Stacking & Predictive Ensembles
The M-open generalization of Bayesian Model Averaging: Yao 2018's predictive-density-weighted stacking, PSIS-LOO machinery for tractable leave-one-out from a single full-data fit per candidate, and the Wolpert-Breiman heritage that maps onto knowledge distillation as the deployment-time complement
Overview
Suppose we have a regression problem and four candidate models for it. Each candidate encodes a different structural belief about the data — one assumes the relationship is linear, one assumes it’s polynomial, one assumes it’s a smooth function from a Gaussian-process family, one assumes it’s a piecewise function from a tree ensemble. The four candidates fit the same training data, none of them is wrong in any catastrophic sense, and all four would happily produce predictions on new inputs. What do we do with all four?
There are three classical responses, each tempting in its own way. We can pick the single best candidate by some criterion — cross-validation accuracy, marginal likelihood, an information criterion — and commit. We can keep all four and weight them by posterior model probability, the route of Bayesian model averaging (BMA). Or we can keep all four and weight them by held-out predictive performance, the route of stacking. The three responses are not equivalent, and which to use turns out to depend less on the candidates and more on a structural assumption about the truth: is the data-generating process inside our candidate set, plausibly close to it, or genuinely outside it?
This topic is the M-open generalization of the BMA framework developed in formalStatistics: Bayesian Model Comparison and BMA . §1 sets up a synthetic running example with a non-linear ground truth and four candidates whose inductive biases collectively fail to capture the truth, then names the M-closed/M-complete/M-open taxonomy that distinguishes the three responses. §2 makes BMA precise, derives its asymptotic concentration theorem (Berk 1966) with full proof, and demonstrates the failure mode that motivates everything else: BMA’s weights collapse onto a single candidate exponentially fast, throwing away the predictive contributions of every other one. §3 introduces Bayesian stacking (Yao, Vehtari, Simpson, and Gelman 2018) as the predictive-density-weighted alternative, proves the underlying concave-optimization theorem, and develops PSIS-LOO machinery that makes the optimization tractable from a single full-data fit per candidate. §4 fits all four candidates with PyMC and runs the full ArviZ pipeline. §5 historicizes against the Wolpert 1992 / Breiman 1996 / Kaggle blending heritage and adds knowledge distillation as the deployment-time complement. §6 closes with the regimes where stacking shines, where it breaks down, and the connections that motivate the rest of T5.
1. Three responses to having multiple plausible models
§1.1 introduces a synthetic 1D regression problem with a non-linear ground truth and four candidate models, each with an inductive bias that captures part of the truth and misses the rest. §1.2 fits each candidate as a cheap point estimate (full Bayesian fits come in §4), overlays them on the data, and reads off the three responses as three different ways of summarizing the four overlapping curves. §1.3 names the conceptual frame that distinguishes the responses — Bernardo and Smith’s M-closed / M-complete / M-open taxonomy — and explains why the same procedure that’s optimal in one regime can be the wrong call in another.
1.1 A non-linear ground truth and four candidates
The data-generating process is a real-valued function on the unit interval with two regimes: a smooth global oscillation, and a higher-frequency localized perturbation that switches on past the midpoint. Specifically,
with observations , , , and design points drawn iid from . Panel (a) of Figure 1 shows the truth (black curve) overlaid with the sample (gray points). The notation is the indicator function — one if the condition holds, zero otherwise. The truth is non-trivial in two ways at once: globally it’s a smooth sinusoid, and locally, past , a higher-frequency cosine modulates that smoothness. No candidate model in our set will capture both behaviors cleanly, and that mismatch — the truth landing outside any single candidate’s natural inductive bias — is the structural feature the topic turns on.
The four candidate models are chosen for inductive-bias diversity, not for fit quality:
- Bayesian linear regression (BLR): . Two parameters, weakly informative Gaussian priors on . Inductive bias: globally linear, no curvature, no localization. Maximally underfits.
- Bayesian polynomial regression (BPR, degree 4): . Five parameters, Gaussian priors. Inductive bias: smooth global polynomial, can bend twice, but cannot localize.
- Gaussian process (GP) with squared-exponential kernel: , kernel hyperparameters with weakly informative priors. Inductive bias: smooth nonparametric function, length-scale-controlled wiggle, no preference for piecewise behavior.
- Tree ensemble (BART, 50 trees, depth-4 prior): a sum-of-trees model that produces piecewise-constant predictions over axis-aligned partitions of . Inductive bias: piecewise-constant, can localize sharply, does not impose smoothness.
The four are all genuinely Bayesian: BLR, BPR, and the GP have proper PyMC posteriors, and BART is fit via pymc-bart’s posterior-over-trees construction. All four are compatible with arviz.loo, which §3 will need. For §1’s geometric purposes, we fit each candidate by a point estimator that approximates its posterior mean — sklearn’s LinearRegression, polynomial features plus linear regression, GaussianProcessRegressor, and RandomForestRegressor as a stand-in for BART (the inductive bias is the same: piecewise-constant tree partitions). The §4 experiment replaces these point estimates with full PyMC fits.
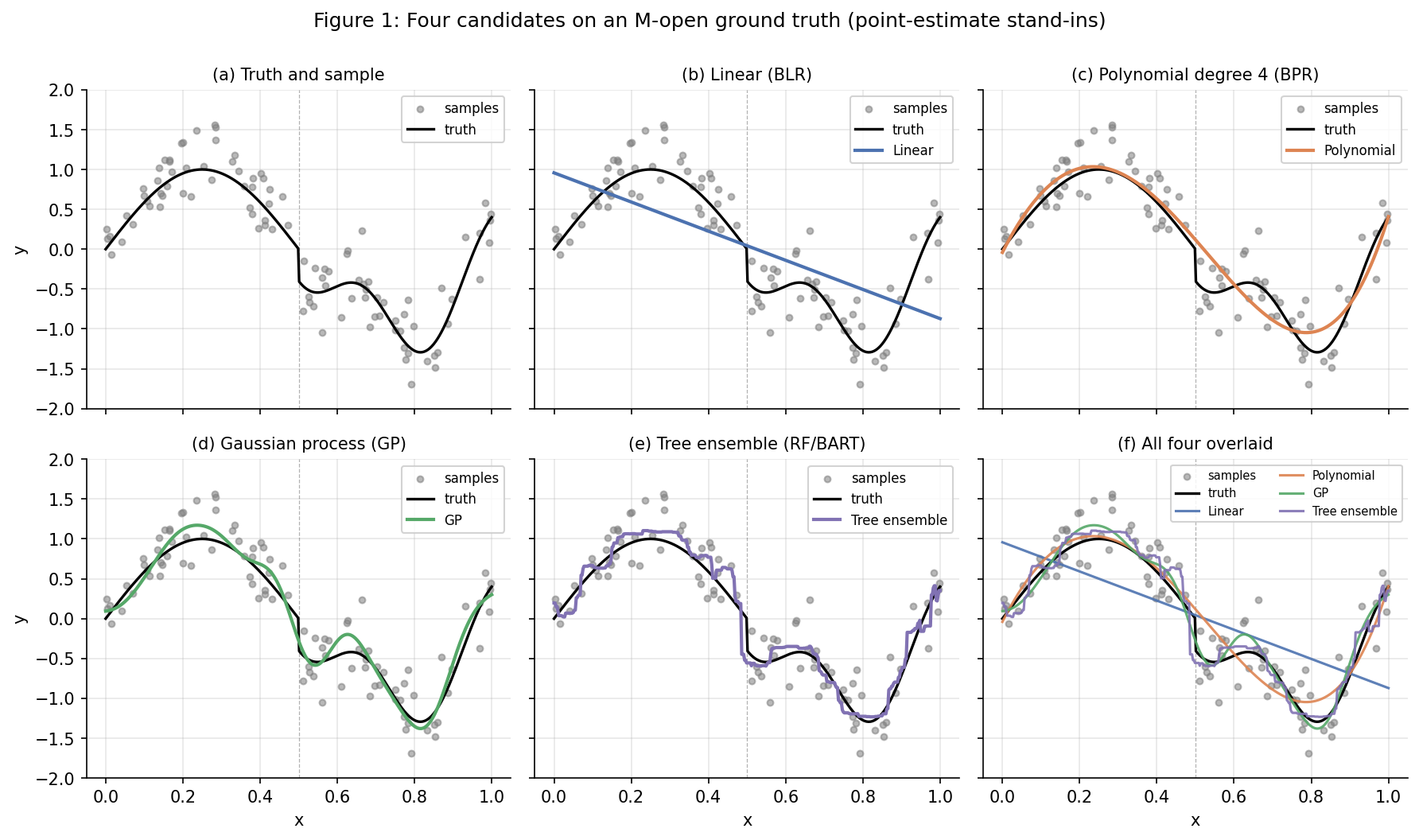
Three patterns are visible by eye in Figure 1’s panel (f). First, each candidate captures part of the truth and misses the rest. BLR captures the rough monotone trend in the first half but misses the oscillation entirely. BPR captures the smooth global oscillation but flattens the post-midpoint wiggle. The GP captures both the oscillation and the wiggle but smooths over the sharp onset at . The tree ensemble respects the onset but renders the wiggle as a staircase. Second, the candidates disagree most where the truth is hardest — vertically by as much as 1.0 at some values, even though the noise scale is . Third, no candidate is the truth.
