VC Dimension
Combinatorial capacity, Sauer–Shelah, and uniform convergence for binary hypothesis classes
Motivation: why finite-class arguments break for infinite hypothesis classes
The PAC Learning topic developed the sharpest tool we have for finite hypothesis classes: take Hoeffding’s inequality on a single hypothesis, apply the union bound over all of them, and a sample size of suffices for uniform convergence at level with confidence . The bound is tight in , transparent in its derivation, and useless the moment we try to use it on anything we’d want to learn — every real-parameter class has , and shuts the argument down. The question for this whole topic: what’s the right combinatorial object to put in place of when the cardinality counts the wrong thing?
The finite-class union-bound recap
Fix the standard setup. We have a labeled sample drawn i.i.d. from a distribution on , a binary hypothesis class , the population risk , and the empirical risk . Hoeffding’s inequality applied to the Bernoulli indicators gives . The PAC framework wants this uniformly over the whole class, so we union-bound across :
Setting the right-hand side to and solving for gives the canonical finite-class sample-complexity bound
the headline result of PAC Learning §3. The logarithm is the union bound’s signature: every extra hypothesis costs us in the sample size. The bound stays usable for surprisingly large finite classes — billions of hypotheses cost twenty-something samples — but it requires .
What |H| should “really” mean
Take the simplest infinite class: half-lines on the real line, with . There are uncountably many hypotheses and bound (1.1) instantly degenerates: forces . Yet half-lines are intuitively a small class — one real degree of freedom, a handful of points should suffice. The bound is counting something it shouldn’t be counting.
The issue is that the union bound treats every as a fresh draw from concentration’s perspective, but on any fixed sample most of those thresholds are behaviorally indistinguishable. Two thresholds in the same gap between consecutive sample points produce the same labels on . The hypotheses are different as functions on , but identical as labelings of . If has uncountably many functions but only distinct labelings of any -point sample, the right effective cardinality for the union bound is , not .
The right object: labelings on a fixed sample, not functions on the input space
For a sample and a class , the restriction of to is
Three immediate consequences: ; ; and the latter inequality can be enormously loose. The hope is to replace in the union bound with some worst-case-over- version of — the growth function in §3. If is polynomial in even when is infinite, the union bound buys a finite sample complexity.
Roadmap: shattering, growth, Sauer–Shelah, uniform convergence
The four-step ladder this topic climbs: (1) shattering in §2 — given of size , shatters when ; (2) the growth function in §3 — ; (3) the VC dimension in §4 — , the largest for which ; (4) the Sauer–Shelah lemma and the FTSL in §§5–6 — finite VC dimension forces polynomial growth, which combined with Hoeffding via a doubled-sample union bound gives the agnostic uniform-convergence bound . The shape of the ladder is the entire story in one substitution: becomes .
Demo — log cardinality blows up; restricted cardinality plateaus
Take an -point sample on and discretized half-line classes with thresholds. As , (red, diverging on the log-log plot) and the finite-class bound (1.1) degenerates. But saturates at exactly (blue plateau) as soon as is large enough to put a threshold in every gap. The red curve is the wrong quantity for learning theory; the blue curve is the right one.
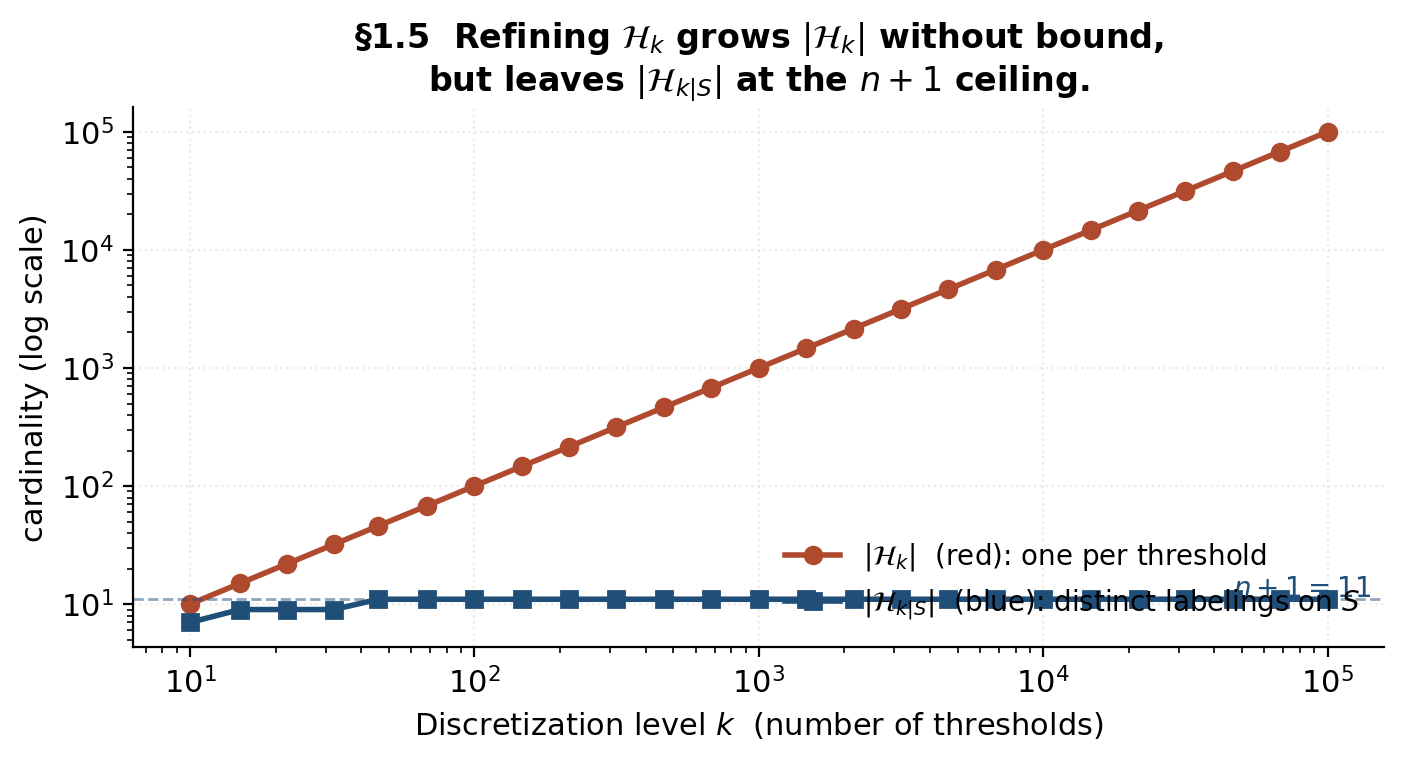
Adding more thresholds inflates |H_k| (red) without adding any new dichotomies once every gap is covered — the restricted cardinality |H_k|_S| (blue) saturates at n + 1.
The takeaway is exactly the diagnosis from §1.2: refining adds hypotheses, but doesn’t add information that distinguishes them on . The behaviorally-distinct hypotheses on — the dichotomies of §2 — are what matters.
Shattering: the combinatorial substitute for |H|
Restriction to S: dichotomies
The set of labelings produced by on is also called the set of dichotomies (Vapnik–Chervonenkis 1971). Three properties: so ; ; the second bound can be loose by an unbounded factor.
Definition: H shatters S
Definition 1 (Shattering).
A class shatters a sample when — every is realized by some .
Two pieces of commentary: shattering is a property of the pair , not of or alone; and the definition is existential in — for each target labeling, we need some witnessing hypothesis.
The three-point picture: half-lines vs half-planes
Three configurations across two classes paint the picture:
- A. Half-lines on three collinear 1D points : only the 4 threshold patterns are realized. The labelings are unrealizable. Half-lines do not shatter.
- B. Half-planes on three collinear 2D points : same 4 patterns; half-planes on collinear points behave like half-lines on the projection.
- C. Half-planes on three triangle vertices : all 8 labelings realized — separation via a half-plane through edges or vertices. Half-planes shatter triangles.
- D. Half-planes on any 4 points in the plane: previewed here; the full proof goes through §8.1 via Radon’s theorem.
Shattering depends on the configuration, not just the cardinality
Cases A–C carry the §2 punchline: shattering is not a function of alone. To prove , we’ll need two pieces: a constructive direction (exhibit some -point set that shatters — existence, usually easy) and a destructive direction (prove that every -point set has some unrealizable labeling — universal, usually hard).
Demo — the shatter atlas
A 3 × 8 grid: rows for the three (config, class) cases, columns for the 8 elements of , marked with realizing classifier when one exists. Rows A and B each tally 4 of 8; row C tallies 8 of 8 — shatters.
