KL Divergence & f-Divergences
Statistical divergences — measuring distributional mismatch through coding excess, convex generators, and variational representations
Overview & Motivation
Cross-entropy loss, variational inference, and generative adversarial networks look like three unrelated ideas. But they share a common engine: each one minimizes a divergence — a function that measures how one probability distribution differs from another.
- Cross-entropy loss minimizes the KL divergence from the true label distribution to the model’s predictions (forward KL).
- Variational inference minimizes the KL divergence from an approximate posterior to the true posterior (reverse KL), which is equivalent to maximizing the ELBO.
- GANs minimize the Jensen–Shannon divergence between the real data distribution and the generator’s output.
All three are special cases of f-divergence minimization, a framework that unifies a family of distributional distance measures through convex analysis. Understanding this framework gives us a single lens through which cross-entropy loss, the ELBO, and the GAN objective are all the same idea in different clothes.
This topic develops the theory systematically: we start with KL divergence and its operational meaning as the excess cost of miscoding, then explore how the direction of the KL divergence (forward vs reverse) determines fundamentally different fitting behavior. We generalize to f-divergences — showing that KL, reverse KL, , Hellinger, total variation, and Jensen–Shannon are all members of one family parameterized by convex generator functions. Variational representations via Fenchel conjugates turn these abstract measures into optimization problems that can be solved with neural networks. Rényi divergences provide a complementary one-parameter family with applications to differential privacy and hypothesis testing.
Prerequisites
This topic builds on:
- Shannon Entropy & Mutual Information — KL divergence is defined as the gap between cross-entropy and entropy: . We use entropy, mutual information, and the data processing inequality throughout.
What We Cover
- KL divergence — definition, Gibbs’ inequality, asymmetry, cross-entropy decomposition
- Forward vs reverse KL — mode-covering vs mode-seeking, connections to MLE and variational inference
- f-divergences — the unifying framework via convex generator functions
- Properties of f-divergences — non-negativity, joint convexity, data processing inequality, Pinsker’s inequality
- Variational representations — Fenchel conjugates, Donsker–Varadhan, NWJ bound, connection to GANs
- Rényi divergence — the -divergence family, monotonicity, special cases
- Computational notes — estimation, cross-entropy loss, ELBO, practical implementations
KL Divergence: Definition & Properties
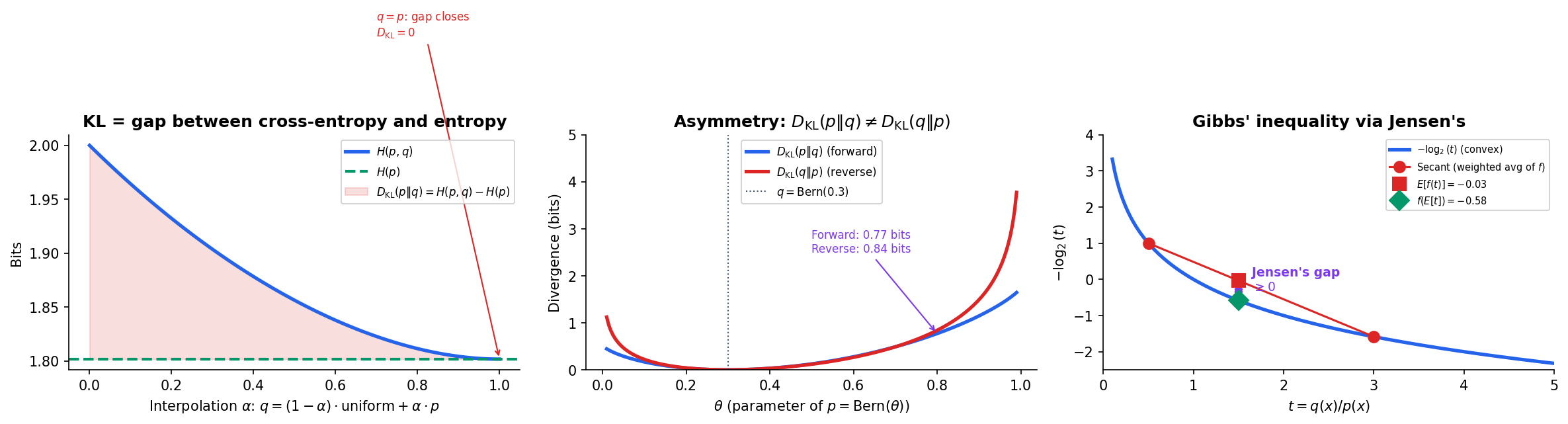
In Shannon Entropy & Mutual Information, we defined the entropy as the minimum average code length for a source with distribution . If we use a code optimized for a different distribution , the average code length increases to — the cross-entropy. The difference is the excess cost of using the wrong code.
Definition 1 (KL Divergence).
The Kullback–Leibler divergence (or relative entropy) from distribution to distribution over a finite alphabet is
with the conventions and when .
The operational meaning: is the expected number of extra bits needed to encode samples from using a code optimized for , beyond the minimum achieved by the optimal code for .
