Conformal Prediction
Distribution-free prediction sets with finite-sample coverage from exchangeability alone
Distribution-Free Prediction and the Exchangeability Setup
We observe feature–response pairs and want to say something useful about the next pair . A point estimate answers “what’s the most likely value of ” but leaves “how much should we trust this answer” untouched. A prediction set is a data-dependent subset of the response space chosen so that
where is the miscoverage level and the probability is over the joint distribution of training, calibration, and test data. Conformal prediction is the construction that makes valid in this sense — without distributional assumptions on , without bounded-noise hypotheses, and without asymptotics. The only assumption is exchangeability.
Two structural points distinguish a prediction set from a confidence interval. First, a confidence interval covers a fixed parameter (a population mean, a quantile ); a prediction set covers a random variable — the unobserved . Second, the confidence interval shrinks at rate as the sample size grows, whereas the prediction set has an irreducible width set by the noise distribution: even with infinite training data, a prediction set for can never be tighter than the conditional spread of at that input.
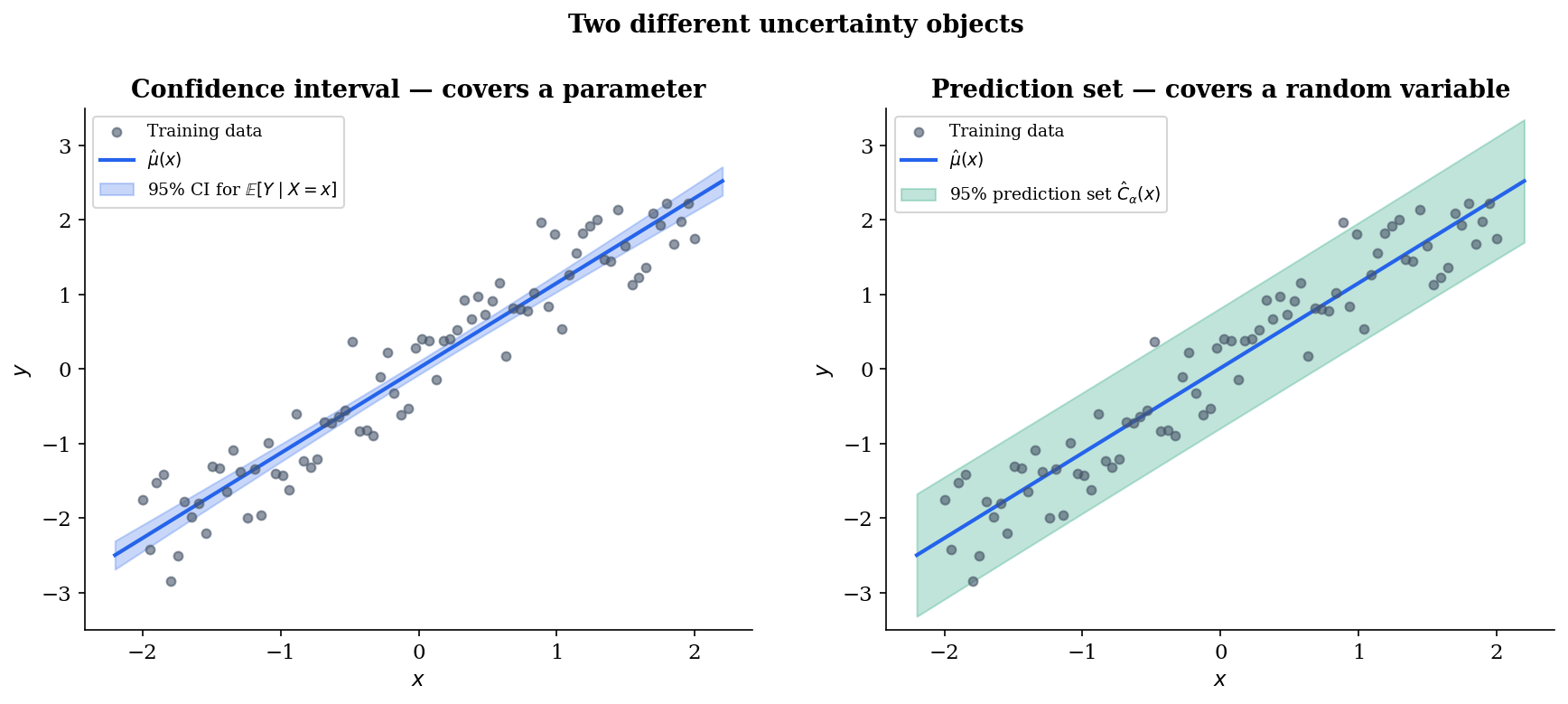
This contrast — CI for a parameter, prediction set for a random variable — is the same one that formalStatistics: Order Statistics & Quantiles draws when introducing distribution-free CIs for the population quantile via paired order statistics. The argument used there relies on rank symmetry under exchangeability, and Topic 29 §29.10 Remark 21 explicitly motivates Vovk–Gammerman–Shafer’s distribution-free prediction as the natural generalization from a fixed parameter to a random variable. We will see this same rank-symmetry machinery in §3’s proof of marginal coverage.
Definition 1 (Exchangeability).
A finite sequence of random variables is exchangeable if its joint distribution is invariant under coordinate permutation: for every permutation of ,
Exchangeability is strictly weaker than iid. Every iid sample is exchangeable — permuting independent draws from a common distribution leaves the joint law unchanged — but the converse fails: an urn drawn without replacement is exchangeable (any permutation of the draws is equally likely as a sequence) yet not iid (later draws depend on earlier ones). The structure of exchangeable sequences is described by de Finetti’s representation theorem: an infinite exchangeable sequence is a mixture of iid sequences, with the mixing measure capturing whatever shared latent structure links the observations. For finite-sample purposes, that subtlety doesn’t bite — what we need is the symmetry property itself.
The bet conformal prediction makes is that exchangeability holds for the augmented sequence — training, calibration, and test points all drawn from the same source. This is genuinely weaker than iid: it accommodates dependence within the dataset (the urn case, time-series with stationary increments, certain sampling-without-replacement designs) provided that no observation has a privileged position. What it does not accommodate is distribution shift — a test distribution that differs from the training distribution. We return to this in §8, where we visualize how naive conformal prediction degrades under covariate shift and see how the importance-weighted variant of formalStatistics: Empirical Processes ‘s sister technique (Tibshirani et al. 2019) restores marginal coverage when the shift is known.
The asymptotic alternative to conformal prediction is the empirical-processes route: Topic 32 of formalstatistics develops uniform-convergence bounds (DKW, VC dimension, Glivenko–Cantelli) that imply distribution-free coverage in the large- limit. Conformal prediction sidesteps the uniform-convergence rate entirely — it gives an exact finite-sample statement — at the price that the coverage is marginal rather than conditional (a distinction that becomes the impossibility theorem of §8). Both routes lead to distribution-free prediction; they pay different prices.
Split (Inductive) Conformal Prediction
The simplest realization of the marginal-coverage promise — and the one used in essentially every modern application — is split conformal prediction, sometimes called inductive conformal prediction. The construction is mechanical: split the data into a training set and a calibration set, fit a predictor on the former, score residuals on the latter, take an empirical quantile, declare the prediction interval. Three short paragraphs and a definition cover everything; the depth is in the proof, which lands in §3.
Partition the available observations into a training set of size and a calibration set of size :
Then run four steps.
Step 1 — Fit. Train a base predictor using only the training set. The base predictor can be anything — ridge regression, a random forest, a neural network — and the coverage guarantee will not depend on what it is. The quality of controls the width of the prediction interval, not its validity.
Step 2 — Score. Compute a nonconformity score at each calibration point. For regression, the standard choice is the absolute residual ; for classification we will use a different score in §7. The score is “large when looks anomalous given the fitted model.”
