Clustering
Mean-shift mode-finding on the KDE substrate: bandwidth-mode-count duality, basin-of-attraction partitions, and the k-means / GMM contrasts
Motivation: when linear partitions fail
The classic clustering algorithms — Lloyd’s k-means most prominently — partition space into pieces with flat boundaries. That’s fine when the true cluster shapes happen to be convex blobs, but it fails predictably the moment a cluster has an elbow, a curve, or any non-convex structure. Mean-shift clustering takes a different angle: rather than partitioning space, it climbs the density. Each point trails uphill toward a local high-density peak — a mode of the kernel density estimator we inherit from formalStatistics: kernel-density-estimation — and the cluster assignment falls out of which peak the trajectory lands at.
This section sets up the contrast geometrically. We defer the algebra (§3) and the convergence theory (§4) until we have a clear picture of what the algorithm is trying to do.
The k-means linear-Voronoi assumption and what breaks under non-convex clusters
Lloyd’s k-means picks centroids , assigns each data point to the nearest centroid, recomputes each centroid as the mean of its cluster, and iterates until convergence. The fixed point has a tidy geometric description: each cluster is the set of points closer to its own centroid than to any other — a Voronoi cell of the centroid configuration — and the boundary between adjacent clusters is the perpendicular bisector of the segment joining their centroids, a flat hyperplane. Every cluster is therefore a convex polytope.
That’s fine when the underlying generative shapes are convex; k-means on a well-separated isotropic Gaussian mixture recovers exactly the right partition. The convexity assumption is silent in the algorithm’s specification — there’s no parameter that relaxes it — so two crescents nested into a moon shape, two concentric rings, or an elongated strip parallel to another all force k-means to slice through what a human eye reads as a single connected piece. The algorithm doesn’t fail loudly; it returns a confident-looking wrong partition.
Density modes as a clustering target
Suppose are i.i.d. samples from a density . In the modal sense (Hartigan 1975), a cluster is a connected region of on which stays above some level, separated from other such regions by lower-density valleys. Each such region corresponds to a mode of : a local maximum where and the Hessian is negative definite. The clustering problem reduces to two coupled subproblems — find the modes of , and decide which mode each data point’s steepest-ascent trajectory converges to.
We don’t have ; we have . So the operational problem is: find the modes of , and trace each data point’s steepest-ascent trajectory on to its mode. Mean-shift is the algorithm that does this, with one elegant trick — the gradient-ascent step has a closed-form update that doesn’t require explicitly computing at each iteration. For now, the geometry: imagine the KDE surface in 2D as a hilly landscape, place a ball at each data point, let each ball roll uphill until it stops at a peak, and group together the data points whose balls stopped at the same peak. That’s the algorithm.
The signature contrast on make_moons
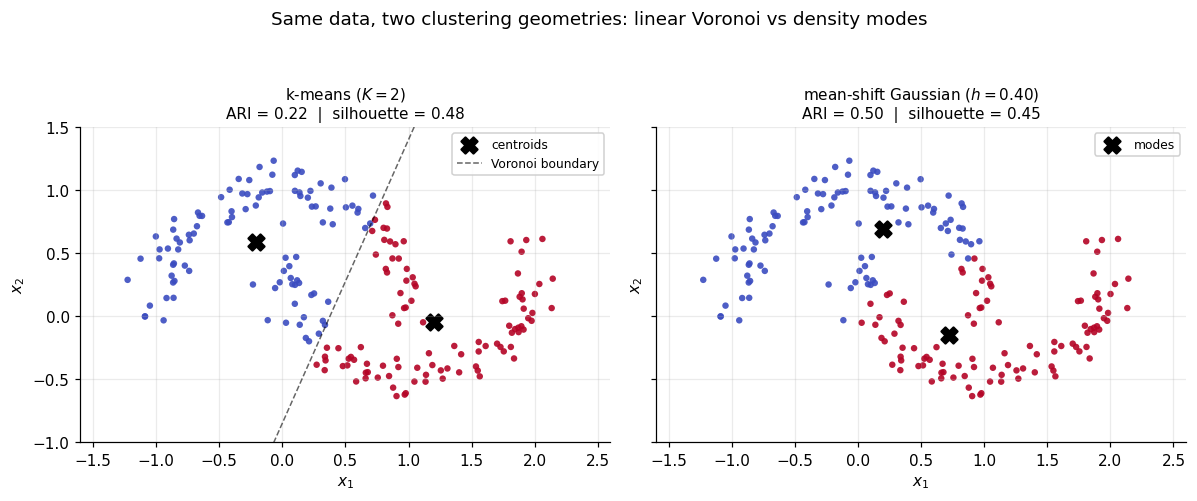
The cleanest demonstration is sklearn.datasets.make_moons(n_samples=200, noise=0.1, random_state=42): two interleaved crescents in separated by a thin gap. K-means with has nowhere reasonable to put a separating hyperplane — the perpendicular-bisector boundary cuts both crescents roughly in the middle, producing two clusters whose members are spread across both true crescents. Mean-shift with moderate bandwidth follows the density: each crescent has its own high-density ridge and its own mode, and the algorithm assigns each data point to its crescent.
Quantitatively, the adjusted Rand index (ARI; Hubert and Arabie 1985) measures cluster-assignment agreement against ground truth, with meaning perfect recovery and meaning no better than random. On this dataset, k-means scores with a clearly-wrong linear cut. Gaussian-kernel mean-shift at scores — roughly twice as high. The mean-shift partition is shape-correct: the two clusters follow the crescent ridges, with some boundary points near the gap mis-classified into the wrong crescent at noise = 0.1. The silhouette score (Rousseeuw 1987) rewards convex compactness and so reports the opposite ordering — k-means looks “tighter,” in the wrong way. The silhouette/ARI disagreement is a useful diagnostic any time a clustering metric prefers convex partitions over the right ones.
Roadmap
§2 recaps the KDE substrate and pins down what “mode” means in . §3 derives the mean-shift update as gradient ascent on — the central algorithmic result. §4 proves convergence: the monotone-density-ascent theorem (Comaniciu and Meer 2002) and Cheng’s (1995) fixed-point convergence. §5 introduces the bandwidth-mode-count duality and the mode tree. §6 takes a brief tour of kernel choice and explains why it matters less than for KDE-as-density-estimator. §7 turns the trajectory map into a clustering by tracking basins of attraction and merging modes; §8 covers the from-scratch implementation, the sklearn.cluster.MeanShift pitfalls, and scaling strategies. §9 and §10 are the contrast sections: k-means as the Voronoi limit, and GMM-via-EM as the parametric soft-clustering alternative. §11 points lightly at spectral clustering and DBSCAN — proper coverage lives in graph-laplacians and random-walks. §12 closes with cross-site references, honest limits, and forward pointers.
The KDE substrate and the mode-finding picture
We pinned down in §1 that the clustering problem we’ll solve is find the modes of and assign each data point to the mode its steepest-ascent trajectory lands at. This section makes both halves precise.
Recap of the multivariate KDE
Given i.i.d. samples from an unknown density , the kernel density estimator with kernel function and bandwidth is
We make three simplifying choices throughout this topic. (a) The kernel is radial: for some univariate profile function (non-increasing on ) and a normalizing constant . The profile function is the trick that powers the §3 derivation. (b) The bandwidth is isotropic and scalar, . (c) The default kernel is Gaussian, , with profile on .
These choices buy a clean mean-shift derivation in §3 without giving up much practical generality. Anisotropic bandwidth matrices and non-radial kernels are addressed in §5.4 and §6.4 as scope-bounding remarks.
What “mode of a multivariate density” means
Definition 1 (Mode of a smooth density).
For a smooth density , a mode is a point at which the gradient vanishes and the Hessian is negative definite:
We write for the set of modes of and for the mode count.
The first condition says is a stationary point; the second rules out saddles, minima, and degenerate plateaus, leaving exactly the local-maximum points. The cardinality is the number of clusters mean-shift discovers — and it depends on in the monotone way §5 develops.
A subtle point. Mean-shift’s convergence theory (§4) will guarantee convergence to a stationary point of , not necessarily a mode. On data, saddle points are measure-zero attractors — almost every trajectory lands at a mode — but a pedantic statement of the algorithm’s guarantee is “stationary point,” not “mode.” We’ll handle this carefully when the theorem statements arrive in §4.
Mode-finding as the clustering target
Clustering algorithms divide cleanly into two paradigms. Partition-based methods — k-means, k-medoids, GMM-via-EM — pick a target number of clusters in advance and solve an optimization that assigns each point to a discrete label, minimizing some within-cluster loss. The cluster count is a hyperparameter, the cluster shape is implicit in the loss, and the algorithm carries no representation of the underlying density. Density-based methods — mean-shift, DBSCAN, level-set tree clustering — estimate the density first and read clusters off its structure. Cluster count is output, not input.
