Statistical Depth
Multivariate centrality scores — Tukey halfspace depth, the zoo of alternatives, asymptotic theory and NP-hardness, and ML applications via DD-classification, depth-based outlier detection, and functional depth
Overview
Statistical depth assigns each point in a centrality score with respect to an empirical or population distribution, generalizing the median, quantile, and rank to dimensions where ordering is no longer well defined. The Tukey halfspace depth — the canonical construction — measures how surrounded a point is by the data: it is the smallest fraction of the sample on either side of any hyperplane through that point. Depth functions package multivariate location, spread, and outlyingness into a single object that obeys a clean axiomatic specification (Zuo and Serfling 2000), supports robust median estimation with breakdown (Donoho and Gasko 1992), and underwrites a small zoo of multivariate ML tools — the DD-classifier, depth-based outlier detection, and functional depth for curves and time series.
The topic structure: motivation and the Zuo–Serfling axioms (§1), Tukey halfspace depth as the canonical depth function (§2), a comparative survey of Mahalanobis, simplicial, projection, and spatial depths (§3), the asymptotic theory and computational complexity of Tukey depth (§4), ML applications via DD-classification, outlier detection, and functional depth (§5), and connections plus honest limits (§6).
The reader is assumed to be comfortable with measure-theoretic probability, weak convergence, and the basic vocabulary of convex geometry — halfspaces, supporting hyperplanes, convex hulls, simplices. Empirical-process limit theorems make a cameo in §4 and are sketched rather than developed from scratch.
This topic closes the T4 Nonparametric & Distribution-Free track. Where the other six T4 topics — Conformal Prediction, Quantile Regression, Rank Tests, Prediction Intervals, Extreme Value Theory, and the univariate machinery they share — operate one variable at a time, statistical depth is what those topics look like in when there is no canonical order on the sample space.
1. From quantile to depth
In one dimension a sample has an unambiguous middle. The median of minimizes , splits the sample into halves, and is the level- value of the empirical quantile function . The empirical CDF orders the sample, the quantile function inverts that order, and rank-based machinery — Wilcoxon tests, sign tests, prediction intervals built from order statistics — drops out. All of it rests on the fact that is totally ordered.
In for that order is gone. There is no canonical way to say which of two points comes “before” the other; the natural componentwise partial order leaves most pairs incomparable, and the obvious workarounds — the componentwise median, the Mahalanobis-distance “center,” the geometric median — each capture some aspect of multivariate centrality but disagree on most samples and behave badly under affine reparametrization. The question “which point in this 2D cloud is most central?” has several reasonable answers, and which one is correct depends on what we want centrality to do.
A depth function is the answer that asks what we want first and derives the construction second. It assigns each point a real number — the depth of with respect to a distribution — large when sits in the bulk of and small when is near the edge or far outside. The depth function is then a multivariate centrality score, and the deepest point is the multivariate median.
1.1 Why componentwise quantiles fail
The fastest way to feel the gap is to try the obvious fix. Given a 2D sample, take the median of the first coordinate and the median of the second coordinate; call the resulting point the componentwise median. The construction is fast, well-defined, and almost always wrong for what we mean by “the center of the cloud.”
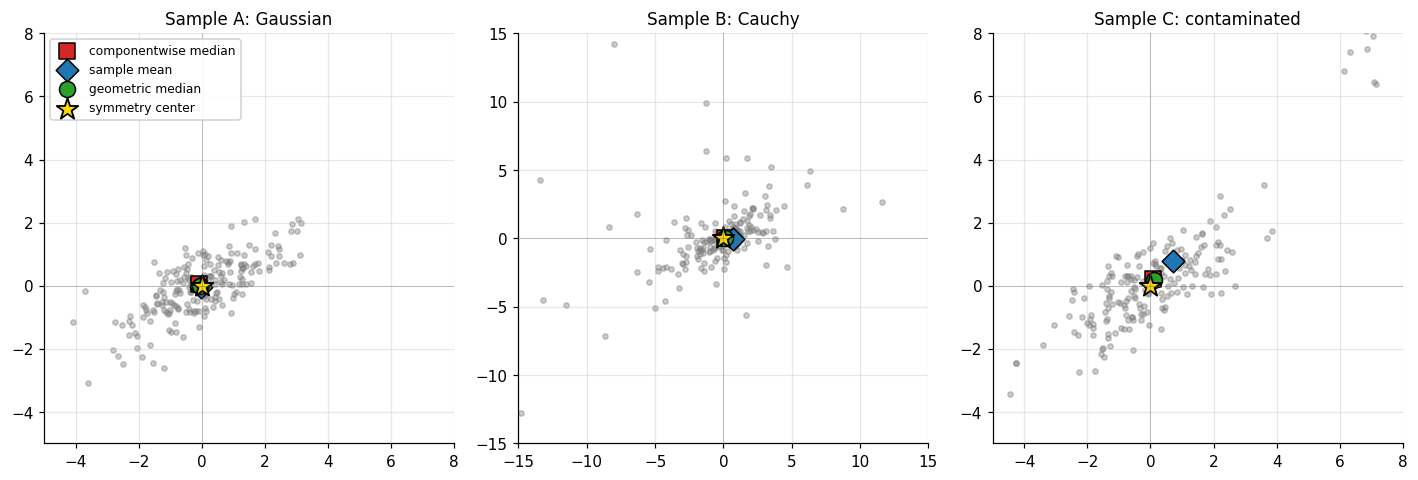
Two failures appear immediately. The first is affine non-equivariance: rotate the sample by and the componentwise median moves as a function of the rotation, not as the rotated original median. The “center” depends on the choice of axes, which is exactly what we do not want for a notion that ought to track the geometry of the cloud rather than the bookkeeping of its representation. The second is lack of fit to non-axis-aligned bulk: when the sample concentrates along a tilted ellipse, the componentwise median can lie outside the bulk entirely, because the marginal medians know nothing about the off-diagonal correlation. The geometric median (Fréchet 1948) — the minimizer of — fixes affine equivariance on rigid motions but still depends on the choice of norm and is not equivariant under arbitrary affine maps.
The mean and the Mahalanobis center handle affine equivariance correctly but inherit moment assumptions: the mean fails outright on heavy-tailed data, and the Mahalanobis center is anchored to the sample covariance, which has breakdown point — a single far outlier can drag the “center” anywhere we like.
What we want from multivariate centrality is a single function that (i) does not care about the choice of axes, (ii) puts the maximum at something that looks geometrically central regardless of the parametric family, (iii) decreases monotonically as we move away from that maximum, and (iv) does not let one or two outliers redefine where the bulk is. Listing those four desiderata is the Zuo–Serfling axiomatization.
1.2 What we want from a depth function
We pause to fix notation. Throughout this topic, denotes a probability distribution on , a random vector with that distribution, and an iid sample from with empirical distribution . Affine transformations for nonsingular and are denoted ; the pushforward of under is written , the distribution of .
A depth function is a map , written , that takes a point and a distribution and returns a non-negative real number. The reading is: measures how central is with respect to , with larger values meaning more central. Several depth functions in §3 take values in ; the unit-interval normalization is conventional but not part of the definition.
