Structural Risk Minimization
The framework for choosing model complexity from data: penalize-and-pick across a nested hypothesis-class family, with Vapnik VC, Bartlett–Mendelson Rademacher, AIC/BIC/MDL, PAC-Bayes, and cross-validation as parallel instantiations of the same oracle inequality
Motivation: why capacity control matters
The fixed-class ERM trap
Empirical risk minimization (ERM) — picking the hypothesis that minimizes training error — is the foundational learning algorithm, and it behaves as advertised as long as the class is small enough that uniform convergence kicks in (the Fundamental Theorem of Statistical Learning from PAC Learning is the formal statement). But small enough is doing all the work. If is too small, we can’t represent the regression function well and bias dominates. If is too rich, we fit the noise and variance dominates. The whole game in learning theory is navigating this trade-off, and the irritating fact is that we can’t navigate it by choosing upfront: the best class to run ERM on depends on the data we haven’t seen yet — the sample size, the noise level, the smoothness of the target.
Make this concrete. Fit polynomials to noisy points drawn from . Degree-1 polynomials underfit; they can’t bend. Degree-15 polynomials interpolate the noise and oscillate wildly between data points. Somewhere in between is a degree that captures the smooth structure without chasing the wiggles. ERM on gives us a bad linear fit; ERM on gives us a wild oscillator. ERM is the wrong question. The right question is which class should we run ERM on?
Bias and variance as functions of capacity
Fix a regression target and a noise process with and . For a nested sequence of classes , let be the ERM in on a sample of size . The pointwise mean-squared test error against a fresh decomposes as the usual bias-variance identity (see formalStatistics: linear-regression for the parametric derivation):
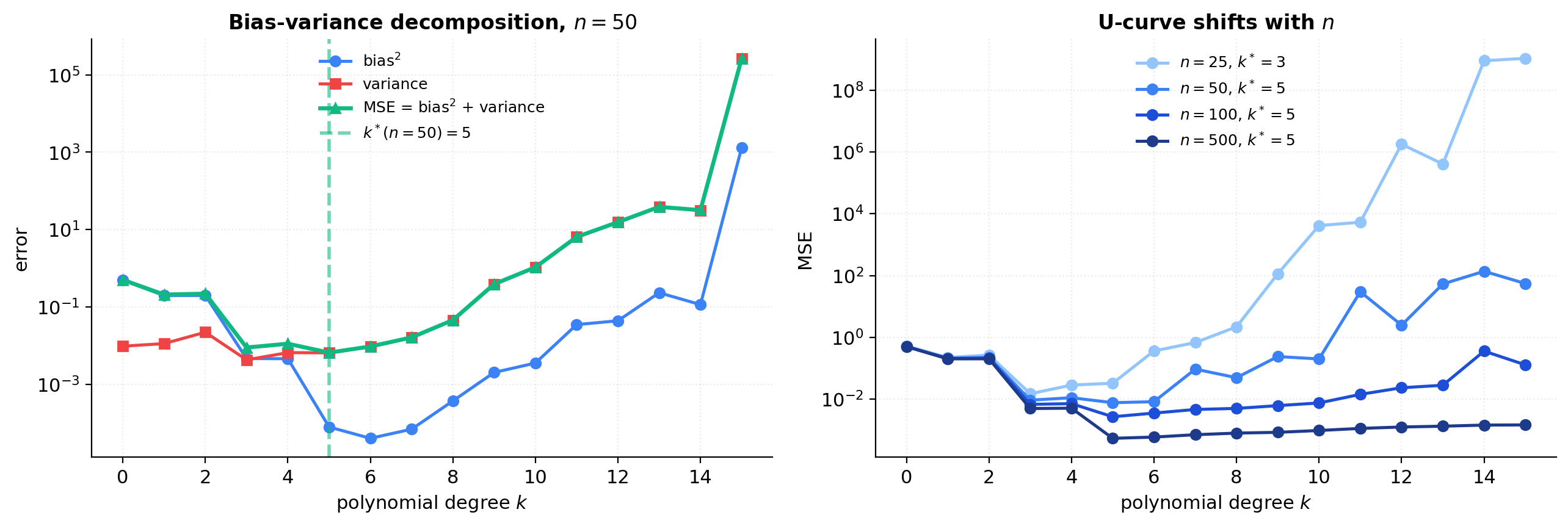
where the expectation is over the training sample and the fresh noise , and is the irreducible noise floor. The error against the regression function alone — — drops the term and is just bias variance. Two observations carry the section. Bias is monotone non-increasing in : a larger nested class can only approximate at least as well as a smaller one. Variance is monotone non-decreasing in : a richer class has more freedom to chase noise, so moves around more across resamplings of . Add them and integrate over to get the expected MSE; the result is a U-curve in .
The minimum of that U-curve — the true optimal — is what we’d pick if we could see the population. The problem is that we can’t; the training error is monotone non-increasing in (more flexibility never hurts in-sample) and bottoms out at zero by interpolation once is large enough. Empirical risk alone tells us a strictly wrong story about how to pick .
Why the “true” optimal capacity depends on
The U-curve isn’t fixed; it shifts with . For ordinary least squares with parameters, the variance term at degree scales like — the textbook Gauss–Markov consequence ( formalStatistics: linear-regression derives it). Doubling halves the variance contribution without touching the bias, so the U-curve flattens on the right and the optimum shifts up: with more data, we can afford more complexity.
This is the central reason no fixed choice of works across problem sizes. A degree-3 ERM that’s near-optimal at leaves bias on the table at ; a degree-9 ERM that’s near-optimal at overfits catastrophically at . The optimal capacity is a function of , so the model class itself has to be chosen as a function of the data.
SRM in one paragraph: penalize-and-pick
Structural Risk Minimization (SRM) is the recipe for choosing from data. (1) Fix in advance a nested family , ordered by increasing capacity. (2) For each , define a capacity-dependent penalty that grows with the capacity of and shrinks with . (3) Pick the class that minimizes training error plus penalty, and return , the ERM on :
The penalty plays the role of a stand-in for the (unobservable) variance. When it’s calibrated correctly — meaning the penalty upper-bounds the gap with probability uniformly across — the picked class provably tracks as grows. The rest of this topic is about how to calibrate the penalty (VC dimension in §4, Rademacher complexity in §5, PAC-Bayes in §9) and what the trade-offs are.
The nested-family setup
Definition: nested hypothesis-class family
A nested hypothesis-class family is a sequence of hypothesis classes indexed by , satisfying two conditions: nesting ( whenever ), and capacity monotonicity (a capacity functional — VC dimension, Rademacher complexity, or effective degrees of freedom — non-decreasing in with ).
Definition 1 (Nested hypothesis-class family).
A nested hypothesis-class family is a sequence of hypothesis classes with whenever , equipped with a capacity functional that is non-decreasing in with as . The ambient class is .
SRM never runs ERM on ; it always runs it on a finite class chosen from the family. Older Russian-school literature (Vapnik 1995) calls a nested family a filtration of the ambient class; the word is borrowed from probability theory and refers to the same object.
The indexing doesn’t have to be discrete — continuous-parameter families like RKHS norm balls are nested in and admit the same SRM analysis; this is the soft-SRM view we’ll formalize in §6. The choice of which nested family to use is a structural modeling decision that happens before seeing the data — the analog of choosing a parametric model in classical statistics. SRM picks from the family, not the family itself. Picking the family poorly is a different (and unaddressed) failure mode.
Canonical examples
Four families recur throughout the topic and across the broader ML literature.
Polynomials by degree. , the toy from §1. The capacity is — the dimension of the parameter space; for the threshold-classification variant of the same family, the VC dimension is also . This is the example we’ll use for all numerics through §11.
SVMs by inverse margin. , the large-margin family from Vapnik (1995). Larger means a smaller class — the linear classifiers are restricted to those that separate with margin at least . Capacity scales as for the worst-case Rademacher bound, independent of input dimension. This is the celebrated dimension-free property that motivates kernel methods, and it anchors §12.1.
Neural networks by width. . The nesting is honest — a width- net is a special case of a width- net by zeroing out the last neuron — but the classical capacity measures are loose enough that the SRM bound is uninformative for any realistic deep net. This is the family where classical theory breaks (§12.2–12.4) and where implicit regularization takes over.
RKHS norm balls. For a reproducing-kernel Hilbert space with kernel , the family is nested in , with empirical Rademacher complexity (Bartlett and Mendelson 2002). The squared-norm penalty implements SRM on in soft form — the §7.1 connection.
Others fit the same template — decision trees by depth (with pruning), boosted ensembles by round count, sparse linear models by -norm. The unifying picture is an indexed family of classes, monotone in some capacity functional, with the index the free parameter the algorithm gets to set.
Capacity measures: VC dimension, Rademacher complexity, effective DoF
Different SRM bounds need different capacity functionals. Three are standard, and the choice between them in a specific bound has both theoretical and practical consequences.
VC dimension (). For binary classification, defined as the size of the largest set can shatter — fully developed in VC Dimension and introduced in PAC Learning. VC dimension is a distribution-free, worst-case measure: it captures the largest possible generalization gap over all data-generating distributions. The Vapnik-style SRM bound (§4) uses VC dimension — universal but typically loose.
Rademacher complexity (, ). Defined as where are i.i.d. Rademacher (uniform on ); the population version takes a further expectation over (Generalization Bounds). Rademacher complexity is distribution-dependent — it sees the actual training sample — and is typically sharper than VC dimension when doesn’t shatter the data the distribution puts mass on. The Bartlett–Mendelson SRM bound (§5) uses it.
Effective degrees of freedom. For linear smoothers — least squares, ridge, kernel smoothers — the effective DoF is . For ordinary least squares with parameters this equals exactly; for ridge regression with penalty it’s , which is strictly less than for and decreases as grows. Effective DoF is the capacity functional underlying AIC, BIC, and the SRM-as-regularization story in §7; it’s specific to linear or near-linear estimators but is the practitioner’s everyday measure.
The three are related but not interchangeable. For a class of VC dimension , the worst-case Rademacher complexity satisfies — a Sauer–Shelah consequence. For our polynomial-regression toy, all three measures grow linearly in , which is why the same SRM picture works regardless of which one we use. For richer model classes — especially deep nets — they diverge sharply, which is part of §12’s story.
What goes wrong with non-nested families
Some natural model families aren’t nested. The clean example is -nearest neighbors: the class of -NN rules indexed by neighbor count is not nested under inclusion — a 3-NN rule is not a special case of a 5-NN rule. Decision trees indexed by depth are nested under pruning; trees indexed by leaf count typically are not. SVMs with different kernels (linear, RBF, polynomial) form a discrete unordered set, not a chain.
The fix is to drop the literal-inclusion requirement and keep only the capacity-indexed part. Given any countable indexed family with capacity monotone non-decreasing, the union-bound argument that produces the SRM penalty (§3) goes through unchanged — we never actually used in the derivation, only that we’d allocated a per-class confidence budget with . The same SRM estimator is well-defined, and the same oracle inequality (§3.3) holds with the same proof.