Mean-shift specifically defines clusters via the trajectory map , which sends each starting point to the limit of its mean-shift iteration. Two points belong to the same cluster if and only if their trajectories converge to the same mode: . The cluster count is , fixed by and the data via the KDE; no to pick.
This is fundamentally different from k-means’ formulation, and it’s why mean-shift is the right tool for the moons problem and k-means isn’t. The trade-off is real: mean-shift offloads the cluster-count choice into a bandwidth choice, and §5 will deal with how to pick well.
KDE surface and mode locations
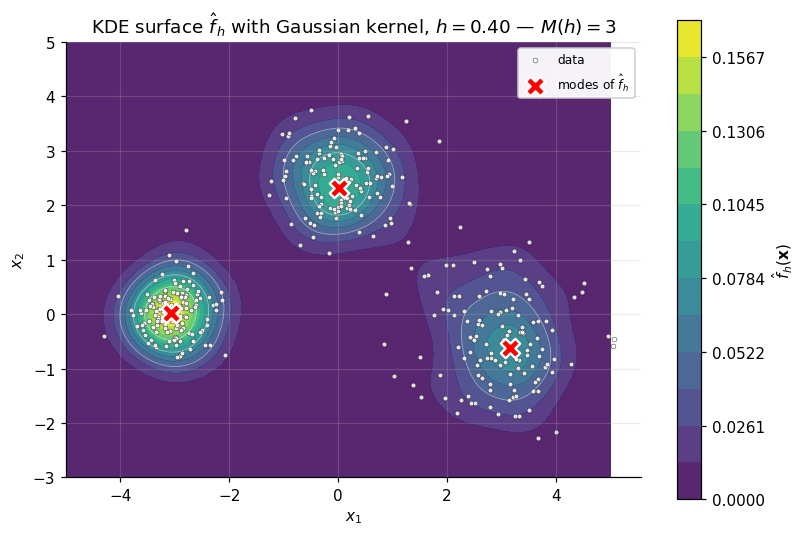
To make the geometric picture concrete, we plot on a fine 2D grid for make_blobs(n_samples=400, centers=[(-3,0),(0,2.5),(3,-0.5)], cluster_std=[0.4,0.6,0.8]) with Gaussian kernel and , and locate the modes by brute-force grid search. With this bandwidth and these well-separated blobs the mode count agrees with the ground-truth cluster count, .
The grid-search mode finder is the geometric stand-in for mean-shift. Grid search costs density evaluations where grows exponentially in , and it gives no per-point cluster assignment — it just locates the modes. Mean-shift will produce both the mode locations and the per-point assignments in one pass.
Mean-shift as gradient ascent on
The point of §3 is to derive the mean-shift update rule and show that it’s gradient ascent on in disguise. The derivation is worth doing in detail because three things follow from it: (a) the closed-form update doesn’t require computing explicitly at each iteration — the algorithmic payoff; (b) the update has a clean geometric reading as “move toward the sample-weighted mean,” motivating both the name and the §4 monotone-ascent proof; (c) the same algebraic decomposition reappears in §4, §7, and §9.
The profile-function decomposition and the gradient of
Start from the radial-kernel form: . Substituting into the KDE,
Write . Differentiating by the chain rule, , so
Because is non-increasing, . The algebra is cleaner if we work with — the derived profile (or shadow profile) of Comaniciu and Meer (2002). Two examples: for the Gaussian kernel, gives — the Gaussian’s shadow is itself, up to a constant. For the Epanechnikov kernel, gives — the shadow is the uniform kernel on the unit ball.
Substituting and flipping the displacement sign,
The gradient identity
Split the sum and factor:
The scalar is strictly positive whenever any sample lies inside the kernel’s support. Define the sample-weighted mean at , the load-bearing object of the section:
In words: is a weighted average of the samples, with each weighted by how close it is to on the kernel’s scale. Substituting back,
This is the central identity. The gradient of at is a strictly positive scalar multiple of the displacement from to the sample-weighted mean. The direction of steepest ascent on at is the direction from toward . We didn’t have to compute the gradient explicitly to find the ascent direction; the sample-weighted mean already encodes it.
Writing , the gradient identity reads .
The mean-shift update rule
Definition 2 (Mean-shift iteration).
Given data , a bandwidth , a profile function with derived profile , and a starting point , the mean-shift trajectory from is the sequence defined by
The mean-shift vector at is .
Proposition 1 (Mean-shift as gradient ascent).
Each mean-shift iteration is a gradient-ascent step on with adaptive step size :
Proof.
Rearrange the §3.2 gradient identity: , so .
∎For the Gaussian kernel, , the cancels in the weighted-mean ratio and the update reads
This has the structural form of kernel regression’s Nadaraya–Watson estimator with the positions playing the role of the responses being averaged.
For the flat (uniform) kernel — Epanechnikov mean-shift — the update collapses to the unweighted local mean within radius .
Why “mean shift” — interpretation
Ascent direction. The mean-shift vector points along .
Adaptive step size. The scalar is large where many samples are near (dense regions) and small where samples are sparse. The per-iteration displacement shrinks as the trajectory approaches a mode (where ) and grows where the data is sparse. No learning rate to tune.
Log-density form. Dividing both sides of the gradient identity by ,
so the mean-shift vector is proportional to — the form §4’s monotone-ascent argument naturally lives in.
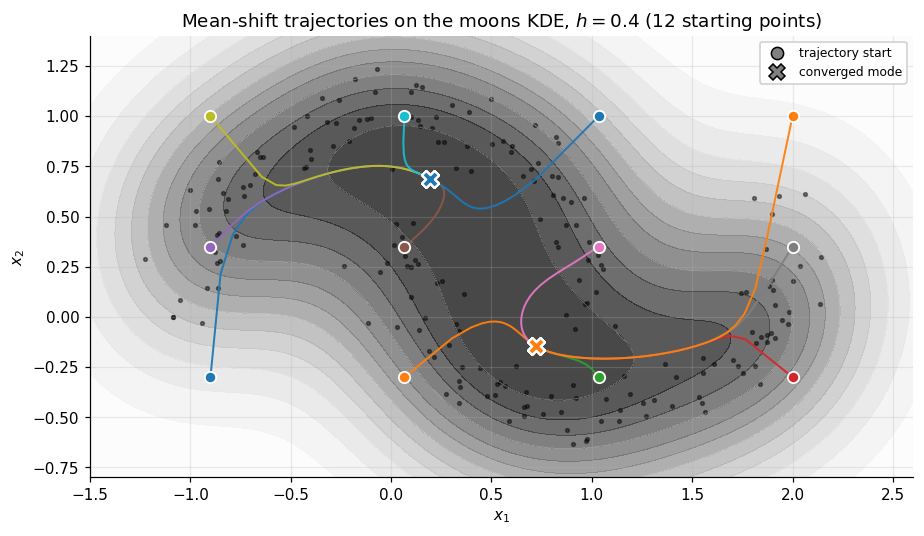
Mean-shift trajectories on the moons KDE
The from-scratch implementation is the central code-experiment. A vectorized Gaussian-kernel mean-shift function takes data , query points , and bandwidth , and returns the full trajectory history. The inner loop computes the matrix of pairwise squared distances via scipy.spatial.distance.cdist, exponentiates to obtain the Gaussian-kernel weights, and performs the weighted-mean update by matrix multiplication.
import numpy as np
from scipy.spatial.distance import cdist
def mean_shift_trajectories(X, Q, h, max_iter=100, tol=1e-6):
Xt = Q.copy()
history = [Xt.copy()]
for _ in range(max_iter):
D2 = cdist(Xt, X, 'sqeuclidean')
# log-domain stability: row-max subtract
log_w = -D2 / (2 * h * h)
log_w -= log_w.max(axis=1, keepdims=True)
W = np.exp(log_w)
Xt_new = (W @ X) / W.sum(axis=1, keepdims=True)
step = np.linalg.norm(Xt_new - Xt, axis=1).max()
Xt = Xt_new
history.append(Xt.copy())
if step < tol:
break
return np.stack(history)The figure plots 12 trajectories on the moons KDE from a sparse grid; the two converged modes are the upper-crescent ridge and the lower-crescent ridge of .
Convergence theory
§3 gave us the algorithm. What §3 did not give us is a guarantee that this algorithm does anything sensible. §4 supplies the missing guarantees. The first is qualitative: each iteration weakly increases (Comaniciu and Meer 2002, Theorem 1). The second is sharper: the trajectory converges to a stationary point of in the limit (Cheng 1995, Theorem 1).
We continue to assume the radial-kernel form with non-increasing, differentiable, and convex. The Gaussian profile is strictly convex; the Epanechnikov profile is linear inside its support and weakly convex.
The monotone-density-ascent theorem
Theorem 1 (Monotone Density Ascent (Comaniciu–Meer 2002, Thm 1)).