The deepest point of is any maximizer
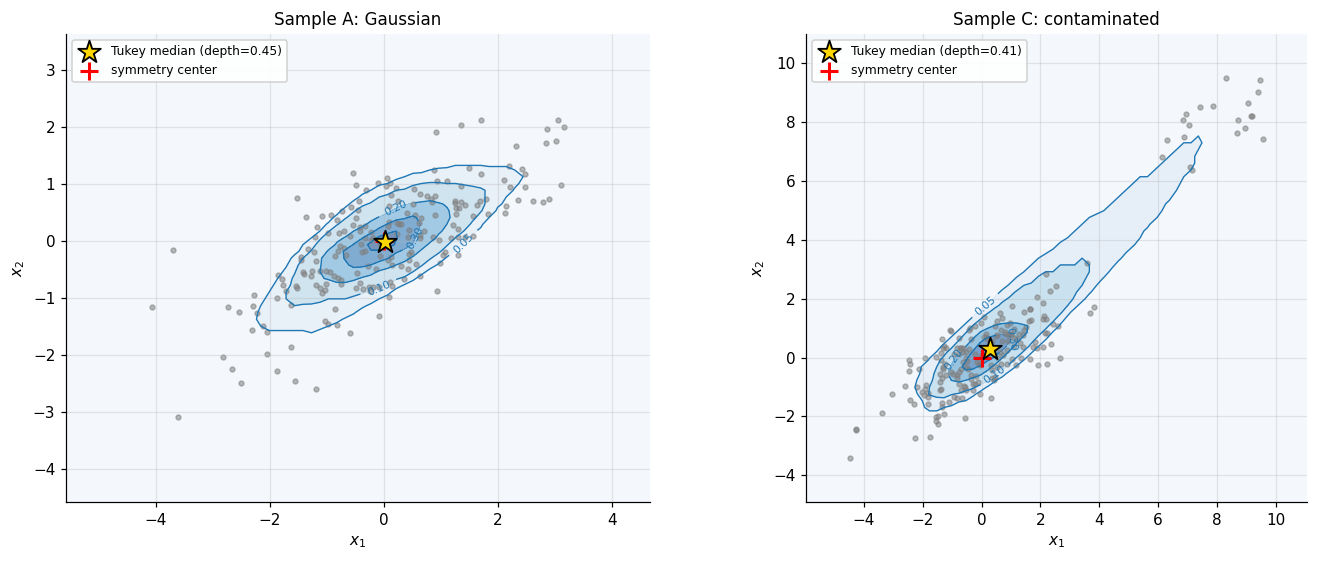
For most depth functions is uniquely determined when has a density, but it is generally a set when is empirical — we will see in §2 that the empirical Tukey median is a region, not a point, and a tie-breaking rule (typically the centroid of that region) returns a single estimate.
The depth contour at level is the upper level set
For halfspace depth these contours are nested closed convex sets indexed by ; they form the multivariate analogue of confidence regions or quantile curves.
1.3 The Zuo–Serfling axioms
Zuo and Serfling (2000) formalize what a depth function ought to do via four axioms that together pick out a flexible but well-disciplined class. We state the axioms first, then motivate each one against the failure modes of §1.1.
Definition 1 (Zuo–Serfling depth function).
A map is a statistical depth function if it satisfies, for every admitting a unique deepest point :
(D1) Affine invariance. For every nonsingular , every , and every ,
(D2) Maximality at the center. If is centrally symmetric about — that is, — then , and the supremum is attained uniquely at .
(D3) Monotonicity along rays from the deepest point. For every and every , the function is non-increasing on .
(D4) Vanishing at infinity. as .
The motivation for each axiom matches one of §1.1’s pain points. (D1) removes the dependence on the choice of axes. (D2) anchors the depth function to a geometric notion of “center” whenever one exists unambiguously. (D3) says depth respects the geometry of “moving outward.” (D4) rules out the pathology where a depth function fails to distinguish “very far away” from “merely far away” — a regularity condition mostly used to guarantee that maxima exist.
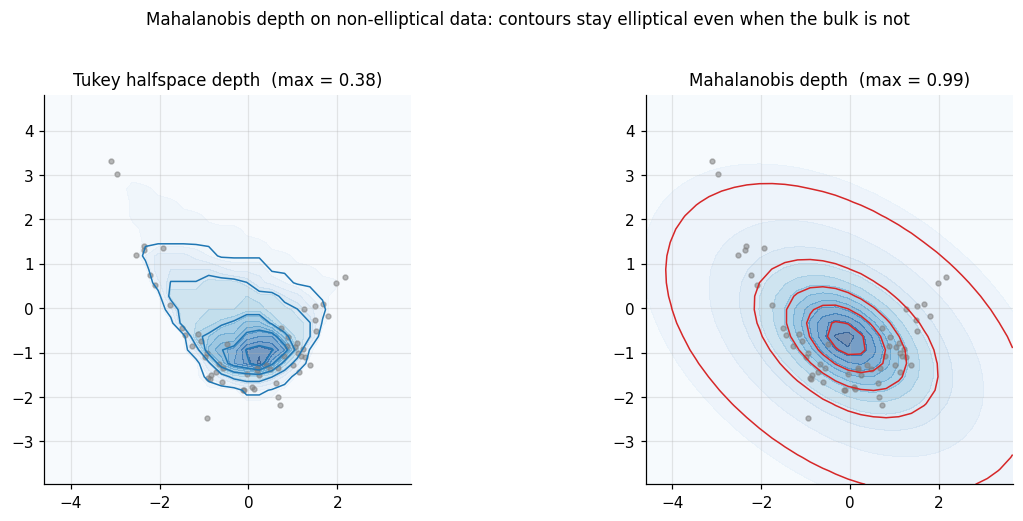
The axioms are not independent — (D2) and (D3) interact through the choice of “center” — and in the literature several authors propose weaker variants. For this topic we adopt Zuo and Serfling’s original four. Each depth function in §3 will be checked against the axioms; one of them, Mahalanobis depth, will fail (D1) in spirit on non-elliptical distributions, and the failure is exactly visible in the side-by-side panel.
1.4 Running examples
Three samples thread §§1–6.
Sample A — bivariate Gaussian. with
This is the canonical exemplar: an elliptical distribution where every depth function in §3 satisfies the axioms and contours are nested ellipses. The deepest point is the origin; depth contours are concentric tilted ellipses oriented along the leading eigenvector of .
Sample B — bivariate Cauchy. Same scale matrix as Sample A. The Cauchy has no mean and no covariance, so the sample mean and Mahalanobis center are unstable — but Tukey, simplicial, and projection depth still produce well-behaved contours, and the deepest point is still the origin (now interpreted as the symmetry center rather than the mean).
Sample C — contaminated Gaussian. A mixture, with . Depth functions with high breakdown (Tukey, simplicial, projection) keep the deepest point near regardless of contamination; depth functions anchored to moments (Mahalanobis on the empirical covariance) drift toward the contamination cluster.
The figure below shows all three samples side by side together with three reasonable-looking but disagreeing notions of “center”: the componentwise median, the sample mean, and the geometric median (the minimizer of via Weiszfeld’s iteration). On the Gaussian they roughly agree; on the Cauchy the mean is unstable; on the contaminated sample they disagree by a meaningful amount and none of them is obviously right. The §2 Tukey median, by contrast, will sit near the origin in all three panels.