In Vapnik’s original formulation the families are nested for cleanliness, but everything generalizes to a capacity-indexed sequence (Shawe-Taylor et al. 1998 treat the data-dependent and non-nested cases explicitly). The cost of relaxing nesting is interpretive, not formal: the bias term doesn’t decompose monotonically when classes overlap unpredictably, so the “more data lets us afford more capacity” story becomes less crisp. For most practical applications — degree-indexed polynomials, depth-indexed trees, width-indexed nets, -indexed SVMs — the families are nested and the cleaner version applies.
Visualizing the polynomial ladder
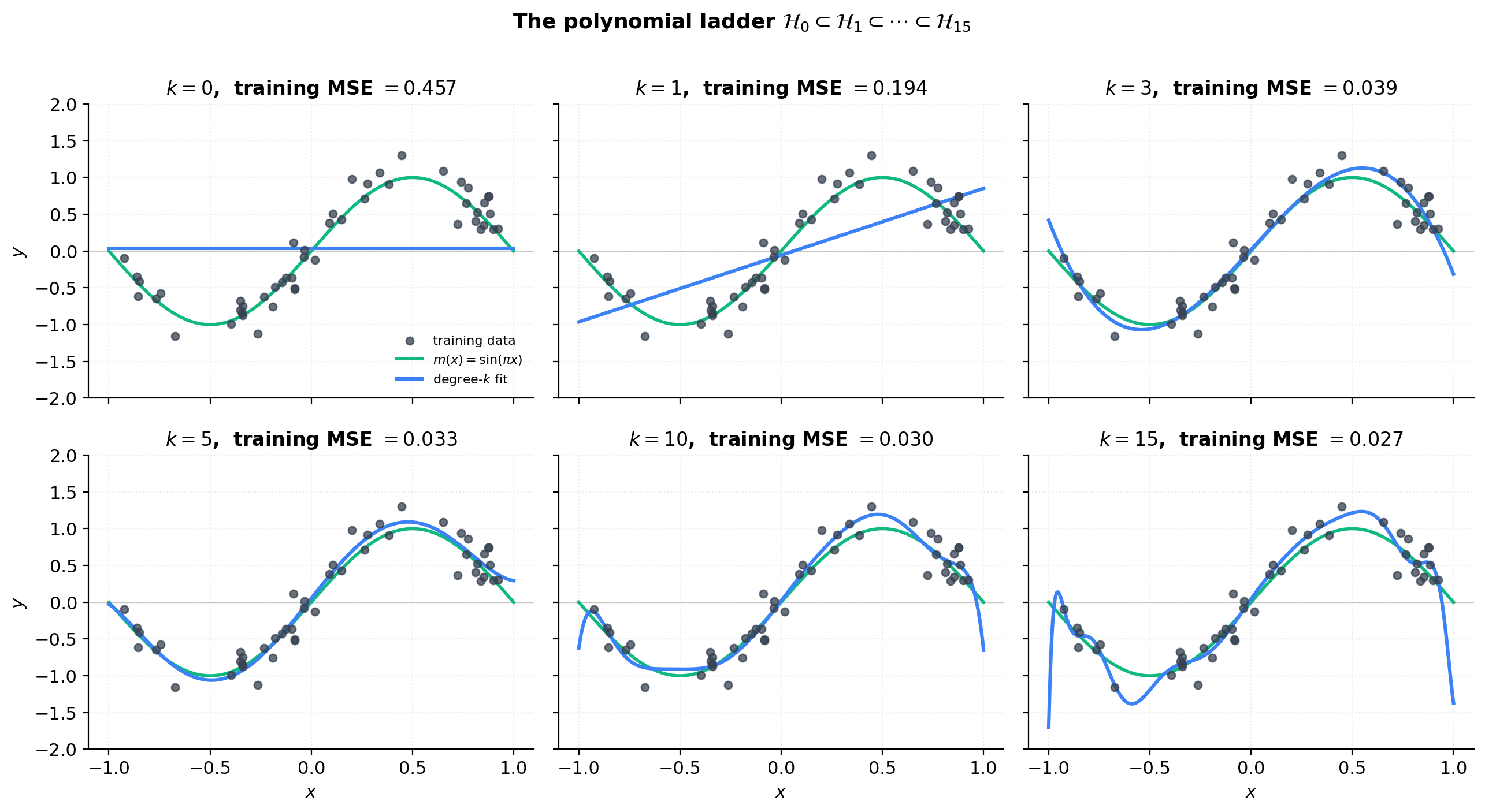
The figure below makes the nested family concrete. On a single training sample of from the §1 toy, we fit polynomials of degrees and plot the six fits as a 2×3 panel grid, with the training data and the true function overlaid on each panel. The reader should see the ladder of capacity unfold: is a horizontal line (mean of ), is a tilted line that still misses the curvature, is the first fit that captures the sinusoidal shape (matching the leading-order Taylor expansion ), is essentially the optimum, starts oscillating between training points, and exhibits catastrophic Runge-style oscillation near the endpoints. The training error (printed in each panel title) decreases monotonically with , confirming the “ERM alone tells the wrong story” thesis from §1.
The SRM principle
The per-class confidence allocation
The SRM principle starts from a per-class uniform convergence bound. For each class in our nested family, suppose we have a high-probability bound on the worst-case gap between training error and population risk: there is a function such that, on a sample of size ,
The function is what the §4 (Vapnik VC) and §5 (Bartlett–Mendelson Rademacher) developments specify; for now it’s a placeholder. The reader can think of for some constant and the VC dimension of , but the SRM derivation that follows doesn’t depend on the specific form — only on the existence of some per-class uniform convergence bound.
The catch: holds with probability for the fixed class in isolation. We’re going to pick from among all the classes based on the same sample , so we need a bound that holds simultaneously across all classes. By the union bound,
For the right-hand side to equal our target failure probability , we need an allocation of confidence-mass across classes with . The canonical choice — Vapnik 1995 — is
which sums to exactly via the Basel identity .
The choice isn’t unique. The telescoping allocation also sums to exactly; the geometric allocation does too. What distinguishes the choice is its growth rate inside the term that ends up in the penalty:
So when we substitute back into , we pick up an additive term in the bound — logarithmic growth in . The geometric allocation would give — linear growth in , a much harsher penalty for large classes. The polynomial-decay allocation is canonical precisely because it gives the slowest-growing penalty consistent with the union bound.
This term is the “price” we pay for considering an infinite nested family rather than a single fixed class. In practical applications ranges over a small finite set ( in our polynomial toy), and the contribution is dominated by the capacity term .
Definition: the SRM estimator
Equipped with a confidence allocation, the SRM penalty is the per-class bound at the allocated level.
Definition 2 (Capacity penalty and SRM estimator).
Given a nested family with per-class uniform convergence functions satisfying , a confidence parameter , and the canonical allocation , the capacity penalty of class at sample size is
The SRM estimator is the pair defined by
where is the ERM in (any minimizer; ties broken arbitrarily).
A practical note: the outer infimum over is taken over the (countably infinite) family, but grows in — the capacity term goes to infinity, and even if the capacity stays bounded the term grows without bound. So the minimum is achieved at some finite , and the search is effectively over a finite prefix of the family.
When the inf inside isn’t achieved (e.g., for some non-parametric classes), the analysis goes through with defined as an -approximate ERM for any ; the additional term in the oracle inequality is taken to zero. From here on we assume the inf is achieved in each — true for all the parametric examples in §2.
The SRM oracle inequality
The oracle inequality is the load-bearing theorem of SRM. It says the SRM estimator’s risk is comparable to the best risk achievable in any class in the family, plus twice that class’s penalty — and we don’t have to know which class is best to enjoy this guarantee.
Theorem 1 (SRM oracle inequality).
Let be a nested family with per-class uniform convergence bounds valid at every level , and let as in Definition 2. Write for the best risk achievable in class . For any , with probability at least over the sample , the SRM estimator satisfies
The right-hand side is what we’d get from an oracle who knows the population risk and picks the optimal — modulo the factor of 2 on the penalty. The factor of 2 is the cost of learning from data: we need uniform convergence twice over, once to validate our choice of and once to compare it to the oracle’s choice.
Two consequences worth flagging. Adaptive guarantee: the bound holds for the best in the family, which can depend on , the noise level, and the target — and we don’t have to specify it in advance. Approximation–estimation decomposition: is the approximation error of class (how well the class can approximate the Bayes-optimal predictor), and is the estimation error (how well we can identify the best element of from a finite sample). SRM trades off approximation vs estimation automatically — taking larger improves approximation (since is monotone non-increasing in by nesting) but worsens estimation (since pen grows in ).
Proof of the oracle inequality
The proof is the union-bound argument written out carefully.
Proof.
Define the event
By applied to each at confidence level , and a union bound over the family,
So . We work on the event for the rest of the proof; all subsequent claims hold simultaneously with probability .
Fix any reference class index . We will show
and since is arbitrary, taking the infimum over on the right will yield the theorem.
Step 1 — Bound the population risk of by its empirical risk plus the SRM-class penalty. On , applied to class ,
Step 2 — Invoke the SRM-estimator’s minimality. By the definition of as the minimizer of the penalized empirical risk,
Combining (2) and (3),
The -dependent terms have cancelled, and the right-hand side now depends only on the reference class .
Step 3 — Bound by the best population risk in . Let (existence by the inf-is-achieved assumption from Definition 2). Since is the ERM in , its training error is no larger than that of any other element of , in particular not larger than that of :
On , applied to ,
Chaining the two,
Step 4 — Combine. Plugging (5) into (4),
Since was arbitrary, taking the infimum over on the right gives the theorem.
∎Three things worth noting about the proof’s structure. The factor of 2 on comes from invoking uniform convergence twice — once for the SRM-picked class in (2), once for the reference class in (5). The penalty for the SRM-picked class cancels between (2) and (3), so the final bound only sees the reference-class penalty — this algebraic cancellation is what makes the bound adaptive: it gives us the best penalty in the family for free. And the contribution from the confidence allocation is hidden inside , since we evaluated at level rather than .
