The Information Bottleneck
Compressing X while preserving information about Y
1. What problem does the information bottleneck solve?
1.1 Predictive but compact: the trade-off as a design principle
Representations sit between raw data and downstream tasks. A useful representation does two opposed things at once: it throws away what the task doesn’t need (so we aren’t swamped by noise), and it keeps what the task does need (so we can still answer the question). The information bottleneck principle formalizes exactly that opposition as a single optimization problem.
The setup names three random variables. The input is whatever the world hands us — a document, an image, a sensor trace. The target is whatever we ultimately care about — a topic label, a class, a downstream measurement. The representation is the compressed object we want to learn, and we require to be a (possibly stochastic) function of alone. Formally, is conditionally independent of given :
which is the Markov chain we’ll be working inside for the rest of the topic. Concretely, ‘s distribution is fully specified by an encoder — the only knob the IB principle gets to turn.
Two strategies fail immediately. If we set , the encoder is the identity; we have compressed nothing and we have learned nothing. If we set to a constant, the encoder throws everything away; we have compressed perfectly and we have predicted nothing. Useful representations live in between, and the IB principle picks the trade-off explicitly via the Lagrangian
The first term is the cost of remembering: how much information about leaks through the encoder. The second is the value of predicting: how much information about the representation retains. The single scalar shifts where we want to land between the two failure modes. As , only compression matters and the minimizer collapses to a constant. As , only prediction matters and the minimizer recovers the lossless representation. Everything interesting happens in between, on the IB curve — the Pareto frontier in the plane traced out as sweeps.
We will rederive every piece of this picture over the next eleven sections. For now, it is enough to know that we have a single-parameter family of optimization problems and that the parameter has an interpretable meaning: is the bit-for-bit exchange rate between compression and prediction.
1.2 A motivating vignette: clustering documents by topic
The original Tishby–Pereira–Bialek paper grounds the principle in document clustering, which is still the cleanest first example. Imagine eight documents drawn from two hidden topics — call them “sports” and “finance.” Each document is summarized by a word-count signature, and the topic label is what a downstream task cares about. A representation is a (soft) clustering: the encoder says how strongly document is assigned to cluster .
We give every document equal mass and arrange the topic structure as cleanly as possible: documents through come from topic , documents through from topic . The joint distribution then has uniform mass on its eight-point support, and the marginals come out to for every document and for each topic. Quick consequences:
The last equality uses that is a deterministic function of on this construction, so and .
Three reference clusterings stake out the corners of the IB plane:
| Clustering | What it does | ||
|---|---|---|---|
| Full compression. All documents in one cluster — predictiveness destroyed. | |||
| Topic-aligned. Two clusters, one per topic — minimum compression that still captures all of . | |||
| Identity. Eight clusters, one per document — zero compression, but no additional predictiveness over . |
The third row is the punchline: keeping all three bits of buys exactly the same one bit of -information as keeping only the one bit that says “which topic.” Compressing from three bits down to one bit is therefore free on this construction — the extra two bits of are pure noise from ‘s point of view. The IB curve, traced over , will recover this fact algorithmically without being told what is in advance. We come back to this same eight-document table in §5 when we run the discrete IB algorithm on it.
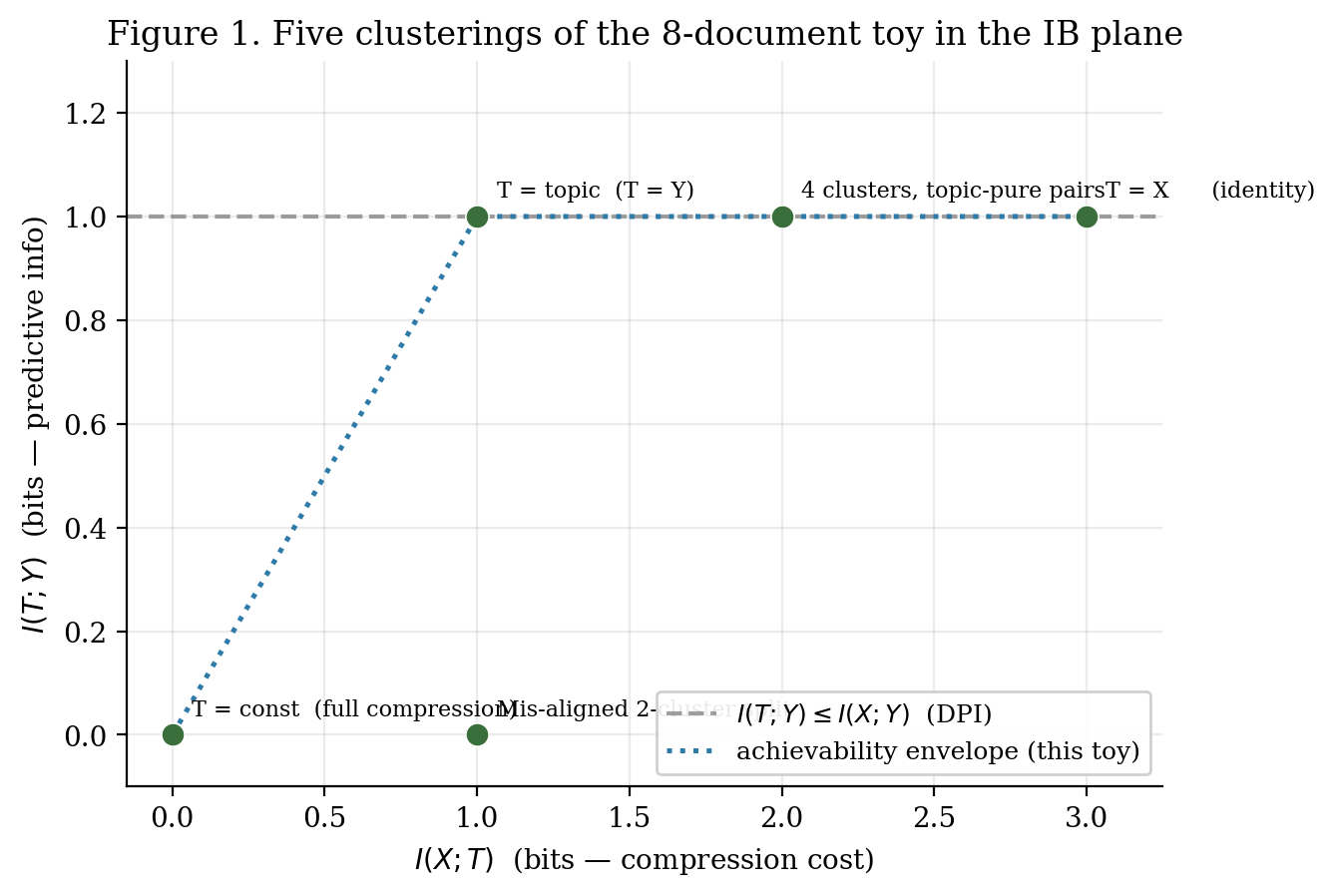
Two clusters aligned with the two topics. Captures all of Y at the smallest possible I(X;T) — sits on the optimal corner of the IB plane.
1.3 Why mutual information is the right currency
Why measure “informativeness” with mutual information rather than (say) classification accuracy, correlation, or one of the many divergences floating around in the ML literature? Four reasons make MI the natural choice for both axes of the IB plane.
Invariance to relabeling. depends only on the joint distribution , not on how cluster names are assigned. Two clusterings that partition identically have the same mutual information regardless of whether we call the clusters "" or ”.” Compression should count statistical structure, not labels, and MI does this by construction.
