Concentration Inequalities
Quantitative convergence rates — from Markov's inequality to sub-Gaussian theory and generalization bounds
Overview & Motivation
The Measure-Theoretic Probability topic established that sample averages converge to population means. The Weak Law of Large Numbers tells us . The Strong Law strengthens this to almost sure convergence. But neither law answers the question a practitioner actually asks: how many samples do we need?
Suppose we train a classifier on samples and observe an empirical error rate of 5%. How confident are we that the true error is close to 5%? The law of large numbers says “eventually” — but “eventually” is not a sample size. We need quantitative bounds on tail probabilities: explicit formulas relating , the error tolerance , and the failure probability .
This is exactly what concentration inequalities provide. They answer questions of the form:
where decreases (typically exponentially) in and . Inverting these bounds gives us sample complexity: the number of samples sufficient to guarantee with probability at least .
The progression of tightness. We develop a hierarchy of increasingly powerful bounds:
- Markov’s inequality uses only the mean — the weakest bound but the most general.
- Chebyshev’s inequality adds the variance — a polynomial () rate.
- Chernoff bounds exploit the full moment generating function — exponential () rates.
- Hoeffding’s inequality provides a clean, usable exponential bound for bounded random variables.
- Sub-Gaussian theory abstracts the pattern: a random variable concentrates like a Gaussian if its MGF is controlled by a quadratic.
- Bernstein’s inequality refines the bound when the variance is small relative to the range.
- McDiarmid’s inequality extends concentration from sums to arbitrary functions of independent variables.
Each step trades generality for tightness. By the end, we will have the precise tools to prove generalization bounds — the theoretical guarantee that a machine learning model’s training error approximates its true error — and derive sample complexity results for finite hypothesis classes.
Basic Tail Bounds: Markov and Chebyshev
The Tail Probability Question
Given a random variable with known moments (mean, variance, etc.), what can we say about the probability that deviates far from its expected value? This is the tail probability question, and it is the foundation of all concentration inequalities.
We begin with the simplest possible bound, which uses only the first moment.
Markov’s Inequality
Theorem 1 (Markov's Inequality).
Let be a non-negative random variable with . Then for any :
Proof.
We write:
The first inequality follows because (so restricting the domain of integration decreases the integral). The second inequality follows because on the set , we have . Dividing both sides by completes the proof.
∎Remark.
Markov’s inequality is remarkably general — it requires only non-negativity and finite mean. But this generality comes at a cost: the bound is often loose. For example, if (so ), Markov gives , while the true value is .
Chebyshev’s Inequality
We can obtain a tighter bound by exploiting the variance. The idea is simple: apply Markov’s inequality to .
Theorem 2 (Chebyshev's Inequality).
Let have finite mean and finite variance . Then for any :
Proof.
Since , we apply Markov’s inequality to with threshold :
∎
Corollary 1 (Chebyshev for Sample Means).
If are i.i.d. with mean and variance , then:
Proof.
The sample mean has mean and variance . Apply Chebyshev.
∎Remark.
This gives our first sample complexity bound: to guarantee , we need . This is the WLLN proof we saw in the previous topic, now made quantitative. But the polynomial rate is far from optimal — we will soon see exponential bounds.
One-Sided Variants
Proposition 1 (Cantelli's Inequality (One-sided Chebyshev)).
Let have finite mean and variance . Then for any :
Proof.
For any , we have:
by Markov applied to . Minimizing over gives , yielding the result.
∎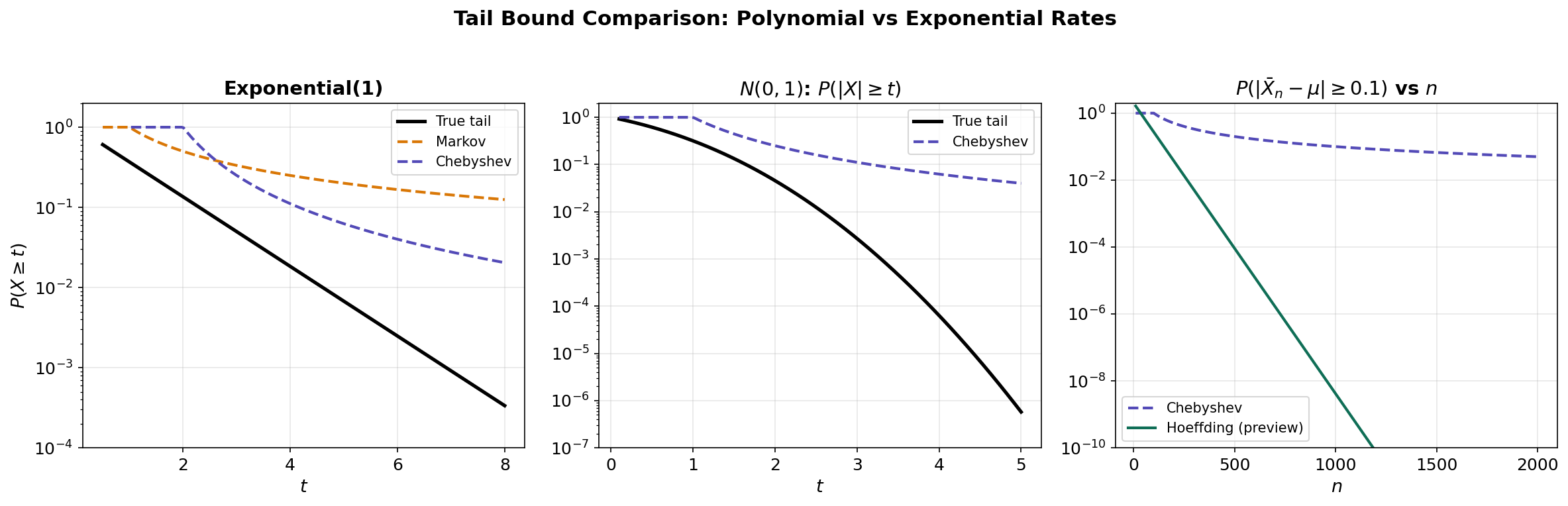
The figure above demonstrates how loose the basic tail bounds are compared to the true tail probability. In the next section, we introduce the key idea that bridges the gap: the Chernoff method.