Penalty decomposition
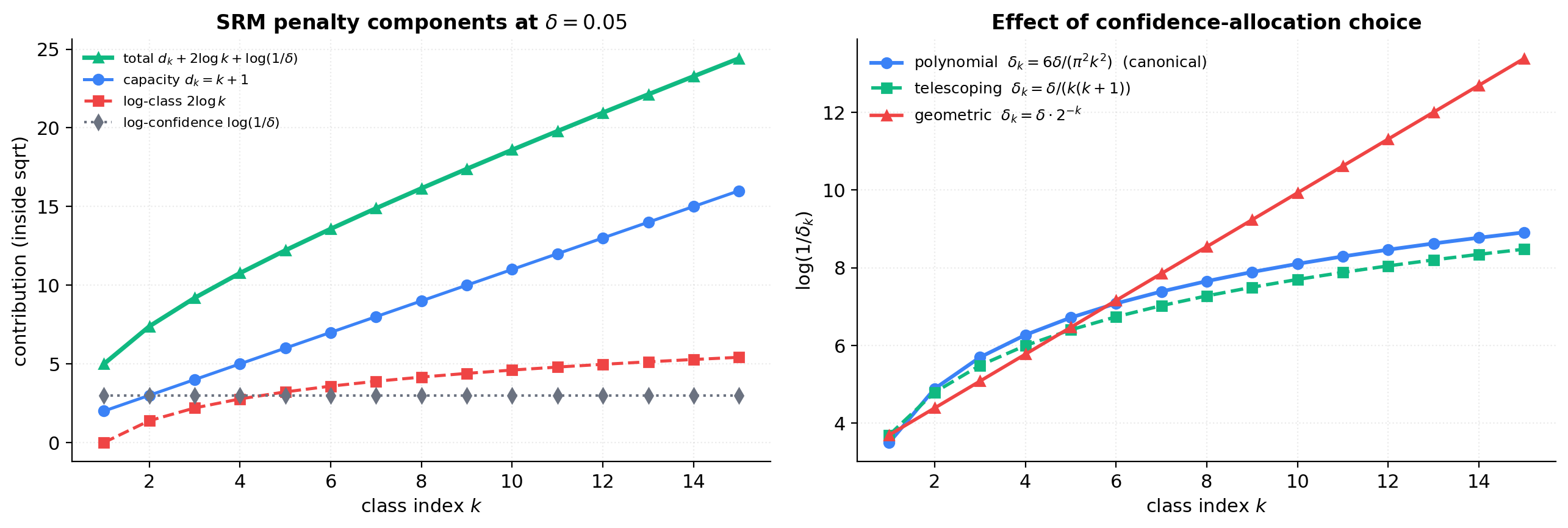
The figure below decomposes the SRM penalty into its three additive contributions on the polynomial-regression toy with . At , , , the capacity term is linear and reaches 16 at ; the log-class term is logarithmic and reaches at (about a third of the capacity term); the log-confidence term is constant. Capacity dominates the penalty; the price for considering an infinite family is real but small in practice.
The second panel compares three confidence-allocation choices for . The canonical polynomial decay gives . The telescoping choice gives essentially the same asymptotic shape. The geometric choice gives — linear in , dramatically harsher. This is the visualization of why the polynomial decay is canonical: it’s the slowest-growing subject to .
Classical VC-bound SRM (Vapnik 1995/1998)
The Vapnik penalty
The SRM oracle inequality (Theorem 1) is loss-agnostic and capacity-agnostic — it works for any per-class uniform convergence bound we can produce. The Fundamental Theorem of Statistical Learning (PAC Learning, agnostic-PAC two-sided form) gives one for any class of finite VC dimension. For a class with VC dimension , any distribution , and any , with probability at least over ,
where is a universal constant (the value depends on the loss function and the route taken through the FTSL proof — Sauer–Shelah + Hoeffding gives one constant, chaining bounds give a smaller one; the qualitative shape is what matters here). Plug in the canonical confidence allocation from §3.
Definition 3 (Vapnik SRM penalty).
Given a nested family with VC dimensions , sample size , and confidence parameter , the Vapnik SRM penalty is
where is the universal constant from (4.1).
Each term in the numerator has a meaning. is the capacity contribution — it comes from the Sauer–Shelah count of dichotomies a VC- class can produce on points and is the dominant term for moderate and . is the union-bound cost from the confidence allocation , the “price for considering infinitely many classes.” is the confidence-level cost. All inside a envelope — the classical “slow rate” of statistical learning.
For regression with squared loss the same shape holds provided predictions and labels are bounded (truncate to and the penalty picks up a multiplicative factor of ). The polynomial-regression toy from §1 satisfies and with overwhelming probability, so the truncation is invisible. For the polynomial family, the VC dimension of the threshold-classification variant equals the parameter dimension — same shape for the regression effective DoF.
Derivation from FTSL
The derivation is the union-bound argument from §3 with instantiated by (4.1). For each at confidence level ,
Substituting ,
The additive rolls into the universal constant when we resolve the s into the form of Definition 3. The result is with . Applying Theorem 1 then gives the Vapnik SRM oracle inequality: with probability ,
This is the original SRM bound from Vapnik (1995, 1998) — the form that motivated the entire framework.
SRM consistency
The oracle inequality is a finite-sample guarantee: for the given and , the SRM estimator’s risk is no worse than the best in-family choice plus twice that class’s penalty. We’d also like an asymptotic guarantee — that as , the SRM estimator’s risk approaches the Bayes-optimal risk , taken over all measurable .
Theorem 2 (SRM consistency (Vapnik 1995)).
Let be a nested family with VC dimensions for every . Suppose
(a) Universal approximation: .
(b) Confidence schedule: depends on with and (e.g., ).
Let be the SRM estimator at sample size with the Vapnik penalty (Definition 3). Then
Two consequences. Convergence rate: if condition (a) is strengthened to a quantitative approximation rate — for some — then the convergence in Theorem 2 happens at a quantifiable rate, determined by trading off against the penalty (Lugosi and Zeger 1995). No rate without smoothness: without quantitative approximation conditions, the convergence in Theorem 2 can be arbitrarily slow (Devroye, Györfi, and Lugosi 1996, §7).
Proof of consistency
The argument is: pick a reference class that’s good enough in approximation, observe that its penalty vanishes as , plug both into the oracle inequality, take the limit.
Proof.
Fix . We will show .
Step 1 — Pick a reference class. By (a), there exists with
This is fixed once and for all — it does not depend on .
Step 2 — The penalty at vanishes. The Vapnik penalty at sample size and the fixed class is
is fixed (Step 1), so . is fixed, so is a constant. By (b), . The numerator inside the square root is , so
Choose such that for all , .
Step 3 — Apply the oracle inequality. By Theorem 1 (applied to the Vapnik penalty), with probability at least over the sample ,
where the second inequality is the trivial upper bound by the value at . For , applying (1) and (2),
This holds with probability at least .
Step 4 — In-probability convergence. From (3),
By (b), , so the right-hand side vanishes. Since was arbitrary, .
∎Two structural notes about the proof. The reference is data-independent. This is essential: we pick based on the approximation property (a), apply the oracle inequality with on the right, and absorb the gap into the penalty. Trying to take would defeat the argument, since the right-hand side of the oracle inequality is fixed before the data is seen. The proof says nothing about itself. We never claim or for some optimal — what’s controlled is the risk, not the index. can oscillate arbitrarily as long as the corresponding risk converges.
Vapnik SRM on the polynomial toy
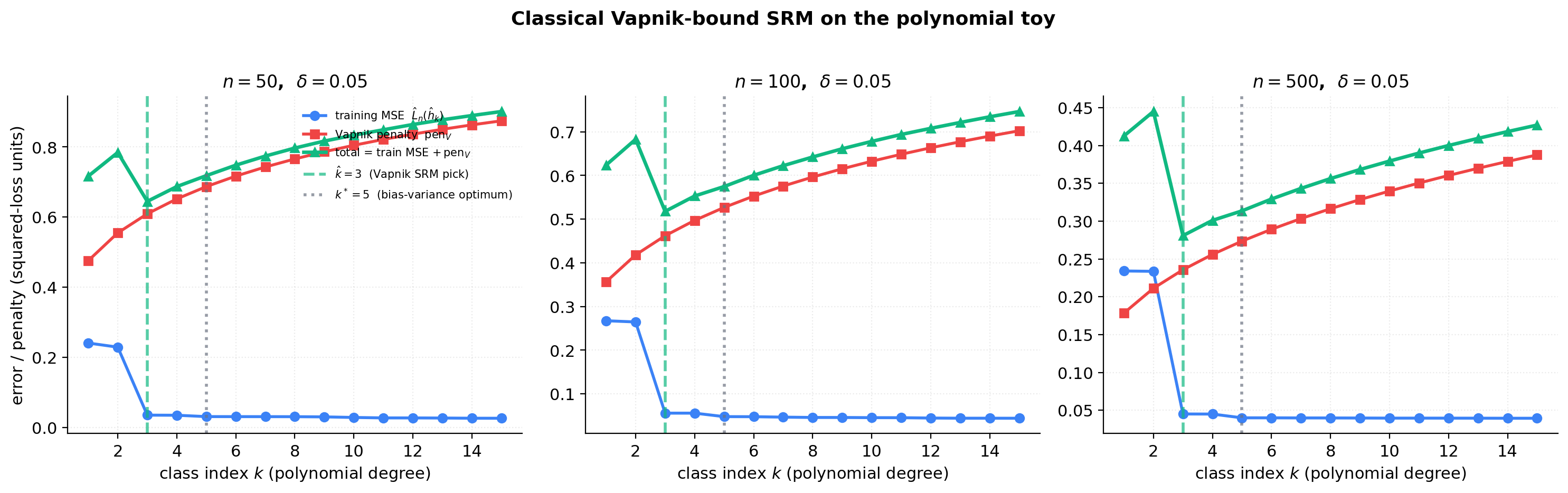
The figure below plots training MSE, the Vapnik penalty, and their sum as functions of on the polynomial-regression toy, at . The picked is the argmin of the total; we also compute the bias-variance optimum from a small Monte Carlo for comparison.
The reader should see two things. The U-shape exists. Training MSE decreases monotonically, penalty grows monotonically, the sum has an interior minimum. The SRM rule is well-defined and computable from the sample alone. Vapnik SRM is conservative. The picked is consistently smaller than the bias-variance optimum computed from §1’s MC. The Vapnik bound is the worst-case uniform-convergence rate over all distributions; on a benign distribution like ours, the actual generalization gap is much smaller than the bound, and the rule pays for the safety margin by under-fitting.
This sets up §5 directly. The Bartlett–Mendelson Rademacher SRM uses a data-dependent capacity measure (empirical Rademacher complexity on the actual sample) instead of the distribution-free VC dimension. On distributions where the worst case is not the worst case (which is most distributions), the Rademacher bound is tighter, and the picked moves closer to — though at very small a McDiarmid confidence term can dominate and flip the relative tightness (§5.5).
The pedagogical above keeps the §4.5 demo’s U-shape interior so the picked is interpretable. The literal FTSL constant from chaining bounds is roughly 2–8, depending on the proof route; practitioners typically don’t use the literal Vapnik bound — they use Rademacher (§5), AIC/BIC (§8), or CV (§10) instead.
Rademacher-complexity SRM (Bartlett–Mendelson 2002)
From worst-case to data-dependent
The Vapnik penalty is the worst case over all distributions on — it bounds the generalization gap of uniformly over every conceivable input distribution. For any distribution where exhibits less complexity than its worst case — because the data is on a low-dimensional manifold, or because the realized inputs lie in a benign region, or just because the noise structure happens to be helpful — the Vapnik bound overestimates the generalization gap, and the SRM rule built on it under-fits (§4.5).
The Rademacher complexity is empirical — it’s defined on the realized sample and measures how well functions in can align with random sign noise on that specific sample. If the class can’t fit Rademacher noise well on this particular — and for benign distributions, it usually can’t, by a factor — the resulting penalty is tighter and the SRM rule picks a less conservative .
The replacement is mechanical: keep everything from §3 and §4, just swap the per-class uniform convergence bound. The Bartlett–Mendelson (2002) bound (Generalization Bounds, which establishes the bound via McDiarmid’s inequality and a symmetrization argument) replaces (4.1).