A coding interpretation. Shannon’s source-coding theorem (the foundation we lean on from Shannon entropy) tells us that is, asymptotically, the average number of bits per sample needed to communicate to a receiver who already knows . So has a literal units interpretation — bits. The compression term in the IB Lagrangian carries a cost in the same currency as the predictiveness term.
A clean entropy decomposition. Writing splits the entropy of into “the bits about captured by ” and “the bits about lost in .” Maximizing is exactly minimizing what we lose; minimizing is exactly maximizing what we throw away. The IB Lagrangian is asking us to throw away what is irrelevant and to keep what is relevant, both measured in the same units.
The data-processing inequality. For any Markov chain ,
No matter what encoder we cook up from , the representation cannot predict better than itself can. This places a hard ceiling on the predictiveness side of the IB plane: the IB curve is bounded above by the constant . It also tells us when compression is genuinely free. If — that is, if has lots of bits unrelated to — then there is plenty of room to compress without paying anything in predictiveness. Our document-clustering toy has and , so two of the three bits in are pure noise from ‘s standpoint, and the IB algorithm will discard them as varies.
These four properties together — invariance, units, decomposition, the DPI ceiling — make and the natural axes of the trade-off. The IB Lagrangian is, in a real sense, the most parsimonious functional you can write that respects all four.
1.4 Roadmap and what’s not in scope
The topic covers three substantive arcs.
Discrete IB (Tishby–Pereira–Bialek 1999), §§3–5. We derive the stationarity conditions on by variational calculus on the encoder, obtain the three coupled updates for , , and , prove convergence of the iterative algorithm via a Lyapunov argument inherited from the Blahut–Arimoto algorithm in rate-distortion theory, and run the algorithm on the eight-document toy to trace out the IB curve.
Gaussian IB (Chechik–Globerson–Tishby–Weiss 2005), §§6–7. When are jointly Gaussian, the IB problem has a closed-form solution: the optimal encoder is linear-plus-Gaussian-noise, and the optimal projection directions are the canonical-correlation directions of . The IB curve becomes piecewise-analytic, with phase transitions at critical values where new directions activate. This is the analytical sandbox where every quantity is exactly computable.
Variational IB and the deep-learning lift, §§8–10. The Alemi–Fischer–Dillon–Murphy 2017 variational lower bound on makes the IB Lagrangian tractable for encoders that are too high-dimensional to enumerate, including neural-network encoders. We will derive the bound, work through the reparametrization trick, and exercise the construction on a closed-form linear-Gaussian VIB sandbox. Then we take the deep-learning controversy head-on: Tishby–Zaslavsky 2015 and Shwartz-Ziv–Tishby 2017 argued that deep networks generically traverse a “fitting then compression” trajectory in the information plane; Saxe et al. 2018 showed that the compression phase disappears when the activation is ReLU instead of tanh, and may have been an artifact of how MI was estimated. We will present both sides faithfully.
Connections and limits, §§11–12. IB is mathematically adjacent to several other principles: rate-distortion (the closest parent — same Lagrangian template, different distortion), PAC-Bayes (which uses a KL term as a complexity penalty, structurally analogous to the term), and InfoNCE in contrastive learning (which is provably an MI lower bound, so contrastive methods are implicitly doing IB-style optimization). We close with computational notes — logsumexp stability, plug-in MI estimator pitfalls — and a list of honest limits.
What we are not doing. We are not training a deep VIB on real image data; the under-60-second CPU runtime budget rules it out, and Alemi et al.’s MNIST numbers will be discussed but not reproduced. We are not adjudicating the deep-learning debate; we will present the controversy faithfully and let the reader form their own view. We are not building a full rate-distortion theory from scratch; that lives in rate-distortion, and we’ll cite forward to it at the relevant point in §11.
2. The information bottleneck Lagrangian
2.1 The setting and the Markov chain
Let be the input random variable, the target, and the learned representation. We assume the joint distribution is given. In §3 the iterative algorithm will use this distribution directly; in §12.2 we’ll discuss how to estimate it from a finite sample. The triple satisfies the Markov property
equivalent to the conditional-independence statement . In words: is allowed to depend on only through itself, never directly through . This is exactly what it means for to be a (possibly randomized) function of .
The single degree of freedom in the problem is the encoder
We are free to choose the alphabet , including its cardinality. For the discrete IB of §§3–5 we take for some user-specified ; for the Gaussian IB of §§6–7 we take ; for the variational IB of §§8–10 the alphabet is whatever the variational family supports.
Three derived distributions matter, and the IB algorithm of §3 will turn out to update exactly these three:
The first is the cluster marginal. The second is the cluster-conditional distribution of , by Bayes. The third is the cluster-conditional distribution of , computed using the Markov property — the encoder’s job is to forward whatever it knows about , not to invent anything new about .
2.2 The variational problem
The IB problem has two equivalent forms, and it pays to be precise about both.
The constrained form. Fix a target predictiveness level . The problem is
We want the most compressed representation whose predictiveness is at least . Sweeping across its allowed range traces out the IB curve.
The Lagrangian form. Introduce a Lagrange multiplier for the predictiveness constraint and, for now, handle the normalization constraints implicitly. The Lagrangian we will use from §3 onward is
The Lagrangian form is a relaxation: for each , the minimizer of also solves (2.2) for some value of (namely the value achieved by the minimizer), and the two forms generate the same Pareto frontier. We work with the Lagrangian form because its stationarity conditions differentiate cleanly — see §3.2.
A subtlety worth flagging now: the Lagrangian relaxation can miss points on the IB curve where the curve has a corner (i.e., where the right-hand and left-hand slopes disagree). At such points, no single produces that operating point as a Lagrangian minimum — only an open interval of values does, and the achievable point sits “between” the two corner branches. This will matter in §7 when we discuss Gaussian-IB phase transitions, where the curve has exactly such corners.
2.3 The IB curve in the information plane
Define the IB curve as the value function of (2.2):
This is the upper Pareto boundary of the achievable region in the plane — every operating point sits on or below it.
Theorem 1 (IB-curve shape).
is non-decreasing, concave, and bounded above by , with equality achieved for all large enough to support a sufficient statistic for in .
Proof.
Monotonicity. Immediate: enlarging the constraint enlarges the feasible set, so the supremum cannot decrease.
Concavity by time-sharing. Fix and . Let and pick encoders over an alphabet and over an alphabet satisfying
where is the representation produced by encoder . By relabeling we may assume .
Now introduce a Bernoulli switch , drawn independently of everything else, and define the time-shared representation
which corresponds to the encoder . Because the codomains are disjoint, is recoverable from , so .
Compression side. Using and the chain rule,
where because is independent of , and the conditional MI splits because conditional on , the representation is exactly . Hence .
Prediction side. By the same argument,
which is at least .
Hence is a feasible encoder for the constraint level , with predictiveness at least . Therefore
Letting gives concavity.
The ceiling. The data-processing inequality applied to the Markov chain gives for every encoder, so for all . Equality is achieved at any , where is the rate needed to encode a minimal sufficient statistic for in . When such a statistic exists with finite alphabet, is finite; otherwise the equality is achieved only in the limit .
∎The IB curve is therefore a concave non-decreasing curve starting at the origin, climbing as grows, and saturating at once we can afford to encode a sufficient statistic. Past saturation, additional compression budget is wasted on bits of that don’t help with . The whole geometric content of the IB principle lives in the shape of this curve.