2. Tukey halfspace depth
Tukey (1975) proposed the construction that defines the canonical multivariate centrality score. The idea is geometric: for a point to be deep, every line through should split the sample roughly in half; a point near the boundary of the cloud, by contrast, has at least one line through it that puts almost all of the sample on one side. The minimum count over all such lines — equivalently, all halfspaces with on their boundary — is the halfspace depth.
2.1 Definition
Recall a closed halfspace in is a set of the form
where is the unit sphere. The boundary hyperplane is .
Definition 2 (Population Tukey halfspace depth).
Let be a probability distribution on and . The halfspace depth of with respect to is
where the infimum runs over all closed halfspaces that contain .
Equivalently, every closed halfspace containing has the form with . The worst case (smallest -mass) is achieved by halfspaces whose boundary passes exactly through , so the infimum reduces to
The reading is direct: pick any direction , slide a hyperplane through orthogonal to , and count the -probability on the -side. Halfspace depth is the worst (smallest) such fraction.
Definition 3 (Empirical Tukey halfspace depth).
Let be a sample from with empirical distribution . The empirical halfspace depth of is
The unit-interval normalization is conventional: . The maximum possible value is bounded by in for any with no atom at (one can always find a hyperplane through that puts at most half the mass on either side), and the upper bound is achieved only at the halfspace median — defined in §2.4.
A worked example fixes ideas. Consider four points in at the corners of a unit square, , and the query point . Every line through either passes through two opposite corners — in which case those corners lie on the boundary, included in the closed halfspace, and the closed halfspace contains all four points on one side — or strictly separates two corners from two corners. The minimum closed-halfspace count is , so . By contrast, the corner has (only one of the four points lies in the halfspace ), and any point outside the square has .
2.2 Verifying the Zuo–Serfling axioms
Halfspace depth was the prototype Zuo and Serfling had in mind when they wrote down the four axioms; verification is short and clean.
Theorem 1 (HD is a Zuo–Serfling depth function).
Tukey halfspace depth satisfies the four Zuo–Serfling axioms (D1)–(D4).
Proof.
(D1) Affine invariance. Let be nonsingular and . The pushforward is the distribution of . A closed halfspace containing has the form with ; pulling back under ,
So pulls back to a halfspace with normal (rescaled to unit length, which only multiplies by a positive scalar) containing . The map is a bijection of , so the infimum of -mass over halfspaces containing equals the infimum of -mass over halfspaces containing . Hence .
(D2) Maximality at the symmetry center. Suppose is centrally symmetric about , i.e., . For any unit direction ,
The two probabilities sum to , so each is at least . Therefore .
For any , take — the unit direction away from the center. Then
By symmetry the distribution of is symmetric about , so the right-hand probability is at most and is strictly less than whenever the corresponding marginal CDF is continuous at . Under the standard regularity assumption (say, has a density), the strict inequality holds for every , so , with strict inequality. The supremum is uniquely attained at .
(D3) Monotonicity along rays. Fix any deepest point of and any direction . We must show is non-increasing on .
For each unit direction , consider the function
For each , is non-increasing in on the set where (the threshold rises as grows) and non-decreasing on the set where . By symmetry between and (the infimum over is the same as the infimum over ), it suffices to take the infimum over with , on which set every is non-increasing in . The infimum of non-increasing functions is non-increasing, so is non-increasing on .
(D4) Vanishing at infinity. Take any unit direction . As with , the probability because . Hence .
∎So Tukey halfspace depth is a Zuo–Serfling depth function — the construction satisfies the entire axiomatic specification. The proofs above used only the closed-halfspace formulation; the same argument works for the empirical version with in place of .
2.3 The Tukey median and contour convexity
The Tukey median of is any maximizer of :
For populations with a density and central symmetry, the proof of (D2) shows uniquely. For the empirical distribution , the maximizer is generally a region, not a point: the level set at the maximum depth is a non-empty closed convex set, and the conventional point estimator is its centroid.
The convexity comes from a structural fact about depth contours.
Proposition 1 (Convexity of halfspace depth contours).
For any and any , the upper level set
is closed and convex.
Proof.
Let and . Set . For any closed halfspace with , write with . Either or — otherwise is a convex combination of two values both less than , contradiction. So at least one of lies in , and
Taking the infimum over gives , so . Closedness follows because is upper semicontinuous (the infimum of continuous functions of ).
∎The depth contours are closed convex sets nested by depth level, and the Tukey median is the deepest such set. This convexity property is what makes halfspace depth particularly useful for constructing multivariate confidence regions.
2.4 Computing 2D Tukey depth
Computing in requires evaluating an infimum over the unit sphere . In 2D this infimum reduces to a search over the angular bearings of the data points relative to , and there is an exact algorithm — the rotating-halfplane sweep (Rousseeuw and Ruts 1996).
Algorithm (Rousseeuw–Ruts, sketch). Let . Compute angles for each non-coincident . Sort the angles. The closed halfplane through with normal at angle contains exactly the points whose angles fall in . As sweeps through , the count changes only when crosses one of the or one of the markers; the minimum over all sweep positions, plus the count of points coincident with (which lie on every halfplane boundary), is the depth count. The whole computation is dominated by the sort, .
The companion algorithm in is more involved: exact computation reduces to enumerating all hyperplanes through the query point and data points, an operation. Aloupis (2006) shows that exact computation of the depth at a single point — without requiring the full enumeration — is NP-hard when is part of the input. We return to that result in §4.4.
2.5 Depth contours
With the 2D algorithm in hand we can plot depth contours as a function of . For Sample A the contours are nested and roughly concentric ellipses, oriented along the leading eigenvector of , with the maximum depth attained near the origin at value . For Sample C the contamination cluster does not redirect the contours: the deepest region remains near the origin, the outliers register only as a small bump on the outer (low-) contours. This is the visual demonstration that halfspace depth has high breakdown — a quantitative argument follows in §4.2.
The interactive widget below recomputes contours on the fly. Switch the sample selector to compare A, B, C; drag the pink crosshair to read live depth at any query point; raise the grid resolution for a sharper picture (at the cost of more depth queries per redraw).
iid bivariate Gaussian; all four §1 centres agree near the origin.
★ marks the empirical Tukey median (centroid of the deepest grid cell). Drag the pink crosshair to read depth at any query point. Grid resolution trades accuracy against wait time — gridSize² Tukey-depth queries per redraw.
3. A zoo of depth functions
Tukey halfspace depth is canonical but not unique. Several other constructions satisfy the Zuo–Serfling axioms, each making different tradeoffs along three axes the §2 algorithm exposed: how fast the depth is to compute, how strongly the depth depends on parametric model assumptions, and how the depth scales with dimension. We catalogue four of the most useful — Mahalanobis, simplicial, projection, and spatial depth — verify the relevant axioms, and put the contours side by side on a common sample.
3.1 Mahalanobis depth
The fastest depth function — closed-form, requiring only a matrix inverse — is the one anchored to the first two moments.
Definition 4 (Mahalanobis depth).
For a distribution with mean and positive-definite covariance , the Mahalanobis depth of is
The empirical version uses the sample mean and sample covariance: .
Mahalanobis depth satisfies (D1)–(D4): the affine-invariance proof is one line, since under the mean shifts to , the covariance shifts to , and the quadratic form is preserved exactly. The maximum is attained at with value ; monotonicity along rays is the convexity of quadratic forms; vanishing at infinity is automatic.