# Tail Bound Comparison: Markov vs Chebyshev vs True Tail
import numpy as np
from scipy import stats
import matplotlib.pyplot as plt
t_vals = np.linspace(0.5, 8, 200)
mu, sigma2 = 1.0, 1.0 # Exp(1): mean=1, var=1
true_tail = np.exp(-t_vals) # P(X >= t) = e^{-t}
markov_bound = np.minimum(mu / t_vals, 1.0) # E[X] / t
chebyshev_bound = np.minimum(sigma2 / (t_vals - mu)**2, 1.0) # Var / (t - mu)^2
# Chebyshev is only meaningful for t > mu
chebyshev_bound[t_vals <= mu] = 1.0
plt.semilogy(t_vals, true_tail, 'k-', linewidth=2.5, label='True tail')
plt.semilogy(t_vals, markov_bound, '--', color='#D97706', linewidth=2, label='Markov')
plt.semilogy(t_vals[t_vals > mu], chebyshev_bound[t_vals > mu],
'--', color='#534AB7', linewidth=2, label='Chebyshev')
plt.xlabel('t'); plt.ylabel('P(X >= t)')
plt.title('Exponential(1): Tail Bounds vs True Tail')
plt.legend()The Chernoff Method and Moment Generating Functions
The Key Idea: Exponentiate and Apply Markov
The breakthrough from polynomial to exponential tail bounds comes from a remarkably simple trick: instead of applying Markov directly to , apply it to for an optimized parameter .
Definition 1 (Moment Generating Function).
The moment generating function (MGF) of a random variable is:
whenever the expectation exists. The MGF is also called the Laplace transform of the distribution of .
Remark.
The MGF encodes all moments of : . This is why exploiting the MGF gives stronger bounds than using any finite number of moments.
The Chernoff Bound
Theorem 3 (Chernoff Bound).
For any random variable and any :
Proof.
For any , the function is strictly increasing, so:
where the inequality is Markov applied to the non-negative random variable . Since this holds for all , we take the infimum.
∎Remark.
The optimization over is the “Chernoff” step. Different choices of give different trade-offs between the decay and the MGF growth. The optimal satisfies , which is the equation for the Legendre transform (or rate function) of the log-MGF.
Application to Sums of Independent Variables
For a sum of independent random variables, the MGF factorizes:
This is because independence gives . The log-MGF (cumulant generating function) therefore adds:
This additivity is why the Chernoff method is particularly powerful for sums of independent variables.
Proposition 2 (Chernoff for Bernoulli Sums).
Let be i.i.d. and . For any :
Proof.
The MGF of is . So . The Chernoff bound gives . Taking the derivative in and setting it to zero gives . Substituting yields the result after algebraic simplification.
∎The Log-MGF and Cramér’s Theorem (Preview)
Definition 2 (Cumulant Generating Function).
The cumulant generating function (CGF, or log-MGF) of is:
Definition 3 (Rate Function (Legendre–Fenchel Transform)).
The rate function of is:
This is the Legendre–Fenchel transform (convex conjugate) of . The Chernoff bound becomes:
The rate function measures how “surprising” it is to observe . This connects to large deviations theory and information-theoretic quantities like the KL divergence.