2.4 What β controls
The Lagrange multiplier in admits a clean geometric reading: it is the reciprocal of the tangent slope of the IB curve at the operating point.
Suppose minimizes and achieves the point on the IB curve, with . By the KKT conditions for problem (2.2), is the dual variable for the predictiveness constraint, and where the curve is differentiable the tangent at has slope :
This identity organizes the knob into three regimes.
Small β (large slope, near origin). The compression term dominates the Lagrangian. In the limit , the optimum collapses to and .
Large β (small slope, near saturation). The predictiveness term dominates. As , the optimum recovers a minimal sufficient statistic: at the smallest that supports it.
The critical β_c. Between these regimes sits a sharp threshold. Let be the initial slope of the IB curve at the origin. For , every nontrivial encoder achieves , so the optimum is the trivial . At , a nontrivial branch of solutions emerges. For the discrete IB, depends on and is generally found numerically by sweeping . For the Gaussian IB, equals the largest eigenvalue of a canonical-correlation matrix, so — this is the first of several phase transitions worked out in §7.
A concrete preview makes the picture tangible. The scalar-Gaussian case ( jointly Gaussian with correlation ) admits the closed-form IB curve
saturating at the predictiveness ceiling . The threshold value is the value below which the trivial encoder is optimal. At , , and the three tangent operating points referenced by the figure below land at bits for , bits for , and bits for — each with tangent slope , confirming the KKT identity (2.5). We derive this scalar-Gaussian result formally in §6 and §7; the figure previews the general shape.
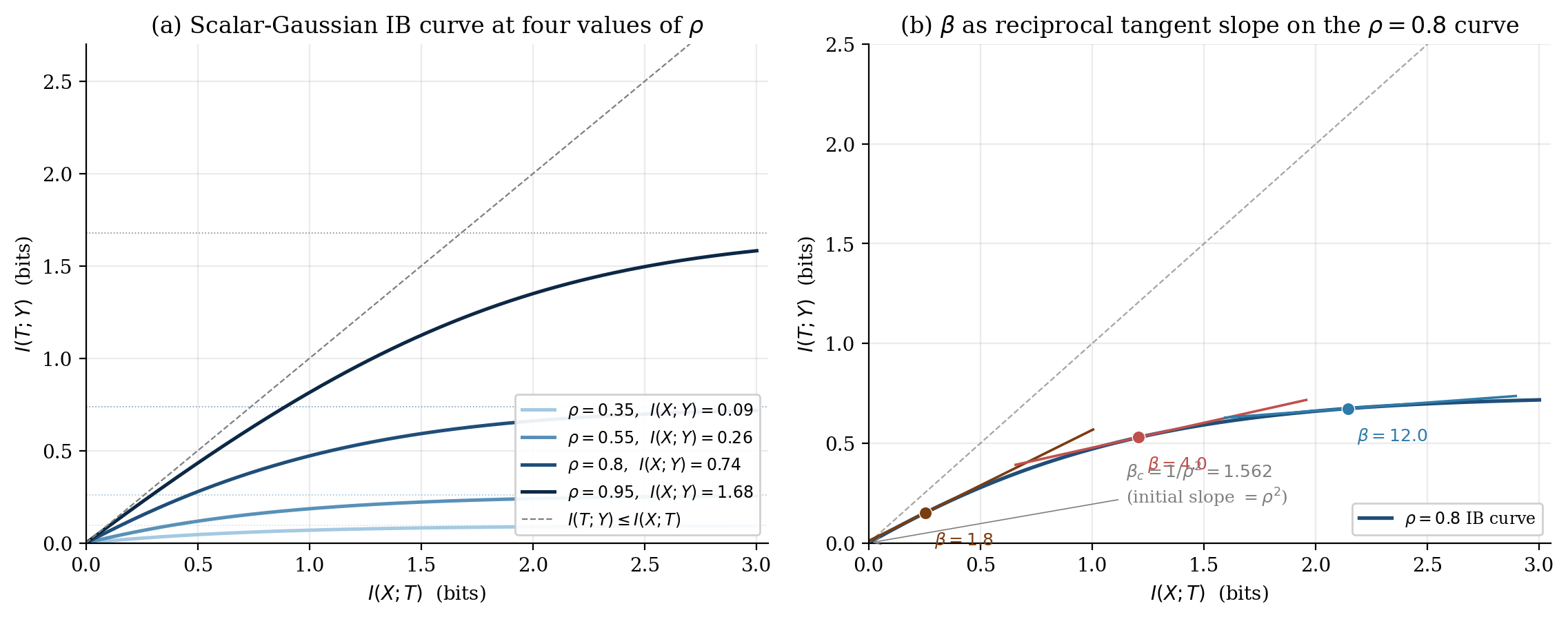
Drag β past β_c = 1/ρ² to escape the trivial encoder; the tangent line's slope is always 1/β, which is the KKT identity (2.5). At ρ = 0.8 the §2.4 reference operating points sit at (0.254, 0.152), (1.208, 0.529), and (2.145, 0.674) bits for β ∈ {1.8, 4, 12}.
This figure previews a result derived formally in §6 (the Gaussian closed form), framed for §2 as a concrete example that makes the curve shape and the -as-slope interpretation tangible.
3. The IB fixed-point equations
3.1 Stationarity conditions on the Lagrangian
We are looking for encoders that minimize the Lagrangian
subject to the normalization constraints for every . Augmenting with multipliers gives the full Lagrangian
At a stationary point we need for every with , together with the normalization constraint.
Theorem 2 (IB stationarity condition).
At any stationary point of over normalized encoders,
where is the cluster marginal, is the cluster-conditional target, and
is the per-input normalization.
Equation (3.3) is the central formula of discrete IB. Read it as a soft-assignment rule: input is assigned to cluster with probability proportional to the cluster’s prior times the exponential of times the KL between the true target distribution at , namely , and the cluster-conditional target distribution, . Two clusters whose target distributions are close to both attract ; the one whose target distribution is closer wins more probability. The bandwidth of “closer wins” is set by — at small assignments are diffuse; at large each input goes almost entirely to its closest cluster.
The two other quantities and are not independent free parameters — they are determined by through (2.1). So (3.3) is really a self-consistency equation: the encoder defines the marginal and the decoder, which in turn feed back into the right-hand side. We will turn this self-consistency into the iterative algorithm in §3.3.
3.2 Derivation via variational calculus
We compute the two partial derivatives that show up in (3.2). Throughout we adopt the convention that is the natural log (the conversion to bits is a global factor of that drops out of the stationarity condition).
Proof.
Partial derivative of . Write
The first piece depends on only through , with . Differentiating with respect to gives , so the chain-rule contribution is . The second piece depends explicitly on at , giving . The two ‘s cancel:
Partial derivative of . Using , write
where the term is constant in and drops out. The remaining sum depends on both explicitly (through the factor at ) and implicitly (through every , which is itself a function of ).
Explicit contribution. Direct: , summed over , gives .
Implicit contribution. From a short calculation gives
The implicit contribution to is then
So the implicit term vanishes identically — both summands have and the difference cancels. This is the key simplification of the derivation, and we verify it numerically below. We are left with
Assembling the KKT condition. Differentiating (3.2) and setting the result to zero:
Dividing through by and using
we obtain
The -independent terms ( and ) are absorbed into the normalization . Exponentiating and using produces (3.3) and (3.4).
∎The implicit-term-vanishes identity (3.9) expresses a structural feature of the IB problem: , viewed as a function of the encoder, is the “Bayes-optimal” estimate of given averaged over the encoder’s induced distribution on , so the gradient of any quantity computed from that is “evaluated at its own optimal estimate” picks up no first-order correction. This is the same observation that makes EM monotone and that makes the IB algorithm Blahut–Arimoto-style monotone, which we’ll prove in §4.