Definition 2 (Cross-Entropy).
The cross-entropy from to is
It measures the expected code length when encoding data from with a code optimized for .
The key decomposition connecting these quantities is immediate:
Proposition 1 (Cross-Entropy Decomposition).
Cross-entropy equals entropy plus KL divergence. Since (Gibbs’ inequality, below), the cross-entropy is always at least as large as the entropy.
Proof.
∎
Gibbs’ Inequality
The most fundamental property of KL divergence is non-negativity: using the wrong code never helps.
Proposition 2 (Non-negativity of KL (Gibbs' Inequality)).
For any distributions and over the same alphabet, .
Proof.
Since is a strictly convex function, Jensen’s inequality gives:
Therefore .
∎
Proposition 3 (KL Divergence and Equality).
if and only if (for all where ).
Proof.
Equality in Jensen’s inequality holds iff the random variable is constant -almost surely. Since , that constant must be , giving wherever .
∎
Asymmetry
Unlike a true distance, KL divergence is not symmetric.
Proposition 4 (Asymmetry of KL).
In general, .
Counterexample. Let and . Then:
The asymmetry is not a defect — it encodes fundamentally different information about the relationship between and . The direction you choose determines the fitting behavior, as we explore in the next section.
KL divergence is also not a metric: it violates the triangle inequality. It is not even a semimetric (which requires symmetry). Despite this, it plays a central role because its information-theoretic interpretation is exact and its connection to maximum likelihood estimation is direct.
Explore the interactive visualization below. Drag the bars to adjust both distributions and watch the KL divergence, cross-entropy, and their asymmetry update in real time.
import numpy as np
def kl_divergence(p, q):
"""KL divergence D_KL(p || q) in bits."""
p, q = np.asarray(p, float), np.asarray(q, float)
mask = p > 0
if np.any(q[mask] <= 0):
return np.inf
return np.sum(p[mask] * np.log2(p[mask] / q[mask]))
def cross_entropy(p, q):
"""Cross-entropy H(p, q) in bits."""
p, q = np.asarray(p, float), np.asarray(q, float)
mask = p > 0
if np.any(q[mask] <= 0):
return np.inf
return -np.sum(p[mask] * np.log2(q[mask]))
# Cross-entropy decomposition: H(p, q) = H(p) + D_KL(p || q)
p = np.array([0.4, 0.35, 0.15, 0.1])
q = np.array([0.25, 0.25, 0.25, 0.25])
H_p = -np.sum(p * np.log2(p)) # 1.8464 bits
H_pq = cross_entropy(p, q) # 2.0000 bits