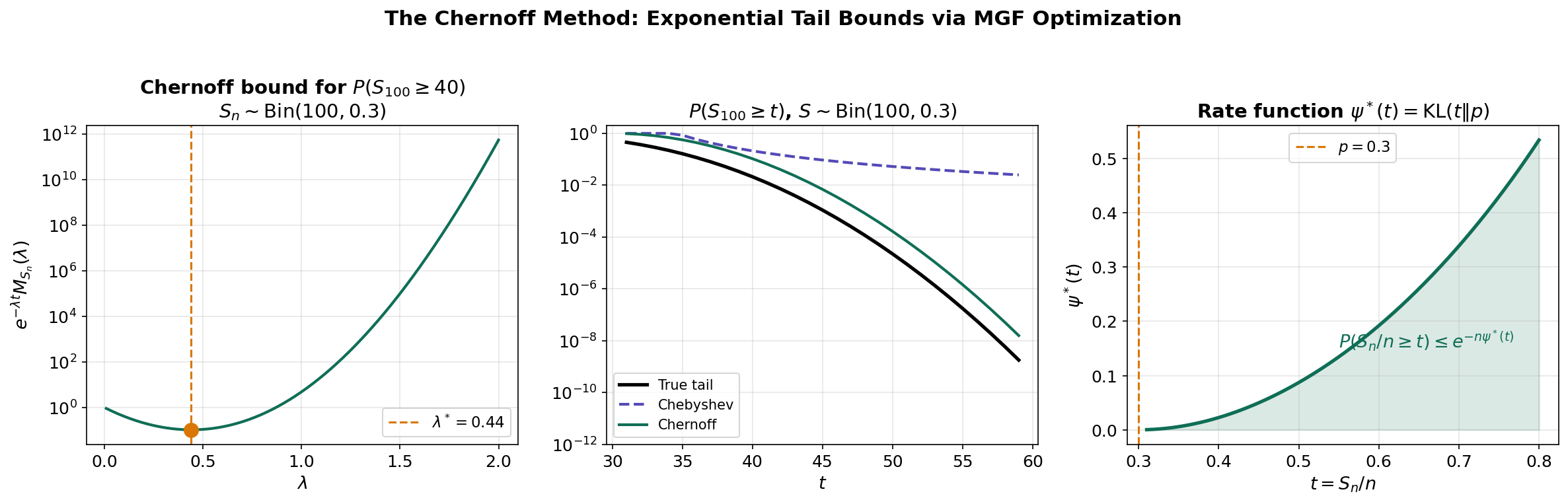
# Chernoff Method: Optimizing the Exponential Tilt
p, n = 0.3, 100
t_target = 40 # P(S_n >= 40) where np = 30
lambdas = np.linspace(0.01, 2.0, 200)
chernoff_bounds = []
for lam in lambdas:
mgf = (1 - p + p * np.exp(lam))**n
bound = np.exp(-lam * t_target) * mgf
chernoff_bounds.append(bound)
chernoff_bounds = np.array(chernoff_bounds)
opt_idx = np.argmin(chernoff_bounds)
# The optimal λ* minimizes the Chernoff bound
print(f"Optimal λ = {lambdas[opt_idx]:.3f}")
print(f"Chernoff bound = {chernoff_bounds[opt_idx]:.2e}")
print(f"True probability = {1 - stats.binom.cdf(39, n, p):.2e}")Hoeffding’s Inequality
The Chernoff method is powerful but requires computing the MGF of each distribution. Hoeffding’s inequality provides a distribution-free exponential bound for bounded random variables, avoiding the need to compute the specific MGF.
Hoeffding’s Lemma
The key technical ingredient is a bound on the MGF of a bounded, zero-mean random variable.
Lemma 1 (Hoeffding's Lemma).
Let be a random variable with and almost surely. Then for all :
Proof.
Since , we can write where . By convexity of :
Taking expectations and using (so and ):
Let , . Then the right side equals where:
We have , , and for all (since is maximized at ). By Taylor’s theorem with the mean-value form of the remainder:
∎
Hoeffding’s Inequality
Theorem 4 (Hoeffding's Inequality).
Let be independent random variables with almost surely. Let . Then for any :
and by a symmetric argument:
Proof.
Apply the Chernoff method: for any , by independence:
Each satisfies and , with range . By Hoeffding’s Lemma:
So:
Minimizing over gives , yielding:
∎
Corollary 2 (Hoeffding for Sample Means).
If are i.i.d. with , then:
Remark.
Inverting: to achieve , we need:
Compare to Chebyshev’s : Hoeffding’s dependence on is instead of — exponentially better for small .