Step 3 — Threshold. Take the -th smallest calibration score and call this value . (When — which happens for very small calibration sets — cap at , equivalently set and the interval becomes all of .)
Step 4 — Predict. For a new test point , the prediction set is the level- sublevel set of the score:
For the absolute-residual score this resolves to a symmetric interval centered on the prediction, . The interval has the same half-width at every test point, regardless of — split conformal with this score is not locally adaptive. We address that in §6 (CQR).
Definition 2 (Split Conformal Prediction Set).
With training-fitted predictor , calibration set of size , nonconformity score , and miscoverage level , the split conformal prediction set at input is
where is the
smallest of the calibration scores .
The "" inside the ceiling deserves a moment. It looks fussy — and it is, in the sense that for moderate it changes by at most one rank — but it is also load-bearing. Under exchangeability, the (unobserved) test-point score will be inserted into the augmented sequence at a uniformly random rank in . The ceiling-and-plus-one converts that rank uniformity directly into the marginal-coverage probability. Drop the and the bound is no longer tight; replace the ceiling with a floor and the bound flips to a strict inequality in the wrong direction. We reconstruct this argument in §3.
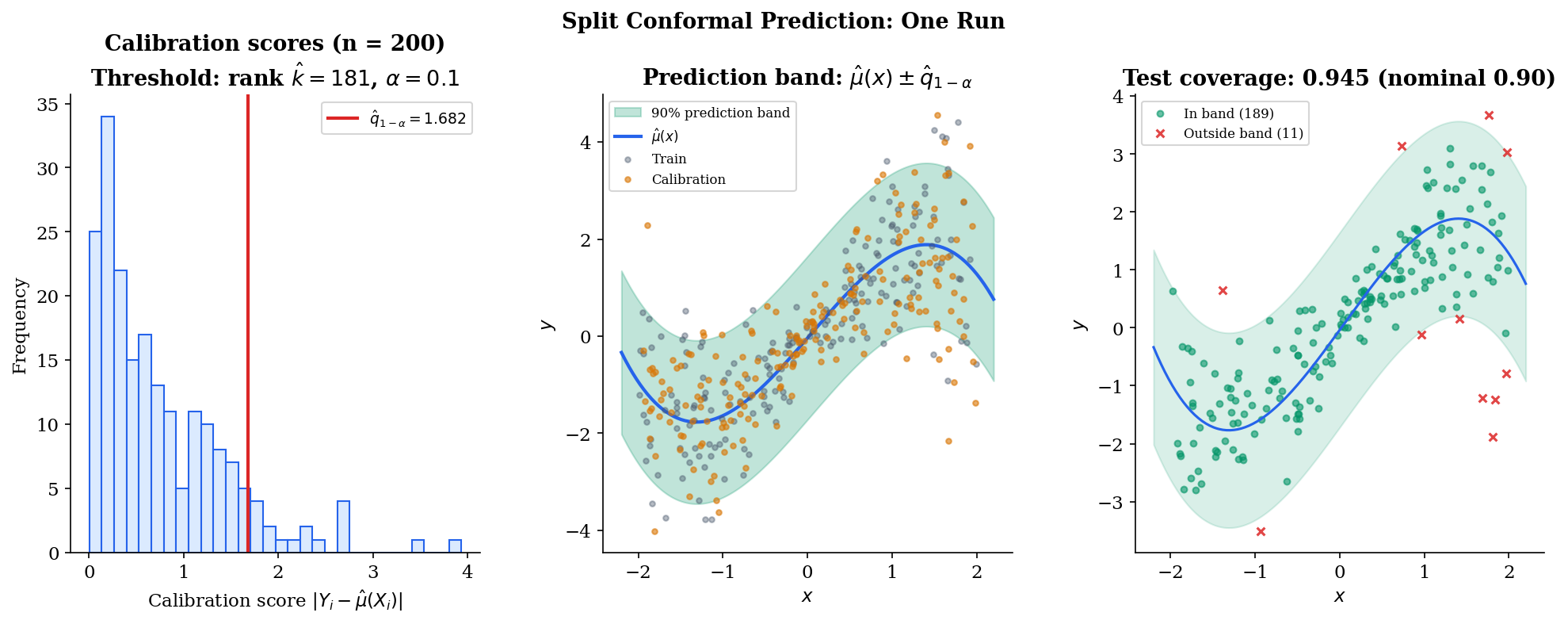
The construction is so spare that it raises an immediate question: why does this work? Nothing in steps 1–4 used the joint distribution of , the smoothness of , or any property of the base predictor beyond its having been fit before the calibration scores were computed. The next section gives the answer — Theorem 1 (marginal coverage), proved entirely from rank symmetry under exchangeability.
Marginal Coverage: The Central Theorem
Theorem 1 is the reason split conformal works. It is also the reason the construction is so insensitive to the choice of base predictor and nonconformity score — the proof never opens those black boxes. Everything follows from a single combinatorial fact: under exchangeability, the test-point score is equally likely to land at any rank within the augmented sequence of calibration-plus-test scores. Convert that rank uniformity to a coverage probability, and the bound is finite-sample, two-sided, and tight.
Theorem 1 (Marginal Coverage — Lei, G'Sell, Rinaldo, Tibshirani & Wasserman 2018).
Let be exchangeable, where the first pairs constitute the calibration set and is a test point. Suppose the nonconformity score does not depend on the calibration or test set — for example, it depends only on a separately-trained predictor. Then the split conformal prediction set at level satisfies
Moreover, if the score distribution is continuous (no ties almost surely),
Proof.
Let for . Because is a fixed function — the training set has been consumed already, and does not depend on the remaining points — exchangeability of the underlying pairs lifts to exchangeability of the scores: the joint distribution of is invariant under any permutation of indices.
Let denote the rank of the test-point score in the augmented vector , that is,
Continuity of the score distribution ensures no ties almost surely, so is well-defined as an integer in . Exchangeability means each of the positions is equally likely to be the test point’s, so
In words: is uniformly distributed on . This is the only probabilistic fact the proof needs.
Set . The prediction set covers iff the test score lies at or below the threshold:
A short combinatorial step converts the calibration-set rank to the augmented-set rank. If occupies augmented rank , exactly of the augmented scores are strictly smaller than it; each of those smaller scores must lie in the calibration set (the test set contributes only itself). So ranks at most among the calibration scores precisely when :
Combining with ():
The lower bound is immediate from the definition of :
so . For the upper bound, use :
so
∎Remark (Marginal Coverage Proof Independence).
The proof never opens the black box of or invokes a property of the data beyond exchangeability. It does not assume that has finite moments, that lies in a bounded set, or that the marginal distribution is continuous — only that the score distribution is continuous (which holds almost surely whenever has a continuous conditional density, the typical regression setting). The score function is chosen by the analyst; the only restriction is that not depend on the calibration or test data, equivalent to fitting any tunable parts of — including the predictor and its hyperparameters — using only the training set.
The two-sided bound says coverage concentrates in a strip of width above . At and the strip is — only percentage points wide. The next visualization runs Monte Carlo trials at user-controlled and shows the empirical coverage histogram concentrating inside the predicted band. Drag the calibration-size slider to see the strip narrow as grows — and notice that even the regime (where the upper bound is fully percentage points above ) preserves marginal validity in expectation.
Drag α to retarget coverage; switch n_cal to see the upper-bound strip narrow as 1/(n_cal+1) shrinks. The middle-panel histogram concentrates inside the orange [1−α, 1−α+1/(n_cal+1)] band predicted by Theorem 1; the bottom-panel running mean converges into the same band as t → T. The top panel's red test points are the rare misses (~α fraction).

The bound is tight, not just a one-sided guarantee — and that tightness is doing real work. A naive reading of "" might suggest the procedure could over-cover wildly with no statistical penalty, but Theorem 1’s upper bound rules that out: split conformal does not waste coverage. As long as the score distribution is continuous and exchangeability holds, the procedure delivers within of nominal — no looser, no tighter.