D_KL = kl_divergence(p, q) # 0.1536 bits
# Verify: H_pq ≈ H_p + D_KL → 2.0000 ≈ 1.8464 + 0.1536 ✓Forward vs Reverse KL
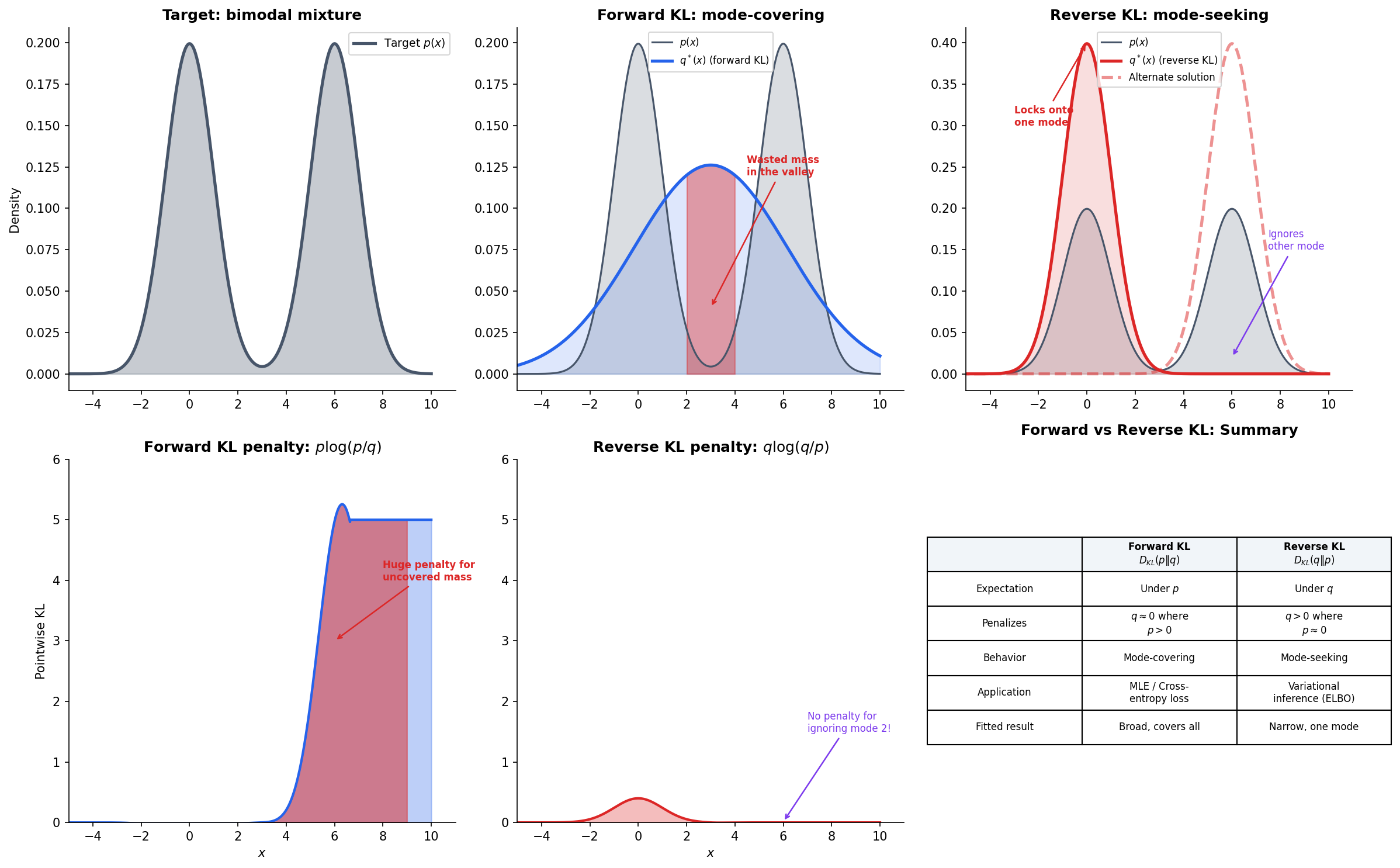
The asymmetry of KL divergence is not merely a mathematical curiosity — it produces two fundamentally different fitting behaviors. When we approximate a complex distribution with a simpler model , the direction of the KL divergence we minimize determines what kind of approximation we get.
Forward KL: Mode-Covering
Minimizing forward KL over the model family produces a model that covers all modes of .
The penalty comes from : if but , the term . This penalty forces to place mass everywhere does — it must cover all modes, even at the cost of putting wasted probability mass in regions between modes.
Remark (Forward KL as MLE).
Minimizing forward KL over is equivalent to maximum likelihood estimation. Since and does not depend on , we have .
When is the empirical distribution over training data, — the log-likelihood. Cross-entropy loss in classification is forward KL minimization.
Reverse KL: Mode-Seeking
Minimizing reverse KL produces a model that seeks a single mode of .
Now the penalty comes from : if but , the term explodes. This forces to avoid placing mass where does not — but it has no penalty for ignoring modes of where is already zero. The result: locks onto a single mode and ignores the rest.
Remark (Reverse KL and ELBO).
In variational inference, we approximate an intractable posterior with a tractable family . The evidence lower bound (ELBO) satisfies:
Since is fixed, maximizing the ELBO is equivalent to minimizing the reverse KL from to the true posterior. This explains why variational autoencoders (VAEs) tend to produce approximations that are too concentrated — the reverse KL lets the approximation ignore modes of the posterior.
The visualization below demonstrates this contrast on a bimodal target. A single Gaussian fit under forward KL spreads to cover both peaks (with wasted mass in the valley), while under reverse KL it locks onto one peak.
f-Divergences: A Unifying Framework
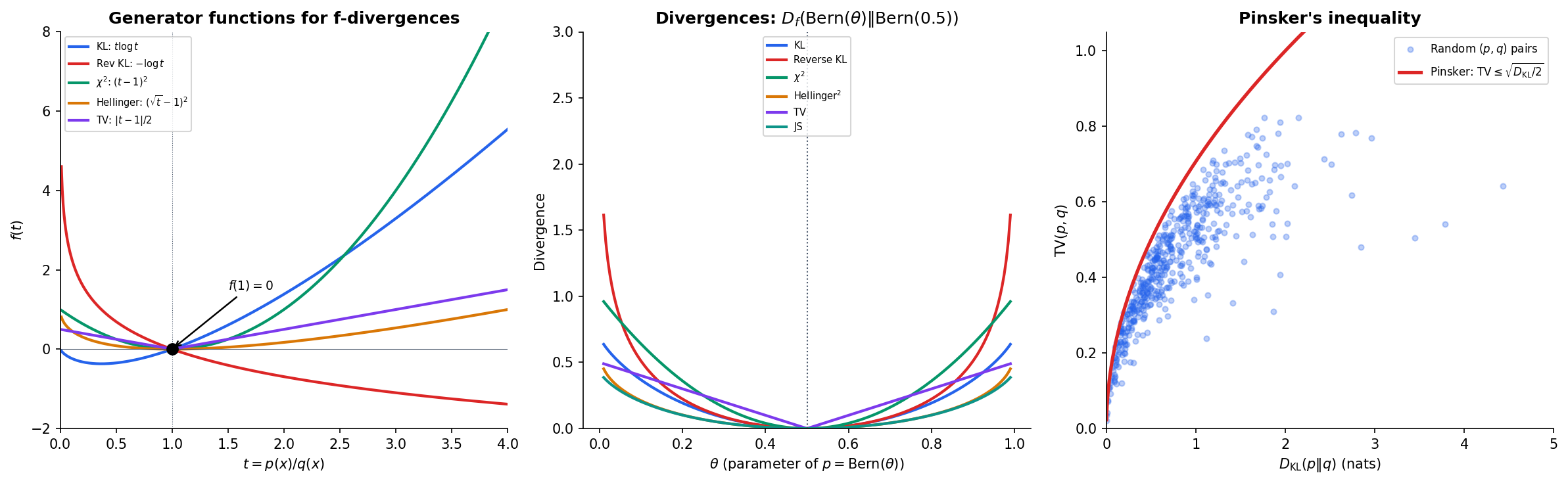
KL divergence is one member of a much larger family. Ali & Silvey (1966) and Csiszár (1967) independently showed that a single construction — parameterized by a convex function — generates an entire family of divergences, all sharing the key properties we proved for KL.