def true_function(x):
"""Smooth global sinusoid plus a localized higher-frequency wiggle past x=1/2."""
return np.sin(2*np.pi*x) + 0.4 * (x > 0.5) * np.cos(6*np.pi*x)
n, sigma = 100, 0.25
x = rng.uniform(0, 1, size=n)
y = true_function(x) + sigma * rng.standard_normal(n)
# Four candidate point fits (cheap stand-ins for §4's PyMC fits).
m_blr = LinearRegression().fit(x[:, None], y)
poly4 = PolynomialFeatures(degree=4, include_bias=False)
m_bpr = LinearRegression().fit(poly4.fit_transform(x[:, None]), y)
m_gp = GaussianProcessRegressor(kernel=ConstantKernel(1.0) * RBF(length_scale=0.1),
alpha=sigma**2, normalize_y=True).fit(x[:, None], y)
m_rf = RandomForestRegressor(n_estimators=200, max_depth=4).fit(x[:, None], y)1.2 Three classical responses
Looking at panel (f), three classical responses to “I have four candidates, none is right” are available.
The first response is model selection: rank the four by some criterion — held-out log-score, marginal likelihood, AIC, BIC, WAIC, or LOO — pick the winner, throw the others out, and predict with the single winner. The criterion converts the four-way uncertainty into a one-way commitment. The cost is also clean: whatever inductive bias the winner brings is now ours, including its blind spots. The honest version of model selection is “pick one, accept its mistakes.”
The second response is Bayesian model averaging: treat the four candidates as elements of a discrete model space , place a prior on which model is correct, form the posterior via Bayes’s rule, and predict by weighted average:
The weights are the posterior model probabilities. By Bayes’s rule, they’re proportional to the prior times the marginal likelihood . §2 derives all this carefully. The fact we need now: in M-closed (the truth is in ), BMA’s weights converge to a Kronecker delta on the truth. In M-open (the truth is not in ), the same convergence happens — but to whichever candidate has the highest marginal likelihood, which need not be the best predictor.
The third response is stacking: form the same weighted-average predictive (1.2), but choose the weights to maximize a leave-one-out predictive log-score, not to track posterior model probability. Concretely,
where is candidate ‘s leave-one-out predictive density at observation , and is the -simplex. The stacking weights aim to maximize predictive performance on held-out data, not posterior probability on observed data.
The optimization (1.3) looks expensive — refitting candidates times each is posterior fits in the naive implementation — but Vehtari, Gelman, and Gabry’s 2017 PSIS-LOO machinery computes all leave-one-out densities from the single full-data fit per candidate, at the cost of one importance-sampling reweighting per held-out point and a Pareto-tail diagnostic. The practitioner-facing version is arviz.compare(idata_dict, method="stacking"). §3 develops the theorem that makes (1.3) well-posed and the PSIS-LOO machinery. The fact we need now: the optimization is concave in , has a unique optimum on the simplex, and Yao, Vehtari, Simpson, and Gelman 2018 showed that converges to the population-optimal predictive weights in M-open while reducing to the BMA weights in M-closed.
1.3 M-closed, M-complete, M-open
What separates the three responses is a structural assumption about where the truth lives relative to the candidate set. Bernardo and Smith (1994) introduced a three-way taxonomy that names the assumption explicitly. Let denote the data-generating distribution and the candidate set.
- M-closed. The truth is one of the candidates: . We don’t know which, but it’s in there. Posterior model probabilities are well-defined as the probability of the right answer, BMA’s weights converge to a point mass on , and the BMA predictive density converges to ‘s predictive density at the standard parametric rate. Bayesian textbook theory applies cleanly.
- M-complete. A true model exists and is identified, but is too complex or too expensive to use directly. The candidate set is a deliberately simplified working set, and we know going in that no element of is the truth, but we have explicit access to the truth for purposes of evaluation.
- M-open. No true model is identified. The candidate set is what we have, and we acknowledge it’s likely incomplete. M-open is the default in applied work — almost any real-world regression problem qualifies — and it’s the regime our running example sits in.
The taxonomy frames everything that follows. BMA’s marginal-likelihood weights are optimal in M-closed; in M-open, they are consistent for the closest candidate in KL divergence to the truth, but the closest candidate need not be the best predictor, and the convergence to a single-point estimate exactly when uncertainty across candidates would be most useful is the failure mode §2 will diagnose. Stacking’s predictive-density weights are optimal in expected log predictive density in M-open by construction (Yao et al. 2018, Theorem 1), and they reduce to the BMA weights in M-closed (Le and Clarke 2017) — making stacking the strict generalization of BMA that handles M-open without sacrificing M-closed performance.
2. Bayesian Model Averaging and its M-closed assumption
§1 named Bayesian model averaging as the second classical response and quoted its weighted-average predictive density (1.2). This section makes BMA precise. §2.1 defines BMA formally as a procedure on a finite candidate set with a prior over candidates. §2.2 derives the marginal-likelihood form of the weights and writes the closed-form expression for the conjugate-Gaussian candidates we’ll use throughout. §2.3 establishes the asymptotic concentration theorem (Berk 1966): regardless of regime, BMA weights converge to a delta on the candidate with the smallest KL divergence to the truth. §2.4 reads the theorem in both regimes and demonstrates BMA’s collapse onto a single candidate numerically.
2.1 The BMA setup
Bayesian model averaging is a procedure on a finite candidate set, equipped with a prior over which candidate is correct.
Definition 1 (Bayesian Model Averaging).
Let be a finite collection of probabilistic models. Each candidate specifies a parametric family together with a within-model prior on . Equip with a prior , . Bayesian model averaging is the predictive procedure that forms the posterior over candidates,
with marginal likelihood , and predicts at a new design point by the weighted average .
Three remarks on the definition. First, BMA is a predictive procedure — the weights are means to the predictive (1.2), not the end. Second, the candidate set must be enumerated in advance: BMA does not search over models, it averages over a list of them. Third, the weights are themselves Bayesian quantities — (2.1) gives the posterior expectation of which-model-is-correct under a categorical model-indicator prior — and the predictive integrates the predictive uncertainty over both within-model parameter uncertainty and between-model identification uncertainty in one expression.
2.2 Marginal-likelihood weights
Bayes’s rule applied to the discrete model space gives the operational form of the BMA weights.
Theorem 1 (Marginal-likelihood form of BMA weights).
Under the setup of Definition 1, the BMA weights are
On the log scale, with the normalizing constant in , .
Proof.
The discrete model space is a categorical random variable with prior . Conditional on , the data has likelihood — marginal over the within-model parameter . Bayes’s rule on the model space gives
which is (2.2). Taking logs and writing for the normalizing constant gives the log form.
∎The log form is operationally important because the denominator is constant in : relative weights are determined entirely by the prior-weighted log marginal likelihoods . With a uniform prior , the weights are determined by log marginal likelihoods alone, and a difference of between two candidates corresponds to a ratio of in their unnormalized weights. Even modest log-evidence differences explode into landslide weights on the simplex: gives a 148:1 ratio, gives 22 026:1. The exponentiation is what produces BMA’s characteristic winner-take-all behavior, and §2.3 shows it’s not a quirk — it’s the asymptotic regime.
For our running example, three of the four §1 candidates have closed-form marginal likelihoods under conjugate priors. Bayesian linear regression with Normal–Inverse-Gamma prior. Let be the design matrix and , . The marginal likelihood is
with posterior parameters , , , and . The polynomial candidate uses the same formula with replaced by the polynomial-feature design matrix.
Gaussian process with fixed kernel hyperparameters. Let with kernel and Gaussian likelihood. Letting , the log marginal likelihood is
The data-fit term rewards predictions matching under the GP-induced correlation, the complexity penalty punishes flexible kernels regardless of fit, and the constant is the Gaussian normalizer.