What the bound does not say is anything about conditional coverage at a specific . The marginal probability averages over the distribution of , so a procedure that under-covers in one region and over-covers in another can still satisfy Theorem 1. We return to this in §8 with the Foygel-Barber 2021 impossibility theorem.
Cross-Validation in Conformal: CV+
Split conformal pays a calibration tax. The data partition has to allocate enough mass to the calibration set for the threshold to be stable — typically — which means the predictor trains on only half the available data. For a fixed total budget this is genuinely wasteful: a better would mean tighter prediction intervals (recall, the width depends on predictor quality even though validity doesn’t).
Cross-validation offers a way out. Partition into folds of roughly equal size, and for each fold fit a predictor on the data with fold removed. The leave-one-fold-out residual at observation is
and the CV+ prediction interval uses these residuals — combined with per-fold predictions at the test point — through the same quantile construction we will introduce for jackknife+ in §5. Every observation contributes to both the fit and the residual scoring; no calibration tax.
The trade-off is computational. Jackknife+ () requires predictor fits; -fold CV+ requires only fits, typically or . For expensive base predictors — random forests, neural networks, anything that costs minutes per fit — CV+ is the only practical route. The coverage guarantee is identical: Theorem 2 in §5 establishes the lower bound for both jackknife+ () and -fold CV+ verbatim. The factor of is worst-case over base predictors; in practice, both procedures achieve coverage very close to nominal .
The full procedural definition, the BCRT 2021 tournament/comparison-graph proof, and the empirical comparison to split conformal all live in §5. The anchor here exists so that any sister-site reference to “cross-validation in machine learning” can deep-link to a coherent treatment without minting a separate topic.
Full (Transductive) Conformal Prediction
CV+ avoids the calibration tax by recycling fits across folds. Full conformal — the original Vovk-Gammerman-Shafer construction — avoids it differently: by treating the candidate response itself as the variable and refitting the predictor once per candidate. Every observation is used for both fitting and calibration; the price is a per-candidate refit at test time.
The procedure. To form the prediction set at a new test input , iterate over candidate values and for each one run four steps.
Step 1 — Augment. Form the augmented dataset — the original observations plus the test input paired with the candidate .
Step 2 — Fit. Fit a predictor on , or equivalently define a score function from .
Step 3 — Score. Compute calibration scores for — every observation, including the augmented test pair.
Step 4 — Include. Include in iff the rank of among is at most .
The marginal-coverage guarantee extends from §3 with no change. When the candidate equals the true (unobserved) , the augmented dataset is exchangeable, and Theorem 1’s argument — uniformity of the test-score rank in — applies verbatim. Therefore .
Why study it. Full conformal is rarely the practical default but it earns its keep on two counts. First, statistical efficiency: every observation contributes to both the fit and the rank computation, so for small — say — the prediction interval is meaningfully tighter than split conformal at the same . Second, theoretical cleanliness: many extensions of conformal (online conformal under streaming data, conformal under model misspecification, conformal for transductive learning) are easier to state and analyze in the full-conformal framework, then specialized to split.
Computational cost. Naively, full conformal requires one predictor fit per candidate . For finite response spaces — classification with classes — this is fits per test point, eminently tractable. For continuous regression, the candidate space must be discretized to a grid, giving fits, which gets expensive but is embarrassingly parallel. For specific predictors the per-candidate refit collapses: ridge regression admits closed-form leave-one-out updates that turn full conformal into a single pass, and recent work has produced similar closed-form recipes for kernel ridge, lasso, and certain neural network families.
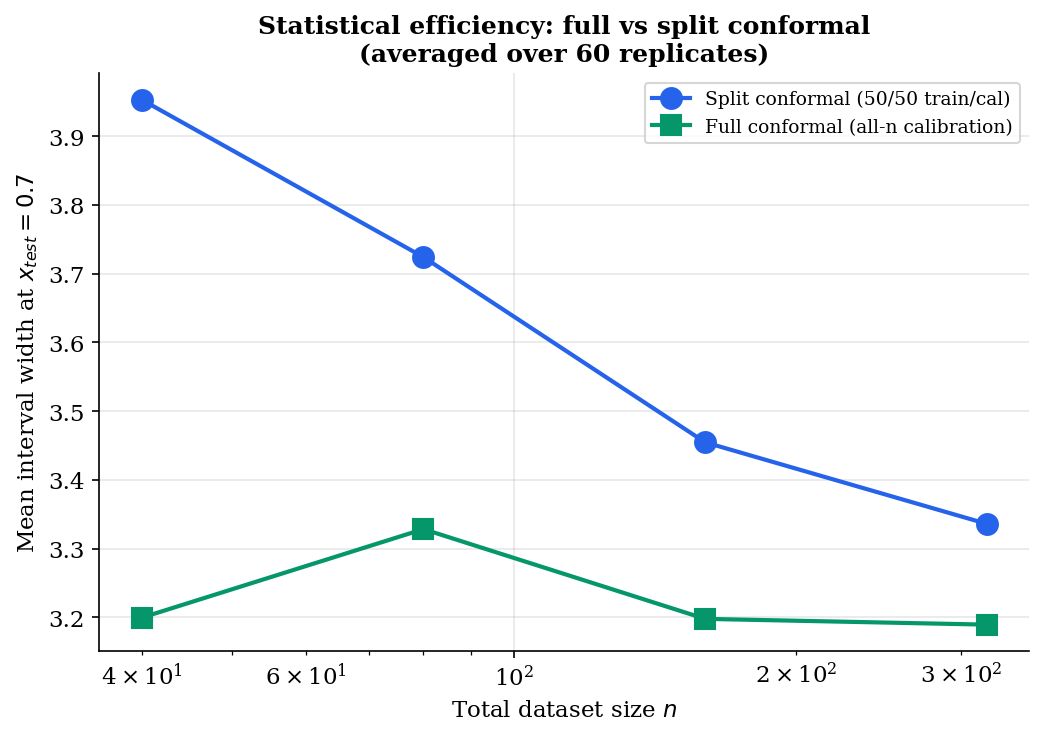
For most practical purposes — modern ML with in the thousands and base predictors that take seconds to fit — split conformal is the right default and the rest of this topic uses it. Full conformal sits in the toolkit for the small- regime, the closed-form-update predictors, and the theoretical extensions that are easier to derive there. Jackknife+ and CV+ in §5 carve out a middle ground: leave-one-out residuals through a small number of refits, with the same exchangeability machinery delivering a (slightly weaker) coverage bound.
Jackknife+ and CV+
Split conformal pays a calibration tax; full conformal pays a per-candidate refit tax. Jackknife+ (Foygel Barber, Candès, Ramdas & Tibshirani 2021) charts a third route: use every observation for both fitting and residual scoring through leave-one-out refitting. Each calibration residual is computed against a predictor that did not see that observation, restoring statistical efficiency without the per-candidate explosion of full conformal. The price is mild — predictor fits per training (one for each leave-one-out), parallelizable — and the coverage guarantee weakens by a factor of two.
For each , let denote the predictor fit on the dataset with the -th observation removed, and define the leave-one-out residual
This is an honest residual in the sense that it never used in its training — exactly the property split conformal extracted by partitioning the data, but achieved here without sacrificing any sample.
Definition 3 (Jackknife+ Prediction Interval).
The jackknife+ prediction interval at test point , miscoverage level , is
where is the -th smallest of a collection of values (with ) and is the -th smallest (with ).
The endpoints look more elaborate than the symmetric split-conformal interval, but each is just an empirical quantile of leave-one-out predictions adjusted by their respective residuals. The lower endpoint asks “across all leave-one-out fits, what’s the small-quantile of ” — a low-side estimate that accommodates predictor variability across LOO fits and the residual magnitudes. The upper endpoint is symmetric. Crucially, the -th LOO predictor’s variability and its residual move together: a fold whose held-out point is hard to predict produces both a wild and a large , and the construction lets these self-correct.