Definition 3 (f-Divergence).
Let be a convex function with . The f-divergence from to is
with the conventions and when , .
The generator function determines which divergence we get. Every satisfying the conditions above — convex, with — produces a valid divergence that is non-negative and zero iff .
The following table shows six important special cases, each recoverable by choosing the appropriate generator:
- KL divergence: gives
- Reverse KL: gives
- divergence: gives
- Squared Hellinger: gives
- Total variation: gives
- Jensen–Shannon: gives
where in the Jensen–Shannon case.
Definition 4 (Total Variation Distance).
The total variation distance between and is
It is the maximum difference in probability assigned to any event: .
Definition 5 (Jensen–Shannon Divergence).
The Jensen–Shannon divergence is the symmetrized, smoothed KL divergence:
Unlike KL divergence, JS is symmetric, bounded (), and its square root is a metric. It is the divergence minimized (implicitly) in the original GAN objective.
Explore the f-divergence family below. The left panel shows the generator functions — all convex, all passing through . The right panel shows how each divergence responds to distributional mismatch.
def f_divergence(p, q, f_func):
"""General f-divergence D_f(p || q) = sum q(x) f(p(x)/q(x))."""
p, q = np.asarray(p, float), np.asarray(q, float)
result = 0.0
for pi, qi in zip(p, q):
if qi > 0 and pi > 0:
result += qi * f_func(pi / qi)
elif qi > 0 and pi == 0:
result += qi * f_func(0.0)
elif qi == 0 and pi > 0:
return np.inf
return result
# Generator functions (use natural log — the standard convention for
# f-divergences; kl_divergence() above uses log2 for bits)
f_kl = lambda t: t * np.log(t) if t > 0 else 0.0
f_reverse_kl = lambda t: -np.log(t) if t > 0 else np.inf
f_chi_sq = lambda t: (t - 1) ** 2
f_hellinger = lambda t: (np.sqrt(max(t, 0)) - 1) ** 2
f_tv = lambda t: abs(t - 1) / 2
f_js = lambda t: (t * np.log(t / ((t + 1) / 2)) + np.log(1 / ((t + 1) / 2))
if t > 0 else np.log(2))Properties of f-Divergences
The power of the f-divergence framework is that all members inherit fundamental properties from the convexity of alone. We do not need separate proofs for KL, , Hellinger, etc. — one proof covers them all.
Theorem 1 (Non-negativity of f-Divergences).
For any convex with , for all distributions . Equality holds iff when is strictly convex at .
Proof.
By Jensen’s inequality applied to the convex function :
When is strictly convex at , equality in Jensen’s holds iff is constant -a.s., which forces .
∎
This is the same proof structure as Gibbs’ inequality for KL — because Gibbs’ inequality is the special case .
Theorem 2 (Joint Convexity of f-Divergences).
is jointly convex in the pair . That is, for :
Proof.
The perspective function is jointly convex when is convex (this is a standard result in Convex Analysis). Since is a sum of jointly convex functions, it is jointly convex.
∎
Joint convexity means that divergence minimization — minimizing over parameters — is a convex problem when the mapping is affine.
