Double Descent
The interpolation threshold, the minimum-norm interpolator, and the modern overparameterized regime
Motivation: the empirical phenomenon
The textbook bias-variance U-curve as the picture being revised
Anyone who has taken a first course in machine learning carries around a picture of generalization. Test error decomposes into bias, variance, and irreducible noise; as model complexity grows, bias falls and variance rises; and somewhere in between is the sweet spot we call the optimal model. The picture is universally drawn as a U-curve, and it underwrites every regularization heuristic from ridge to early stopping to dropout. If we want to generalize, we don’t make our model bigger — we make it the right size.
This picture comes from the classical learning-theory regime where the number of parameters is small relative to the number of training points . The U-curve has decades of empirical and theoretical support in that regime. VC bounds, structural risk minimization, AIC, BIC, and cross-validation all give different recipes for finding the bottom of the U, and in the underparameterized regime they roughly agree. The picture is right.
What the picture leaves out is what happens past the bottom. If is small the right edge of the U is just “variance keeps growing as the model overfits more.” The picture says nothing specific about , because nobody used to fit models in that regime. When statisticians said “more parameters than data points,” they meant “the problem is ill-posed and the answer is to either get more data or shrink the model class.” That answer was correct as long as we were planning to use OLS — and as long as we didn’t have a way to pick one of the infinitely many interpolators that exist past the threshold.
The reason this matters now is that modern neural networks live in the regime by orders of magnitude. ResNet-50 has 25M parameters; ImageNet has 1.3M images. GPT-3 has 175B parameters; the training corpus has somewhere between and tokens. In every case the model class is wildly larger than what classical learning theory says we can hope to generalize from. The networks generalize anyway. Why is the question this topic is built around — and the first step is to recognize that the U-curve isn’t wrong, but it tells the story of only the first half of the picture.
The empirical phenomenon: a synthetic linear-regression demo
Let’s make this empirical before we make it formal. The cleanest experimental setup is the one Hastie, Montanari, Rosset, and Tibshirani (2022) analyze: linear regression with isotropic Gaussian features.
We fix an ambient feature dimension , a training-set size , a noise level , and a signal-to-noise ratio . We draw a fixed true coefficient vector uniformly on the sphere of radius , and for each replicate we generate
For each model size , we use only the first columns of to fit a linear model. When this is ordinary least squares; when the system is underdetermined and we pick the minimum-norm interpolator via the SVD pseudoinverse:
where is the thin SVD of the truncated design matrix and is the pseudoinverse of the singular-value matrix — we invert nonzero singular values and zero out the rest, with a numerical truncation threshold of .
We evaluate excess test risk against the full signal,
where the expectation is over a fresh test point , estimated empirically on a held-out set of 1000 test points and averaged over replicates. The result is Figure 1.
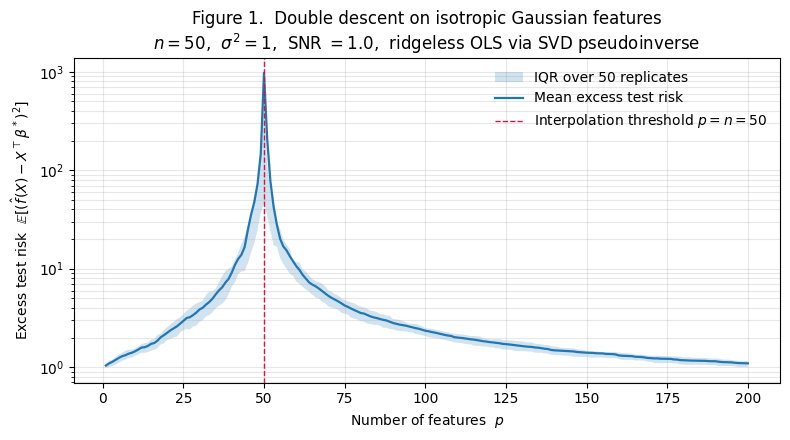
What the curve shows:
- Classical regime . Excess risk climbs gently from at to at and at . As we add parameters, bias falls (we capture more of ) but variance rises. For these parameters the variance growth dominates.
- Interpolation threshold . The mean excess risk spikes to — nearly three orders of magnitude above its neighbors. The IQR band widens dramatically here; the spike is a genuine concentration of the curve, not a single-replicate outlier.
- Overparameterized regime . Excess risk crashes back down. By we’re at . By we’re at . At , excess risk is — essentially indistinguishable from the baseline.
This is double descent. Two descents — one in the classical regime, one past the threshold — separated by a spike at exactly the point where the design matrix becomes square.
A note on the feature choice. The features in Figure 1 are isotropic Gaussian, rather than a structured basis like polynomials or wavelets. This isn’t a cosmetic choice. The clean second descent depends on the random-matrix-theory machinery we develop in §5, which requires the columns of to behave as approximately i.i.d. random vectors. Polynomial features on a 1D uniform input — the most familiar concrete example — don’t satisfy this, and the second descent fails to appear cleanly. The right way to think about the isotropic-Gaussian features here is as a stand-in for the random representations a neural network learns in the wide regime; §8 returns to this with the random-features model and makes the connection precise.
Nakkiran 2020: the deep-net version of the same curve
The phenomenon we just saw isn’t a quirk of linear regression. Nakkiran et al. (2020) showed that the same shape appears in modern neural networks across multiple axes:
- Width-wise. At fixed depth and training-set size, test error spikes at a critical width and falls again past it. For ResNet-18 on CIFAR-10 with 15% label noise, the spike sits at approximately the width where the network has just barely enough capacity to drive training error to zero.
- Depth-wise. At fixed width and training-set size, the same shape appears as a function of depth.
- Epoch-wise. At fixed architecture, test error during training shows a non-monotone descent — improvement, spike near the epoch when training error crosses zero, then improvement again.
What unifies these axes is that the spike always appears at the point where the model just barely manages to interpolate the training set. Before that point we’re in the classical “more capacity hurts” regime. After that point we’re in the modern “more capacity helps” regime. Section 10 returns to this with a sidebar reproducing the width-wise curve on a small MLP toy; the rest of the topic establishes why the linear theory we develop predicts this exact shape.
What’s special about the interpolation threshold
The spike in Figure 1 isn’t an artifact of the random initialization or the small sample size. It’s a generic consequence of what happens to a linear system when the number of features matches the number of training points.
Let’s name three regimes by what the design matrix looks like.
- Underparameterized regime . The matrix is tall. The normal equations have a unique solution that minimizes the squared training error. There’s no requirement that this solution interpolate the training points; generically, it can’t.
- Overparameterized regime . The matrix is wide. The normal equations are underdetermined: any with achieves zero training error, and there’s an entire -dimensional affine subspace of such solutions. We need an additional principle to pick one. The SVD pseudoinverse picks the element of that subspace with smallest -norm — what we’ll call the minimum-norm interpolator in §4.
- Interpolation threshold . The matrix is square. Under generic conditions on — Gaussian features, random subsets of an orthogonal basis, polynomial features at distinct points — the matrix is almost surely invertible, and the unique solution exactly interpolates the training data including the noise.
The threshold is special for a reason we can already read off the third bullet: the system has just enough degrees of freedom to interpolate the noise and no slack to absorb it. Algebraically, the condition number diverges as we approach from either side. Geometrically, the smallest singular value of — which controls how much the noise vector gets amplified into the fitted coefficients — is order in the well-behaved regime but collapses to order near the threshold. The spike in Figure 1 is the manifestation of blowing up.
We’ll make all of this precise in §3 with explicit closed-form expressions for the variance, and in §§5–6 with the asymptotic random-matrix-theory machinery that produces the analytic double-descent curve. For now, the moral is: the U-curve breaks at exactly because the linear system has no slack to absorb noise; and the second descent is what happens when we move past the threshold into the regime where there’s room to choose a good interpolator.
Roadmap
The path forward:
- §§2–3 revisit the classical bias-variance / VC / SRM picture and pin down exactly where it breaks. The interpolation threshold is the focus of §3.
- §§4–6 build the analytic double-descent curve from scratch. §4 introduces the minimum-norm interpolator and its SVD expression; §5 introduces the Marchenko–Pastur eigenvalue density that governs the spectrum of ; §6 gives the closed-form bias-variance decomposition and proves the second descent.
- §§7–8 generalize beyond the basic setup. §7 separates model-wise from sample-wise double descent in the Nakkiran taxonomy. §8 extends to random-features models and connects to the kernel limit.
- §§9–10 explain why explicit regularization isn’t needed for the second descent. §9 proves that gradient descent from zero init converges to the minimum-norm interpolator. §10 is a sidebar on deep double descent.
- §§11–12 discuss effective dimension (why can behave like for the right designs) and the modern revision of classical capacity-control theories.
- §§13–14 close with computational notes and an honest accounting of what the linear theory predicts versus what remains open in the deep regime.
The classical story being revised
Bias-variance decomposition and the classical U-curve
The picture from §1.1 has a precise mathematical formulation. Suppose we have a true function and a learned predictor trained on a random dataset. The excess test risk at a fixed test point , averaged over the randomness of the training set, is
Adding and subtracting the mean predictor and expanding,
The cross term vanishes — the mean predictor is the -projection of onto constants in training-set space — and we get the canonical decomposition. Squared bias measures how far the average learned predictor sits from the truth; variance measures how much the predictor wobbles around its average across training-set draws.
Averaging over a fresh test point gives the total excess risk:
The classical bias-variance trade-off is the empirical observation that as we increase model complexity, bias falls but variance rises. To make this concrete, Figure 2 shows the decomposition on a clean textbook setup: polynomial regression on a noisy sine wave, well inside so the interpolation-threshold pathology from §1 doesn’t enter.
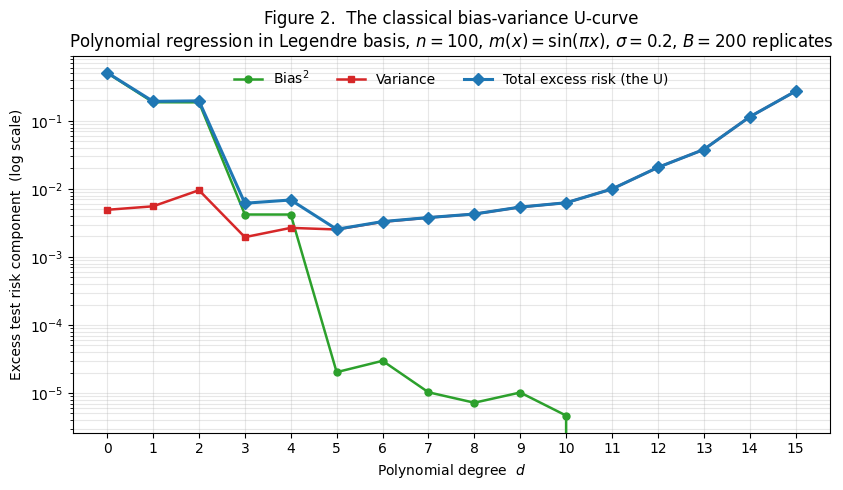
We sample training points and observe with . For each polynomial degree we fit by ordinary least squares in the Legendre polynomial basis — Legendre because the monomial basis is catastrophically ill-conditioned at moderate degrees on , but stays bounded and the design matrix stays well-behaved. We compute bias² and variance by Monte Carlo over replicates with a shared test set of 1000 points, applying the standard finite- correction to remove the MC bleed-through into the bias estimator.
Three things stand out in Figure 2:
- Bias drops in two steps. From to and again from to and from to , with plateaus between. The target is an odd function, so even-degree Legendre polynomials don’t contribute to its approximation; adding an even-degree term doesn’t reduce bias. This staircase pattern is a nice illustration that bias depends on how well the model class can approximate , not on the raw parameter count.
- Variance grows roughly linearly with . From at to at . The per-feature variance contribution is approximately when features are well-conditioned, and we have features at degree .
- Total has a clear minimum. At , where bias has dropped below the noise floor and variance is still small. By , total excess risk is two orders of magnitude above the minimum — variance has taken over. This is the classical U.