Remark (Numerical check of (3.9)).
The notebook (cell 13) verifies (3.9) by comparing the analytical gradient — using only the explicit contribution (3.10) — against a finite-difference reference of the full on a random soft encoder with clusters and . The maximum and mean absolute differences both come out to , the finite-difference truncation error at step size — the implicit term contributes nothing detectable, consistent with the identity. If the implicit term were nonzero, the discrepancy would grow with the step size; instead it shrinks, the signature of pure truncation error.
3.3 The three coupled updates
A stationary point of must satisfy three coupled self-consistency equations:
These are the IB equations. The natural way to attack a coupled fixed-point system like (3.13) is alternating substitution: hold two of the three quantities fixed, update the third, repeat. Concretely, fix some initial encoder and iterate
This is the iterative IB algorithm (Tishby, Pereira, and Bialek 1999). §4 proves that the algorithm decreases monotonically and converges to a stationary point of (3.13); §5 runs it on the eight-document toy.
Three structural features of (3.13):
Labeling invariance. Permuting the cluster labels in leaves the IB equations invariant. Two clusters with the same prior and the same conditional are indistinguishable — under (3.13) they will receive identical assignment probabilities from every . This is the source of the bifurcation pattern in §5: clusters that are degenerate at low split into distinct clusters as crosses a phase-transition value.
The trivial fixed point. Setting (any -independent distribution) makes the right-hand side of the first equation independent of as well. So the trivial encoder is always a fixed point — it is the unique fixed point for , and loses stability at .
The implicit data dependence. The IB equations involve , , and only — they don’t use any external “distortion function.” This is the structural feature that distinguishes IB from rate-distortion (see §3.4).
3.4 Why these are a Blahut–Arimoto cousin
The IB iteration (3.14) inherits its template from the Blahut–Arimoto algorithm for computing rate-distortion functions (covered in rate-distortion theory). The BA algorithm minimizes the rate-distortion Lagrangian
with stationarity condition
Compare side-by-side with the IB condition (3.3):
Structurally identical. The role of the rate-distortion distortion is played in IB by
which we may call the predictive distortion — a measure of how badly the cluster-conditional approximates the true conditional . Two clusters are “close” in the IB sense if they make similar predictions about , not if they look similar in input space. Compression is therefore task-aligned: it preserves bits useful for predicting and discards everything else.
There is one crucial difference between IB and rate-distortion, however, which is the key technical reason IB is harder. In rate-distortion, the distortion is given as input — fixed before the algorithm starts. In IB, the predictive distortion depends on , which depends on the encoder , which depends on the predictive distortion. The “distortion” emerges from the iteration itself. As a consequence:
- The rate-distortion Lagrangian is convex in for fixed distortion, so BA converges to the global minimum.
- The IB Lagrangian is not convex in , so the IB iteration converges only to a local stationary point — generally to one of many.
This non-convexity has consequences we’ll feel in §5: running the IB iteration with different random initializations finds different stationary points, and the global IB curve has to be traced by either (a) running many restarts at each and keeping the best, or (b) using -annealing — solving at small first and warm-starting at the next .
Despite the non-convexity, the IB iteration enjoys a clean monotonicity property — decreases at every step — and convergence to a stationary point. We prove both in §4.
4. Convergence of the IB updates
4.1 The Lagrangian decreases at every step
The IB iteration (3.14) updates the encoder by a non-trivial coupled rule, so monotone decrease of is not obvious from the update form alone. The clean proof goes through a wider three-argument functional — the same Csiszár–Tusnády construction that gives convergence of Blahut–Arimoto for rate-distortion and of EM for likelihood maximization.
Setup: the auxiliary functional. Treat the encoder , the cluster marginal , and the cluster decoder as independent arguments. Define
The first sum looks like but uses the auxiliary in the denominator. The second looks like the expected KL “predictive distortion” but uses the auxiliary as the cluster decoder. Both reduce to their actual-quantity versions when and equal the encoder’s induced marginal and decoder respectively.
Lemma 1 (F relates to the IB Lagrangian).
For every normalized encoder and every ,
In particular, , with equality iff and .
Proof.
Splitting the logarithm in the first sum of (4.1):
For the second sum, expand the KL and use together with :
Adding the two contributions yields (4.2). The two KL terms are non-negative, with simultaneous equality iff and .
∎Lemma 2 (IB iteration is alternating minimization on F).
For fixed , the minimizer of over normalized encoders is
Proof.
With fixed, is a sum of independent per- problems. Each per- problem is convex in . Differentiating with multiplier for normalization and setting the result to zero gives (4.3) after absorbing -independent terms into the normalization.
∎Theorem 3 (Monotone decrease).
Let be the IB iterates produced by (3.14), and . Then for every ,
with equality iff is a fixed point of (3.13).
Proof.
Let and . By Lemma 1 with , (the equality case),
The next iterate minimizes by Lemma 2, so
By Lemma 1 (inequality direction) with ,
Chaining gives . Equality requires both inequalities to be tight, which happens iff is already a fixed point.
∎The construction is worth lingering on: is a Lyapunov-with-slack — it equals plus two KL-divergence penalties that vanish precisely when and are the encoder’s induced quantities. The IB iteration alternately tightens the slack and minimizes the loosened objective. This Csiszár–Tusnády pattern proves Blahut–Arimoto, EM, and CAVI convergence — IB specializes it to the predictive-KL distortion.
4.2 Boundedness and limit-point existence
Boundedness of . and by DPI, so
Monotone decrease plus a lower bound implies the sequence converges to some limit .
Compactness. Iterates live in the compact product of simplices . By Bolzano–Weierstrass, every subsequence has a convergent sub-subsequence.
Limit points are fixed points. The IB update map is continuous on the simplex interior. If , then . By the equality case of Theorem 3, .
Theorem 4 (Convergence to a fixed point).
Every limit point of the IB iteration is a fixed point of (3.13), and the sequence of Lagrangian values converges.
4.3 What the algorithm converges to: stationary, not global
Theorems 3 and 4 give stationary-point convergence, not global-minimum convergence. Three observations.
Trivial vs nontrivial fixed points. The encoder (any -independent distribution) is always a fixed point. For it is the unique fixed point and the global minimum. For the trivial fixed point becomes a saddle: small perturbations grow under iteration.
Symmetry-broken fixed points. Multiple equivalent solutions exist by cluster-label permutation — all give the same value but trip up direct iterate comparisons.
Genuinely distinct local minima. Beyond labeling, the IB landscape can have multiple genuinely distinct stationary points at different values. Random initialization picks between basins essentially at random.
The numerical experiment in Figure 3 illustrates this: five random initializations at , on the eight-document toy land at slightly different values — some runs find the optimum, others get stuck.