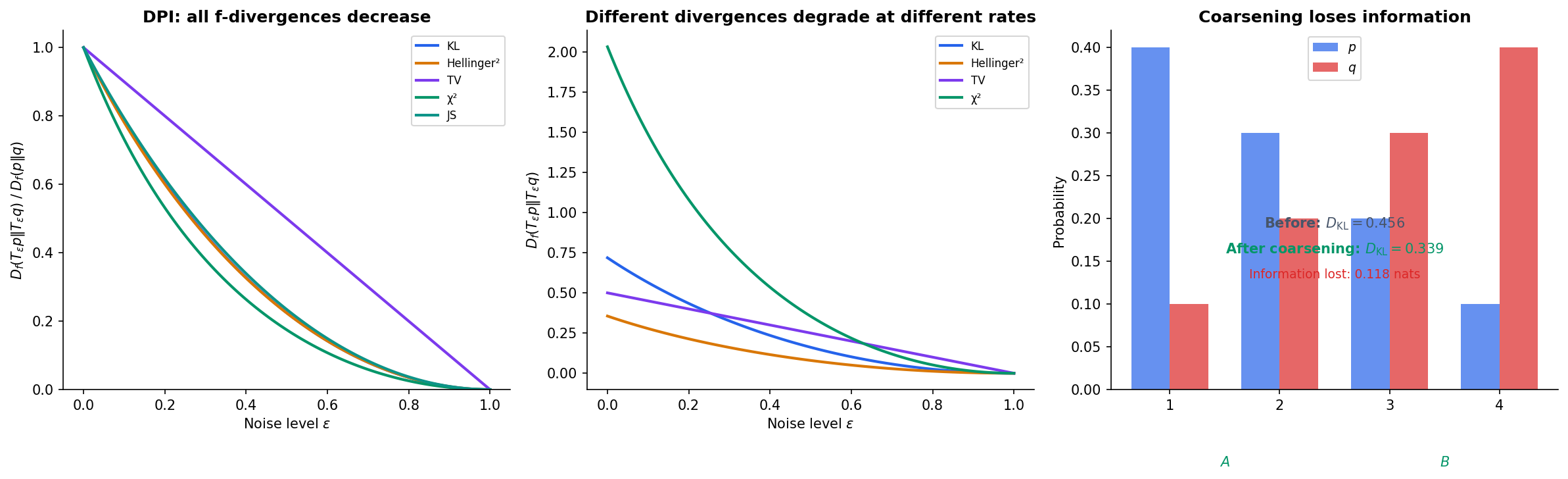
Data Processing Inequality for f-Divergences
The data processing inequality (DPI) says that processing data can only lose information — it can never increase the divergence between two distributions.
Theorem 3 (Data Processing Inequality for f-Divergences).
For any f-divergence and any Markov kernel (channel) :
where is the output distribution when is passed through channel .
Proof.
For each output , the ratio is a -weighted average of the input ratios :
where the weights sum to . By the convexity of (Jensen’s inequality):
Multiplying by and summing over gives .
∎
This is strictly more general than the mutual information DPI from Shannon Entropy & Mutual Information. The mutual information DPI for a Markov chain is the special case where applied to the joint vs product of marginals.
Pinsker’s Inequality
Pinsker’s inequality provides a bridge between KL divergence and total variation — two divergences with very different structures.
Theorem 4 (Pinsker's Inequality).
or equivalently, .
The proof involves a careful comparison of the generator functions for TV and KL via a quadratic bound on near (see Cover & Thomas, Ch. 11, or Tsybakov, 2009). The bound is tight: equality is approached as and become close.
Pinsker’s inequality is practically important: total variation has a clean interpretation (maximum probability difference over events) but is hard to work with in optimization; KL divergence has a clean optimization theory (convexity, connections to MLE) but a less transparent geometric interpretation. Pinsker’s inequality lets us convert bounds between them.
Variational Representations
The variational representation of f-divergences is one of the most powerful results in modern information theory. It transforms divergence computation from a density ratio problem (requiring knowledge of and ) into an optimization problem (requiring only samples from and ).
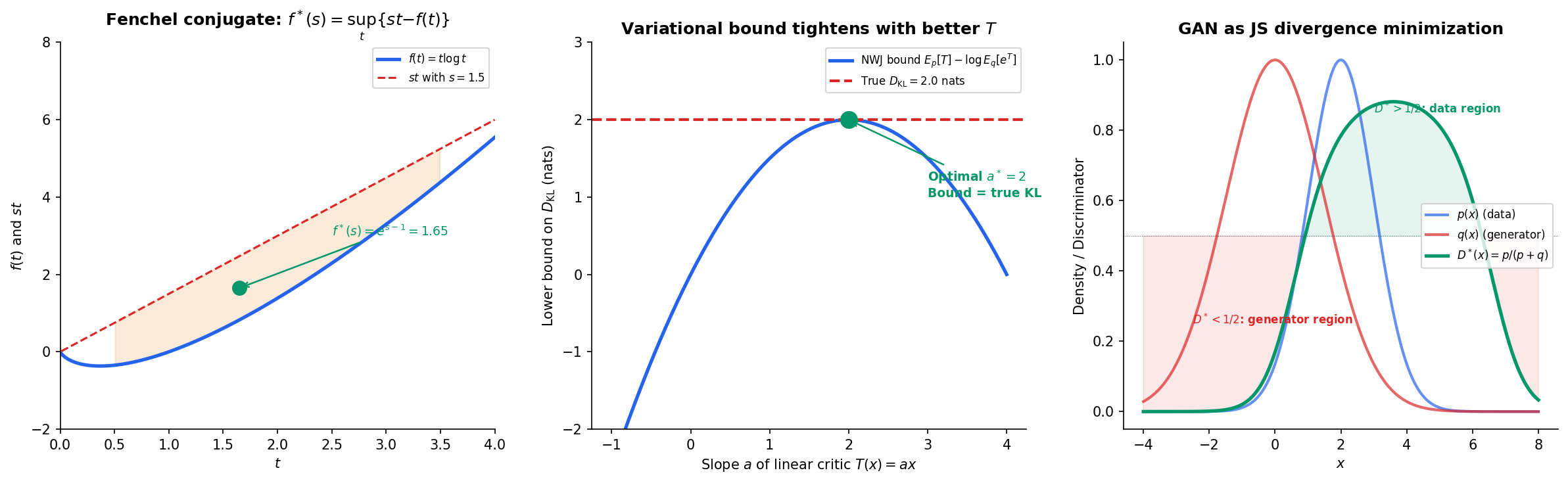
The key idea comes from Convex Analysis: every convex function can be represented as the supremum of affine functions via its Fenchel conjugate (also called the convex conjugate or Legendre transform):
Theorem 5 (Variational Representation of f-Divergences).