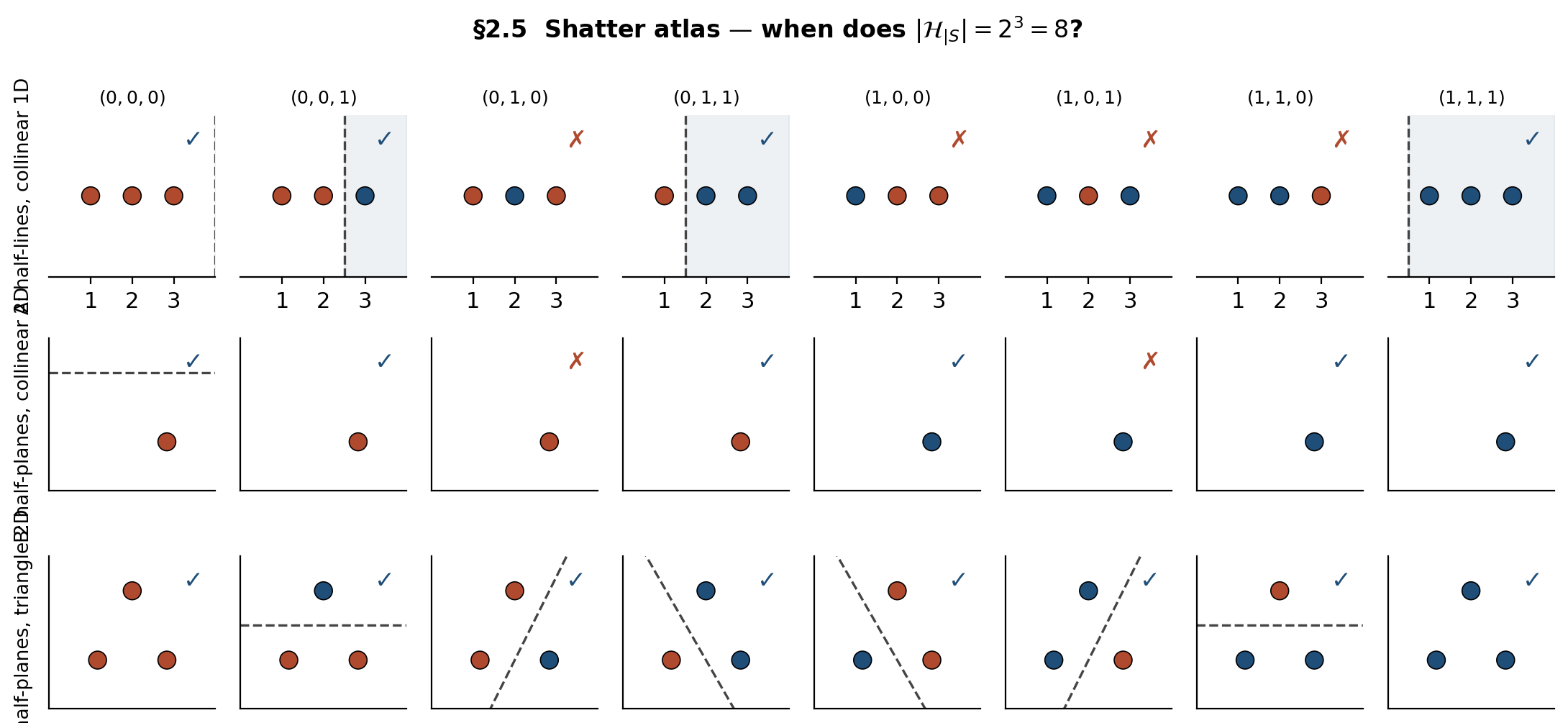
Top row: half-lines on three collinear 1D points realize 4 of 8 labelings (the monotone prefix patterns). Middle row: half-planes on three collinear 2D points realize the same 4. Bottom row: half-planes on a triangle realize all 8 — shatters.
The atlas makes the §2.4 asymmetry concrete. Rows A and B each top out at 4 of the 8 labelings; row C realizes all 8. Drag a point in row B onto the line and the row jumps from 4 to 8 — shattering switched on by a one-pixel move. The class alone doesn’t determine shattering; the configuration matters every bit as much.
The growth function Π(n)
Definition: maximum number of labelings on an n-point sample
Definition 2 (Growth function).
The growth function of is
A function of alone; monotone non-decreasing in (extending a sample at most preserves the labeling count).
The trivial bound, and the shattering equivalence
Proposition 1 (Trivial bound and shattering).
, with equality iff some -point sample is shattered.
The Proposition converts shattering into an algebraic question and sets up VC dimension as “the largest for which the bound is tight.”
Closed-form growth functions for the canonical classes
Four canonical classes have closed-form growth functions:
- Half-lines on : . The threshold falls in one of gaps between consecutive sample points.
- Intervals on : . Each non-empty interval picks a contiguous run of labels.
- Half-planes in : (Cover 1965), derived from the recursion on the number of regions cut by lines in general position, summed with the two trivial all-0 and all-1 dichotomies.
- Axis-rectangles in : no closed form, but via the bounding-box argument — every rectangle dichotomy is determined by its four extreme points along the two axes.
The phase transition: exponential below the VC dimension, polynomial above
Each canonical class tracks until , then peels off to polynomial. Half-lines peel at , intervals at , half-planes at , rectangles at . The polynomial degree is exactly . The phase transition is what Sauer–Shelah (§5) upgrades to a theorem.
Demo — the growth-function gallery
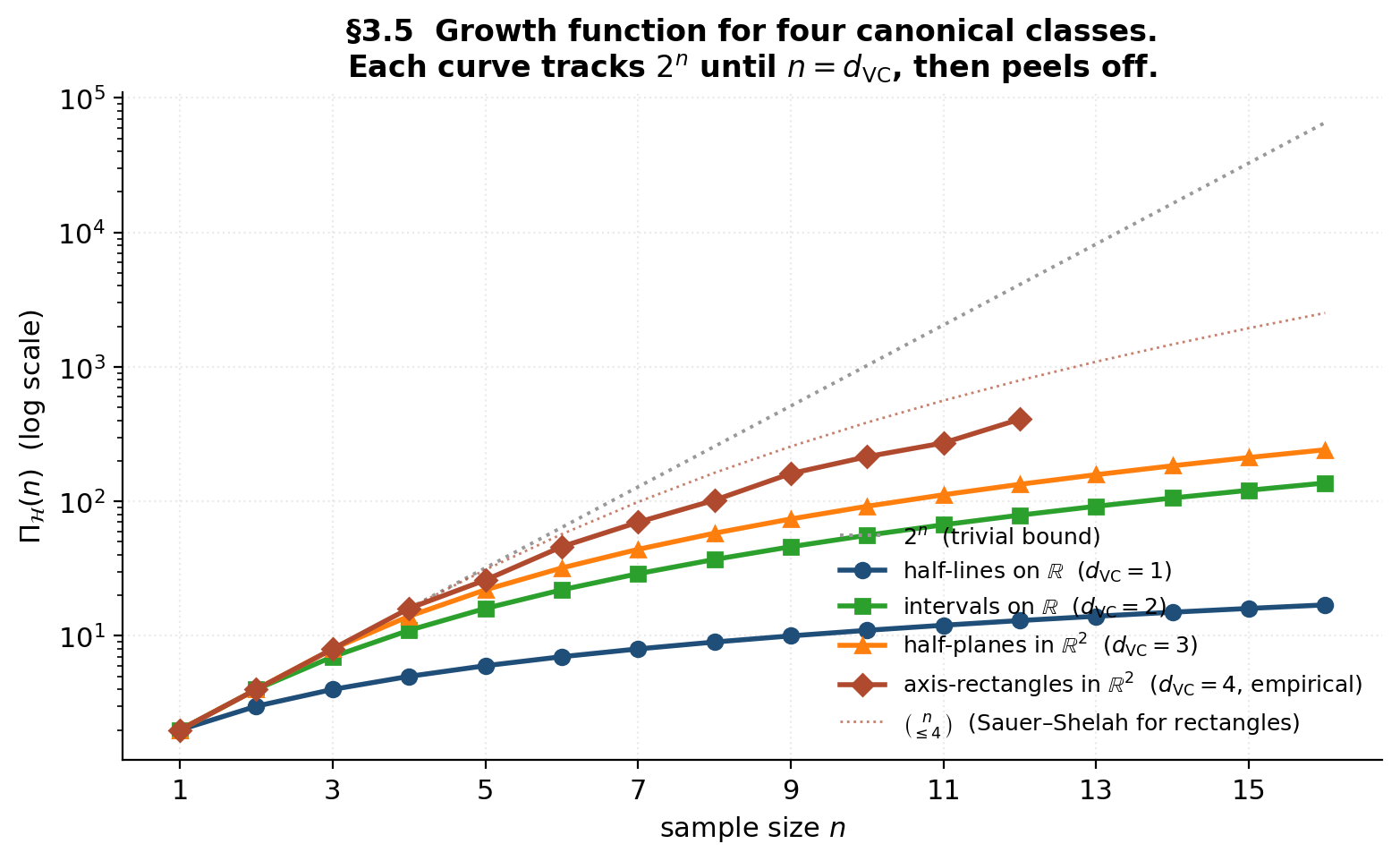
The picture matches the §3.4 prediction exactly: each curve tracks on the log scale until , then peels off to polynomial. The Sauer–Shelah binomial-sum bounds (dotted) sit above each class’s true growth function — loose by a constant factor, but the right asymptotic order.
The VC dimension
Definition: largest shattered set
Definition 3 (VC dimension).
The VC dimension of is
or if the maximum does not exist. Conventions: and .
Integer-valued (or ); reduces to no other dimension notion for binary classes.
The two-sided proof template
To prove , we need two ingredients: (1) constructively exhibit some -point set that shatters, and (2) destructively prove that every -point set has some unrealizable labeling. The destructive direction is universal — quantified over all -point samples — and is where Radon’s theorem (§8.1) and pigeonhole arguments (§8.2) earn their keep.
Worked examples: half-lines, intervals, half-planes
- . Constructive: a single point shatters (one labeling each way). Destructive: any two points have the unrealizable labeling — no threshold realizes “1 then 0.”
- . Constructive: any two points shatter via four intervals. Destructive: any three points have the unrealizable labeling — an interval is a contiguous set, so it cannot label the endpoints “in” and the middle “out.”
- . Constructive: a triangle shatters (§2.5 row C). Destructive: every 4-point configuration has an unrealizable labeling, following from Radon’s theorem in §8.1.
Pathological cases: H_sin has 1 parameter but infinite VC dimension
The sine-wave family has one real parameter but . The construction (Vapnik 1998 §3.4) uses geometrically-spaced points ; for any labeling , the choice realizes . Parameter count is not a reliable proxy for VC dimension.
Demo — destructive direction for each canonical class
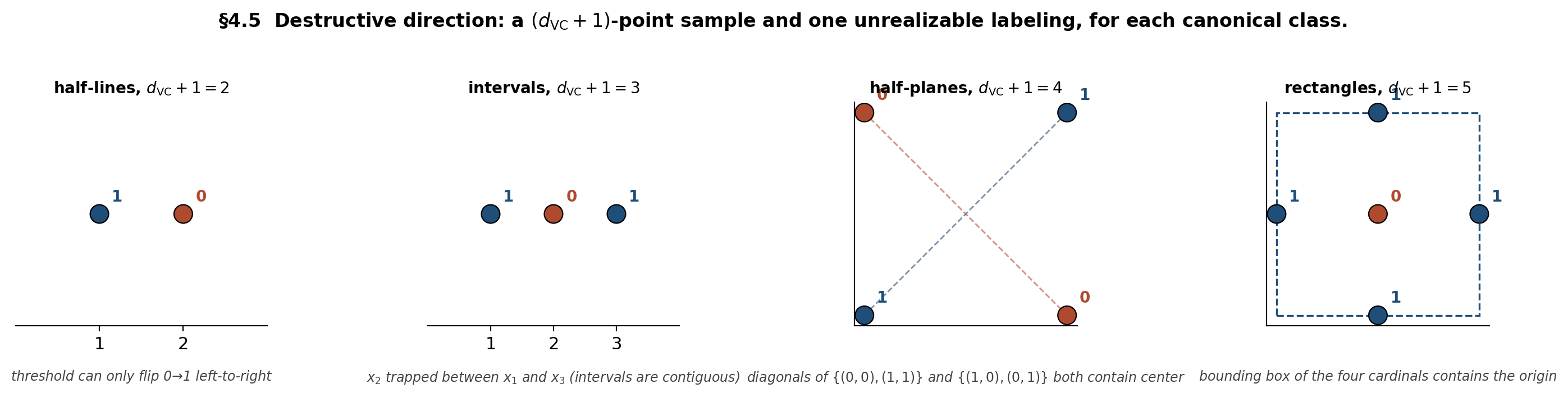
Blue circles labeled 1; red circles labeled 0. Each panel shows the smallest unrealizable labeling for its class — the geometric obstruction that caps the VC dimension at d_VC.
