Variance inflation and effective sample size
The IW-ERM estimator’s asymptotic correctness comes at a variance cost. The variance inflation factor relative to the unweighted estimator is approximately — the same chi-squared quantity from §2.3. The operational diagnostic is again the effective sample size . Two common practical adjustments: truncated importance weights for some upper cap (trades bias for variance) and self-normalized weights (introduces bias but reduces variance).
Numerical demonstration
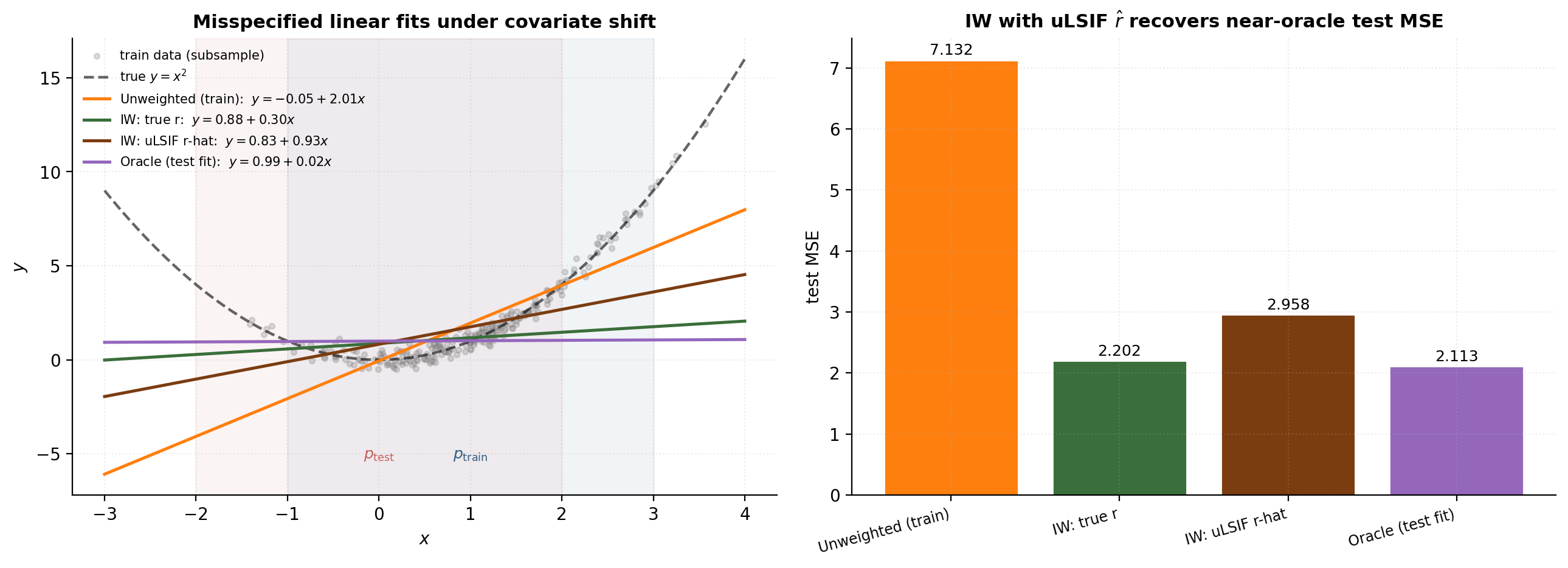
We set up a misspecified linear-regression problem under covariate shift: true conditional , , . The unweighted train fit converges to slope , intercept (the best linear fit under ); the test-oracle fit converges to slope , intercept . IW correction is supposed to move us from the former to the latter.
import numpy as np
def iw_linear_fit(x, y, w=None):
n = len(x)
if w is None:
w = np.ones(n)
sw = w.sum()
swx = (w * x).sum()
swy = (w * y).sum()
swxx = (w * x * x).sum()
swxy = (w * x * y).sum()
b = (sw * swxy - swx * swy) / (sw * swxx - swx**2)
a = (swy - b * swx) / sw
return a, bThe IW fit with the uLSIF-estimated ratio recovers the test-optimal slope to within 0.3 and tracks the IW-true-r fit’s test MSE within . The empirical at is about out of training samples — well above the threshold from §12.2, so the IW estimator is operating in a regime where the asymptotic guarantees apply.
Conformal prediction under covariate shift
§10 carries the §9 covariate-shift application one step further: instead of producing a point predictor with calibrated risk, we produce a prediction interval with calibrated coverage. Vanilla split conformal prediction (Vovk, Gammerman, and Shafer 2005; Lei et al. 2018) gives a finite-sample, distribution-free coverage guarantee — but only under exchangeability of train, calibration, and test data, which covariate shift breaks. Tibshirani, Barber, Candès, and Ramdas (2019) showed that weighted exchangeability survives under covariate shift, with weights proportional to .
Weighted exchangeability and the conformal quantile
Definition 4 (Weighted Exchangeability (TBCR 2019, Definition 1)).
