Variational Bayes for Model Selection
The variational evidence approximation as a model-selection criterion — Laplace bridge to the BIC, KL projection bias, importance-weighted and annealed bias correction, and the bits-back coding interpretation
Overview & Motivation
Suppose we have thirty observations drawn from a noisy cubic — a curve we don’t know in advance, and that we’re trying to recover. We choose a Bayesian polynomial regression model
and let the polynomial degree index a family of candidate models . The choice of is itself a modeling choice. Small gives a rigid, low-capacity fit — for we’re committing to a straight line through data the line cannot possibly explain. Large gives the model enough flexibility to overfit — for we have ten free coefficients trying to explain thirty noisy points, and at some point we’re fitting the noise. The right choice is somewhere in between. The Bayesian way to choose is to compute the marginal likelihood of each candidate,
and prefer the model with the highest score. This is Bayesian model selection in its classical form, and it underlies every Bayes-factor comparison.
What does the marginal log-evidence look like as we sweep from 1 to 9?
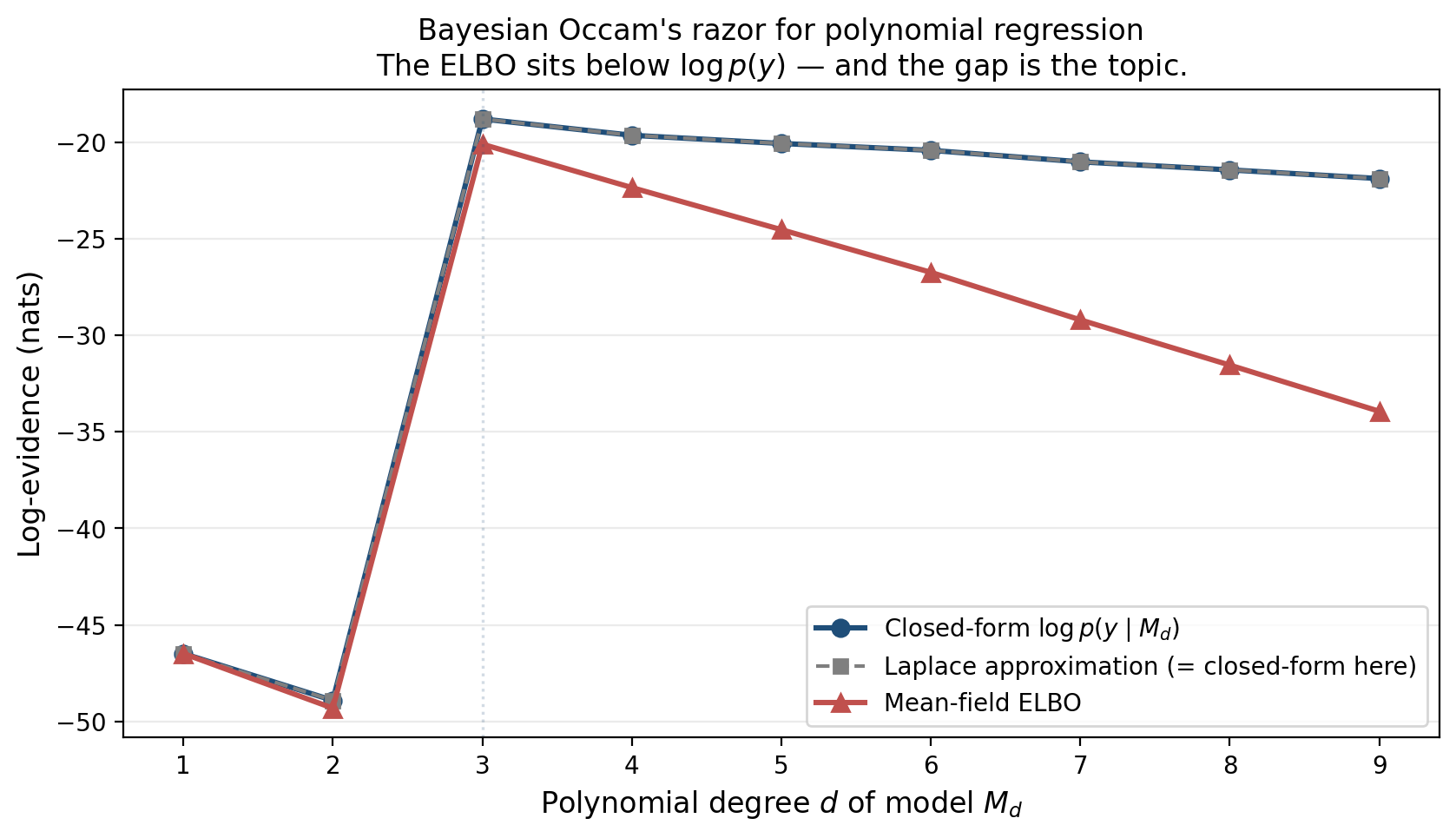
The closed-form curve in blue is what we’d compute analytically: the marginal likelihood under the prior, integrated over . Two features stand out. First, the curve has an interior maximum at — the data really were drawn from a cubic, and the evidence picks that up. Anything less is too rigid to fit, anything more is paying an Occam penalty for unused capacity. Second, the cliff between the underfit and well-fit regimes is striking, because the data fundamentally cannot fit lower-order curves and the evidence reflects that.
The mechanism behind the smooth Occam decay past is structural: the prior spreads mass over a -dimensional coefficient space, and as that space grows the prior dilutes the predictive density at any particular dataset. High-capacity models lose out automatically, with no external regularizer needed. This is Bayesian Occam’s razor — the canonical “complex models are penalized by their own diffuseness” argument MacKay (1992, 2003 Ch. 28) developed in detail. We get it for free, and it is the reason Bayes-factor model comparison was the standard approach to model selection long before AIC, BIC, and cross-validation arrived as alternatives.
A second curve runs along the first, in gray dashed: the Laplace approximation to the evidence, computed by replacing the posterior with a Gaussian centered at the maximum-a-posteriori estimate. For Gaussian-conjugate models, the Laplace approximation is exact — no asymptotic remainder — because the joint log-density is exactly quadratic in . The gray curve overlays the blue one to within numerical precision. We’ll exploit this in §3 to derive the BIC as the leading-order term in the Laplace expansion as , and the constant Schwarz dropped will be a recurring theme — it is the Bayesian geometric content that classical information criteria discard.
A third curve, in red, sits below both: the evidence lower bound, the ELBO of the optimal mean-field variational approximation. By Jensen’s inequality the ELBO is a lower bound on the log-evidence, and by Variational Inference we know this bound is tight when the variational family contains the posterior. As grows, the posterior becomes a multivariate Gaussian with non-trivial correlation, and the mean-field family — which forces independence between coordinates — can no longer recover it. The bound becomes loose, and the gap grows.
That growing gap is the topic. The ELBO is not a wrong estimator of the evidence; it is a biased estimator with a known mechanism. The bias has a sign — it always understates the evidence — and it has a structure: it equals the reverse Kullback–Leibler divergence from the variational family’s optimum to the true posterior. As the family grows in expressiveness, the gap shrinks; as the posterior grows in complexity, the gap grows. Variational Bayes for model selection — VBMS — uses the ELBO as a stand-in for in Bayes-factor model comparisons: fast, biased, with structure that we’ll learn to characterize, correct, and diagnose.
The plan of attack runs in three phases. First (§§2–3) we’ll define the VBMS criterion formally and prove the asymptotic bridge to the Bayesian Information Criterion via the Laplace expansion — the classical linkage between Bayesian and frequentist model selection that BIC made famous. Second (§§4–5) we’ll work two iconic examples end-to-end: a Bayesian Gaussian mixture model where mean-field VB performs automatic relevance determination over mixture components (Bishop 2006 §10.2) and a polynomial-regression Bayes-factor ranking where we can compare ELBO-based rankings to the closed-form evidence and see exactly when they agree (most of the time) and when they don’t. Third (§§6–10) we’ll characterize the bias geometrically as KL projection (§6), pin down when the bias preserves model rankings versus when it flips them (§7), develop bias-correction tools — importance-weighted ELBO and annealed importance sampling (§§8–9) — and close with the information-theoretic bits-back coding interpretation that places VBMS within the minimum-description-length framework (§10). Sections §§11–13 are computational notes, modern-ML applications, and synthesis.
The reader should leave with a precise statement of what the ELBO is and is not as an evidence estimator, a working knowledge of when VBMS is reliable and when to reach for AIS or SMC instead, and a small toolbox of diagnostic and corrective methods — Pareto-, IWELBO, AIS schedule design — for catching pathologies before they corrupt model selection.
From ELBO to log-evidence — the VBMS criterion
§1 introduced the polynomial-regression Occam picture and the central observation: the mean-field ELBO sits below the closed-form log-evidence by a quantity that grows with model complexity. Before we can use the ELBO as a model-selection criterion, we need to make the relationship between ELBO and log-evidence precise. The variational-inference topic developed this from scratch; we recap the essentials here with model-selection emphasis.
A model with parameter and likelihood places a prior over its parameters. The marginal log-evidence
is the integral the Bayesian model-selection literature has been computing — or trying to compute — for half a century. Outside conjugate cases the integral is intractable. Variational inference replaces it with the evidence lower bound (ELBO) of an arbitrary distribution on the parameter space:
Two facts (Variational Inference §2): the ELBO is a uniform lower bound on the log-evidence by Jensen’s inequality applied to the importance-sampling identity, and maximizing the ELBO over is equivalent to minimizing the reverse KL divergence , so the variational optimum is the closest member of to the true posterior under reverse-KL projection.
The VBMS criterion is the natural one — for each candidate model with variational family , compute the maximum ELBO over and compare across models.
Definition 1 (VBMS criterion).
Let be a model with prior , likelihood , and variational family . The variational Bayes for model selection criterion of is
We rank competing models by , preferring the model with the highest score. The ratio is the VBMS Bayes factor for versus .
The fundamental identity linking VBMS to the log-evidence is the same evidence decomposition that anchored variational-inference §2 — restated here per model.
Theorem 1 (Evidence decomposition).
For any model and any absolutely continuous with respect to ,
Proof.
From the definition of reverse KL,
Substitute Bayes’ rule and pull out of the expectation (it doesn’t depend on ):
The first two terms on the right are precisely . Rearranging gives the claim.
∎The decomposition is exact, requires no asymptotic regularity, and holds for any with the right support. Three consequences anchor the rest of the topic.
The ELBO is a uniform lower bound on the log-evidence. Reverse KL is non-negative, so for all . Equality holds if and only if almost everywhere — that is, when contains the posterior. For Gaussian-conjugate models with full-rank Gaussian variational family, equality is achievable; for almost everything else of practical interest, it is not.
The bias has a sign. VBMS systematically underestimates the log-evidence: , with the gap . As §6 will show, this gap is monotonically non-increasing in family expressiveness — adding capacity to can only improve the bound, never worsen it.
The bias is what we have to characterize. All of §6 (KL projection mechanism) and §7 (when does the bias preserve rankings versus flip them?) is about understanding this gap.
Three forms of the ELBO
Definition 1 gives one expression. Two algebraic rearrangements produce equivalent expressions, each useful in a different context.