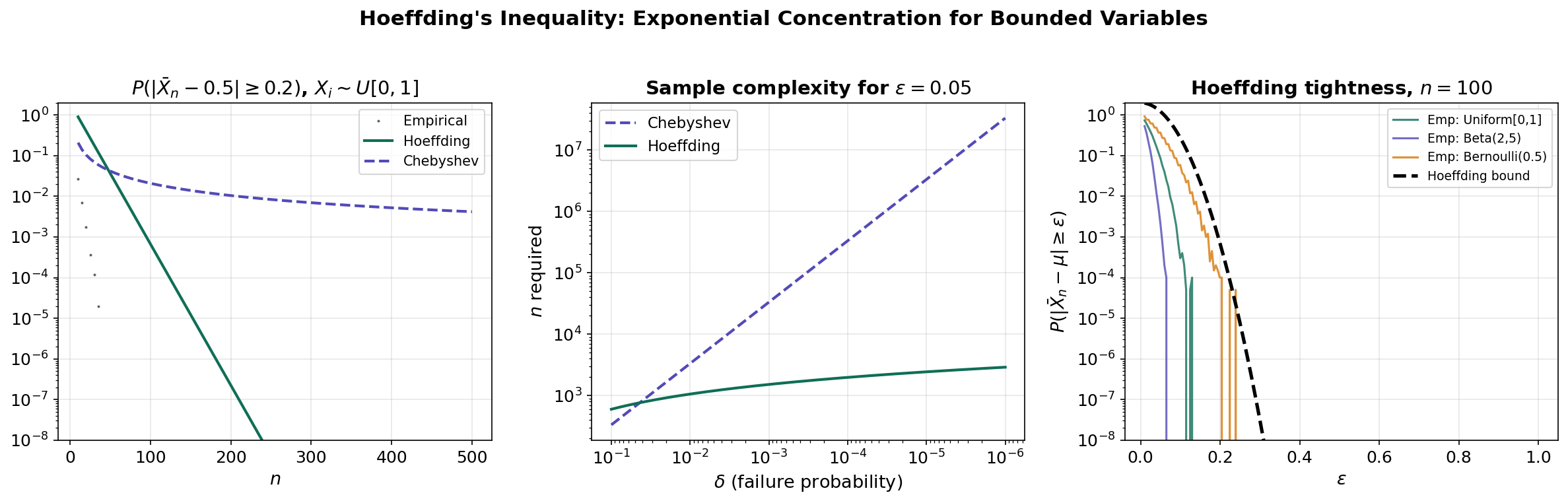
# Hoeffding's Inequality: Empirical Verification
np.random.seed(42)
n_values = np.arange(10, 501, 5)
eps = 0.2
a, b = 0, 1 # Uniform[0,1]
mu, sigma2 = 0.5, 1/12
n_mc = 50000
empirical_probs = []
for n in n_values:
samples = np.random.uniform(0, 1, (n_mc, n))
means = samples.mean(axis=1)
empirical_probs.append(np.mean(np.abs(means - mu) >= eps))
hoeffding_bound = 2 * np.exp(-2 * n_values * eps**2 / (b - a)**2)
chebyshev_bound = np.minimum(sigma2 / (n_values * eps**2), 1.0)
# The Hoeffding bound is a valid upper bound at every n
# Chebyshev is always looser (higher) than HoeffdingSub-Gaussian Random Variables
Hoeffding’s inequality works for bounded random variables, but many important random variables are unbounded (e.g., Gaussian). We need a framework that captures the tail behavior rather than relying on boundedness. This leads to the theory of sub-Gaussian random variables — a class defined by having tails that decay at least as fast as a Gaussian’s.
Motivation
A standard Gaussian has MGF . The Chernoff method gives:
This Gaussian tail bound has the form . Many distributions — even non-Gaussian ones — exhibit this same qualitative behavior. Sub-Gaussian theory captures this commonality.
Definition and Equivalent Characterizations
Definition 4 (Sub-Gaussian Random Variable).
A random variable with is sub-Gaussian with parameter (written ) if its MGF satisfies:
The parameter is called the sub-Gaussian proxy variance (or sub-Gaussian norm).
Proposition 3 (Equivalent Characterizations of Sub-Gaussian).
For a mean-zero random variable , the following are equivalent (up to universal constants in the parameters):
- MGF condition: for all .
- Tail condition: for all .
- Moment condition: for all .
- -norm: .
Remark.
These characterizations are not equivalent with the same constant — they are equivalent up to universal multiplicative factors. The MGF condition is the cleanest for proving concentration bounds. The tail condition is most intuitive.
Key Examples
Example 1 (Gaussian). is — the defining example.
Example 2 (Rademacher). with equal probability. Then , so .
Example 3 (Bounded). If and , then by Hoeffding’s Lemma.
Example 4 (Not sub-Gaussian). is not sub-Gaussian: its MGF diverges at , so it cannot be bounded by a quadratic for all .
Concentration for Sums of Sub-Gaussians
Theorem 5 (Sub-Gaussian Sum).
If are independent with , then .
Proof.
By independence:
∎
Corollary 3 (Sub-Gaussian Sample Means).
If are i.i.d. , then:
Maximal Inequality
Theorem 6 (Sub-Gaussian Maximum).
If are (not necessarily independent) sub-Gaussian with parameter , then:
Proof.
For any :
where we used (log-sum-exp) and Jensen’s inequality. Optimizing: gives the result.
∎Remark.
The rate is ubiquitous in high-dimensional statistics. It tells us that the maximum of sub-Gaussian variables grows only logarithmically — a fundamental reason why many statistical procedures work in high dimensions.