For any f-divergence with generator :
The supremum is attained at .
Proof.
By the Fenchel–Young inequality, for all (this is the definition of the conjugate). Therefore for any function :
This gives .
For the reverse inequality, set — the derivative of at the density ratio. The Fenchel–Young equality (holding when is differentiable) shows this achieves equality.
∎
Donsker–Varadhan and NWJ Bounds
For KL divergence specifically, gives , yielding:
Theorem 6 (Donsker–Varadhan Representation).
The supremum over all measurable functions is achieved at for any constant .
The Nguyen–Wainwright–Jordan (NWJ) bound is a related lower bound that replaces with , which is easier to optimize:
Connection to GANs
Remark (GAN as JS Minimization).
The original GAN objective (Goodfellow et al., 2014) is the variational representation of the Jensen–Shannon divergence. The discriminator plays the role of the variational function , and the optimal discriminator satisfies — the density ratio between real and generated distributions.
More generally, the f-GAN framework (Nowozin et al., 2016) shows that any f-divergence can serve as a GAN objective: train the generator to minimize and the discriminator to maximize the variational lower bound. The choice of determines the GAN’s training dynamics and mode-collapse behavior.
Rényi Divergence & -Divergences
The f-divergence family is parameterized by a function. Rényi divergences provide a complementary parameterization by a single scalar , interpolating between familiar divergences.
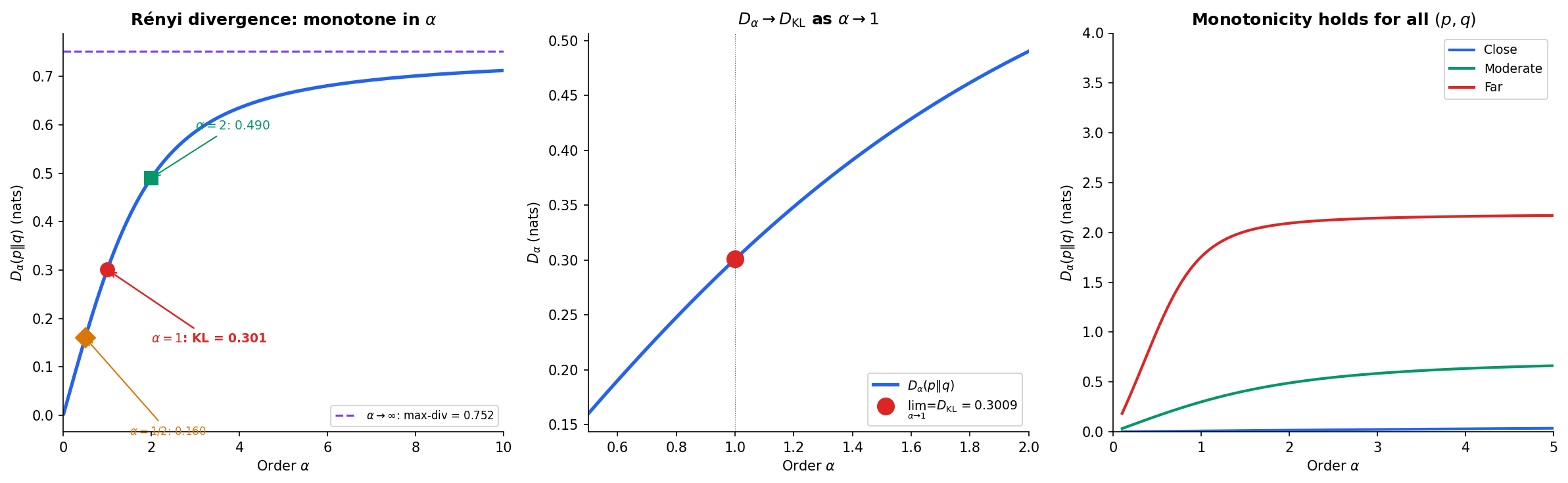
Definition 6 (Rényi Divergence).
The Rényi divergence of order , , from to is
with the convention that if and for some .