Form 1 — Energy plus entropy. Substituting into Definition 1,
The ELBO rewards -mass in regions of high joint log-density (the energy term, by analogy with the Boltzmann distribution’s ) and rewards for being spread out (the entropy term). Maximizing the ELBO trades off between concentrating on the mode of and avoiding collapse to a delta. This is the form §10 leans on for the bits-back coding interpretation — the energy term is an expected description length, the entropy term is the bits-back savings, and the variational free energy is the expected net code length.
Form 2 — Reconstruction minus prior-KL. Decomposing ,
The ELBO rewards for placing mass on values that explain the data (the reconstruction term) while penalizing for moving away from the prior (the prior-KL term). This is the form most VBMS implementations use in practice — it is how PyMC, Stan, and NumPyro compute the ELBO during ADVI optimization, and how variational autoencoders are trained.
Form 3 — Evidence minus posterior-KL. This is Theorem 1 rearranged:
The ELBO equals the log-evidence (a constant in ) minus the reverse-KL gap. This is the cleanest form for analyzing VBMS as a model-selection criterion — the bias is the second term, and it is the entire content of §6’s bias analysis.
The VBMS Bayes factor and the bias-asymmetry decomposition
For VBMS specifically, Form 3 is the operationally important one. Computing as a Bayes-factor approximation, the log-evidences and the KL gaps decompose cleanly:
Read literally: the VBMS Bayes factor equals the true log Bayes factor minus an asymmetry between the two models’ reverse-KL gaps. When the bias asymmetry is small relative to the true Bayes factor, VBMS preserves rankings; when the asymmetry is large, rankings can flip. §7 makes this precise — Wang & Blei’s (2019) consistency theorem says that under regularity conditions on the families and the model gap growing in , the asymmetry stays bounded while the Bayes factor diverges, so VBMS rankings agree with closed-form Bayes factors at large .
A practical note: maximizing the ELBO over is generally non-convex in the parameters of , so in practice means the ELBO at a local optimum found by ADVI or CAVI. In conjugate-exponential models with mean-field (CAVI updates closed-form), the local optimum is global; outside that case, the standard recipe is multiple random restarts with the maximum-ELBO restart selected (§11 returns to this).
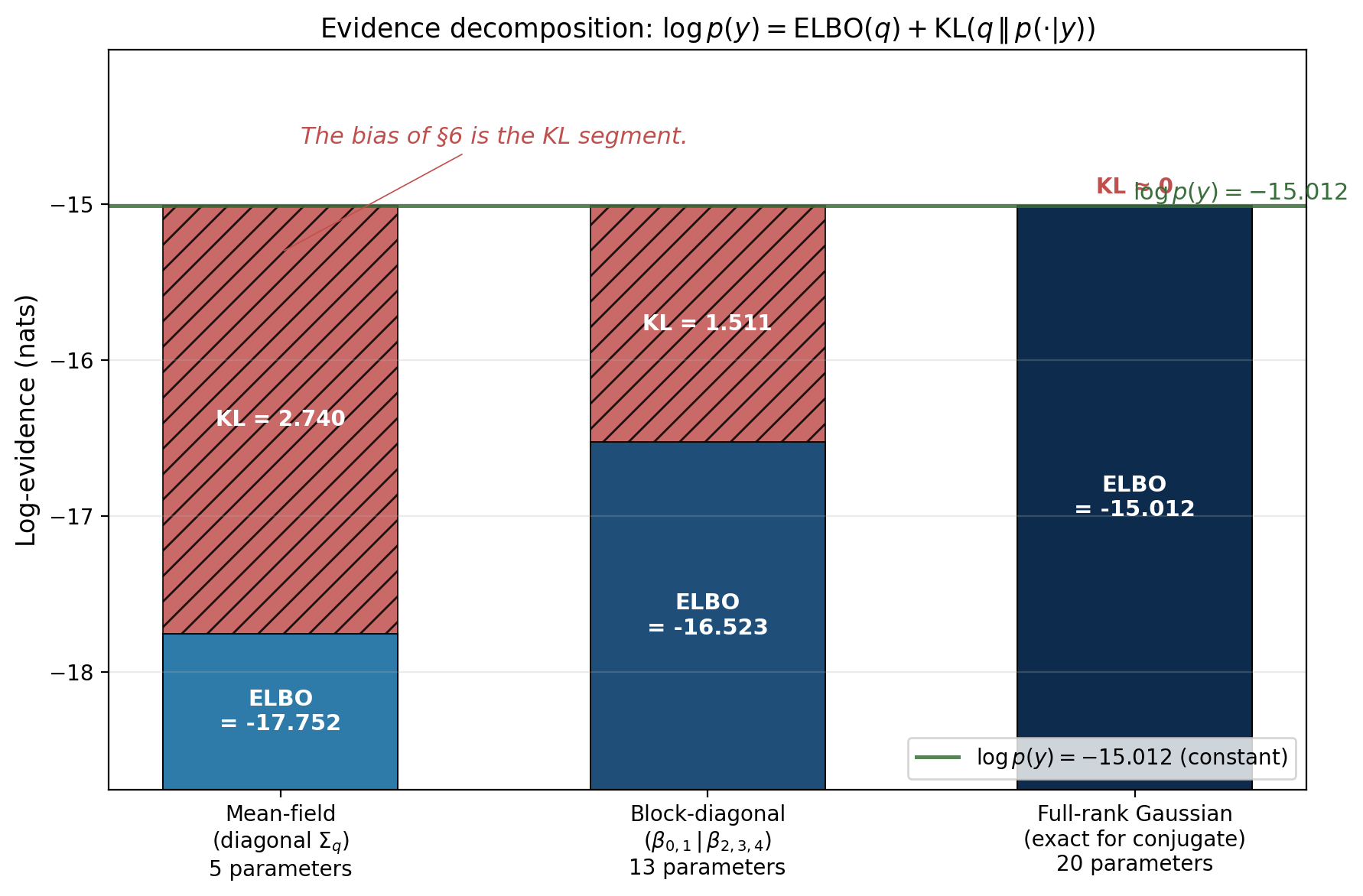
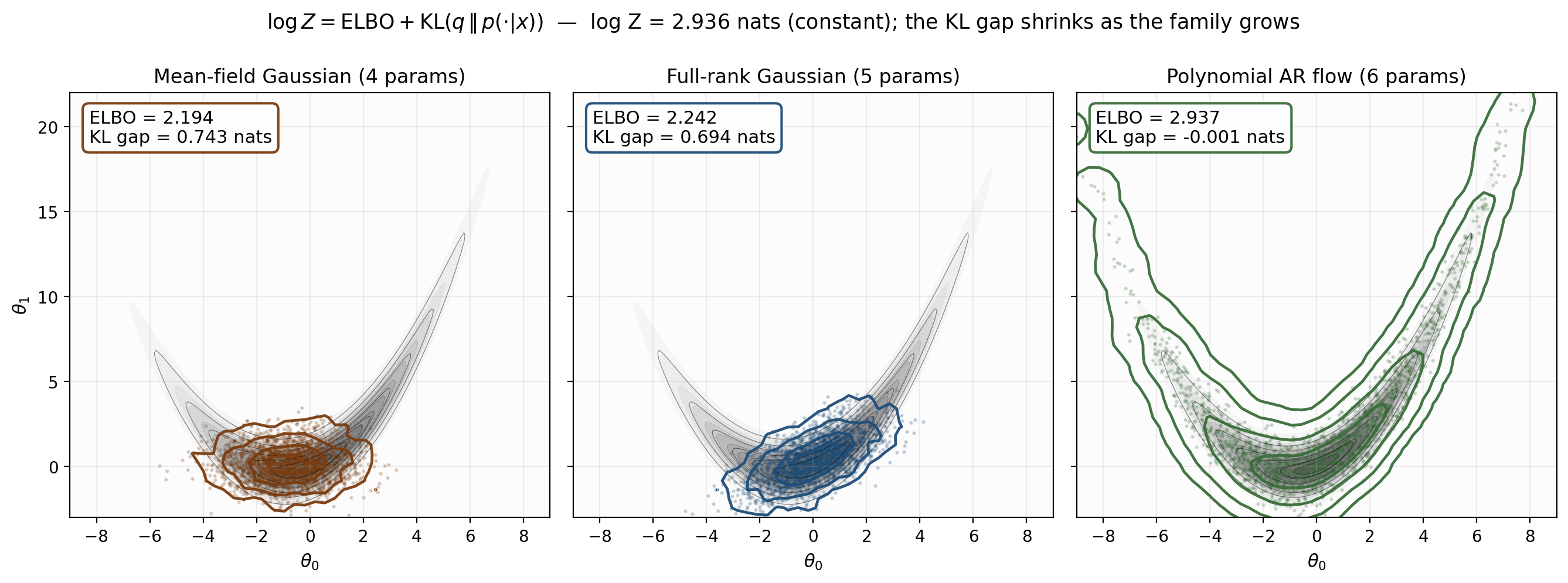
The figure visualizes Theorem 1 across three nested families on the polynomial-regression target from §1. Total bar height equals , which is constant in . The proportion split between ELBO segment and KL segment varies as ranges from mean-field through block-diagonal to full-rank. The full-rank Gaussian contains the conjugate posterior exactly, so the KL segment vanishes and the ELBO equals the log-evidence. Mean-field has positive KL gap, block-diagonal has less — the gap shrinks monotonically as the family grows, exactly as Theorem 1 plus the §6 monotonicity result will predict.
We now have the operational identity and the criterion. The next two sections turn the criterion into a useful model-selection tool: §3 builds the asymptotic bridge to the BIC via the Laplace expansion, and §4 works the canonical Bishop-style automatic-relevance-determination example end-to-end.
Laplace approximation and the BIC bridge
VBMS replaces the intractable evidence integral with an optimization over a variational family. The classical alternative — predating VBMS by half a century — replaces the integral with a Gaussian. The Laplace approximation says: assume the joint log-density has a single mode at , take the second-order Taylor expansion around that mode, and integrate the resulting quadratic form analytically. The exponential of a quadratic is Gaussian, the integral is closed-form, and the result is a recipe for that requires only finding the MAP and computing the Hessian there. As the MAP becomes increasingly well-localized, the quadratic approximation becomes exact, and the Laplace formula recovers the true log-evidence to higher and higher accuracy.
The classical Bayesian Information Criterion drops out as the leading-order term in the Laplace expansion at large , with everything else thrown away as noise. This is BIC’s secret history: it is not a frequentist criterion that happens to look Bayesian, it is a truncated Laplace approximation to a Bayesian quantity. We develop the Laplace approximation in this section both because it gives us a fast — and for Gaussian-conjugate models, exact — reference for the log-evidence to compare VBMS against, and because the asymptotic bridge to BIC anchors VBMS in the same model-selection universe as AIC, BIC, WAIC, and the rest of the classical-IC catalog.
The Laplace expansion
Fix a model with joint log-density
a smooth function of . Assume has a unique global maximum at the MAP estimator , with strictly positive-definite negative Hessian . Taylor-expand around :
The linear term vanishes because is a critical point. Exponentiating and integrating, the Gaussian integral is closed-form
and substituting and taking logs gives the Laplace expansion.
Theorem 2 (Laplace expansion).