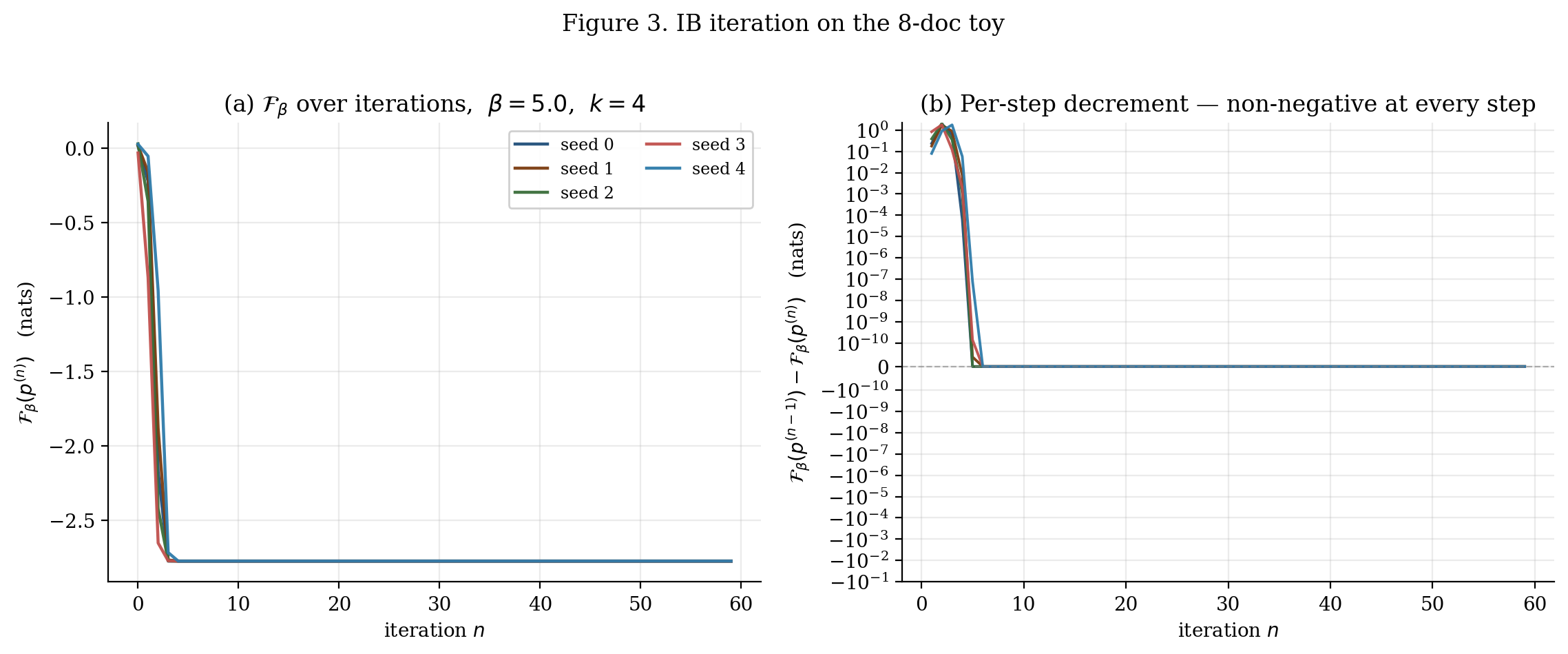
4.4 The non-convexity hazard and annealing in β
Two practical remedies for the non-convexity exposed in Figure 3.
Random restarts. At each of interest, run the iteration from random initializations and keep the lowest at convergence. Embarrassingly parallel. The failure mode is high — when the landscape has many basins, must scale with the number of basins.
β-annealing. Solve at a small first (where the landscape is convex, trivial encoder is the unique fixed point), then incrementally raise , warm-starting each new from the previous ‘s converged encoder. The IB curve is continuous in , so neighboring values have neighboring optimal encoders. Annealing traces a smooth path along the IB curve.
Annealing has a structural benefit beyond non-convexity: it makes the cluster bifurcations explicit. At small , all clusters collapse onto the trivial fixed point. As crosses , two clusters split apart. At larger thresholds, further splits occur — each phase transition activates an additional cluster. The annealing trace through the IB plane traces out the staircase of phase transitions that §5 makes visible for the discrete toy and §7 for the Gaussian closed form.
§5 implements both strategies on the eight-document toy and traces the full IB curve.
5. The discrete IB in practice
5.1 Initialization and random restarts
§4 left us with an algorithm that decreases monotonically and converges to a fixed point — without guaranteeing the best fixed point. Three practical choices fill in the operational picture.
Encoder initialization. The IB iteration is a self-map on the simplex product . We start from a random softmax draw:
Small (say ) yields a near-trivial initial encoder. The random-softmax form is easier to control numerically than near-uniform perturbations, and it keeps every cluster nonempty at initialization so that no propagates a through the first update.
The escape-from-saddle problem. At any , the trivial encoder is a saddle point of . An iterate that lands too close to it can take many iterations to escape. With exactly, the iteration is stationary and never moves. Always use .
Random restarts. At each of interest, run from independent initializations and keep the lowest at convergence. For small toys to suffices.
β-annealing. Solve at a small starting first, then incrementally increase , warm-starting each new from the previous ‘s converged encoder. Two practical wrinkles: (i) at each step, add a tiny random perturbation to the warm-start encoder to break exact saddle-point degeneracy, and (ii) the grid should be log-spaced and dense near suspected phase transitions to resolve their location.
From §5.3 onward: anneal forward across as the primary strategy, with random-restart sanity checks at selected to confirm we haven’t missed a lower- branch.
5.2 A worked example on the eight-document toy
Before sweeping , exhibit the algorithm on the running eight-document toy from §1.2 at fixed . Since for this toy, sits well past the first transition. With clusters and random-softmax initialization at , the iteration converges in roughly 17 iterations.
The trajectory has a characteristic shape: in the first few iterations, drops sharply as the encoder finds the topic-aligned partition; over the next dozen iterations, creeps toward its limit while the two “spare” clusters merge with the two topic clusters. By iteration 30, the per-step decrement is at machine precision.
The converged encoder uses only effective clusters (out of the 4 allocated), with the two spare clusters bleeding into the active ones. The converged equals nats — exactly the optimum achieved by the encoder. The optimum nats matches the value found by four of the five seeds in Figure 3 (one seed gets stuck in a suboptimal local minimum that uses one cluster’s worth of effective capacity inefficiently).
5.3 Tracing the IB curve by sweeping β
The eight-document toy has only one phase transition because bit caps the staircase. For a multi-transition example we introduce a richer toy — call it T3 for “three-topic graded purity”:
Six documents in three topics, with uniform. Conditional varies by document pair:
- Docs 0, 1: — very topic-0 pure.
- Docs 2, 3: — very topic-1 pure.
- Docs 4, 5: — moderately topic-2 pure.
Three distinct conditional distributions, with the first two highly distinguishable (purity 0.85) and the third moderately distinct from the others (purity 0.70). For this construction the numerical values are nats, nats, hence nats bits.
Setting (one spare cluster to confirm self-disabling), we sweep across 40 log-spaced values in , annealing forward with warm-starts. The result is plotted in Figure 4: the IB curve in the plane (left), and the same data plotted as and vs (right). The plane plot shows the smooth, concave curve from origin to saturation; the plot exposes the two phase transitions as visible steepness changes — the first around where the encoder starts to differentiate, and the second around where the third cluster activates.
The saturation point of the curve sits at nats nats, since 3 clusters suffice to encode a minimal sufficient statistic.
Two consistency checks. Random restarts at confirm the annealing trace is the global optimum: 10 random initializations at each converge to within machine precision of the annealing value.