Let be a radial kernel with non-increasing, differentiable, convex profile , and let be the corresponding KDE on data . For any starting point at which , the mean-shift iteration satisfies
with equality if and only if .
The bound is sharper than just ” is non-decreasing”: the density gain is at least quadratic in the step size.
Proof.
Move 1 — convexity inequality. Because is convex and differentiable, the supporting-line inequality holds for all . Set and for each , and substitute :
Move 2 — chain across samples. Multiply by and sum. The LHS telescopes into :
Move 3 — expand the difference of squared distances. Write and expand . Sum over and pull out the -independent terms, with :
The mean-shift definition gives , so the sum becomes .
Move 4 — recognize the squared step size. Expand the bracket:
So . Plugging back into the Move 2 inequality, the two minus signs cancel:
This is the claimed inequality.
∎Stationarity characterization
A fixed point of the mean-shift map is a point with .
Proposition 2 (Stationarity characterization).
At any with ,
Proof.
The gradient identity from §3.2 reads , with .
∎The fixed-point set of equals the set of stationary points of , which includes modes (local maxima), saddles, and minima. The monotone-ascent property rules out convergence to a strict local minimum. Saddles are measure-zero attractors — almost every starting point converges to a mode.
Convergence to a stationary point
Theorem 2 (Trajectory convergence (Cheng 1995, Thm 1)).
Under the Theorem 1 assumptions, and assuming additionally that has only isolated stationary points (a generic-position assumption that holds almost surely for data with continuous distribution), the mean-shift trajectory from any converges to a stationary point of :
Proof.
Step 1 — the trajectory is bounded. For the Gaussian kernel, each iterate is a convex combination of the data points (the weights are non-negative and sum to one). So for every , and the trajectory lies in the bounded convex hull of the data.
Step 2 — the density values converge. By Theorem 1, is monotone non-decreasing; bounded above by . A monotone bounded sequence converges, so .
Step 3 — step sizes are square-summable, hence vanishing. Sum the Theorem 1 bound over :
Taking , the LHS is bounded by , so . On the bounded set, is bounded below by some (continuity and positivity of ). Dividing,
Step 4 — accumulation points are stationary; isolation forces convergence. Let be an accumulation point (Bolzano–Weierstrass) and a convergent subsequence. By continuity of and step-vanishing,
Every accumulation point is a fixed point of — a stationary point of . The accumulation-point set is discrete (isolated-stationary-points assumption). Choose smaller than half the minimum pairwise distance in . Eventually for all large ; the trajectory cannot jump between different -balls, forcing convergence to some .
∎Step-size bounds and the local-curvature scale
Near a mode, the rate is linear in the favorable case. Linearizing around a mode , where . The §3.3 Proposition gives
The local contraction factor is the operator norm of . Eigenvalues lie in — giving linear contraction — when . For Gaussian-kernel mean-shift this is automatic near typical modes.
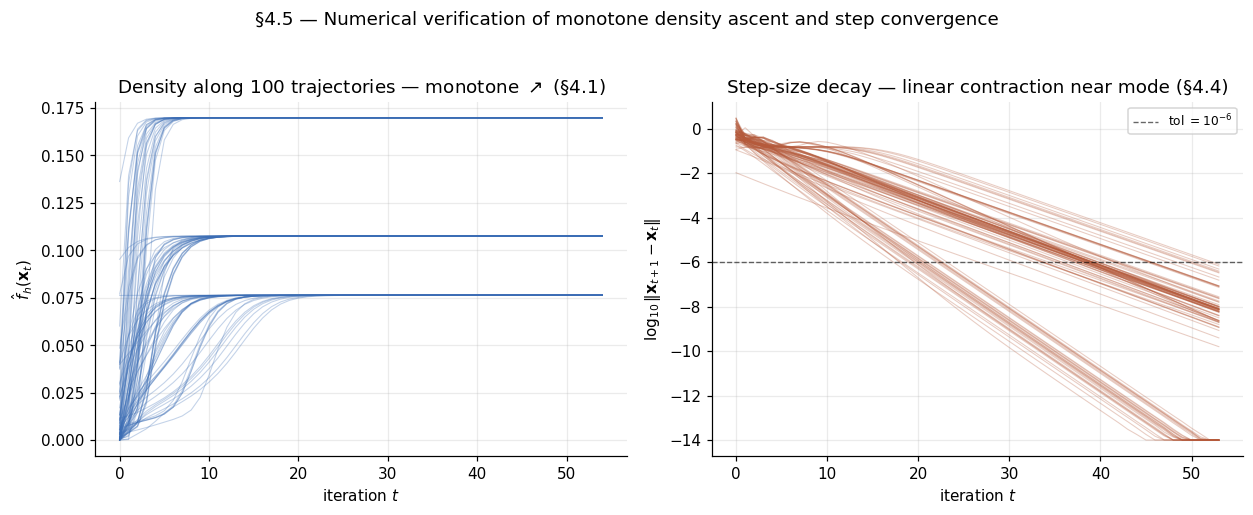
Numerical verification
We verify the two empirical predictions: (a) is monotone non-decreasing; (b) . We run mean-shift from random starting points in on the 3-blob KDE at (the plateau bandwidth in our reproduced data). For each trajectory we record and at every iteration. The left panel below shows monotone-non-decreasing density curves with zero violations; the right panel shows geometrically-decaying step sizes (straight lines in log scale), consistent with the linear-contraction sketch.
Bandwidth, resolution, and the mode tree
§§3–4 took as given. §5 asks how the answer depends on . The center-of-gravity result is the bandwidth-mode-count duality — as increases, is non-increasing, with modes merging but never splitting. The duality has a clean proof in from Silverman (1981) via the heat-equation reformulation; the multivariate version, due to Chacón (2015) and Chacón and Duong (2018), follows the same convolution-semigroup picture and holds in a generic-position sense.
Bandwidth-as-resolution
The KDE is a convolution: , where is the empirical measure and is the Gaussian density with isotropic scalar bandwidth . The bandwidth is the scale at which we look at the data.
The bandwidth’s role in density estimation: small has low bias and high variance, large has high bias and low variance, with AMISE-optimal rate . The clustering picture is the same trade-off through a different loss — we care about mode structure. Small over-clusters (); large under-clusters (). The “right” is the one whose mode structure matches the cluster structure.
The Chacón–Duong bandwidth-mode-count duality
Theorem 3 (Bandwidth-mode-count duality).
Let be the Gaussian-kernel KDE with isotropic scalar bandwidth on data with distinct points, and let be its mode count. For the function is non-increasing on (Silverman 1981, Theorem 2). For , the same conclusion holds generically — for almost every data configuration and almost every , modes can merge as grows but cannot split (Chacón 2015; Chacón and Duong 2018, Ch. 7).
Proof.
Step 1 — convolution semigroup. Gaussian densities form a semigroup under convolution: if then (probabilistic proof: independent Gaussians sum to ). For any and ,
Step 2 — heat-equation reformulation. Define . Then satisfies the heat equation with . Setting identifies .
Step 3 — critical-point monotonicity in . Apply the heat operator to , which also solves the heat equation. Sturm’s lacunary theorem (Sturm 1836; modern proofs in Matano 1982 and Angenent 1988) says: if solves the 1D heat equation and has finitely many zeros, then has finitely many zeros for all and the count is non-increasing in . The zeros of are the stationary points of , so the stationary-point count of is non-increasing in .
Modes are strict local maxima — a subset of stationary points. In 1D with at , stationary points alternate max–min–max–… starting and ending with a max. Stationary points disappear only in min–max pairs at degenerate critical points, each annihilation removing one min and one max. The mode count is exactly half the stationary-point count (plus a half) and is non-increasing.
Step 4 — multivariate generalization. In , Chacón (2015) and Chacón and Duong (2018, Ch. 7) carry out the Morse-theoretic analysis: generically (Sard’s theorem), all critical points of are non-degenerate, and as grows, critical points disappear only in max–saddle or min–saddle annihilations. Pathological data configurations exist in where the strong statement fails on a measure-zero set of bandwidths; they don’t occur for data sampled from a continuous distribution.
∎Remark.
Known counterexamples in are tuned configurations where two well-separated modes briefly coalesce at one bandwidth, then re-separate as a third mode pinches off at a slightly larger bandwidth. Measure-zero in data-space; Carreira-Perpiñán (2015, §3.2) discusses the literature. The numerical experiment in §5.5 will show small blips in on the moons that are a finite-precision shadow of this caveat — they should not be smoothed away.
The mode tree
The bandwidth-indexed family traces a mode tree — a dendrogram whose leaves are fine-scale modes at small and whose internal nodes are merge events, with root at large where . A flat region of the tree (long horizontal segment with no merges) corresponds to a stable bandwidth range over which the cluster assignment doesn’t change. The cluster count at this flat region is the natural cluster count — the scree-criterion principle of §5.4.