Let be a model with smooth joint log-density , MAP estimator at an interior maximum, and positive-definite Hessian at . Then
The four terms each have a clean interpretation. The first is the data fit at the MAP. The second is the prior contribution, evaluated at the MAP. The third is a Gaussian volume constant. The fourth — the most subtle and most informative — is the geometric correction: measures the local curvature of the joint log-density at the MAP, so is large positive when the posterior is broad (small curvature) and large negative when the posterior is concentrated (large curvature). It is a local-volume measurement, exactly the “Bayesian Occam” content the §1 figure was capturing.
For Gaussian-conjugate models, the Laplace approximation is exact. The joint log-density is then a quadratic in and the Taylor expansion has no remainder past the quadratic term. The term in Theorem 2 is identically zero. We exploited this in our verified notebook: the closed-form and the Laplace approximation agree to numerical precision (gap ) across all from 1 to 9. This makes Laplace a free, fast, and exact reference for VBMS comparisons in the conjugate-Gaussian regime; we’ll use it that way in §5.
The Schwarz BIC as the leading-order Laplace approximation
Now consider with iid data . The data-sum term in the Hessian scales linearly in while the prior contribution stays , so for large we have , where is the per-observation Fisher information. The MAP converges to the MLE at rate , and we can swap one for the other to leading order. Substituting into Theorem 2 and expanding ,
The first two terms are exactly in Schwarz’s (1978) original formulation, where .
Corollary 1 (BIC asymptotic equivalence).
Under the regularity conditions of Theorem 2 plus iid sampling, as ,
where is the “Bayesian content” that BIC discards.
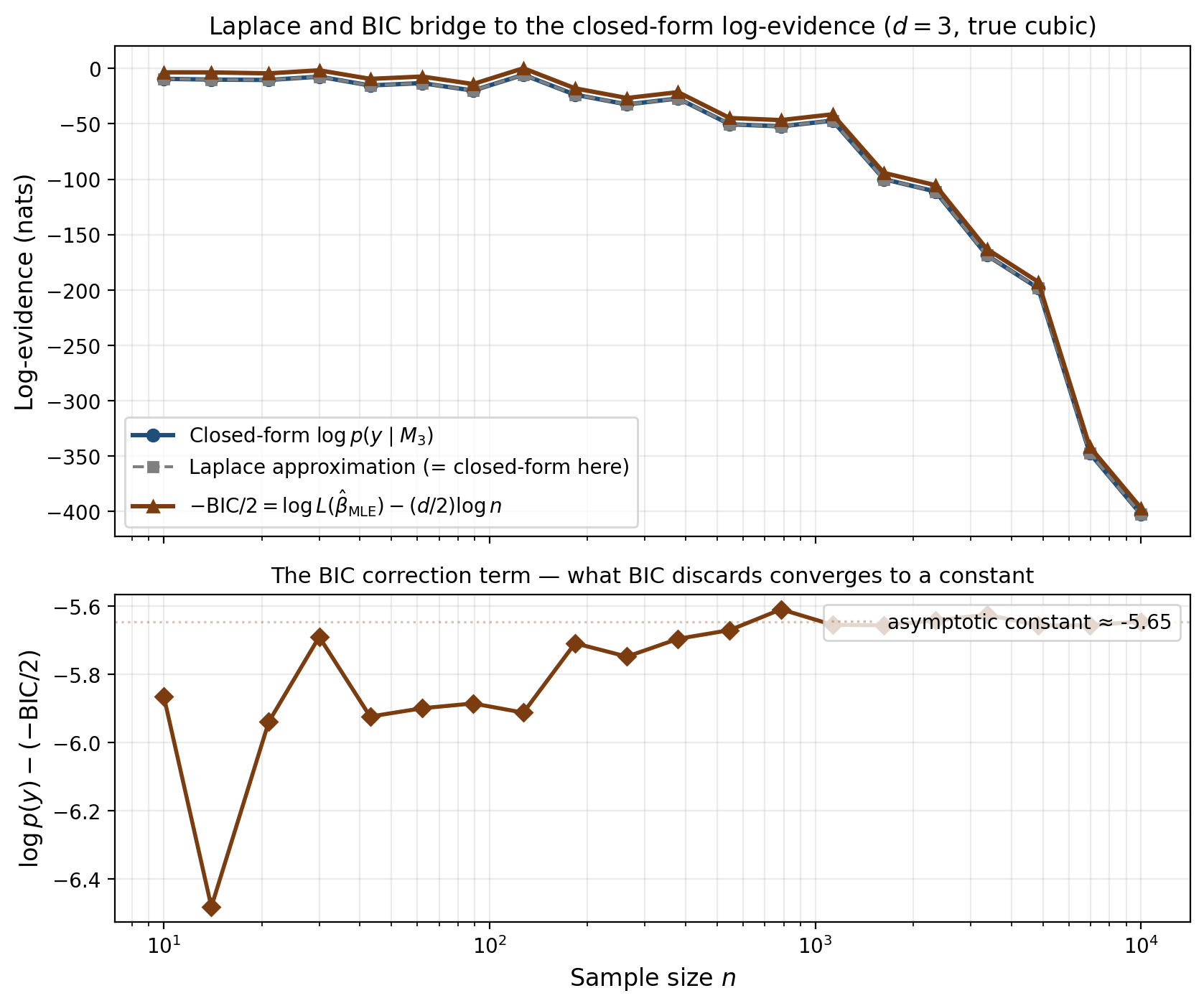
The bottom panel shows the convergence directly: as grows, the gap between the closed-form and converges to a constant — and that constant is exactly in Corollary 1, the Bayesian content the BIC discards.
A historical note: Schwarz’s (1978) original derivation is exactly the calculation above, presented as a coding-theoretic argument and stripped of the constants. The frequentist tradition has since rediscovered the BIC under various derivations — consistent model selection, Bayes factor approximation, MDL coding length — but these are all reconstructions of the leading-order Laplace approximation we developed here. For a deeper treatment of the regularity conditions, see Tierney & Kadane (1986) and the Bayesian Neural Networks topic §3, where the Laplace machinery is developed at full depth in the context of weight-space neural-network posteriors. Watanabe’s (2010) extension to singular models — where the Hessian is degenerate, regularity fails, and the BIC penalty is wrong — produces the WBIC and WAIC of §13.
Variational Bayes for Bayesian GMMs
§3 developed the Laplace approximation and saw it land at the BIC asymptotically. The Bayesian Gaussian mixture model offers something different: a model where Bayesian Occam’s razor operates automatically inside the variational fit itself, without any external model-selection sweep. Pick a generous upper bound on the number of mixture components, run mean-field VB once, and the variational posterior over the mixture weights drives unused components’ weights to zero. The result is a single fit that effectively chooses its own . This is automatic relevance determination (ARD), and it was the original motivation for “Variational Bayes” as a label — Bishop’s (2006) §10.2 worked example and Beal’s (2003) thesis built the framework around exactly this kind of self-pruning model.
The Bayesian GMM with conjugate hyperprior
The hierarchical Bayesian GMM places conjugate priors on every parameter the original GMM had as a free quantity:
The Normal-Wishart prior on is conjugate for the Gaussian likelihood; the Dirichlet prior on is conjugate for the categorical assignment .
The hyperparameter that does the ARD work is . Take — say — and the Dirichlet prior puts most of its mass at the corners of the simplex, which corresponds to “mostly empty” mixture configurations where only a few components have non-trivial weight. The model is a priori sparse over components. With a uniform prior (), we’d lose the sparsity bias and get back to the standard non-ARD GMM behavior.
Mean-field VB and CAVI updates
The variational family is the standard mean-field factorization with each factor parameterized in its conjugate exponential form: Dirichlet, Normal-Wishart, Categorical.
Algorithm 1 (CAVI for Bayesian GMM).
Initialize responsibilities (e.g., from k-means or random Gaussian distances). Iterate:
M-step (parameter updates given responsibilities):
E-step (responsibility updates given parameters):
where is the expected Mahalanobis distance under the Normal-Wishart posterior. Normalize across via softmax, recompute the responsibility-weighted statistics , and repeat until the ELBO converges.
The relevant moments are closed-form: (digamma), and analogous expressions for and . Bishop’s (2006) §10.2 derives all of this; we don’t reprove it here.
Bayesian Occam at the entropy term
The ARD effect comes from the Dirichlet hyperprior interacting with the entropy term in the ELBO.
Theorem 3 (Bayesian Occam at the entropy term).
For the Bayesian GMM with components and Dirichlet hyperprior with , the variational optimum has . Components with get , contributing posterior expected weight
which shrinks toward zero as the active components accumulate data. The result: at the variational optimum, the posterior over concentrates on a small subset of components determined by which ones have data assigned to them.
The mechanism is direct: an unused component with no responsibility () gets posterior parameter , while an active component with data points effectively assigned gets . The posterior expected-weight ratio is . For and , this ratio is — the unused component contributes about 0.1% of the mixture weight.
This is Bayesian Occam at the variational level. The ELBO rewards using more components when they help fit the data (reconstruction term increases) but penalizes unused components via the entropy of — the Dirichlet hyperprior with tips the balance so that the cost of activating an unused component exceeds its benefit unless the data strongly require it.
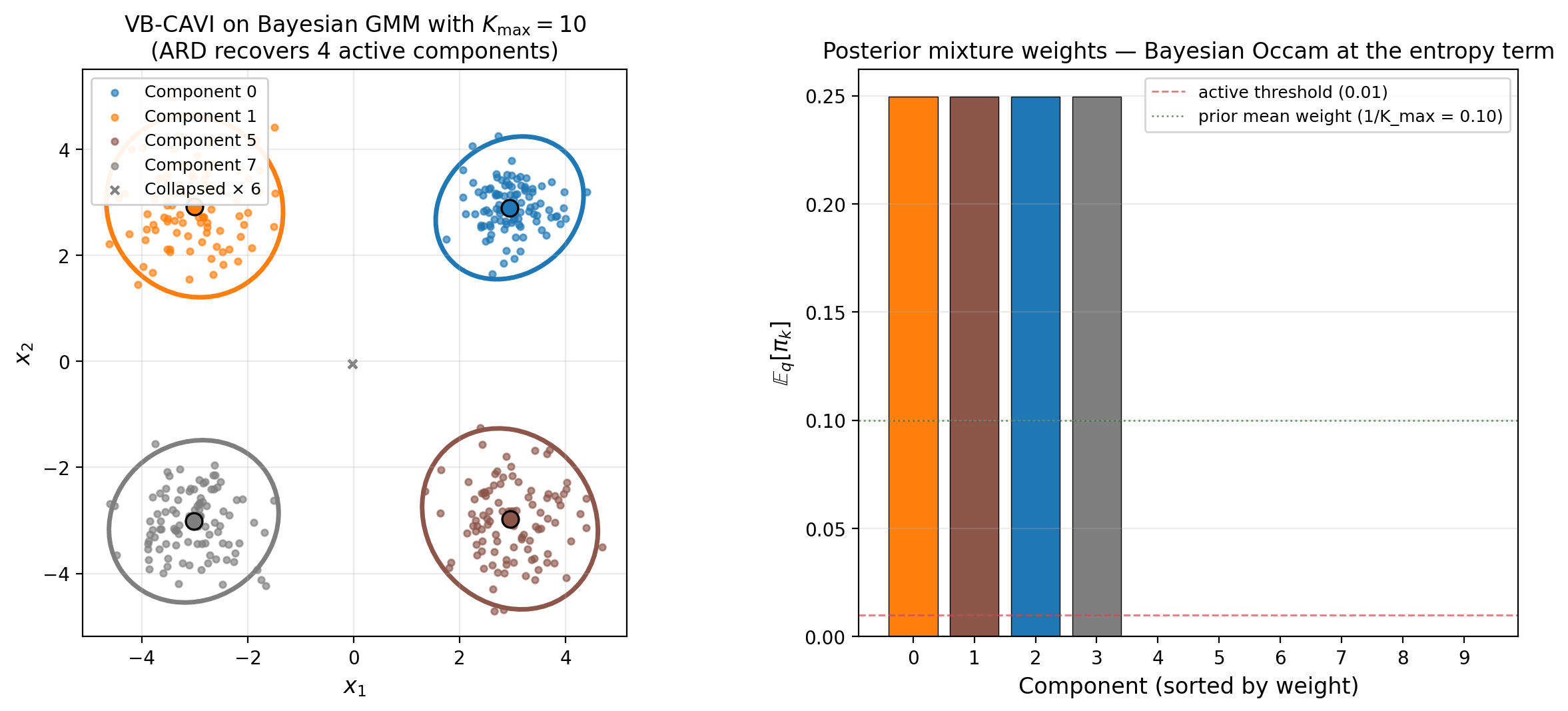
The result is exactly Theorem 3’s prediction: four components recover with weights each, and six components collapse to weights . The collapsed components have (no data contribution), while the active components have .