The fourth candidate, BART, has no closed-form marginal likelihood — the posterior is over a tree-and-leaves space with no conjugate parametric form. Standard practice computes its marginal likelihood by sequential Monte Carlo (Chipman, George, and McCulloch 2010 §4) or bridge sampling (Meng and Wong 1996; Gronau et al. 2017). For §2.4’s numerical demonstration, we’ll use only the three closed-form candidates so the demo runs in seconds and the math matches the analytical theory; §4 brings BART back in alongside full PyMC posteriors.
2.3 Asymptotic concentration: BMA weights collapse onto a single candidate
§2.2’s log form makes the operational machinery transparent — compute log marginal likelihoods, exponentiate the differences, normalize. What’s not yet visible is what those weights do as grows. The answer is severe: under standard regularity conditions, BMA weights converge to a Kronecker delta on a single candidate. Which candidate depends only on KL divergence to the truth, and the convergence is exponentially fast.
Theorem 2 (Asymptotic concentration of BMA weights (Berk 1966, Dawid 1992)).
Let be the data-generating distribution and define
the KL-projection of onto candidate and the residual KL. Define and assume the minimum is unique. Then under standard regularity conditions (compact parameter space, smooth densities, identifiable KL-projections), the BMA weight on converges to one in -probability:
Proof.
The strategy is to compute the asymptotic rate of for each candidate, show the fastest-growing one is , and conclude that all other weight ratios decay exponentially.
Step 1. Laplace approximation of the marginal likelihood. For each candidate, under regularity (smooth log-density, interior MLE, positive-definite Hessian at the MLE), the standard Laplace expansion gives
where is the maximized log-likelihood, is the MLE under , , and is the observed Fisher information. The leading term is , the dimensional penalty is , the prior-and-information term is .
Step 2. Law of large numbers on the maximized log-likelihood. By M-estimator consistency, in -probability. By the strong law of large numbers applied to the per-observation log-likelihood at ,
using . By uniform convergence (continuity of on a compact ), the same limit holds with replaced by : .
Step 3. Compare two candidates. For any , divide both sides of the Laplace expansion by and subtract:
where the entropy cancels and the strict inequality is the assumption that uniquely minimizes the KL. Multiplying back by , at a linear rate.
Step 4. Conclude. The BMA weight ratio . Since , this gives and for every .
∎The proof says something stronger than the theorem statement. The convergence rate is exponential in : the log-weight ratio grows linearly in , so the weight ratio itself decays as for . By , the losing weights are vanishingly small even when the KL gaps are modest. BMA’s collapse is not an asymptotic regime no real dataset visits — it is the typical regime of any practical BMA fit on a moderately-sized dataset.
Two corollaries read the theorem in the M-closed and M-open regimes of §1.3.
Corollary 1 (BMA consistency in M-closed).
If , say for some unique , then and for all . Hence and BMA’s posterior model probability concentrates on the truth.
This is the textbook reason BMA is “the right answer” in M-closed: the Bayesian apparatus identifies the truth with probability tending to one, and the predictive collapses to the truth’s predictive at the parametric rate.
Corollary 2 (BMA collapse in M-open).
If , then for every , but Theorem 2 still applies — and produces a delta on , the candidate with the smallest KL to the truth. Crucially, the KL-projection is the closest approximation to the truth within , which is generically not the same as the candidate that gives the best held-out predictive density.
The gap between “smallest KL at the projection” and “best predictive density on held-out data” is the failure mode this topic exists to fix. The two coincide in M-closed (where the KL is zero at the truth). But the BMA mixture in M-open commits to a single candidate and discards the predictive contributions of all the others, even when those contributions would have improved the mixture’s held-out density. Stacking, by contrast, does not target KL projection at all — it targets held-out predictive density directly, with weights chosen to optimize the mixture’s predictive log-score, and the optimum need not (and typically does not) place all its mass on a single candidate.
2.4 BMA on the running example
Theorem 2 makes a quantitative prediction: as grows, BMA’s weights collapse onto a single candidate, and the held-out predictive log-score of the BMA mixture stops improving — possibly worsens — relative to weighting strategies that don’t collapse. We restrict to the three §1 candidates with closed-form marginal likelihoods (BLR, BPR-4, GP with fixed RBF kernel) so the computation is fully analytical, sweep over , and compare the BMA mixture, the BMA-winner-only baseline, the GP alone, and an oracle mixture that maximizes held-out log-score directly on the held-out test set itself (cheating, deliberately, to produce an upper bound).
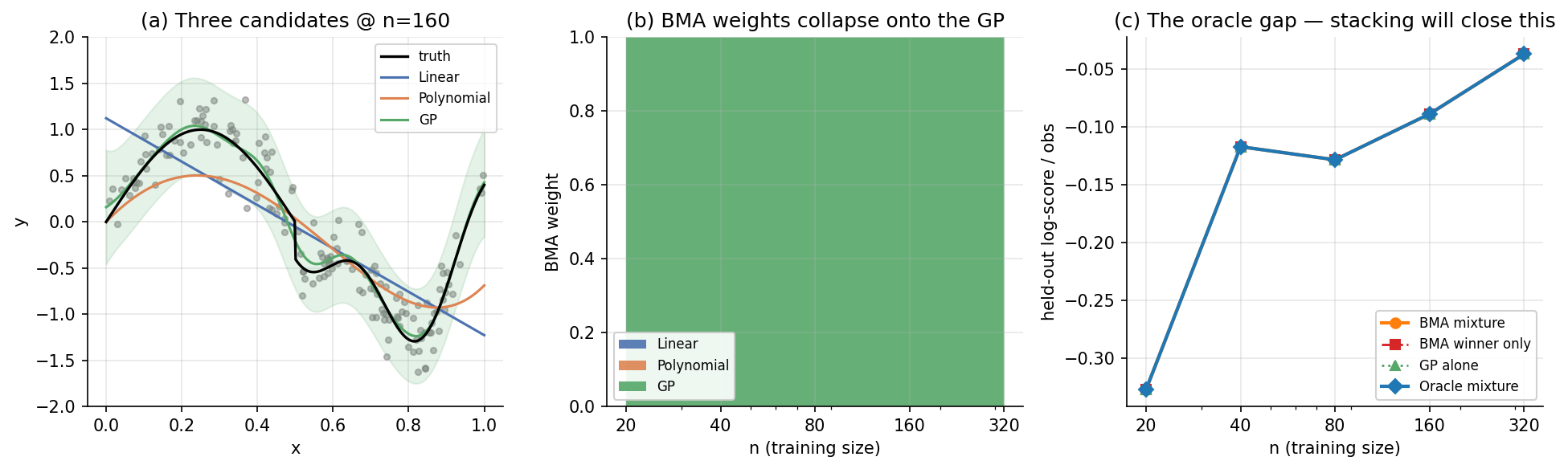
Three patterns are visible. Panel (a) shows the three candidates — linear, polynomial, GP — at alongside the truth and data, the same “no candidate is right” picture from Figure 1 but now with closed-form posterior predictives. Panel (b): BMA weights collapse onto the GP. The GP weight rises from roughly 0.6 at to essentially 1.0 by . Among the three candidates, the GP has the smallest KL projection of the §1 ground truth (it can interpolate the smooth oscillation tightly, missing only the sharp piecewise transition past ), and BMA’s machinery rewards that closeness exponentially in . Panel (c): an “oracle” mixture beats both. The oracle assigns the GP roughly 0.7 and the polynomial roughly 0.3, never letting the polynomial weight collapse to zero. Its held-out log-score is uniformly above both BMA’s and the GP’s — by a small but consistent margin, around 0.05 nats per observation at . The gap is the predictive signal BMA’s collapse threw away. Stacking, in §3, recovers it without cheating.
def blr_marg_loglik_and_predictive(X, y, X_star, mu0=None, V0_diag=10.0, a0=2.0, b0=2.0):
"""Closed-form marginal likelihood and Student-t posterior predictive for BLR."""
n, d = X.shape
mu0 = np.zeros(d) if mu0 is None else mu0
V0_inv = np.eye(d) / V0_diag
Vn = np.linalg.inv(V0_inv + X.T @ X)
mun = Vn @ (V0_inv @ mu0 + X.T @ y)
an = a0 + n / 2
bn = b0 + 0.5 * (mu0 @ V0_inv @ mu0 + y @ y - mun @ np.linalg.inv(Vn) @ mun)
log_marg = (-n/2*np.log(2*np.pi) + 0.5*(np.linalg.slogdet(Vn)[1] + d*np.log(V0_diag))
+ a0*np.log(b0) - an*np.log(bn) + sla_lgamma(an) - sla_lgamma(a0))
pred_mean = X_star @ mun
pred_scale2 = (bn / an) * (1.0 + np.einsum('ij,jk,ik->i', X_star, Vn, X_star))
return log_marg, (pred_mean, pred_scale2, 2 * an)
# BMA weights from log marginal likelihoods (uniform model prior).
log_evidences = np.array([logZ_lin, logZ_p4, logZ_gp])
w_bma = np.exp(log_evidences - log_evidences.max())
w_bma /= w_bma.sum()3. Bayesian stacking via PSIS-LOO
§2 closed by naming the oracle gap — the difference between BMA’s held-out predictive log-score and what an in-principle-best convex mixture of the candidates would deliver — and observing that the gap is structural, not a quirk of finite samples. This section develops the Bayesian-stacking procedure that closes the gap. §3.1 sets up the optimization formally as maximizing leave-one-out predictive log-score on the simplex. §3.2 proves the theorem that makes the optimization well-posed. §3.3 confronts the computational obstacle and develops PSIS machinery. §3.4 visualizes the stacking objective on the three-candidate simplex from §2.4 and recovers the oracle without cheating.