The four obstructions are exemplars of the four most common destructive-direction arguments in VC theory: monotonicity (no realization of decreasing patterns), connectivity (no disconnected positive set), convex-hull (no separation across the hull’s interior), and bounding-box (no positive set excluding an interior point).
The Sauer–Shelah lemma
The numerical phase transition in §3.4 told us that finite VC dimension appears to force polynomial growth of . The Sauer–Shelah lemma is that observation upgraded to a theorem. Two independent discoveries — Sauer (1972) and Shelah (1972), with antecedents in Vapnik–Chervonenkis (1971) — established the bound; the modern proof we give here is due to Frankl–Pach (1983) and Pajor (1985), using a clever operation on called the shifting operator.
Statement: finite VC dimension forces polynomial growth
Theorem 1 (Sauer–Shelah).
Let have . Then for every ,
Consequently for .
The binomial-sum form (5.1) is tight in general; the closed form (Corollary 1) is the convenient version for downstream applications. Loose by a constant factor for any specific class — half-planes have vs the Sauer–Shelah ceiling — but universal across all classes with .
The shifting operator
Identify with its restriction on a fixed sample of size .
Definition 4 (Shifting operator).
For , the shifting operator is constructed as follows. For each with , let denote the down-shifted vector obtained by flipping to . Replace with in if ; otherwise leave both and in place.
Lemma 1 (Size preservation).
.
Proof.
The map on “lonely” labels (those whose down-shift is not in ) is a bijection between vectors leaving and vectors entering .
∎Lemma 2 (VC dimension preservation).
If shatters a set , then shatters .
Proof.
Suppose shatters . For each , we must produce a vector with . By shattering, there is some with . Two cases.
Case A: . Take . Done.
Case B: . Then is a down-shifted vector — its -th coordinate is , and there exists with and for .
-
Sub-case B1: . Take ; since the disagreement is at coordinate , we have .
-
Sub-case B2: and . We need with and . Apply the shattering of by to the flipped labeling defined by and for . The witness is with , so . Now cannot have been produced by a down-shift — a down-shift would set the -th coordinate to , not — so directly. Consider the down-shift of : it has and . We claim . Suppose not: then would be “lonely” in (its down-shift would be missing), so the shifting operator would replace with in — putting and removing from . But by hypothesis, a contradiction. Therefore and realizes on .
-
Sub-case B2 with would require , and from Case B works directly.
The Sub-case B2 contradiction is the only delicate moment in the entire proof: we need to live in , and the only way to extract that fact is to suppose otherwise and watch the shifting operator’s definition force a contradiction with .
Full proof of Sauer–Shelah
Proof.
Five steps.
Step 1. Apply the shifting operators iteratively, cycling until no further changes occur. The total weight decreases by at least whenever a shift moves a lonely vector down, and is bounded below by , so the process terminates in finitely many cycles. Call the resulting class (the “stable class”). By construction, for every .
Step 2. Lemma 1 applied iteratively: . Lemma 2 applied iteratively: (if shattered some set, so would ).
Step 3 — the stable class is down-closed. Suppose has . By stability , so the down-shift must be in — otherwise would replace with , contradicting stability. Iterating one coordinate at a time, every (coordinatewise) lies in .
Step 4 — count by support sizes. For any , every subset has indicator by down-closedness. So the restriction contains all labelings — shatters . By Step 2, this forces .
Step 5. The number of with is exactly . So . Taking the maximum over gives .
∎The shifting trick does two pieces of work simultaneously: Lemma 1 conserves the count we want to bound, and Lemma 2 conserves the VC dimension. The stable class is structurally much simpler — a down-closed family of subsets — and easy to count by support size.
The (en/d)^d closed form
Corollary 1 (The (en/d)^d bound).
For ,
Proof.
Multiply by and weaken the leading factor to :
The standard inequality at gives . Combining: .
∎The slack between and is by Stirling — exponential in but constant in . The closed form gives the right asymptotic order in and the right exponent in .
Demo — the three bounds compared
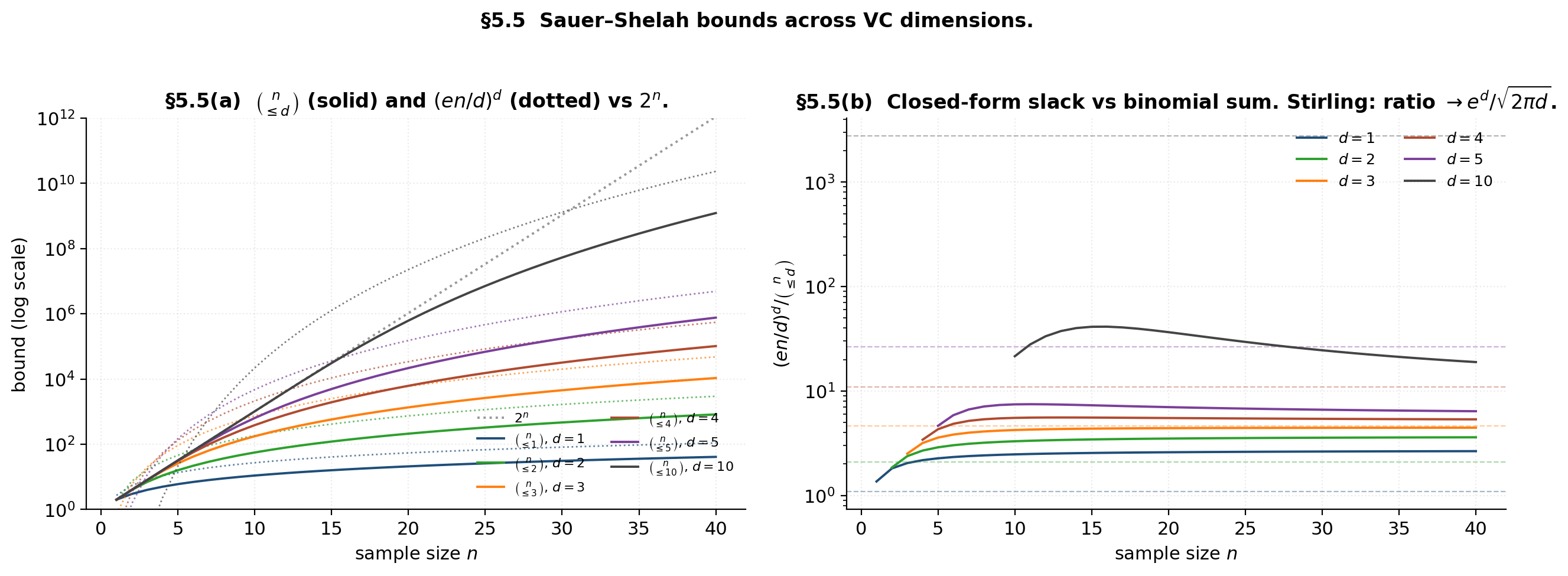
The left panel shows the bounds themselves on log scale: each sits below for every , and the closed form sits above it. The right panel verifies the Stirling-derived gap: the ratio of closed form to binomial sum settles onto , the multiplicative slack we accept in exchange for a clean polynomial.
The Fundamental Theorem of Statistical Learning
Hoeffding for one + symmetrization + union bound over labelings + Sauer–Shelah substitution → the agnostic uniform-convergence bound. The result is one direction of the equivalence theorem that Blumer–Ehrenfeucht–Haussler–Warmuth (1989) named the Fundamental Theorem of Statistical Learning.
Setup: agnostic PAC, ERM, and the worst-case gap
For , hypothesis class , and 0-1 loss: , . The empirical risk minimizer is . The worst-case generalization gap is
A high-probability bound on gives ERM’s agnostic guarantee where is the population-best hypothesis.
Symmetrization: from population risk to a doubled empirical risk
Lemma 3 (Symmetrization (Vapnik–Chervonenkis 1971)).
For and ,
Proof.
Fix with . Chebyshev’s inequality applied to the empirical risk on the ghost sample gives
for . So with probability over , the ghost-sample risk is within of . Combined with , the triangle inequality yields . The factor 2 on the right absorbs the “with probability ” step. The full derivation is in Vapnik (1998) Theorem 4.1.
∎The payoff: the right side of (6.1) is a statement about empirical averages on of size , where only the distinct labelings matter — finitely many, by Sauer–Shelah.
The agnostic uniform-convergence bound
Theorem 2 (FTSL upper bound).
Let . For and , with probability at least over ,
Proof.
From symmetrization (6.1),
The supremum on the right involves at most distinct random variables — one for each labeling of . Union-bound over labelings, then apply Hoeffding to the difference of two -sample averages of -bounded variables:
Combining:
Apply Corollary 1: . Setting the right side to and solving for gives .
∎The rate is — from Hoeffding, from Sauer–Shelah, from polynomial growth. The constants (the 8 and the 4) are loose by factors of 2–4 in modern refinements (Massart, McDiarmid, Talagrand). Inverting for sample complexity with a self-bounding argument gives — the agnostic-PAC bound that matches (1.1) with replacing .
The lower-bound direction and the FTSL equivalence
Theorem 3 (No-free-lunch).
If , then for every learning algorithm and every , there exists a distribution such that .
Proof.
Pick any -point set shattered by (exists because ). Let be uniform on with an adversarially-chosen labeling drawn after commits to its strategy. By shattering, some realizes the labeling exactly, so . Algorithm sees of the points; on the unseen half, has no information about the labeling and must guess, incurring error at least on the unseen half — equivalently, at least overall. Full derivation in Shalev-Shwartz–Ben-David Theorem 5.1.