This is the picture the U-curve has stood for since at least Geman, Bienenstock, and Doursat (1992), and it is exactly the right picture for the regime we’re plotting. The textbook recommendation that follows — pick the model complexity that minimizes test error, or use cross-validation to estimate it — is correct in this regime and remains the operating assumption for most of statistics.
VC and SRM: capacity must be controlled
The bias-variance picture in Figure 2 is descriptive, not predictive — we observed the U-curve, but we’d like a theoretical argument for why test error grows with capacity past the bias-variance minimum, and a tool for picking the right capacity before seeing the data.
This is the program of statistical learning theory. The two foundational tools — both shipped formalML topics — are VC dimension (Vapnik and Chervonenkis 1971, formalized in Vapnik 1995) and structural risk minimization (Vapnik 1995). VC dimension gives a combinatorial capacity measure for binary-classification hypothesis classes: the largest sample size on which the class can realize every labeling pattern. Sample-complexity bounds turn this into uniform convergence guarantees of the form
with probability at least — the generalization gap is controlled by VC capacity relative to sample size.
Structural risk minimization is the algorithmic counterpart: rather than picking a fixed hypothesis class up front, take a nested family of increasing capacity and let the data decide where to sit. The SRM estimator picks
where is a per-class capacity penalty. The penalty grows with capacity, the training loss falls with capacity, and the SRM estimator picks where their sum is smallest — exactly the argmin of the bias-variance U-curve, with the penalty playing the role of “predicted variance” and the training loss playing the role of “predicted bias.”
The point for us is that classical learning theory’s central recommendation is to control capacity. Cross-validation, AIC, BIC, ridge, lasso, and early stopping are all operationally capacity-control devices, even when they’re motivated differently. The story is coherent: the U-curve exists, the minimum is somewhere on the underparameterized side, and the regularizer’s job is to find it.
Why was historically considered hopeless
Continue the right edge of Figure 2 toward . The variance contribution from each additional feature is approximately once the design matrix becomes nearly singular — the inverse of the smallest singular value of blows up. By we’re at variance per feature, and at the OLS estimator doesn’t exist: is singular and the normal equations have no unique solution.
Classical statistics’ answer to this was unambiguous: don’t go there. If a problem genuinely has , the options were three. (i) Get more data. (ii) Pick a smaller model class — feature selection, dimensionality reduction. (iii) Regularize so heavily that the effective capacity drops well below — ridge with , lasso with sparsity constraint . Hastie, Tibshirani, and Friedman’s Elements of Statistical Learning (2009), the canonical reference for the classical synthesis, devotes its high-dimensional chapter to exactly these three options.
What classical theory did not contemplate, except as a curiosity, was simply solving the underdetermined system for some specific — say the minimum-norm one — and using that as the predictor. The minimum-norm interpolator exists for any via the SVD pseudoinverse, and it has zero training error by construction. Classical theory’s reading of “zero training error in the high-dimensional regime” was unambiguous: this is the worst possible overfit. The empirical bias-variance decomposition past the threshold — variance crashing, bias not exploding — wasn’t on the radar because nobody was running the experiment.
What Belkin et al. (2019), Hastie et al. (2022), and Nakkiran et al. (2020) collectively demonstrated is that the minimum-norm interpolator generalizes anyway — sometimes as well as the classical U-curve minimum, often better in the data-poor / overparameterized regimes that modern ML actually inhabits. This is the surprise the topic is built around. The rest of §§3–9 explains why.
Where the classical story holds — and where it doesn’t
The bias-variance decomposition itself is unconditional — it’s just an application of the parallelogram law in — and holds for any estimator at any model size, including the minimum-norm interpolator past the threshold. What changes past the threshold is the behavior of the components, not the validity of the decomposition.
Three things break.
- Variance doesn’t keep growing. In the classical regime, variance grows roughly as for well-conditioned designs. Past the threshold, the variance of the minimum-norm interpolator scales as for — and decreases with . The intuition is that adding more features past the threshold gives the noise more directions to spread into, each contributing less individually. We make this precise in §6.
- Bias doesn’t drop to zero. With more parameters than data, an unbiased estimator of doesn’t exist — the minimum-norm interpolator shrinks the projection onto the data subspace and discards the orthogonal complement. The bias of the minimum-norm interpolator approaches as . Not zero, but bounded. This is the phenomenon §11 makes precise as “effective dimension.”
- Capacity-control recipes change meaning. Cross-validation still works (it’s a black-box procedure); SRM-style penalties don’t, because classical VC and Rademacher capacity terms become vacuous past the threshold — a class that interpolates every labeling pattern on the training set has trivially . The flatness and margin theories developed for deep nets are the modern substitutes, which §12 treats.
The classical U-curve is the left half of the picture. The spike at is the transition. The second descent past the threshold is the right half. Sections 3 through 9 build the right half from scratch.
The interpolation threshold
Linear regression setup
Fix notation. We have observations for where are feature vectors and are responses. Stack into matrix form: with rows , and .
We assume the linear data-generating model
where is the (unknown) true coefficient vector and is noise with and . The OLS estimator is .
When is invertible — which requires together with having full column rank — the unique minimizer is . When is singular, either because or because columns of are linearly dependent, the OLS optimization has infinitely many minimizers. For with rows of in general position, every with achieves zero training error. We need an additional principle to select one. The natural choice, motivated in §§4 and 9, is the minimum-norm interpolator
Definition 1 (Minimum-norm interpolator).
For and , the minimum-norm interpolator is
where is the Moore–Penrose pseudoinverse. When is invertible (so the constraint has the unique projection-form solution), reduces to the OLS estimator .
We use as the uniform notation from §4 onward.
The square design at : exact interpolation forces noise-fit
At the design matrix is square. For with independent continuous-distribution entries — Gaussian features being the canonical example — is almost surely invertible. The system has the unique solution
Two things are now visible from this expression.
- The estimator is unbiased. . No systematic error.
- The variance is governed entirely by . Conditional on , .
Expand with singular values . Then . The expected squared coefficient norm, which equals the trace of this covariance matrix, is
This sum is dominated by the smallest singular value . If is order , the trace is order and the noise amplification is modest. If is order for small , the trace is order and the amplification is huge.
For square iid Gaussian , the smallest singular value has the distribution analyzed by Edelman (1988): scales as in expectation, with substantial fluctuations. So is of order — enormous noise amplification, growing with sample size rather than shrinking.
The geometric reading: when is square and just barely invertible, amplifies the noise vector by along the direction of ‘s least-stable singular vector. Even when has typical Gaussian magnitude, has wild magnitude in that one direction. The fitted inherits the wildness, and the predicted inherits it at a random test point.
The unbiasedness is what makes this counterintuitive. We’re not biased, but our variance is so large that is useless. Classical estimation theory has names for this — minimax suboptimality at low signal-to-noise, the curse of unbiasedness in singular models — but the upshot is that we shouldn’t trust unbiasedness as a sufficient property near the threshold.
The condition-number blowup near the threshold
For , the condition number measures how singular the design matrix is. We want to know what looks like as varies with fixed.
The Marchenko–Pastur (MP) theorem, which we’ll meet properly in §5, gives the asymptotic answer. For iid features with finite variance, as with fixed, the empirical spectral distribution of converges to the MP density, which is supported on the interval
where . Taking square roots and rescaling,
At both endpoints contain : . The condition number . This is the analytic origin of the threshold spike. The MP density’s support degenerates to exactly at , and the integral diverges.
For finite the MP prediction is an excellent approximation away from , and Figure 3 (top panel) verifies this directly: the observed and overlay the MP predictions and across the full sweep. The V-shape at is unmistakable — and doesn’t quite reach zero at finite (it’s of order ), which is what saves the experiment from total numerical failure.
Translating into variance amplification: scales as — finite for , blowing up at . §6 turns this scaling into a closed-form analytic curve via integrals against the MP density.
The empirical risk spike: synchronized demonstration
Figure 3 makes the full chain visible. Three panels, all with on the x-axis and the interpolation threshold marked.
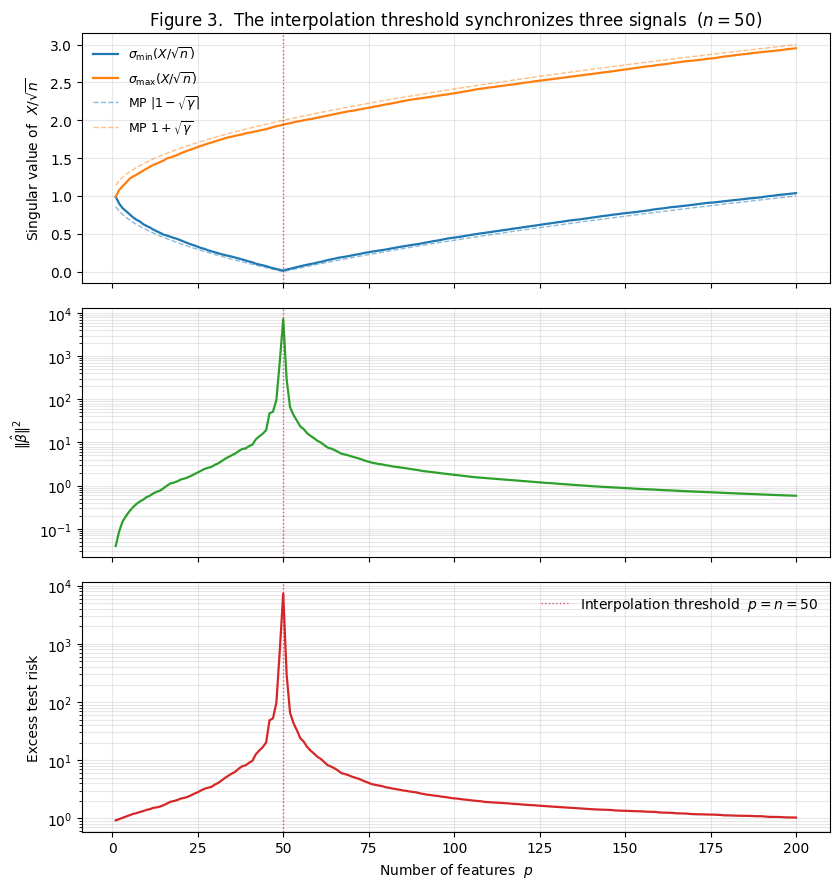
Three panels:
- Top: singular values. V-shapes down to a near-zero minimum at , matching the MP prediction across the full range. climbs smoothly from at to at , also matching MP. The agreement is surprisingly good at finite .
- Middle: coefficient norm. spikes by five orders of magnitude at — from at to at to at . The shape exactly mirrors from the top panel.
- Bottom: excess test risk. Test risk follows almost identically: a spike to at , recovery to at . This is the same data as §1 Figure 1; the new content is its alignment with the eigenvalue and coefficient-norm curves.
The synchronization is the §3 punchline. The interpolation threshold isn’t a special location in any abstract sense — it’s the unique value of where the design matrix becomes singular, the noise amplification factor blows up, the fitted coefficient norm explodes, and test risk follows. Every spike in the lower two panels of Figure 3 is mechanically caused by the dip in the top panel.
Two consequences worth stating now.
- The spike is intrinsic, not artifactual. Different random initializations, different basis choices, different sample sizes — anything that preserves the structural fact “design matrix becomes square at ” — will reproduce the spike. The only way to soften it is to explicitly avoid the singularity: ridge regularization adds to , which pushes away from zero and smooths the spike. §4 returns to this with the RidgelessVsRidge story.
- The mechanism is purely about . Bias barely changes near the threshold (we saw this in §2.4); the spike is all variance, all driven by . The post-threshold descent isn’t a separate phenomenon; it’s the eigenvalue distribution reopening past , taking the variance amplification back down with it.
Beyond the threshold: ridgeless regression
The wide regime: infinitely many zero-training-error solutions
When , the system has infinitely many solutions. Every satisfying this equation interpolates the training data exactly — zero training error, perfect memorization.