Mode-tree algorithms: Minnotte and Scott (1993) introduced the 1D version; Klemelä (2009) carries the multivariate version.
Selectors in practice
Four selectors are in use.
Silverman’s rule of thumb.
with a marginal-spread estimate. Cheap, often within a factor of two of optimal, easy to nudge upward to find the plateau.
Plug-in selectors (Sheather–Jones 1991; Wand and Jones 1994 for ) estimate AMISE-optimal from the data. Excellent for density estimation; tend to under-smooth for clustering.
LSCV (Rudemo 1982; Bowman 1984; Scott and Terrell 1987): minimize . Consistent (Stone 1984), high-variance.
Scree criterion on the mode tree (Carreira-Perpiñán 2015, §4.1). Compute on a log-spaced grid, identify the longest plateau; the cluster count at the plateau is the natural cluster count.
For clustering, the workflow: start with Silverman’s , sweep around it, find the plateau, report the cluster assignment at the plateau midpoint.
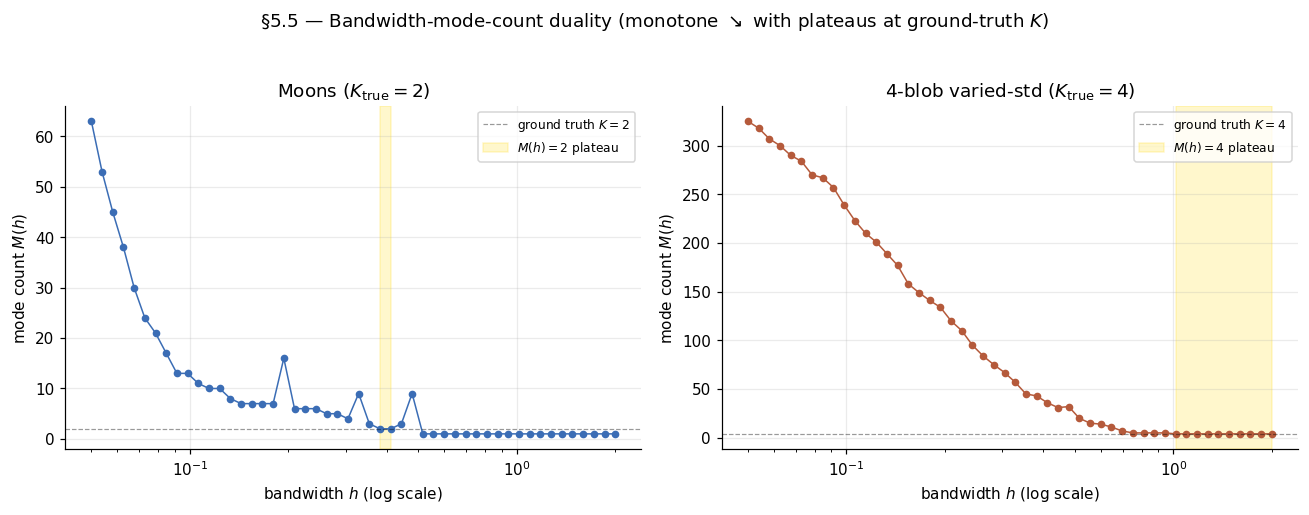
Numerical experiment: on the moons and 4-blob datasets
We sweep across 50 log-spaced values in on the moons (, ground-truth ) and a varied-std 4-blob (, ground-truth ). At each , run from-scratch mean-shift starting at every data point, count distinct converged modes. The 4-blob curve is cleanly monotone with a wide plateau; the moons curve descends monotonically with a narrow plateau followed by small blips back up before collapsing to — the multivariate-Silverman caveat from the Theorem 3 remark made empirically visible. The blips are not failures of the duality; they make the moons a cautionary example for naive scree-criterion bandwidth selection.

Kernel-function choice
The §3.2 derivation went through for any radial kernel with non-increasing differentiable convex profile, so the mean-shift algorithm and its convergence theory are unchanged across kernels. What changes is the weighting function in the sample-weighted mean, and as a result the local curvature of near each mode. The cluster assignment in the plateau regime is remarkably robust to those local changes.
The standard zoo
| Kernel | Profile | Shadow | Support |
|---|---|---|---|
| Gaussian | |||
| Epanechnikov | |||
| Biweight (quartic) | |||
| Triweight | |||
| Uniform (box) |
The uniform kernel’s profile is discontinuous; “uniform-kernel mean-shift” is shorthand for Epanechnikov-shadow mean-shift (Cheng 1995, §3) — both use .
By Hodges and Lehmann’s (1956) efficiency comparison, kernel efficiencies fall in a tight band — Gaussian 95%, biweight 99%, triweight 99%, uniform 93% — smaller than a 5% bandwidth perturbation.
Flat-kernel mean-shift
Epanechnikov shadow gives
Replace by the arithmetic mean of data points within radius . Most computationally tractable variant; the version most users carry in their head. Two practical wrinkles: empty neighborhood (stop the trajectory; locally expand ; or seed inside the convex hull) and boundary non-smoothness of (the Epanechnikov gives jump discontinuities in at distance exactly from each sample — measure-zero, harmless for mean-shift).
Why kernel choice rarely moves the cluster assignment
The basin-of-attraction structure is determined by the topology of . At bandwidth in the §5 plateau, is locally smoothed enough that the global mode structure is robust to kernel-shape changes. The cluster assignment is invariant up to label permutation across kernel choice.
Two reasons. Smoothing-stable mode count: §5.2’s duality holds for any convex-profile radial kernel; the plateau corresponds to a bandwidth range with stable mode count regardless of small perturbations including kernel shape. Basin-boundary stability: basin boundaries are determined by saddle-ridge structure, stable under the same perturbations. Carreira-Perpiñán (2015, §3.3): “The choice of kernel function has very little effect on the clusters produced by mean-shift, given a sensible bandwidth choice.”
In sharp contrast to KDE-as-density-estimator, where kernel sensitivity at the AMISE-optimal level is real (capped at ~5% by Hodges–Lehmann efficiency). For cluster assignments, sensitivity is essentially zero in the plateau regime.
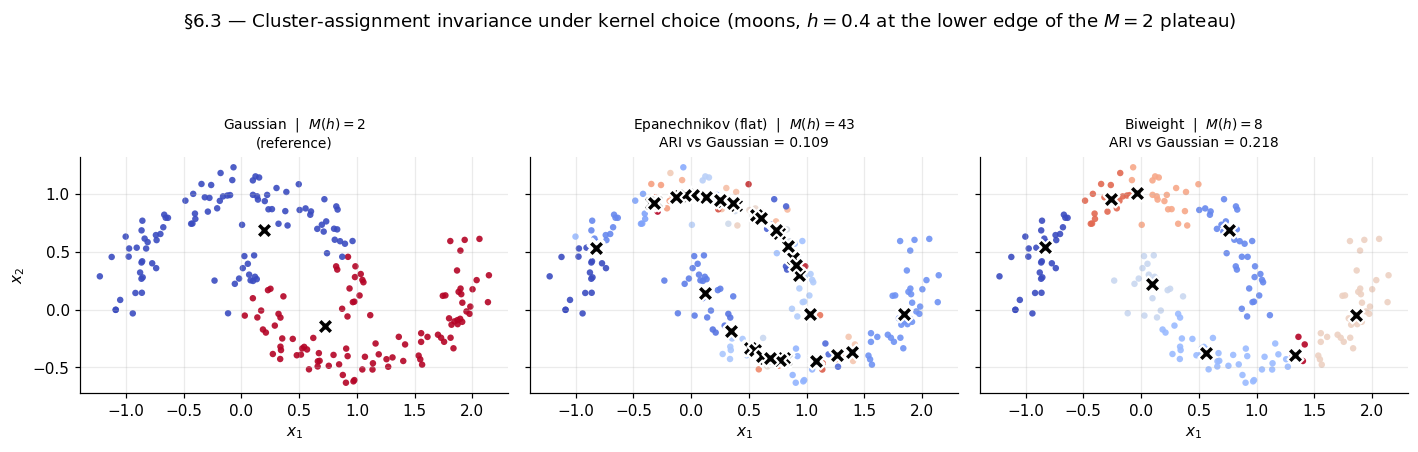
When kernel choice does matter
Heavy-tailed data, far from the bulk. Gaussian’s exponentially decaying tails give distant points non-zero weight; compact-support kernels give zero. Can shift mode locations near data extremes by amounts crossing cluster boundaries.
Computational cost. Gaussian needs all data points per query — per iteration. Compact-support kernels accelerate to via kd-tree / ball-tree (§8.3). For large , order-of-magnitude difference.