Theorem 2 (Jackknife+ Coverage Bound — Foygel Barber, Candès, Ramdas & Tibshirani 2021).
Under exchangeability of ,
The constant cannot be improved without further structural assumptions on the predictor: BCRT 2021 exhibit a degenerate base predictor under which jackknife+ achieves coverage arbitrarily close to .
Proof.
The proof follows BCRT 2021 §3.2; we reconstruct the key combinatorial moves and direct the reader to the original for the formalization of the tournament step.
For each , define the leave-one-out swap residual
the absolute residual we would have observed if the test point had taken the role of training point and had taken the role of the test point. By exchangeability of the observations together with the fact that the predictor is a symmetric function of its inputs (the order of the training observations does not matter), the joint distribution of the residuals is invariant under any swap of indices . In particular, and have the same marginal distribution for each .
Consider the comparison graph on vertex set defined by placing a directed edge whenever the leave--out residual at exceeds the leave--out residual at (BCRT 2021 §3.2). For the swap-symmetry argument, what matters is the pairwise comparison between each training index and the test index . The exchangeability swap above shows the comparison is symmetric in , so the directed in-degree of vertex in this graph is uniformly distributed among .
The “bad event” for jackknife+ — the test point falling outside the prediction interval — splits into two failure modes:
BCRT 2021 Lemma 1 establishes that each of these failure modes corresponds to at most an fraction of comparison-graph configurations. Concretely: the lower endpoint is the -th smallest of , and a counting argument over the comparison graph shows
with the symmetric statement for the upper endpoint. The argument is non-trivial because the residuals are not independent under the swap — they share the LOO predictor structure — but the tournament-style counting in BCRT 2021 Lemma 1 handles this dependence by showing the bad events at indices and cannot both occur for too many pairs simultaneously.
Combining the two bounds via a union bound:
equivalently .
Two ingredients carry the argument: (a) rank symmetry under exchangeability combined with the symmetry of in its inputs, and (b) the union bound over the two endpoint-failure modes. The full formalization of step (a) — the comparison-graph counting that resolves the dependence between and — is BCRT 2021 Theorem 1, which we have not reproduced here.
∎Remark (Jackknife+ Worst-Case Tightness).
The factor of in is worst-case over base predictors. BCRT 2021 §4 constructs an adversarial base predictor — essentially a constant function on most of the input space with a single sharp anomaly — that drives jackknife+ to coverage arbitrarily close to from above. For reasonable base predictors (ridge, random forest, neural networks with standard regularization) the empirical coverage of jackknife+ is typically within a percentage point or two of the nominal — much closer to split conformal’s tight than the worst-case would suggest. The factor-of-two penalty is the theoretical price for refusing the calibration-set partition; the empirical price is usually negligible.
CV+ (the -fold extension introduced in §3.8) inherits Theorem 2 verbatim: for any . The proof is identical — the swap-symmetry and union-bound moves work for any leave-fold-out predictor structure, not just leave-one-out. The trade-off is the one we already saw: fits instead of , with the empirical coverage typically a hair worse than jackknife+ at small (more residual variance) and effectively identical at (which recovers jackknife+).
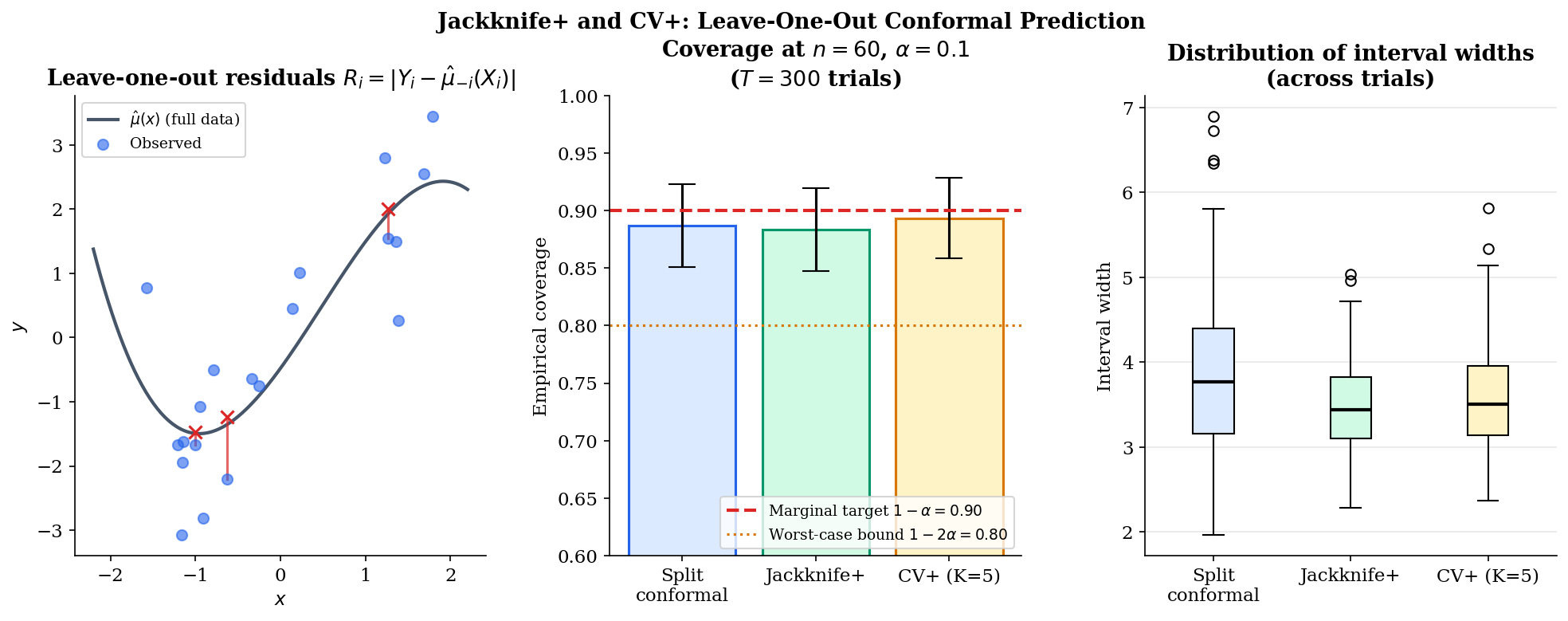
The empirical takeaway visible in the figure: at — small enough that the calibration tax matters — jackknife+ and CV+ produce tighter intervals than split conformal at the same , and the BCRT bound is loose by a wide margin. The choice between the three procedures is essentially a budget question. With abundant data and an expensive base predictor, split conformal is the workhorse. With a moderate and a cheap-to-refit predictor, jackknife+ extracts more from each observation. With expensive predictors but enough data to support fold-level fits, CV+ is the practical compromise.
What none of the three procedures achieve — and what §6 addresses — is locally adaptive width. Every procedure in §2–§5 produces a band whose half-width is a single global threshold; the band is wide where it doesn’t need to be (low-noise regions) and narrow where it shouldn’t be (high-noise regions). Conformalized quantile regression (CQR) fixes this by replacing the mean-residual nonconformity score with one built from quantile-regression endpoints.
Conformalized Quantile Regression (CQR)
The split-conformal interval has the same half-width everywhere. On homoscedastic data this is fine — the conditional spread of is constant by hypothesis. On heteroscedastic data it is wasteful where the noise is small and over-confident where the noise is large: the band over-covers in low-noise regions and under-covers in high-noise regions. The marginal coverage guarantee from Theorem 1 still holds — it is an average over the input distribution — but the conditional coverage at any specific can drift far from in either direction.