To see why there are infinitely many: with high probability has full row rank, so the linear map is surjective onto . The set of solutions to is then a translate of the null space of , , for any particular solution . The null space has dimension , so the solution set is a -dimensional affine subspace. We need a selection principle to pick one element.
The natural choice (Bartlett et al. 2020; Hastie et al. 2022) is the minimum-norm interpolator , for three reasons that come later in the topic.
- Algorithmic. Gradient descent on from converges to , with no explicit regularizer. §9 proves this. So any practitioner who runs vanilla SGD on an overparameterized linear model from zero init has, whether they chose it or not, ended up at the minimum-norm interpolator.
- Statistical. Under the isotropic feature model of §1.2 with , the minimum-norm interpolator achieves the lowest excess risk among interpolators in the limit with fixed. §6 proves this via the Hastie–Montanari–Rosset–Tibshirani 2022 closed form.
- Geometric. Minimum norm is the maximum-likelihood interpolator under an isotropic Gaussian prior on centered at zero. If we believe is approximately origin-centered, minimum norm is the natural choice.
The minimum-norm interpolator
Recall the SVD: where is orthogonal, is orthogonal, and is with singular values .
The Moore–Penrose pseudoinverse is , where is with diagonal entries . Two special cases:
- For with full column rank, .
- For with full row rank, .
The minimum-norm interpolator is then .
Two properties verified directly.
- It interpolates the training data. .
- It has minimum norm. Any other interpolator can be written with . We have , so , and .
SVD decomposition and the noise-amplification picture
Writing out the SVD form coordinate by coordinate makes the geometry explicit. Let be the right singular vectors and be the left singular vectors. Then
This says: project onto each left singular vector, divide by the corresponding singular value, and combine with the right singular vectors. Three things are now visible.
- Noise amplification per direction. The coefficient on is . If is small, a small noise component along produces a large coefficient on . This is the analytic origin of the §3 spike.
- Pseudoinverse vs inverse. For in the wide regime, has only nonzero singular values. The pseudoinverse simply omits the missing terms. The fitted coefficient vector lives in the -dimensional row space of , with zero component along the -dimensional null space.
- Ridge as singular-value shrinkage. The ridge estimator has the SVD form
The shrinkage factor equals when (large singular values are inverted normally) and when (small singular values are dampened toward zero instead of inverted). Setting replaces with , which is bounded for any . The noise amplification along the near-singular direction is fundamentally capped.
Ridgeless vs ridge: the spike, smoothed and overshrunk
Figure 4 shows the test-risk curves for ridge with several values of , all on the §1 setup (, isotropic Gaussian features, ). Each curve is computed by the same per-() SVD, reused across values via the singular-value shrinkage formula.
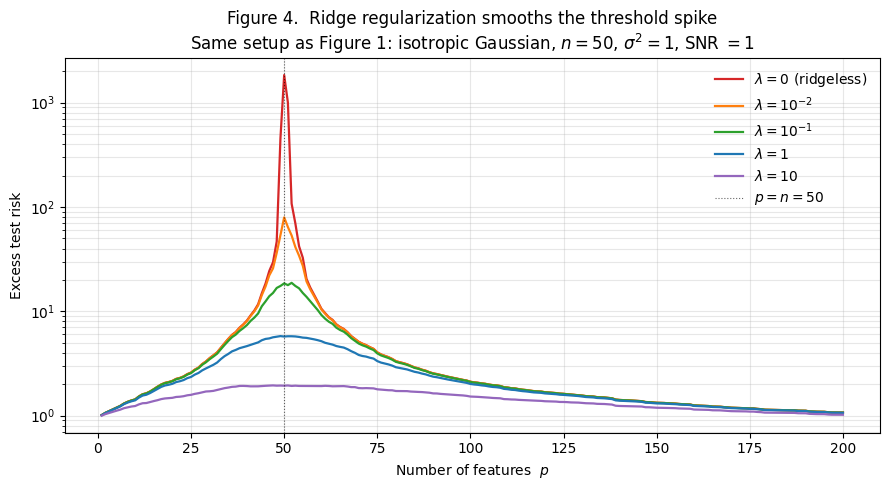
What we see:
- (ridgeless). The double-descent curve from §1. Spike at reaches .
- (light ridge). Spike attenuated by an order of magnitude (peak ). Outside a narrow neighborhood of the threshold, this curve sits on top of the ridgeless curve.
- . Spike eliminated. Curve has a smooth bump around that peaks at .
- . Spike gone entirely. Bump peaks at .
- . Heavy regularization. Curve is monotone in , with no bump — but the test risk floor is , twice the ridgeless minimum at the extremes. Overshrinkage has a cost.
Three takeaways.
- Ridge is the natural cure for the spike. Any removes the analytic singularity at . The spike is the unique signature of ridgeless regression.
- There’s no single that uniformly dominates. Light matches ridgeless except in a narrow neighborhood of the threshold; heavy overshrinks. The optimal depends on — and in the heavily overparameterized regime approaches zero, meaning ridgeless is optimal there.
- The min-norm interpolator is the ridgeless limit, viewed correctly. As , , recovering . So the question “why minimum-norm rather than some other interpolator?” has the answer: “because it’s what ridge gives, which is what every practical training procedure delivers in the overparameterized regime.”
The discussion above discharges the cross-site forward-pointer from formalStatistics: regularization-and-penalized-estimation : the smoothing of the threshold spike is the answer to “what does ridge do in the overparameterized regime?”
Random matrix theory bridge: Marchenko–Pastur
The Wishart matrix and its empirical spectral distribution
Fix the central object. Let have iid entries with mean and variance . The sample covariance matrix is , with eigenvalues .
The eigenvalues encode the geometry of the design. Large eigenvalues correspond to directions in feature space with high data variance, small eigenvalues to directions with little. The smallest eigenvalue governs noise amplification (§3.2), the largest governs the maximum singular value, and the ratio governs the condition number.
The empirical spectral distribution (ESD) is the probability measure , putting mass at each eigenvalue. The question is how behaves as . If the eigenvalues spread out without constraint we have no theory; if they concentrate on a deterministic density we have one we can integrate against.
The MP density and its support endpoints
The Marchenko–Pastur theorem (Marchenko and Pastur 1967) settles the behavior.
Theorem 1 (Marchenko–Pastur limit).
Let have iid entries with mean and variance . As with fixed, the empirical spectral distribution of converges weakly (almost surely) to the deterministic measure with density
supported on together with an atomic mass when .
We derive the support endpoints. The Stieltjes transform of is
The Stieltjes transform is analytic off the support, and the density can be recovered from it by the Stieltjes inversion formula .
The MP theorem says: in the limit with , where satisfies the self-consistent equation
Proof.
Multiply through and rearrange to get a quadratic in :
The discriminant is
which vanishes at . So outside (Stieltjes transform real-valued, no density) and inside (nonzero imaginary part, density lives).
Picking the branch with as , we get . For , taking and using :
Applying Stieltjes inversion,
which is the MP density. The atomic mass at for is the probability mass left over after integrates to on .
We skip the proof that . Bai and Silverstein (2010) §3.3 and Anderson, Guionnet, and Zeitouni (2010) §2.1 are the canonical references; Tao (2012) gives a streamlined version using the method of moments.
∎Bulk eigenvalues and the noise edge as varies
Three behaviors as varies through 1.
- (tall designs). The smallest support endpoint is . All eigenvalues are nonzero a.s., and the smallest is bounded away from zero. The noise amplification is finite, and the integral that determines the OLS variance converges. Classical regime.
- (square designs). The smallest support endpoint hits . The density diverges as — an eigenvalue is certain to be near zero in the limit. The integral diverges logarithmically. This is the analytic content of the spike.
- (wide designs). The smallest nonzero eigenvalue is again. The atomic mass at accounts for the eigenvalues that are identically zero by rank deficiency. But the variance integral over the nonzero spectrum is finite — the noise has somewhere to land that’s not arbitrarily near zero. This is what enables the second descent.
The eigenvalue density transitions continuously through , but the integral against the density passes through infinity. The density geometry is the double-descent geometry.
Numerical verification
Figure 5 verifies the MP theorem on finite samples. We draw with rows and varying , compute the eigenvalue spectrum of (or equivalently when , which captures only the nonzero eigenvalues), and overlay the analytic MP density on the empirical histogram.
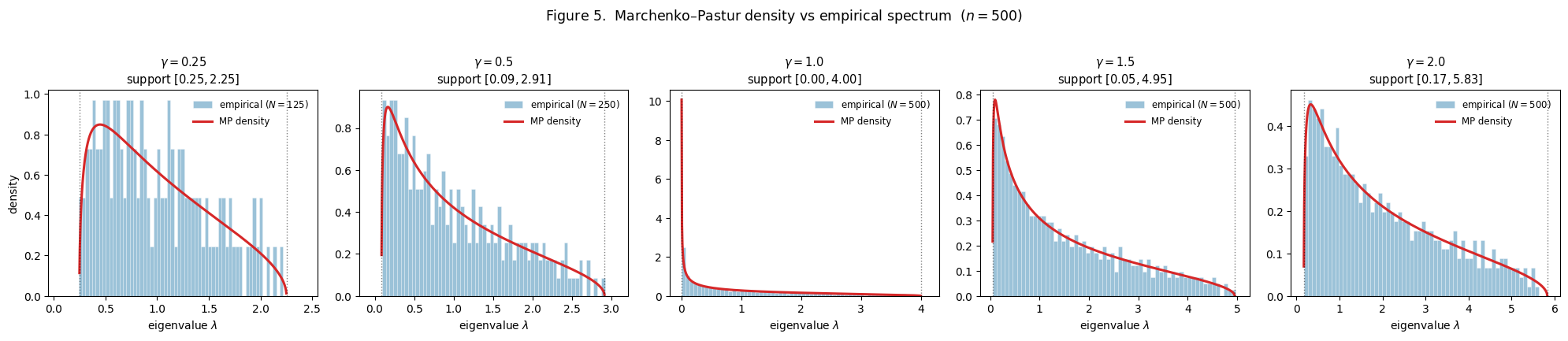
What we see across the five panels:
- . Support . Density bounded above; bulk sits in the middle of support.
- . Support . Density rises faster near as support stretches.
- . Support . Density diverges as . The dramatic concentration near is the singularity that produces the threshold spike.
- . Support . Support reopens.
- . Support . Density spreads wider; smallest nonzero eigenvalue is now well above zero.
The MP curves track the empirical histograms with no fitting — the density is fully determined by . The finite- agreement at is excellent.
The threshold is not a marginal case. The density at has an integrable singularity at , and the variance integral genuinely diverges. The finite- smoothing produces a finite spike, but the spike grows without bound as .
Asymptotic bias-variance under ridgeless OLS
Setup: isotropic Gaussian features, fixed signal-to-noise ratio
We switch to the well-specified Hastie–Montanari–Rosset–Tibshirani 2022 setup for the analytic theory. The difference from §1’s running example is small but matters: in §1 we fixed a single in the ambient dimension and let the model at size use only its first features (so the model is misspecified for ). In the well-specified Hastie setup, the true coefficient vector lives in — matching the model dimension — and the data are generated from precisely the model the predictor is fitting. The closed-form theorem we want lives in the well-specified setting; the misspecified version requires the additional bookkeeping of Belkin, Hsu, and Xu (2020) and Hastie et al. (2022) Theorem 3.
The well-specified setup:
- Features: with iid entries.
- Coefficients: with (signal strength).
- Response: with .
- Estimator: — ridgeless OLS, equal to the minimum-norm interpolator for .
- Test point: independent of training.
- Excess risk: .
The signal-to-noise ratio is the only nontrivial knob. By the rotational invariance of an isotropic Gaussian design, the direction of doesn’t matter — only does.
Theorem 1: the asymptotic risk
Theorem 2 (Hastie, Montanari, Rosset & Tibshirani (2022), Theorem 2).
Under the setup of §6.1, in the proportional asymptotic regime with fixed, the excess test risk converges almost surely to
Three immediate observations from the formula.