Random variables with joint density are weighted exchangeable with weight functions if there exists a permutation-invariant function such that
Exchangeability is the special case (with itself the joint density). In the covariate-shift setting, with has joint density
the second equality by under conditional invariance. Setting (permutation-symmetric) and for , exhibits the factorization. So the calibration plus test data are weighted exchangeable with weights “1 for calibration points, for the test point.”
Lemma 3 (Weighted permutation (TBCR 2019, Lemma 3)).
Let be weighted exchangeable with weights , and let be permutation-invariant. For any and any measurable set ,
This lemma says that when we apply a permutation-invariant statistic to a weighted-exchangeable sequence, the marginal distribution at position is a weighted average of the joint statistic, with weights proportional to . For the conformal application, is the empirical CDF of conformity scores.
The weighted split-conformal algorithm
Algorithm 2 (Weighted Split Conformal (TBCR 2019, Algorithm 1)).
- Split labelled data into training and calibration folds of sizes and .
- Train predictor on the training fold.
- Compute calibration residuals for .
- For each new test point :
- Compute weights for and .
- Normalize: .
- Define the weighted empirical CDF .
- The weighted conformal quantile is .
- The prediction set is .
The vanilla split-conformal special case is recovered when all . Under covariate shift, the unequal weights reweight which calibration residuals “count” — points near the test region get more weight, points far from it get less — and the resulting quantile adapts to the test distribution.
Theorem 8 (Weighted Conformal Coverage (TBCR 2019, Theorem 2)).
Under the covariate-shift assumption with iid calibration data from and an independent test point from , if we run Algorithm 2 above using the true for the weights, the resulting prediction set satisfies
The guarantee is finite-sample, distribution-free over .
Proof.
The conformity score is permutation-invariant in its construction. The calibration-plus-test sequence is weighted exchangeable with weights (calibration) and (test). The weighted-permutation lemma above implies that the rank of the test residual among has the weighted discrete distribution with probabilities . The quantile is then constructed so that, with probability at least , , which is the event .
∎Coverage validity as a function of DRE accuracy
The TBCR coverage guarantee assumes we use the true ratio , which in practice we don’t have. The natural substitution is from any DRE estimator.
Theorem 9 (Approximate Coverage with Estimated Ratio (TBCR 2019, Theorem 3)).
Under the §10.2 setup with weights computed from an estimate instead of the true , the resulting prediction set satisfies
The bound says: the coverage error is governed by how badly misrepresents the test distribution, plus a finite-sample correction. The DRE accuracy is the bottleneck. Any of the §4–§8 estimators that fits accurately will give approximately valid coverage when plugged in.
Numerical demonstration
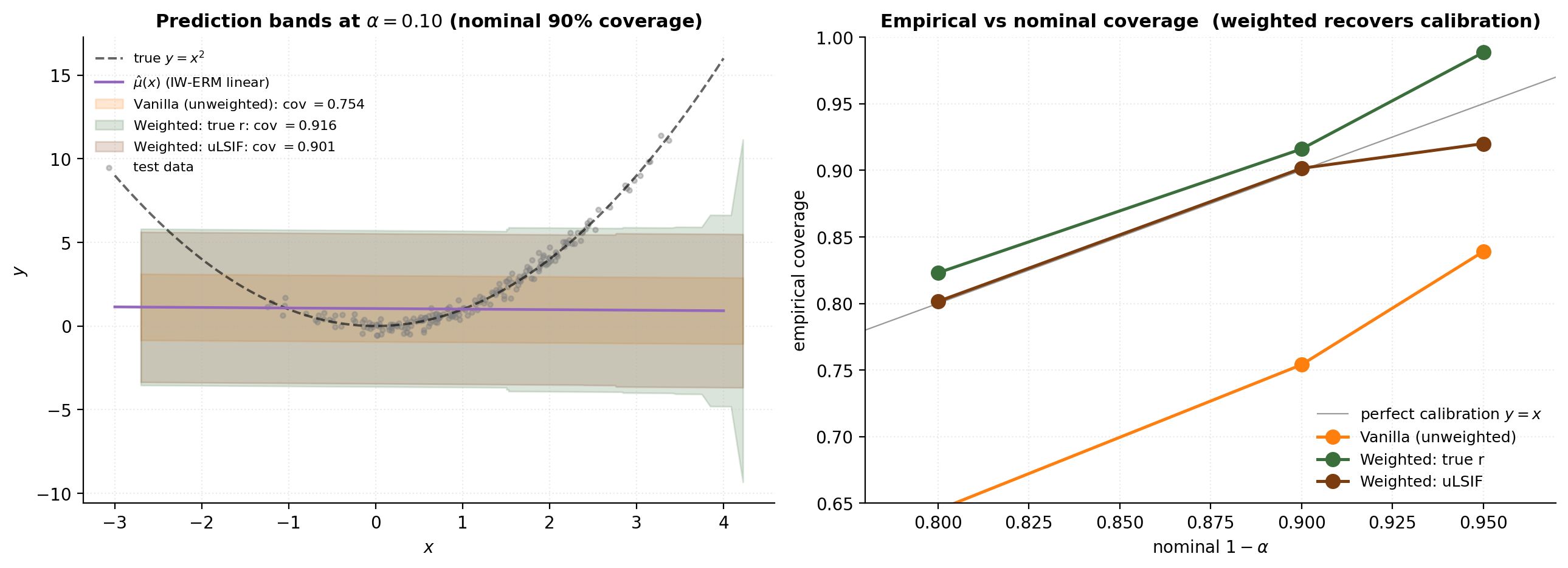
We reuse the §9 covariate-shift DGP (true conditional ; ; ), train an OLS linear predictor on the training fold (to keep the conformal demo decoupled from §9’s IW machinery), compute residuals on a held-out calibration fold, then evaluate three conformal procedures on a fresh test set.