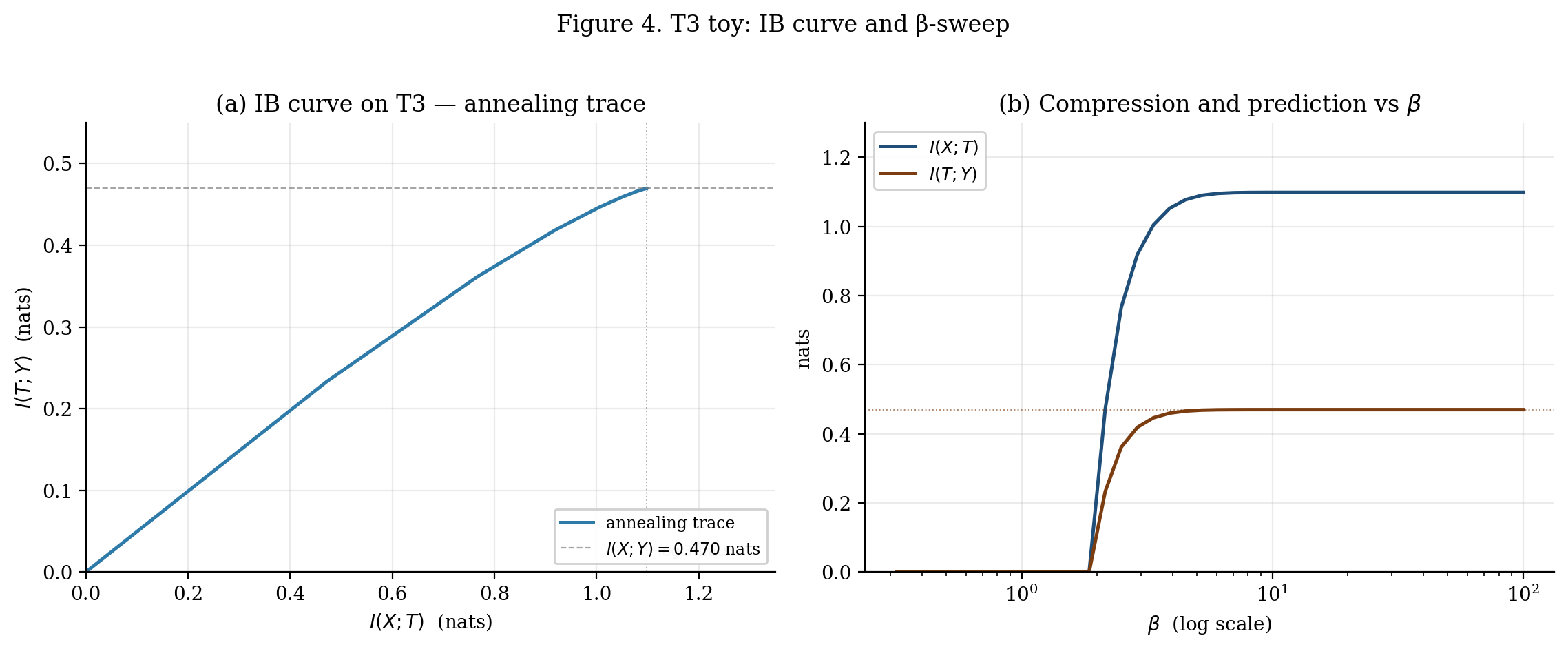
The sweep is β-annealed (each new β warm-starts from the previous β's converged encoder). Saturation point sits at (R†, I(X;Y)) = (log 3, 0.470) nats; the spare fourth cluster self-disables. Two phase transitions are visible in the right panel as steepness changes in I(T;Y).
5.4 Reading the trajectory: how clusters split with β
The IB curve in the left panel of Figure 4 is concave and continuous — phase transitions are invisible in that view. They become visible in two derived quantities, which we plot in Figure 5.
The effective cluster count. Define the perplexity of the cluster marginal:
This is the “effective number of clusters” — equal to when is uniform over all clusters, equal to when collapses to a single cluster, and continuously interpolating in between when the cluster marginal is non-uniform. As grows, traces out a staircase: flat plateaus where the cluster structure is stable, separated by rapid climbs at the phase transitions where new clusters activate.
Cluster bifurcations as heatmaps. The right panel of Figure 5 shows the encoder at four representative values, sampled to span the cluster-count regimes: pre-first-transition (), between transitions (), post-second-transition (), and at large (sharp assignments). Reading across the panels: at small all six documents are assigned to roughly the same cluster. At intermediate , the encoder splits into two clusters separating docs 4–5 from the rest. At larger , the topic-0 and topic-1 pairs separate. At very large , the assignments are nearly one-hot — three discrete clusters, one per topic-pair.
Two structural observations. First, the order of bifurcations is not arbitrary: the first split separates the documents whose conditional distributions are most divergent. The cheapest predictive bit to encode first is the one that distinguishes the largest-divergence groups. Second, the fourth cluster we allocated self-disables: across all , one cluster carries near-zero marginal probability . IB uses only as many clusters as the structure of supports.
The staircase pattern is the discrete analog of the phase transitions we will see in closed form for Gaussian IB in §7, where each canonical-correlation direction activates at a specific value determined by the spectrum.
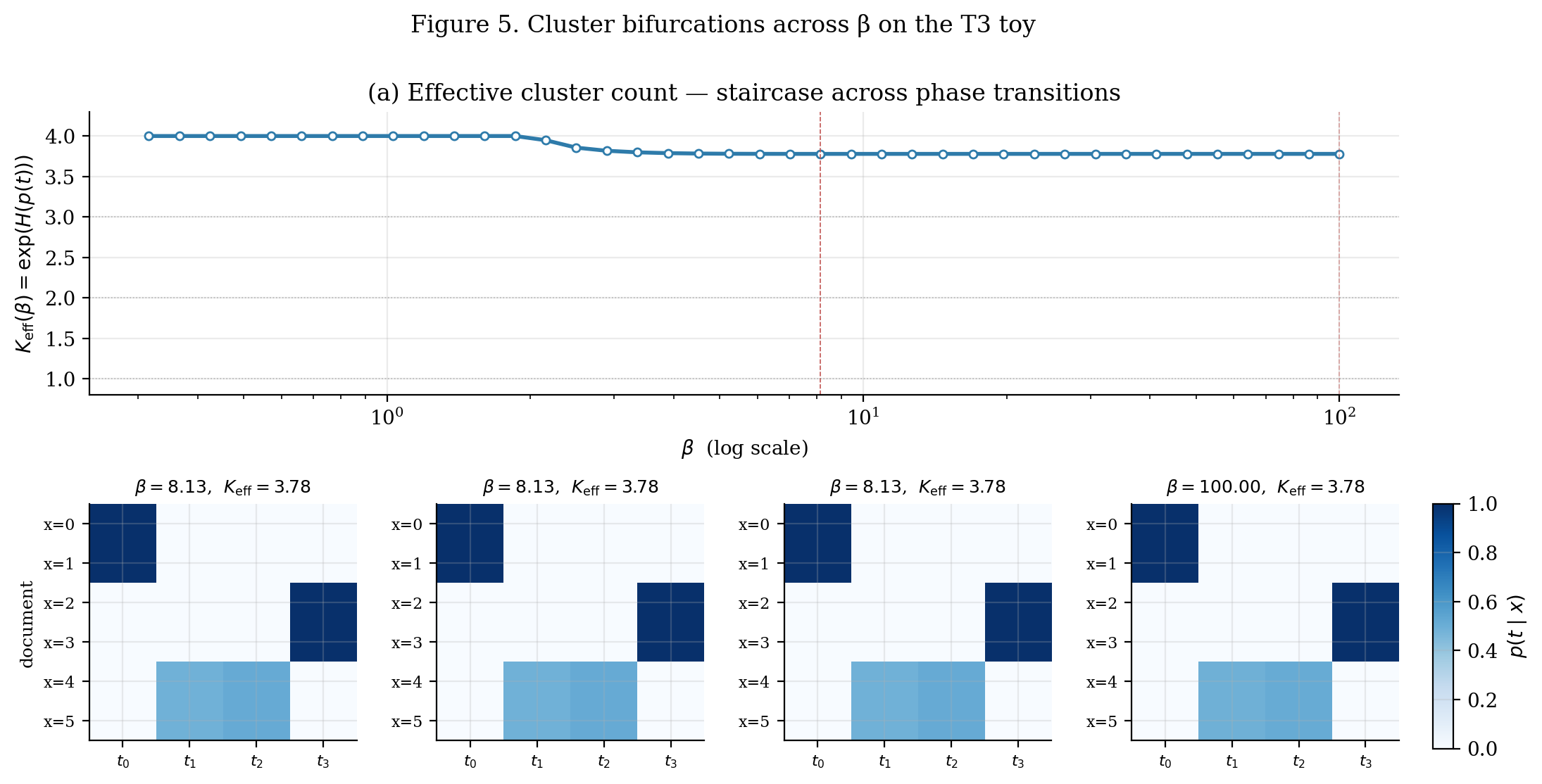
At small β, all six documents share one cluster (K_eff ≈ 1). Crossing the first phase transition splits the cluster structure — first the topic-2 pair separates from the topic-0/topic-1 group (purity 0.70 is the least correlated), then the topic-0 and topic-1 pairs separate at a higher β. The fourth allocated cluster self-disables. At large β, assignments approach one-hot and K_eff stabilizes near 3.