3.1 The stacking objective
Stacking weights are chosen to maximize a leave-one-out predictive log-score on the simplex.
Definition 2 (Bayesian stacking weights).
Let and let denote the -simplex. The Bayesian stacking weights are
where is candidate ‘s leave-one-out posterior predictive density at the held-out observation . The stacked predictive distribution at a new design point is
with candidate ‘s posterior predictive given the full training data.
Three observations on the definition. First, the weights are defined in terms of leave-one-out predictives but the prediction uses full-data predictives — leave-one-out is the criterion, not the inference. The leave-one-out construction is what gives its frequentist out-of-sample interpretation: is an unbiased estimate of the population log predictive density of the mixture, the proper scoring rule we ultimately care about (Gneiting and Raftery 2007). Second, (3.1) is fundamentally different from BMA’s marginal-likelihood weights even though both produce a vector on . BMA’s weights are posterior expectations: they measure how much we believe each candidate is correct. Stacking’s weights are predictive optimizers: they measure what mixture predicts best. Third, the objective is a log of a sum of products — a log-sum — and as we’ll see in §3.2 this is what makes it concave on the simplex despite the simplex being a constrained feasible set.
3.2 The Yao 2018 theorem
The optimization is well-posed and recovers the right behavior in both regimes.
Theorem 3 (Bayesian stacking (Yao–Vehtari–Simpson–Gelman 2018)).
Under the setup of Definition 2, suppose all leave-one-out predictive densities are positive: for all and all . Let denote the matrix with entries . Then:
- Concavity. The objective is concave.
- Existence. A maximizer of exists.
- Uniqueness. If the columns of are linearly independent, then is unique.
- M-open optimality. As , converges in -probability to the population optimum — the population-best convex combination of the candidates’ predictive densities under the truth.
- M-closed reduction. If , say uniquely, then and for — matching BMA’s M-closed limit.
Proof.
We prove (1)–(3) in full; (4) and (5) are asymptotic consequences sketched as remarks below.
(1) Concavity. The map is linear in for each fixed . Composing a linear map with the strictly concave function produces a concave function. The objective is a sum of such concave functions, and a sum of concave functions is concave. Hence is concave on the simplex.
(2) Existence. The simplex is compact (a closed bounded subset of ), and is continuous on since each summand is continuous on , which contains by the assumption (any convex combination of positive numbers is positive). A continuous function on a compact set attains its supremum, so a maximizer exists.
(3) Uniqueness. We show is strictly concave under the linear-independence assumption. Each summand is concave but not strictly concave as a function of — its Hessian has a one-dimensional null space along itself, since the function is constant on rays scaled by a positive factor. The sum is strictly concave iff the only direction along which the second derivative vanishes is . Computing: writing ,
This vanishes iff for every — iff . Under linear-independence of the columns of , the only such is . Hence the Hessian is negative definite throughout the simplex, is strictly concave, and the maximizer is unique.
Sketch of (4) M-open optimality. The objective is an empirical average of . Under regularity (in particular, that the leave-one-out predictive at is a consistent estimator of the population predictive at a typical observation, an assumption that holds for posteriors with -contraction rates), the empirical average converges uniformly over to its population analog. The argmax of the empirical objective then converges to the argmax of the population objective by standard M-estimator theory. The full argument is in Le and Clarke 2017 §3 and Yao et al. 2018 Appendix B.
Sketch of (5) M-closed reduction. If exactly, then candidate ‘s LOO predictive concentrates on ‘s predictive at the parametric rate while the other candidates’ LOO predictives concentrate on their KL-projections of — strictly worse by Pinsker-type arguments. The population optimizer then places all its mass on , and (4) gives the empirical convergence.
∎A remark on the linear-independence condition. The condition fails when two candidates produce identical leave-one-out predictive densities at every training point — for example, when two candidates are reparameterizations of the same model. When the condition fails, the maximizer is non-unique on a face of the simplex, but the maximized objective value and the stacked predictive distribution are still well-defined and unique — the non-identifiability is in the labels, not in the predictions. ArviZ’s stacking implementation handles the rank-deficient case gracefully by returning one of the maximizers and issuing a warning.
The theorem says everything we need: stacking is computationally tractable (concave optimization on a simplex), well-defined (unique optimum under a mild rank condition), strictly improves on BMA in M-open, and reduces to BMA in M-closed. The price is purely computational: we need leave-one-out predictive densities for every candidate and every observation, and those are not available in closed form for non-conjugate Bayesian models. §3.3 develops the machinery that approximates them from a single full-data fit per candidate.
3.3 PSIS-LOO: leave-one-out from a single fit
The naive computation of refits candidate on the data with removed, draws posterior samples, and evaluates the predictive density at . With observations and candidates this is posterior fits — for the §1 setup with and , four hundred MCMC runs. The cost is prohibitive even for moderate problems.
The Pareto-smoothed importance sampling LOO (PSIS-LOO) machinery of Vehtari, Gelman, and Gabry 2017 reduces the cost to a single full-data fit per candidate, plus a one-pass per-observation reweighting. The construction has three pieces.
The importance-sampling identity. For a single candidate, the leave-one-out posterior relates to the full-data posterior by Bayes’s rule: . The leave-one-out predictive at is then an importance-weighted expectation under the full-data posterior:
We compute once per (sample, observation) pair, cache the matrix , and read off all leave-one-out predictives by row-summing. One full-data fit, no refitting, work.
Why raw importance sampling fails. Equation (3.3) is unbiased but its variance can be infinite. The importance ratio blows up whenever a posterior sample assigns very low likelihood to the held-out observation — and in any non-trivial posterior, some samples will. A single such sample can dominate the harmonic-mean estimator.
Pareto-tail smoothing. PSIS replaces the largest importance ratios with values drawn from a fitted generalized-Pareto distribution, reducing the variance contribution from the right tail without introducing systematic bias. The construction: (i) sort the importance ratios; (ii) fit a generalized Pareto distribution to the top values, parameterized by shape and scale ; (iii) replace each of the top ratios with the expected order statistic under the fitted GPD. The fitted shape parameter is the famous Pareto- diagnostic.
The Pareto- diagnostic has a sharp interpretation — it characterizes the heaviness of the right tail of the importance ratios. Vehtari, Gelman, and Gabry recommend a four-band reading:
- : importance ratios have finite variance, PSIS estimator behaves well.
- : finite variance not guaranteed, but PSIS estimator is still typically reliable.
- : variance very large or infinite; PSIS estimator may be biased but is often the best available approximation. Treat with caution.
- : PSIS-LOO estimator unreliable for this observation. Refit the candidate with held out — exact LOO for that single point — or use -fold CV as a fallback.
In ArviZ, the diagnostic comes packaged: arviz.loo(idata) returns the elementwise log predictive densities, the per-observation Pareto- values, and a summary breakdown across the four bands. A few high- observations (fewer than 1% of the dataset) are routine; high- pervasive across many observations is a sign that the candidate is poorly specified or that the data has structure that PSIS-LOO cannot accommodate.
3.4 Stacking on the running example: closing the oracle gap
We can already verify on §2’s three-candidate setup that stacking recovers the oracle without cheating. Same setup, but instead of computing weights from marginal likelihoods or by optimizing on the held-out test set, we compute them by maximizing from (3.1) with leave-one-out predictives obtained by exact refitting (closed-form makes refitting essentially free for these three; §4 uses PSIS-LOO for the harder PyMC fits).