The catch is what maximum it produces. The of Mahalanobis depth is the mean, not the symmetry center. For a centrally symmetric with finite covariance the two coincide, so (D2) holds. For a non-elliptical — say, a banana-shaped distribution — Mahalanobis depth still produces ellipsoidal contours centered at the mean, even when the actual bulk of is far from elliptical. The depth is not wrong in the axiomatic sense; it is committed to the parametric ellipsoid, and any deviation from that model leaks straight into the depth contours. The breakdown is also the breakdown of the sample covariance: zero. A single far outlier moves enough that tilts toward the outlier, and the deepest point drifts.
3.2 Simplicial depth
Liu (1988, 1990) proposed a depth function defined entirely in terms of the convex-hull geometry of random simplices.
Definition 5 (Simplicial depth).
For a distribution on , the simplicial depth of is
where are iid from and denotes the closed convex hull (here a -simplex with probability when has a density).
The empirical version is a U-statistic of order :
The U-statistic structure is exactly what Liu’s result exploits: the kernel is symmetric, bounded, and has expectation . Standard U-statistic theory (Hoeffding 1948) gives consistency, asymptotic normality, and explicit variance formulas for .
Theorem 2 (Liu 1990 — simplicial depth axioms).
satisfies (D1)–(D4) for every absolutely continuous .
Proof.
(Sketch.) (D1) Affine invariance follows because affine maps preserve convex-hull membership: if is nonsingular, if and only if . The pushforward simplex has the same indicator, so the expectations match. (D2) For centrally symmetric at the symmetry center , take and apply the Bárány–Kalai random-simplex argument: the probability that the simplex contains exceeds the probability that it contains any other point, with strict inequality under the density assumption. (D3) The probability is non-increasing as moves outward from the deepest point because the convex-hull membership constraint becomes more restrictive. (D4) For , the probability that an iid -simplex contains vanishes by tail-decay of . Full details in Liu (1990), Theorem 1.
∎Simplicial depth is fully nonparametric (no moment assumptions), affine invariant, and satisfies a clean U-statistic-based asymptotic theory. Its computational cost, however, is severe in high dimensions: the U-statistic of order has terms, and even in 2D this is point-in-triangle tests per query.
3.3 Projection depth
Random projections give a depth function that scales gracefully with dimension at the cost of trading exactness for a Monte-Carlo approximation.
Definition 6 (Projection depth).
For a distribution on , define the outlyingness of as
where is the univariate median and is the median absolute deviation. The projection depth is
The reading: project onto direction to get the univariate distribution of . Compute the standardized univariate distance from to the projected median. Take the supremum over directions. The deepest point in is the one whose projected position is closest to the projected median in every direction — the multivariate generalization of “the median of every projection.”
In practice, the supremum over is approximated by sampling random unit directions and taking the maximum:
The cost is per query — linear in dimension and trivially parallel. Projection depth satisfies (D1)–(D4): affine invariance follows because the median and MAD are univariate-affine equivariant, and the supremum over pulls back the same way Tukey’s does. The approximation holds at every fixed by the strong law applied to the supremum over a uniform sample on the sphere; the error is uniformly on a compact set.
3.4 Spatial depth
Spatial depth (Vardi and Zhang 2000; Serfling 2002) replaces the sup-over-directions structure of projection depth with an optimality criterion.
Definition 7 (Spatial depth).
For a distribution on with no atom at ,
The empirical version uses the sample mean of the unit-direction vectors. The geometric reading is clean. Each contributes a unit vector pointing from toward . If sits at the geometric median of the sample, the unit vectors balance: their average is close to , so . If sits on the periphery, all the unit vectors point roughly the same way, the average has large norm, and . The deepest point is the spatial median, which coincides with the Fréchet geometric median.
Spatial depth is affine equivariant only under orthogonal transformations — it depends on the choice of norm via the unit-direction normalization. For elliptically distributed data, this matters less than one might expect, because all relevant comparisons are in . The cost is per query, the cheapest of the four after Mahalanobis.
3.5 Side-by-side comparison
All four depth functions evaluated on Sample A produce qualitatively similar contour pictures — nested, roughly elliptical, peaked near the origin. The differences appear in (a) the rate at which contours decay outward, (b) sensitivity to contamination, and (c) whether the contour shape can deviate from an ellipse when the underlying distribution does. The five-panel figure below shows the contours on a common Gaussian sample.
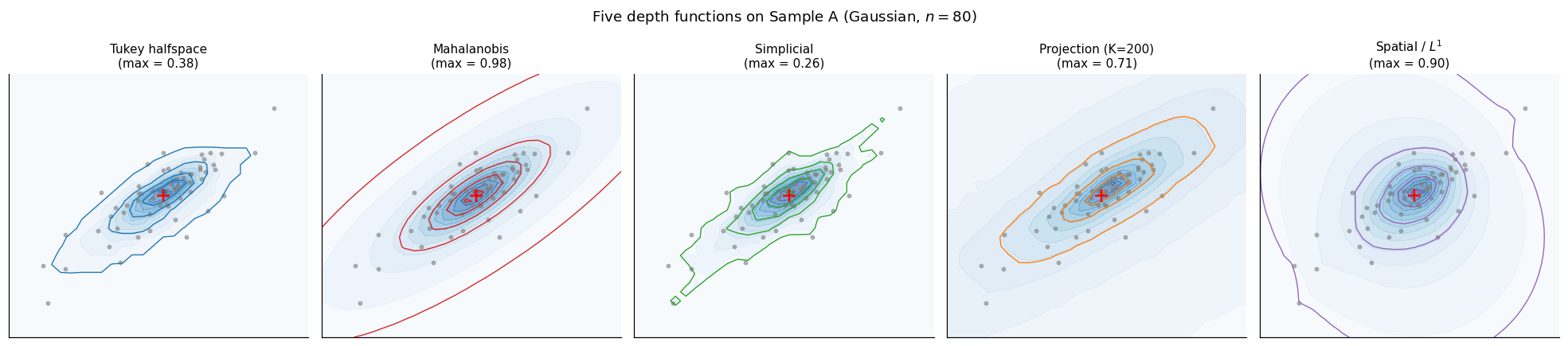
The interesting failure mode appears on non-elliptical data, where Mahalanobis depth’s commitment to the ellipsoid model leaks into the contours and produces depth structure that does not track the actual density of the sample.
The interactive comparison below lets you switch the sample (Gaussian / banana) and the right-hand depth function. The left panel always shows Tukey halfspace as the affine-invariant canonical reference. The simplicial branch is capped at ; for -direction projection depth, the inline approximation runs at .
Gaussian (Σ tilted) · n = 60
On Gaussian data all five depths produce nearly affine images of one another — the elliptical bulk doesn't punish any choice. On the banana sample, Mahalanobis depth's elliptical commitment shows: contours stay aligned with the sample covariance even though the bulk bends. Tukey halfspace depth tracks the bend; the others vary.
4. Theory and computation
The §§2–3 implementations would be of limited value without theoretical guarantees that the empirical depth converges to its population counterpart, that the Tukey median is robust in a quantifiable sense, and that the asymptotic behaviour of empirical depth has a known limit law. This section assembles those guarantees and pairs each with its computational counterpart.