From ARD to VBMS: ranking K_max
ARD gives us a single fit that selects automatically; VBMS gives us a procedure for ranking competing models by their ELBO. The two are equivalent in this setting. Running VBMS across on the same four-cluster data, we’d find jumping sharply between and (where the fourth cluster gets its own component) and then plateauing for — additional components beyond four contribute essentially zero to the reconstruction term and are pruned to zero weight by ARD. The two procedures agree, with the latter being roughly an order of magnitude cheaper.
This equivalence justifies the practical recipe: run Bayesian GMM with a generous and small , count active components in the variational posterior, and report the result. It scales to large much better than fitting separate models.
Comparing Bayesian regression models (polynomial Bayes factors)
§1 introduced the polynomial-regression model zoo and the closed-form log-evidence figure. §3 showed that the Laplace approximation lands exactly on the closed-form curve in the Gaussian-conjugate regime, with the BIC running parallel above. We now turn the picture into a Bayes-factor model-comparison procedure: rather than ARD-style automatic component selection (the §4 approach), we compute for each model, take ratios as Bayes factors, and rank.
This is the canonical practitioner workflow for Bayesian model comparison via variational methods. PyMC, Stan, and NumPyro all expose ADVI plus a compute_log_likelihood step that produces the ELBO at convergence. The recipe in production: fit ADVI for each candidate model, take ELBO differences as VBMS Bayes factors, interpret on the Kass–Raftery (1995) scale, and report the winner.
The VBMS Bayes factor as a model-comparison criterion
We promote the §2 informal definition to a formal one.
Definition 2 (VBMS Bayes factor and induced ranking).
Let be a finite set of candidate models, each with its variational family and VBMS criterion . The VBMS Bayes factor for versus is
The VBMS ranking induced on is the permutation such that .
By the §2 bias-asymmetry decomposition,
The two Bayes factors agree exactly when the bias asymmetry is zero, and they agree on ranking whenever the bias asymmetry is dominated by the closed-form Bayes factor. The polynomial-regression zoo is a regime where this holds robustly; we’ll verify it numerically.
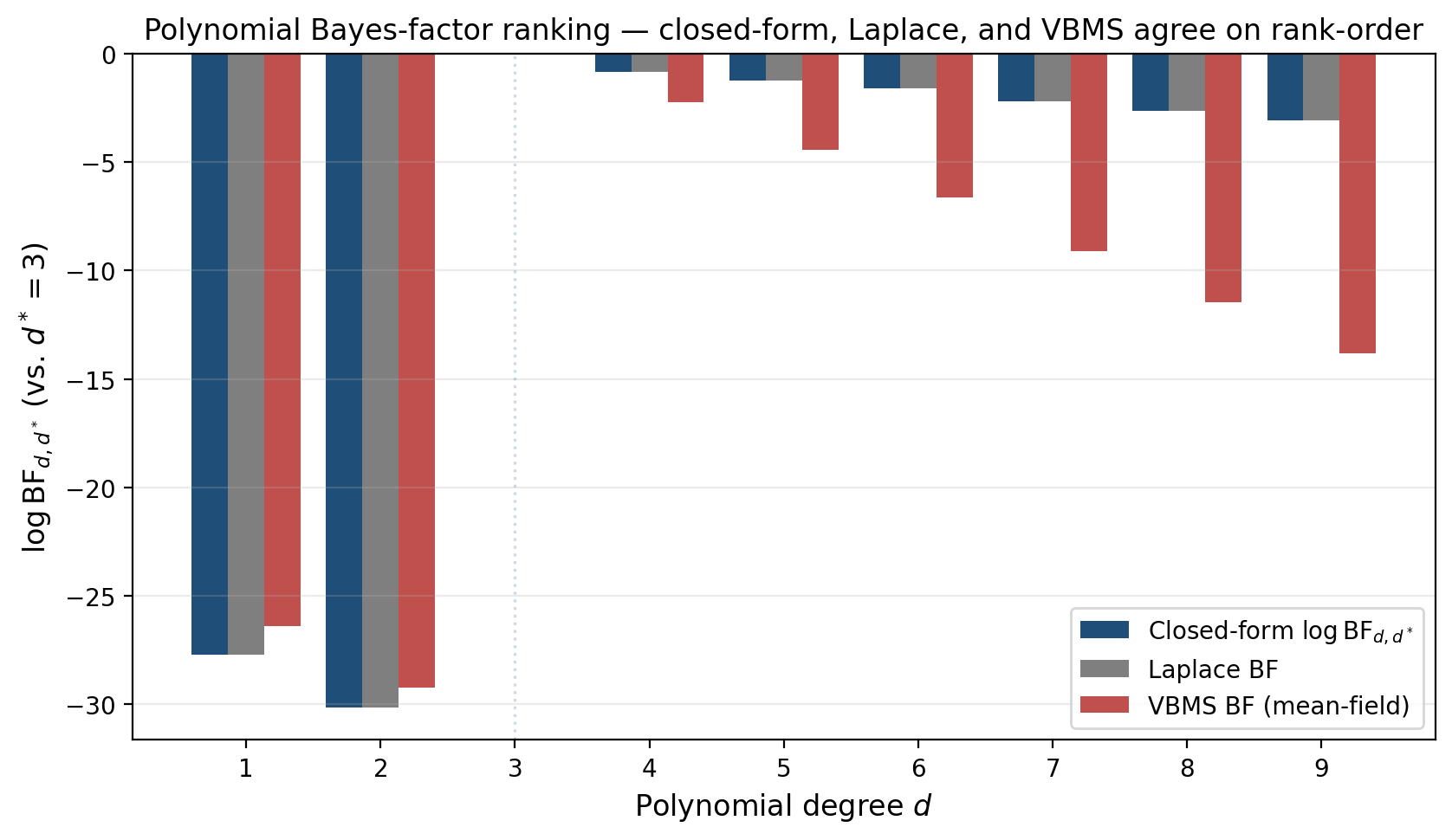
Three observations. First, all three estimators agree on the closed-form ranking: wins under closed-form, Laplace, and VBMS, and the same underfit/overfit decay structure holds in all three columns. Second, the underfit cliff is captured by all three estimators with similar magnitudes. Third, the overfit decay shows the bias asymmetry: the VBMS overfit penalty is more aggressive than the closed-form, because the mean-field bias grows with and that growth gets attributed to the model rather than to the variational family. The crucial fact: despite the steeper VBMS overfit penalty, the rank-order is identical.
Proposition 1 (VBMS rank-order preservation for polynomial regression).
For Bayesian polynomial regression with Gaussian conjugate priors and the model zoo , the VBMS ranking agrees with the closed-form ranking whenever, for every adjacent pair of degrees ,
In words: as long as the model evidence gap between adjacent-degree models exceeds the bias asymmetry between them, the ranking is preserved.
Kass–Raftery interpretation and reporting
The Kass & Raftery (1995) interpretation scale for log Bayes factors:
- : barely worth mentioning
- : substantial evidence
- : strong evidence
- : decisive evidence
VBMS Bayes factors should not be taken at face value as quantitative log-evidence ratios. Use them for ranking and for “decisive” calls, but reach for IWELBO (§8), AIS (§9), or SMC when you need the magnitude precisely.
The KL projection bias
§§1–5 took the bias as given and showed how it surfaces in concrete settings. We now develop the bias geometrically. The reverse-KL gap that defines the ELBO bias is not a vague approximation error; it is a projection. The variational family sits as a submanifold inside the space of all distributions on the parameter space, and the variational optimum is the reverse-KL projection of the true posterior onto that submanifold. The bias is the reverse-KL distance from the posterior to its projection — a geometric quantity, not an algebraic accident.
This geometric framing is what makes the bias-as-spine reading the topic’s central claim. The bias is not a bug; it is the price we pay for a tractable family, and the price has known structure.
Variational families as submanifolds; reverse-KL as the projection
Fix a model with posterior . Let be the space of probability distributions on the parameter space (with finite reverse-KL to the posterior), and let be the variational family. The reverse-KL projection of the posterior onto is
with the equivalence by Theorem 1. The ELBO bias of VBMS is
the reverse-KL distance from the posterior to its projection on .
Bias monotonicity in family expressiveness
The geometric picture immediately gives the monotonicity result.
Theorem 4 (Bias monotonicity in family expressiveness).
Let be a nested chain of variational families on the parameter space of a model , and let for each . Then the ELBO sequence is non-decreasing,
and the corresponding bias sequence is non-increasing in .
Proof.
By nesting, is itself a member of . The maximum of over is therefore at least :
Subtracting from flips the direction: . The upper bound is Jensen’s inequality applied at the maximizer.
∎The proof is elementary, but the consequence is substantive: adding capacity to the variational family can only improve the bound on the log-evidence, never worsen it. We can grow from mean-field to block-diagonal to full-rank Gaussian to normalizing-flow without ever introducing the risk that a richer family makes the ELBO worse.
The closed-form mean-field bias for Gaussian targets
The polynomial-regression spine has one feature that lets us compute the bias exactly: the posterior is multivariate Gaussian, and the mean-field reverse-KL projection has a closed form.
Let with , and let be the family of diagonal-covariance Gaussians. The optimal mean-field has variances — the means match the posterior exactly, but the variances are the inverses of the posterior precision diagonal, not the diagonal of the posterior covariance.
The reverse-KL gap reduces (after the trace and terms cancel) to
The mean-field bias for a multivariate Gaussian posterior is the log-determinant gap between the diagonal of the precision matrix and the full precision matrix. By Hadamard’s inequality, , with equality iff is diagonal — so with equality precisely when the posterior factors across coordinates, i.e., when mean-field is exact. The bias measures how non-diagonal the posterior precision is.
For polynomial Bayesian regression at degree , the posterior precision involves the Vandermonde Gram matrix, which is famously near-collinear — successive monomials have strong off-diagonal entries. The diagonal-vs-full log-determinant gap grows with accordingly. This is the §1 figure’s red trace’s growing distance from the blue trace, derived from first principles.