Smoothness of . Gaussian ; Epanechnikov ; biweight ; triweight . For mean-shift itself it doesn’t matter; for downstream applications using beyond cluster assignment (Hessian estimation, level-set trees), pick a smooth profile.
Recommendation: Gaussian by default; switch to Epanechnikov if computational cost forces it.
From trajectories to clusters
§3.5 showed individual trajectories converging. §5.5 used trajectory endpoints as cluster proxies. §7 makes both moves formal.
The trajectory map and basin-of-attraction clustering
Definition 3 (Trajectory map and basin).
The trajectory map is
The basin of attraction of mode is . The basins partition (almost everywhere); the partition is the basin-of-attraction clustering induced by .
Two data points are in the same cluster iff their trajectories converge to the same mode. The map defines a spatial clustering — every point in has a cluster label, not just the data points. Any new is classified by running a fresh trajectory.
Basin boundaries are the -dimensional saddle ridges of .
Mode merging with tolerance
In finite precision, two trajectories that should converge to the same mode land at endpoints separated by a small distance. The mode-extraction step needs a merging tolerance .
Greedy-union rule (used throughout): walk through endpoints, attach each to an existing mode if within , else create a new mode. Heuristics for : (safety margin) or (well below inter-mode separation). The from-scratch implementation uses .
The mode-merging tolerance is a numerical parameter, not a clustering hyperparameter; cluster assignment is invariant to over a wide range.
Blurring mean-shift
Cheng (1995, §4) introduces a variant where data points themselves move at each iteration:
The KDE is rebuilt at each iteration. Converges much faster — data collapses to modes in geometric time — but Cheng (1995, Theorem 2) shows long-time blurring collapses to a single point regardless of . The practical algorithm runs only a small number of iterations.
Standard (non-blurring) mean-shift is the default: respects the mode-tree structure and the §4 convergence theory.
Initialization
Sample-as-queries — initialize at the data points. Standard for clustering data points.
Grid-as-queries — initialize on a regular grid covering the data extent. Produces the basin-of-attraction map for (not just the data).
Adaptive initialization — only at “promising” locations (high- regions, coarse-pass modes). For in 2D, savings are modest; for very large in higher , substantial.
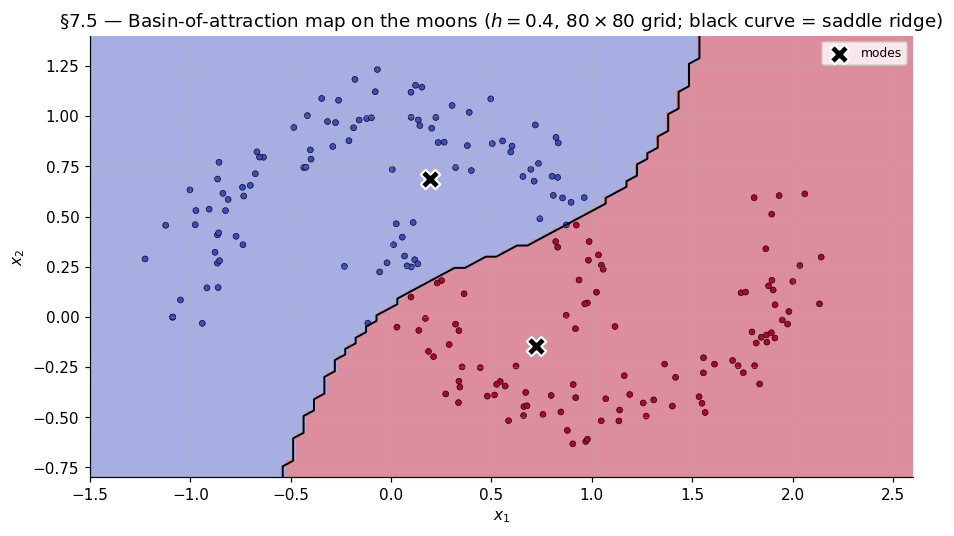
The basin-of-attraction map on the moons
80 × 80 = 6400 trajectories from a grid over the moons range, Gaussian kernel at , deduped at tolerance . Endpoints aligned to data-trajectory modes for consistent label coloring between basin map and scatter. The basin boundary appears as a smooth curve threading between the two crescents, far from either’s bulk.
Practical mean-shift
§§3–7 covered the algorithm and theory. §8 is about what happens when you actually want to run mean-shift on real data.
Design choices in the from-scratch implementation
The mean_shift_trajectories function from §3.5 makes four design choices.
Vectorized pairwise distance. scipy.spatial.distance.cdist for the squared-distance matrix per iteration — in compiled C. Memory bytes (float64), fine for . At larger scale, batch queries in chunks of .
Log-domain stability. Per-row max-subtract before exponentiating the Gaussian-kernel weights — the subtracted constant cancels in the weighted-mean ratio. Same trick as softmax.
Vectorized convergence. Stop when the maximum per-query step falls below tol. Per-query stopping is more efficient but harder to vectorize.
Full trajectory history returned. array — more memory than necessary if you only need final positions, but needed for diagnostic plots and basin visualizations. At our scale (, ) it’s MB.
A production implementation would tighten all four. The notebook implementation is optimized for pedagogical clarity, not throughput.
sklearn.cluster.MeanShift pitfalls
Three quirks worth knowing.
The estimate_bandwidth default. MeanShift() with bandwidth=None calls estimate_bandwidth(X) internally, which is in time and memory. For : distance computations, ~800 MB intermediate memory. For : computations, 80 GB. Always pass an explicit bandwidth=h chosen via §5.4’s selectors.
The internal kernel is flat, not Gaussian. Uses Epanechnikov-shadow update (unweighted mean inside bandwidth ball). Not user-selectable. §6.3 already showed kernel-invariance in the plateau regime; this is rarely a correctness issue but is the source of rare ARI < 1.0 disagreement on boundary points.
Orphan points get label -1. Trajectories not reaching a mode within max_iter (default 300) iterations are labeled -1. Rare at reasonable bandwidth, common at adversarial small .
bin_seeding=True initializes only at coarse-grid bin centers — substantial speedup for large data.
Scaling: kd-tree and ball-tree neighbor queries
For compact-support kernels, only contributes to . Brute force is per query; kd-tree (Bentley 1975) or ball-tree (Omohundro 1989) is where is the average neighborhood size. Build time .
At in with Epanechnikov: brute force distance computations per iteration; kd-tree neighbor lookups. Three orders of magnitude per iteration.
For Gaussian, truncate: ignore for (captures 99.7% of Gaussian mass). Truncated Gaussian admits the same kd-tree acceleration.
scipy.spatial.cKDTree and sklearn.neighbors.BallTree provide tree implementations. Kd-tree for ; ball-tree for ; benchmark in between.
The sample-and-cluster pattern
For , the sample-and-cluster pattern (Carreira-Perpiñán 2015, §6.2) trades small approximation error for order-of-magnitude speedup:
- Sample seed points.
- Run mean-shift trajectories from seeds; dedupe to mode set.
- Assign remaining data via nearest-mode kd-tree query.
Total cost . With , dominant term .
Approximation error from sub-sampling: low-density modes may be missed. Harmless for typical clustering; mitigated by stratified sampling for anomaly localization.
Sanity check: from-scratch vs sklearn
Run both implementations on the moons, 3-blob, and 4-blob at plateau bandwidths, with the from-scratch in flat-kernel mode for like-for-like comparison against sklearn’s internal Epanechnikov shadow. Expect mode counts to agree dataset-by-dataset and ARIs in — small disagreement on boundary points is normal.
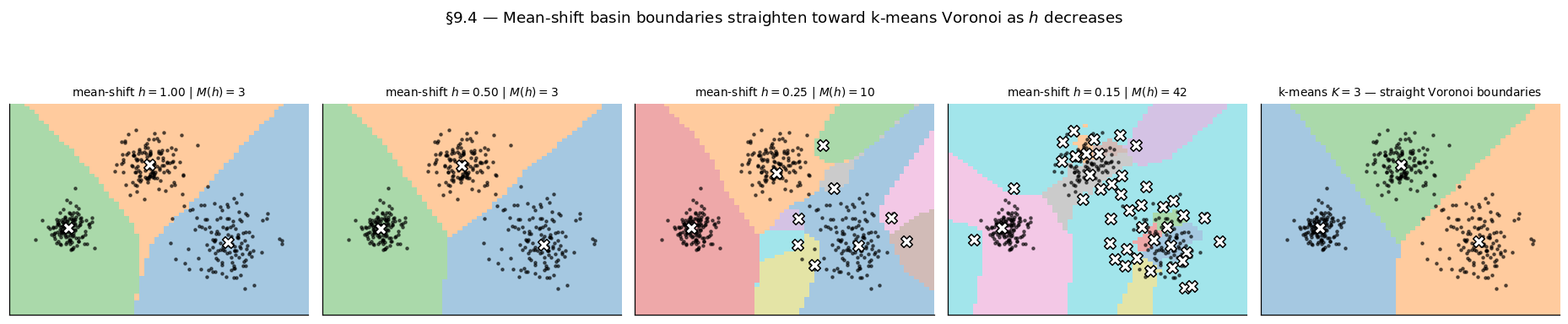
k-means as the Voronoi limit
K-means and mean-shift cluster the same data with different parameters and produce different partitions on anything non-Gaussian. §9 makes the relationship precise. Gaussian-kernel mean-shift in the limit collapses onto Lloyd’s hard nearest-mean assignment.