Conformalized quantile regression (Romano, Patterson & Candès 2019) keeps the conformal envelope but swaps the base learner. Instead of fitting a single mean predictor , fit two quantile regressions — one estimating the lower conditional quantile of , the other estimating the upper conditional quantile . The conditional QR endpoints already capture heteroscedasticity by design (they are wider where is more dispersed); the conformal layer wraps them with a calibration step that preserves marginal coverage exactly. CQR thus inherits the distribution-free guarantee of split conformal and the locally adaptive width of quantile regression — the best of both worlds, with the only assumption still exchangeability.
Quantile regression itself is a topic for another day. For our purposes, treat and as black-box functions that take training data and return estimated conditional quantiles — fitted by check-loss minimization, possibly with regularization. Quantile Regression covers the estimation theory, asymptotic distribution, and broader applications.
Definition 4 (CQR Prediction Set).
Let and be quantile-regression estimates of the conditional and quantiles of , fit on the training set. For each calibration point , define the CQR nonconformity score
The score is positive when lies outside the QR interval — measuring how far outside, in the direction of the violation — and negative when lies inside. Let denote the -th smallest of . The CQR prediction set at test input is
The construction is mechanically simple: shift the lower QR endpoint down by , shift the upper up by the same amount. If the QR fits are well-calibrated and most already fall inside their intervals, then is negative for most , the empirical quantile is small or even negative, and CQR produces an interval narrower than the QR interval itself (a tighter band, achievable because the calibration step “credits back” the QR’s natural slack). If the QR fits are systematically narrow or wrong, is positive for many , is large and positive, and the CQR interval inflates the QR endpoints to recover the marginal-coverage guarantee. Either way, the band width is allowed to vary with — which is the locally adaptive property naive split conformal lacks.
Heteroscedasticity: σ(x) = 0.3 + h · |x|. At h = 0 the noise is constant and both bands are equivalent. As h grows, naive split-conformal's constant-width band over-covers near x = 0 and under-covers in the tails (visible in the right panel as a U-shaped dip below 1 − α). CQR's per-x quantile estimates track the noise envelope, keeping the right-panel curve much flatter — approximate conditional coverage as a side benefit of locally adaptive width.

Theorem 3 (CQR Coverage Inheritance — Romano, Patterson & Candès 2019).
Under exchangeability of ,
Proof.
CQR is split conformal applied to the nonconformity score
This score depends on the training set (through the fitted quantile regressions and ) but not on the calibration or test data — exactly the hypothesis of Theorem 1. The marginal-coverage statement therefore applies verbatim, giving . The two-sided refinement from Theorem 1 also extends: if the score distribution is continuous, coverage is bounded above by .
∎Remark (CQR's Novelty Is the Score, Not the Theorem).
The proof of Theorem 3 is one paragraph because CQR is a special case of Theorem 1. The novelty of CQR is not a new probabilistic argument — it is the choice of score function. Naive split conformal with produces an interval of constant half-width centered on . CQR replaces this with an interval whose endpoints are themselves regressed on : the lower endpoint is shifted down by , the upper is shifted up. Because the QR estimates capture heteroscedasticity at the base-learner level, the conformal envelope inherits a locally adaptive width without any additional machinery. The lesson generalizes: any time you want a different shape of prediction interval, design the nonconformity score to extract that shape, and let Theorem 1 deliver the coverage guarantee for free.
Remark (Approximate Conditional Coverage).
CQR does not achieve exact conditional coverage — that is impossible for any distribution-free procedure with finite, informative prediction sets, as we will show in §8. It does achieve an empirically much flatter conditional-coverage curve than naive split conformal, in the sense that the gap is small on average over when the QR base learner is well-specified. The visualization above makes this precise on a heteroscedastic example: naive split conformal under-covers in the high-noise tails by 5–10 percentage points, while CQR holds within 2–3 percentage points across the input range. The improvement is empirical, not theoretical, and it depends on the QR fits being good enough to capture the conditional spread — which is itself a hard estimation problem for high-dimensional or low-data settings.
CQR is the practical default whenever the data is visibly heteroscedastic and computational budget allows fitting two quantile regressions. It is also the construction that points furthest in the direction of conditional coverage — a property that motivates the impossibility theorem of §8 and the importance-weighted extensions for known covariate shift. Before that, §7 takes the conformal envelope into a different setting entirely: classification, where the response is discrete and “interval” gets replaced by prediction set.
Adaptive Prediction Sets (APS) for Classification
Everything so far has been regression. Conformal prediction adapts to classification with a single change: replace the absolute-residual nonconformity score with one built on top of the classifier’s softmax probabilities. The output is no longer an interval — it is a set of predicted classes, sized to match the model’s uncertainty at the test input. Adaptive Prediction Sets (APS), due to Romano, Sesia & Candès (2020), is the canonical construction. Like CQR, it is split conformal applied to a different score, so Theorem 1 delivers the marginal coverage guarantee for free.
Setup. Let be the discrete response space. A classifier produces softmax probabilities with . Order the classes at input from highest to lowest probability:
For any class , write for its rank in this descending ordering — so the most-probable class has rank 1, the second-most has rank 2, and so on.
Definition 5 (APS Score and Prediction Set, Deterministic Variant).
The APS nonconformity score at a labeled point is the cumulative mass of all classes ranked strictly above :
The top-predicted class has score (no classes above it); the second has score ; and so on through the ordering. Given calibration scores for , let denote the -th smallest. The deterministic APS prediction set at a new test input is
Equivalently: include classes from highest probability downward until the cumulative mass of the strictly-higher classes exceeds the threshold.
Three Gaussian blobs at fixed centers; σ controls within-class spread (smaller = more separable, larger = more overlap). At small σ the classifier is confident almost everywhere and APS produces singletons; at large σ the decision boundaries get thick and the set sizes grow to 2 or 3 there. Marginal coverage tracks 1 − α regardless of σ; per-set-size coverage stays close to nominal — APS is not over-extracting coverage from any one set-size bucket.

The deterministic APS variant always includes the top-predicted class (its score is for any non-trivial threshold), so is never empty. Romano-Sesia-Candès also describe a randomized variant that achieves exactly coverage by allowing the borderline class to be included with a probability tuned to the calibration set; the deterministic version overcovers by at most — the same discretization slack we saw in Theorem 1’s upper bound — and is the version implemented in libraries like mapie.
Coverage. APS is split conformal with the score above. The score depends only on the training-fitted classifier (and therefore not on the calibration or test data), so Theorem 1 applies verbatim and gives
with the same two-sided refinement when scores are continuous. (For APS the score is discrete by construction — it takes at most distinct values per input — so the upper bound holds with the discrete analog: ties between calibration scores can be broken with the deterministic-rule convention with no impact on the lower bound.)
Why APS, not top-K? A naive alternative is “include the smallest set of classes whose cumulative softmax mass exceeds .” This is the top- procedure where varies per input. It works when the classifier’s softmax is well-calibrated — meaning the predicted probabilities match the true conditional probabilities — but degrades sharply when softmax is miscalibrated, which is the typical case for modern neural networks. APS is the calibrated alternative: the threshold is determined empirically from the calibration set rather than implicitly through the softmax magnitudes, so coverage is decoupled from softmax-calibration assumptions. Whatever the classifier’s calibration quality, APS recovers the marginal-coverage guarantee.
Adaptivity. The set size at any test input is exactly the number of classes with — equivalently, the smallest such that . Where the classifier is confident (), the second class already has score (typically), so the set is a singleton. Where the classifier is genuinely uncertain across multiple classes, the top score grows slowly and several classes pass the threshold, producing a multi-class set. Romano-Sesia-Candès 2020 prove that APS achieves approximate conditional coverage when softmax is well-calibrated — the average gap is small — though, as with CQR, exact conditional coverage is impossible by the result we turn to next.