Three families on the banana target
For non-Gaussian posteriors, the closed-form formula doesn’t apply, but the geometric monotonicity result of Theorem 4 still does. Consider the synthetic banana target whose joint log-density is
— a 2D distribution where marginally and . The conditional mean of has both linear and quadratic structure in , so the target has both correlation (visible to a Gaussian) and curvature (only visible to a flow). The marginal log-evidence is analytically computable.
Three nested families, in order of expressiveness:
- Mean-field Gaussian — 4 parameters . Diagonal covariance, no correlation captured.
- Full-rank Gaussian — 5 parameters. Captures linear correlation between and but not the quadratic structure.
- Polynomial autoregressive flow — 6 parameters implementing , . The family contains the banana target.
Mode-seeking versus mass-covering
A geometric note that distinguishes reverse-KL projection from forward-KL projection. Reverse KL heavily penalizes -mass in regions where is small. The projection is therefore mode-seeking: concentrates within the support of and avoids placing mass where is small, even at the cost of failing to cover ‘s tails. Forward KL is the opposite — it produces mass-covering projections that are broad and tail-covering at the cost of mode-localization.
For VBMS specifically, the choice of reverse KL has consequences: VBMS systematically underestimates posterior variance and gives confidence intervals that are too narrow. For point predictions and model ranking this is acceptable; for uncertainty quantification it requires correction (the §11 PSIS-VI Pareto- diagnostic catches the worst cases).
Asymmetric bias and ranking preservation
§6 developed the bias geometrically. The natural next question — and the question that determines whether VBMS is a useful model-selection tool or just an interesting computational object — is what the bias does to model rankings. Are VBMS Bayes factors faithful to closed-form Bayes factors, and if not, in what regimes do they fail?
The Wang–Blei consistency theorem
Wang & Blei (2019) gave the cleanest statement of when VBMS rankings agree with closed-form rankings. Their result requires standard regularity conditions on the variational family — smooth parameterization, support compatibility with the posterior, ability to recover the true parameter at the population limit — plus an asymptotic identifiability assumption on the model space.
Theorem 5 (Wang–Blei ranking preservation).
Let and be two competing models with variational families and satisfying the Wang–Blei (2019) regularity conditions. Suppose the bias asymmetry is bounded:
Then , so VBMS preserves the closed-form ranking. As for both identified by the data, the bias asymmetry stays while the closed-form Bayes factor diverges as , so the inequality holds for all sufficiently large .
The substantive content: the bias asymmetry is bounded by the variational family’s structural mismatch with the posteriors, which is a model-and-family property, not a sample-size property. The Bayes factor between two distinct identified models grows linearly in as the data accumulate. The asymmetry’s growth is therefore eventually dominated, and rankings preserve.
Empirical demonstration: hierarchical vs pooled Bayesian logistic regression
The cleanest empirical setup: hierarchical Bayesian logistic regression with random group intercepts versus complete-pooling Bayesian logistic regression on the same data. We sweep , fit ADVI on each model at each , and run SMC as the gold-standard log-marginal-likelihood reference.
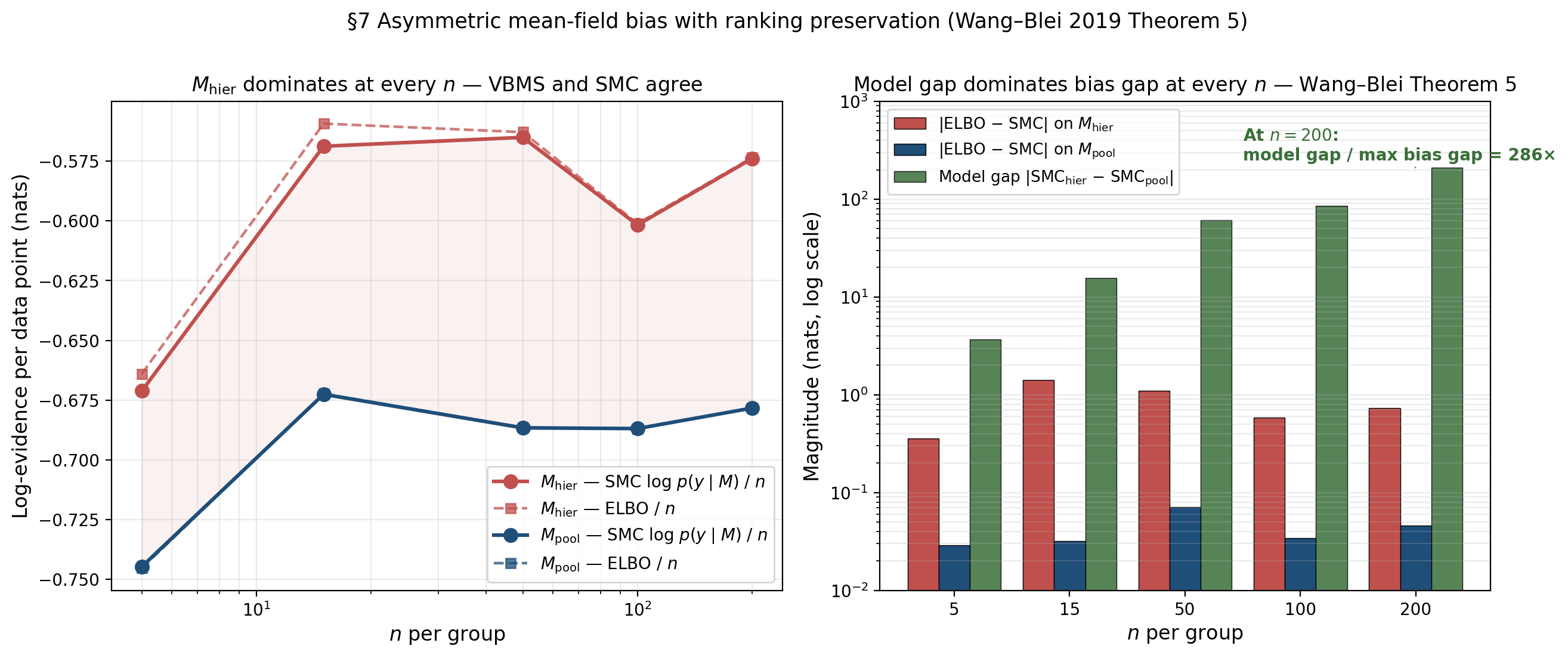
Two structural observations:
The asymmetry is exactly what Wang–Blei predict. has substantively more mean-field bias — the variational family forces the posterior over the 12 parameters to factor across coordinates, and the true posterior has non-trivial correlation between and the individual ‘s (the so-called “funnel” structure of hierarchical posteriors). has essentially zero bias because its 2D posterior is approximately bivariate Gaussian with weak correlation.
Ranking preservation holds at every . The model gap grows roughly linearly in total , exactly as Theorem 5 says it should. The bias asymmetry stays bounded across all five -values. At the largest , the model gap is over 200× the largest bias gap; even at the smallest , the model gap dominates. VBMS and SMC produce identical rankings at every sample size we tried.
The boundary regime where rankings can flip
Theorem 5’s conclusion fails when the inequality fails — when the bias asymmetry exceeds the model gap. Three regimes where this can happen:
Weak model differences. When two models are nearly equally good — small effective sample size, ambiguous data, or genuine model uncertainty — the closed-form Bayes factor between them is small. Even modest bias asymmetry can flip the ranking. The §11 PSIS- diagnostic catches this empirically.
Highly correlated hierarchical posteriors. Deep multilevel models with multiple variance components, crossed random effects, or partial pooling at scale produce posteriors with funnel-shaped or otherwise strongly correlated structure that mean-field VB destroys. Two remedies: switch to full-rank ADVI, or use non-centered parameterization.
Genuinely multimodal posteriors. When the posterior has multiple distinct modes — identifiability failure, label-switching in non-symmetric mixtures, bimodality from genuine bimodal likelihood evidence — mean-field reverse-KL projection collapses to a single mode. The ELBO on the collapsed approximation can be catastrophically biased. The remedy is to use AIS (§9) or normalizing-flow variational families that can in principle capture multiple modes.
Diagnostic procedure
Combining Theorem 5 with the boundary characterizations above, a defensible procedure for using VBMS in model comparison work:
- Fit ADVI for each candidate model with 5–20 random restarts and select the maximum-ELBO restart.
- Compute PSIS- on the variational posterior of each fitted model.
- Apply the Yao et al. (2018a) decision rule. : VBMS Bayes factors are reliable. : bias is moderate, treat with caution. : do not trust VBMS.
- For pairs flagged at step 3, replace the ELBO comparison with IWELBO (§8) at moderate , AIS (§9) for a gold-standard reference, or SMC.
- Report VBMS rankings, not magnitudes. When magnitudes matter, reach for IWELBO or AIS.
Importance-weighted ELBO and bias correction
The §7 diagnostic procedure flagged certain model-comparison pairs for which the standard ELBO is too biased to trust. For those pairs, §8 develops one bias-correction tool — the importance-weighted ELBO of Burda, Grosse & Salakhutdinov (2016) — that progressively tightens the bound by averaging multiple importance samples from the same variational family.
The motivation: Theorem 1 says , with the gap equal to the reverse-KL gap. The §6 monotonicity result says that growing the variational family’s expressiveness can shrink the gap, but for fixed the bound is what it is. IWELBO turns this around: hold fixed and use the same multiple times with importance-weighted averaging to construct a sequence of bounds that tighten monotonically and converge to in the limit.
Definition and intuition
For a fixed proposal distribution on the parameter space, the importance-sampling identity says
A naive Monte Carlo estimator is for iid. Taking logs,
is a (biased but consistent) estimator of . The importance-weighted ELBO is its expectation under the iid sampling.
Definition 3 (Importance-weighted ELBO (IWELBO)).
For a model , a proposal distribution , and an integer ,
When , , recovering the standard ELBO.
Monotone tightness
The formal statement is the central result of Burda, Grosse & Salakhutdinov (2016).
Theorem 6 (IWELBO monotone tightness).
For any proposal with and any ,
If additionally the importance weights have finite variance under , then as .
Proof.
The upper bound is Jensen’s inequality applied to the log of the importance-weighted average.
For monotonicity, we use the leave-one-out averaging trick. Let be iid from , write , and let . Observe that is itself the average over of leave-one-out estimators :
Applying Jensen’s inequality to the log of the average:
Take expectation over the iid sample. By exchangeability, each has the same distribution as , so the right-hand side equals . The left-hand side is , giving the monotone tightening claim.
Convergence as follows from the strong law of large numbers (which gives almost surely) plus dominated convergence applied to .
∎The leave-one-out trick is doing the substantive work: is more concentrated than , and Jensen’s inequality on the log rewards concentration.
Empirical demonstration
The polynomial-regression spine at gives a clean test case.