Lloyd’s algorithm and the Voronoi-partition fixed point
Lloyd’s algorithm (Lloyd 1982; MacQueen 1967 historical antecedent) picks centroids (typically via k-means++ seeding, Arthur and Vassilvitskii 2007), then alternates:
- Assignment. .
- Update. .
The fixed point locally minimizes the WCSS . Local convergence; k-means++ providing expected-WCSS approximation.
At a fixed point, belongs to cluster iff — the Voronoi cell of . Each cell is a convex polytope; cell boundaries are perpendicular bisectors of centroid pairs.
What each method assumes
K-means. Cluster count fixed in advance; cluster shape implicitly convex (Voronoi polytope); no density representation. WCSS objective is, up to constants, the NLL of an isotropic Gaussian mixture with equal variances and equal mixing weights (Bishop 2006, §9.1). Works exactly on well-separated isotropic Gaussians. Fails confidently on non-convex / non-isotropic / unequal-spread clusters.
Mean-shift. Cluster count emerges from ; cluster shape is the basin of attraction of ; density-based. Handles any data with well-defined density modes. Trades hyperparameter for hyperparameter.
K-means optimizes WCSS; mean-shift optimizes . The silhouette/ARI disagreement on the moons (§1.3) reflects this — silhouette rewards convex compactness (the k-means objective), ARI rewards getting the right partition.
The collapse theorem
Theorem 4 (Gaussian-kernel mean-shift collapse to nearest sample).
Let be the Gaussian-kernel KDE on data with distinct points. Fix with a unique nearest sample — i.e., for all , where . Then
where and .
The convergence rate is exponentially fast in .
Proof.
Factor out from numerator and denominator of with . With , for ,
with . Compute:
Take the Euclidean norm; apply the triangle inequality with and the bound (denominator ):
∎Corollary 1 (Basin = Voronoi cell at $h = 0$).
For any with a unique nearest sample , , and the basin partition converges to the Voronoi diagram of the data, .
Proof.
Theorem 4 shows in one iteration. The next iteration starts arbitrarily close to , at which the nearest sample is itself (distance 0), so the trajectory stays put. ; the preimage converges to the Voronoi cell.
∎Remark.
The corollary makes the "" equivalence precise: mean-shift in the limit produces the Voronoi diagram of the data — the partition k-means with frozen-data centroids would produce. For k-means, equivalence is approximate and conditional: in the plateau on isotropic-Gaussian-mixture data, both algorithms recover the same partition. The equivalence breaks on non-isotropic or non-Gaussian data — on the moons no value matches k-means at any .
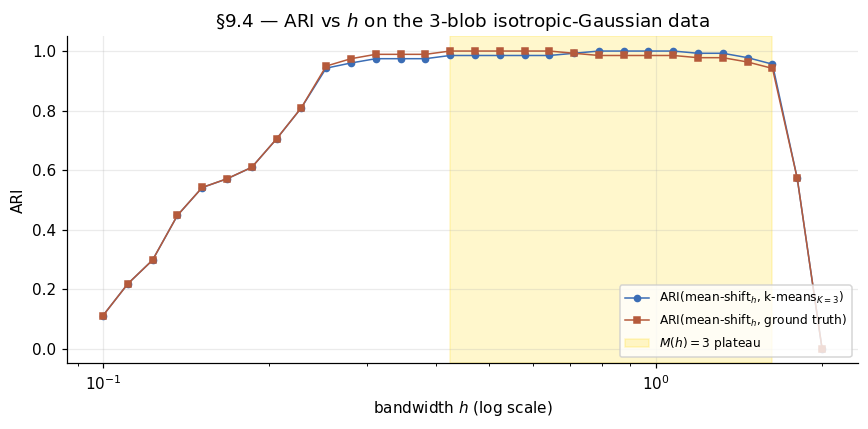
Numerical experiment: ARI(mean-shift, k-means) on the 3-blob
Run k-means with as reference. Sweep across the plateau and below; at each compute mean-shift labels and ARIs against k-means and against ground truth. ARI(mean-shift, k-means) ≈ 1.0 across the plateau; ARI drops below the plateau when . The basin-mosaic at decreasing shows boundaries first straightening (within the plateau’s lower edge) then fragmenting (below the plateau).
GMM-via-EM and soft assignment
§9 contrasted against k-means — the simplest hard-partition baseline. §10 contrasts against the probabilistic hard-partition baseline: Gaussian mixture models fit by expectation-maximization (Dempster, Laird, and Rubin 1977).
The Gaussian mixture model and its likelihood
with summing to 1, component means , covariances positive definite. Latent-variable form: , .
Log-likelihood:
Log-sum-over-components has no closed-form maximum.
EM for GMMs: responsibilities as soft assignments
E-step. Compute posterior responsibilities:
is the soft assignment; .
M-step. With :
Weighted single-Gaussian MLEs. See Bishop (2006, §9.2.2) for the full derivation.
Theorem 5 (EM monotone-likelihood ascent (Dempster–Laird–Rubin 1977, Thm 1)).
At each EM iteration the log-likelihood is monotone non-decreasing; the algorithm converges to a local maximum of (under regularity conditions on the latent-variable model).
The structural connection to mean-shift: GMM-EM’s M-step is the §3.3 mean-shift update form with responsibilities as kernel weights. Differences: parametric vs fixed-bandwidth weighting; centroids vs query points; soft per-component vs hard per-mode. The Gaussian-mean-shift → k-means limit (§9.3) and the GMM-EM → k-means limit both converge on k-means.
Identifiability, label-switching, and what “the” cluster labels mean
Permuting component labels leaves the density unchanged. The likelihood has equivalent global maxima differing only in component naming.
Consequences: EM with random initialization converges to permuted optima; Bayesian inference suffers label-switching (Stephens 2000); cluster-quality metrics must be permutation-invariant (ARI does it, raw accuracy doesn’t).
The label-switching issue affects names, not partition. Two GMM fits agreeing on which samples cluster together but disagreeing on naming are operationally the same fit.
A separate identifiability concern: GMM likelihood is unbounded above. Setting and sends . sklearn.mixture.GaussianMixture regularizes via reg_covar (default ).
The M-open critique
GMM produces correct cluster assignments when data is genuinely a Gaussian mixture. When it isn’t, assignments are systematically biased: GMM fits ellipsoidal components to non-ellipsoidal cluster structure.
Bernardo and Smith (1994) framework: M-closed = true model is in our class; M-complete = known true model is intractable; M-open = true model is outside our class.
For clustering, GMM is M-open whenever cluster shapes aren’t ellipsoidal — most real data. Moons aren’t Gaussian. Concentric rings aren’t. Image segmentation, text embedding, biological data — none are Gaussian in any literal sense.
The critique cuts in two directions. Against GMM: when true clusters are non-Gaussian, biased assignments. Against mean-shift: non-parametric in but commits to “cluster = basin of attraction of kernel-smoothed empirical density.” Less restrictive than ellipsoidal Gaussian, but not assumption-free.
Practical takeaway. Approximately-Gaussian clusters with arbitrary covariance shape: GMM-EM. Non-Gaussian or unknown-shape clusters: mean-shift. On real data, “run both and compare.”