∎Infinite VC is fatal for distribution-free learning. The sine-wave family from §4.4 is a concrete instance — one real parameter is enough to defeat any learning algorithm in the agnostic setting.
Theorem 4 (FTSL equivalence (Blumer–Ehrenfeucht–Haussler–Warmuth 1989)).
For a binary class , the following are equivalent: (1) has finite VC dimension; (2) has the uniform convergence property; (3) is agnostically PAC-learnable; (4) ERM is a successful agnostic PAC learner for ; (5) is PAC-learnable in the realizable case.
The proof chain is (1) ⇒ (2) ⇒ (3) ⇒ (4) via Theorem 2 and standard ERM analysis; (3) ⇒ (5) a fortiori; and (5) ⇒ (1) by the contrapositive of Theorem 3. The full development is in Shalev-Shwartz–Ben-David §6.4. The equivalence is what gives this theorem its “fundamental” name: every interesting learnability property reduces to the single integer .
Demo — the FTSL bound versus the empirical generalization gap
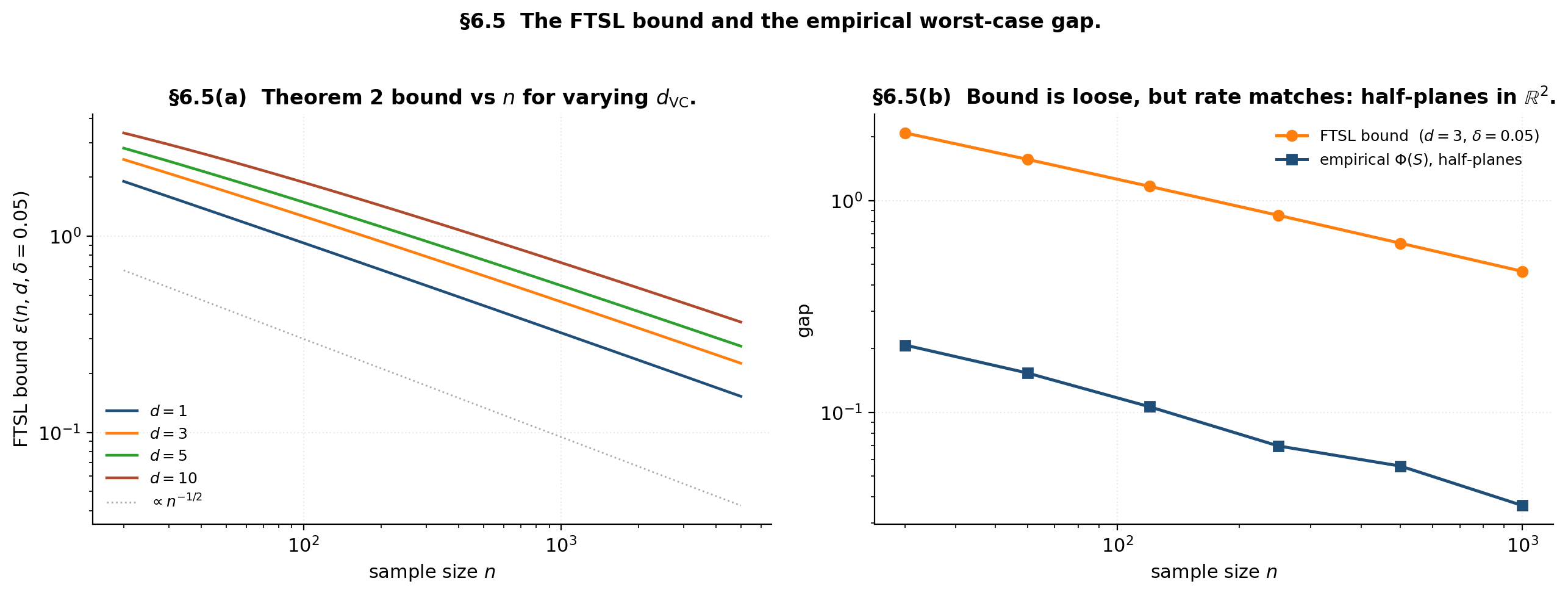
At n = 120, d = 3, δ = 0.05: FTSL bound ε = 1.170. The bound has slope −1/2 in n on log-log, just like the empirical gap (right panel).
The bound has the right asymptotic shape — both the empirical worst-case gap and the FTSL bound scale as — but is loose by roughly a factor of 10. The Hoeffding constant is the largest source of slack; the polynomial-growth substitution is comparatively tight. Modern refinements via Talagrand and McDiarmid close the constant gap by another factor of 2–4 but the order-of-magnitude looseness persists.
Realizable versus agnostic rates
The FTSL sample complexity is — quadratic in . The realizable PAC case has linear dependence: . The factor- gap is the headline practical consequence of the realizability assumption.
Realizable PAC: the 1/ε rate
Theorem 5 (Realizable PAC bound).
Under realizability (), with probability at least , any ERM satisfies provided
Proof.
Define the bad subclass — every hypothesis ERM might erroneously pick. The union bound on consistency gives
using . Set this and solve for to get (7.1). The exponential decay is in , not — that’s where the linear versus quadratic split comes from.
∎The crucial step is — the probability that a Bernoulli() random variable is zero times in a row. This is not Hoeffding; the “rare-event” bound has tails, not .
Agnostic PAC: the 1/ε² rate
Theorem 2’s bound inverts to . The practical contrast at , , is dramatic: realizable needs , agnostic needs — two orders of magnitude.
Bernstein versus Hoeffding: where the gap comes from
Hoeffding’s bound is variance-blind: regardless of . Bernstein’s bound is variance-aware:
When — which is what realizability says about the variance of the error — the denominator vanishes and the bound tightens. The realizable analysis effectively uses Bernstein in disguise: at , the exponent is , matching the rate. Hoeffding ignores the variance information and pays the price.
When realizable rates degrade to agnostic
Realizability is fragile. Three concrete failure modes:
- Label noise. Even flip probability — one in a hundred labels corrupted — destroys the realizable assumption. Every has , so the rare-event bound does not apply for . Natarajan et al (2013) develop the noisy-label theory in detail.
- Misspecification. If — the class doesn’t contain a perfect classifier — Theorem 5 doesn’t apply and the agnostic FTSL bound (6.2) takes over.
- Intermediate regime: Tsybakov margin. Between realizable () and agnostic (), the Tsybakov margin condition (Mammen–Tsybakov 1999) interpolates with parameters : for . The resulting rate is for — linear at (full margin), quadratic at (no margin). Full development in Generalization Bounds §9.
Demo — sample complexity versus accuracy, two regimes
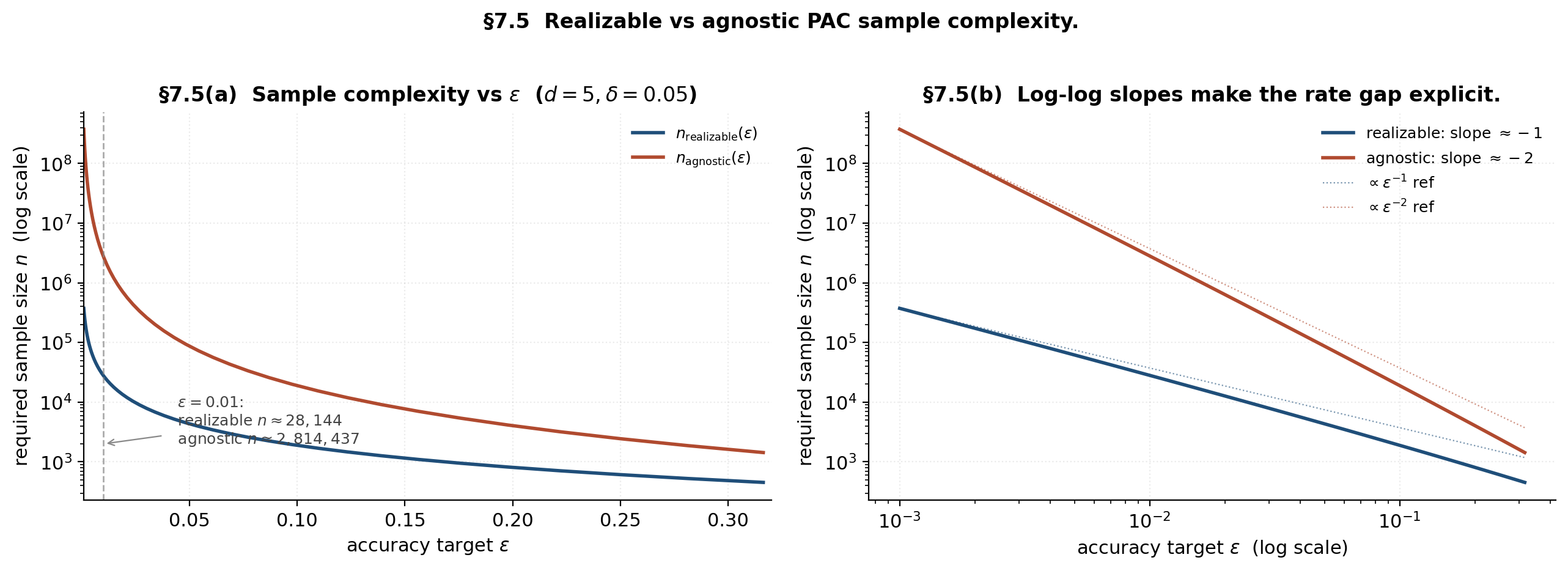
The left panel makes the dramatic practical gap visible: at , the realizable bound asks for around 5,000 samples; the agnostic bound asks for around 500,000. The right panel decomposes the gap into its asymptotic shape — slope versus slope on log-log. The variance-aware Bernstein-style analysis that the realizable case implicitly uses is what buys the extra factor.
VC dimension of canonical classes
Four canonical classes with full VC-dimension proofs — half-spaces in via Radon’s theorem, axis-aligned rectangles in via pigeonhole, decision stumps and Boolean classes (the easy cases), and neural networks via the Bartlett bound.
Half-spaces in R^d via Radon’s theorem
Theorem 6 (VC dimension of half-spaces).
.
The destructive direction depends on the following geometric fact.