4.1 Consistency
Halfspace depth at a fixed point is consistent under minimal assumptions on .
Theorem 3 (Donoho–Gasko consistency).
Let be a probability distribution on that assigns mass zero to every hyperplane. Then for every ,
Proof.
Fix . Define the class of closed halfspaces with on the boundary,
By definition and .
The class has finite Vapnik–Chervonenkis dimension at most — it is a sub-class of the VC class of all closed halfspaces, which has VC dimension . By the Vapnik–Chervonenkis theorem (Glivenko–Cantelli for classes of finite VC dimension),
The sup-norm convergence transfers to the infimum: , so
The hyperplane-zero-mass assumption is needed only to handle boundary ties: without it, individual points on the boundary hyperplane could destabilize as grows. Under the hyperplane-zero-mass assumption, the closed-halfspace count converges to at every uniformly.
∎The same argument gives consistency for projection depth (with the additional assumption that the population MAD is bounded away from ), spatial depth (with no atom at ), and Mahalanobis depth (under the additional finite-second-moment condition the definition requires).
4.2 Breakdown of the Tukey median
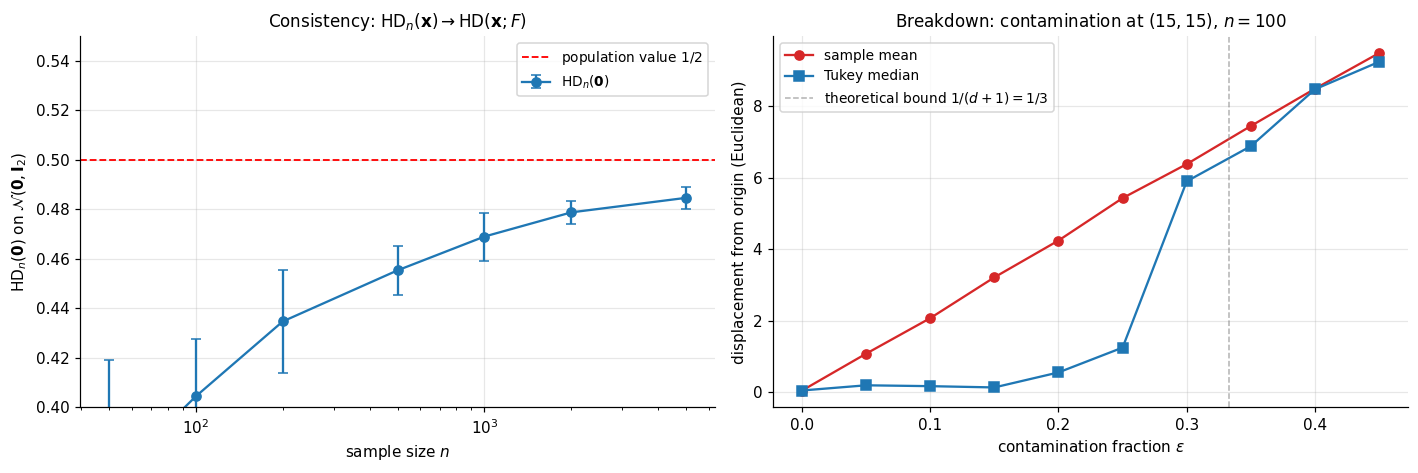
The Tukey median’s breakdown point — the smallest fraction of contamination that can move it arbitrarily far — gives a quantitative version of the §2.5 contour-stability picture.
Theorem 4 (Donoho–Gasko 1992 breakdown bound).
Let be in general position in . The finite-sample breakdown point of the Tukey median is
Proof.
(Sketch.) For any contamination scheme that replaces original points with arbitrary , the contaminated empirical halfspace depth at any point that was originally deep — say with depth on the clean sample — satisfies
The maximal clean-sample depth is at most but at least (by a packing argument: in general position, every points form a simplex, and any point inside the convex hull of the data has depth at least proportion-of-simplices-containing-it). Setting , the bound gives that the deepest point of the contaminated sample has depth at least , which remains positive — and hence located in a bounded region — as long as . Therefore . Full details: Donoho and Gasko (1992), Theorem 3.1.
∎In the bound gives , comfortably above the breakdown of the sample mean.
4.3 Asymptotic distribution
Pointwise convergence (Theorem 3) is the consistency baseline. The next question is the rate.
Theorem 5 (Massé 2004 — asymptotic normality).
Let have a continuously differentiable density on that is bounded away from zero on every compact set. Fix at which the infimum defining is attained at a unique direction . Then
where .
Proof.
(Sketch in three steps.)
Step 1 — Hadamard differentiability of the depth functional. Define by , where is the space of distribution functions on equipped with the Kolmogorov sup-norm. Under the unique-minimizer assumption, the envelope theorem (a finite-dimensional version of Danskin’s theorem applied to the parametrization ) gives that is Hadamard-differentiable at in the direction with derivative
where is interpreted as a signed measure and is its mass on the optimal halfspace.
Step 2 — Functional CLT for the empirical process. By Donsker’s theorem applied to the VC class of halfspaces, converges in distribution (in the space of bounded functions on ) to a Gaussian process with covariance kernel .
Step 3 — Functional delta method. Combining Steps 1 and 2,
The right-hand side is where ; recognizing closes the proof.
∎The unique-minimizer assumption is essential: at points where the depth-defining infimum is attained at a set of directions (e.g., a centrally symmetric distribution at its center, where every direction attains ), the Hadamard-differentiability argument fails and the limit distribution becomes the supremum of a Gaussian process over the optimal-direction set.
4.4 Computational complexity
The §2 sweep gave for one query in 2D. The general- exact algorithm scales much worse.
Theorem 6 (Aloupis 2006).
Computing exactly is NP-hard in when is part of the input.
The result is stated and not proved here — the proof is a reduction from the maximum-bisection problem and requires a separate combinatorial-geometry treatment. The practical consequence is decisive: exact computation of halfspace depth is restricted to fixed low dimension. The exact algorithm via hyperplane enumeration is feasible for (where it is ) and only marginally feasible for at moderate . For the practitioner must fall back on the random-direction approximation .
4.5 Projection-depth approximation efficacy
How accurate is the random-direction approximation as a function of ? The §3.3 analysis gave with error . The same bound applies to the random-direction approximation of halfspace depth itself, since both are infimum-over-the-sphere objects. In practice is sufficient for sub-percent error on moderately concentrated samples.
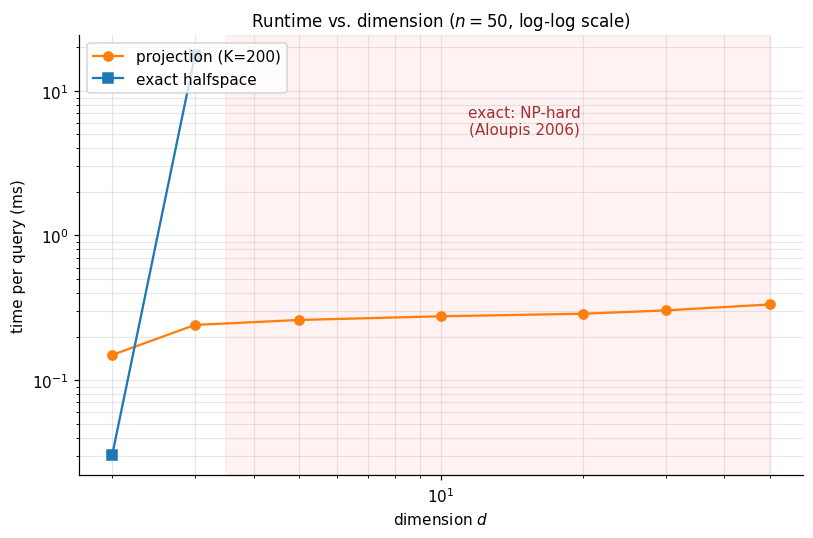
The widget below re-runs the benchmark live. Slide to see the projection-depth time scale linearly in directions; slide to see both methods scale at their predicted rates.