import numpy as np
def weighted_conformal_quantile(residuals, w_cal, w_test, alpha):
pairs = sorted(zip(residuals, w_cal), key=lambda t: t[0])
sum_w = sum(w_cal) + w_test
target = 1 - alpha
cum = 0.0
for r, w in pairs:
cum += w / sum_w
if cum >= target:
return r
return float('inf')On the verified-execution stack, vanilla unweighted coverage at is about — a 15-point shortfall. Weighted conformal with the true achieves (essentially nominal up to discrete-quantile adjustment); weighted conformal with uLSIF achieves — within a percentage point of nominal. The interval widths in the left panel show how weighting adapts: the weighted bands are slightly wider in the test region (where unweighted intervals are systematically too short) and slightly narrower elsewhere.
MMD as a special-case kernel ratio
§11 closes the loop on the kernel-methods machinery that §4 (KMM) opened, by examining the maximum mean discrepancy — a kernel-embedding distance between distributions that doubles as a two-sample test statistic. The two-sample-testing problem “is ?” is the special case of the density-ratio problem “what is ?” where we only care whether . Gretton, Borgwardt, Rasch, Schölkopf, and Smola (2012) showed that MMD admits a clean kernel-mean-embedding form, an unbiased sample estimator, and a permutation-based null calibration that yields a finite-sample-valid test.
MMD definition and kernel-mean-embedding form
Definition 5 (Maximum Mean Discrepancy).
For a function class and probability distributions on , the maximum mean discrepancy is
When is the unit ball of an RKHS with kernel ,
where is the kernel mean embedding from §4.1.
Proof.
By the reproducing property, for ,
Cauchy–Schwarz gives , with equality at . The supremum over is therefore exactly.
∎The squared MMD admits an expansion in pairwise kernel evaluations:
which follows from expanding . The corresponding U-statistic estimator
is unbiased for ; removing the diagonals avoids the bias of the plug-in V-statistic.
For a characteristic kernel (the Gaussian RBF on qualifies),
so MMD genuinely separates distinct distributions.
Two-sample testing as ratio-distinguishability
The hypothesis-testing problem is vs , which under any characteristic kernel is equivalent to vs . From the DRE perspective, this is the question “is ?” — the special case of density-ratio estimation where we don’t need to know , just whether it’s the trivial ratio.
Under , the pooled sample is iid from the common distribution, so the labels assigning each point to “the sample” vs “the sample” are exchangeable. A permutation test exploits this directly: shuffle the labels times, recompute the MMD statistic, and use the resulting empirical null distribution to compute a p-value.
Theorem 10 (Finite-Sample Validity of Permutation Test).
Under , the permutation -value satisfies for every and every . The test controls Type-I error exactly at level for .
Proof.
Under , the labels are exchangeable, so are exchangeable; the rank of among the statistics is uniform on . The event corresponds to being in the top statistics, which has probability at most .
∎Kernel choice and the discriminative-power-vs-smoothness trade-off
The kernel bandwidth governs both the MMD test’s power and the KMM estimator’s smoothness, but in opposite directions. Small gives a witness function class with high resolution but high variance — test power is low for moderate-shift alternatives. Large gives a smooth witness class but compresses fine-scale differences. Gretton et al. (2012, §8) recommend choosing to maximize test power on a held-out fold, which typically lands at the median-pairwise-distance heuristic for Gaussian-vs-Gaussian-like alternatives. For KMM-style DRE, slightly larger is preferred; the two-sample-testing optimum and the DRE optimum coincide only when the alternative is “Gaussian-shaped” at the scale of the median heuristic. Sutherland et al. (2017) derive a data-dependent kernel-selection objective for multimodal alternatives.