- The classical regime has zero bias (the model is well-specified and OLS is unbiased) and pure variance. The variance diverges as — this is the analytic spike.
- The interpolation regime has both contributions. The bias term comes from the minimum-norm interpolator’s projection onto a random -dimensional subspace of . The variance term shrinks as grows.
- The spike has structurally different sources on the two sides. Approaching from below, — pure variance, no bias. Approaching from above, — still pure variance (bias is bounded at ), but the variance now scales as rather than . The two limits are different functional forms.
Proof: bias and variance integrals against the MP density
Proof.
Throughout, expectations are over the joint distribution of . The excess risk decomposes via the bias-variance identity from §2.1: , using that .
Underparameterized regime (). Here . The estimator is unbiased. The variance contribution is
Let be the eigenvalues of . Then . The empirical mean converges almost surely to by the MP theorem.
This integral equals , the Stieltjes transform at the origin. Taylor-expanding the explicit formula around on the branch that converges to a finite value as :
So , and
Combining, .
Overparameterized regime (). Here . Expanding,
where is the orthogonal projection in onto the (random, -dimensional) row space of .
The bias contribution: the bias is where is the projection onto . Because has iid isotropic Gaussian rows, is a uniformly random orthogonal projection onto an -dimensional subspace of . By rotational symmetry, and . Therefore
The variance contribution:
using the cyclic identity . The matrix is . Its eigenvalues are the nonzero eigenvalues of , and by the dual MP picture they have asymptotic density on . The Stieltjes-transform computation gives . Therefore .
Combining bias and variance, . This completes the proof of Theorem 2.
∎The bias-variance crossover and the second descent
Figure 6 shows the analytic curve from Theorem 2 overlaid on an empirical Monte Carlo curve using the well-specified setup (, , ).
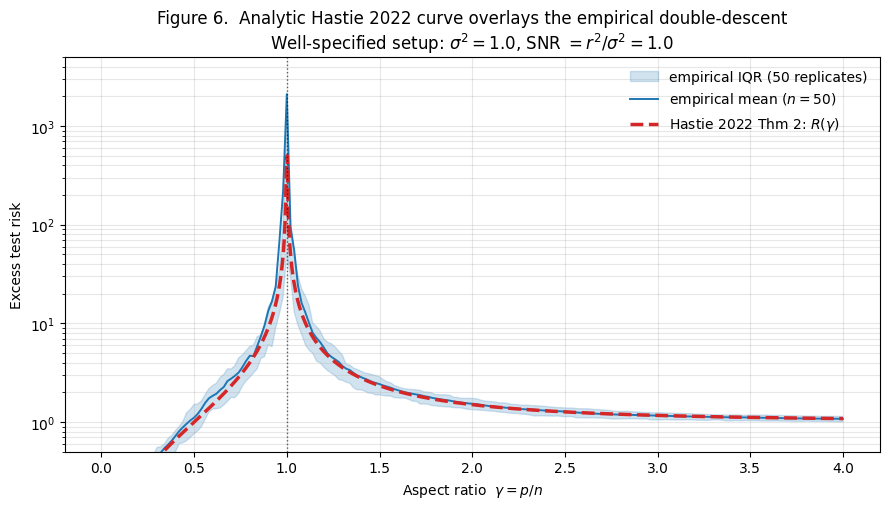
The agreement is excellent everywhere except in a narrow neighborhood of . Away from the threshold, empirical and analytic curves overlap to within Monte Carlo error (ratios in the range – across ).
Figure 7 shows the analytic decomposition of into bias-squared and variance components separately.
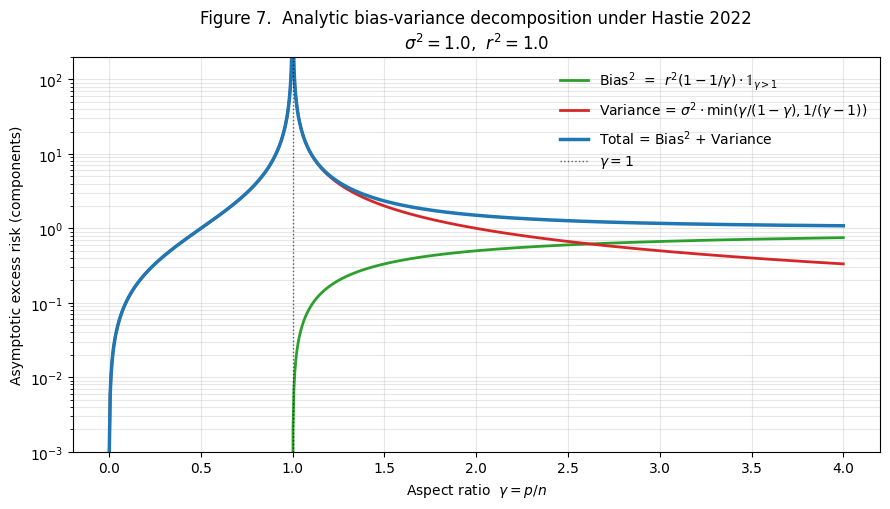
What the analytic decomposition reveals:
- Classical regime (). Bias-squared is exactly zero. All risk is variance. The variance is small at low and grows as .
- Interpolation threshold (). Variance diverges as from either side; bias jumps continuously through zero.
- Overparameterized regime (). Bias-squared grows monotonically from at to the asymptotic limit as . Variance falls monotonically from at to as .
- Crossover. For the setup in Figure 7, bias and variance curves cross at . The minimum of the total curve in the overparameterized regime sits at when , and the total is monotone-decreasing all the way to when .
Two final observations:
- The “double descent” name describes the unconditional curve , not the components. The bias is monotone in each regime; the variance is monotone in each regime; only their sum has the dramatic spike followed by descent.
- The Hastie 2022 formula tells us when ridgeless beats classical. At with our SNR, the overparameterized risk is . For the practitioner with fixed and a choice of how many features to include, the post-threshold curve often matches the classical floor and is more robust to model-size miscalibration — there’s no narrow optimum to miss.
Sample-wise vs model-wise double descent
The Nakkiran 2020 taxonomy
So far we’ve fixed and swept . That’s a sensible thing to do — when we’re tuning model architecture for a fixed dataset, is the knob we control. But it’s not the only sweep direction. Nakkiran et al. (2020) identified three axes along which double descent appears, each producing the same spike-at-interpolation-threshold curve:
- Model-wise double descent. Fix the training set (), sweep model capacity (). Spike at . This is what we’ve been studying in §§1–6.
- Sample-wise double descent. Fix the model (), sweep the training set size (). Spike at . More data can hurt in a window leading up to the threshold.
- Epoch-wise double descent. Fix everything else, sweep the number of training epochs. For overparameterized neural networks, test error shows a non-monotone curve as a function of training time. The linear theory of this topic doesn’t predict it directly; we sketch it briefly in §10.
What unifies the three is the interpolation threshold: the spike sits at the configuration where the model’s effective capacity is just barely sufficient to interpolate the training set. The classical intuition for the first two — “more parameters means more overfitting risk” and “more data means lower variance” — both fail in the same way near the same threshold, because what they’re really measuring is proximity to the boundary .
Model-wise: fix , sweep
The model-wise sweep is what we’ve been computing throughout. We fix the training set size (here ). We vary the model capacity from to large values. The aspect ratio varies from to . The Hastie 2022 curve from Theorem 2 applies: pure variance for , spike at , bias + variance for .
Figure 8(a) reproduces the picture as the left panel of a two-panel comparison. Empirical curve in blue overlays the analytic Hastie curve in red dashed.
Sample-wise: fix , sweep
Now invert. Fix the model capacity and vary the training-set size . Model capacity is fixed (here ). Training set size varies from small () to large (). The aspect ratio now varies from (very overparameterized) down to (well underparameterized). The Hastie 2022 curve still applies — but now we’re reading it backwards. We pass through at .
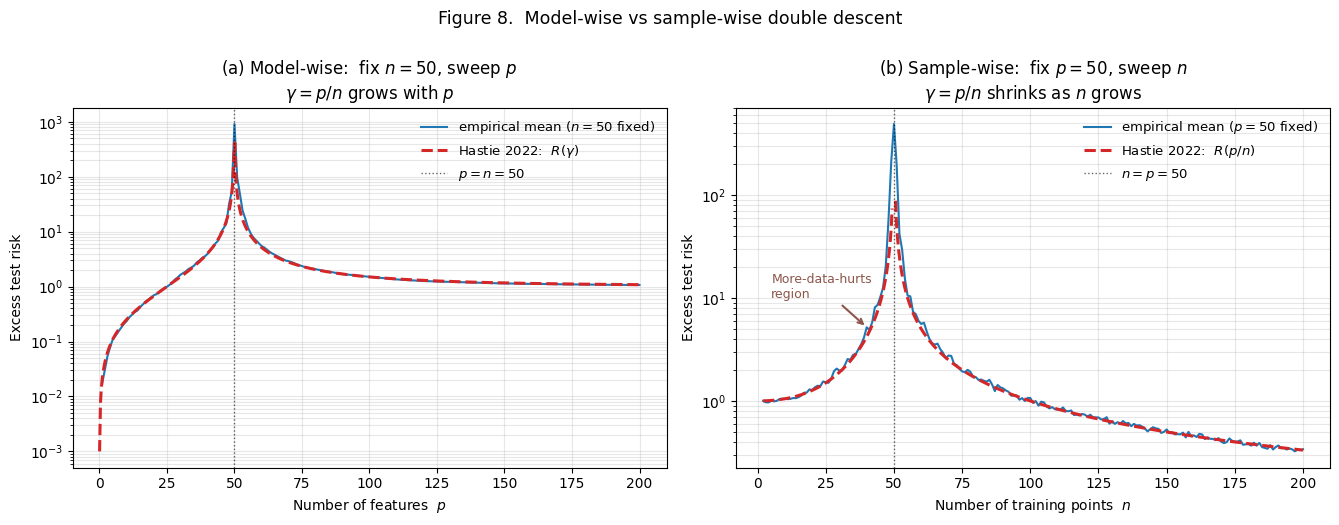
Reading the right panel left to right (small to large):
- small, large. Excess risk is . At with , empirical .
- grows, but stays below . Excess risk increases. Empirically: , , , .
- (the spike). Excess risk diverges. Empirically (at finite ): .
- grows past . Excess risk descends rapidly. Empirically: , , , , .
The -shaped curve and “more data can hurt”
The disorienting feature of Figure 8(b) is the non-monotone region: between (where ) and (where ), adding training points makes test error worse. Doubling the data, or quadrupling it, in this window doesn’t help — it hurts.
This is not a finite- artifact. The Hastie 2022 formula, extended to vary at fixed , predicts the same shape in the asymptotic limit:
derived by setting in the Hastie 2022 formula. The local minimum’s location: differentiating the branch with respect to and setting to zero, , so . For our setup with , — the curve is monotone-increasing from all the way to the spike. For higher SNR (), is positive and the wide-regime curve has a U-shape: a local minimum at , followed by ascent to the spike.
What this means for ML practice:
- There’s a regime where collecting more data is harmful. In our Figure 8(b) at , getting more training points pushes us to with excess risk increasing from to . The “data is always more valuable than features” instinct fails here.
- The threshold-vicinity is where this happens. Far from the threshold — or — more data is good. The pathology is concentrated in the band or so.
- Cures are the same as for model-wise. Explicit regularization smooths the spike for the sample-wise picture too. The threshold is a structural feature of the relationship between and — not a feature of either alone.
Beyond the linear theory, sample-wise double descent has been observed empirically in deep networks (Nakkiran et al. 2020, Figure 5).
Random features and the kernel limit
The random-features model
So far we’ve analyzed linear regression with isotropic Gaussian features. That setting is mathematically pure but artificial — in practice, “features” come from a feature map applied to some input space.
The setup. Let be input vectors, drawn iid from . Generate a random projection matrix with , and pick a nonlinear activation (ReLU, tanh). The random feature map is
with the rescaling chosen so that has typical entries of order . The training design matrix is with rows . We then fit ridgeless OLS in the random-feature space: , .