Per-query timing in milliseconds. Exact halfspace runs only at d ∈ {2, 3} per the §4.4 NP-hardness result.
Projection depth's roughly flat curve in d (cost is O(K · n), independent of dimension after the projection step) is the punchline of §4.5: in practice, the only depth that scales is the approximate one. Increasing K trades accuracy for cost — the random-direction approximation has Op(√(log K / K)) error.
5. ML applications
The depth machinery of §§2–4 was developed without reference to a specific ML problem, but it slots cleanly into three: nonparametric classification through the DD-plot, multivariate outlier detection that does not assume ellipticity, and analysis of functional data — random samples in which each observation is a curve rather than a vector.
5.1 The DD-classifier
The depth-versus-depth plot, or DD-plot, is the depth-based analogue of a Q–Q plot for two distributions. Given samples from a putative class- distribution and from class , every point has two depths:
Plotting the pair for each training point in produces the DD-plot — a low-dimensional summary of how the two classes’ depth structures compare, regardless of the dimension of the original data.
Definition 8 (DD-classifier).
Let be a depth function. Given training samples for classes and with size-balancing weights, the DD-classifier assigns a new query point to class iff
(with ties broken by a convention).
The classifier’s decision boundary in the original feature space corresponds to the line in the DD-plot. When the two depth structures are well-separated, classes appear as distinct clusters in the DD-plot, and the diagonal is a competent decision rule.
Theorem 7 (Li, Cuesta-Albertos & Liu 2012).
Suppose the two classes have densities that are unimodal and elliptically symmetric about distinct centers, with . The Bayes-optimal classifier is equivalent to the DD-classifier iff the densities are depth-calibrated: is a strictly monotone function of .
This depth-calibration condition holds for halfspace depth on Gaussians (where depth is monotone in Mahalanobis distance, hence in density). The implication: when the elliptical-symmetry assumption is reasonable, the DD-classifier is essentially Bayes-optimal without ever fitting a parametric model — only the empirical depth function is needed. The implementation below computes a DD-plot for the harder Iris pair (Versicolor vs. Virginica) using halfspace depth on the petal-length × petal-width subspace.
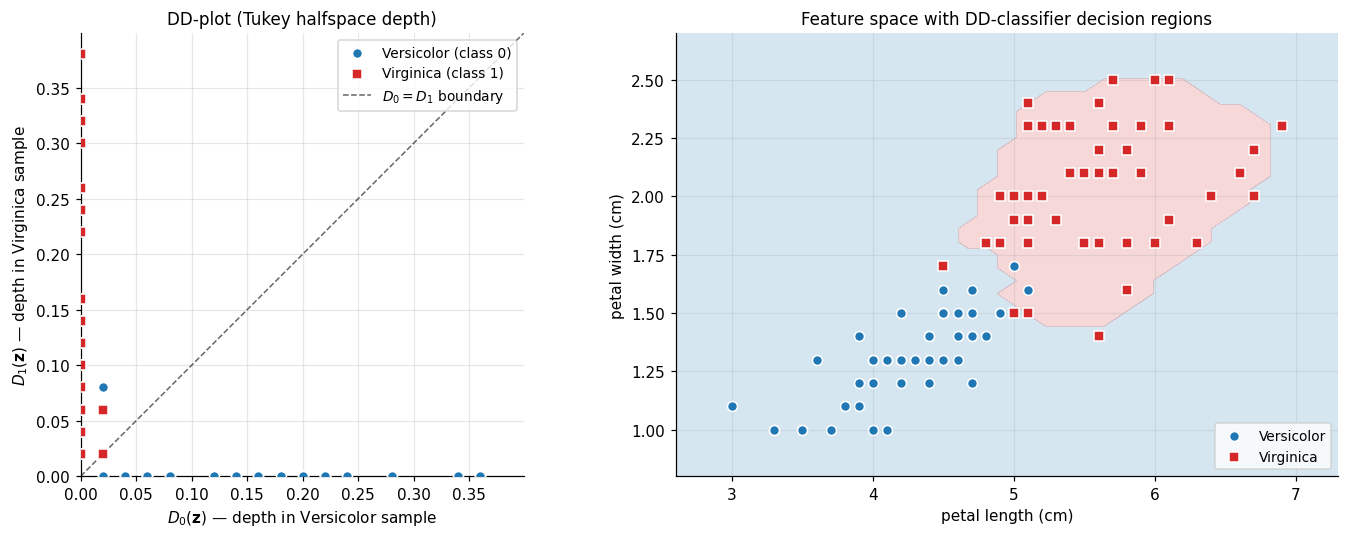
The widget below reproduces both views with the live training-accuracy readout. Toggle DD-plot ↔ feature space.
In the DD-plot, the diagonal D₀ = D₁ is the decision boundary. Points above the line are classified as Virginica; points below as Versicolor. The two clusters separate cleanly because the Iris petal subspace is nearly linearly separable.
5.2 Multivariate outlier detection
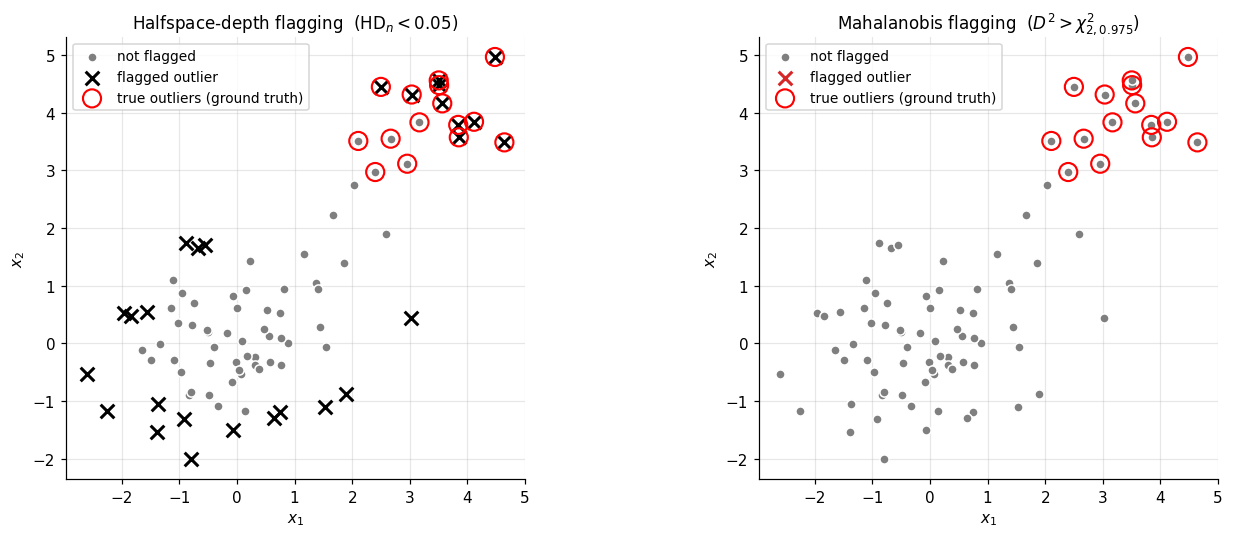
A multivariate outlier is a point that is far from the bulk of a distribution in a sense that respects the bulk’s shape. Mahalanobis distance is the standard tool, but it commits to ellipticity (§3.1). Depth-based outlier detection inverts the problem: outliers are the points with low depth.