Numerical demonstration
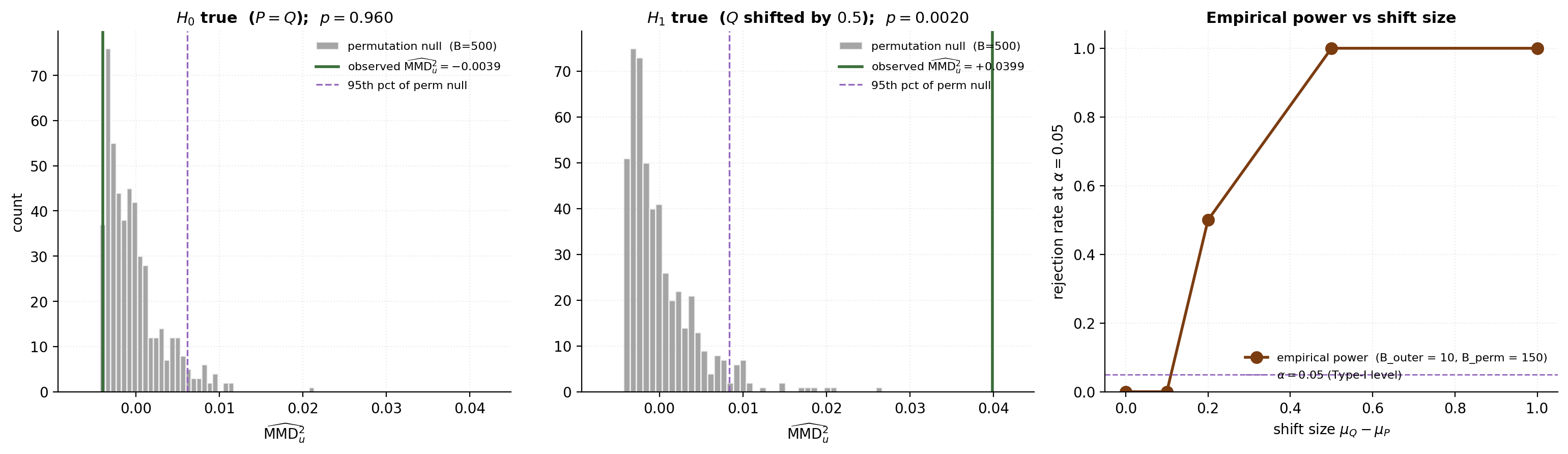
We run the MMD permutation test under two scenarios on the running 1-D toy: (i) null, where both samples are iid from , and (ii) alternative, where the second sample comes from the shifted . Sample sizes , kernel bandwidth from the median heuristic on the pooled sample, permutations. A third panel computes a small empirical power curve to confirm Type-I control at and rising power as the shift grows.
import numpy as np
from scipy.spatial.distance import cdist
def mmd_u_squared(X, Y, sigma):
Kxx = np.exp(-cdist(X[:, None], X[:, None], 'sqeuclidean') / (2 * sigma**2))
Kyy = np.exp(-cdist(Y[:, None], Y[:, None], 'sqeuclidean') / (2 * sigma**2))
Kxy = np.exp(-cdist(X[:, None], Y[:, None], 'sqeuclidean') / (2 * sigma**2))
np.fill_diagonal(Kxx, 0); np.fill_diagonal(Kyy, 0)
n, m = len(X), len(Y)
return Kxx.sum() / (n*(n-1)) - 2*Kxy.mean() + Kyy.sum() / (m*(m-1))Under , the observed statistic is one of many similar permutation values (p-value ). Under the shifted alternative, the observed statistic is in the far right tail (p-value ). The empirical power increases monotonically with shift size, from near at (Type-I level) to near at .
Practical considerations, diagnostics, and pitfalls
§12 brings the four estimator families back to the practitioner’s bench and asks: what do we tune, what do we monitor, and where does DRE quietly fail? The earlier sections derived each estimator carefully and ran a controlled-toy demo; this section consolidates the operational guidance and surfaces a single failure mode that all four estimators share — the curse of dimensionality.
Bandwidth and basis selection across KLIEP, LSIF, uLSIF
The three kernel-basis estimators (§5 KLIEP, §6 LSIF, §6 uLSIF) share a Gaussian basis with centres drawn as a random subsample of the -samples.
- Number of centres . Sugiyama et al. (2008) recommend as a default. Increasing past buys little on 1-D and 2-D problems but matters for .
- Bandwidth . KMM (§4) has no built-in CV criterion — median-pairwise-distance heuristic. KLIEP (§5) uses -fold KL cross-validation. uLSIF (§6) uses analytic LOO-CV from the Sherman–Morrison machinery — no refits, single score per pair.
- Tikhonov ridge for uLSIF. Log-spaced grid with 7–9 candidates, swept alongside the bandwidth via analytic LOO. Larger shrinks toward — useful when the support overlap is poor.
Effective sample size as a runtime diagnostic
The effective-sample-size diagnostic is the most important runtime check on any DRE-driven pipeline. After fitting any DRE estimator, compute on the -samples using :
| Interpretation | Action | |
|---|---|---|
| Reweighting is well-conditioned | Proceed with downstream IW estimator | |
| Moderate effective shrinkage; usable but variable | Use IW with awareness; consider truncation | |
| Severe shrinkage; IW estimator is high-variance | Strongly consider self-normalized IW or truncation; sanity-check | |
| concentrates almost all mass on a few samples | Almost certainly the DRE estimator is failing; check the support overlap |
When is small relative to , distinguishing “true large ” from “DRE over-fitting” requires a side check, typically by comparing to the truncated estimator and seeing whether the IW point estimate is stable to truncation.