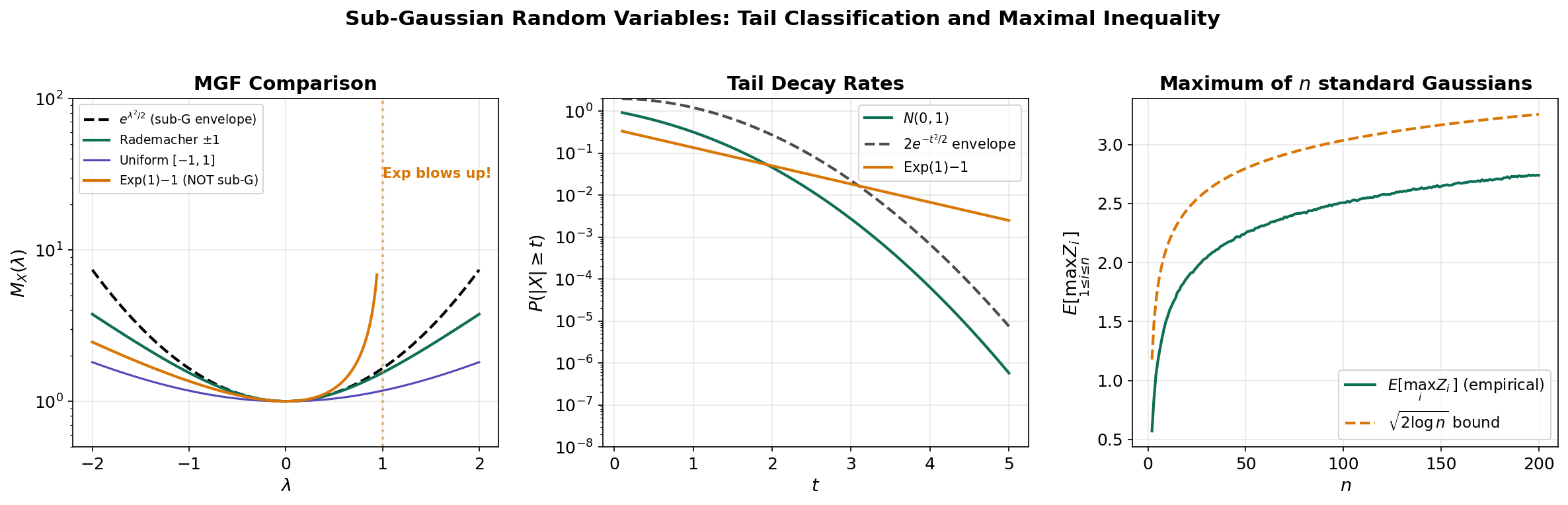
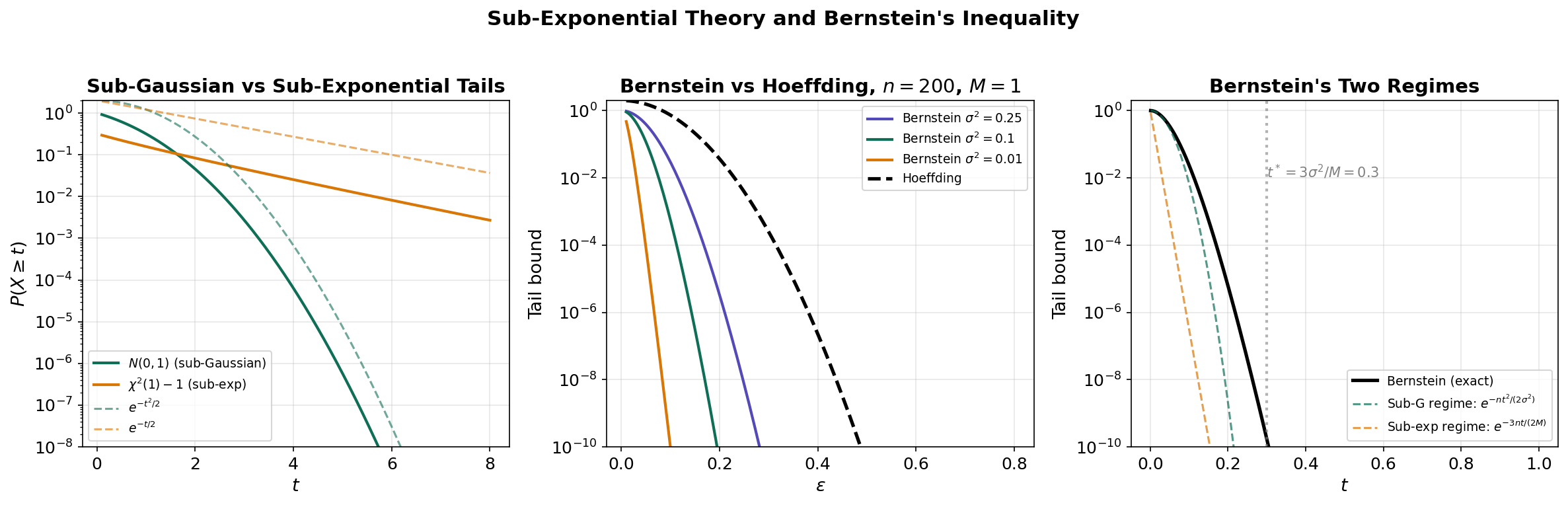
Sub-Exponential Random Variables and Bernstein’s Inequality
Beyond Sub-Gaussian: Heavier Tails
Not all useful random variables are sub-Gaussian. The centered exponential where , or the square of a Gaussian, have tails that decay as rather than . These are sub-exponential random variables.