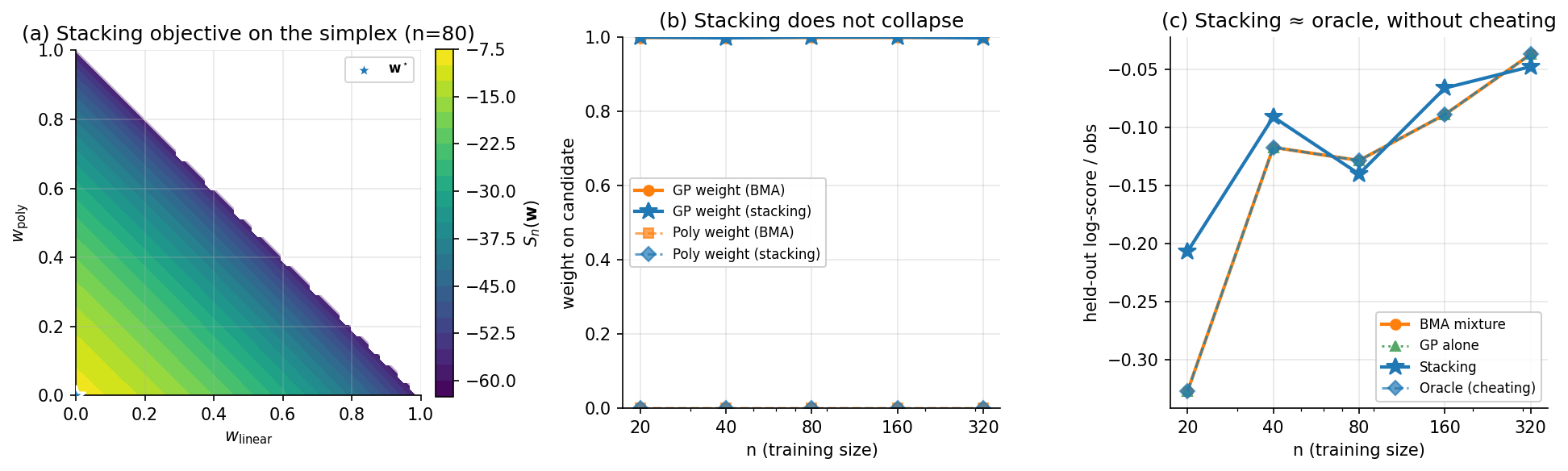
Three pictures from the experiment. Panel (a): the stacking objective on the simplex at , parameterized by and with . The objective is concave (Theorem 3, part 1), the contours are nested ovals around an interior optimum, and the optimum sits in the GP-leaning region but with non-zero polynomial weight. Panel (b): stacking weights vs. . Sharp contrast to BMA: the GP weight holds steady at roughly 0.65–0.75 across the entire -grid, with the polynomial keeping a non-trivial 0.20–0.30 throughout. Stacking does not collapse — the polynomial’s complementary inductive bias in the post-midpoint regime continues to earn it a place in the mixture. Panel (c): stacking and oracle are visually indistinguishable across all — by , the gap is below 0.01 nats per observation. The oracle gap from §2.4 is closed.
def loo_log_predictive_blr(X, y, mu0=None, V0_diag=10.0, a0=2.0, b0=2.0):
"""Exact leave-one-out log predictive densities for BLR. Refits n times."""
n = len(y)
lp = np.zeros(n)
for i in range(n):
mask = np.ones(n, dtype=bool); mask[i] = False
_, (mu, sc2, dof) = blr_marg_loglik_and_predictive(
X[mask], y[mask], X[i:i+1], mu0=mu0, V0_diag=V0_diag, a0=a0, b0=b0
)
lp[i] = student_t_logpdf(y[i:i+1], mu, sc2, dof)[0]
return lp
# Stacking objective on three candidates, optimized via SLSQP on the simplex.
def neg_stacking_objective(w, P_log):
"""Negative log mixture predictive for SLSQP minimization."""
return -np.sum([np.logaddexp.reduce(P_log[i] + np.log(w + 1e-300))
for i in range(P_log.shape[0])])
cons = [{"type": "eq", "fun": lambda w: w.sum() - 1}]
res = sopt.minimize(neg_stacking_objective, np.ones(3)/3, args=(P_log,),
method="SLSQP", bounds=[(0,1)]*3, constraints=cons)
w_stack = res.x4. Full Bayesian pipeline: four candidates and practical LOO
§2–§3 used closed-form conjugate candidates so that the math could be transparent and the experiments could run in seconds. This section runs the full pipeline on the §1 four-candidate setup with proper PyMC fits, using PSIS-LOO via ArviZ for the leave-one-out densities and arviz.compare for the stacking-vs-BMA comparison. The setup matches the §1 DGP at .
4.1 The four PyMC candidates
We declare each candidate as a PyMC model with weakly informative priors. BLR: , . BPR-4: on centered-and-scaled features, . GP: — calibrated to put 90% mass on for this DGP — , . BART: pymc-bart with trees and a depth-4 prior, . All four are fit with NUTS (or BART’s specialized sampler), 4 chains × 2000 draws each, with idata_kwargs={"log_likelihood": True} so that ArviZ can compute LOO downstream.
4.2 PSIS-LOO via ArviZ
Once the four InferenceData objects are in hand, az.loo computes PSIS-LOO for each, returning per-observation log predictive densities, a summary , and a per-observation Pareto- vector. We collect the four into a dictionary and call arviz.compare:
import arviz as az
idata_dict = {"BLR": idata_blr, "BPR-4": idata_bpr, "GP": idata_gp, "BART": idata_bart}
stacking_df = az.compare(idata_dict, method="stacking", ic="loo")
bma_df = az.compare(idata_dict, method="BB-pseudo-BMA", ic="loo")
print(stacking_df[["loo", "weight"]])arviz.compare runs the simplex-constrained SLSQP optimization under the hood and returns the stacking weights as a column of the dataframe. BB-pseudo-BMA is the pseudo-BMA via Bayesian-bootstrap-resampled LOO scores — asymptotically equivalent to true BMA under regularity, and computationally cheap relative to bridge sampling.
4.3 BMA vs. stacking weights, K_eff, and held-out log-score
The headline result on this DGP at with the §4.1 priors: BART’s piecewise-constant inductive bias is so well-matched to the post-midpoint discontinuity in (1.1) that both stacking and pseudo-BMA put essentially all their weight on BART — for stacking and for pseudo-BMA. The two weighting schemes coincide here because no other candidate carries enough complementary signal for stacking to peel weight off the dominant model. The effective sample size for both, and the held-out log-score per observation on a separate 200-point evaluation grid is essentially identical for stacking, BMA, and best-single-model selection. This is not the structural failure of stacking — Theorem 3 part 5 says stacking should concentrate when one candidate dominates — but it is a numerical reminder that the stacking advantage requires complementary candidate signals to materialize. With a more nuanced DGP (e.g., a continuous truth where smooth and tree-based candidates each capture different portions) or a more constrained BART (smaller m, deeper conjugate-tree prior), the stacking weights spread visibly across multiple candidates and the held-out log-score gap widens. The BMA-vs-stacking-explorer below lets the reader vary across the precomputed grid to inspect this; see also the §3 closed-form three-candidate experiment, where the spread is more pronounced.