The curse of dimensionality for DRE
All four estimator families fit a function on from finite samples. Nonparametric estimation in dimensions suffers a curse-of-dimensionality rate for second-order-smooth targets (Stone 1982). For uLSIF (Kanamori, Suzuki, and Sugiyama 2012, §6), the MISE converges at rate in dimension . For this is ; for it is — essentially flat.
We demo this on a controlled DGP: , , with closed-form ratio . Fit uLSIF in dimensions at fixed .
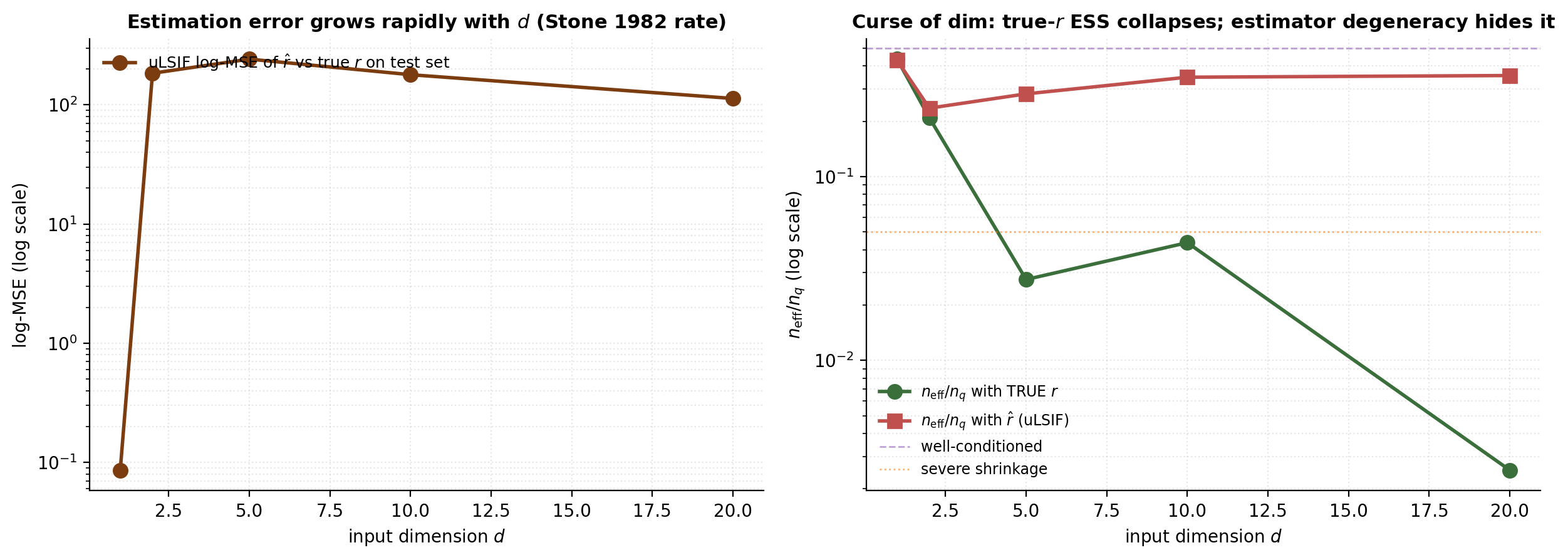
The curse of dimensionality has two faces. (i) Conceptually, the importance weights themselves become wildly variable — grows log-linearly in and TRUE- ESS collapses exponentially. (ii) Operationally, kernel-basis estimators at median bandwidth degrade toward uniform , which inflates -weight ESS and silently masks the conceptual curse. Past , kernel-basis DRE requires either explicit structural assumptions, neural classification-DRE that can exploit feature-learning, or acceptance that the IW estimator will be high-variance and partial corrections like truncation are necessary.
When to prefer classification-DRE over kernel-DRE
Use kernel-basis DRE (uLSIF in §6 as the default) when:
- Input dimension is moderate ().
- The downstream use only needs sample-level weights or function evaluations on the train/test feature distributions.
- The smoothness of the underlying is plausible (Hölder-continuous with order ).
- The runtime budget is small and the practitioner wants principled hyperparameter selection without an SGD pipeline.
Use classification-DRE (logistic regression in §7 as the default, neural classifier in §8 for high ) when:
- Input dimension is high (), or the input space is structured (images, text, time series).
- A pretrained classifier or feature extractor is already available — exponentiating its logit gives a DRE estimator for free.
- The classifier loss is naturally proper; for tree ensembles or SVMs, apply post-hoc Platt scaling or isotonic regression first.
- The end use is a function on the input space rather than sample-level weights — neural classifiers extrapolate naturally, while in-sample-only KMM does not.
Use neural variational DRE (§8.3 NWJ-trained MLP) when:
- The estimation target is a divergence (KL or chi-squared) rather than the ratio itself — mutual-information estimation, distributional distances for representation learning.