The Bartlett–Mendelson SRM penalty
For a function class defined on a sample , the empirical Rademacher complexity is
where are i.i.d. Rademacher variables uniform on (also developed in PAC Learning and Generalization Bounds). The Bartlett–Mendelson generalization bound: for the loss class , with probability at least over ,
The factor of 2 in front of comes from the symmetrization step (passing from the data-sample to an i.i.d. ghost sample and bounding by — see Generalization Bounds). The comes from two applications of McDiarmid’s bounded-differences inequality.
Plug into (5.1).
Definition 4 (Bartlett–Mendelson SRM penalty).
Given a nested family , sample , and confidence , the empirical Rademacher SRM penalty is
where is the loss class associated with .
Three observations. The penalty is sample-dependent. The capacity term has no factor: for nice classes its scaling is , not as in Vapnik. That factor is the savings on benign distributions. For Lipschitz losses, Talagrand’s contraction lemma (Generalization Bounds) gives , so we can compute Rademacher complexity on the hypothesis class and absorb into a constant.
The Rademacher SRM oracle inequality
Theorem 3 (Bartlett–Mendelson SRM oracle inequality).
Under the setup of Definition 4, with probability at least over the sample , the SRM estimator with penalty satisfies
Same shape as the Vapnik oracle inequality (§4), with replaced by . The only thing that has changed is which uniform-convergence bound feeds into Theorem 1.
The bound is data-dependent in a sharper sense than Vapnik’s. The Vapnik bound depends on the sample only through ; the Rademacher bound depends on the sample through . Two practical consequences. Adaptivity: on benign samples, is small even when is large. Sample-by-sample variability: the picked can differ across samples even when the underlying distribution is the same — a feature, not a bug.
Proof
Proof.
Define the event
By (5.1) applied to each at confidence level , , so the per-class bound is exactly as in Definition 4. A union bound over gives . The remainder of the argument is identical to the proof of Theorem 1 (§3) with replaced by .
∎The proof is short because all the work is delegated. The McDiarmid + symmetrization machinery that establishes (5.1) lives in Generalization Bounds; the union-bound algebra lives in §3.4. What §5 contributes is the instantiation.
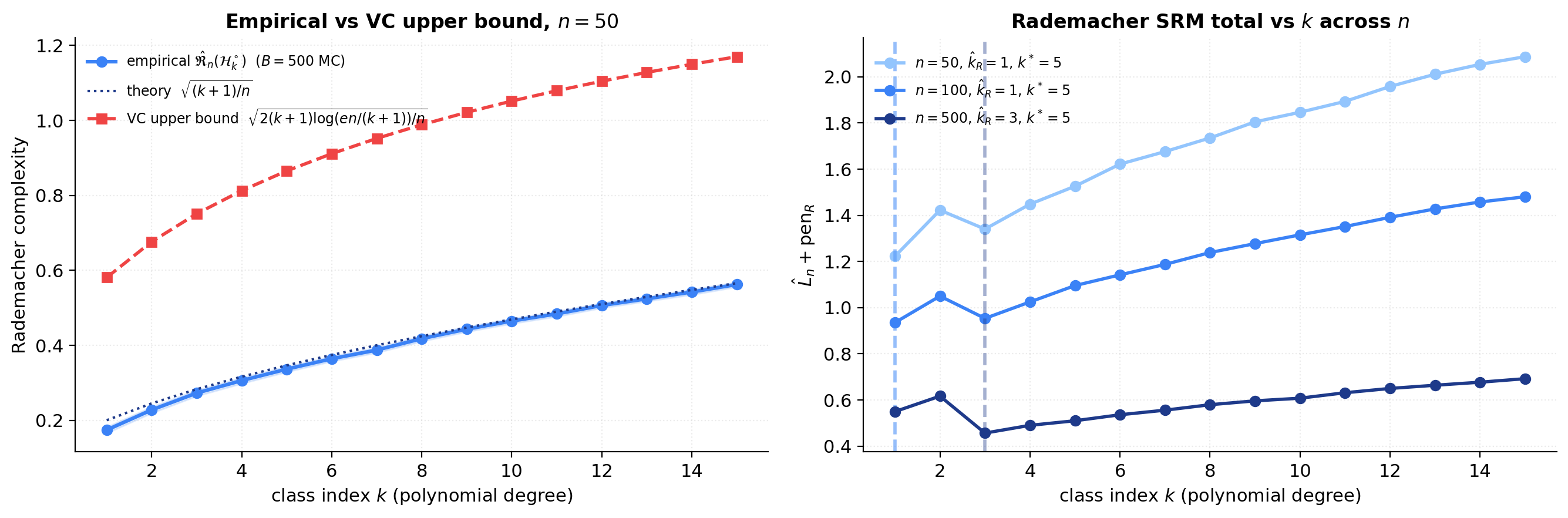
Empirical Rademacher vs the VC upper bound
The polynomial-regression toy admits a clean closed form for the empirical Rademacher complexity of the -unit-ball polynomial class . A direct computation (Cauchy–Schwarz in the inner product, where is the Vandermonde of the realized sample) gives
where is the orthogonal projection onto the column space of . So , estimated by Monte Carlo over Rademacher draws. The closed form makes the computation deterministic — no actual fitting required, just orthogonal projection.
For comparison, the VC-implied upper bound (Massart’s lemma + Sauer–Shelah) is . The factor that distinguishes them is the — the log savings from data-dependent vs distribution-free analysis.
The expected behavior — Rademacher tighter than Vapnik on benign distributions — is asymptotic. At small the Bartlett–Mendelson confidence term can dominate the data-dependent capacity savings, and the Rademacher-picked can come out smaller than rather than larger. On our polynomial toy, at and , while across all three sample sizes; the cross-over happens around . The honest reading: Rademacher is tighter than Vapnik asymptotically, on benign distributions; at small the McDiarmid confidence term can dominate and produce a conservative pick. The picture sharpens visibly as grows.
Penalized ERM and soft SRM
From hard nesting to soft penalty
Sections 3–5 derived SRM as a discrete rule. The discreteness is a notational artifact. Every practical model class can be smoothly interpolated by a continuous capacity functional , and the discrete family is recovered as the level sets of the capacity functional.
With a continuous capacity functional in hand, two natural problems present themselves. The constrained form:
The penalized form replaces the constraint with a Lagrange multiplier:
Under mild convexity assumptions on and — both satisfied for squared loss plus a convex norm penalty — strong Lagrangian duality holds: every solution of (6.1) at level is a solution of (6.2) at some , and vice versa (Boyd and Vandenberghe 2004, §5.5).
For SRM the practical consequence is that we don’t need to enumerate the discrete family. We can solve (6.2) for a continuous grid of values, trace out the entire regularization path of solutions , and pick to minimize a soft SRM objective — training error plus a penalty that depends on the effective capacity at .
The penalty parameter as a continuous SRM level
Let denote the solution of (6.2) at penalty parameter . As varies from to , varies monotonically: implies (Tikhonov 1963).
So acts as a continuous capacity dial. Small = high capacity, large = low capacity. This monotonicity is the soft analog of the nested-family inclusion: as shrinks, the effective class grows.
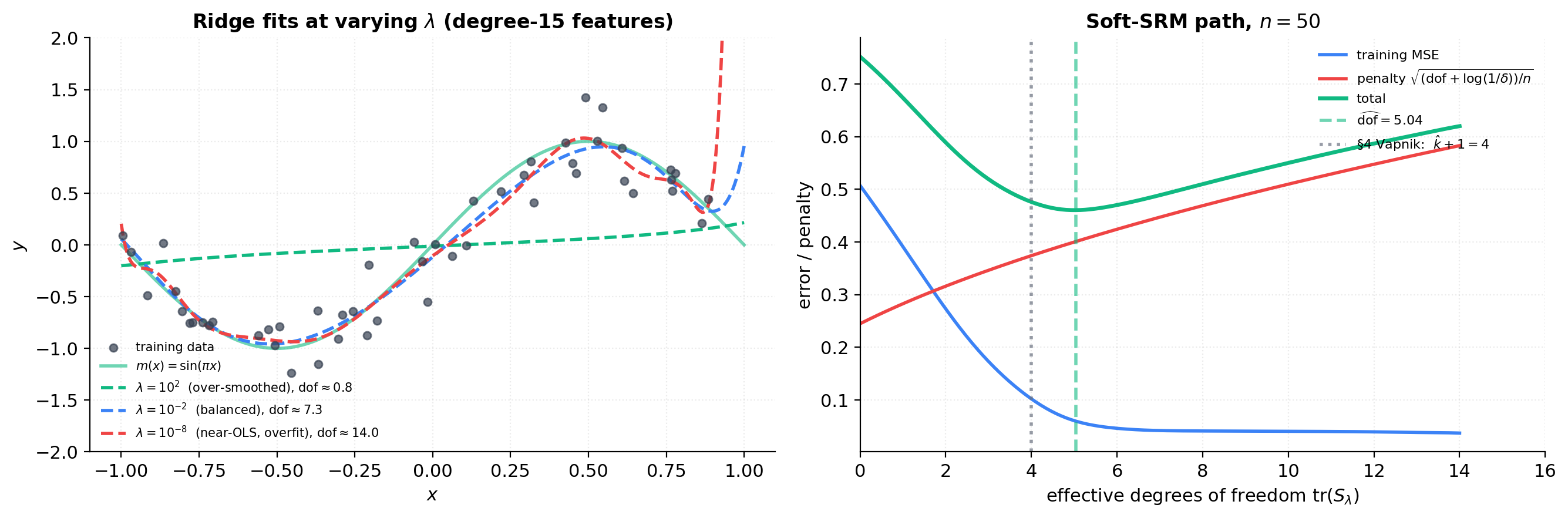
A useful capacity measure for the penalized-ERM regime is the effective degrees of freedom: for linear smoothers. For ridge regression with Vandermonde features and penalty ,
where are the singular values of . This trace decreases smoothly from at to at , providing exactly the continuous interpolation we want.
The soft SRM estimator and its relationship to
Definition 5 (Soft SRM estimator).
Given a capacity functional , a continuous penalty , and a confidence parameter , the soft SRM estimator is
The natural form replaces the discrete capacity term with effective DoF. The hard/soft correspondence: for each , Lagrangian duality identifies a unique such that solves the constrained problem at level . For benign penalty constants, the picked effective DoF at should be close to the discrete SRM’s .
Implicit nested families
Given any penalty functional and any , the level set is a well-defined hypothesis class, and as varies these classes are nested. This is the implicit nested family generated by the penalty.
The consequence: any penalty-based method automatically inherits the SRM framework. The penalty type — for ridge, for lasso, Sobolev norm for spline smoothing, -pseudo-norm for best-subset selection — determines the geometry of the implicit family, but the soft-SRM rule and its oracle inequality apply regardless.
Soft-SRM path on the polynomial toy
The figure below uses the degree-15 Vandermonde feature matrix as the ambient parameter space and fits ridge regression for a logarithmic grid of . For each we compute training MSE, effective DoF , and a simplified soft-SRM penalty .
SRM as regularization
Tikhonov regularization as soft SRM
Tikhonov (1963) introduced the regularization functional for some operator . With this is standard ridge regression. With a discrete-derivative operator it becomes spline smoothing. With a finite-difference matrix it becomes total-variation denoising.