Two interpretations.
- Linear model as a special case. Taking , the random-features predictor is linear in . The effective “coefficients” live in , not — the linear case has effective dimension .
- Two-layer neural network with frozen first layer. A single-hidden-layer network with frozen first-layer weights at random initialization and trained second-layer weights is exactly the random-features predictor.
The random-features model has an interpolation threshold at , just as the isotropic Gaussian model did. Figure 9 shows what double descent looks like for three activation choices.
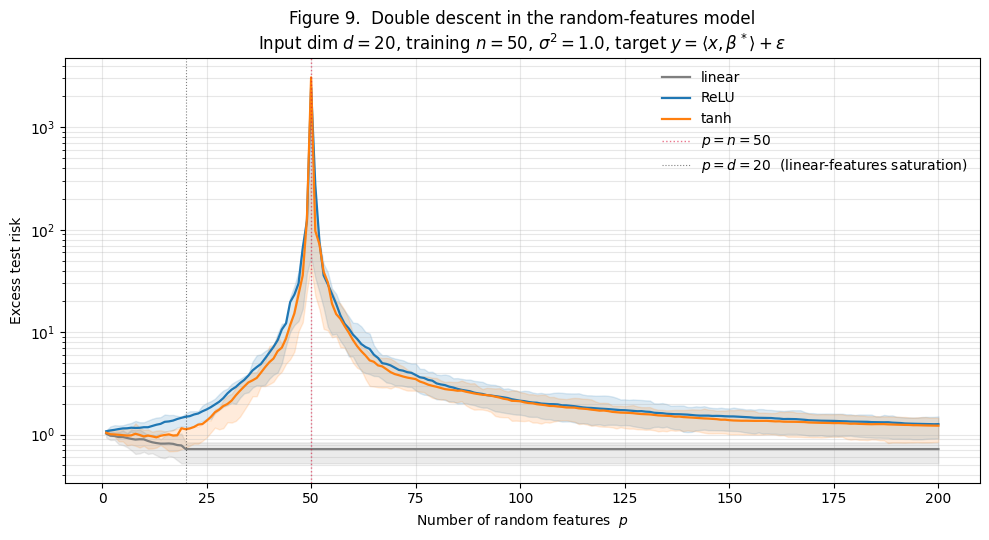
What the three curves reveal:
- Linear features (gray). Test risk descends from at to a floor of at , then is perfectly flat from to . No spike, no double descent. Linear random features span at most a -dimensional subspace.
- ReLU features (blue). Classical climb from to at . Spike to at . Descent past the threshold: at , at .
- tanh features (orange). Same shape as ReLU. Spike at is even higher (). Descent past the threshold to at .
The contrast is the §8 punchline. Random features only show double descent when the activation is genuinely nonlinear — that’s what gives the feature map enough “effective dimension” to fill out and trigger the threshold spike.
Mei–Montanari 2022: precise asymptotic risk
The analytic story behind Figure 9 comes from Mei and Montanari (2022), who extend the Hastie 2022 closed form to the random-features setting. Their setup is the one above, in the proportional asymptotic limit
This is a three-parameter limit. The relevant aspect ratio for the interpolation threshold is , which equals the from §§5–6. The spike sits at .
The Mei–Montanari Theorem 1 gives the asymptotic excess risk as an explicit function , where are explicit constants determined by the activation via its Hermite expansion:
The constant captures the linear component; captures the nonlinear residual. For specific activations:
- Linear : , . No nonlinearity. Reduces to Hastie 2022 with a flat region past .
- ReLU : , .
- tanh: similar values, slightly different numerics.
The qualitative content: the variance term diverges at (). For at fixed, the variance shrinks to zero — the over-parameterized “lazy” regime. The bias term has a “linear” part (proportional to ) that shrinks as grows and a “nonlinear” part (proportional to ) that approaches an irreducible floor. The “irreducible floor” is what Figure 9 shows: ReLU and tanh features at don’t quite reach the linear-target optimum because their nonlinearity introduces approximation error.
The lazy-training regime and the NTK connection
Why is random features a natural model for neural networks? Because of the lazy training regime, where wide neural networks behave like random-features predictors during training.
The argument (Jacot, Gabriel, and Hongler 2018; Lee et al. 2019; Chizat, Oyallon, and Bach 2019): consider a two-layer network with parameters initialized at random. During gradient descent training, in the wide limit , the change in becomes vanishingly small in relative terms. In the limit, the prediction at training time is linear in the parameters , with respect to a kernel called the neural tangent kernel (NTK):
In the wide limit, the random-features design matrix’s Gram matrix converges almost surely to . This is what makes random features the right model for deep-net generalization in the lazy regime — and what makes double descent in random features a faithful prediction of double descent in deep networks (§10).
The kernel-ridgeless limit as
The limit at fixed takes random features to the kernel ridgeless regressor , where is the kernel Gram matrix and .
The remarkable observation, going back to Liang and Rakhlin (2020): the kernel ridgeless regressor can generalize well despite achieving zero training error. The kernel has an effective complexity governed by the eigenvalue decay of , and when this effective dimension is small compared to , the kernel ridgeless regressor is well-regularized implicitly.
For ReLU features this kernel is the arc-cosine kernel (Cho-Saul 2009). The minimum at in Figure 9 — the second-descent floor — is the kernel-ridgeless test risk, not the linear-regression optimum.
Three implications for practice:
- The second descent isn’t unique to “neural networks.” Any kernel ridgeless regressor will show it.
- The kernel limit caps performance. The floor is fixed by the activation (via its induced kernel) and the target. Increasing beyond a few hundred delivers vanishing returns.
- The connection to deep networks is the lazy regime. Wide networks in their training trajectory stay close to the NTK linearization, so deep-net generalization in the wide-and-lazy regime is well-approximated by NTK-ridgeless theory.
Implicit regularization
Gradient descent on overparameterized linear regression with zero init
§§3–8 told a story about the estimator. §9 makes the algorithmic answer rigorous.
The setup. Consider gradient descent on the least-squares loss with iterates
where is the learning rate. For overparameterized problems (), the loss surface is convex with a continuum of global minima. Gradient descent picks one of them. Which?
Theorem 3 (Gradient descent's implicit regularization).
Suppose and has full row rank. Gradient descent with and any learning rate converges to the minimum-norm interpolator:
No explicit regularizer is needed. The minimum-norm choice arises automatically from the optimizer.
The iterates remain in : inductive argument
Lemma 1 (Iterates stay in the row space).
For all , .
Proof.
By induction on . Base case: trivially. Inductive step: assume . Then , and regardless of what’s inside the parentheses. So is the sum of two elements of , which is itself in .
∎The lemma is structurally important: the GD iterates never populate the -dimensional null space of . Whatever direction moves in, it moves within .
This is the algorithmic counterpart to the geometric structure of the minimum-norm interpolator from §4.2: is the unique interpolator in . If we can show that GD converges to some interpolator, Lemma 1 forces it to be .
Convergence to the minimum-norm solution
Proof.
Two steps.
Step (a): GD converges and reaches zero training loss. Write the SVD . The GD update (for any fixed point with ) is a linear recursion. In the eigenbasis of , each component shrinks by the factor at each step. Convergence requires , i.e., .
For any in this range, the components along nonzero singular directions converge geometrically. The null-space components aren’t affected by the update (the gradient has no null-space component), but by Lemma 1 they’re zero throughout. So converges to some interpolator with .
To see that GD reaches zero training loss, observe that has components which shrink by per step. After enough iterations, all components are below any tolerance. The training loss decays at linear rate (in iterations) governed by the slowest-shrinking mode, .
Step (b): the limit is . From Lemma 1, . From Step (a), satisfies . These two facts together pin down uniquely: the set of interpolators is the affine subspace , and the only element in this set that also lives in is itself. Therefore .
∎The proof says: the geometry of GD with zero initialization is identical to the geometry of the minimum-norm pseudoinverse. Both pick the unique interpolator that lives in the row space of , and they arrive at it by different routes.
Figure 10 verifies this empirically.
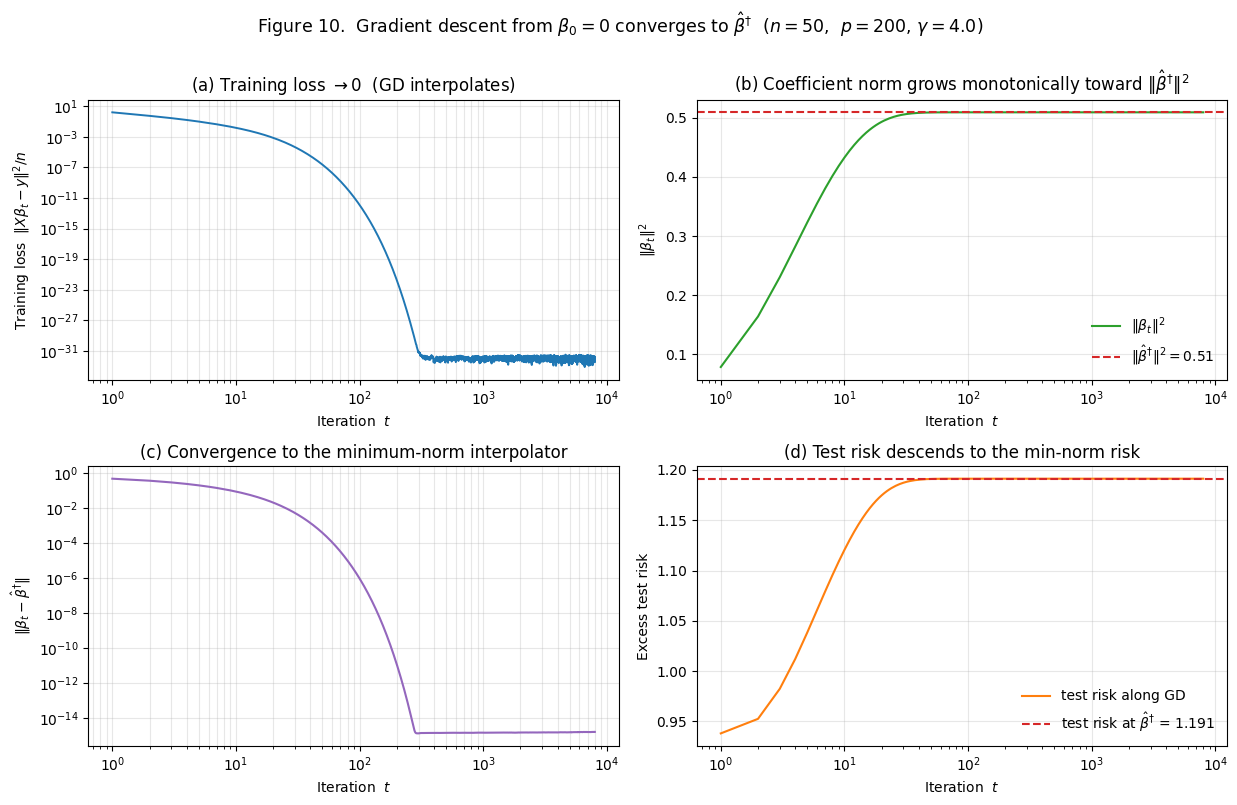
The four panels:
- (a) Training loss. Drops from at iteration 0 to by iteration 1000 — machine precision, exact interpolation.
- (b) Coefficient norm. Grows monotonically from at iteration 0 to at convergence. The horizontal dashed line shows — GD never overshoots it. This is “implicit shrinkage” visualized.
- (c) Distance to . Drops from to — machine zero.
- (d) Test risk. Descends from the initial test risk at to the test risk at . Note that test risk increases slightly through this trajectory — at this the early-stopped GD predictor is marginally better than the fully-converged one. This is the early-stopping phenomenon.
The empirical agreement is exact to machine precision. The final ‘s projection onto is — confirming Lemma 1 holds throughout the GD trajectory, not just in the limit.