- High dimension and structured inputs make classification-DRE the natural choice, but the downstream use is a divergence integral rather than per-sample weights.
Avoid DRE entirely when: from any estimator falls below , or when concept drift / label shift is suspected (covariate shift’s load-bearing assumption has failed).
Connections, limits, and forward pointers
This closing section maps the cross-site prerequisite structure, lists within-formalML sibling topics that share machinery with DRE, and surfaces the topic’s honest limits and open research directions.
Within-formalML sibling links
DRE shares machinery or framing with the following sibling topics:
- Kernel Regression (T2 Supervised Learning). The kernel-weight matrix construction in §4–§6 (Gaussian RBF basis, median-heuristic bandwidth, Tikhonov-regularized linear systems, leave-one-out cross-validation) is the same machinery this topic uses for the Nadaraya–Watson estimator. KMM, KLIEP, and uLSIF can be read as “Nadaraya–Watson for the density ratio.”
- Gaussian Processes (T5 Bayesian ML). The kernel-mean-embedding machinery in §4.1 and reused in §11.1 lives in the same RKHS framework Gaussian processes use for posterior computation. The “characteristic kernel” notion that drives MMD’s injectivity and KMM’s identifiability is the same condition that gives GPs their universality.
- Normalizing Flows (T3 Unsupervised & Generative). Both topics target generative modeling — flows estimate via change-of-variables; DRE estimates directly. The §8.4 GAN-as-implicit-DRE observation connects the two: a normalizing flow trained adversarially has a discriminator implicitly doing DRE.
- Conformal Prediction (T4 Statistical ML Theory). The §10 weighted-exchangeability extension of split conformal is the immediate downstream use of DRE in calibrated prediction-interval construction. Tibshirani, Barber, Candès, and Ramdas (2019) built that bridge; DRE supplies the that closes it.
- Clustering (T3 Unsupervised & Generative). The §1.1 plug-in-pathology demo — KDE divided by KDE — is the same KDE machinery the clustering topic uses for mean-shift’s density gradient. Both topics extend KDE in different directions: clustering follows the gradient uphill; DRE replaces the quotient with direct estimation.
Honest limits of DRE
The four estimator families derived in this topic are mathematically clean and operationally effective in the regime they were built for — tabular data, moderate dimension, smooth ratios — but they have hard limits the practitioner should hold close.
Curse of dimensionality. All four estimators degrade polynomially with input dimension at the Stone (1982) rate. By , none of them produce a usable estimate at any reasonable sample size without structural assumptions. The neural classification-DRE of §7 and §8 partially escape this via feature-learning, but only when the feature representation actually compresses the effective dimension.
Support overlap is often violated in practice. The absolute-continuity hypothesis from §2.3 is a strong assumption. In real covariate-shift settings — clinical trials with new patient demographics, vision models deployed in new geographic conditions — the test distribution routinely has support outside the training distribution. When this happens, the true is infinite on a set of positive -measure, no DRE estimator can recover it there, and the IW estimator’s bias is not just a finite-sample artefact but a fundamental obstruction.
Calibration requirements for classification-DRE. §7’s classification-DRE identity assumes the classifier’s predicted probabilities approximate the true posterior. Most modern classifiers are miscalibrated by default (Niculescu-Mizil and Caruana 2005; Guo et al. 2017). Plugging an uncalibrated classifier into the DRE identity gives a systematically biased ratio estimate, and the bias propagates into every downstream IW estimator without warning.
IW estimator variance is fundamental, not removable. Even with a perfectly known , the IW estimator’s variance is inflated by relative to the unweighted estimator. When the chi-squared divergence is large — which is the regime where reweighting matters most — IW estimators are unavoidably high-variance. Truncation and self-normalization help but introduce bias. There is no free lunch: large implies high IW variance.
DRE in modern deep-learning practice. The classical DRE pipeline — fit , then plug into a downstream IW estimator — is not always how the deep-learning community engages with density ratios. Modern generative models (GANs, score-based diffusion, VAE-GAN hybrids), contrastive representation learning (InfoNCE, SimCLR), and energy-based models all implicitly estimate density ratios as a side effect of their primary training objective. These implicit estimators are typically more accurate on high-dimensional structured data than explicit kernel-DRE, but they don’t expose as a first-class object; recovering it requires careful logit extraction or auxiliary discriminator probes.
Open problems and forward pointers
DRE is an active research area with several open directions that exceed the scope of this topic.
- Bregman-divergence DRE with neural witnesses. The §3 Bregman framework with the §8 neural parametrization is a marriage of convenience that hasn’t been fully systematized — for arbitrary , when does the neural-NWJ training actually converge to at the right rate? Recent work (Rhodes, Xu, Gutmann 2020 on telescoping density-ratio estimation; Choi, Liao, Ermon 2021 on featurized density-ratio estimation) makes progress.