Definition 9 (Depth-based outlier rule).
Fix a depth function and a threshold . A point is flagged as an outlier with respect to if
The threshold tunes the rule’s strictness. The most aggressive choice is , which flags only convex-hull boundary points; this catches isolated outliers but misses any contamination cluster dense enough to form its own convex region. A more useful default is a fixed in the – range, calibrated either to a clean reference distribution or to the desired fraction of training points one is willing to flag.
A subtle but important property of depth-based outlier rules: they are not fooled by masking — the failure mode where multiple co-located outliers raise their own neighborhood density, inflate the sample covariance toward the contamination direction, and thereby pull their own Mahalanobis distances below the cutoff. Depth-based rules see through masking partially, because the convex-hull and projection structures that define depth do not get pulled toward dense regions of contamination — a contamination cluster of points can lower the halfspace depth of any point near the bulk by at most , regardless of how the cluster is arranged. The honest caveat: when the contamination cluster is dense enough to form its own convex region of significant volume, depth-based flagging can still miss outliers inside that region (they are deep with respect to the cluster, even if shallow with respect to the bulk), and false positives accumulate in the clean bulk’s outer rim.
5.3 Functional depth
A functional dataset is a sample of curves , each a function on a common index set . The natural depth analogue is band depth — defined by how often a curve lies between bands generated by other sample curves.
Definition 10 (Band depth (López-Pintado–Romo 2009)).
Let be sample curves on . For an integer define the band of curves as
The band depth of a curve is
The modified band depth relaxes the indicator to the fraction of on which the inclusion holds:
Band depth and modified band depth share the §1.3 axiomatic structure (with appropriate substitutions for functional spaces) and provide center-outward orderings of curves: the deepest curve is the functional median, the most central curve in the sample.
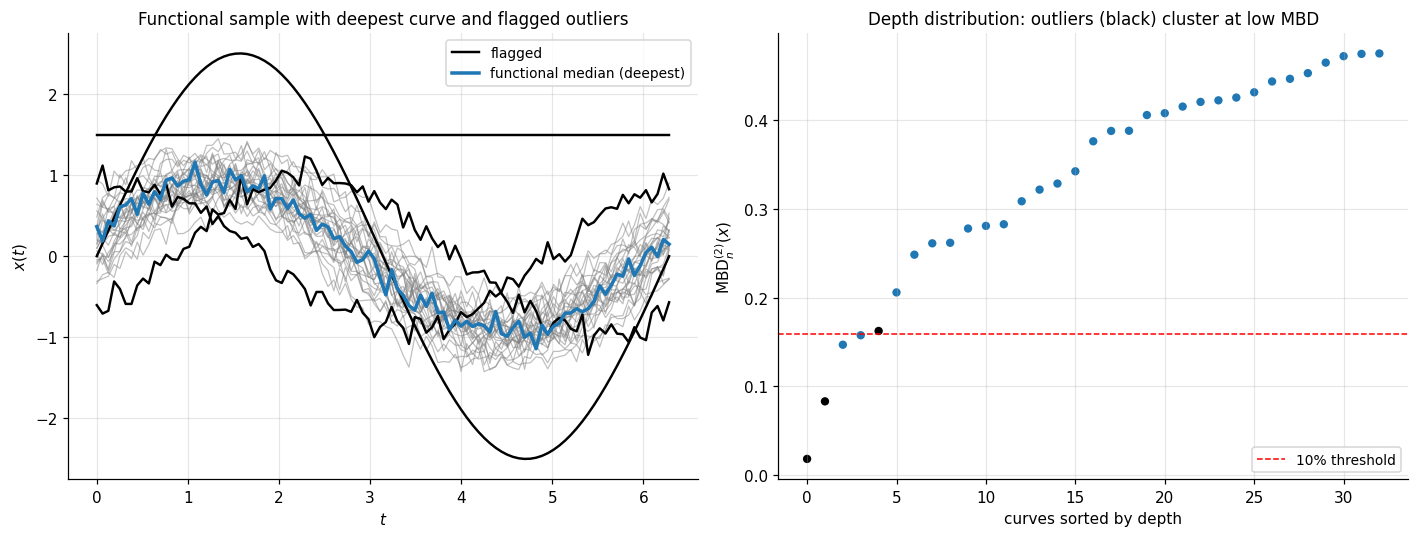
5.4 Depth-weighted M-estimation
A natural generalization of the §4.2 Tukey median is depth-weighted M-estimation: instead of using the deepest point, build an estimator that weights all sample points by a function of their depth. For a weight function ,
For this is the centroid of the -trimmed Tukey region, generalizing the median. Continuous weight functions yield smooth estimators that retain a controllable breakdown point (Donoho and Gasko 1992 Theorem 4 gives a bound under a mild monotonicity condition on ).
6. Connections and limits
The depth machinery sits at a junction between the rest of the formalML curriculum and the broader statistical literature on which it is built. This section orients the topic among its neighbors, then lays out the assumptions and computational realities that bound where statistical depth is the right tool and where it isn’t.
6.1 Within formalML
Quantile regression. The §1.1 motivation — that componentwise quantiles fail to give a well-defined multivariate notion of center — is the converse of the quantile regression motivation. Quantile regression handles the conditional multivariate problem (fixing a regressor and asking about the response distribution) by working one quantile level at a time. Statistical depth handles the unconditional multivariate problem (no regressor, just the joint distribution) by collapsing the multidimensional information into a center-outward scalar. The two converge at the multivariate-quantile-regression frontier, where Tukey contours of the residual distribution serve as nonparametric prediction regions.
Conformal prediction. Conformal prediction sets achieve marginal coverage by ranking calibration scores and inverting at the desired quantile. When the score is a multivariate residual, the natural rank is depth rather than componentwise quantile — which gives depth-based conformal prediction: prediction regions whose shapes adapt to the residual distribution’s geometry rather than being committed to coordinate-aligned boxes.
Extreme value theory. EVT and statistical depth are duals: EVT studies the outermost observations, depth studies the innermost. The two combine in multivariate extreme value theory, where shallow-depth observations identify candidate extremes and depth-based contours bound the central mass against which extremes are measured.
Rank tests. Depth provides the multivariate analogue of the rank ordering induced by the empirical CDF. Hodges-Lehmann-style multivariate rank tests built on depth-induced ranks are distribution-free under the elliptical-symmetry assumption and inherit the §4.1 consistency.