The explicit-vs-implicit regularization duality
The result has a sharper formulation: gradient descent from zero initialization on the unregularized squared-error loss is equivalent to ridge regression with the limit . The trajectory is connected to ridge regression at a time-varying effective regularization , with and .
The precise statement (Yao, Rosasco, and Caponnetto 2007; Suggala, Prasad, and Ravikumar 2018): for GD with zero init,
derived by diagonalizing the linear recursion in the SVD basis. Compare with the ridge SVD formula from §4.3:
The shrinkage factors are different but qualitatively the same: small singular values are shrunk more aggressively than large ones. The “effective ridge regularization” of GD at time is approximately .
Three consequences for ML practice.
- Early stopping is implicit ridge regularization. Stopping GD at iteration gives a ridge-like estimator with effective . This is the formal version of “early stopping prevents overfitting” — it’s an implicit ridge penalty.
- Vanilla SGD in deep learning inherits this property in the lazy regime. For wide neural networks training in the lazy / NTK regime, the trained network at time is approximately a kernel-ridge regressor with as .
- Adam, momentum, and other optimizers change the implicit regularizer. Different optimizers correspond to different implicit regularizers. The choice of optimizer is a choice of implicit regularizer, even when no explicit penalty is in the loss.
The high-level point: the dichotomy between “regularized” and “unregularized” estimation is misleading in the overparameterized regime. Every numerical procedure that fits an overparameterized linear model performs some kind of regularization implicitly.
Deep double descent (sidebar)
This section is a sidebar — we step away from the linear theory and look at neural networks. Nakkiran et al. (2020) demonstrated that double descent appears in deep networks across three different sweep axes, and the threshold-spike-descent shape is qualitatively the same as in the linear case.
Width-wise, depth-wise, and epoch-wise double descent
Width-wise. Fix a deep-network architecture and a training set. Vary the width of the network. Train each width to convergence. Test error as a function of width has the double-descent shape.
Figure 11 reproduces width-wise double descent on a small CPU-budget demo: a single-hidden-layer MLP on an 8-dimensional regression target with 40% label noise. We sweep the hidden-layer width from 1 to 200, train each width to convergence with L-BFGS, and average test MSE over 5 replicates.
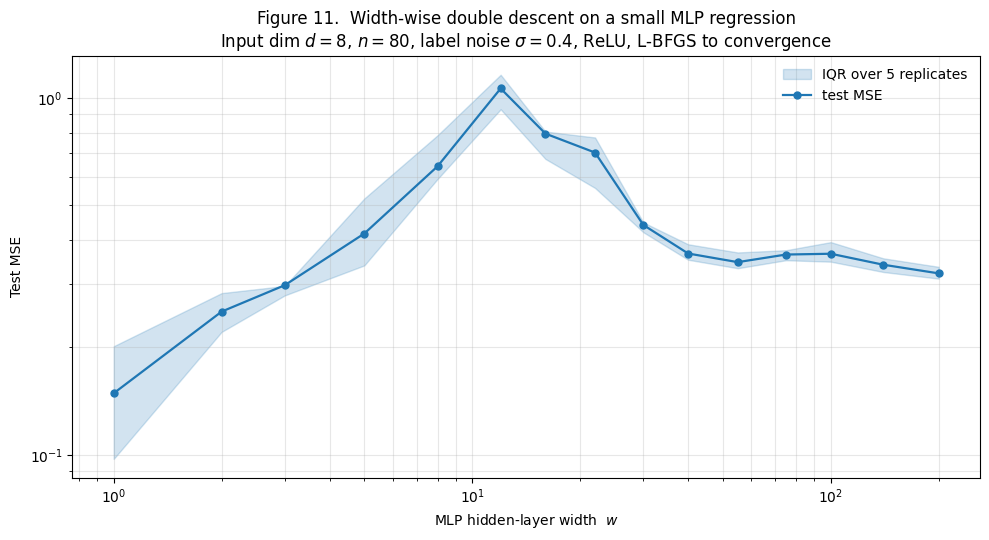
The shape: test MSE climbs from at width 1 to a peak of at width 12, then descends to by width 100. The peak sits where the training loss first reaches machine precision — where the network has just enough capacity to fit the noisy training set exactly.
Depth-wise. Fix the width and the training set, vary the number of layers. Same shape. Nakkiran et al.’s Figure 3 demonstrates this on ResNet variants on CIFAR-100.
Epoch-wise. Fix everything except training time. During training, test error shows a non-monotone curve: an initial descent, a rise around the epoch when training error first reaches zero, then a further descent.
What unifies the three axes is the interpolation threshold: whichever knob we vary, the spike sits at the configuration where the network is “just barely” interpolating the training set.
Effective vs nominal parameter counts
In the linear case the parameter count was unambiguous: was both the nominal number of coefficients and the effective model size. In a neural network, these come apart.
The nominal parameter count of a network with width , depth , and input dimension is roughly for moderate .
The effective parameter count is harder to define, but it’s typically much smaller than the nominal count for networks trained near interpolation:
- Activation sparsity. ReLU networks have many “dead” neurons. The effective width is the number of active units.
- Symmetries and degeneracies. Permutations of hidden units leave the network’s function unchanged.
- Spectral concentration of the Jacobian. The neural tangent kernel has a spectrum that decays rapidly. The effective rank of the training-time Jacobian is typically when .
The empirical consequence is what Figure 11 shows: the spike sits at width 12, not at “width = .” The network has ~120 nominal parameters at width 12 but somewhere closer to ~80 effective parameters interacting with the data — matching the training set size.
In deeper networks the gap is wider. ResNet-18 has 25M nominal parameters but its effective NTK rank on a typical training set is closer to . So "" is true nominally but the effective is closer to .
Open theoretical questions in the deep regime
- Feature learning vs lazy regime. The NTK / lazy analysis assumes weights don’t move much from random initialization. In the practical training regime weights move substantially and the network learns features. Whether double descent in the feature-learning regime is quantitatively the same as in the lazy regime is open (Yang and Hu 2021 for a survey).
- Architecture-specific spikes. The spike location depends on architecture in ways the linear theory doesn’t predict.
- Implicit-regularization gap. §9 proved that vanilla GD from zero init lands at the minimum-norm interpolator in linear models. The analog for neural networks does not in general land at the “minimum-norm” predictor.
- Optimization dynamics near the threshold. The spike often corresponds to training failures — networks that fail to interpolate within the iteration budget.
What the linear theory does and doesn’t predict
Linear theory predicts: the qualitative double-descent shape; the threshold’s structural location at the interpolation point; the asymmetry between regimes; the smoothing effect of ridge; the “more data can hurt” pathology.
Linear theory doesn’t predict: the exact location of the spike in nominal-parameter space; architecture-specific differences; behavior in the feature-learning regime; optimizer-specific implicit regularization; why some training runs land in “good” minima and others in “bad” ones at the same architecture.
The honest read: the linear theory is a remarkably accurate description of the lazy / NTK regime of deep networks, and a useful qualitative guide outside that regime. It explains why double descent exists and roughly where the spike sits; it doesn’t let us predict the spike’s exact location, height, or sensitivity to architectural choices.
Effective dimension
The eigenvalue spectrum of on a log scale
§§3–9 told the analytic story for isotropic Gaussian features. §10.2 introduced that what counts as "" in a neural network is less clean-cut than the nominal parameter count. §11 makes this precise in the linear setting: the effective dimension of a design matrix is the number of singular directions that are well-conditioned enough to participate in the pseudoinverse computation.
For isotropic features, the MP theorem tells us the eigenvalues concentrate in a tight band, with extreme values — a dynamic range of at most for moderate . With this is a few orders of magnitude at most.
For structured features — polynomial bases, kernel features, the features learned by a neural network — the spectrum can be radically different. We illustrate this in Figure 12.
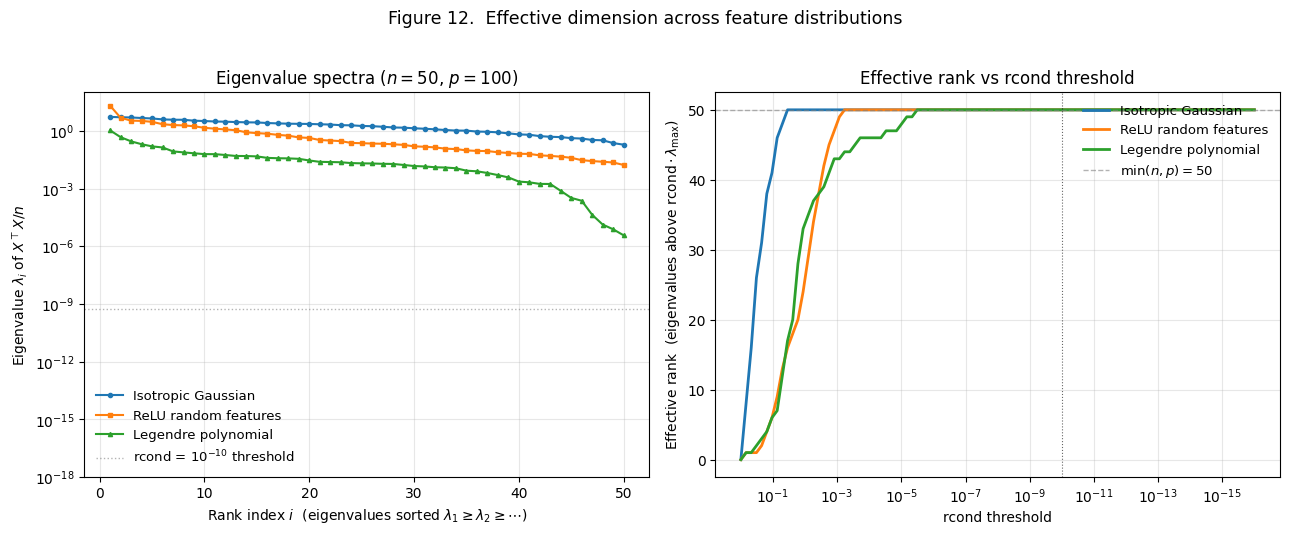
The left panel plots eigenvalues for three feature distributions at the same nominal size (, ):
- Isotropic Gaussian (blue). Spread over about one order of magnitude — from to . Dynamic range .
- ReLU random features (orange). A large (the bias direction) followed by a flatter bulk. Dynamic range .
- Legendre polynomial (green). From to , spanning more than 8 orders of magnitude. Dynamic range .
The right panel re-expresses the same data: for each rcond threshold, how many singular values sit above ?
The rcond-style spectral cutoff
The notion of “effective dimension” enters as soon as we implement ridgeless OLS via the SVD pseudoinverse:
def ols_via_svd(X, y, rcond=None):
if rcond is None:
rcond = max(X.shape) * np.finfo(float).eps
U, s, Vt = np.linalg.svd(X, full_matrices=False)
s_inv = np.where(s > rcond * s.max(), 1.0 / s, 0.0)
return Vt.T @ (s_inv * (U.T @ y))For any singular value below , the pseudoinverse sets the inverse to .
Definition 2 (Effective dimension).
The effective dimension of at threshold is
Three observations.
- rcond truncation is what makes the ridgeless pseudoinverse numerically well-defined at the threshold.
- rcond truncation is operationally the same as ridge regularization at . The §4.3 SVD formula for ridge replaces with . So ridge with behaves identically to rcond-truncated pseudoinverse.
- rcond is the “effective ” of vanilla numerical linear algebra. Any practitioner using
np.linalg.lstsqornp.linalg.pinvon an ill-conditioned design is implicitly applying this truncation.
Effective parameter count vs nominal
For an isotropic Gaussian design, the eigenvalue spectrum is bunched and the effective rank tracks across a wide range of reasonable rcond values. The blue curve in Figure 12’s right panel sits at for rcond from down to , then drops abruptly. The transition is sharp.
For structured designs the picture is qualitatively different. The Legendre polynomial curve drops continuously across a wide rcond range — at rcond = , effective rank is only about ; at , about ; at , about . Each decade of rcond buys a few more effective directions.