Definition 5 (Sub-Exponential Random Variable).
A random variable with is sub-exponential with parameters if:
Remark.
The MGF condition looks like the sub-Gaussian condition, but it only holds for rather than all . This restricted domain reflects the heavier tails.
Proposition 4 (Sub-Gaussian ⊂ Sub-Exponential).
Every sub-Gaussian random variable is sub-exponential (with , formally). The converse is false: where is sub-exponential but not sub-Gaussian.
Proposition 5 (Product Rule (Sub-Gaussian squares)).
If , then is sub-exponential with parameters depending on .
Bernstein’s Inequality
Bernstein’s inequality is sharper than Hoeffding when the variance is small relative to the range. It interpolates between sub-Gaussian behavior (for small deviations) and sub-exponential behavior (for large deviations).
Theorem 7 (Bernstein's Inequality).
Let be independent mean-zero random variables with almost surely. Let . Then:
Proof.
For bounded with , we have for (Bernstein’s moment condition). This gives:
for . Using and the Chernoff method, then optimizing , we obtain the result.
∎Remark.
The denominator creates two regimes:
- Small deviations (): the bound behaves as — sub-Gaussian with the variance, not the range.
- Large deviations (): the bound behaves as — sub-exponential, linear in .
When , Bernstein is much tighter than Hoeffding in the small-deviation regime.
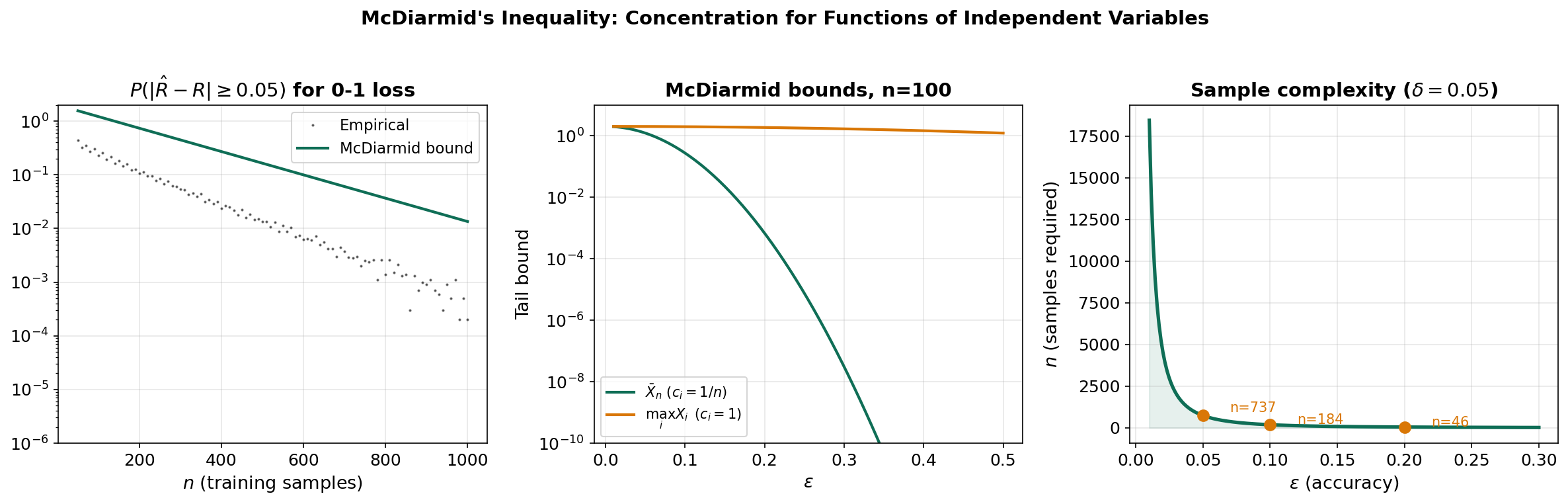
McDiarmid’s Inequality
From Sums to General Functions
Hoeffding’s inequality applies to sums . But in machine learning, we often care about more general functions of independent random variables — for instance, the empirical risk , or the supremum of an empirical process .
McDiarmid’s inequality extends concentration to any function that doesn’t depend too much on any single coordinate.
The Bounded Differences Condition
Definition 6 (Bounded Differences Property).
A function satisfies the bounded differences property with constants if for every and every :
In words: changing any single input to changes by at most .
McDiarmid’s Inequality
Theorem 8 (McDiarmid's Inequality).
Let be independent random variables, and let satisfy the bounded differences property with constants . Then:
Proof.
The proof uses a martingale difference decomposition. Define:
Then is a telescoping sum of martingale differences ().
The bounded differences condition implies almost surely. Each is conditionally bounded and mean-zero given , so Hoeffding’s Lemma applies conditionally:
The remainder follows the same Chernoff optimization as Hoeffding’s inequality, yielding the stated bound with constant instead of by tighter analysis of the conditional ranges.