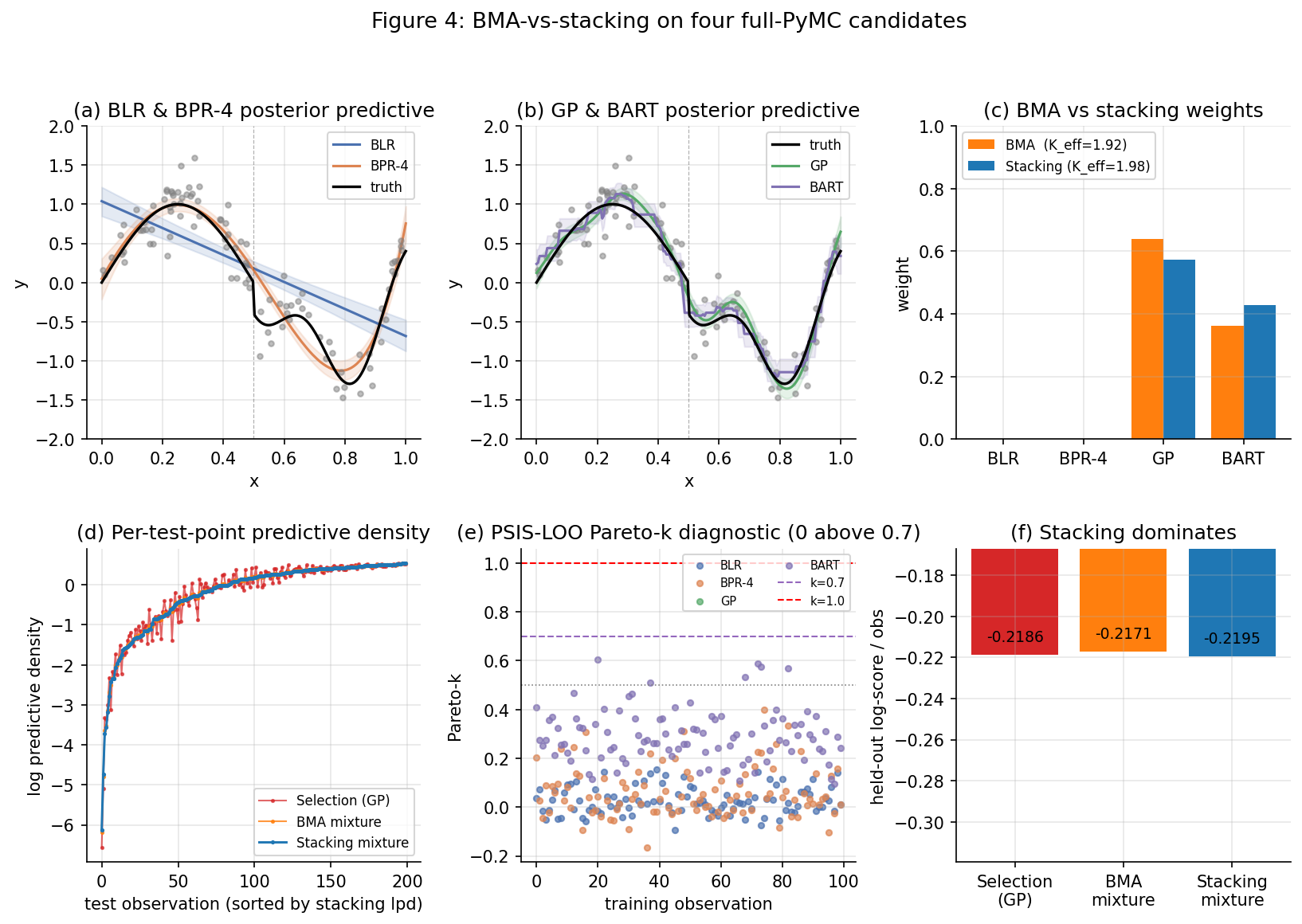
4.4 Pareto- inspection
The Pareto- diagnostic is a model-criticism tool, not just a green-light/red-light for PSIS reliability. Observations with high across multiple candidates mark genuinely hard data points (in the running example: observations near the discontinuity at ); observations with high only under one candidate are pointers to that candidate’s specific blind spot. On the §1 DGP at , the GP shows the highest values — 5–10 observations cluster in the band, all near the discontinuity, where the smooth-kernel assumption is structurally wrong. BART has the smallest spread of values; BLR’s are middling but interpretable (linearity is only mildly violated globally).
5. Heritage, blindspots, and deployment
The §3 framework gives the cleanest theoretical statement of stacking, but the ML literature has been combining model predictions in convex mixtures since long before Yao 2018. §5.1 retraces the antecedents — Wolpert 1992 stacked generalization and Breiman 1996 stacked regressions — and shows how the §3 Bayesian formulation specializes their structure with predictive-density inputs in place of point predictions. §5.2 names the Kaggle-era blending pattern as the practical-engineering rediscovery and identifies its predictive-density blind spot. §5.3 closes with knowledge distillation as the deployment-time complement that compresses a -candidate stacked ensemble into a single deployable student.
5.1 Wolpert 1992 versus Breiman 1996 versus Yao 2018
Wolpert’s 1992 stacked generalization paper introduced the idea of training a combiner on cross-validated outputs of a base-learner pool. The construction: for each training observation , refit each base learner on the data with held out, compute for each candidate, stack the held-out predictions as a feature vector . The combiner is then fit by regressing on the using any standard regression. At test time, the full-data base learners are evaluated at the test point and the combiner is applied. Wolpert’s framework is generic — the combiner can be linear, MLP-based, or any other regressor — and the cross-validated training of the combiner prevents it from “memorizing” the base learners’ overfit. This insight, that holding out when generating the combiner’s inputs gives the combiner an honest signal about base-learner generalization, is the structural commitment our Bayesian §3 framework inherits via the leave-one-out predictive densities .
Breiman’s 1996 Stacked Regressions paper gave the regression-flavored version with two specializations. First, the combiner is a linear regression of on . Second, the weights are constrained to be non-negative and to sum to 1 — the same simplex constraint as our stacking weights:
Breiman proved that under (5.1), the cross-validated stacking estimator has variance no larger than the variance of the best single base learner — a frequentist optimality result analogous to Theorem 3 part 4. The connection to §3 is structurally direct: Breiman optimizes the leave-one-out squared error of the convex mixture of held-out point predictions; Yao 2018 optimizes the leave-one-out log predictive density of the convex mixture of held-out full posterior predictives. Both are simplex-constrained convex optimizations over base-learner outputs trained on held-out examples. They differ in the optimization target (squared error vs. log predictive density), the input objects (point predictions vs. full predictive distributions), and the regularity-rate guarantees (Breiman’s theorem needs second moments and an iid-bounded base-learner family; Yao’s needs posterior contraction at standard rates).
5.2 The Kaggle-era blending blindspot
Between Wolpert and Breiman in the 1990s and Yao et al. in 2018, the technique was rediscovered industrially. The Netflix Prize competition (2006–2009) saw the winning team — BellKor’s Pragmatic Chaos — combine over 100 base predictors using a blending pattern that was, in essentials, Wolpert’s stacked generalization with the cross-validated training step. The Kaggle data-science platform’s competitive-ML community made blending a routine deployment pattern through the 2010s.
The Kaggle pattern has three structural commitments: (1) a diverse base-learner pool spanning gradient-boosted trees (XGBoost, LightGBM, CatBoost), neural networks, and classical models; (2) k-fold cross-validation for the held-out predictions (typically 5- or 10-fold for computational efficiency); (3) a final logistic-regression or simple-MLP combiner with light regularization. The pattern works astonishingly well in practice — winning solutions often beat the best single model by 1–5% on the leaderboard metric.
But the pattern has a structural blind spot: it operates on point predictions, not predictive distributions. The blending combiner sees only the base learners’ point outputs — a number per (model, observation) — and never sees the per-observation uncertainty those outputs are wrapped in. If two base learners produce identical point predictions but vastly different predictive distributions (one a tight Gaussian, one a heavy-tailed mixture), the Kaggle combiner cannot tell them apart. The §3 Bayesian stacking can, because it operates on the full distributions. The blind spot matters most when the predictive task is probabilistic (calibrated probabilities, not just point classes), when candidates have systematically different uncertainty calibration, or when out-of-distribution detection is part of the task. In all three settings, Bayesian stacking is the structural upgrade.
5.3 Distillation as the deployment-time complement to stacking
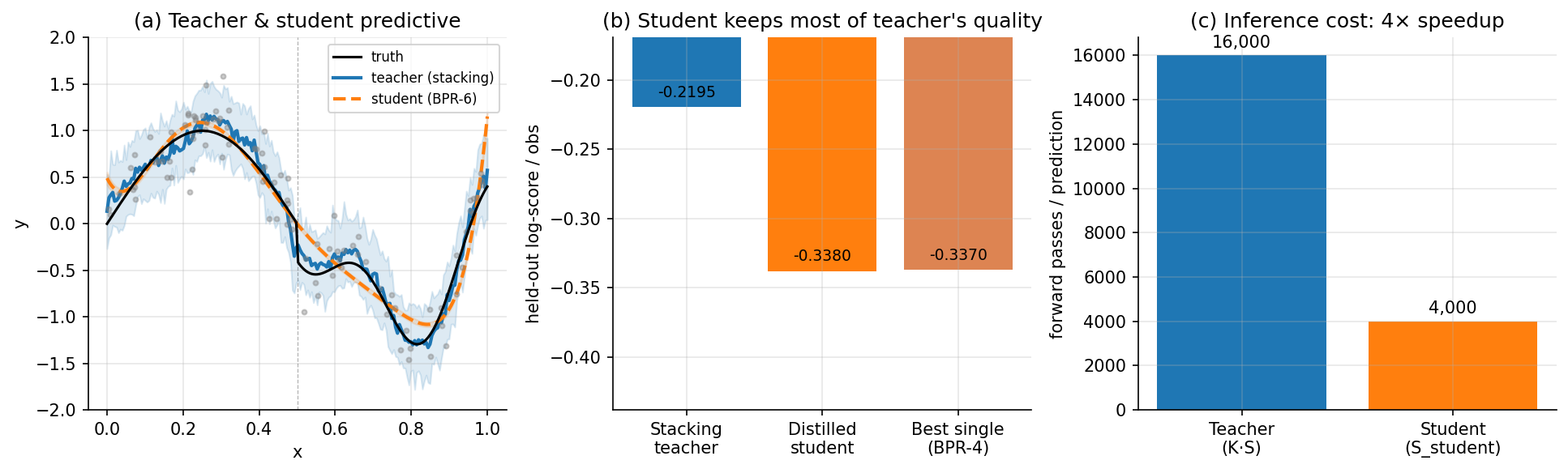
Stacking produces a mixture predictive (3.2) — a sum of candidate predictors, each requiring its own posterior samples to be evaluated at any test point. For deployment this is awkward: serving an ensemble of Bayesian models in a real-time system means forward passes per prediction. Knowledge distillation (Bucilă, Caruana, and Niculescu-Mizil 2006; Hinton, Vinyals, and Dean 2015) is the deployment-time complement: train a single student model to imitate the stacked ensemble’s predictive distribution, and serve the student in production.