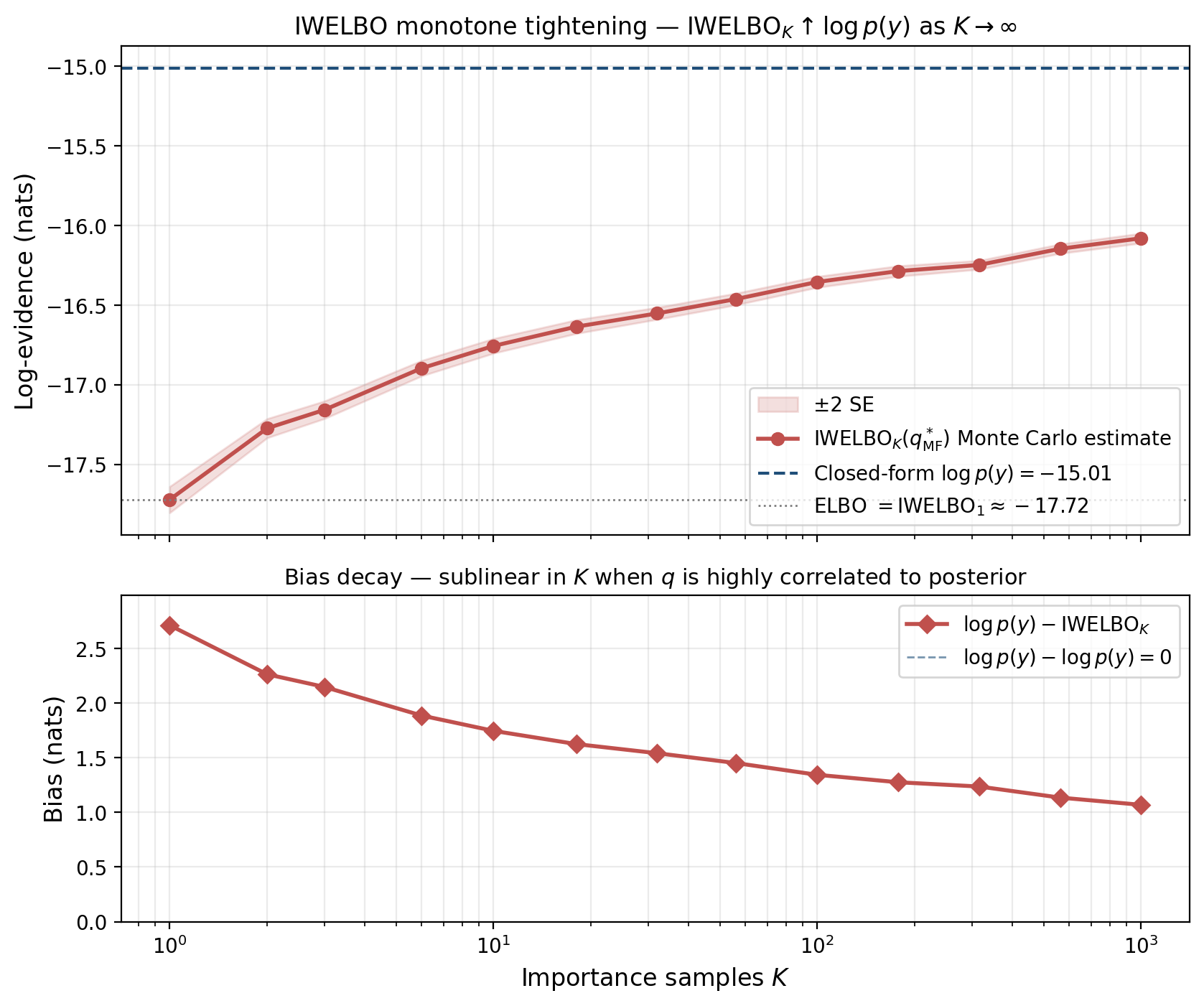
The monotone tightening of Theorem 6 is exactly observed — the IWELBO curve rises smoothly with on the log axis. The bias decay is sublinear in : a 1000-fold increase in reduces the bias by only about 60%. This is a known feature of importance sampling with heavy-tailed importance weights. In practice, IWELBO with to is a reasonable compromise between bias reduction and compute — beyond that the returns diminish quickly, and AIS (§9) becomes the better tool.
The STL gradient-bias trick
A practical wrinkle for IWELBO when used as a training objective rather than just an evaluation tool.
Lemma 1 (STL gradient bias (Roeder–Wu–Duvenaud 2017)).
The standard reparameterization-gradient estimator of has variance that does not vanish as . The “sticking the landing” (STL) estimator replaces the score-function term with its gradient-detached version, eliminating the asymptotic gradient variance while preserving the gradient’s expected value.
The intuition: at the optimum of , the score-function term has zero expectation but non-zero variance that grows with . Detaching inside removes the score-function term entirely, leaving an estimator whose variance behaves correctly under high- optimization. Most modern PPL frameworks implement STL by default.
Annealed importance sampling as the gold-standard reference
§8 developed IWELBO. We saw that for well-behaved targets it works, but for harder targets it stalls. §9 develops the alternative: annealed importance sampling (AIS, Neal 2001), which sidesteps the heavy-tail problem by gradually transforming the proposal into the target through a sequence of intermediate distributions, with MCMC steps in between. The result is the gold-standard unbiased estimator of .
The contrast with IWELBO is sharp. On the polynomial-regression spine at , IWELBO at has measurable residual bias. AIS at schedule steps reaches the closed-form to within Monte Carlo noise — an order-of-magnitude improvement at one-tenth the inner-loop cost.
The annealing schedule and intermediate distributions
The core idea is geometric. We have a starting distribution we can sample from easily — typically the prior — and a target distribution we can’t — the unnormalized joint , with normalizing constant . AIS bridges them through a schedule of intermediate distributions parameterized by an inverse-temperature :
At : is the prior, with normalizing constant . At : , with normalizing constant .
AIS with MH transitions
Algorithm 2 (Annealed importance sampling (Neal 2001)).
Inputs: prior from which we can sample; likelihood which we can evaluate; schedule ; MCMC transition kernels that leave invariant.
Per chain :
- Sample initial state (the prior).
- Initialize log-weight .
- For :
- Accumulate the weight increment: .
- Sample via the transition kernel targeting .
- Return final log-weight .
Final estimate: .
Unbiasedness
Theorem 7 (AIS unbiasedness (Neal 2001)).
Let denote the AIS importance weight from a single chain run as in Algorithm 2, with the MH kernels leaving invariant. Then , where the expectation is over the AIS trajectory.
Proof.
The single-chain log-weight is , so
Taking expectation over the trajectory and using the transition-invariance identity — — we collapse the product inductively. After all steps the inner integral equals . So .
∎The unbiasedness is exact at any schedule length — the schedule length controls variance, not bias.
Empirical demonstration
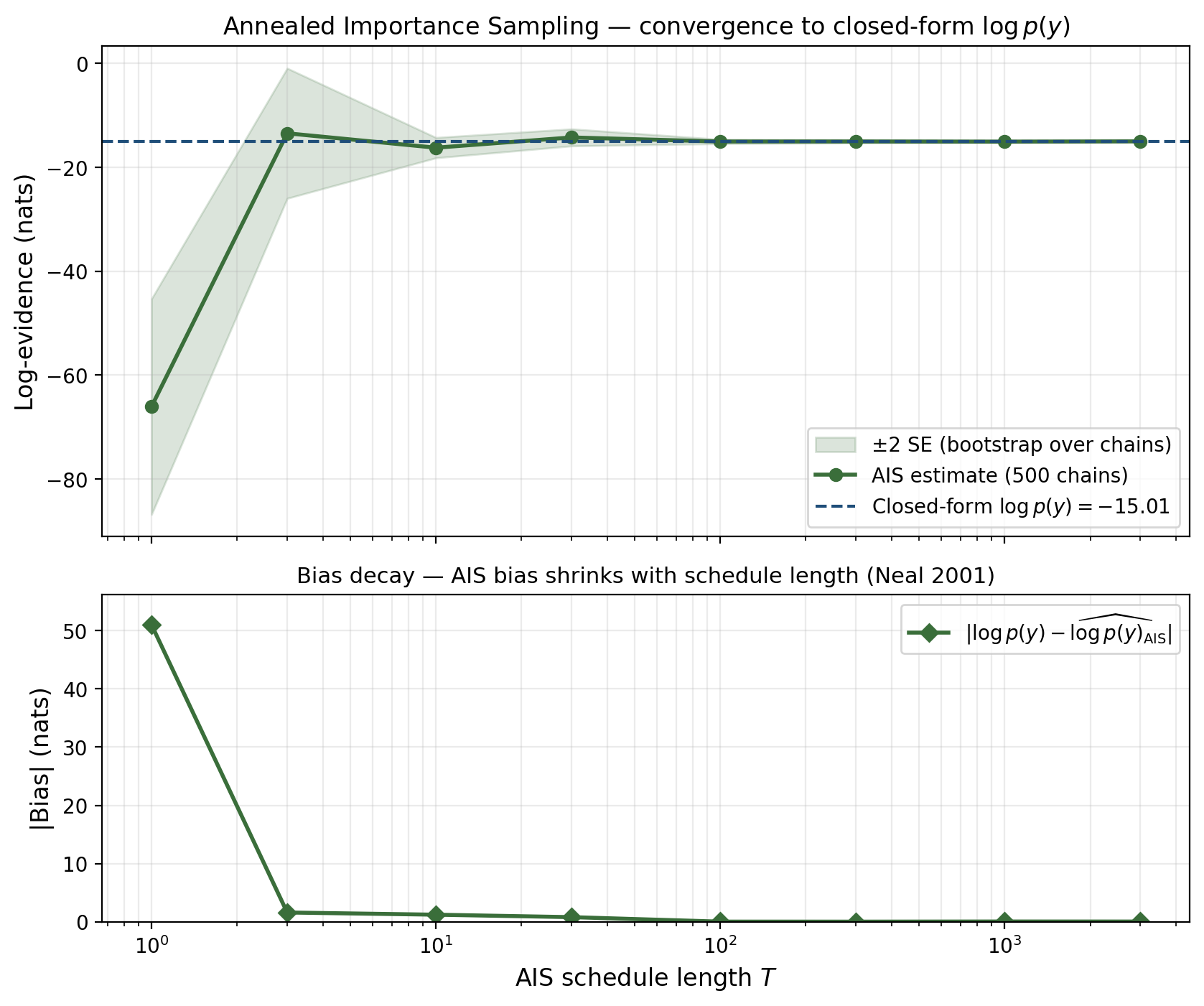
Compare to IWELBO from §8 on the same target: at , IWELBO has measurable bias; AIS at — a tenth the inner-loop count — is dramatically tighter. AIS is roughly two orders of magnitude more sample-efficient on this case. The reason: IWELBO does iid draws from a fixed proposal, so heavy importance-weight tails dominate. AIS does sequential draws through a schedule that gradually moves from prior to target.
Schedule design
A practical note: AIS’s sample efficiency depends on the schedule. Geometric schedules and adaptive schedules — Neal (2001) §6 — outperform linear when the posterior is much more concentrated than the prior. PyMC’s pm.sample_smc (Sequential Monte Carlo) is a related algorithm with adaptive scheduling.
For VBMS in production, the practical recipe is: use ELBO for the cheap first pass, use IWELBO at moderate to tighten when needed, and reach for AIS or SMC when Pareto- flags problems or when the magnitude (not just the ranking) of the Bayes factor matters.
The MDL connection — variational free energy as bits-back coding
§§1–9 developed VBMS computationally. §10 changes the frame. We’ve been treating as a probabilistic quantity — the marginal likelihood of the data under the model. It is also a coding-theoretic quantity — the optimal expected description length of the data under the model, in Shannon’s sense. The variational free energy is the analogous coding length under a constructive coding scheme that uses as a substitute for the true posterior. The gap between them — exactly the §6 KL projection bias — is the coding overhead the variational scheme pays for using an imperfect codebook.