∎Remark.
McDiarmid’s inequality is sometimes called the “method of bounded differences.” It subsumes Hoeffding’s inequality: for with , each , and the bound reduces to Hoeffding.
Application: Concentration of Empirical Risk
Example 5 (Empirical Risk). Let be i.i.d. training samples, a fixed hypothesis, and a loss function bounded by . Define the empirical risk:
Changing any single sample changes by at most . By McDiarmid:
This is the concentration result that enables generalization bounds: the empirical risk concentrates around the true risk at an exponential rate.
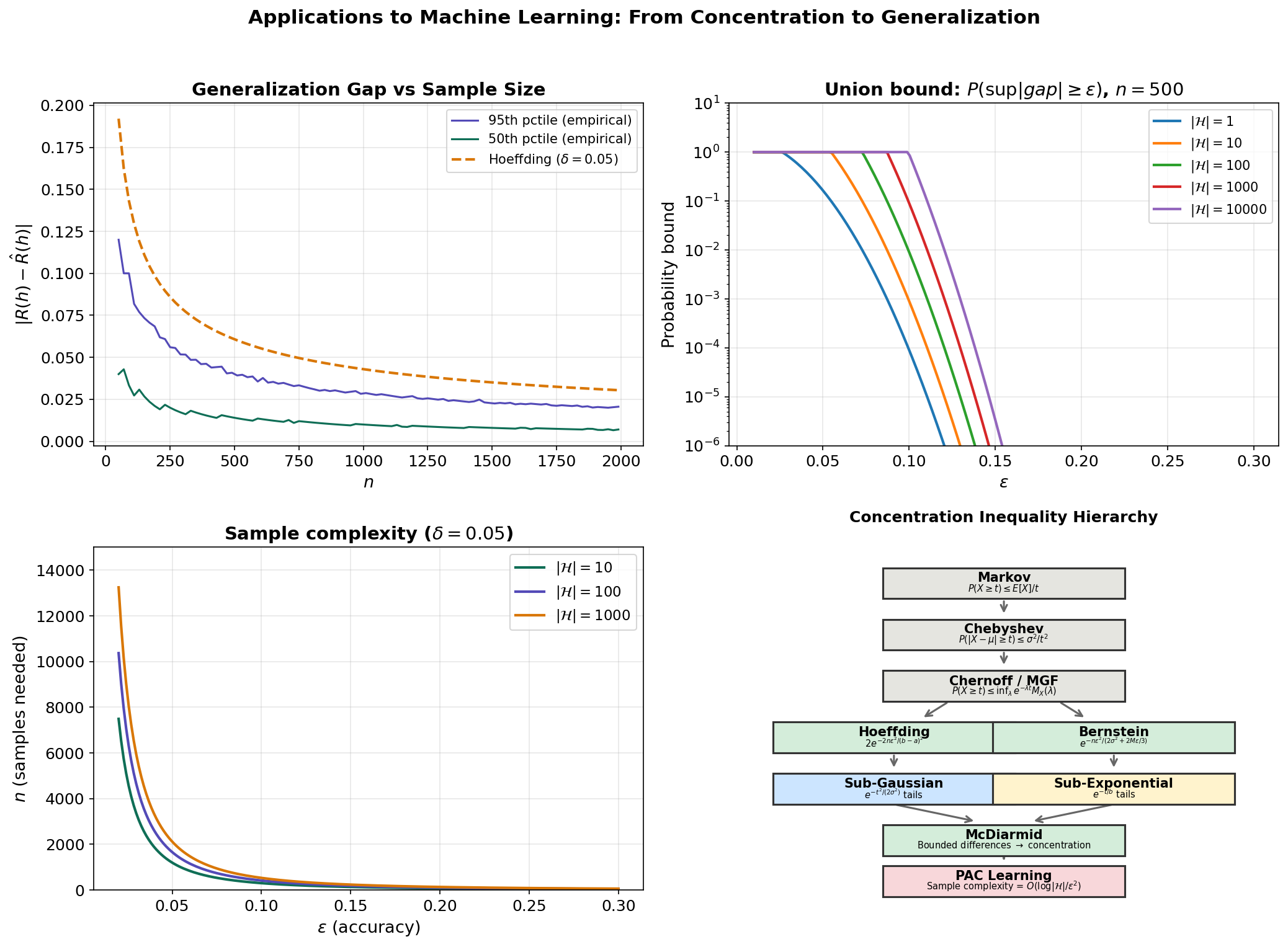
Applications to Machine Learning
Generalization Bounds for a Fixed Hypothesis
The simplest generalization bound follows directly from Hoeffding’s inequality (or McDiarmid). Given a hypothesis , its true risk and empirical risk , if the loss is bounded by :
Theorem 9 (Fixed-Hypothesis Generalization Bound).
With probability at least :
Proof.
Apply Hoeffding’s Corollary 2 with and solve .