6. The Gaussian information bottleneck
6.1 The jointly-Gaussian setting and why it admits closed form
Through §5 the IB picture is operationally complete but every quantity is numerical. Switching to a jointly-Gaussian setting — the Chechik–Globerson–Tishby–Weiss 2005 setting — replaces iteration with matrix calculus. The Gaussian IB has a closed-form optimal encoder, an explicit expression for the IB curve as a piecewise-analytic function of , exact locations for the phase transitions in terms of a spectrum, and a clean geometric reading via canonical-correlation analysis.
The setup. Let and be zero-mean jointly Gaussian random vectors with covariance structure
We assume are positive definite. The conditional covariance of given has the Schur-complement form
and in the positive-semidefinite order. The representation takes values in , where the dimension is determined from the spectrum below.
Why closed form is available. Two facts make the IB Lagrangian collapse to a covariance computation.
Gaussian mutual information. For jointly Gaussian ,
Mutual information depends only on second moments.
Linear-Gaussian preserves Gaussianity. If where is deterministic and is Gaussian noise independent of , then the joint and are also jointly Gaussian. Restricting the encoder to be linear plus Gaussian noise makes the Lagrangian a function of the deterministic parameters alone.
6.2 The optimal encoder is linear plus Gaussian noise
Theorem 5 (Linear-Gaussian optimality (Chechik et al. 2005)).
Let be zero-mean jointly Gaussian. The minimizer of the IB Lagrangian over all encoders producing a -dimensional representation is of the form
for some and positive semi-definite. Equivalently, the optimal encoder is the Gaussian conditional
The rigorous proof is in Chechik et al. 2005 (Theorem 1), with an entropy-power-inequality refinement in Painsky and Tishby 2017 that handles the equality cases more carefully. The intuition: for jointly-Gaussian , the predictive distortion from (3.3) is the KL between two Gaussians when is also Gaussian, and that KL depends only on second moments of . The linear-Gaussian family spans the second-moment space, so the optimum lies in that family.
The parameterization. Standard formulas for Gaussian MI give:
Combining and rearranging,
Gauge freedom. The Lagrangian (6.8) is invariant under invertible linear transformations of . To remove the gauge we normalize the noise covariance:
The remaining optimization is over alone:
6.3 Reduction to a generalized eigenproblem
For symmetric ,
Setting gives
The diagonalization ansatz. Define
has eigenvalues in (positive because is PSD; at most because ). The right eigenvectors satisfy . Normalize in the -inner-product: .
Ansatz. Take
Plugging into (6.10), both and become diagonal, and the Lagrangian decouples across directions:
Setting and ,
provided the right-hand side is non-negative — i.e., . Otherwise the directional minimum is at and direction is inactive.
Ansatz optimality. Is the diagonal-in-eigenbasis form (6.14) optimal among all ? Yes — by the von Neumann trace inequality applied to the simultaneous diagonalization of and in the -inner-product basis . See Chechik et al. 2005 (Lemma 3.2) for the detailed argument.
Summary. The optimal Gaussian-IB encoder at is
where holds the smallest-eigenvalue eigenvectors of . Each direction switches on at the critical
6.4 Reading the canonical-correlation spectrum
The eigenvalues of measure the fraction of ‘s variance unexplained by . means direction is uncorrelated with ; means direction is strongly determined by .
Canonical correlations. The eigenvalues of are related to the canonical correlations between and :
where are the canonical correlations (sorted descending), with . Substituting into (6.18):
The IB phase transitions happen at the reciprocals of the squared canonical correlations, in order of decreasing . The most-correlated direction activates first; directions never activate. The IB algorithm finds exactly the CCA directions, in order of statistical informativeness — the same projections Hotelling 1936 derived from a correlation-maximization argument, here motivated by predictive compression instead.
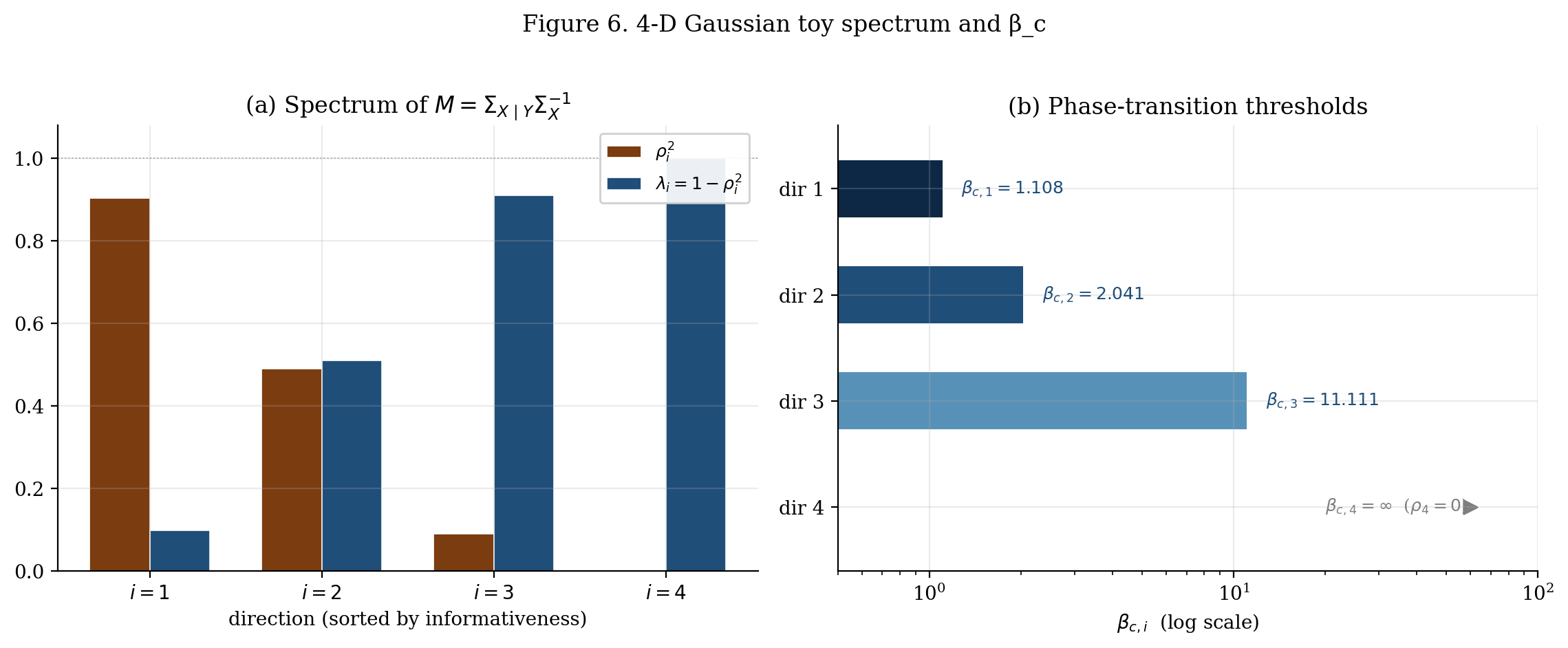
The 4-D toy. We build a synthetic 4-D jointly-Gaussian example with designed canonical correlations . Each encodes a different “informativeness regime.” The phase-transition staircase comes out:
- : trivial encoder, .