The figure above is worth pausing on. The middle panel — the region map colored by set size — is the most direct visualization of what APS is doing. Inside each class blob the set is a singleton (green); along the decision boundaries between blobs, where two classes are competitive, the set grows to two (amber); in the central region where all three classes are roughly equally probable, the set grows to three (red, when present). The bar chart on the right confirms the marginal coverage and shows that per-set-size coverage is also close to — the procedure is not gaming the average by extracting all its coverage from one set-size bucket.
APS extends to multi-label classification, ordinal classification, and hierarchical class structures — each by appropriate redesign of the nonconformity score. The pattern from §6 holds: the score does the work, and Theorem 1 delivers the guarantee. Where the difficulty really lies is the conditional coverage problem: APS approximates it, but it cannot be achieved exactly without distributional assumptions. The next section makes that precise.
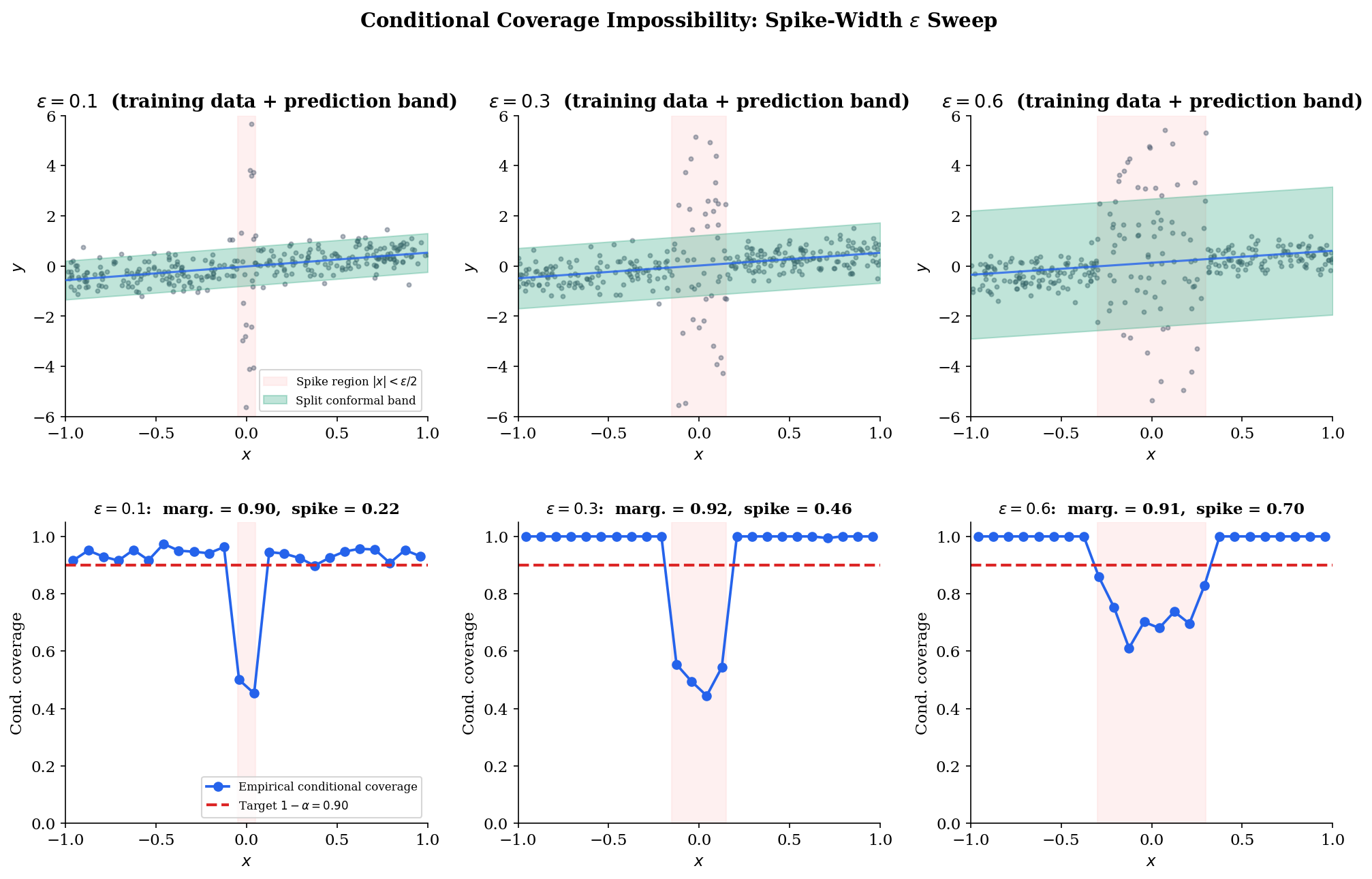
Conditional Coverage: Impossibility and Approximations
Theorem 1 guarantees marginal coverage: averaged over the joint distribution of training, calibration, and test data, the prediction set covers with probability at least . The marginal probability is computed over the distribution of , so a procedure that systematically under-covers in one input region and over-covers in another can still satisfy Theorem 1. A user typically wants more — conditional coverage,
Conditional coverage means the procedure works uniformly across the input space: no input region is systematically undercovered. CQR and APS are designed with this property in view, and they achieve it approximately under reasonable assumptions on the base learner. The result of this section is that exact conditional coverage — the bound at for every , distribution-free — is impossible for any procedure that produces finite, informative prediction sets. Foygel-Barber et al. 2021 made this precise by exhibiting an adversarial family of distributions on which any conditionally-valid procedure must produce arbitrarily wide intervals at the adversarial input.
Theorem 4 (Conditional Coverage Impossibility — Foygel Barber, Candès, Ramdas & Tibshirani 2021).
Let be a class of distributions on satisfying:
(i) has a continuous distribution under each ;
(ii) is closed under spiked-variance perturbations: for any , , and , the distribution
belongs to .
Suppose is a (data-dependent) prediction procedure satisfying conditional coverage uniformly over . Then for any fixed sample size and any , there exists a distribution (with spike width ) such that, with probability at least over the calibration data,
where is the standard normal CDF. As can be taken arbitrarily large, the expected Lebesgue measure of under is unbounded.
Proof.
The argument is constructive. Fix the sample size and the resolution parameter . We will exhibit a member of on which any conditionally-valid procedure must produce an arbitrarily wide prediction set at .
Step 1: Choose the spike. Set . Let be the spiked-variance distribution from condition (ii) with spike center , spike width , baseline noise , and spike magnitude (to be sent to infinity at the end). Under , the conditional distribution at — the spike center — is , while at any outside the spike interval the conditional distribution is .
Step 2: The “no spike samples” event . Each draw has in the spike interval with probability (the interval has length and is uniform on ). The probability that no calibration point falls in the spike interval is
as . For moderate — and for our — this probability exceeds . So with probability at least over the calibration data, no observation in the calibration set is informative about the spike.
Step 3: Indistinguishability. Let denote the spike-free baseline distribution: , , no spike. On the event (no calibration point lands in the spike), the calibration data is observationally indistinguishable from a sample drawn under — every observed pair is consistent with both and . Because is a measurable function of the calibration data, on the event the procedure produces the same prediction set it would have produced under :
with denoting the procedure’s output when calibrated under . The procedure cannot tell which distribution it is operating under because the calibration data does not separate them.
Step 4: Conditional coverage at the spike. Now condition on event and on the test input . Under the true distribution , the conditional law is — full spike variance. The conditional-coverage hypothesis requires
where we have substituted from Step 3. The left side is the probability that an random variable lies in a fixed (data-dependent) set .
Step 5: Anderson’s lemma. For any measurable with where , the Lebesgue measure of is bounded below by the Lebesgue measure of the smallest symmetric interval centered at the mode containing the same probability mass:
(This is Anderson’s lemma applied to a unimodal Gaussian: among all sets of prescribed measure, the central interval maximizes the Gaussian probability; equivalently, among all sets of prescribed Gaussian probability, the central interval minimizes Lebesgue measure.) Applied to and :
Step 6: Send . The right side grows without bound as increases, and the inequality holds on the event (probability at least ). The expected Lebesgue measure of under is therefore unbounded, completing the construction.