∎The Union Bound and Finite Hypothesis Classes
For a finite hypothesis class , we want uniform convergence: simultaneously for all . The union bound (Boole’s inequality) and Hoeffding give:
Theorem 10 (Uniform Convergence for Finite H).
With probability at least :
Proof.
By the union bound:
Set this equal to and solve for .
∎Remark.
The price of uniformity is — logarithmic in the size of the hypothesis class. This is remarkably mild: even with hypotheses, we only need additional samples’ worth of concentration.
Sample Complexity
Corollary 4 (Sample Complexity for Finite H).
To achieve with probability , it suffices to have:
This is the PAC-style sample complexity bound. The dependence on the key parameters is:
- : quadratic in the accuracy — fundamental to most concentration-based bounds.
- : logarithmic in the hypothesis class size — the key insight that makes learning tractable.
- : logarithmic in the confidence — exponentially better than Chebyshev’s .
The Bridge to PAC Learning
This section has developed the concentration machinery that the PAC Learning Framework will use extensively. The key ingredients flowing forward are:
- Hoeffding’s inequality for bounding the gap between empirical and true risk.
- The union bound for extending single-hypothesis bounds to finite classes.
- Sub-Gaussian theory as the abstract framework for tail control.
- McDiarmid’s inequality for concentration of general functions (needed for Rademacher complexity).
The PAC learning framework formalizes this: a hypothesis class is PAC-learnable if there exists an algorithm that, given i.i.d. samples, outputs a hypothesis with with probability . The sample complexity depends on the “complexity” of — measured by VC dimension, Rademacher complexity, or covering numbers — all of which rely on the concentration inequalities developed here.
# Generalization Bounds: Union Bound + Hoeffding for Finite H
np.random.seed(42)
n_vals = np.arange(50, 2001, 20)
true_risk = 0.3
n_mc = 5000
# Empirical generalization gaps (Monte Carlo)
gen_gaps_95 = []
for n in n_vals:
emp_risks = np.random.binomial(n, true_risk, n_mc) / n
gaps = np.abs(emp_risks - true_risk)
gen_gaps_95.append(np.percentile(gaps, 95))
# Hoeffding bound for 95% confidence (delta = 0.05)
hoeffding_95 = np.sqrt(np.log(2 / 0.05) / (2 * n_vals))
# Sample complexity: n >= log(2|H|/delta) / (2 * eps^2)
# For |H| = 100, delta = 0.05:
n_needed = lambda eps: np.log(2 * 100 / 0.05) / (2 * eps**2)Connections & Further Reading
Connections Map
| Topic | Domain | Relationship |
|---|---|---|
| Measure-Theoretic Probability | Probability & Statistics | Prerequisite — provides spaces, convergence modes, and the expectation operator used throughout |
| PCA & Low-Rank Approximation | Linear Algebra | Matrix concentration inequalities bound the gap between sample and population covariance eigenvalues |
| PAC Learning Framework | Probability & Statistics | Direct downstream — uses Hoeffding + union bound for sample complexity; Rademacher complexity uses McDiarmid |
| Bayesian Nonparametrics (coming soon) | Probability & Statistics | Concentration bounds for posterior contraction rates |
Key Notation Summary
| Symbol | Meaning |
|---|---|
| Moment generating function | |
| Cumulant generating function (log-MGF) | |
| Rate function (Legendre–Fenchel transform) | |
| Sub-Gaussian with proxy variance | |
| Sub-Gaussian (Orlicz) norm | |
| True risk | |
| Empirical risk | |
| Hypothesis class |
Connections
- Direct prerequisite — provides Lp spaces, expectation, independence, the convergence hierarchy, and the Lebesgue integral machinery used throughout. measure-theoretic-probability
- Matrix concentration inequalities (extensions of the scalar theory developed here) bound the gap between sample and population covariance eigenvalues. pca-low-rank
- Where concentration inequalities give asymptotic distribution-free bounds (DKW, Hoeffding-style), conformal prediction achieves *exact* finite-sample coverage via rank symmetry under exchangeability — a different mathematical machinery for the same distribution-free goal. The two routes meet at split conformal's marginal-coverage theorem. conformal-prediction
References & Further Reading
- book Concentration Inequalities: A Nonasymptotic Theory of Independence — Boucheron, Lugosi & Massart (2013) Definitive reference — covers all topics in this page and much more
- book High-Dimensional Probability — Vershynin (2018) Excellent treatment of sub-Gaussian/sub-exponential theory
- book High-Dimensional Statistics: A Non-Asymptotic Viewpoint — Wainwright (2019) Connects concentration to statistical estimation and testing
- book Understanding Machine Learning: From Theory to Algorithms — Shalev-Shwartz & Ben-David (2014) Chapters 2-4 use these inequalities for PAC learning
- book Probability: Theory and Examples — Durrett (2019) Chapter 2 covers the classical large deviations perspective
- paper Probability Inequalities for Sums of Bounded Random Variables — Hoeffding (1963) The original paper — still beautifully clear
- paper On the Method of Bounded Differences — McDiarmid (1989) Original presentation of the bounded differences inequality