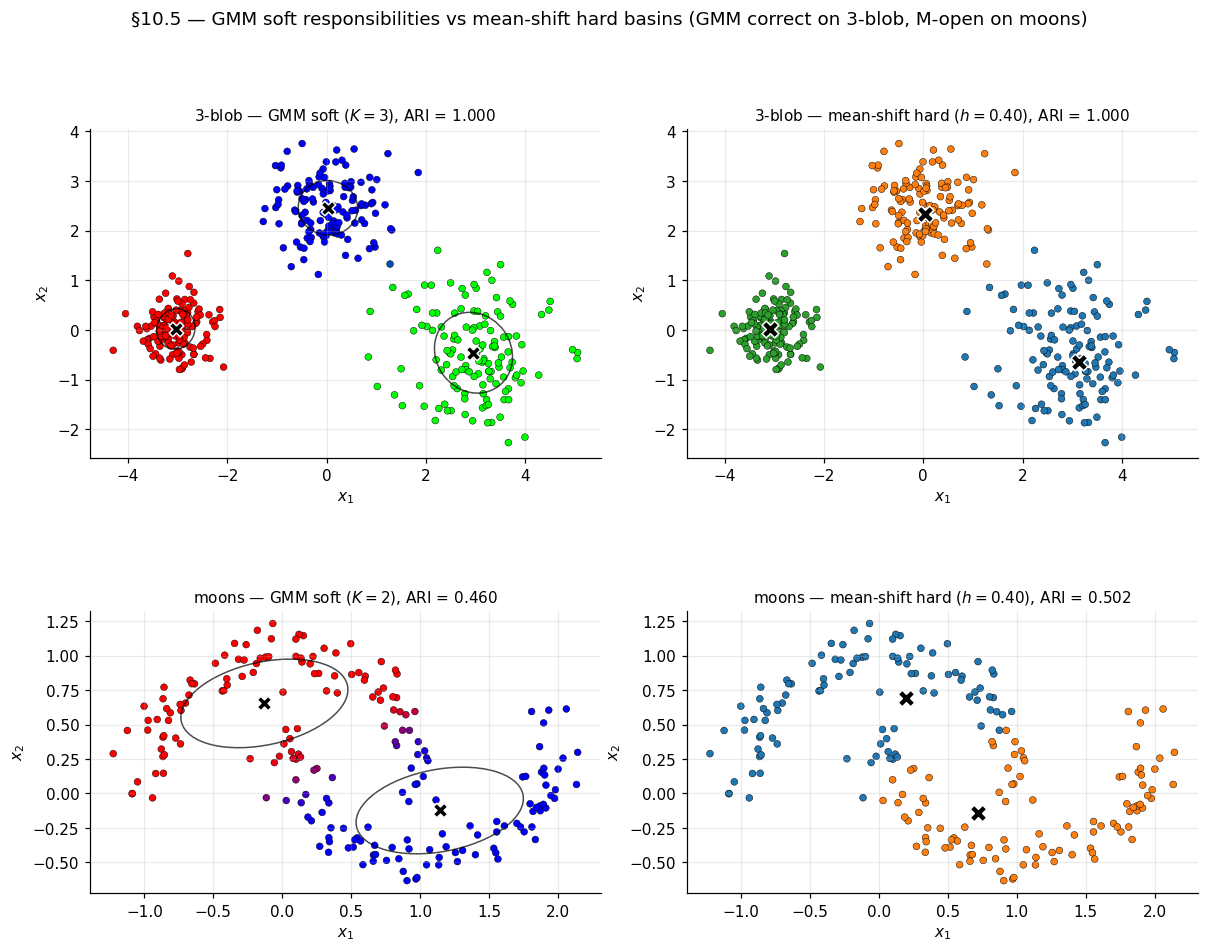
GMM responsibilities vs mean-shift basins
3-blob (where GMM is correct): GMM-EM recovers components; responsibilities sharp inside blobs, soft at boundaries; mean-shift hard MAP agrees up to label permutation; ARI on both.
Moons (both partially M-open): GMM-EM with fits two ellipsoids that span across the crescent gap, ARI . Mean-shift at the plateau bandwidth finds the right cluster count and shape but mis-classifies boundary points, ARI . Both algorithms beat k-means’ ARI from §1.3 but neither recovers the moons perfectly at noise = 0.1 — the crescents are intrinsically hard at this noise level.
Pointers: spectral and density-based clustering
§§9–10 covered partition-based contrasts. §11 covers two methods that don’t fit cleanly into either partition-based or mode-based — spectral clustering and DBSCAN. Light pointer; proper coverage of spectral clustering is in graph-laplacians and random-walks.
Affinity graphs and the Laplacian
Spectral clustering builds an affinity graph: vertices are samples, edge weights encode pairwise similarity. Standard constructions: Gaussian similarity ; -NN graph; -graph. -NN is most common: sparse, robust to , density-adaptive.
Graph Laplacian: , . Normalized variants: (Ng–Jordan–Weiss); (Shi–Malik). Eigenvectors corresponding to smallest eigenvalues encode cluster structure: for an ideal -component disconnected graph the bottom eigenvectors are component indicators; for almost-disconnected graphs they approximately encode the clusters (Mohar 1991; von Luxburg 2007).
Shi–Malik and Ng–Jordan–Weiss
Shi and Malik (2000). Bottom eigenvectors of ; for , partition by sign of second-smallest eigenvector; for , recursive bipartitioning or k-means on bottom eigenvectors. Motivated by the normalized cut objective.
Ng, Jordan, and Weiss (2002). Bottom eigenvectors of as . Row-normalize: . Run k-means on rows of . Geometric interpretation: row-normalized embedding lies on the unit sphere in , where cluster structure is spherical.
For the variational characterization, Cheeger inequality, perturbation analysis, random-walk dual — consult graph-laplacians and random-walks. von Luxburg (2007) is the standard intro.
DBSCAN
Density-Based Spatial Clustering of Applications with Noise (Ester, Kriegel, Sander, and Xu 1996). Two hyperparameters: (neighborhood radius) and . Point types: core (), border (in a core’s neighborhood, not itself core), noise (neither). Clusters are connected components of density-reachability between core points; noise gets label .
DBSCAN vs mean-shift: both density-based, but DBSCAN uses hard threshold (, MinPts) while mean-shift uses KDE smoothing. DBSCAN handles noise via ; mean-shift assigns every point. DBSCAN has 2 hyperparameters, mean-shift 1. HDBSCAN (Campello, Moulavi, Sander 2013) replaces fixed with a hierarchy.
For uniform-density clusters, DBSCAN excels. For varied-density data, it struggles — single can’t resolve both tight and diffuse clusters; mean-shift’s bandwidth adapts via KDE smoothing.
Numerical demonstration on make_circles
make_circles(n_samples=200, factor=0.5, noise=0.05): outer ring radius 1.0, inner ring radius 0.5. KDE density is concentrated on ring-shaped ridges, not point modes — mean-shift trajectories converge to points along the ridges, basin partition fragments. Spectral and DBSCAN both succeed by exploiting connected-component structure on the affinity graph.
Four panels: mean-shift fails (ARI ); spectral with -NN affinity succeeds (ARI ); DBSCAN MinPts succeeds (ARI ); spectral embedding showing linear separability of the two rings.
Light pointer per §11. Full spectral-clustering theory lives in graph-laplacians and random-walks in the Graph Theory track.
Connections, limits, and forward pointers
Within-formalML siblings
Kernel regression (Supervised Learning, intermediate). Covariate-conditional KDE counterpart. The NW estimator is structurally identical to Gaussian-kernel mean-shift update; kernel regression averages responses, mean-shift averages positions; same machinery.
Graph Laplacians (Graph Theory, advanced). Proper home for spectral clustering — eigenvalue spectrum, Cheeger inequality, perturbation analysis. §11 gestures; graph-laplacians develops.
Random walks (Graph Theory, intermediate). Dual Laplacian view: generates a random walk; mixing times encoded by spectral eigenvalues.
Normalizing flows (Unsupervised, advanced). Continuous-density estimation via invertible neural transformations. Mean-shift’s KDE is the non-parametric precursor to flow-based estimators.
Forward pointers
Density-ratio estimation (coming soon). KLIEP, LSIF, uLSIF — density-ratio estimators that plug KDE substrates into . The unsupervised.ts exports meanShift and modeFinder are direct dependencies. Closes the T3 Unsupervised track.
Honest limits
Curse of dimensionality on . AMISE-optimal grows with , but the bandwidth-ball volume grows much faster — . In with , the typical neighborhood at contains essentially zero samples. Mean-shift becomes infeasible above without dimensionality reduction (PCA, autoencoder, t-SNE / UMAP) as preprocessing.
Mode-vs-cluster distinction. Mean-shift converges to stationary points; the modal-clustering hypothesis (Hartigan 1975) asserts cluster = basin of attraction of a density mode. Three failure modes: well-separated clusters that don’t produce distinct density modes (concentric rings); spurious modes from noise; genuinely ambiguous cluster structure where no algorithm agrees.
No cluster-count guarantees under noise. Under additive noise, KDE develops spurious local maxima counting toward . The bandwidth-mode-count duality is preserved (still monotone) but the plateau may shift or disappear. Carreira-Perpiñán (2015, §3.3) discusses noise-robust mode estimation; practical fix is to combine moderate bandwidth with a low-density-prune step dropping modes with insufficient basin mass.
Take-home. Mean-shift is the right tool for cluster discovery via density modes on moderate-dimensional, moderately-noised data with moderately-distinct cluster shapes. Outside that regime, k-means, GMM, spectral, DBSCAN are alternatives — on hard data, ensembles often do better than any single one.