∎Remark (Impossibility Holds with Only Measurability).
The proof never invokes any regularity property of the procedure beyond its being a measurable function of the calibration data. The argument does not assume the procedure is symmetric, exchangeable, or based on any specific score; it does not assume the predictor is consistent or unbiased; it does not even assume produces an interval (it works for arbitrary measurable subsets of ). The “no spike samples” event does the entire heavy lifting: on , the calibration data does not separate from , so any procedure computed only from data cannot discriminate between the two — yet at requires distinguishing them. The impossibility is a statement about the information content of the calibration data, not about the procedure’s design.
Remark (Approximate Conditional Coverage of CQR/APS).
Theorem 4 does not contradict §6 (CQR) or §7 (APS). Both procedures retain marginal coverage — Theorem 1 still applies — and produce adaptive prediction sets whose width or size varies with . What they do not claim is conditional coverage uniformly over the spiked-variance family . Under additional smoothness assumptions on — assumptions that exclude spiked-variance distributions, such as Lipschitz continuity of the conditional CDF — CQR achieves an approximate conditional-coverage guarantee in which the average gap
is small. The empirical message of §6’s CQR-vs-naive comparison was exactly this: under reasonable conditions, CQR’s per-bin coverage curve is much flatter than naive split conformal’s. Theorem 4 says: drop the smoothness assumptions and adversarial constructions reassert themselves. Any practical claim to “conditional coverage” implicitly invokes such assumptions.
Remark (Covariate Shift Connection — Tibshirani, Foygel Barber, Candès & Ramdas 2019).
The impossibility motivates an extension that has become the standard fix when the user has known distribution-shift information. If the test distribution differs from the training distribution , exchangeability fails and naive split conformal can lose its marginal coverage at the test distribution. Tibshirani, Foygel Barber, Candès & Ramdas (NeurIPS 2019) showed that importance-weighted split conformal — where calibration scores are weighted by the likelihood ratio — restores marginal coverage at the test distribution under known shift. The construction is the weighted empirical quantile of the calibration scores, with the test point’s own weight entering the denominator (this is the weightedSplitConformal in nonparametric-ml.ts). It does not solve the conditional-coverage problem of Theorem 4 — that remains impossible — but it does solve the marginal-coverage-under-shift problem, which is the more practical concern in many deployment settings.
Train distribution: x ~ N(0, 1), blue histogram. Test distribution: x ~ N(Δ, 1), green histogram. Naive split conformal (blue band) was calibrated on the train distribution and progressively under-covers as Δ grows — the bottom-panel blue curve drops well below 1 − α. The TBCR 2019 importance-weighted variant (green band) uses the closed-form Gaussian density ratio w(x) = N(x; Δ, 1) / N(x; 0, 1) to recalibrate; the bottom-panel green curve holds at the 1 − α target across the entire shift range.
The takeaway from §8 is paired. Negative: distribution-free conditional coverage is impossible at full generality; any procedure claiming it must restrict to a smaller distribution class. Positive: marginal coverage under shift is recoverable when the shift is known, via importance-weighted variants of the procedures we’ve already developed. Conditional coverage in practice is achieved approximately by adaptive base learners (CQR, APS) and assessed empirically — an honest report of the per-region coverage gap, not a theoretical guarantee. With these limits drawn, §9 returns to the practical question that motivated the topic: how do we wrap conformal prediction around any black-box ML model?
Wrapping Black-Box ML Models
The whole point of conformal prediction’s distribution-free guarantee is that the base predictor can be anything — ridge regression, gradient boosting, random forest, neural network, transformer, anything that maps inputs to predictions. Theorem 1 doesn’t care what’s inside; it only cares that the score function is held fixed across calibration and test. This means the entire topic up to here applies, unchanged, to any model you already have.
The skeleton in five steps:
Step 1 — Split. Partition your data into training, calibration, and test (typically 50/50 between the first two; test is whatever you want to evaluate on later).
Step 2 — Fit. Train your favorite black-box model on the training set. Hyperparameter tuning, early stopping, ensembling — all fine, as long as none of it touches the calibration set.
Step 3 — Score. Compute calibration scores on the calibration set (or the CQR/APS variants from §6/§7 if you want adaptivity).
Step 4 — Threshold. Set to the -th smallest calibration score.
Step 5 — Predict. For each new test point , return (or the appropriate analog for your score function).
That is the entire procedure. There are no model-class-specific tweaks; ridge and a 100-million-parameter transformer use the same five steps. The cost of conformal wrapping is one calibration pass and one threshold lookup — additive overhead measured in milliseconds for any non-trivial base predictor.
The empirical demonstration in Figure 9 below applies these five steps to three base predictors on the same heteroscedastic regression dataset: a degree-3 polynomial ridge (the predictor we have used throughout), a small MLP with two hidden layers, and a random forest. All three target and all three achieve empirical marginal coverage near 0.90 — the conformal layer enforces the guarantee regardless of the base predictor’s particulars. What does vary across predictors is the width of the prediction interval: the better-fit predictor produces tighter intervals because its residuals on the calibration set are smaller, so shrinks. Width depends on accuracy, coverage does not — a one-line summary of what conformal prediction buys you.
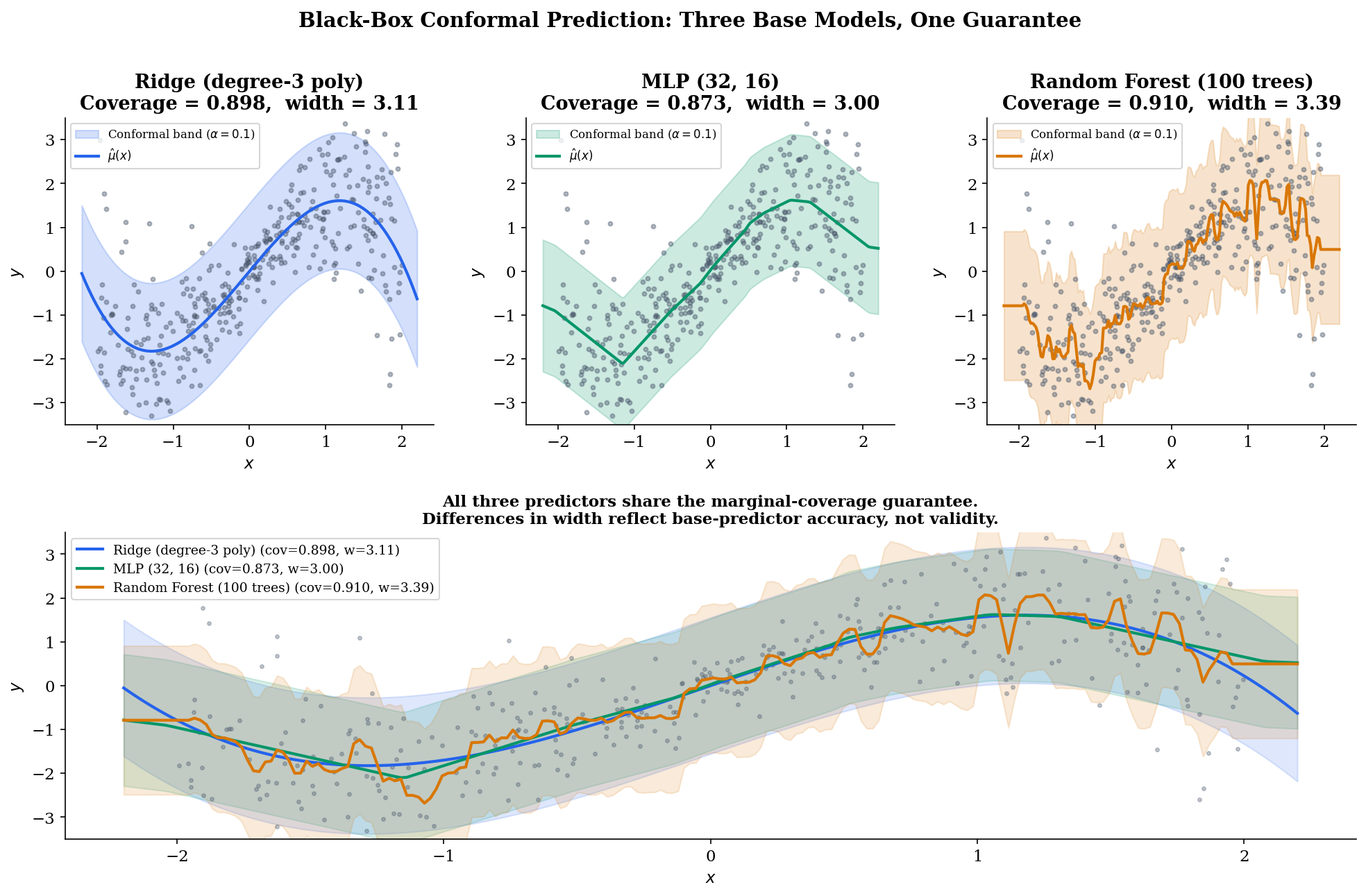
For production deployments, the mapie library implements split conformal, jackknife+, CQR, and APS (deterministic and randomized) for arbitrary scikit-learn estimators with a few-line API. The Python reference implementation in this topic’s notebook uses mapie for the §9 black-box demonstration — the same pattern carries to PyTorch and JAX models with minimal adaptation. Conformal prediction is one of the rare statistical guarantees that scales from toy datasets to industrial pipelines without changing its assumptions or its math.