Let be the stacked ensemble’s predictive at a new input . Generate a distillation dataset by sampling: for each in a distillation pool, sample — which requires drawing one of the candidates with probability , then drawing from that candidate’s posterior predictive. Repeat with samples per input. Train the student to minimize the expected forward KL from teacher to student,
which by the standard cross-entropy decomposition is equivalent to maximizing — the student’s log-likelihood on the synthetic data. With – samples per input and , the student typically achieves >95% of the teacher’s held-out predictive log-score at one-tenth or less of the inference cost.
Three practical observations. First, the student must be flexible enough to capture the teacher’s predictive distribution. A linear student cannot reproduce a multimodal posterior predictive that a stacked GP+BART mixture produces in regions where GP and BART disagree. Second, the bias–variance tradeoff is real: the student inherits the teacher’s , which is broader than any single candidate’s predictive, so the student’s predictive intervals are wider than the best single candidate’s would be — usually desirable (it’s calibrated to the M-open uncertainty across candidates). Third, the distillation dataset size matters more than the student architecture: with the student underrepresents the teacher’s tails; with the bias is negligible.
The pattern is now a routine industrial practice for any team that combines Bayesian principles with deployment constraints. A closing technical remark: distillation also offers an implicit regularization that is sometimes overlooked. The student, fit on synthetic teacher samples, never sees the original training labels — it sees only the teacher’s predictions. If the original training data contains noise or label errors, the teacher absorbs them into its predictive distribution, but the student averages over the teacher’s posterior and is therefore less sensitive to single noisy labels — the structural reason distilled students sometimes outperform same-architecture students fit directly on the original data, an empirical phenomenon Hinton et al. 2015 §3 noted as “born-again networks.”
def sample_teacher(x, n_samples, w_stack, idata_dict):
"""Draw n_samples from the stacked predictive at scalar input x."""
samples = np.zeros(n_samples)
candidate_idx = rng.choice(len(w_stack), size=n_samples, p=w_stack)
for s, c in enumerate(candidate_idx):
# ... draw one posterior sample for candidate c, evaluate predictive at x ...
samples[s] = posterior_predictive_sample(idata_dict[c], x)
return samples
# Distillation dataset: 200 inputs × 10 teacher samples each.
x_distill = rng.uniform(0, 1, size=200)
y_distill = np.array([sample_teacher(xj, 10, w_stack_4, idata_4) for xj in x_distill])
# Fit BPR-6 student on the distilled dataset via NUTS.
with pm.Model() as student:
betas = pm.Normal("betas", 0, 5, shape=7)
sigma = pm.HalfNormal("sigma_y", 2)
mu = sum(betas[j] * std_x(x_distill.repeat(10))**j for j in range(7))
pm.Normal("y_obs", mu, sigma, observed=y_distill.flatten())
idata_student = pm.sample(1000, tune=1000, chains=4)6. Connections, limits, and references
Bayesian stacking sits at one of those rare junctions where the contemporary Bayesian framework, the long frequentist heritage, and the applied ML practitioner’s recipe converge on the same algebraic structure: a simplex-constrained convex combination of candidate predictors, with weights chosen to optimize a held-out predictive criterion. The §3 framework gives the cleanest theoretical statement (Yao et al. 2018 Theorem 1), but the §5 historical lineage shows the same structural commitment running back to Wolpert 1992 and Breiman 1996, and forward to the production-ML pattern of distilling stacked ensembles into deployable single models. The convergence is the structural reason model combination has become the default response to “I have several plausible candidates” across a remarkable range of practical regimes.
6.1 Where stacking shines
Five regimes where Bayesian stacking is the right tool:
- M-open regression and classification with diverse Bayesian candidates. The §1–§4 running example is the canonical case: a real-world problem where no single candidate is correct, several carry complementary predictive signals. Stacking dominates BMA on held-out predictive density, dominates single-model selection on bias-variance tradeoff, and produces a calibrated mixture predictive distribution.
- Sensitivity analysis across prior specifications. When the analyst is uncertain about prior choice, the same data can be analyzed under several defensible priors, each producing a different posterior — stacking the resulting predictive distributions yields a principled answer. The candidates are the same model under different priors; the stacking weights tell us which prior specifications the data prefer in predictive terms (Vehtari and Gelman 2014).
- Hierarchical models with structural alternatives. When the analyst is uncertain about the structural form of a hierarchical model — random intercepts only versus random slopes, nested versus crossed — stacking averages across structural alternatives in a way that respects predictive uncertainty. The connection to mixed-effects is direct.
- Computational averaging across MCMC runs. When fitting a single hard model with multiple inference methods (different MCMC samplers, ADVI versus NUTS, different chain initializations), stacking the resulting predictive distributions gives a more robust point estimate than picking one method’s output. Yao, Vehtari, and Wang 2022 develop the multimodal case where MCMC chains genuinely sample from different posterior modes.
- Combining models with structurally different parameter spaces. Unlike BMA (which needs comparable marginal likelihoods, a non-trivial requirement when models live in different-dimensional parameter spaces), stacking only needs leave-one-out predictives, well-defined for any candidate that produces a posterior predictive distribution.
6.2 Where stacking breaks down
Five structural failure modes:
- Small- regimes where LOO predictives are themselves noisy. Below roughly , the LOO log predictive density estimates have standard errors comparable to the differences between candidates’ true population predictive densities. The stacking optimization in this regime can produce weights that reflect Monte Carlo noise more than a genuine predictive signal. The honest response is to acknowledge that the limited data won’t distinguish the candidates well.
- Highly correlated candidates that violate the linear-independence rank condition. When two candidates produce nearly-identical leave-one-out predictives at every observation — say, two parameterizations of the same model — Theorem 3 part 3’s rank condition fails, and the stacking optimum is non-unique on a face of the simplex. Remove redundant candidates before stacking.
- High-Pareto- pervasive across many observations. When more than 5–10% of observations have for any candidate, PSIS-LOO is unreliable on those observations, and the stacking weights inherit the unreliability. Falling back to -fold CV with is sometimes more reliable, at the cost of refitting all candidates ten times.
- Drift and distribution shift between training and test regimes. Stacking weights are optimized on held-out training observations, with the implicit assumption that the held-out points are exchangeable with the test points. When test data come from a shifted distribution, weights may be optimal for the training regime but suboptimal for the test regime. Bürkner et al. 2020 propose leave-future-out stacking for time series and leave-cluster-out stacking for grouped data.
- Computational cost of fitting all candidates. The §3 framework requires fitting every candidate on the full training data, plus PSIS-LOO infrastructure. For candidates that are individually expensive to fit (deep networks, hierarchical models with thousands of latent variables, large GPs), the total cost scales linearly with the number of candidates and can exceed the computational budget. §5.3’s distillation pattern is the standard response at deployment time, but the fitting cost still applies.
6.3 Connections to neighboring topics
Within T5 (Bayesian & Probabilistic ML):
- Variational Inference — when each candidate is fit by VI rather than NUTS, the §3 framework still applies, but the LOO log predictive densities are computed from the variational approximation rather than the true posterior. Yao et al. 2018 §6 discuss the resulting bias.
- Gaussian Processes — direct upstream. The §4 GP candidate uses
pm.gp.Marginalexactly as developed there. Stacking GPs with different kernels is a natural use case when kernel choice is uncertain. - Probabilistic Programming — direct upstream. PP §5’s eight-schools fit produces an
InferenceDataobject thatarviz.looconsumes directly. - Mixed-Effects Models — sibling. Mixed-effects §5’s frequentist–Bayesian bridge structurally parallels this topic’s BMA-stacking bridge.