The implication: the “effective ” of a structured design at any practical rcond is much smaller than its nominal . For the Legendre features with and rcond around , the effective dimension is — well below the nominal and even below .
Why effective dimension can be small when
The deep-network connection. The NTK , viewed as an matrix, has an eigenvalue spectrum that decays rapidly. The effective rank of the NTK at any reasonable rcond is bounded independent of .
Three consequences:
- Wide networks can have small effective dimension. ResNet-18 has “effective ” close to .
- Generalization in overparameterized models is governed by effective dimension. The §6 Hastie 2022 risk uses the nominal , but for designs with rapidly decaying spectra, the effective governs the actual generalization behavior. When , the over-parameterized spike sits at , not .
- This unifies the empirical observation in §10. Figure 11’s peak at width 12 (~120 nominal parameters, ~80 effective parameters at ) is consistent with the linear-theory threshold prediction once we replace nominal with effective.
The honest read: the double-descent threshold sits at the point where effective dimension matches training-set size, not where nominal parameter count matches it. The linear theory in §§3–9 is the “effective dimension” theory in disguise — the isotropic Gaussian setup has effective dim exactly, so nominal and effective coincide and the threshold formulation is unambiguous.
Connections to PAC-Bayes and SRM
What changes in the modern reading of capacity control
The classical learning-theory bounds (§2.2) have the form
The capacity functional varies — VC dimension for binary classification, Rademacher complexity for general loss classes, KL-divergence to a prior for PAC-Bayes — but the structural claim is the same: the worst-case generalization gap over all hypotheses in is controlled by a complexity measure of .
This framework breaks in the overparameterized regime in two specific ways.
Way 1: The capacity term becomes vacuous past the threshold. A neural network class with width and depth has VC dimension at least for ReLU activations (Bartlett, Maiorov, and Meir 1998). For ResNet-50 on ImageNet, and , so the VC bound’s RHS is
The bound says the generalization gap is at most 17 with high probability. For a – loss bounded by 1, this is the trivial guarantee. The bound isn’t wrong — it’s just vacuous. Same conclusion for Rademacher-complexity bounds: for a class that can interpolate the training set, exactly.
Way 2: The worst-case framing doesn’t match the actual estimator. The bound holds for every simultaneously, but in practice we care about one specific . In the overparameterized regime, the optimizer doesn’t explore all of ; it follows a specific trajectory and lands at a specific predictor with specific properties.
Flat-minima and margin theories as substitutes
Modern bounds replace “capacity of ” with “complexity of the specific .” Two families.
Flat-minima bounds (Hochreiter and Schmidhuber 1997; Keskar et al. 2017; Dinh et al. 2017). Minimizers of the training loss in flat regions (low Hessian curvature) generalize better than minimizers in sharp regions. Empirically, SGD with small batch sizes finds flatter minima than large-batch SGD, and the flatter minima do generalize better. The mechanism: a flat minimum corresponds to a region of parameter space where small perturbations to don’t change the predicted function much. The “effective” model class around is small.
Margin-based bounds (Bartlett, Foster, and Telgarsky 2017; Neyshabur et al. 2018). For classification with margin , bounds of the form
where is a norm-based complexity of the specific predictor — typically the product of spectral norms of layer weights. The bound is per-predictor: change to a different , the bound changes. For interpolating predictors with large margin, can be moderate even at large nominal parameter count.
PAC-Bayes posterior concentration and double descent
PAC-Bayes is where the modern bounds connect cleanest to the classical SRM framework. From the PAC-Bayes bounds topic, the Catoni–McAllester family of bounds takes the form
where is a data-independent prior and is a posterior. The bound is tightest when is small.
For a network trained from initialization (Dziugaite and Roy 2017), take and . Then . The KL divergence is small when the trained weights are close to the initialization. For lazy-trained networks, this is precisely the case — has small norm, scaling as in the wide limit. The PAC-Bayes bound is non-vacuous and tight.
This is the bridge between classical SRM and modern overparameterized generalization. The SRM principle (“control the capacity”) becomes “find a posterior close to the prior.” Implicit regularization is what keeps the posterior concentrated; the PAC-Bayes bound is what translates that concentration into a generalization guarantee.
For the double-descent shape: the bound is tightest in the heavily overparameterized regime, where lazy training keeps small; loosest at the threshold, where the optimizer has just barely enough capacity to interpolate and the weights must move substantially. The spike is a regime where the PAC-Bayes posterior can’t concentrate.
The open landscape
- The feature-learning regime. Lazy training is the regime where PAC-Bayes and NTK analyses work. In practice, deep networks learn features in ways that depart from the lazy approximation. A satisfying generalization theory for this regime is open.
- Finite- constants. Asymptotic bounds capture the qualitative shape. The finite- constants are often loose by 10× or more, which makes the bounds quantitatively unreliable.
- Optimizer-specific predictions. Different optimizers correspond to different implicit regularizers. Existing PAC-Bayes bounds treat the optimizer as a black box; they don’t yet give differentiated predictions across optimizers.
- The “lottery ticket” phenomenon. Some random initializations are dramatically better than others (Frankle and Carbin 2019). A theory of “which initializations are winners” is missing.
- Real-data benchmarks. The closest validated correspondence is on synthetic datasets. For real-world data, the gap between “the theory works qualitatively” and “the theory predicts the next experimental result quantitatively” is wide.
The honest read: classical capacity-control theory is correct in its regime (underparameterized) but not the right framework for overparameterized models. PAC-Bayes with posterior-concentration arguments is the modern replacement.
Computational notes
Closed-form ridgeless via SVD pseudoinverse
The workhorse helper used in §§1–9:
import numpy as np
def ols_via_svd(X, y, rcond=None):
if rcond is None:
rcond = max(X.shape) * np.finfo(float).eps
U, s, Vt = np.linalg.svd(X, full_matrices=False)
s_inv = np.where(s > rcond * s.max(), 1.0 / s, 0.0)
return Vt.T @ (s_inv * (U.T @ y))Five things about this implementation matter.
The default rcond. for double precision. Matches NumPy’s np.linalg.lstsq(..., rcond=None).
The order of factors matters for cost. SVD has complexity . full_matrices=False is essential for the wide case.
The trailing rather than full matrix product. The pseudoinverse as a matrix-matrix product is ; via three matrix-vector products is . For this is a 1000× speedup.
Equivalence to ridge. The rcond truncation is operationally equivalent to ridge at .
Sanity checks. to within rcond-controlled precision, and ‘s projection onto should be zero.
Marchenko–Pastur simulation and analytic density
def sample_nonzero_eigs(n, gamma, rng):
p = int(round(gamma * n))
X = rng.standard_normal((n, p))
if p <= n:
S = X.T @ X / n
else:
S = X @ X.T / n
return np.linalg.eigvalsh(S)Singularity at . The density diverges as when . For numerical integration use scipy.integrate.quad with points=[0] to flag the singularity.
Verification by moments. The MP measure has , useful as a sanity check.
Random-features implementation in pure NumPy
def random_features(x, W, activation, d):
return activation(x @ W.T / np.sqrt(d))The normalization is load-bearing. Without it, the input to the activation has typical magnitude and the activation saturates.
Precompute features at max , slice for each model size. Regenerating at each value would change the random features and add noise to the sweep.
Matrix-free hot paths for interactive viz
The interactive viz components face a tension: the user wants the curve to update smoothly as sliders move, but the Monte Carlo sweep underlying the curve is .
Separate display and committed slider values. Render two values from each slider: displayValue updates on every onChange (for the visible label) and committedValue updates only on onMouseUp / onTouchEnd / onKeyUp (for the heavy recomputation).
Cache shared SVDs across cheap parameters. The §4 ridgeless-vs-ridge viz computes 5 values at each . All five share the same SVD of . Reuse via the shrinkage formula .
Hoist scratch allocations out of inner loops. Preallocate buffers and use in-place ops.
Reproducibility checklist
- Use NumPy’s
default_rng(seed), not the legacynp.random.seed. - Use a fresh
Generatorper Monte Carlo sweep, seeded explicitly. - Verify on small problems first.
- Always plot in log scale near the threshold.
- Use shared test sets when computing bias-variance decompositions.
- Apply the finite- correction to Bias² estimates: .
Connections and limits
What we still don’t know in the deep regime
Feature learning. The entire analytical apparatus of §§3–9 assumes either explicitly linear features or features that are random but fixed (§8). In actual deep-network training, features are learned. Mean-field analyses of two-layer networks (Mei, Montanari, and Nguyen 2018; Sirignano and Spiliopoulos 2020), neural-collapse phenomena (Papyan, Han, and Donoho 2020), depth-wise overparameterization theory (Allen-Zhu, Li, and Song 2019), and the effective-theory framework of Roberts, Yaida, and Hanin (2022) are the closest extant frameworks, but none yet predict double-descent curves with the precision of Hastie 2022 for the linear case.
Architecture sensitivity. The linear theory predicts the spike at . For real architectures, the spike’s location, height, and width all depend on the architecture in ways the theory doesn’t capture.
Quantitative finite- constants. Most of our analytic predictions hold in the limit . Constants in PAC-Bayes bounds, in margin bounds, in the spike-height predictions, all differ from empirical values by factors of 10× or more.
Initialization sensitivity. The “lottery ticket” phenomenon (Frankle and Carbin 2019) demonstrated that some random initializations are dramatically better than others. A theory of “good” initializations is missing.
Double-descent in other dimensions. Depth-wise double descent has its own analysis but no clean closed-form curve. Epoch-wise double descent has neither.
Discharged forward-pointers and cross-site reciprocity
This topic discharges one specific forward-pointer: formalStatistics: regularization-and-penalized-estimation on formalStatistics. The forward pointer from there to here was a promised treatment of ridge regression’s behavior in the overparameterized regime — specifically, how the limit relates to the minimum-norm interpolator and how explicit ridge smooths the threshold spike. §4 does exactly that.
Two backward pointers are worth noting.
To shipped formalML topics. §§2.2, 9.4, and 12 explicitly cite VC dimension, structural risk minimization, generalization bounds, and PAC-Bayes bounds. The cross-site relationship is one of “modern revision”: the classical theories give the right answer in the underparameterized regime and need substantive revision in the overparameterized regime.
To sister-site topics. The formalStatistics: linear-regression substrate is what every section of this topic builds on.
Honest limits of the linear theory
The theory is reliable on: the qualitative shape (threshold + spike + descent); the spike’s structural location at the interpolation threshold; the asymmetry between regimes; the smoothing effect of ridge; the “more data can hurt” pathology; closed-form bias-variance decomposition; the implicit-regularization equivalence between gradient descent and the minimum-norm interpolator.
The theory is unreliable on: the spike’s exact location in nominal-parameter space; quantitative spike height and width; behavior in the feature-learning regime; optimizer-specific predictions; the lottery-ticket phenomenon; cross-architecture predictions in deep networks.
The honest read: the linear theory developed here is the cleanest analytic picture of double descent, faithful to the underlying mechanism, and a useful qualitative guide to deep-network phenomena. It is not yet a quantitative prediction tool for production neural networks.
Where to go next inside formalML
The Bayesian connection (Gaussian processes, Bayesian neural networks, variational inference). The kernel limit of §8.4 connects directly to Gaussian-process regression. Bayesian neural networks formalize the “posterior over weights” picture of §12.3.
The NTK literature (a planned but not-yet-shipped formalML topic on neural tangent kernels). The lazy-training and NTK material we sketched in §§8 and 10 deserves a dedicated topic.
Optimization theory (stochastic-gradient MCMC, Meta-Learning (coming soon)). The implicit regularization story of §9 generalizes to other optimizers — SGD, Adam, AdaGrad — and each has its own “implicit prior.”
The closing image. We started with a textbook U-curve and the empirical observation that something different happens past it. We end with a fairly complete linear theory of the something-different, a connection back to the classical capacity-control framework, and an honest list of where we still don’t know what we’re doing. The U-curve isn’t wrong. The picture is wider than the U-curve. The work of the next decade is to close the gap between the wider picture’s qualitative correctness and quantitative predictions for the systems people actually build.