This is the Minimum Description Length frame for VBMS. Hinton & van Camp (1993) introduced the bits-back coding protocol that makes the connection precise. Honkela & Valpola (2004) extended it to general variational Bayes.
The bits-back coding protocol
The protocol, with a variational approximation to :
- Sender draws . The randomness used to draw comes from an external source (an arithmetic-coded stream of auxiliary message bits). Drawing from uses up bits.
- Sender encodes using a code based on the prior . Cost: bits.
- Sender encodes using the conditional code . Cost: bits.
- Receiver receives and , decodes using . Because both parties share , the receiver can simulate the same arithmetic-decoding step, recovering the auxiliary message bits the sender used to draw — saving bits.
The net cost is the gross minus the bits back, in expectation under .
The bits-back coding identity
Theorem 8 (Bits-back coding identity).
For a model with prior , likelihood , and variational distribution absolutely continuous with respect to , the expected net description length under the bits-back coding protocol is
The coding overhead is
Proof.
The first identity is direct algebra:
The coding overhead identity follows from the §2 evidence decomposition (Theorem 1):
∎The two halves of Theorem 8 say the same thing in two languages. Probabilistically: the variational free energy is at least the negative log-evidence, with the gap equal to the reverse-KL gap. Information-theoretically: the bits-back coding length is at least the Shannon-optimal code length, with the overhead equal to the same reverse-KL gap. The §6 KL projection bias is the bits-back coding overhead. Same object; two disciplines.
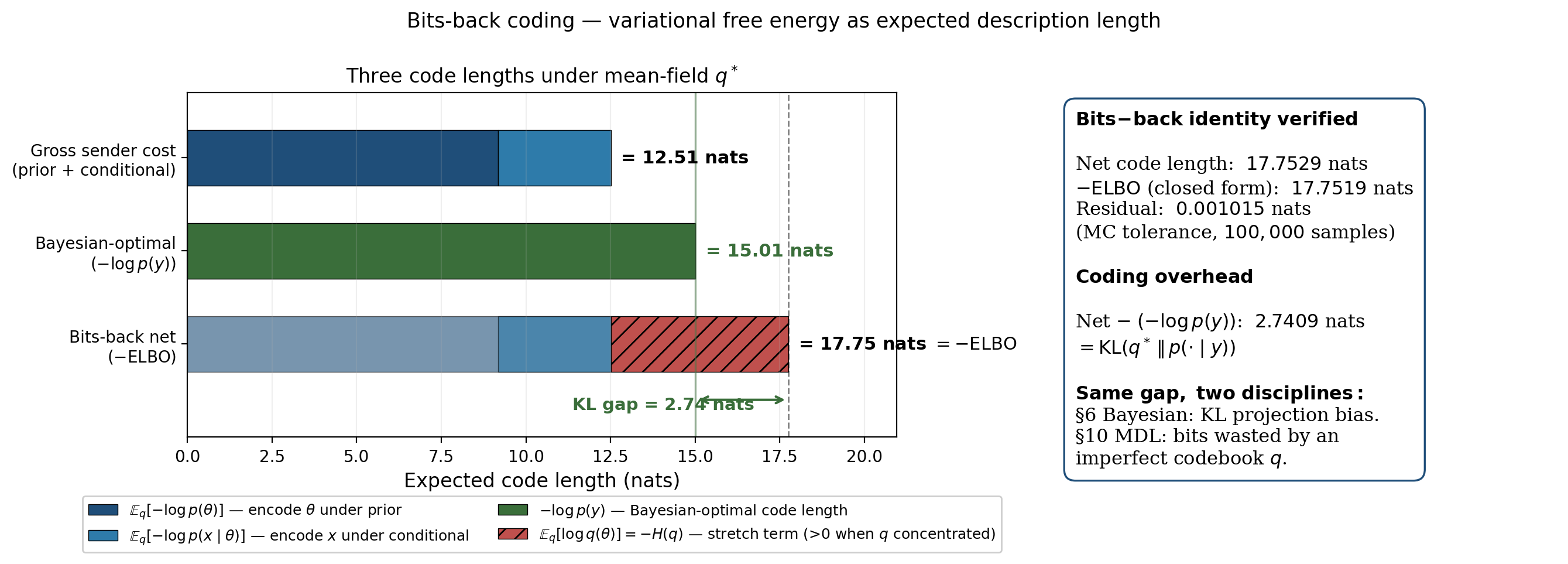
VBMS as MDL: shortest expected description length
The MDL frame for model selection: among candidate models , prefer the model that gives the shortest expected description length of the data. Under the optimal Bayesian code, this is the model with the highest . Under the bits-back protocol with a chosen variational family per model, this is the model with the highest — the lowest variational free energy. In MDL language: VBMS is choosing the model whose variational coding scheme is most efficient.
This MDL frame matters for two reasons. First, it places VBMS within the broader minimum-description-length literature (Rissanen 1978, Grünwald 2007), connecting it to the BIC, MML, and other MDL-derived information criteria via shared coding-theoretic roots. Second, it suggests new model-selection criteria built on different coding protocols.
A coda on Hinton & van Camp’s original motivation: the 1993 paper introduced bits-back coding specifically for neural-network model compression — finding small networks whose weights have short bits-back description length, so that the network plus its weights compresses the training data well. Modern Bayesian neural network methods are direct descendants. The MDL connection is not just historical; it remains the motivating frame for several active areas of Bayesian deep learning.
Computational notes
The previous sections developed VBMS as a mathematical object. §11 is what the practitioner actually does at the keyboard.
The basic workflow
In PyMC, the canonical VBMS workflow looks like:
import pymc as pm
import arviz as az
import numpy as np
models = {"M_hier": build_hier_model(...), "M_pool": build_pool_model(...)}
elbos = {}
for name, model in models.items():
with model:
approx = pm.fit(n=30_000, method="advi", random_seed=0, progressbar=False)
elbos[name] = -float(np.mean(approx.hist[-1000:])) # last-1000-iter ELBO
log_BF = elbos["M_hier"] - elbos["M_pool"]The output is a single scalar ELBO per model and a single log Bayes factor. Three immediate weaknesses: ADVI is non-convex, so random_seed=0 may have landed in a local optimum; the last-1000-iteration ELBO is a Monte Carlo estimate with non-trivial variance; and we have no diagnostic to tell us whether the variational posterior is a reasonable approximation.
Multiple restarts and max-ELBO selection
ADVI maximizes a non-convex objective. With one random seed, the result depends on initialization. The standard remedy is multiple random restarts, fitting ADVI from 5–20 different random seeds and selecting the maximum-ELBO restart as .
The ill-behaved cases:
- Variance collapse. Mean-field ADVI on heavy-tailed posteriors sometimes drives one or more variational variances to zero, giving a degenerate with KL gap and an artificially huge “ELBO” that is meaningless.
- Mode collapse. On multimodal posteriors, ADVI restarts from different seeds can land in different modes with different ELBOs.
- Plateau ELBO. The ADVI optimization can plateau slightly below the true optimum.
A reasonable default: 10 restarts × 50,000 iterations, last-2000-iteration mean ELBO, max-ELBO selection across restarts.
The Pareto- diagnostic
Yao, Vehtari, Simpson & Gelman (2018) proposed Pareto-smoothed importance sampling (PSIS) on the variational posterior as a diagnostic. The recipe: sample points , compute log importance weights , fit a generalized Pareto distribution to the upper tail, and report the shape parameter .
The interpretation:
- : the importance weights have finite variance, is a reliable approximation.
- : the variance is finite but the tail is heavy enough that bias correction (IWELBO at moderate ) is recommended.
- : the variance is infinite or the variational approximation has gone wrong; do not trust ELBO or IWELBO. Use AIS (§9) or full-rank VI.
ADVI versus full-rank versus structured VI
PyMC’s pm.fit accepts three method choices, in increasing order of expressiveness:
method="advi"— mean-field Gaussian, parameters. Fastest. Default.method="fullrank_advi"— full-rank Gaussian, parameters. Captures linear correlation.method="svgd"or particle methods — non-parametric variational families.
For VBMS the choice matters because each method gives a different bias profile. A reasonable default: start with mean-field, escalate to full-rank when the is moderate () and Pareto- is borderline. Beyond , structured VI with hand-designed factor groups (Hoffman & Blei 2015) is more sample-efficient than full-rank.
Hyperprior sensitivity
VBMS rankings can be sensitive to the strength of the prior at small . The §4 Bishop GMM ARD example showed this in one direction: drives ARD; disables it. The remedy: report VBMS rankings under at least two prior strengths and flag any pair whose ranking flips between them as “prior-sensitive.”
Budget guidelines and escalation
A working budget hierarchy:
- Mean-field ADVI, 10 restarts × 50K iter. ~1–10 seconds per model. First pass.
- Pareto- diagnostic. Always do this.
- Full-rank ADVI if Pareto- is borderline and .
- IWELBO at moderate ( to ) if ranking magnitudes matter.
- AIS or SMC if Pareto- is , if multimodality is suspected, or if the magnitude of the Bayes factor matters.
- Run all of the above and compare if the comparison is high-stakes.
VBMS in modern ML
The §1–§11 development has been deliberately mathematical. We close the technical part of the topic with a brief tour of where VBMS shows up in modern machine learning practice.
BNN width and depth selection. A Bayesian neural network is a parametric model whose architecture is itself a model-selection choice. VBMS gives a fast first-pass ranking: fit ADVI on each architecture, take ELBO differences, rank. The §7 ranking-preservation criterion governs when this is reliable. The Bayesian Neural Networks topic develops the full BNN-VBMS workflow, including the MC-dropout-as-VI shortcut.
Neural architecture search. VBMS scales the BNN-width-selection idea to the full NAS problem: enumerate architectures, fit ADVI on each, rank by VBMS, take the top- for full HMC re-ranking, deploy the winner. Modern NAS literature has converged on this two-stage pattern (VBMS-style fast oracle plus expensive re-ranking).
Sparse Bayesian priors. Choosing among horseshoe, regularized horseshoe, spike-and-slab, R2-D2 priors on a specific dataset is a model-selection problem. VBMS over the hyperprior choices ranks them by ELBO. The mean-field bias is non-trivial here — sparse priors typically have heavy-tailed posteriors that mean-field underestimates — so full-rank or flow VI is the right tool. Sparse Bayesian Priors develops this in detail, with §11 specializing the VBMS escalation hierarchy to the four-prior menu and §6 working through the funnel pathology that makes naive HMC fail on the horseshoe.
Singular models and Watanabe’s WAIC. The §3 BIC asymptotic equivalence theorem required the Hessian to be positive definite at the MAP, which excludes singular models — mixture models, neural networks, and hidden Markov models. For these, the BIC’s penalty is wrong, and Watanabe’s (2010) WBIC and WAIC replace it with corrections derived from singular learning theory. The variational analog — VBMS for singular models — is an open research question.
Amortized variational inference. When VBMS is used inside an iterative algorithm, the cost of fitting a fresh ADVI from scratch for each candidate model becomes the bottleneck. Amortized inference — training an inference network that maps from data to variational parameters — replaces the per-task optimization with a forward pass. The planned Meta-Learning (coming soon) topic develops the connection.