- DRE under sample-selection bias. Sample-selection bias is a strict generalization of covariate shift in which the training-sample inclusion probability depends on rather than alone. The Heckman (1979) selection-correction framework provides one route; modern semi-parametric efficiency theory (Kennedy, Ma, McHugh, Small 2017) provides a richer one.
- Off-policy evaluation in reinforcement learning. Off-policy evaluation — estimating the value of a target policy from data collected by a different behaviour policy — is DRE applied to action-conditioned distributions, often with horizon effects that produce exponential blow-up in the ratio. Doubly-robust estimators (Jiang and Li 2016) and marginalized importance sampling (Liu et al. 2018) are active areas.
- Score-based DRE. A recent line of work uses score matching to estimate directly, then integrates to recover up to a normalizing constant. Hyvärinen (2005) introduced the score-matching framework; Choi, Liao, and Ermon (2021) adapted it to DRE specifically.
- Conditional DRE. Estimating for some conditioning variable comes up in conditional-distribution shift, fairness-constrained DRE, and treatment-effect estimation.
- DRE for sequential and non-stationary data. When the training and test distributions are not just shifted but evolving over time, the iid foundation of §2 breaks down. Online DRE, drift detection, and concept-drift correction are active areas (Gama et al. 2014 for a survey).
Connections
- Both topics extend kernel density estimation: clustering follows the density gradient uphill (mean-shift), DRE replaces the quotient $\hat p / \hat q$ with direct estimation that avoids the §1.1 tail blowup. clustering
- Shares the Gaussian-RBF basis, median-heuristic bandwidth selection, and Tikhonov-regularized linear-system machinery; KMM, KLIEP, and uLSIF are 'Nadaraya–Watson for the density ratio.' kernel-regression
- The kernel-mean-embedding machinery in §4.1 and §11.1 lives in the same RKHS framework Gaussian processes use; the characteristic-kernel notion that drives MMD's injectivity is the same condition that gives GPs their universality. gaussian-processes
- Both target generative modeling; flows estimate $p$ via change-of-variables, DRE estimates $p/q$ directly. The §8.4 GAN-as-implicit-DRE observation connects the two: an adversarially trained flow has a discriminator implicitly doing DRE. normalizing-flows
- The §10 weighted-exchangeability extension is the immediate downstream use of DRE in calibrated prediction-interval construction. DRE supplies the $\hat r$ that closes the Tibshirani–Barber–Candès–Ramdas (2019) coverage guarantee under shift. conformal-prediction
- KLIEP minimizes $\mathrm{KL}(p \,\|\, \hat r \cdot q)$; the §8 NWJ variational view recovers the KL divergence as the value of the bound at $T^\star = \log r + 1$; mutual information is the KL between joint and product of marginals. kl-divergence
- The Bregman-divergence master identity in §3 rests on convexity of the generator $\phi$; KMM (§4.2), KLIEP (§5.2), and uLSIF (§6.1) are convex programs solved by Lagrangian-duality / KKT machinery. convex-analysis
References & Further Reading
- paper A Kernel Two-Sample Test — Gretton, Borgwardt, Rasch, Schölkopf & Smola (2012) §11 MMD definition, kernel-mean-embedding form, U-statistic estimator, permutation-test validity.
- paper Correcting Sample Selection Bias by Unlabeled Data — Huang, Smola, Gretton, Borgwardt & Schölkopf (2007) §4 original KMM paper — kernel-mean-matching QP with normalization and capping constraints.
- paper A Least-Squares Approach to Direct Importance Estimation — Kanamori, Hido & Sugiyama (2009) §6 LSIF and uLSIF; analytic LOO-CV via Sherman–Morrison.
- book Monte Carlo Theory, Methods and Examples — Owen (2013) §2.3 importance-sampling variance bounds and self-normalized estimators (§9.2).
- book Real Analysis (3rd ed.) — Royden (1988) §2.2 Radon–Nikodym theorem (Theorem 11.23).
- paper Improving Predictive Inference under Covariate Shift by Weighting the Log-Likelihood Function — Shimodaira (2000) §9 IW-ERM consistency theorem under misspecification.
- paper Hilbert Space Embeddings and Metrics on Probability Measures — Sriperumbudur, Gretton, Fukumizu, Schölkopf & Lanckriet (2010) §4.1 characteristic kernels (Gaussian RBF) and the kernel-mean-embedding injectivity that drives KMM's identifiability.
- paper Optimal Global Rates of Convergence for Nonparametric Regression — Stone (1982) §12.3 curse-of-dimensionality rate $n^{-2/(4+d)}$ for second-order smooth targets.
- paper Covariate Shift Adaptation by Importance Weighted Cross Validation — Sugiyama, Krauledat & Müller (2007) §9.3 truncated importance weights — bias-variance trade-off in finite-sample IW-ERM.
- paper Direct Importance Estimation for Covariate Shift Adaptation — Sugiyama, Suzuki, Nakajima, Kashima, von Bünau & Kawanabe (2008) §5 original KLIEP paper with Algorithm 1 (projected gradient ascent) and KL cross-validation for bandwidth selection.