Theorem 7 (Radon's theorem (1921)).
Any points in admit a partition such that .
Proof.
Consider the linear system in :
This is scalar equations in unknowns, so a nontrivial solution exists. Let and ; both are non-empty because . Let . The point
is a convex combination from both sides: the coefficients for are non-negative and sum to , and the coefficients for are likewise non-negative and sum to . So .
∎Proof.
Proof of Theorem 6, destructive direction. For any points, Radon’s theorem gives a partition with shared point . Consider the labeling that assigns to and to . Any separating half-space would contain all of (and hence by convexity of ) and exclude all of (so ). But then — contradiction. So this labeling is unrealizable, and .
∎Proof.
Proof of Theorem 6, constructive direction. Take any affinely-independent points, e.g., the origin together with the standard basis vectors . For any labeling , let and be the centroids of the - and -labeled vertices respectively. The half-space whose normal is and which passes through the midpoint contains the -labeled vertices and excludes the -labeled vertices, by affine independence. Full details in Mohri–Rostamizadeh–Talwalkar Theorem 3.20.
∎Axis-aligned rectangles in R^d
Theorem 8 (VC dimension of axis-aligned rectangles).
.
Proof.
Constructive direction. Take the unit-axis-direction points . For any labeling , build the rectangle one axis at a time: the -th range is if both and are labeled , if only is labeled , if only , and if neither (which excludes both). Four cases per axis, each producing the required labels on that axis’s two extreme points.
∎Proof.
Destructive direction. Among any points in , by pigeonhole at least one point is not extreme on any axis — every axis has at most two extreme positions (the maximum and minimum coordinate), giving only extreme positions total. Now consider the labeling “1 everywhere except .” Any rectangle that includes the other points must include their bounding box; but the bounding box contains (because is not extreme on any axis), so the rectangle includes as well — contradicting the requested labeling. This labeling is unrealizable, so .
∎Decision stumps and small Boolean concept classes
Decision stumps in are hypotheses of the form (or its complement) for some axis and threshold . The growth function is — polynomial in of degree . The exact VC dimension is (Anthony–Bartlett 1999 §3.6). This logarithmic bound is why boosting (Friedman 2001) works: weak learners (stumps) have logarithmic VC dimension, so -stump ensembles have VC dimension at most — much smaller than a -depth tree’s .
For -of- majority thresholds on , there are only such functions, so by the finite-class bound.
Neural networks: where classical VC analysis breaks
Theorem 9 (Neural-network VC dimension (Bartlett–Maiorov–Meir 1998 / Bartlett–Harvey–Liaw–Mehrabian 2019)).
For a feedforward neural network with parameters and layers using piecewise-linear activations,
for absolute constants .
For ResNet-50 (, ), this gives . The FTSL bound (6.2) then asks for around training samples to achieve a non-vacuous generalization guarantee. ImageNet has . The classical VC bound is vacuous on every realistic deep network.
This is the deep-learning puzzle: networks generalize well in practice despite enormous classical VC dimension. Three modern responses pursue different routes around the impasse:
- Margin/norm-based bounds (Bartlett–Mendelson 2002, Bartlett–Foster–Telgarsky 2017, Neyshabur–Tomioka–Srebro 2015): replace with capacity measures scaling with weight norms or margins, often yielding non-vacuous bounds.
- Implicit-bias of SGD (Soudry et al 2018, Gunasekar et al 2017, Ji–Telgarsky 2019): show that gradient descent on overparameterized models is biased toward low-complexity solutions, so the effective capacity is much smaller than the parameter count.
- Beyond uniform convergence (Nagarajan–Kolter 2019): argue that uniform-convergence-style FTSL is fundamentally the wrong tool for deep networks; algorithm-specific bounds (PAC-Bayes, compression) are needed instead.
PAC-Bayes Bounds is the canonical alternative. Full treatments of margin/norm bounds appear in Generalization Bounds §12; the implicit-bias and beyond-UC stories will be developed in the forthcoming Double Descent (coming soon) topic.
Demo — Radon’s theorem in the plane
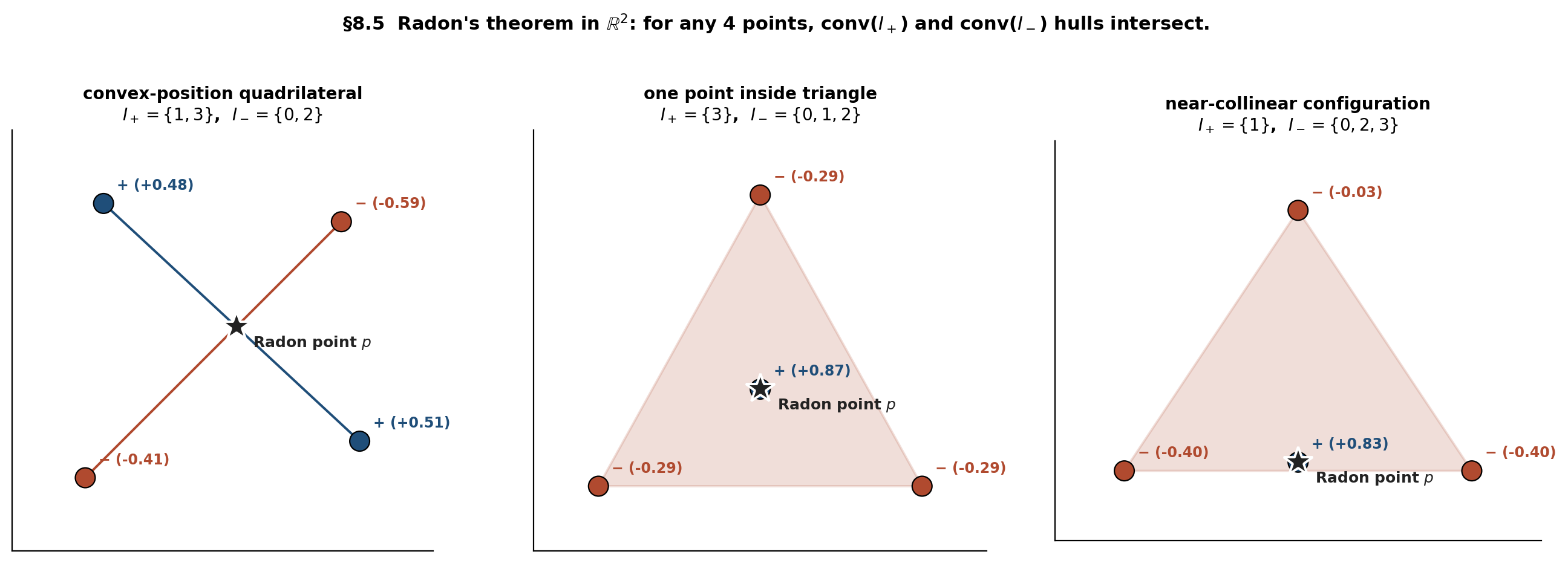
Drag any point in any panel; the Radon partition reassigns automatically. The shared point p (teal) always lies inside both convex hulls — that's what makes the corresponding labeling unrealizable by a half-plane.
The three panels show three distinct Radon-partition geometries, and the §8.5 demo lets you drag the four points to watch the partition reassign as the configuration deforms. The shared point is always inside both convex hulls — that’s what makes the labeling ”, ” unrealizable by any half-plane.
From VC dimension to Rademacher complexity
The bounds developed so far are distribution-free — strong universality but worst-case tightness. Rademacher complexity is the canonical data-dependent successor: it refines the union-bound step of the FTSL by replacing with on the actual sample .
Empirical Rademacher complexity and Massart’s lemma
Definition 5 (Empirical Rademacher complexity).
The empirical Rademacher complexity of on sample is
where are i.i.d. Rademacher variables (uniform on ). The population Rademacher complexity is .
The quantity measures how well can fit random labelings of : small means the class can’t fit random labels (limited capacity), large means it can (large capacity).
Lemma 4 (Massart's finite-class lemma).
For a finite set with ,
Specialized to (so ):
The proof is the standard sub-Gaussian max-bound argument; the full derivation is in Generalization Bounds §5 or Mohri–Rostamizadeh–Talwalkar Theorem 3.7.
The Sauer–Shelah substitution
Combining (9.2) with Sauer–Shelah’s :
The same shape as the FTSL bound (6.2). The data-dependent version uses the actual before the Sauer–Shelah substitution, which can be much tighter when the sample is benign.
Via the canonical Rademacher-based generalization bound (developed in Generalization Bounds §5.4):
The §9 framework feeds directly into the Structural Risk Minimization §5 Bartlett–Mendelson SRM penalty, where empirical Rademacher complexity replaces VC dimension as the capacity functional.
Why Rademacher can be tighter
Three sources of tightening over the worst-case VC bound:
- Duplicate samples. drops when the sample contains duplicates — fewer distinct points means fewer distinct labelings. Rademacher follows the drop; the VC bound is oblivious.
- Margin. On data with a separation margin , only the “boundary” labelings near the decision surface are realized, so is much smaller than the worst case. Rademacher captures the margin directly; the VC bound does not.
- Low-rank structure. Data lying on a -dimensional submanifold has empirical Rademacher complexity scaling with instead of . The gap can be exponential in for benign distributions.
Forward-pointer: pseudo-dimension and fat-shattering for real-valued classes
For real-valued function classes , three complexity measures generalize VC dimension:
- Pseudo-dimension (Pollard 1984) — the VC dimension of the subgraph class . Reduces to VC dimension when is binary.
- Fat-shattering at scale , (Bartlett–Long–Williamson 1996) — a margin-aware refinement; as .
- Covering numbers (Dudley 1967, van der Vaart–Wellner 1996) — the minimum number of -balls covering ; tied to fat-shattering by .
Full theory in Generalization Bounds §8 — Dudley’s entropy integral, Talagrand’s contraction lemma, McDiarmid plus symmetrization for real-valued losses.