For SRM, the relevant fact is that Tikhonov with is precisely soft SRM (Definition 5) with capacity functional . The implicit nested family is the parameter-space ball . Geometrically the ball is rotationally symmetric — solutions shrink isotropically toward zero. No coefficient is ever set to exactly zero.
Ridge effective degrees of freedom
The effective DoF from §6 plays a dual role for ridge regression. First, it’s the capacity of the implicit family at . Second, it’s the Stein’s unbiased risk estimator (SURE) bias-correction term: the expected training MSE is biased downward from the population risk by .
For ridge on polynomial-Vandermonde features, the SVD gives — a smooth monotone function from (OLS) to . The SURE interpretation also gives a sample-only way to estimate : minimize . This is Mallows’s in disguise (§8).
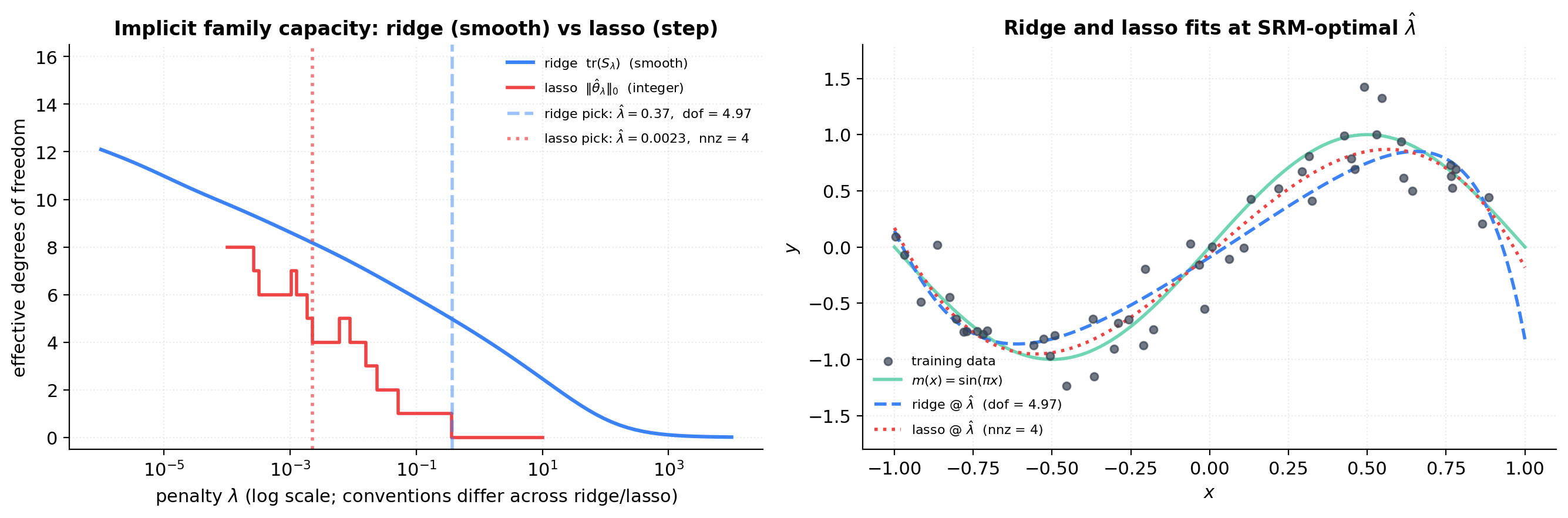
Lasso and the ball
Lasso (Tibshirani 1996) replaces Tikhonov’s penalty with :
The implicit nested family is the ball — a cross-polytope. The geometry forces solutions to lie on low-dimensional faces with most coordinates exactly zero. The natural capacity measure for lasso is sparsity — the number of nonzero coefficients. Zou, Hastie, and Tibshirani (2007) prove that this count equals the effective DoF in the SURE sense:
The Bickel-Ritov-Tsybakov (2009) lasso oracle inequality has exactly the SRM shape: , with the true sparsity — the capacity term plays the role of from §4.
In linear models, weight decay — adding to the loss — is literally Tikhonov regularization with , hence soft SRM on the ball. The terminology comes from the gradient-descent update rule: . In deep networks the connection to classical SRM is murkier (§12), but the soft-SRM intuition still motivates the practice. For our polynomial-regression toy, weight decay is just ridge regression and the ridge effective-DoF analysis applies verbatim.
Ridge vs lasso on the polynomial toy
Fit ridge and lasso on the polynomial Vandermonde with the same training sample. Compute training MSE, effective DoF (smooth for ridge, integer-valued for lasso), and the soft-SRM total. The figure compares ridge + effective DoF, lasso + number of nonzeros, §4 Vapnik hard-SRM , and the §1 bias-variance oracle . All four should fall in a narrow band on this benign toy.
SRM and information criteria
AIC
The Akaike Information Criterion (Akaike 1973) is . For Gaussian-noise regression with plug-in , AIC is equivalent to picking minimizing . So AIC is exactly the SRM rule with capacity penalty — linear in , no factor, no confidence parameter.
Motivation: Akaike derived AIC by asking, asymptotically, which model gives the smallest Kullback–Leibler divergence from the true distribution. The rule is calibrated for prediction risk, not selection consistency: AIC is asymptotically efficient for prediction.
BIC
The Bayesian Information Criterion (Schwarz 1978) is — penalty rather than . For Gaussian-noise regression, BIC penalty is . For , , so BIC is strictly more conservative than AIC.
Motivation: Schwarz derived BIC as a Laplace approximation to the negative log marginal likelihood of a Bayesian model with a flat prior. BIC is consistent for selection: if the true model lies in the family, BIC picks it with probability as . The AIC vs BIC distinction: AIC minimizes prediction risk asymptotically, BIC identifies the true model asymptotically.
MDL
The Minimum Description Length principle (Rissanen 1978) views model selection as data compression. The “best” coding scheme for parameters (Rissanen’s universal Bayesian code) yields . Doubling and comparing to BIC: asymptotically. MDL and BIC are the same rule from different starting points. See Minimum Description Length for the coding-theoretic substrate.
Unification
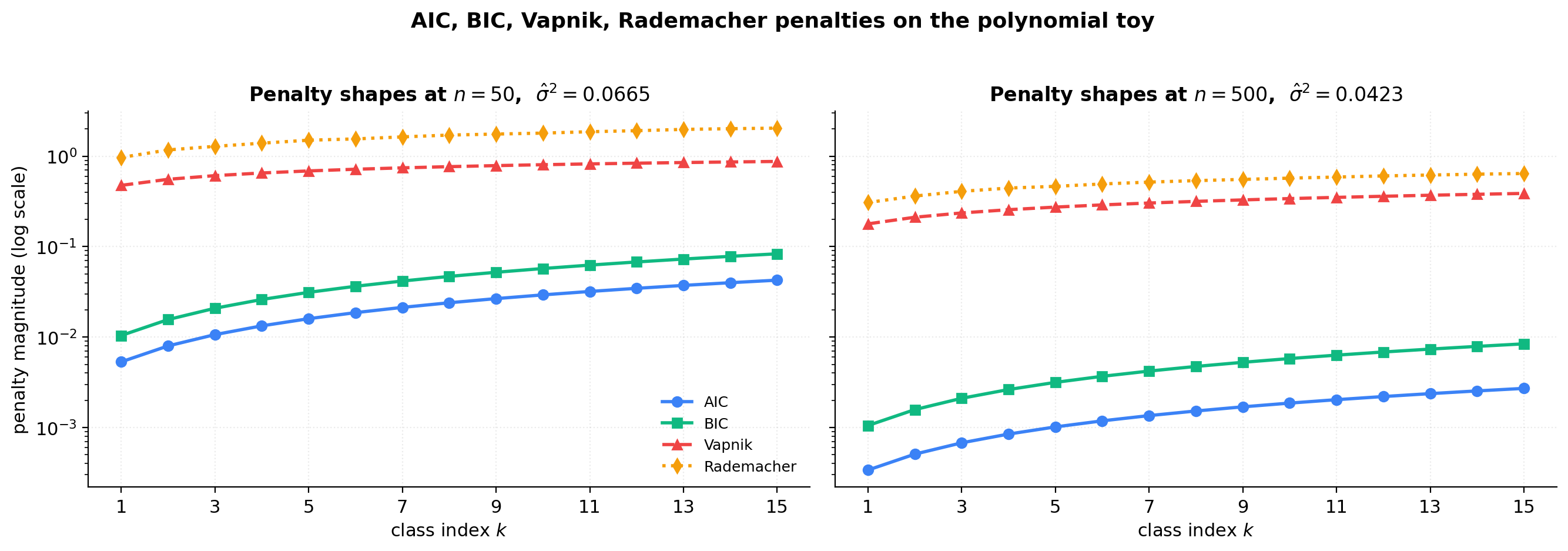
All five SRM rules fit the same template — pick minimizing . They differ in the penalty function:
| Rule | Penalty | Shape |
|---|---|---|
| AIC | linear in ; no ; no | |
| BIC, MDL | linear in ; ; no | |
| Vapnik | square-root in ; ; finite-sample | |
| Rademacher | empirical; data-dependent; finite-sample |
Three structural differences. Capacity shape: AIC/BIC are linear (parametric, fast rate); Vapnik/Rademacher are square-root (non-parametric, slow rate). factor: BIC and Vapnik have it; AIC and Rademacher don’t. Confidence parameter: Vapnik and Rademacher are finite-sample bounds; AIC and BIC are asymptotic.
Each targets a different goal: AIC for asymptotic prediction efficiency; BIC/MDL for selection consistency; Vapnik for worst-case finite-sample generalization; Rademacher for data-dependent finite-sample generalization.
Penalty shapes and pick-agreement
For on the polynomial toy, compute training MSE and each of the four penalties as functions of . The figure plots the four penalty shapes on a log y-scale (the bound-based and asymptotic penalties span ~50× in magnitude) and tabulates the picked for each rule.
SRM and PAC-Bayes
From class-indexed nesting to posterior-averaged capacity
PAC-Bayes generalizes SRM substantially: the rule produces a probability distribution over hypotheses, with the predictor being either the posterior-mean function or a stochastic sample from .
The setup. Fix a prior over chosen before seeing the data. After observing , choose a posterior — any data-dependent distribution, subject to . The PAC-Bayes framework bounds the posterior-averaged generalization error in terms of posterior-averaged training error and KL divergence . The implicit nested family is indexed by KL: . PAC-Bayes is smooth SRM with KL as the capacity functional.
The PAC-Bayes bound (Catoni–McAllester family)
Theorem 4 (PAC-Bayes generalization bound (McAllester)).
Fix a prior over chosen independently of the sample. Suppose the loss takes values in . For any , with probability at least over , every posterior satisfies
The bound is uniform over all by a continuous- MGF argument (PAC-Bayes Bounds contains the full derivation via Donsker–Varadhan). Catoni’s tighter 2007 form replaces the square-root capacity term with an exponentially-tilted bound sharper for small ; for SRM purposes the qualitative shape is identical.
KL divergence as a continuous capacity measure
For Gaussian posteriors and priors, KL has a closed form. With and ,
KL is monotone in — the connection to Tikhonov regularization from §7 becomes explicit at the PAC-Bayes level. Minimizing over a Gaussian centered at the ridge estimator produces a penalty .