Prediction intervals. Multivariate prediction regions inherit the depth-conformal connection: a depth-based prediction region built from the calibration sample’s residual depths is the multivariate analogue of the standard quantile-based univariate prediction interval.
PCA and low-rank methods. PCA finds a lower-dimensional subspace explaining maximum variance; depth maps each point to a scalar quantifying its centrality. The two combine in projection depth (§3.3): the projection-depth value is the worst-case standardized residual over all 1D projections — a robustified version of the leading PCA loading.
Convex analysis. Theorems 1 (axiomatic) and Proposition 1 (convexity of contours) live entirely in the language of supporting hyperplanes, halfspaces, and convex hulls. The convex-analysis toolkit is the natural staging ground for derivations and contour-level-set arguments.
6.2 Cross-site connections
The univariate quantile function on formalstatistics/order-statistics-and-quantiles is the foundational concept that depth generalizes. Empirical-process limit theorems on formalstatistics/empirical-processes — the Vapnik–Chervonenkis Glivenko–Cantelli theorem and Donsker’s theorem on the halfspace VC class — are the structural prerequisites for Theorems 3 and 5 here. The elliptical-symmetry framework on formalstatistics/multivariate-distributions is the assumption under which Theorem 7 (DD-classifier Bayes-optimality) holds. The integrals defining halfspace and band masses live in formalcalculus/multiple-integrals.
6.3 Limits
Sample inefficiency in high dimensions. Statistical depth is a fundamentally geometric construction, and geometry in high is hostile. The §4.1 consistency rate is dimension-free pointwise — but the uniform rate over depth contours degrades as . For practical purposes, depth-based methods are most useful at . Beyond that, deep-region estimation requires sample sizes that are usually unavailable.
Computational cost. Theorem 6 (Aloupis 2006) is decisive: exact halfspace depth is NP-hard when is part of the input. The §3.3 projection construction provides a polynomial-time approximation, but the approximation rate in the number of projections degrades quickly when must scale with .
Ellipticity assumption in some applications. Theorem 7 (DD-classifier Bayes-optimality) requires elliptical class densities. When the class densities are non-elliptical, the DD-classifier is no longer Bayes-optimal — though it remains a competent classifier and inherits the §4.1 consistency. Practitioners should not lean on the Bayes-optimality result when the data exhibits multimodality, skewness, or heavy non-elliptical structure.
Non-uniqueness of the halfspace median. The Tukey median is in general a set, not a point; uniqueness requires additional symmetry assumptions on . Implementations report the centroid of the deepest level set (§2.3), but this introduces an arbitrary choice that has no statistical justification when the deepest level set has positive volume.
Functional depth is order-dependent. Band depth (§5.3) ranks curves but does not provide a metric structure on the function space — two equally deep curves can be very different in shape. The correct comparison metric (e.g., distance) must come from outside the depth machinery.
Connections
- The §2 axiomatic theorems and the convexity of depth contours (Proposition 2.4) live entirely in the language of supporting hyperplanes, halfspaces, and convex hulls. The convex-analysis toolkit is the natural setting for derivations and contour-level-set arguments. convex-analysis
- Projection depth (§3.3) is the worst-case standardized residual over all 1D projections — a robustified version of the leading PCA loading. PCA finds maximum-variance subspaces; projection depth finds maximum-outlyingness directions over the same sphere of unit projections. pca-low-rank
- Depth-based conformal prediction sets achieve marginal coverage with shapes that adapt to the residual distribution's geometry, replacing componentwise quantile rankings with depth-induced rankings of multivariate scores. conformal-prediction
- Statistical depth handles the unconditional multivariate-quantile problem by collapsing dimension into a center-outward scalar; quantile regression handles the conditional problem one quantile-level at a time. The two converge to multivariate-quantile regression with depth-based prediction regions. quantile-regression
- Depth-induced multivariate ranks make Hodges-Lehmann-style multivariate rank tests well-defined, giving distribution-free tests under elliptical symmetry that inherit the §4.1 consistency. rank-tests
- Depth and EVT are duals: EVT studies the outermost observations (block maxima, threshold exceedances), depth studies the innermost (the median, deep regions). They combine in multivariate EVT where shallow-depth observations identify candidate extremes. extreme-value-theory
- Multivariate prediction regions inherit the depth-conformal connection: a depth-based prediction region from calibration-sample residual depths is the multivariate analogue of standard quantile-based prediction intervals. prediction-intervals
References & Further Reading
- paper Mathematics and the Picturing of Data — Tukey (1975) Original statement of halfspace depth in §2 (Proceedings of the International Congress of Mathematicians, Vancouver 1974, vol. 2, pp. 523–531).
- paper Breakdown Properties of Location Estimates Based on Halfspace Depth and Projected Outlyingness — Donoho & Gasko (1992) Theorem 4.1 (consistency) and Theorem 4.2 (breakdown $\ge 1/(d+1)$) here (Annals of Statistics).
- paper On a Notion of Simplicial Depth — Liu (1988) Original definition of simplicial depth used in §3.2 (Proceedings of the National Academy of Sciences).
- paper On a Notion of Data Depth Based on Random Simplices — Liu (1990) Theorem 3.3 here: simplicial depth satisfies (D1)–(D4) (Annals of Statistics).
- paper General Notions of Statistical Depth Function — Zuo & Serfling (2000) Definition 1.1 here: the four-axiom specification of a depth function (Annals of Statistics).
- paper Asymptotics for the Tukey Depth Process, with an Application to a Multivariate Trimmed Mean — Massé (2004) Theorem 4.3 here: Hadamard differentiability + functional delta method asymptotics (Bernoulli).
- paper Multivariate Analysis by Data Depth: Descriptive Statistics, Graphics and Inference — Liu, Parelius & Singh (1999) Comprehensive survey covering the §3 zoo of depth functions (Annals of Statistics, with discussion).
- paper Geometric Measures of Data Depth — Aloupis (2006) Theorem 4.4 here: NP-hardness of exact halfspace depth in $d$ (DIMACS Series, vol. 72).
- paper A Depth Function and a Scale Curve Based on Spatial Quantiles — Serfling (2002) Spatial / $L^1$ depth definition used in §3.4 (Birkhäuser, Statistical Data Analysis Based on the L1-Norm).
- paper Algorithm AS 307: Bivariate Location Depth — Rousseeuw & Ruts (1996) The $O(n \log n)$ rotating-halfplane sweep used in §2.4 to compute 2D halfspace depth (JRSS-C).
- book Depth Statistics — Mosler (2013) Comprehensive modern survey; principal advanced reference for §§2–4 (Springer chapter, Robustness and Complex Data Structures).
- paper DD-Classifier: Nonparametric Classification Procedure Based on DD-Plot — Li, Cuesta-Albertos & Liu (2012) Theorem 5.2 here: DD-classifier Bayes-optimality under depth-calibration (Journal of the American Statistical Association).
- paper On the Concept of Depth for Functional Data — López-Pintado & Romo (2009) Definition 5.4 here: band depth and modified band depth for functional data (Journal of the American Statistical Association).
- paper Multivariate Functional Outlier Detection — Hubert, Rousseeuw & Segaert (2015) Modern functional-outlier taxonomy (constant / shape / amplitude) used in the §5.3 demo (Statistical Methods & Applications).