Demo — empirical Rademacher for axis-rectangles
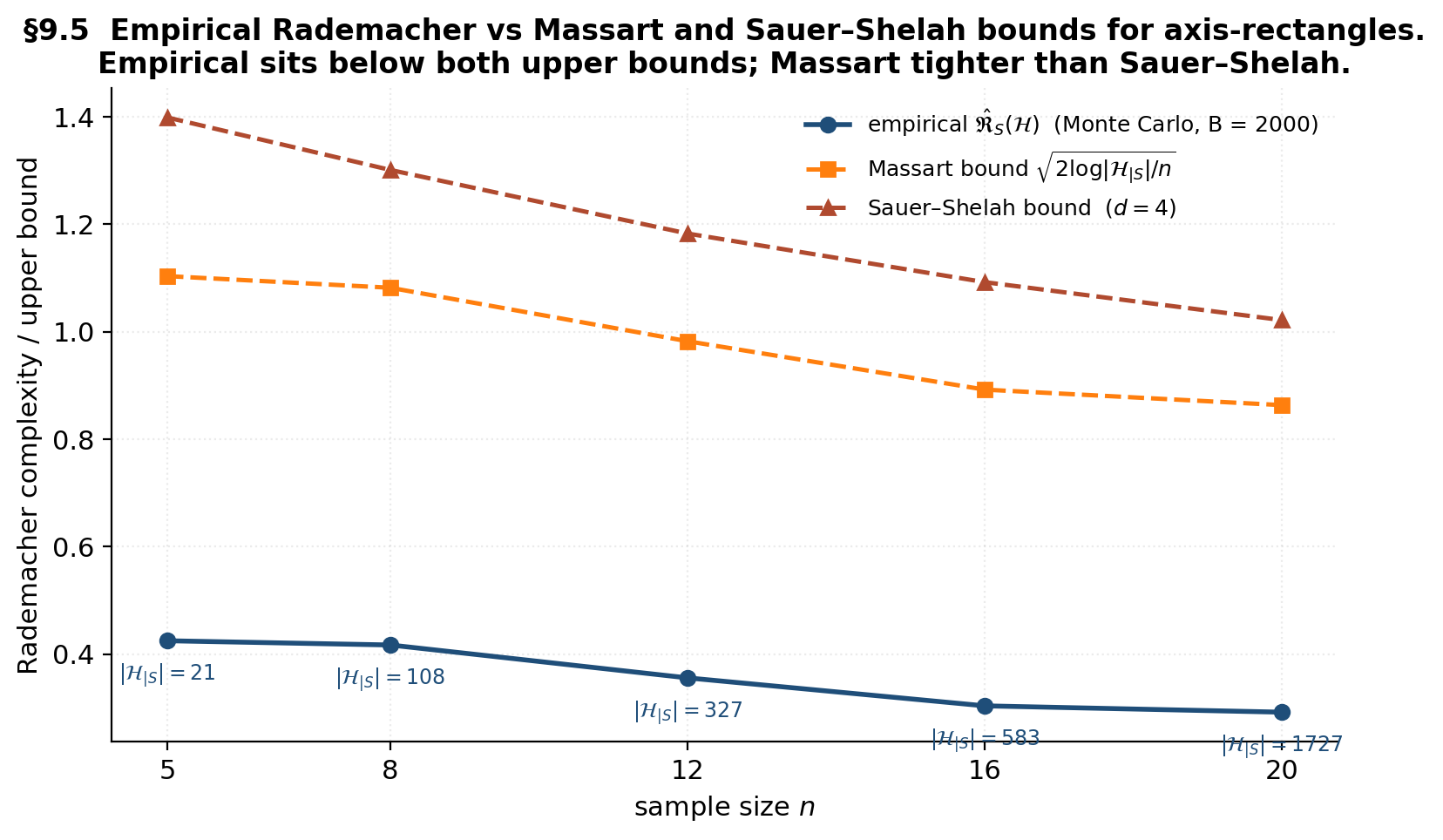
Loading precomputed Rademacher Monte Carlo...
The empirical Rademacher (blue) sits below both upper bounds at every . The Massart bound (orange) tracks the empirical closely because the actual restricted class sizes on benign random samples are far below the Sauer–Shelah ceiling. The Sauer–Shelah bound (red) is the worst-case envelope — universal but loose by a constant factor on every benign distribution.
Integrative worked example: half-planes and rectangles, end to end
A single integrative Monte Carlo on the two anchor classes verifies every box in the bound-vs-empirical chain — growth function (§3), Sauer–Shelah (§5), FTSL envelope (§6), realizable PAC (§7), and empirical Rademacher (§9) — all on the same two test problems.
The two test classes and experimental setup
Half-plane test: uniform on with — a separating line offset from the diagonal, realizable in with . Rectangle test: uniform on with — a centered square, realizable in .
Four protocols on each class:
- Growth-function check at — exhaustive enumeration of for half-planes via the Cover-1965 closed form and for rectangles by brute force on candidate labelings.
- FTSL envelope check at with replicates — empirical worst-case gap from LinearSVC at (half-plane ERM) or smallest-enclosing axis-rectangle (rectangle ERM), measured on a 30k-point held-out test set.
- Realizable sample-complexity verification at , — find the smallest at which 95% of replicates achieve , compared to the theoretical (7.1) prediction.
- Empirical Rademacher at — brute-force followed by Rademacher-draw averages of the sup over realized labelings.
Growth-function verification
For each , enumerate for half-planes (closed form , exact) and rectangles (brute-force over labelings, exact). Both classes respect the Sauer–Shelah ceiling. The empirical matches the closed form exactly; the rectangle empirical sits below with slack that varies by sample configuration.
FTSL envelope check
Run ERM Monte Carlo. The empirical gap is 1/10 to 1/30 of the FTSL envelope across all sample sizes; the same shape on log-log; the rectangle gap is larger than the half-plane gap by roughly the ratio predicted by the scaling.
Realizable sample-complexity verification
Both empirical curves scale as , matching the theoretical (7.1) shape; the theoretical bound is loose by roughly an order of magnitude; the rectangle-to-half-plane ratio holds across all , consistent with the scaling.
Demo — the integrative four-panel “money shot”
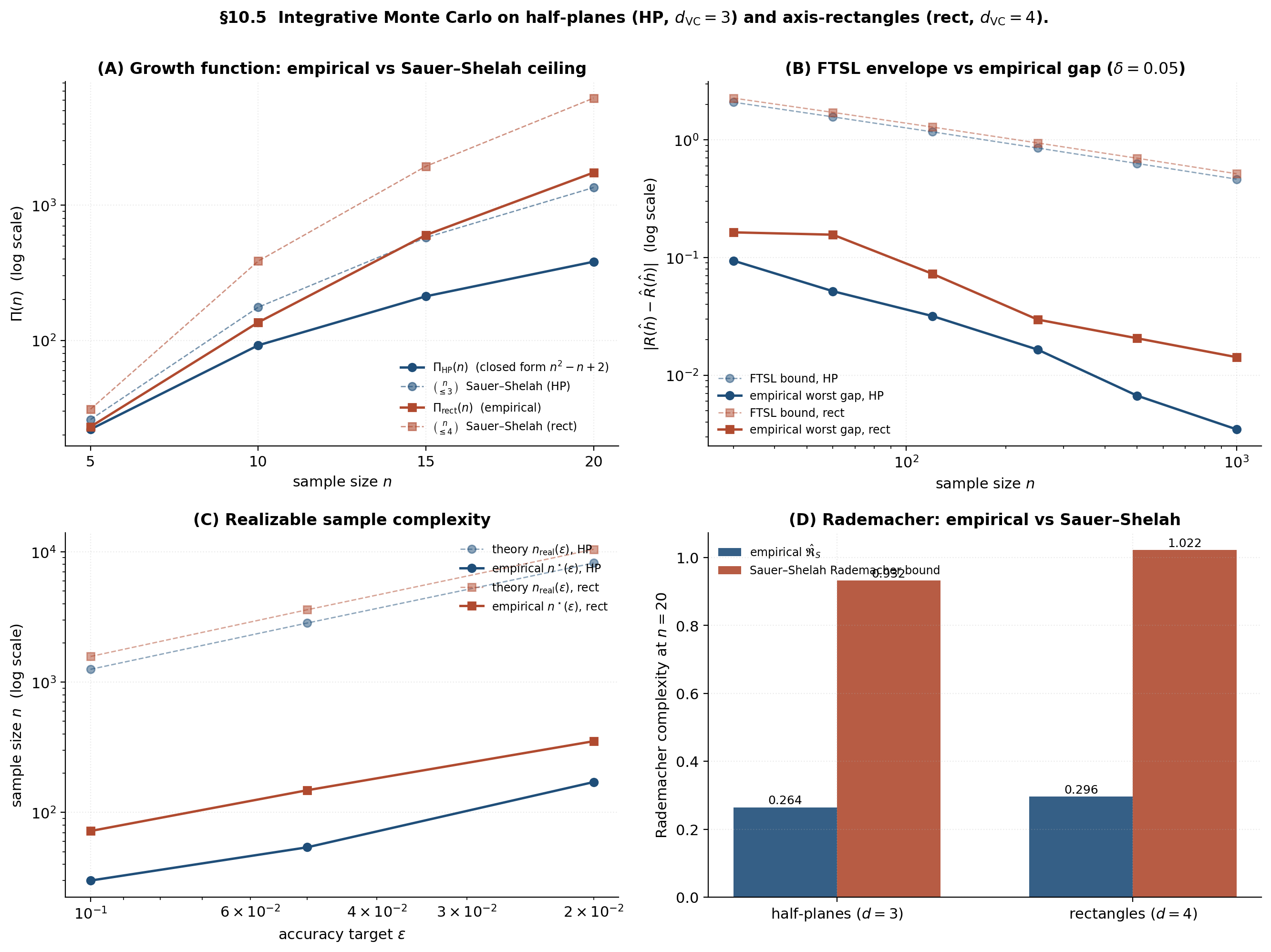
Loading integrative Monte Carlo (4 protocols)...
Panel A confirms empirical growth functions sit below Sauer–Shelah ceilings ( and slopes). Panel B is the FTSL envelope versus empirical worst-case gap — loose by an order of magnitude but rate-correct ( slope on log-log for both classes). Panel C is the realizable sample-complexity story — linear in as predicted. Panel D is the empirical Rademacher comparison — empirical sits below the Sauer–Shelah Rademacher bound at every , with the gap growing as the actual stays well below the worst-case ceiling. Every bound is verified; the looseness is universal but the rate is right.