The Rényi family provides a continuous spectrum of divergences. As varies, we recover fundamental information-theoretic quantities:
- : — support divergence
- : — Bhattacharyya distance
- : — KL divergence (by L’Hôpital)
- : — related to divergence
- : — max-divergence
The convergence as is verified by L’Hôpital’s rule applied to the indeterminate form in the definition.
Theorem 7 (Monotonicity of Rényi Divergence).
For fixed distributions and , the map is non-decreasing on .
Proof.
Define , so . Taking the derivative and applying Hölder’s inequality shows . The key step uses the log-convexity of — a consequence of Hölder’s inequality applied to the sum with conjugate exponents and .
∎
This monotonicity has important consequences:
- Differential privacy: The -DP guarantee is controlled by the max-divergence (). Rényi DP (Mironov, 2017) uses finite to get tighter composition bounds, leveraging the monotonicity to relate different privacy definitions.
- Hypothesis testing: The Chernoff information, which governs the optimal Bayesian error exponent, is .
def renyi_divergence(p, q, alpha):
"""Rényi divergence D_alpha(p || q) in nats."""
p, q = np.asarray(p, float), np.asarray(q, float)
if abs(alpha - 1.0) < 1e-10:
# Limit: KL divergence in nats
mask = p > 0
if np.any(q[mask] <= 0):
return np.inf
return np.sum(p[mask] * np.log(p[mask] / q[mask]))
summand = np.sum(p ** alpha * q ** (1 - alpha))
if summand <= 0:
return np.inf
return np.log(summand) / (alpha - 1)
# Verify: D_alpha → D_KL as alpha → 1
p = np.array([0.7, 0.2, 0.1])
q = np.array([0.3, 0.4, 0.3])
alphas = [0.5, 0.9, 0.99, 0.999, 1.0, 1.001, 1.01, 1.1, 2.0]
for a in alphas:
print(f"D_{a:.3f}(p || q) = {renyi_divergence(p, q, a):.6f} nats")
# Observe smooth convergence to D_KL at α = 1Computational Notes
Plug-In Estimation from Samples
Given i.i.d. samples from and , the simplest KL estimator replaces the true distributions with empirical histograms:
This plug-in estimator is consistent but converges slowly — in general — and is biased in finite samples due to the nonlinearity of . For continuous distributions, binning introduces discretization error, and kernel-based or -NN estimators (Pérez-Cruz, 2008; Wang et al., 2009) are preferred.
Cross-Entropy Loss Decomposition
During training of a classifier with model and true distribution :
The entropy is the irreducible noise floor — we cannot reduce the loss below no matter how good the model. The KL divergence is the reducible component that training shrinks toward zero. For one-hot labels, and cross-entropy equals KL divergence.
ELBO as Reverse KL
The evidence lower bound (ELBO) in variational inference decomposes as:
Since is fixed, maximizing the ELBO is equivalent to minimizing the reverse KL to the posterior. The gap between and the ELBO is exactly the reverse KL divergence — a direct measure of how well the approximate posterior fits the true posterior.
Practical Implementations
from scipy.special import rel_entr
import torch
import torch.nn.functional as F
# SciPy: KL divergence via relative entropy
# rel_entr(p, q) returns p * log(p/q) elementwise (in nats)
p = np.array([0.4, 0.35, 0.15, 0.1])
q = np.array([0.25, 0.25, 0.25, 0.25])
kl_nats = np.sum(rel_entr(p, q)) # D_KL in nats
# PyTorch: cross-entropy loss (forward KL for one-hot labels)
logits = torch.tensor([2.0, 1.0, 0.5, -0.5])
target = torch.tensor(0) # one-hot: class 0
ce_loss = F.cross_entropy(logits, target) # -log(softmax(logits)[0])
# PyTorch: KL divergence (expects log-probabilities for input)
log_q = F.log_softmax(logits, dim=0)
p_tensor = torch.tensor([0.4, 0.35, 0.15, 0.1])
kl = F.kl_div(log_q, p_tensor, reduction='sum') # D_KL(p || q) in nats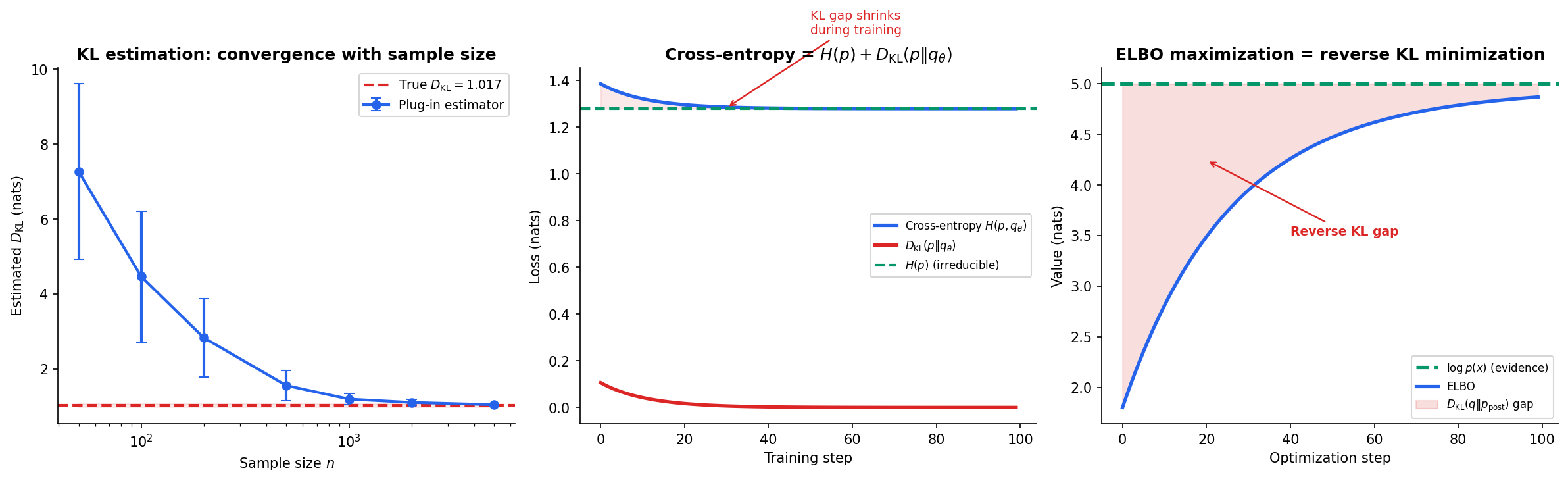
Connections & Further Reading
KL divergence and its generalizations connect information theory to optimization, geometry, and learning theory. This topic sits at the intersection of several curriculum tracks:
-
Shannon Entropy & Mutual Information (Information Theory) — KL divergence decomposes as . Mutual information . The data processing inequality for mutual information is a special case of the f-divergence DPI.
-
Information Geometry & Fisher Metric (Differential Geometry) — The Fisher information matrix is the Hessian of KL divergence at . The dual - and -connections arise from the asymmetry of KL. The -connections generalize via Rényi divergences.
-
Convex Analysis (Optimization) — f-divergences are defined through convex generators; the Fenchel conjugate yields the variational representation; joint convexity makes divergence minimization a convex program.
-
Measure-Theoretic Probability (Probability & Statistics) — Continuous KL requires the Radon–Nikodym derivative. Absolute continuity () is necessary for finite KL divergence.
Downstream on this track
- Rate-Distortion Theory — the minimum rate for encoding a source at distortion level is an optimization over mutual information — itself a KL divergence — subject to a distortion constraint. The Blahut–Arimoto algorithm iteratively minimizes KL divergence to compute .
- Minimum Description Length — model selection via code length: the regret of a universal code is bounded by the KL divergence between the true and estimated distributions. The minimax regret connects to the capacity of the model class.
Notation Reference
- — KL divergence from to
- — Cross-entropy from to
- — f-divergence with generator
- — Fenchel conjugate of
- — Total variation distance
- — Jensen–Shannon divergence
- — Rényi divergence of order
Connections
- KL divergence decomposes as D_KL(p || q) = H(p, q) - H(p): the excess bits from using code q instead of p. Mutual information is the KL divergence from the joint to the product of marginals. shannon-entropy
- The Fisher information metric is the Hessian of KL divergence at p = q. KL divergence induces the dual affine connection structure (e- and m-connections) on statistical manifolds, and the α-connections generalize via Rényi divergences. information-geometry
- f-divergences are defined through convex generator functions. The Fenchel conjugate f* yields the variational representation. Joint convexity of D_f in (p, q) makes divergence minimization a convex program. convex-analysis
- Continuous KL divergence requires the Radon–Nikodym derivative: D_KL(P || Q) = integral (dP/dQ) log(dP/dQ) dQ. Absolute continuity (P << Q) is necessary for finite KL divergence. measure-theoretic-probability
References & Further Reading
- book Elements of Information Theory — Cover & Thomas (2006) Chapter 2 — KL divergence, Gibbs' inequality, data processing inequality, Pinsker's inequality
- book On Divergences and Informations in Statistics and Information Theory — Liese & Vajda (2006) Comprehensive treatment of f-divergence theory, variational representations, and statistical applications
- paper A General Class of Coefficients of Divergence of One Distribution from Another — Ali & Silvey (1966) Original introduction of f-divergences (with Csiszár independently in 1967)
- paper Estimating Divergence Functionals and the Likelihood Ratio by Convex Risk Minimization — Nguyen, Wainwright & Jordan (2010) Variational divergence estimation — the NWJ bound used in modern density ratio estimation
- paper f-GAN: Training Generative Neural Samplers using Variational Divergence Minimization — Nowozin, Cseke & Tomioka (2016) f-GAN framework — unifies GAN training objectives as variational f-divergence minimization
- paper On Measures of Entropy and Information — Rényi (1961) Rényi divergence definition and the monotonicity property in the order parameter
- book Information Geometry and Its Applications — Amari (2016) Chapters 3–4 — dual geometry of KL divergence, α-connections, and the dually flat structure