Soft-to-hard SRM limit
Posterior concentrates on a single hypothesis: for any continuous prior . To recover hard SRM, use a discrete prior: uniform over , point-mass on one , — the union-bound rule from §3 as a special case.
Posterior equals prior: gives a tight bound on the prior-mean predictor, which has no data-adaptation.
The PAC-Bayes-optimal posterior is the Gibbs posterior — the analog of the Bayesian posterior, with controlling concentration. The PAC-Bayes-optimal trades off the two extremes: exactly the SRM trade-off. See PAC-Bayes Bounds for the full Gibbs construction.
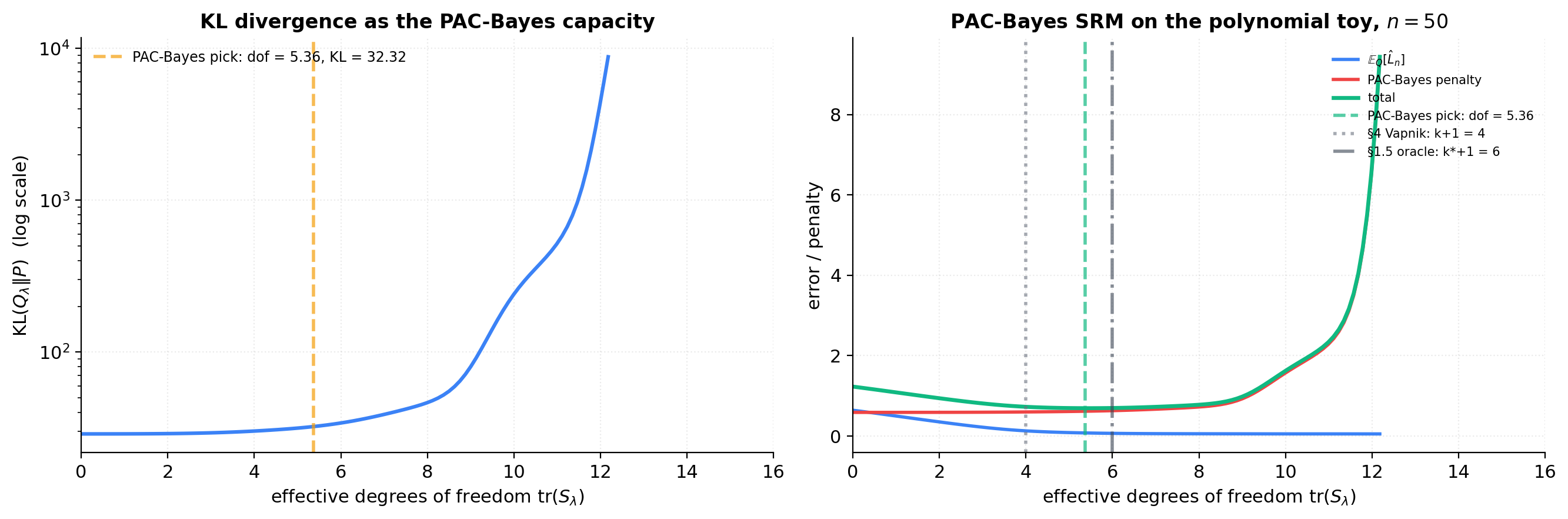
PAC-Bayes on the polynomial toy
The figure uses the polynomial Vandermonde features of degree 15 as the parameter space (). Prior with . For a logarithmic grid of , the posterior mean is set to the ridge estimate and the posterior covariance to with . We compute KL via (9.2), posterior-averaged training error, and PAC-Bayes total.
The choice is a pedagogical simplification — the proper Bayesian-ridge posterior covariance is , which depends on . Decoupling from keeps the §9 demo focused on the KL-as-capacity story without re-engineering for the full Bayesian-ridge posterior.
Cross-validation as data-driven SRM
CV as a complexity-penalty surrogate
Cross-validation takes a different route from the bound-based rules: estimate the population risk by holding out part of the sample. The -fold cross-validation procedure for partitions into folds, fits on the other folds, and evaluates on the held-out fold:
CV picks and returns refit on the full sample. The key structural fact: no explicit penalty. is an unbiased estimator of the population risk of the -subsample fit. The trade-off is information loss: CV uses of the data for testing per fold, so it has higher statistical variance than bound-based rules.
A CV oracle inequality
Theorem 5 (CV oracle inequality (finite-class)).
Let be a finite family with bounded loss . For -fold CV with fold size , with probability at least over the random fold partition,
The rate matches SRM up to constants. For infinite families, the analog (Bartlett, Lugosi, Mendelson 2002; Yang 2007) replaces with a stability-based or VC-based measure. Proof sketch: Hoeffding on each fold plus union bound over candidates.
The CV-variance vs SRM-stability trade-off
CV has higher statistical variance — the score depends on the random fold partition, with width 1–3 degrees on the polynomial toy across 100 partitions. Bound-based SRM depends on the algorithm’s stability — Vapnik is loose for stable algorithms, tight for unstable. Practical rule: CV for complex algorithms (deep nets, ensembles); bound-based SRM for simple families with clean capacity analysis.
When CV picks differently from SRM
Three regimes: loose bound constants (Vapnik’s slack); asymptotic vs finite- (AIC/BIC are asymptotic, CV is finite-sample); fold-partition noise (CV varies by 1–2 across rerolls). Agreement is reassuring; disagreement is diagnostic.
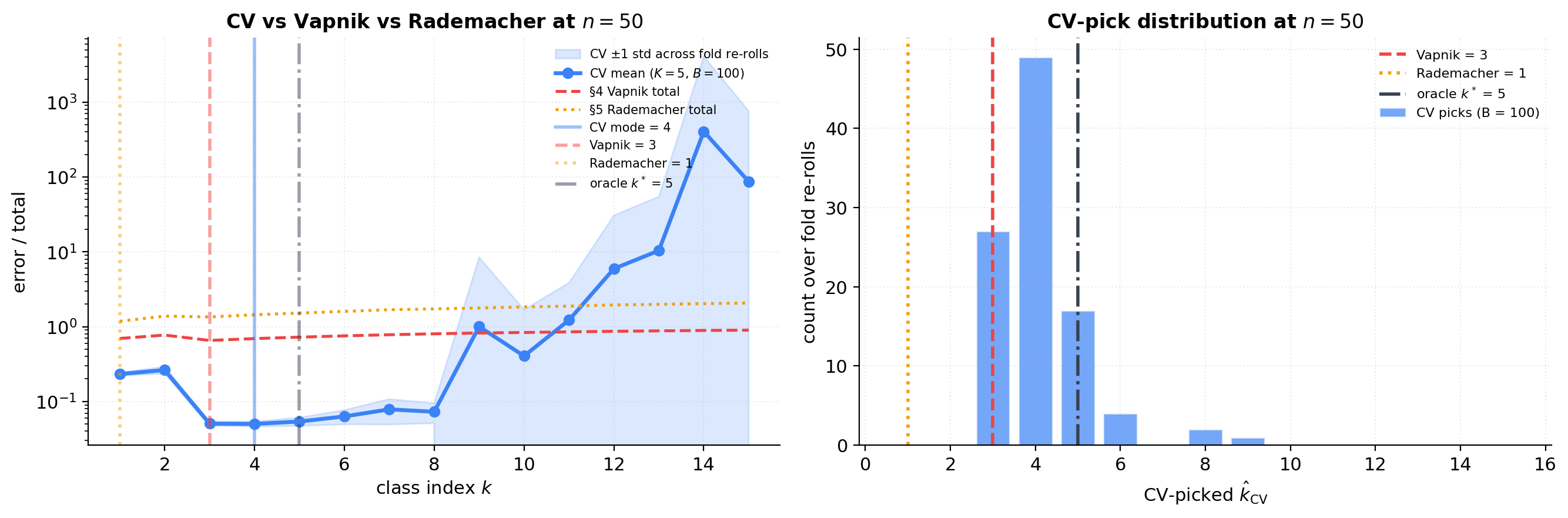
CV vs Vapnik vs Rademacher
Run 5-fold CV at with 100 random fold partitions. The figure aggregates to the mean CV curve, std band across partitions, and the distribution of picked . The histogram of CV picks shows fold-to-fold variability concretely.
Worked example: polynomial regression with SRM
Setup recap
The toy from §1, used throughout: , , , , polynomials of degree .
Bias-variance Monte Carlo
The bias-variance decomposition from §1, with replicates per sample size. The argmin of MSE over defines the bias-variance oracle .
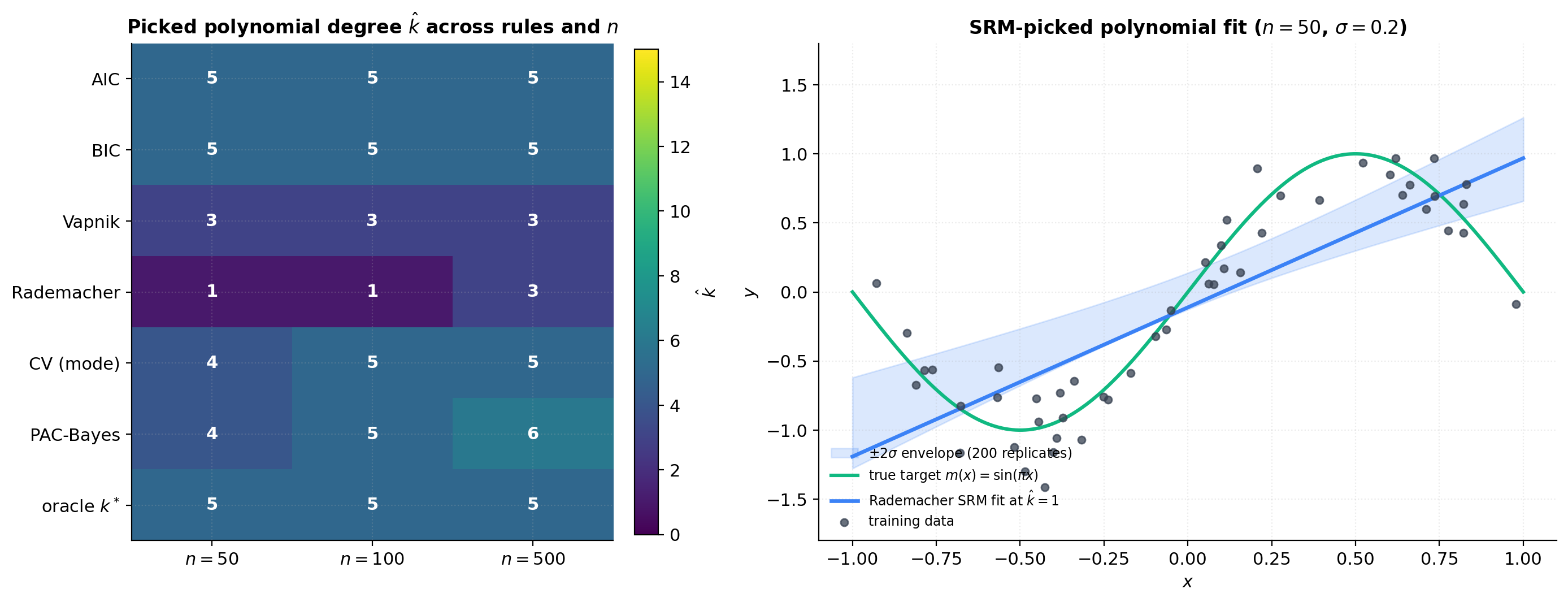
The agreement matrix
For each rule and each , the picked on the executed notebook (NumPy PCG64 seed 20260512):
| Rule (this seed) | |||
|---|---|---|---|
| AIC | 5 | 5 | 5 |
| BIC | 5 | 5 | 5 |
| Vapnik () | 3 | 3 | 3 |
| Rademacher | 1 | 1 | 3 |
| 5-fold CV (mode, 100 rerolls) | 4 | 5 | 5 |
| PAC-Bayes (degree ) | 4 | 5 | 6 |
| Oracle | 5 | 5 | 5 |
Three patterns: the picks cluster within a 4-degree band; AIC and BIC pick largest, Vapnik smallest at moderate ; all picks shift upward (or hold steady) with (consistency in action). The one surprise is Rademacher at small — the McDiarmid confidence term in dominates the data-dependent capacity savings on this benign distribution, and the rule picks rather than the asymptotic prediction.