ML applications
SVMs and the margin: tightening VC dimension with geometry
Half-spaces in have — large for high-dimensional feature spaces, FTSL bound vacuous. SVMs sidestep the dimension dependence via margin-based VC analysis: for the margin-restricted class of half-spaces achieving at least margin on data with radius ,
independent of the ambient dimension . Linear SVMs in and kernel SVMs in infinite-dimensional RKHS are both tractable only because the margin bound replaces dimension-dependent VC dimension with geometry-dependent . Hinge-loss training is direct margin maximization; the soft-margin slack handles the non-separable case. The forward link is Generalization Bounds §10.
Decision trees, pruning, and capacity control
A decision tree with leaves on -dimensional input has (Mansour–McAllester 2000). Pruning controls VC dimension directly: cost-complexity pruning (Breiman et al 1984) walks a nested family of decision trees with increasing , applying the SRM machinery from Structural Risk Minimization. Random forests (Breiman 2001) and gradient-boosted trees (Friedman 2001) extend the picture with bagging and boosting respectively. The §8.3 fact that decision stumps have is precisely why boosting works: a -stump ensemble has , exponentially smaller than a -depth tree.
ERM and the bias-complexity decomposition
The agnostic FTSL bound gives the decomposition
Approximation error decreases in (richer classes can approximate the Bayes-optimal classifier more closely); estimation error increases in (richer classes have larger generalization gap). SRM minimizes the sum: scan nested classes ordered by VC dimension and pick the index minimizing training error plus a VC-based capacity penalty. Full development in Structural Risk Minimization §4.
The deep-learning puzzle
ResNet-50 has ; FTSL needs training samples; ImageNet provides ; ResNets generalize well in practice. Zhang et al (2017) confirmed three findings on this picture: memorization capacity is enormous (deep networks can fit random labels to perfect accuracy); the same networks generalize on real labels; classical VC bounds are vacuous. Three modern responses pursue different routes:
- Margin/norm-based bounds (Bartlett–Mendelson 2002, Bartlett–Foster–Telgarsky 2017, Neyshabur–Tomioka–Srebro 2015): replace with capacity measures scaling with weight norms or margins. The bound is informative when per-layer norms are controlled and vacuous otherwise.
- Implicit-bias of SGD (Soudry et al 2018, Gunasekar et al 2017, Ji–Telgarsky 2019): the optimizer biases the trained network toward low-complexity solutions, so effective VC dimension is much smaller than parameter count.
- Beyond uniform convergence (Nagarajan–Kolter 2019): classical FTSL is uniform-convergence-based, but the right tool may be non-uniform algorithm-specific bounds. PAC-Bayes (PAC-Bayes Bounds) and compression bounds (Moran–Yehudayoff 2016) are canonical alternatives.
The forward-pointer is Double Descent (coming soon): test error decreases past the interpolation threshold, a phenomenon classical VC analysis fundamentally cannot explain.
Demo — margin tightens the VC bound
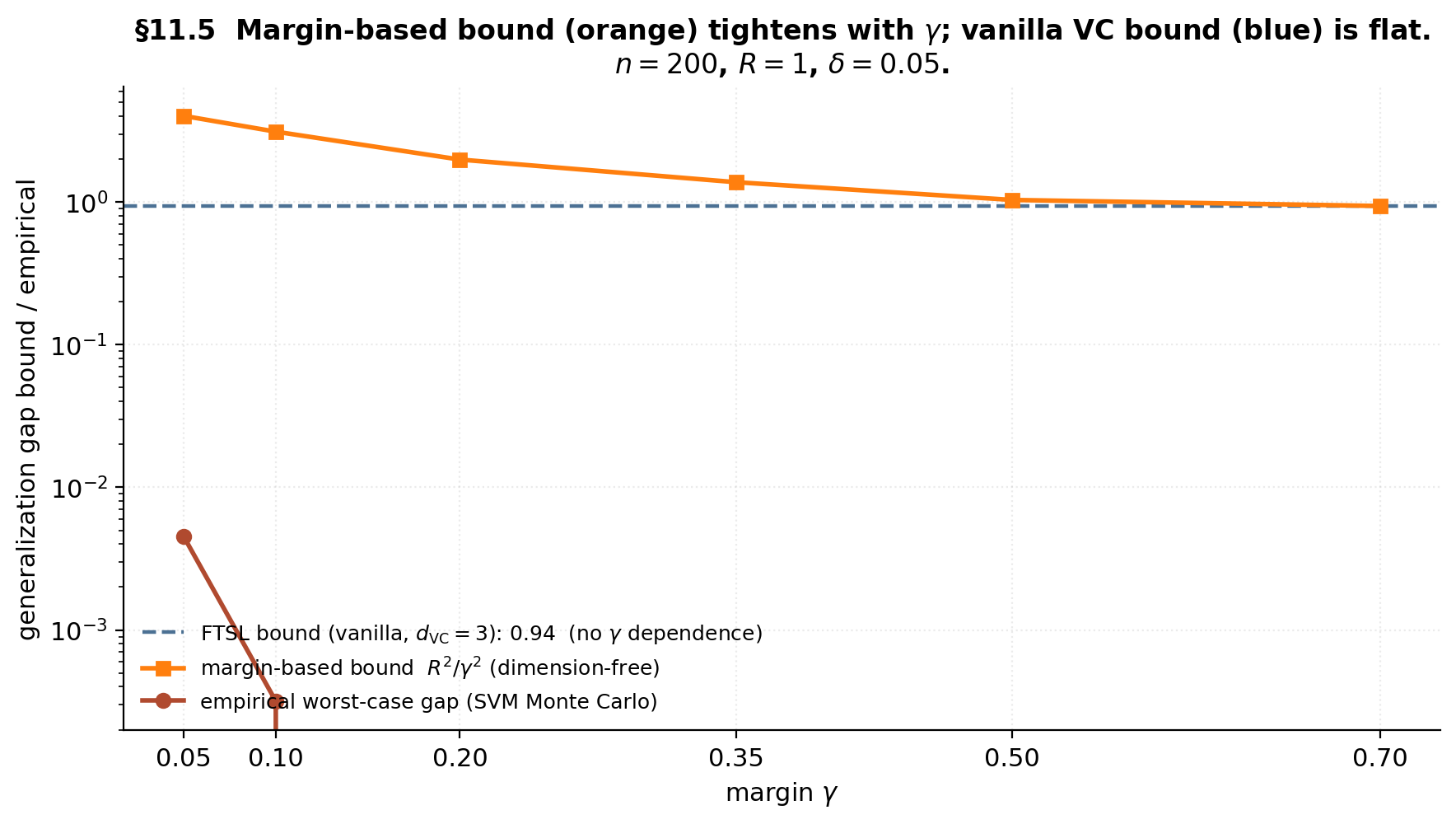
At γ = 0.20: vanilla FTSL = 0.939 (flat), margin bound = 1.987, empirical = 0.0020. The margin bound tracks the empirical gap's shape; the vanilla bound doesn't see γ at all.
The FTSL bound (blue dashed) is flat — sees only and , neither dependent on . The margin-based bound (orange) decreases with because the effective capacity shrinks as the data become more separable. Empirical SVM Monte Carlo (red) matches the margin-based shape — the flat VC bound is genuinely the wrong capacity measure when the data have margin.
Computational notes
The 2^n enumeration ceiling
Brute-force enumeration of requires labeling checks at cost per check. Laptop ceiling: takes milliseconds; takes 1–5 seconds; takes 30–90 seconds; takes many minutes. For in-browser visualizations, the cap is . Above that, use closed-form (half-lines, intervals, half-planes via Cover 1965), Sauer–Shelah upper bounds, or symmetry-aware enumeration.
Symmetry exploitation for half-spaces
Cover (1965): , not . The constructive enumeration: every distinct dichotomy is determined by a -tuple of support points. For , this is — a sample of has vs . The ceiling extends to in .
Cell decomposition for axis-rectangles
enumeration: every rectangle dichotomy is determined by extreme points (axis min/max of the labeled-1 subset). For : candidates at , versus — impossible by brute force. Production visualizations should use this; the pedagogical demos in §§3.5 and 10.5 use brute force for conceptual clarity at small .
Reproducibility and visualization caps
Seed convention: RNG = np.random.default_rng(20260513) at the notebook top. Practical caps for in-browser visualizations: the shattering playground at ; the growth-function plotter empirical curves at ; the FTSL bound explorer uses closed-form bounds plus cached JSON; the empirical-shatter-check four-panel is fully precomputed and served as JSON. NumPy convention throughout: always default_rng, never the deprecated np.random.seed global state.
Connections and limits
Pseudo-dimension and fat-shattering for real-valued classes
For real-valued , the three complexity measures generalizing VC dimension are:
- Pseudo-dimension (Pollard 1984) — largest such that some sample admits a threshold vector for which the thresholded class shatters every binary pattern. Reduces to VC for binary classes. For linear regression in , . For neural networks, depends on the architecture and is polynomial in the parameter count.
- Fat-shattering at scale , (Bartlett–Long–Williamson 1996) — a margin constraint on the shattered set; as .
- Covering numbers (Dudley 1967, van der Vaart–Wellner 1996) — minimum number of -balls covering ; tied to fat-shattering by .
Full theory in Generalization Bounds §8 — Dudley’s entropy integral, Talagrand’s contraction lemma, McDiarmid plus symmetrization for real-valued losses.
The deep-learning generalization puzzle
Zhang et al (2017) crystallized the three findings discussed in §11.4: memorization is enormous, generalization on real labels is real, and classical VC bounds are vacuous. The conclusion is that uniform convergence is not the operative framework for deep learning — the worst-case capacity argument that powers FTSL fails on modern models. Three modern responses sketched in §11.4 follow different routes; the forward-pointer is Double Descent (coming soon), which addresses the interpolation-threshold phenomenon directly.
Distribution-free versus distribution-dependent guarantees
The VC framework is distribution-free — universal but worst-case. Three distribution-dependent alternatives:
- Bayes-style smoothness assumptions — Tsybakov margin (§7.4 mode 3) interpolates to ; smoothness classes (Hölder, Sobolev) yield minimax rates. The formalStatistics: nonparametric-regression topic is the entry point.
- Algorithmic stability (Bousquet–Elisseeff 2002) — -stability gives rate, no VC required. Ridge is -stable. Forward link: Generalization Bounds §11.
- Compression bounds (Littlestone–Warmuth 1986, Floyd–Warmuth 1995, Moran–Yehudayoff 2016) — reconstruction from a -subsample gives a rate. Every PAC-learnable class admits a compression scheme of size (Moran–Yehudayoff converse).