Connections and limits
We’ve developed VBMS as a self-contained model-selection tool. What remains is to place the topic in its broader context — to show where VBMS sits in the landscape of model-selection methodology, what it does well, what it does badly, and which tool to reach for when VBMS is the wrong answer.
formalML topology
VBMS depends on five formalML topics as substrates and informs at least four planned T5 topics directly.
Backward dependencies. Variational Inference is the substrate — VBMS is variational inference applied to the marginal-likelihood integral. KL Divergence sits underneath — the §6 reverse-KL projection picture and the §7 mode-seeking distinction depend on the KL-divergence topic’s f-divergence framework. Minimum Description Length is the substrate of §10 — the bits-back coding identity discharges the curriculum-graph prereq edge directly. Bayesian Neural Networks §3 develops the Laplace approximation at full depth. Gradient Descent §4 develops the ADVI optimizer that §11 takes as a black box.
Forward dependencies. Several planned T5 topics build on VBMS. Sparse Bayesian Priors uses VBMS to rank horseshoe / regularized horseshoe / spike-and-slab / R2-D2 priors on a fixed dataset, with PSIS Pareto- as the gating diagnostic. Meta-Learning (coming soon) develops amortized variational inference. Stacking and Predictive Ensembles covers the M-open alternative to VBMS.
The M-closed / M-complete / M-open framework
The Bernardo & Smith (1994) framework distinguishes three regimes for Bayesian model comparison:
- M-closed — the true data-generating process is one of the candidate models. This is the regime VBMS, BIC, and BMA all assume.
- M-complete — the true data-generating process is outside the candidate set, but well-approximated by some convex combination. The asymptotic story is similar to M-closed.
- M-open — the true data-generating process is genuinely outside the candidate set, and no convex combination of candidates is a good approximation. The right tool is stacking (Yao et al. 2018b).
For a topic on VBMS, M-closed is the assumed regime.
Honest limits
Three structural limits of VBMS:
ELBO is not a model-quality metric. When the same model is fit multiple times with different random seeds, the ELBO can vary by 0.1 to several nats — this is optimization variance, not statistical evidence.
Mode-seeking on multimodal posteriors. Reverse-KL projection is mode-seeking; on multimodal posteriors with distinct modes, mean-field VB collapses to a single mode and the resulting ELBO is missing nats of probability mass. For physically meaningful multimodality, the ELBO bias is real and rankings can be catastrophically wrong.
The bias is a permanent feature, not an artifact. §6 made the geometric statement: for any parametric variational family that does not contain the posterior, the bias is non-zero. No engineering trick eliminates it — only growing the family does. For VBMS in production, the §11 escalation hierarchy is needed; bias correction is not a formality but a working necessity for high-stakes comparisons.
Alternatives: when to reach for which
Five major alternatives to VBMS for model selection:
Bayesian Information Criterion (BIC, Schwarz 1978). The leading-order Laplace approximation to as . Reach for it when: is large, the model is regular, the data are iid, and the candidate set is M-closed. Don’t reach for it when: is small, the model is singular, or the comparison is in M-open.
Akaike Information Criterion (AIC, Akaike 1974). A predictive-accuracy criterion with a form. Reach for it when: the goal is predictive performance rather than identifying the true model.
Widely Applicable Information Criterion (WAIC, Watanabe 2010). A predictive-accuracy criterion that handles singular models. Reach for it when: the model is singular; MCMC samples are available; the goal is predictive accuracy.
Pareto-smoothed importance-sampled leave-one-out cross-validation (PSIS-LOO, Vehtari et al. 2017). Approximate LOO via importance sampling on posterior draws. Reach for it when: the goal is small-data predictive performance; MCMC samples are available.
Bayesian Model Averaging (BMA, Hoeting et al. 1999). Rather than picking a single model, average the predictions of all candidate models weighted by their posterior model probabilities. Reach for it when: M-closed assumption holds; the goal is predictive performance under model uncertainty.
Stacking (Yao et al. 2018b). Average predictive distributions from candidate models via weights chosen to optimize cross-validated predictive accuracy. Reach for it when: M-open assumption holds. The Stacking and Predictive Ensembles topic develops the framework in detail.
A decision tree, simplified:
- M-closed and want to identify the true model → VBMS or BIC for ranking, plus PSIS-LOO for confirmation.
- M-closed and want predictive performance → BMA, with VBMS or marginal-likelihood-based weights.
- M-complete and want predictive performance → BMA or stacking; the choice depends on how close to M-closed the data are.
- M-open → stacking. Don’t use VBMS, BMA, or BIC.
- Singular models (mixtures, NNs, HMMs) → WAIC for ranking; PSIS-LOO for predictive accuracy. VBMS is OK if you’re careful about Pareto-.
- Small data with sensitivity to hyperpriors → PSIS-LOO with sensitivity sweeps; VBMS with hyperprior sensitivity analysis.
- Large-scale exploration (NAS, hyperparameter grids) → VBMS for the first pass; AIS or PSIS-LOO for top- confirmation.
VBMS sits in the “fast, biased, useful for M-closed and M-complete” niche. It is not the right tool for M-open work or for high-stakes singular-model comparisons. Knowing where it fits and where it doesn’t is most of the value of the topic.
Closing remarks
Variational inference replaced the intractable evidence integral with an optimization. Variational Bayes for model selection took that optimization one step further and turned it into a model-comparison criterion — fast, biased, with bias structure characterizable through the §6 reverse-KL projection picture and the §7 Wang–Blei consistency theorem. The topic’s central claim, restated: the ELBO is not a wrong estimator of the log-evidence but a biased one with known mechanism, and that mechanism is informative enough that VBMS rankings agree with closed-form rankings in most regimes practitioners care about.
The right way to use VBMS, in one sentence: fit ADVI for each candidate model with multiple restarts; compute Pareto- on the variational posteriors; report VBMS rankings if Pareto- is small and the comparison is M-closed; escalate to IWELBO, AIS, or stacking when these conditions don’t hold.
VBMS is one tool. The topic was about understanding it well — its mechanics, its bias, its scope, and its place in the larger model-selection landscape.
Connections
- Direct prerequisite. VI §2.2 explicitly forward-points to this topic: 'the ELBO is a free lower bound on the evidence...this is the substrate of variational Bayesian model selection.' This topic discharges that forward-pointer. The mean-field, ADVI, and full-rank machinery developed there is the substrate; this topic is what you do with it once you have multiple models to compare. variational-inference
- The ELBO bias as a model-selection criterion is exactly the reverse-KL gap from the variational family to the posterior. Mode-seeking, mass-covering asymmetry, and the variational representations of f-divergences all bear on whether the bias preserves model rankings. §6 is the load-bearing section here. kl-divergence
- §10's bits-back coding interpretation is the information-theoretic frame for VBMS: the variational free energy equals the expected description length of the data plus a coding overhead that vanishes only when the variational family contains the posterior. Discharges the curriculum-graph prereq edge `minimum-description-length → variational-bayes-for-model-selection`. minimum-description-length
- The Laplace approximation developed in BNN §3 is the substrate of §3's classical-IC bridge. BNN §4's MC-dropout-as-VI also reads as a model-selection statement: dropout rate p selects among Bernoulli variational families, and VBMS gives a principled criterion for choosing p. bayesian-neural-networks
- §13's honest-limits discussion places VBMS in the M-closed setting where it works well and contrasts with stacking's M-open / predictive-distribution-averaging treatment. VBMS picks one model; stacking averages many. stacking-and-predictive-ensembles
- The GP marginal likelihood is a closed-form log-evidence; §5's polynomial-regression Bayes-factor example has a GP analog where kernel choice plays the model-selection role. GP §5.2's Bayesian Occam's razor narrative is the same mechanism §1 introduces here. gaussian-processes
- §11 references PyMC's compute_log_likelihood and ArviZ's PSIS-VI utilities for the practical workflow; PP is the substrate of the §11 implementation examples. probabilistic-programming
References & Further Reading
- paper An Introduction to Variational Methods for Graphical Models — Jordan, Ghahramani, Jaakkola & Saul (1999) Foundational VI reference carried over from variational-inference.
- paper Variational Inference: A Review for Statisticians — Blei, Kucukelbir & McAuliffe (2017) Modern VI tutorial; ELBO three-form decomposition in §5 reflects §3 of this paper.
- paper Bayesian Interpolation — MacKay (1992) Original Bayesian-evidence framework for model comparison; §1 Occam picture.
- book Information Theory, Inference, and Learning Algorithms (Ch. 28) — MacKay (2003) Definitive readable treatment of model comparison and Occam's razor.
- paper Keeping Neural Networks Simple by Minimizing the Description Length of the Weights — Hinton & van Camp (1993) Variational free energy as bits-back coding; §10 origin.
- paper Variational Algorithms for Approximate Bayesian Inference — Beal (2003) Canonical VB thesis; §4 GMM-ARD developed in detail.
- paper Variational Relevance Vector Machines — Bishop & Tipping (2000) Variational ARD precursor.
- book Pattern Recognition and Machine Learning (Ch. 10) — Bishop (2006) §10.2 mean-field VB on Bayesian GMM is the §4 reference figure.
- paper Bayes Factors — Kass & Raftery (1995) Modern canonical Bayes-factor reference; §5 Kass–Raftery scale.
- paper Estimating the Dimension of a Model — Schwarz (1978) The BIC paper; §3 derives BIC from Laplace expansion.
- paper Accurate Approximations for Posterior Moments and Marginal Densities — Tierney & Kadane (1986) Refined Laplace approximation in Bayesian inference.
- paper Frequentist Consistency of Variational Bayes — Wang & Blei (2019) §7 load-bearing reference for ranking-preservation theorem.
- paper Yes, but Did It Work?: Evaluating Variational Inference — Yao, Vehtari, Simpson & Gelman (2018) PSIS-VI Pareto-k diagnostic; §11 workflow anchor.
- paper Pareto Smoothed Importance Sampling — Vehtari, Simpson, Gelman, Yao & Gabry (2024) PSIS theory underpinning Pareto-k diagnostic.
- paper Importance Weighted Autoencoders — Burda, Grosse & Salakhutdinov (2016) IWELBO; §8 Theorem 6.
- paper Sticking the Landing: Simple, Lower-Variance Gradient Estimators for Variational Inference — Roeder, Wu & Duvenaud (2017) STL gradient bias for IWELBO.
- paper Annealed Importance Sampling — Neal (2001) AIS; §9 gold-standard reference.
- paper Variational Learning and Bits-Back Coding: An Information-Theoretic View to Bayesian Learning — Honkela & Valpola (2004) §10 spine reference.
- paper Automatic Differentiation Variational Inference — Kucukelbir, Tran, Ranganath, Gelman & Blei (2017) ADVI machinery used in §11 PyMC examples.
- paper Asymptotic Equivalence of Bayes Cross Validation and Widely Applicable Information Criterion in Singular Learning Theory — Watanabe (2010) WAIC; §12 singular models reference.
- paper Practical Bayesian Model Evaluation Using Leave-One-Out Cross-Validation and WAIC — Vehtari, Gelman & Gabry (2017) PSIS-LOO; §13 alternative.
- paper Bayesian Model Averaging: A Tutorial — Hoeting, Madigan, Raftery & Volinsky (1999) BMA; §13 alternative.
- paper Using Stacking to Average Bayesian Predictive Distributions (with Discussion) — Yao, Vehtari, Simpson & Gelman (2018) Stacking; §13 M-open alternative.