The wrapping pattern also extends in directions we have only sketched. Online conformal prediction (Vovk-Gammerman-Shafer 2005, Gibbs-Candès 2021) updates the threshold as new data arrives, retaining marginal coverage even when the data stream has slow distribution drift. Conformal prediction for time series handles non-exchangeable streams via blocked or weighted variants. Conformal classification with structured output spaces (multi-label, hierarchical, set-valued) generalizes APS by redesigning the score for each setting. None of these change the five-step skeleton above; they swap the score, the calibration step, or the data assumption — and let the marginal-coverage theorem do its work.
Notation Reference
The symbols used throughout this topic, gathered for quick lookup. The “Connections” and “References & Further Reading” sections that follow are auto-generated from the topic frontmatter; the related-topics relationships expressed there are the structured form of the cross-references made inline in §1, §6, and §8.
| Symbol | Meaning |
|---|---|
| Feature–response pair, , . | |
| Calibration set size. | |
| Miscoverage level; nominal coverage is . | |
| Fitted base predictor (training data only, in the split case). | |
| Nonconformity score; large = anomalous. | |
| Calibration score at observation . | |
| Threshold: the -th smallest of . | |
| Prediction set: . | |
| Leave-one-out residual (jackknife+ / CV+). | |
| Empirical quantiles with floor/ceiling conventions (jackknife+). | |
| Conditional quantile estimates (CQR base learner). | |
| CQR nonconformity score at observation . | |
| Predicted softmax probability of class at input (APS). | |
| -th most probable class at . | |
| Rank of class in the descending probability ordering. | |
| Spiked-variance adversarial family from the Theorem 4 proof. | |
| Standard normal inverse CDF (Anderson’s lemma in Theorem 4). |
Forward Connections to Planned formalML Topics
Three topics in the T4 Nonparametric & Distribution-Free track that pick up where this one leaves off. Plain-text references — links will activate as the topics ship.
Quantile Regression — the base learner inside CQR (§6). The full topic covers QR estimation theory, the asymptotic distribution of , regularized variants (lasso, group lasso) for high dimensions, and the broader use of quantile regression beyond the conformal envelope.
Statistical Depth (coming soon) — depth-based prediction regions are the geometric alternative to the score-based conformal construction. For symmetric distributions the two routes reproduce each other; for asymmetric ones they diverge instructively, with depth regions tracking the geometric center of mass and conformal sets tracking the score quantile. The cross-fertilization runs both ways.
Prediction Intervals (coming soon) — the umbrella topic that positions conformal prediction inside the broader prediction-interval ecosystem (frequentist plug-in, Bayesian posterior predictive, quantile-regression direct, conformal). Each route has different assumptions and different asymptotic properties; the comparative table is the topic’s central contribution.
Connections
- Concentration is the standard tool for bounding empirical-quantile fluctuation; conformal uses rank symmetry instead, which delivers an exact (not asymptotic) finite-sample statement. The contrast is instructive — concentration gives uniform asymptotic bounds, conformal gives marginal exact bounds. concentration-inequalities
- Calibration scores function as low-dimensional summaries of prediction error; the leave-one-out updates underlying jackknife+ are formally analogous to LOO covariance updates in low-rank settings. pca-low-rank
- Exchangeability — the only assumption conformal prediction requires — is a measure-theoretic invariance under coordinate permutation, strictly weaker than iid sampling. de Finetti's representation theorem describes the structure of exchangeable sequences. measure-theoretic-probability
- PAC bounds give *learning* guarantees (low expected loss) under iid assumptions; conformal gives *coverage* guarantees under exchangeability. The two operate on orthogonal axes — predictability versus uncertainty — and the choice of which to use depends on whether the downstream task cares about average error or per-prediction reliability. pac-learning
- Theorem 1 of this topic (split-conformal marginal coverage) is cited verbatim there in §2 and reused in §5.1's CQR-coverage-decomposition proof. The score-function abstraction in §2.1 of prediction-intervals lifts directly from the conformal frame; CQR is just split conformal under a quantile-regression score with the conformal $(1-\alpha)$-quantile threshold. prediction-intervals
- T4 track closer. Depth-based conformal prediction sets achieve marginal coverage with shapes that adapt to the residual distribution's geometry, replacing componentwise quantile rankings with depth-induced rankings of multivariate scores. The split-conformal marginal-coverage theorem here transfers verbatim to the depth-as-score regime. statistical-depth
References & Further Reading
- book Algorithmic Learning in a Random World — Vovk, Gammerman & Shafer (2005) The book that systematized conformal prediction. Definitive reference for the full / transductive variant.
- paper Distribution-free predictive inference for regression — Lei, G'Sell, Rinaldo, Tibshirani & Wasserman (2018) The marginal-coverage theorem (Theorem 1) and split conformal as the modern default.
- paper Conformalized quantile regression — Romano, Patterson & Candès (2019) CQR — locally adaptive prediction intervals via a quantile-regression base learner (NeurIPS 2019).
- paper Classification with valid and adaptive coverage — Romano, Sesia & Candès (2020) APS for classification with approximate conditional coverage (NeurIPS 2020).
- paper Predictive inference with the jackknife+ — Foygel Barber, Candès, Ramdas & Tibshirani (2021) Jackknife+ and CV+ — leave-one-out conformal with the $1 - 2\alpha$ coverage bound (Theorem 2).
- paper The limits of distribution-free conditional predictive inference — Foygel Barber, Candès, Ramdas & Tibshirani (2021) Conditional-coverage impossibility (Theorem 4).
- paper Conformal prediction under covariate shift — Tibshirani, Foygel Barber, Candès & Ramdas (2019) Importance-weighted conformal for known covariate shift (NeurIPS 2019) — the extension powering the ExchangeabilityBreakdown viz.
- paper Conditional validity of inductive conformal predictors — Vovk (2012) Original conditional-coverage impossibility statement; Theorem 4 here generalizes it.
- paper Distributional conformal prediction — Chernozhukov, Wüthrich & Zhu (2021) Conformal prediction extended to full conditional CDF inference (PNAS 2021).