Where to go next
Connected formalML topics:
- Structural Risk Minimization — uses as the canonical capacity penalty in the Vapnik SRM framework.
- PAC-Bayes Bounds — replaces the worst-case supremum over with a posterior average, using KL divergence as the capacity measure.
- Generalization Bounds — the empirical-process machinery (Rademacher complexity, symmetrization, McDiarmid, Talagrand) used here without full proof.
- PAC Learning — the parent framework for agnostic PAC, realizable PAC, and the union-bound machinery.
- Double Descent (coming soon) — the modern overparameterized regime where VC analysis breaks down.
The VC framework’s value is not tight bounds for every ML setting; it is the structural insight that capacity is the right quantity to bound, that shattering is the right way to measure capacity, and that is the right substitute for in the union-bound argument. Every modern alternative — margin/norm bounds, PAC-Bayes, implicit-bias analysis, compression schemes — is built on this foundation.
We started asking what’s the right combinatorial substitute for when the cardinality counts the wrong thing. The answer is the VC dimension and its growth-function machinery. Sauer–Shelah converts the integer into polynomial growth, the FTSL converts polynomial growth into a uniform-convergence bound, and the equivalence theorem ties finite VC dimension to PAC-learnability in both directions. The topic delivers the foundation; tighter bounds for modern overparameterized models require the margin/norm refinements, PAC-Bayes, or implicit-bias analysis from connected topics.
Connections
- PAC-learning sets up the (ε, δ)-framework and the finite-class union-bound; this topic supplies the combinatorial machinery (shattering, growth function, VC dimension) that extends finite-class arguments to infinite classes. The Fundamental Theorem of Statistical Learning equivalence we prove in §6 ties finite VC dimension to agnostic PAC-learnability in both directions. pac-learning
- The §9 bridge to Rademacher complexity feeds directly into the Massart, McDiarmid, and Talagrand machinery developed in generalization-bounds; finite VC dimension is the discrete capacity precursor of the continuous-time empirical-process bounds shown there. The §14.2 VC-dimension stub in generalization-bounds is discharged by this topic. generalization-bounds
- VC dimension is the canonical capacity functional in the Vapnik SRM penalty (SRM §4); the §3 phase-transition picture and §5 Sauer–Shelah bound are the substrate that makes the SRM oracle inequality nontrivial for infinite classes. The §11.3 bias-complexity decomposition is the SRM motivation in compressed form. structural-risk-minimization
- Hoeffding's inequality from concentration-inequalities is one of the two ingredients in the FTSL proof — the other being polynomial growth via Sauer–Shelah. The §7.3 Bernstein-vs-Hoeffding rate-gap discussion is the variance-aware concentration story that explains the realizable vs agnostic split. concentration-inequalities
References & Further Reading
- paper On the Uniform Convergence of Relative Frequencies of Events to Their Probabilities — Vapnik & Chervonenkis (1971) The founding paper. Defines shattering, the growth function, and proves the uniform-convergence theorem in its original form.
- paper On the Density of Families of Sets — Sauer (1972) Independent discovery of the polynomial growth bound — the Sauer half of the Sauer–Shelah lemma.
- paper A Combinatorial Problem: Stability and Order for Models and Theories in Infinitary Languages — Shelah (1972) Shelah's parallel discovery from model theory in the same year.
- paper Mengen konvexer Körper, die einen gemeinsamen Punkt enthalten — Radon (1921) Radon's theorem on partitions of d+2 points in R^d — the load-bearing geometric fact in §8.1's half-space proof.
- paper Geometrical and Statistical Properties of Systems of Linear Inequalities with Applications in Pattern Recognition — Cover (1965) Closed-form growth function n²−n+2 for half-planes in §3.3; symmetry-aware O(n^d) enumeration for half-spaces in §12.2.
- paper On the Number of Sets in a Null t-Design — Frankl & Pach (1983) The shifting-operator proof of Sauer–Shelah used in §5.
- book Sous-espaces ℓ_1^n des espaces de Banach — Pajor (1985) The cleaner presentation of the shifting argument that §5.2–§5.3 follow.
- paper Learnability and the Vapnik-Chervonenkis Dimension — Blumer, Ehrenfeucht, Haussler & Warmuth (1989) The Fundamental Theorem of Statistical Learning equivalence (§6.4 Theorem 4): finite VC ⇔ uniform convergence ⇔ agnostic PAC-learnability.
- book The Nature of Statistical Learning Theory — Vapnik (1995) Pedagogical book-length presentation of VC theory and SRM; the §4.4 sine-wave pathology in our topic is from Chapter 3.4.
- book Statistical Learning Theory — Vapnik (1998) Comprehensive treatment; Theorem 4.1 here is the symmetrization step used in §6.2 Lemma 3.
- book Neural Network Learning: Theoretical Foundations — Anthony & Bartlett (1999) Standard reference for VC dimension of canonical classes; §3.6 develops decision stumps and small Boolean classes used in §8.3 of our topic.
- book Understanding Machine Learning: From Theory to Algorithms — Shalev-Shwartz & Ben-David (2014) The clearest modern textbook treatment. §6.4 contains the FTSL equivalence chain we follow in §6.4, and §5.1 has the no-free-lunch lower bound in §6.4 of our topic.
- book Foundations of Machine Learning, 2nd ed. — Mohri, Rostamizadeh & Talwalkar (2018) Theorem 3.20 has the constructive direction of the half-space VC dimension; Theorem 3.7 is the Massart lemma proof used in §9.1.
- book Convergence of Stochastic Processes — Pollard (1984) Pseudo-dimension for real-valued classes (§13.1 forward-pointer) was introduced here.
- paper Some Applications of Concentration Inequalities to Statistics — Massart (2000) Massart's finite-class lemma (§9.1 Lemma 4) and the constant-improvement program for FTSL bounds.
- paper The Sample Complexity of Pattern Classification with Neural Networks: The Size of the Weights Is More Important Than the Size of the Network — Bartlett (1998) Margin-based capacity control as the first systematic alternative to the dimension-dependent VC bound for neural networks (§11.4 modern responses).
- paper Almost Linear VC-Dimension Bounds for Piecewise Polynomial Networks — Bartlett, Maiorov & Meir (1998) Half of the Theorem 9 (§8.4) bound; the lower bound c WL log(W/L) on VC dimension for piecewise-linear nets.
- paper Fat-Shattering and the Learnability of Real-Valued Functions — Bartlett, Long & Williamson (1996) Fat-shattering at scale γ (§13.1 forward-pointer) — the margin-aware refinement of pseudo-dimension.
- paper Rademacher and Gaussian Complexities: Risk Bounds and Structural Results — Bartlett & Mendelson (2002) Canonical Rademacher-complexity development feeding §9 and the margin-norm bounds in §11.4.
- paper Nearly-Tight VC-Dimension and Pseudodimension Bounds for Piecewise Linear Neural Networks — Bartlett, Harvey, Liaw & Mehrabian (2019) The matching upper bound C WL log W in Theorem 9 (§8.4). Together with Bartlett–Maiorov–Meir 1998 this sandwiches the VC dimension of piecewise-linear neural networks.
- paper What Size Net Gives Valid Generalization? — Baum & Haussler (1989) Earliest VC bound for neural networks; precursor to the Bartlett family of bounds in §8.4.
- book Weak Convergence and Empirical Processes: With Applications to Statistics — van der Vaart & Wellner (1996) Definitive treatment of covering numbers, bracketing, and the Dudley entropy integral that real-valued generalizations (§13.1) point to.
- paper Understanding Deep Learning Requires Rethinking Generalization — Zhang, Bengio, Hardt, Recht & Vinyals (2017) The empirical observation that powers §11.4: deep networks can memorize random labels, so classical VC bounds are vacuous.
- paper Spectrally-Normalized Margin Bounds for Neural Networks — Bartlett, Foster & Telgarsky (2017) Modern margin-norm bound for deep networks; one of the three responses to the deep-learning puzzle in §11.4.
- paper Norm-Based Capacity Control in Neural Networks — Neyshabur, Tomioka & Srebro (2015) Early norm-based capacity control for neural networks (§11.4 response 1).
- paper The Implicit Bias of Gradient Descent on Separable Data — Soudry, Hoffer, Nacson, Gunasekar & Srebro (2018) Implicit-bias program (§11.4 response 2): SGD on separable data converges to the maximum-margin solution, so effective capacity is much smaller than parameter count.
- paper Uniform Convergence May Be Unable to Explain Generalization in Deep Learning — Nagarajan & Kolter (2019) The beyond-uniform-convergence response (§11.4 response 3): classical FTSL is uniform-convergence, but the right tool may be non-uniform algorithm-specific bounds.
- paper Nonparametric Regression Using Deep Neural Networks with ReLU Activation Function — Schmidt-Hieber (2020) Approximation-theoretic deep-net rates as a contrast to capacity-based VC bounds; §13.2 connection point.
- paper Stability and Generalization — Bousquet & Elisseeff (2002) Algorithmic stability as a distribution-dependent alternative to VC (§13.3); ridge is β=O(1/(λn))-stable.
- paper Sample Compression Schemes for VC Classes — Moran & Yehudayoff (2016) The Moran–Yehudayoff converse: every PAC-learnable class admits a sample-compression scheme of size O(d_VC). §13.3 distribution-dependent alternative.
- paper Generalization Bounds for Decision Trees — Mansour & McAllester (2000) Decision-tree VC dimension O(N log(Nd)) used in §11.2.
- book Classification and Regression Trees — Breiman, Friedman, Olshen & Stone (1984) Cost-complexity pruning as nested-SRM (§11.2).
- paper Random Forests — Breiman (2001) Bagging extension to decision trees (§11.2).
- paper Greedy Function Approximation: A Gradient Boosting Machine — Friedman (2001) Gradient boosting on decision stumps; the §8.3 logarithmic VC of stumps is what makes the boosted ensemble's effective capacity grow linearly in the number of weak learners (§11.2).
- paper Smooth Discrimination Analysis — Mammen & Tsybakov (1999) Tsybakov margin condition: the (c, α) interpolation between realizable (1/ε) and agnostic (1/ε²) rates used in §7.4 failure mode 3.
- paper Learning with Noisy Labels — Natarajan, Dhillon, Ravikumar & Tewari (2013) Label-noise as the canonical degradation from realizable to agnostic (§7.4 failure mode 1).