Sensitivity to noise, sample size, and confidence
Noise variance: larger shifts oracle down. AIC and BIC have explicit factors. Vapnik/Rademacher are -free but indirectly affected via the training-error curve. Sample size: all rules shift up with . Confidence parameter: only Vapnik, Rademacher, PAC-Bayes depend on ; AIC, BIC, CV are -free.
Agreement matrix, money shot, sensitivity sweep
![Sensitivity sweep: each rule's picked $\\hat k$ as a function of noise standard deviation σ in [0.05, 0.5] at n = 50. All rules shift downward as σ grows, consistent with the bias-variance optimum shifting down with noise.](/images/topics/structural-risk-minimization/11_sensitivity_sigma.png)
SRM in practice: SVMs and beyond
SVMs and the -parameter as SRM
Soft-margin SVMs (Cortes and Vapnik 1995) are the canonical classical-SRM application:
This is soft SRM (Definition 5) with hinge loss and capacity functional . The implicit nested family is the margin-balls . The capacity calculation is celebrated: for an RKHS with bounded kernel ,
Dimension-free — this is why kernel methods work in infinite-dimensional spaces without curse-of-dimensionality penalty.
Neural networks: where classical SRM goes loose
For a depth- neural network with total parameters, (Bartlett, Maiorov, Meir 1998). For , , that’s — vacuous bound. Why classical SRM fails: the bound is uniform over but SGD explores only a small subset; implicit regularization biases SGD toward low-norm solutions. Active research: spectral norms (Bartlett, Foster, Telgarsky 2017), PAC-Bayes with data-dependent priors (Dziugaite and Roy 2017), sharpness (Foret et al. 2021).
The overparameterized regime
Modern ML operates with . Classical SRM says generalization should be terrible; empirically it’s fine. Three theory threads address the puzzle: benign overfitting (Bartlett, Long, Lugosi, Tsigler 2020), implicit regularization, norm-based margin bounds. None is yet predictive. Practical model selection still uses CV.
Double descent as the modern complication
Belkin, Hsu, Ma, Mandal (2019); Nakkiran et al. (2020): test risk as a function of capacity has two regimes. Classical regime (): U-curve. Interpolation threshold (): catastrophic peak. Modern regime (): second descent, often below the classical minimum. Detailed treatment: Double Descent (coming soon).
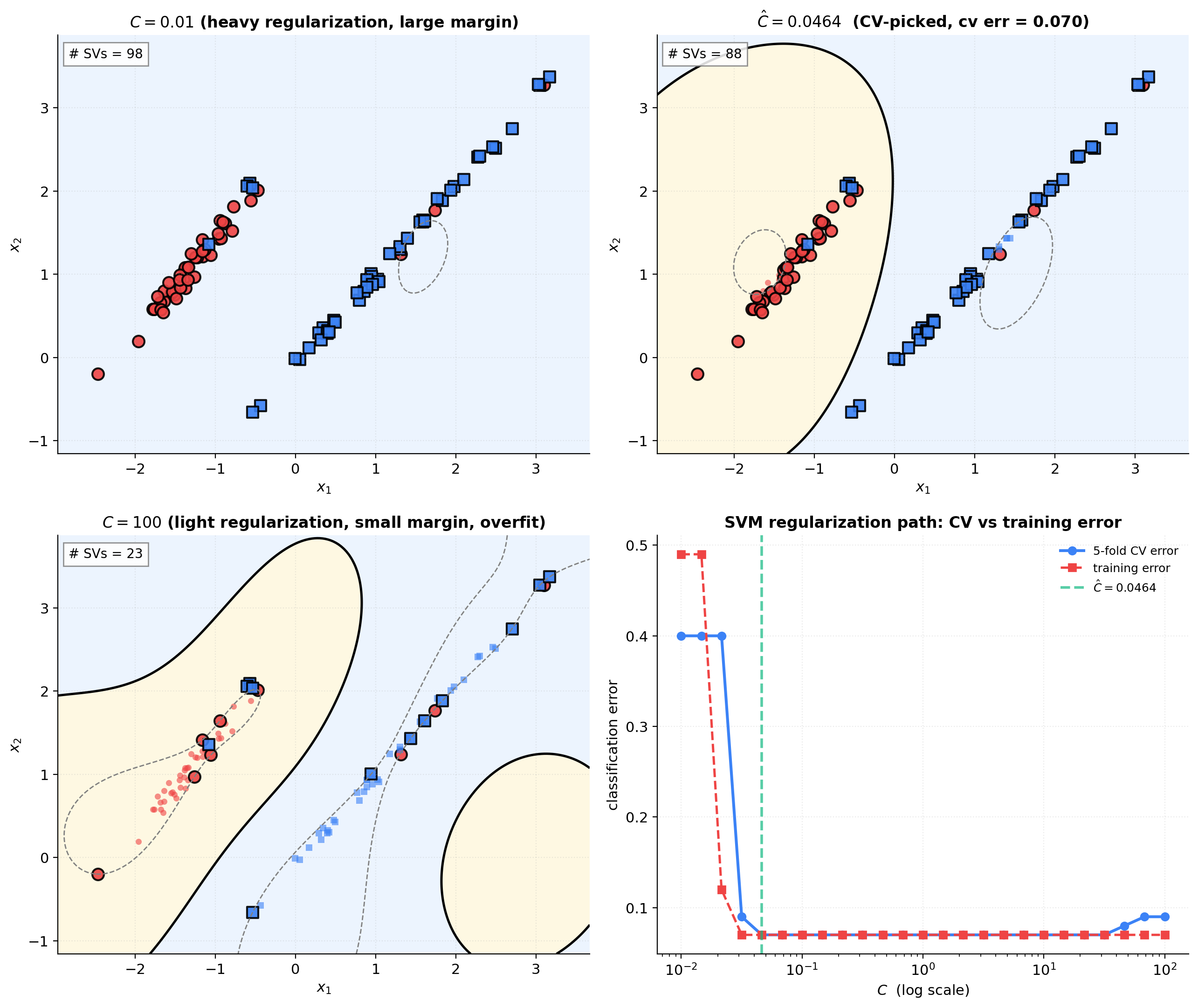
SVM- sweep on a 2D classification toy
A 2D binary classification toy (, two Gaussian clusters). RBF-kernel SVM across . 5-fold CV picks . The four-panel figure shows decision boundaries at three values plus the CV error vs path.
Connections and limits
Tightness of the bounds
The Vapnik bound is loose by orders of magnitude on benign distributions — the price of being distribution-free. Rademacher tightens by going data-dependent (factor of for nice distributions). PAC-Bayes tightens further by leveraging the prior. Lower bounds: the Vapnik rate is tight up to constants for some problem instances — the worst case is real, just not the average case. Practitioner hierarchy: Vapnik for deterministic guarantee with looseness tolerance; Rademacher for tighter guarantee on the specific dataset; PAC-Bayes for prior knowledge; CV for empirical right-answer.
Non-nested families
Many families aren’t nested: -NN, different SVM kernels, decision trees by leaf count, bagging. The §2.4 workaround: drop the strict inclusion requirement and keep only the capacity-indexed part. The union-bound argument (§3.1) never used — only . The same SRM estimator and oracle inequality work for any countable capacity-indexed family. What’s lost is interpretive: the bias term doesn’t decompose monotonically. For unions of finite collections of nested chains (e.g., SVM with multiple kernels), hierarchical SRM with across chains works cleanly.
Computational cost
Bound-based SRM: per-class fit cost × number of classes. Cheap for polynomial regression; manageable for SVMs; dominated by training cost for deep nets. CV: per-class fit cost. Expensive for large neural nets. Implicit regularization (early stopping, dropout): essentially free but theoretically opaque. The trade-off: clean theory and low cost (bounds) vs universal applicability (CV) vs cheap-but-opaque (implicit).
What SRM doesn’t tell you
Distribution shift: SRM assumes i.i.d. training and test data. Real-world shift breaks this; domain adaptation is the active research area (Ben-David et al. 2010). Agnostic-PAC gap: SRM bounds , not (Bayes-optimal gap); if the family doesn’t approximate Bayes-optimal well, SRM is vacuous on absolute risk. Model misspecification: classical SRM assumes well-specified models; under misspecification, “best-in-class” may be far from any meaningful target. Other: family choice (vs index within family), loss-function choice, adversarial robustness, active learning. SRM is precise for given fixed family + i.i.d. sampling, how to pick adaptively; silent on everything else.
Where to go next
- Double Descent (coming soon) — the modern overparameterized regime; benign overfitting; implicit regularization.
- PAC-Bayes Bounds — full PAC-Bayes theory; Donsker-Varadhan, Maurer’s lemma, Catoni.
- Generalization Bounds — McDiarmid plus symmetrization; Bartlett-Mendelson Rademacher bounds in detail.
- PAC Learning — foundational VC plus Sauer-Shelah plus FTSL plus Rademacher.
- Stacking and Predictive Ensembles — ensembling and Bayesian model averaging as soft model averaging across the SRM family.
Beyond formalML: Massart’s Concentration Inequalities and Model Selection (Springer 2007); Mohri, Rostamizadeh, Talwalkar’s Foundations of Machine Learning (MIT 2018); Vapnik’s Statistical Learning Theory (Wiley 1998).
Computational notes
Every numerical experiment in this topic runs in under a second per slider commit on a 2020-era CPU. The computational bottleneck across §§4–11 is the polynomial Vandermonde-based linear algebra; below is the Python skeleton used to produce the figures.
import numpy as np
def make_data(n, sigma, rng):
"""Polynomial-regression toy: X ~ U(-1,1), Y = sin(πX) + N(0, sigma²)."""