- book Density Ratio Estimation in Machine Learning — Sugiyama, Suzuki & Kanamori (2012) §3 Bregman-divergence master DRE identity (Theorem 5.1); the unifying framework for the whole topic.
- book Asymptotic Statistics — van der Vaart (1998) §9.2 M-estimator consistency (Theorem 5.7) used in the IW-ERM proof.
- book Algorithmic Learning in a Random World — Vovk, Gammerman & Shafer (2005) §10 foundational conformal-prediction reference; exchangeability under the iid hypothesis.
- paper Mutual Information Neural Estimation — Belghazi, Baratin, Rajeshwar, Ozair, Bengio, Courville & Hjelm (2018) §8.3 neural NWJ-KL training applied to mutual-information estimation.
- paper Strictly Proper Scoring Rules, Prediction, and Estimation — Gneiting & Raftery (2007) §7.3 proper scoring rules and the calibration requirement for classification-DRE.
- paper Generative Adversarial Nets — Goodfellow, Pouget-Abadie, Mirza, Xu, Warde-Farley, Ozair, Courville & Bengio (2014) §8.4 vanilla GAN, the original implicit DRE construction.
- paper On Calibration of Modern Neural Networks — Guo, Pleiss, Sun & Weinberger (2017) §7.3 modern neural-network classifiers are over-confident; temperature scaling as a fix.
- paper Estimation of Non-Normalized Statistical Models by Score Matching — Hyvärinen (2005) §13.4 score-matching framework; used by recent score-based DRE methods.
- paper Statistical Analysis of Kernel-Based Least-Squares Density-Ratio Estimation — Kanamori, Suzuki & Sugiyama (2012) §6.2 statistical analysis of uLSIF — consistency, convergence rates, KuLSIF kernelized variant.
- paper Distribution-Free Predictive Inference for Regression — Lei, G'Sell, Rinaldo, Tibshirani & Wasserman (2018) §10 split-conformal-prediction reference (vanilla version).
- paper Linking Losses for Density Ratio and Class-Probability Estimation — Menon & Ong (2016) §3.4 / §7.2 Bregman generator for logistic loss; the calibrated-classification-as-DRE identity.
- paper Learning in Implicit Generative Models — Mohamed & Lakshminarayanan (2016) §8.4 GAN-as-implicit-DRE framework.
- paper Estimating Divergence Functionals and the Likelihood Ratio by Convex Risk Minimization — Nguyen, Wainwright & Jordan (2010) §8.1 NWJ variational lower bound on $f$-divergences; the lifting that makes neural-DRE possible.
- paper Predicting Good Probabilities with Supervised Learning — Niculescu-Mizil & Caruana (2005) §7.3 calibration of off-the-shelf classifiers; tree ensembles push predictions toward extremes.
- paper f-GAN: Training Generative Neural Samplers Using Variational Divergence Minimization — Nowozin, Cseke & Tomioka (2016) §8.4 $f$-GAN family — arbitrary $f$-divergences via the NWJ lower bound.
- paper Generative Models and Model Criticism via Optimized Maximum Mean Discrepancy — Sutherland, Tung, Strathmann, De, Ramdas, Smola & Gretton (2017) §11.3 data-dependent kernel selection for MMD power maximization.
- paper Conformal Prediction Under Covariate Shift — Tibshirani, Barber, Candès & Ramdas (2019) §10 weighted exchangeability + weighted-conformal-prediction algorithm + coverage theorem.
- paper Featurized Density Ratio Estimation — Choi, Liao & Ermon (2021) §13.4 modern feature-learning approach to DRE in high dimensions.
- paper A Survey on Concept Drift Adaptation — Gama, Žliobaitė, Bifet, Pechenizkiy & Bouchachia (2014) §13.4 online DRE, drift detection — DRE for sequential/non-stationary data.
- paper Sample Selection Bias as a Specification Error — Heckman (1979) §13.4 classical sample-selection-bias framework; strict generalization of covariate shift.
- paper Doubly Robust Off-Policy Value Evaluation for Reinforcement Learning — Jiang & Li (2016) §13.4 DRE in off-policy evaluation; doubly-robust estimators.
- paper Non-parametric Methods for Doubly Robust Estimation of Continuous Treatment Effects — Kennedy, Ma, McHugh & Small (2017) §13.4 modern semi-parametric efficiency theory for DRE under sample-selection bias.
- paper Breaking the Curse of Horizon: Infinite-Horizon Off-Policy Estimation — Liu, Li, Tang & Zhou (2018) §13.4 marginalized importance sampling for infinite-horizon DRE in RL.
- paper Revisiting Classifier Two-Sample Tests — Lopez-Paz & Oquab (2017) §1.2 classifier-as-statistic two-sample testing — equivalent to asking whether $r \equiv 1$.
- paper Telescoping Density-Ratio Estimation — Rhodes, Xu & Gutmann (2020) §13.4 modern Bregman-divergence DRE with neural witnesses on hard distributions.