Connections
- The Gaussian-kernel mean-shift update (§3.3) and the Nadaraya–Watson regression estimator are structurally identical — both compute a kernel-weighted average over the data. Kernel regression averages responses given covariates; mean-shift averages positions given the current iterate. The same bandwidth-selection machinery applies to both. kernel-regression
- The §11 spectral-clustering pointer gestures at the eigenvalue structure of the normalized Laplacian. The proper development — Cheeger inequality, perturbation analysis, Shi–Malik / Ng–Jordan–Weiss derivations — lives in graph-laplacians on the Graph Theory track. graph-laplacians
- The §11 spectral pointer also covers the random-walk Laplacian $L_{\mathrm{rw}}$. The dynamics view (mixing times, spectral gap, hitting times) is the substrate random-walks develops; this topic just names the connection and redirects. random-walks
- Mean-shift's KDE is the non-parametric precursor to flow-based density estimation. The §12.3 forward pointer notes that the unsupervised.ts shared module introduced here for the mean-shift estimators is the same module that normalizing-flows can plug into for KDE baselines. normalizing-flows
- Each mean-shift iteration (§3.3 Proposition) is a gradient-ascent step on $\hat f_h$ with adaptive step size $\alpha(\mathbf{x}_t)^{-1}$. The convergence theory (§4) is the gradient-ascent convergence story specialized to a smooth bounded objective with isolated stationary points. gradient-descent
References & Further Reading
- paper The Estimation of the Gradient of a Density Function, with Applications in Pattern Recognition — Fukunaga & Hostetler (1975) The original mean-shift paper, framing the algorithm as gradient estimation on the KDE (IEEE TIT).
- paper Mean Shift, Mode Seeking, and Clustering — Cheng (1995) Foundational convergence theory for mean-shift; Theorem 1 (§4.3) is the trajectory-convergence result (IEEE TPAMI).
- paper Mean Shift: A Robust Approach toward Feature Space Analysis — Comaniciu & Meer (2002) The profile-function formulation and Theorem 1 (§4.1's monotone-density-ascent inequality) come from this paper (IEEE TPAMI).
- paper A Review of Mean-Shift Algorithms for Clustering — Carreira-Perpiñán (2015) The standard modern reference. §3.3 (kernel-choice robustness), §4.1 (noise-robust modes), §5 (sample-and-cluster) all draw on this review.
- paper Using Kernel Density Estimates to Investigate Multimodality — Silverman (1981) The 1D bandwidth-mode-count duality (§5.2 Theorem in $d = 1$) and the heat-equation reformulation (JRSS-B).
- book Density Estimation for Statistics and Data Analysis — Silverman (1986) The standard reference for the AMISE-optimal-bandwidth selectors §5.4 surveys (Chapman & Hall).
- paper A Population Background for Nonparametric Density-Based Clustering — Chacón (2015) The multivariate-extension of Silverman's duality result; §5.2 Theorem in $d \geq 2$ (Statistical Science).
- book Multivariate Kernel Smoothing and Its Applications — Chacón & Duong (2018) Chapter 7 develops the multivariate bandwidth-mode-count duality and the mode-tree machinery §5.3 uses (CRC Press).
- paper Mémoire sur une classe d'équations à différences partielles — Sturm (1836) The classical zero-count-non-increase theorem for parabolic equations §5.2 invokes (J. Math. Pures Appl.).
- paper Nonincrease of the Lap-Number of a Solution for a One-Dimensional Semilinear Parabolic Equation — Matano (1982) Modern proof of the Sturm zero-count result invoked in §5.2 (J. Fac. Sci. Univ. Tokyo).
- paper The Zero Set of a Solution of a Parabolic Equation — Angenent (1988) Companion modern treatment of the Sturm result (J. reine angew. Math.).
- paper Maximum Likelihood from Incomplete Data via the EM Algorithm — Dempster, Laird & Rubin (1977) The foundational EM paper; §10.2's M-step derivation and monotone-likelihood-ascent come from here (JRSS-B).
- book Bayesian Theory — Bernardo & Smith (1994) The M-closed / M-complete / M-open framework §10.4 invokes for the GMM-on-non-Gaussian-data critique (Wiley).
- paper Dealing with Label Switching in Mixture Models — Stephens (2000) The §10.3 label-switching problem in Bayesian mixture inference (JRSS-B).
- paper Least Squares Quantization in PCM — Lloyd (1982) Lloyd's algorithm — the alternating-minimization §9.1 calls k-means (IEEE TIT).
- paper Some Methods for Classification and Analysis of Multivariate Observations — MacQueen (1967) The earlier formulation that coined the term 'k-means' (Berkeley Symposium).
- paper k-Means++: The Advantages of Careful Seeding — Arthur & Vassilvitskii (2007) The §9.1 k-means++ initialization with $O(\log K)$ expected-WCSS approximation (SODA).
- paper A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise — Ester, Kriegel, Sander & Xu (1996) The original DBSCAN paper §11.3 sketches (KDD).
- paper Density-Based Clustering Based on Hierarchical Density Estimates — Campello, Moulavi & Sander (2013) HDBSCAN — the bandwidth-hierarchical extension of DBSCAN §11.3 references (PAKDD).
- book Clustering Algorithms — Hartigan (1975) The §1.2 / §12.4 modal-clustering hypothesis — cluster = basin of attraction of a density mode — is developed here (Wiley).
- paper Normalized Cuts and Image Segmentation — Shi & Malik (2000) The random-walk-Laplacian spectral-clustering algorithm §11.2 states (IEEE TPAMI).
- paper On Spectral Clustering: Analysis and an Algorithm — Ng, Jordan & Weiss (2002) The symmetric-normalized-Laplacian spectral-clustering algorithm §11.2 states (NeurIPS).
- paper A Tutorial on Spectral Clustering — von Luxburg (2007) The standard pedagogical reference for spectral clustering §11 redirects to (Statistics and Computing).
- paper The Laplacian Spectrum of Graphs — Mohar (1991) The bottom-eigenvector / cluster-indicator relationship §11.1 invokes (in Graph Theory, Combinatorics, and Applications).
- paper Comparing Partitions — Hubert & Arabie (1985) The Adjusted Rand Index used throughout for cluster-assignment agreement (J. Classification).
- paper Silhouettes: A Graphical Aid to the Interpretation and Validation of Cluster Analysis — Rousseeuw (1987) The silhouette score §1.3 contrasts against ARI (J. Comput. Appl. Math.).
- paper A Reliable Data-Based Bandwidth Selection Method for Kernel Density Estimation — Sheather & Jones (1991) The plug-in bandwidth selector §5.4 references (JRSS-B).
- paper Multivariate Plug-in Bandwidth Selection — Wand & Jones (1994) The multivariate plug-in selector §5.4 references (Computational Statistics).
- paper Empirical Choice of Histograms and Kernel Density Estimators — Rudemo (1982) The least-squares cross-validation (LSCV) selector §5.4 references (Scand. J. Statist.).
- paper An Alternative Method of Cross-Validation for the Smoothing of Density Estimates — Bowman (1984) Companion LSCV paper §5.4 references (Biometrika).
- paper Biased and Unbiased Cross-Validation in Density Estimation — Scott & Terrell (1987) Cross-validated bandwidth selection theory cited in §5.4 (JASA).
- paper An Asymptotically Optimal Window Selection Rule for Kernel Density Estimates — Stone (1984) LSCV consistency result invoked in §5.4 (Ann. Statist.).
- paper The Efficiency of Some Nonparametric Competitors of the t-Test — Hodges & Lehmann (1956) The kernel-efficiency comparison §6.1 invokes (Ann. Math. Statist.).
- paper The Mode Tree: A Tool for Visualization of Nonparametric Density Features — Minnotte & Scott (1993) The 1D mode-tree visualization §5.3 references (J. Comput. Graph. Statist.).
- book Smoothing of Multivariate Data: Density Estimation and Visualization — Klemelä (2009) The multivariate mode-tree algorithm §5.3 references (Wiley).
- paper Multidimensional Binary Search Trees Used for Associative Searching — Bentley (1975) The kd-tree spatial index §8.3 references (Comm. ACM).
- paper Five Balltree Construction Algorithms — Omohundro (1989) Ball-tree spatial index §8.3 references (ICSI Tech Report TR-89-063).
- paper Quick Shift and Kernel Methods for Mode Seeking — Vedaldi & Soatto (2008) Quick shift — a mean-shift variant briefly referenced for downstream computer-vision use (ECCV).
- book The Elements of Statistical Learning — Hastie, Tibshirani & Friedman (2009) Standard ML reference; Chapter 14 develops clustering with the perspective adopted throughout (Springer).
- book Machine Learning: A Probabilistic Perspective — Murphy (2012) The probabilistic-clustering chapter that complements §10's GMM-via-EM treatment (MIT Press).
- book Pattern Recognition and Machine Learning — Bishop (2006) §9 (mixture models and EM) is the standard reference for §10.2's derivation (Springer).