Connections
- SRM's central recommendation — control capacity to bound generalization error — depends on a uniform-convergence bound that becomes vacuous past the interpolation threshold (a class that interpolates every labeling has trivially d_VC ≥ n). §12 reads SRM as the right answer in the underparameterized regime and explains what replaces it past the threshold. structural-risk-minimization
- VC bounds for ReLU networks scale as Lw², making the uniform-convergence guarantee vacuous (>1) at production scale. §12.1 makes the calculation explicit and uses it to motivate flat-minima, margin-based, and PAC-Bayes alternatives. The §2.4 'capacity-control recipes change meaning' discussion is the practical consequence. vc-dimension
- The Rademacher-complexity bounds developed there are sharp in the underparameterized regime and become uninformative past the threshold because the empirical Rademacher complexity of an interpolating class equals 1/2 exactly. §12 connects the classical Rademacher story to the modern norm-based per-predictor bounds. generalization-bounds
- PAC-Bayes is the most direct modern replacement for VC and Rademacher capacity control in the overparameterized regime. §12.3 develops the Dziugaite–Roy posterior-concentration bound where the trained weights stay near the initialization in the lazy regime — the bound is non-vacuous when KL(Q‖P) is small, which is precisely what happens in the second-descent region. pac-bayes-bounds
- The high-dim regression topic introduces ridge and lasso as the canonical p ≫ n estimators. This topic answers the parallel question for ridgeless OLS — what happens when you simply solve Xβ = y for the minimum-norm solution past the interpolation threshold? §6's Hastie 2022 result is the high-dim regression analogue of the bias-variance phase transition. high-dimensional-regression
- The SVD pseudoinverse machinery from PCA is the operative tool of this topic. §4's β̂† = X⁺ y is computed via SVD; §11's effective-dimension story is read off the singular-value spectrum on a log scale. The rcond truncation and Vandermonde-conditioning gotcha both inherit from PCA's numerical-linear-algebra discussion. pca-low-rank
References & Further Reading
- paper Reconciling Modern Machine-Learning Practice and the Classical Bias-Variance Trade-Off — Belkin, Hsu, Ma & Mandal (2019) The paper that named 'double descent' and demonstrated the phenomenon across kernel regression, random forests, and neural networks. §1's framing follows their picture.
- paper Surprises in High-Dimensional Ridgeless Least Squares Interpolation — Hastie, Montanari, Rosset & Tibshirani (2022) The closed-form Annals of Statistics paper that supplies §6 Theorem 1. The well-specified-isotropic-Gaussian setup and the Marchenko–Pastur integrals are direct ports.
- paper Deep Double Descent: Where Bigger Models and More Data Hurt — Nakkiran, Kaplun, Bansal, Yang, Barak & Sutskever (2020) The deep-network demonstration paper. §§7 (sample-wise) and §10 (width/depth/epoch-wise) follow their taxonomy and reproduce the width-wise curve on a small MLP.
- paper The Generalization Error of Random Features Regression: Precise Asymptotics and the Double Descent Curve — Mei & Montanari (2022) The §8 random-features asymptotics. Hermite expansion of the activation produces (ζ, τ²) constants that determine bias and variance up to the interpolation threshold and the kernel-ridgeless floor.
- paper Distribution of Eigenvalues for Some Sets of Random Matrices — Marchenko & Pastur (1967) The 1967 founding paper of the limiting eigenvalue density for sample covariance matrices. §5.2 reproduces the Stieltjes-transform derivation; the support (1±√γ)² is the load-bearing fact.
- book Spectral Analysis of Large Dimensional Random Matrices — Bai & Silverstein (2010) The canonical textbook treatment of MP and its generalizations. §5 cites §§3.3 for the Stieltjes-transform machinery.
- book An Introduction to Random Matrices — Anderson, Guionnet & Zeitouni (2010) Alternative random-matrix reference. §2.1 covers MP via moments and via the resolvent method.
- book Topics in Random Matrix Theory — Tao (2012) Streamlined method-of-moments proof of MP. Useful entry point if Bai–Silverstein feels heavy.
- paper Eigenvalues and Condition Numbers of Random Matrices — Edelman (1988) The smallest-singular-value distribution for square iid Gaussian matrices used in §3.2 to derive the spike's σ²n² scaling.
- paper Benign Overfitting in Linear Regression — Bartlett, Long, Lugosi & Tsigler (2020) Sharp characterization of when ridgeless OLS generalizes despite interpolating — depends on the decay of the population covariance spectrum. §11's effective-dimension picture is the simplified version.
- paper Does Data Interpolation Contradict Statistical Optimality? — Belkin, Rakhlin & Tsybakov (2019) Proof that interpolating kernel-ridgeless regression can be minimax-optimal under specific spectral decay conditions — the theoretical companion to Liang–Rakhlin.
- paper Just Interpolate: Kernel 'Ridgeless' Regression Can Generalize — Liang & Rakhlin (2020) Generalization analysis of kernel-ridgeless regression. §8.4's claim that the p → ∞ floor of random features is the kernel-ridgeless test risk follows from this paper.
- paper Two Models of Double Descent for Weak Features — Belkin, Hsu & Xu (2020) Closed-form misspecified case used in §1's running example — the Belkin–Hsu–Xu setup with β* in the ambient ℝ^{P_max} and the model using only the first p features.
- paper Optimal Regularization Can Mitigate Double Descent — Nakkiran, Venkat, Kakade & Ma (2021) Theoretical and empirical demonstration that tuning ridge optimally can remove the threshold spike — formalizes §4.4's 'no single λ uniformly dominates' observation.
- paper Neural Tangent Kernel: Convergence and Generalization in Neural Networks — Jacot, Gabriel & Hongler (2018) The founding NTK paper. §8.3 introduces the lazy-training regime and the equivalence between wide-net training and kernel-ridgeless regression in the NTK.
- paper Wide Neural Networks of Any Depth Evolve as Linear Models Under Gradient Descent — Lee, Xiao, Schoenholz, Bahri, Novak, Sohl-Dickstein & Pennington (2019) Rigorous deep-net version of the NTK linearization — used in §10's lazy-vs-feature-learning discussion.
- paper On Lazy Training in Differentiable Programming — Chizat, Oyallon & Bach (2019) Defines the lazy training regime precisely. §8.3 follows their formalism for when wide networks behave like random-features predictors.
- paper Tensor Programs IV: Feature Learning in Infinite-Width Neural Networks — Yang & Hu (2021) Survey of feature-learning vs lazy regimes in infinite-width networks. §10.3 cites this as the state of the art on what the linear theory does not yet predict.
- paper Kernel Methods for Deep Learning — Cho & Saul (2009) The arc-cosine kernel induced by ReLU random features — the kernel limit of the §8 setup.
- paper Scaling Description of Generalization with Number of Parameters in Deep Learning — Geiger, Spigler, d'Ascoli, Sagun, Baity-Jesi, Biroli & Wyart (2020) Physics-style scaling theory of the double-descent curve in deep networks; corroborates the linear-theory predictions for the wide regime.
- paper The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks — Frankle & Carbin (2019) The 'lottery ticket' phenomenon — some initializations dramatically outperform others. §14.1's honest-limits discussion flags this as open.
- paper A Mean Field View of the Landscape of Two-Layer Neural Networks — Mei, Montanari & Nguyen (2018) Mean-field PDE characterization of two-layer network SGD dynamics — feature-learning regime analog of NTK.
- paper Mean Field Analysis of Neural Networks: A Law of Large Numbers — Sirignano & Spiliopoulos (2020) Companion mean-field law of large numbers result; pairs with Mei–Montanari–Nguyen as the feature-learning theoretical framework.
- paper Prevalence of Neural Collapse during the Terminal Phase of Deep Learning Training — Papyan, Han & Donoho (2020) Empirical discovery of neural collapse — class-mean simplex equiangular tight frame at the terminal phase. §14.1 cites as a phenomenon the linear theory does not yet predict.
- paper A Convergence Theory for Deep Learning via Over-Parameterization — Allen-Zhu, Li & Song (2019) Polynomial-time SGD convergence for L-layer over-parameterized networks (FC, CNN, ResNet) — the depth-wise analog of the width-wise overparameterization theory cited in §14.1.
- book The Principles of Deep Learning Theory: An Effective Theory Approach to Understanding Neural Networks — Roberts, Yaida & Hanin (2022) Effective-theory / 1/width-expansion treatment of deep networks; the most complete textbook treatment of beyond-NTK feature learning.
- paper On Early Stopping in Gradient Descent Learning — Yao, Rosasco & Caponnetto (2007) Original early-stopping-as-implicit-regularization result. §9.4 ports their effective-λ ≈ 1/(ηt) formula.
- paper Connecting Optimization and Regularization Paths — Suggala, Prasad & Ravikumar (2018) Refines the GD-vs-ridge correspondence — the §9.4 SVD formula for β_t and its comparison to β_λ comes from here.
- paper The Marginal Value of Adaptive Gradient Methods in Machine Learning — Wilson, Roelofs, Stern, Srebro & Recht (2017) Empirical demonstration that different optimizers correspond to different implicit regularizers — the §9.4 'optimizer choice is regularizer choice' claim.
- paper Flat Minima — Hochreiter & Schmidhuber (1997) The original flat-minima paper. §12.2 develops the modern reading.
- paper On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima — Keskar, Mudigere, Nocedal, Smelyanskiy & Tang (2017) Empirical evidence that small-batch SGD finds flatter minima that generalize better — §12.2 cites for the sharp-vs-flat distinction.
- paper Sharp Minima Can Generalize for Deep Nets — Dinh, Pascanu, Bengio & Bengio (2017) Reparameterization counterexample to the sharp-minimum-bad picture — caveats the §12.2 story without overturning it.
- paper Spectrally-Normalized Margin Bounds for Neural Networks — Bartlett, Foster & Telgarsky (2017) Per-predictor norm-based generalization bound using product of layer-spectral norms — §12.2's margin-based bound.
- paper A PAC-Bayesian Approach to Spectrally-Normalized Margin Bounds for Neural Networks — Neyshabur, Bhojanapalli, McAllester & Srebro (2018) PAC-Bayes flavor of the Bartlett-Foster-Telgarsky bound — connects §12.2 (margin) to §12.3 (PAC-Bayes posterior).
- paper Computing Nonvacuous Generalization Bounds for Deep (Stochastic) Neural Networks with Many More Parameters Than Training Data — Dziugaite & Roy (2017) The PAC-Bayes-with-Gaussian-prior-around-initialization construction used in §12.3 — first non-vacuous bound at deep-net scale.
- book The Nature of Statistical Learning Theory — Vapnik (1995) Canonical SRM textbook reference cited throughout §2.2 and §12.
- paper On the Uniform Convergence of Relative Frequencies of Events to Their Probabilities — Vapnik & Chervonenkis (1971) The 1971 VC-dimension founding paper, cited at §2.2 as the source of the uniform-convergence framework.
- paper Neural Networks and the Bias/Variance Dilemma — Geman, Bienenstock & Doursat (1992) The classical reference for the bias-variance U-curve picture revised in §1.1.
- book Neural Network Learning: Theoretical Foundations — Anthony & Bartlett (1999) VC-dimension for neural networks — used at §12.1 for the L w² bound.
- paper Almost Linear VC-Dimension Bounds for Piecewise Polynomial Networks — Bartlett, Maiorov & Meir (1998) Sharper VC bound for ReLU networks — §12.1's vacuity calculation depends on this scaling.
- book The Elements of Statistical Learning: Data Mining, Inference, and Prediction — Hastie, Tibshirani & Friedman (2009) Canonical synthesis of the pre-double-descent classical picture. §2.3 cites the high-dimensional chapter for the three classical remedies (get more data / smaller model / heavy regularization).
- book Concentration Inequalities: A Nonasymptotic Theory of Independence — Boucheron, Lugosi & Massart (2013) Reference for the concentration substrate underlying every uniform-convergence claim in §§2 and §12.