X = rng.uniform(-1.0, 1.0, size=n)
Y = np.sin(np.pi * X) + sigma * rng.standard_normal(n)
return X, Y
def vapnik_penalty(d_k, n, k, delta, C=1.0):
"""Vapnik penalty (Definition 3) with universal constant C exposed."""
capacity = d_k * np.log(2 * n / np.maximum(d_k, 1))
klog = np.where(np.asarray(k) <= 1, 0.0, 2 * np.log(np.maximum(k, 1)))
conf = np.log((np.pi ** 2) / (6 * delta))
return C * np.sqrt((capacity + klog + conf) / n)
def empirical_rademacher_polynomial(X, k, B, rng):
"""Closed-form empirical Rademacher complexity for the polynomial unit ball."""
V = np.vander(X, k + 1, increasing=True)
Q, _ = np.linalg.qr(V) # thin QR — orthonormal basis for col(V)
n = len(X)
norms = np.empty(B)
for b in range(B):
sigma = rng.choice([-1, 1], size=n)
norms[b] = np.linalg.norm(Q.T @ sigma) / np.sqrt(n)
return norms.mean(), norms.std() / np.sqrt(B)
def estimate_sigma2(X, Y, k_max):
"""Unbiased plug-in noise variance from SVD-pseudoinverse OLS at k_max."""
V = np.vander(X, k_max + 1, increasing=True)
coef, *_ = np.linalg.lstsq(V, Y, rcond=None)
rss = float(np.sum((Y - V @ coef) ** 2))
return rss / max(len(Y) - (k_max + 1), 1)
def aic_penalty(d_k, n, sigma2):
return 2.0 * sigma2 * d_k / n
def bic_penalty(d_k, n, sigma2):
return sigma2 * d_k * np.log(n) / n
def ridge_fit_predict(X, Y, k_max, lam):
V = np.vander(X, k_max + 1, increasing=True)
n, d = V.shape
A = V.T @ V + lam * np.eye(d)
alpha = np.linalg.solve(A, V.T @ Y)
return V @ alpha, alpha
def ridge_effective_dof(X, k_max, lam):
V = np.vander(X, k_max + 1, increasing=True)
s = np.linalg.svd(V, compute_uv=False)
return float(np.sum(s ** 2 / (s ** 2 + lam)))Numerical pitfalls worth flagging. Vandermonde conditioning at high degree: the monomial Vandermonde on points at degree 15 has condition number ; use SVD-pseudoinverse (numpy.linalg.lstsq with rcond=None) or QR rather than the normal equations directly. Numerical lasso convergence: at very small , the lasso fit on a degree-15 Vandermonde converges slowly under coordinate descent; set max_iter generously and suppress benign convergence warnings, or use the Chebyshev basis as the working basis. Plug-in : at small relative to the unbiased estimator has non-trivial variance, and BIC picks can shift by 1–2 degrees across reseeds. The agreement matrix above gives the central pick at the notebook seed; expect drift across alternative seeds.
Connections
- PAC-learning's Fundamental Theorem of Statistical Learning supplies the per-class uniform convergence bound (4.1) that SRM converts into a capacity penalty via §3.1's confidence allocation. Without uniform convergence at every level of the nested family, the union-bound argument that produces the SRM oracle inequality has nothing to work with. pac-learning
- The McDiarmid-plus-symmetrization machinery (`generalization-bounds` §6.3) that establishes (5.1) is the foundation of §5's Bartlett–Mendelson SRM penalty. The Rademacher complexity definition (`generalization-bounds` §3, §5) and Talagrand's contraction lemma (`generalization-bounds` §5.2) are used as given. SRM is the model-selection layer built on top of generalization-bounds' uniform-convergence layer. generalization-bounds
- PAC-Bayes is the continuous-capacity generalization of discrete SRM, with KL divergence between posterior and prior playing the role of the capacity penalty. §9 of this topic reproduces the McAllester bound in SRM form; the Catoni-Gibbs construction that pac-bayes-bounds develops in detail is the soft-to-hard limit of §9.4. pac-bayes-bounds
- Hoeffding's inequality is the workhorse of every uniform-convergence-based SRM penalty. McDiarmid's bounded-differences inequality is required for the Rademacher penalty via symmetrization. §3.4's proof uses the union bound over countably many classes; the per-class Pr[gap > pen] ≤ δ_k comes from Hoeffding-type concentration inside each class. concentration-inequalities
- KL divergence is the load-bearing capacity measure in §9's PAC-Bayes SRM. The closed-form KL between two isotropic Gaussians (eq 9.2) is the workhorse of the §9.5 polynomial-regression PAC-Bayes demo; minimizing KL(Q∥P) under a posterior-averaged training-error constraint is exactly what soft SRM does on the implicit nested family generated by the prior. kl-divergence
- Ensembling and Bayesian model averaging are soft model averaging across the SRM family: instead of picking one $\hat k$, the practitioner combines the predictions of all $\hat h_k$ with weights that reflect each class's posterior probability or stacking score. The SRM oracle inequality bounds the loss of the single picked class; the stacking analogue bounds the loss of the convex combination. stacking-and-predictive-ensembles
References & Further Reading
- paper Principles of Risk Minimization for Learning Theory — Vapnik (1992) The original SRM paper, presenting the penalize-and-pick framework alongside the VC-dimension penalty (NeurIPS 4).
- book The Nature of Statistical Learning Theory — Vapnik (1995) Vapnik's pedagogical presentation of SRM with the canonical δ_k = 6δ/(π²k²) confidence allocation; Chapter 4 (Springer).
- book Statistical Learning Theory — Vapnik (1998) The full mathematical treatment; Chapters 6–7 develop SRM oracle-inequality theory in detail (Wiley).
- paper Structural Risk Minimization over Data-Dependent Hierarchies — Shawe-Taylor, Bartlett, Williamson & Anthony (1998) Extension of SRM to data-dependent (non-nested, capacity-indexed) families (IEEE Trans. Inform. Theory).
- book A Probabilistic Theory of Pattern Recognition — Devroye, Györfi & Lugosi (1996) Comprehensive treatment of nonparametric consistency theory; §17 covers SRM (Springer).
- paper Nonparametric Estimation via Empirical Risk Minimization — Lugosi & Zeger (1995) Quantitative convergence rates for SRM under polynomial approximation conditions (IEEE Trans. Inform. Theory).
- paper Rademacher and Gaussian Complexities: Risk Bounds and Structural Results — Bartlett & Mendelson (2002) The Rademacher-complexity bound (5.1) and the data-dependent SRM penalty of §5 (JMLR).
- paper Rademacher Penalties and Structural Risk Minimization — Koltchinskii (2001) Independent and contemporaneous derivation of Rademacher-penalty SRM (IEEE Trans. Inform. Theory).
- paper PAC-Bayesian Model Averaging — McAllester (1999) The square-root PAC-Bayes bound underlying §9's continuous-capacity SRM (COLT 1999).
- book PAC-Bayesian Supervised Classification: The Thermodynamics of Statistical Learning — Catoni (2007) The linear-form bound and the Gibbs-distribution-as-RHS-minimizer view; §9.4's soft-to-hard limit (IMS Lecture Notes 56).
- paper Computing Nonvacuous Generalization Bounds for Deep (Stochastic) Neural Networks with Many More Parameters than Training Data — Dziugaite & Roy (2017) The first non-vacuous deep-network PAC-Bayes certificate; referenced in §12 as the modern SRM frontier (UAI 2017).
- paper Stability and Generalization — Bousquet & Elisseeff (2002) Algorithmic stability as an alternative SRM-style penalty; complement to capacity-based bounds (JMLR).
- paper Information Theory and an Extension of the Maximum Likelihood Principle — Akaike (1973) The original AIC paper; §8.1's information-theoretic derivation (Second International Symposium on Information Theory).
- paper Estimating the Dimension of a Model — Schwarz (1978) The original BIC paper; §8.2's Bayesian-marginal-likelihood Laplace approximation (Annals of Statistics).
- paper Modeling by Shortest Data Description — Rissanen (1978) Original MDL principle; §8.3's data-compression view of model selection (Automatica).
- paper Solution of Incorrectly Formulated Problems and the Regularization Method — Tikhonov (1963) Original regularization functional; §7.1's Tikhonov-as-soft-SRM identification (Soviet Math. Doklady).
- paper Regression Shrinkage and Selection via the Lasso — Tibshirani (1996) Original lasso paper; §7.3's ℓ¹-penalty soft SRM (JRSS-B).
- paper On the Degrees of Freedom of the Lasso — Zou, Hastie & Tibshirani (2007) Effective DoF of lasso equals number of nonzeros — used in §7.3's lasso capacity formula (Annals of Statistics).
- paper Simultaneous Analysis of Lasso and Dantzig Selector — Bickel, Ritov & Tsybakov (2009) Lasso oracle inequality in SRM shape: $s^* \log p / n$ as the capacity term (Annals of Statistics).
- book Model Selection and Multimodel Inference — Burnham & Anderson (2002) Standard reference for AIC/BIC in applied statistics; complements §8's theoretical treatment (Springer, 2nd ed.).
- paper Support-Vector Networks — Cortes & Vapnik (1995) The original soft-margin SVM paper; §12.1's canonical classical-SRM application (Machine Learning).
- book Learning with Kernels — Schölkopf & Smola (2002) Kernel-method bible; §12.1's margin-as-inverse-capacity view (MIT Press).
- book Convex Optimization — Boyd & Vandenberghe (2004) §5.5 Lagrangian-duality theorem invoked in §6.1 for the constrained-vs-penalized SRM equivalence (Cambridge University Press).
- paper Reconciling Modern Machine-Learning Practice and the Classical Bias–Variance Trade-Off — Belkin, Hsu, Ma & Mandal (2019) The double-descent paper; §12.4's forward-pointer to where classical SRM breaks (PNAS).
- paper Deep Double Descent: Where Bigger Models and More Data Hurt — Nakkiran, Kaplun, Bansal, Yang, Barak & Sutskever (2020) Empirical confirmation of double descent in deep networks; §12.4 background (ICLR 2020).
- paper Benign Overfitting in Linear Regression — Bartlett, Long, Lugosi & Tsigler (2020) Modern overparameterized-regime theory; §12.3 background (PNAS).
- paper Spectrally-Normalized Margin Bounds for Neural Networks — Bartlett, Foster & Telgarsky (2017) Spectral-norm complexity measure for deep nets; §12.2 modern-bound thread (NeurIPS 30).
- paper Almost Linear VC-Dimension Bounds for Piecewise Polynomial Networks — Bartlett, Maiorov & Meir (1998) The W L log W VC bound for deep nets used in §12.2 (Neural Computation).
- paper Consistency of Cross Validation for Comparing Regression Procedures — Yang (2007) Modern CV-oracle-inequality theory referenced in §10.2 for infinite families (Annals of Statistics).
- paper A Theory of Learning from Different Domains — Ben-David, Blitzer, Crammer, Kulesza, Pereira & Vaughan (2010) Domain-adaptation generalization theory; §13.4's distribution-shift caveat (Machine Learning).
- book Foundations of Machine Learning — Mohri, Rostamizadeh & Talwalkar (2018) Standard graduate text; Chapter 4 on Rademacher complexity and Chapter 11 on model selection complement §§4–5 and §10 (MIT Press, 2nd ed.).
- book Concentration Inequalities and Model Selection — Massart (2007) The technical reference for SRM-style penalty theory; §13.5 further reading (Springer Lecture Notes in Mathematics 1896).