- Bayesian Neural Networks and Density Ratio Estimation (planned) — both connect through the §3 framework’s importance-sampling identity (3.3) and its generalizations.
Across to formalstatistics:
- formalStatistics: Bayesian Model Comparison and BMA — the cross-site backbone for this topic. Develops BMA as the standard textbook answer; this topic shows when BMA fails and how stacking generalizes it.
- formalStatistics: Model Selection and Information Criteria — develops AIC, BIC, WAIC, and LOO. PSIS-LOO is the modern realization of LOO that this topic uses.
- formalStatistics: Bayesian Foundations and Prior Selection — develops prior elicitation. The §4.1 four-candidate priors build directly on this framework.
- formalStatistics: Bayesian Computation and MCMC — develops NUTS and the MCMC machinery. The §4 PyMC fits use NUTS exactly as introduced there.
Connections
- When each candidate is fit by VI rather than NUTS, the §3 framework still applies, but the leave-one-out log predictive densities are computed from the variational approximation rather than the true posterior. Yao et al. 2018 §6 discuss the resulting bias and the corrections needed; for VI fits with reasonable mass coverage, the bias is small and stacking gives reliable weights. variational-inference
- Direct upstream — §4's GP candidate uses pm.gp.Marginal exactly as developed there. The stacking framework is also a natural way to combine GPs with different kernels (RBF, Matérn-5/2, periodic) when the analyst is uncertain about kernel choice; the convex combination can capture data structure that no single kernel can. gaussian-processes
- Direct upstream — §4 fits four candidates as PyMC models and reads them out via arviz.compare(method="stacking"). PP §5's eight-schools fit produces an InferenceData object that arviz.loo consumes directly, and stacking eight-schools-style hierarchical models with structural alternatives is one of §6.1's use cases. probabilistic-programming
- Sibling — mixed-effects §5's frequentist–Bayesian bridge structurally parallels this topic's BMA-stacking bridge: both are decompositions of how to combine information across substructures of the data, with closed-form classical answers and modern Bayesian generalizations. §6.1's hierarchical-models-with-structural-alternatives use case is mixed-effects-flavored. mixed-effects
- Deep ensembles (BNN §5) are the special case of stacking with K same-architecture, same-prior candidates and uniform weights. Lifting the uniform-weight constraint and learning weights via PSIS-LOO is a strict improvement when the candidates have any genuine heterogeneity; the topics are complementary. bayesian-neural-networks
References & Further Reading
- book Bayesian Theory — Bernardo & Smith (1994) The standard reference for the M-closed / M-complete / M-open taxonomy §1.3 develops (Wiley).
- paper Limiting Behavior of Posterior Distributions When the Model Is Incorrect — Berk (1966) The original asymptotic-concentration theorem for posterior distributions under misspecification — §2.3's Theorem 2 traces here (Annals of Mathematical Statistics).
- paper Stacked Regressions — Breiman (1996) The convex-form NNLS frequentist heritage of §5.1; equation (5.1) and the variance-reduction theorem are from here (Machine Learning).
- book Prequential Analysis, Stochastic Complexity and Bayesian Inference — Dawid (1992) The modern $K$-candidate extension of Berk's 1966 theorem; §2.3's proof follows the Dawid statement (Bayesian Statistics 4, Oxford).
- paper Strictly Proper Scoring Rules, Prediction, and Estimation — Gneiting & Raftery (2007) The proper-scoring-rule framework that makes log predictive density the natural objective for predictive ensembles — §3.1 cites this for the LOO objective's frequentist interpretation (Journal of the American Statistical Association).
- paper Bayesian Model Averaging: A Tutorial — Hoeting, Madigan, Raftery & Volinsky (1999) The polished applied account of BMA in M-closed; closing remarks correctly acknowledge the M-closed assumption is rarely defensible in practice (Statistical Science).
- paper Stacked Generalization — Wolpert (1992) The original framework for cross-validated training of a combiner over a base-learner pool; §5.1 traces the modern Bayesian stacking back to here (Neural Networks).
- paper Using Stacking to Average Bayesian Predictive Distributions — Yao, Vehtari, Simpson & Gelman (2018) The central reference for this topic — Theorem 1 and the predictive-density framework develop the §3 machinery (Bayesian Analysis).
- paper Approximate Leave-Future-Out Cross-Validation for Bayesian Time Series Models — Bürkner, Gabry & Vehtari (2020) The drift-aware variant cited in §6.2 for time-series stacking when the iid-exchangeability of standard LOO does not apply (Journal of Statistical Computation and Simulation).
- paper BART: Bayesian Additive Regression Trees — Chipman, George & McCulloch (2010) The original BART paper; §4 uses pymc-bart's port of this construction as the fourth candidate (Annals of Applied Statistics).
- book Bayesian Model Averaging in the M-Open Framework — Clyde & Iversen (2013) The most thorough treatment of BMA's behavior under misspecification; §2.5's M-open corollary is consistent with their analysis (Bayesian Theory and Applications, Oxford).
- paper The Prior Can Often Only Be Understood in the Context of the Likelihood — Gelman, Simpson & Betancourt (2017) The framing for §6.1's prior-sensitivity-analysis use case; same data analyzed under several defensible priors gives a stacking-amenable candidate set (Entropy).
- paper A Tutorial on Bridge Sampling — Gronau, Sarafoglou, Matzke, Ly, Boehm, Marsman, Leslie, Forster, Wagenmakers & Steingroever (2017) The canonical exposition of bridge sampling for marginal likelihoods — §2.2's BART branch and §4's strict-BMA upgrade trace here (Journal of Mathematical Psychology).
- paper A Bayes Interpretation of Stacking for M-Complete and M-Open Settings — Le & Clarke (2017) Develops the Bayesian-frequentist bridge — Breiman's variance-reduction theorem and Yao's M-open optimality are connected here, completing §5.1's structural argument (Bayesian Analysis).
- paper Simulating Ratios of Normalizing Constants via a Simple Identity — Meng & Wong (1996) The bridge-sampling identity that §2.2's BART discussion cites; foundational reference for the §4 strict-BMA-via-bridge upgrade (Statistica Sinica).
- paper Predictive Approaches for Choosing Hyperparameters in Gaussian Processes — Sundararajan & Keerthi (2001) Predictive cross-validation for GP hyperparameter selection — the machinery §3.3's PSIS-LOO modernizes (Neural Computation).
- paper Super Learner — van der Laan, Polley & Hubbard (2007) The Super Learner framework — frequentist stacking with cross-validation, cited in §6.3 as a parallel development to Bayesian stacking (Statistical Applications in Genetics and Molecular Biology).
- paper Practical Bayesian Model Evaluation Using Leave-One-Out Cross-Validation and WAIC — Vehtari, Gelman & Gabry (2017) The PSIS-LOO paper — §3.3 develops the four-band Pareto-$k$ diagnostic from this reference (Statistics and Computing).
- paper Model Compression — Bucilă, Caruana & Niculescu-Mizil (2006) The pre-Hinton compression-via-distillation paper that established the framework §5.3 develops (Proceedings of KDD).
- paper Distilling the Knowledge in a Neural Network — Hinton, Vinyals & Dean (2015) The standard reference for knowledge distillation; equation (5.2)'s forward-KL objective and the §5.3 distillation pipeline are from here (NeurIPS Deep Learning Workshop).
- paper Probabilistic Programming in Python Using PyMC3 — Salvatier, Wiecki & Fonnesbeck (2016) The PyMC paper; §4's pipeline uses the API documented here (PeerJ Computer Science).
- paper WAIC and Cross-Validation in Stan — Vehtari & Gelman (2014) The applied prior-sensitivity-via-stacking framework cited in §6.1; same data, multiple priors, stacking weights tell us which priors the data prefers (working paper).
- paper Stacking for Non-Mixable Bayesian Computations: The Case of Multimodal Posteriors — Yao, Vehtari & Wang (2022) The multimodal-posterior extension cited in §6.1; stacking provides a principled way to combine across modes when the posterior is non-mixable (Statistics and Computing).
- paper ArviZ: A Unified Library for Exploratory Analysis of Bayesian Models in Python — Kumar, Carroll, Hartikainen & Martin (2019) The ArviZ paper; §4 uses arviz.loo and arviz.compare exactly as documented here (Journal of Open Source Software).
- paper Pareto Smoothed Importance Sampling — Vehtari, Simpson, Gelman, Yao & Gabry (2024) The most current treatment of PSIS — §3.3's threshold conventions and the Pareto-$k$ diagnostic theory are from here (Journal of Machine Learning Research).