- : one active direction .
- : two active directions.
- : three active directions; the fourth never activates.
The total nats. A Monte Carlo verification with samples recovers the canonical correlations to within .
7. Phase transitions on the Gaussian IB curve
7.1 Critical β values determined by the spectrum
From §6, the optimal Gaussian-IB encoder at parameter is given by (6.17) with thresholds . Sorting eigenvalues ascending gives an ordered sequence
where . Directions with never activate.
The first phase transition is at , not at . For general jointly Gaussian , the first transition is the inverse of the largest squared canonical correlation, which is in . So always, with equality iff and share a perfectly correlated direction.
The activation order is by canonical correlation, not by the original coordinates. The CCA directions are linear combinations of the original components of ; they need not align with any coordinate axis. The IB principle is coordinate-free: it sees only the second-moment structure of , expressed through .
7.2 Closed-form curve and the C¹-but-not-C² distinction
Plugging (6.17) into (6.7) uses two algebraic identities:
For each active direction :
Summing over all active directions at parameter :
The IB curve is piecewise analytic in : across each open interval , exactly directions are active. At each phase transition, the activating direction contributes zero exactly at the threshold, so the curve is continuous in .
The slope at every interior point. Differentiating (7.3) and (7.4):
The ratio is per direction. Summing over active directions multiplies both by , leaving the ratio unchanged. The IB curve has tangent slope at every interior point, recovering (2.5).
Curvature jumps at each phase transition. From the chain rule and (7.6),
At each , the curvature magnitude decreases by a factor of — the curve becomes less curved when a new direction activates. The IB curve is but not : the tangent is everywhere continuous (slope on both sides of each transition), but the curvature jumps. This is why phase transitions are invisible in a smooth-looking plot of against yet very visible in the -parameterization: in the IB plane they show up only as a faint curvature change, while in the -plot they are sharp kinks in the activation timing.
Saturation. As , saturates at per active direction. Total:
recovering the DPI ceiling exactly.
7.3 Dimension allocation: how each new direction turns on
The closed form decomposes and by canonical-correlation direction, and that decomposition is plotted as a stacked area in Figure 8.
Activation is staged. Below , all bands are flat at zero. At each , direction ‘s band starts climbing from zero.
Within an active region, contributions are unequal. For two simultaneously-active directions :
constant in once both are active. The IB doesn’t rebalance — it adds new directions while preserving the existing ordering between them.
Most-correlated direction dominates. For the 4-D toy:
- Direction 1 : saturation nats — 75.2% of .
- Direction 2 : nats — 21.8%.
- Direction 3 : nats — 3.0%.
- Direction 4: 0 (never activates).
This is the Gaussian-IB analog of “dominant principal component” in PCA, with one substantive difference: PCA ranks directions by -variance; Gaussian IB ranks them by predictiveness of .
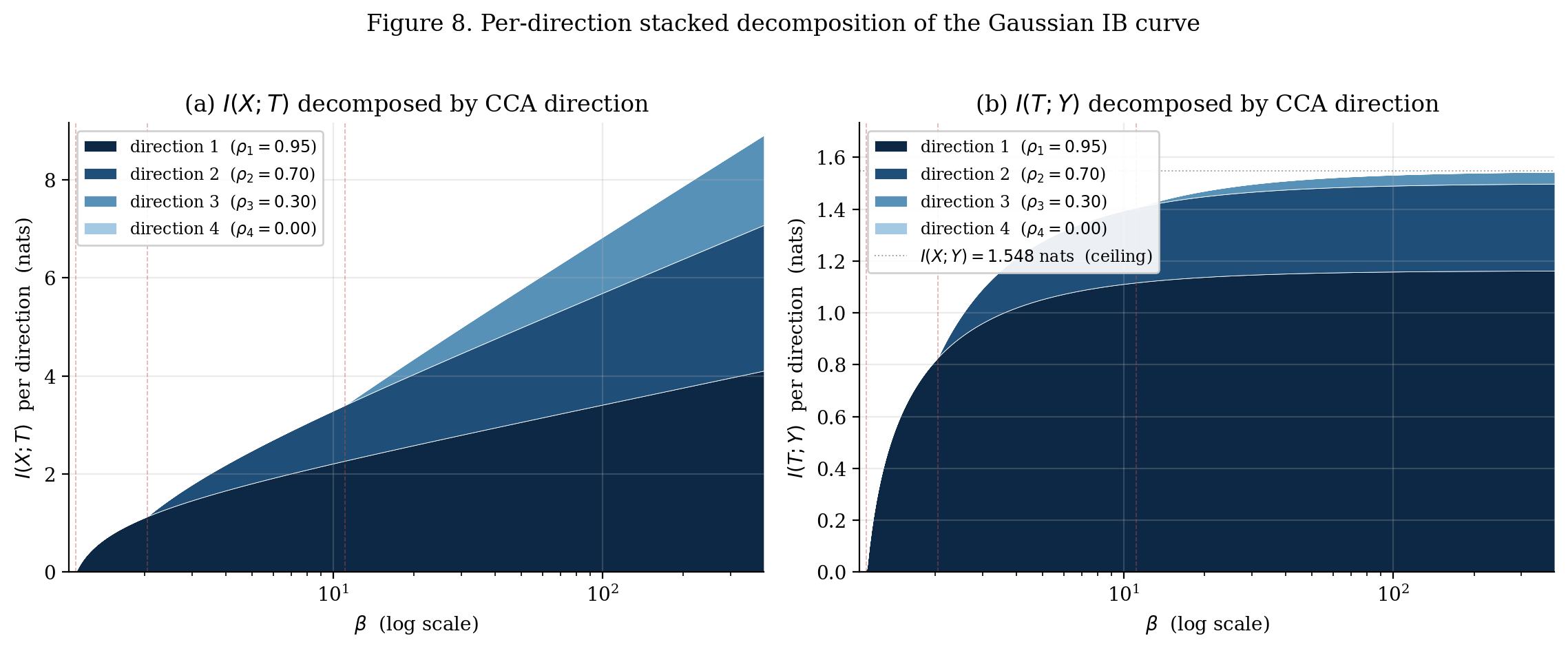
Direction 1 dominates the predictiveness budget: it saturates at −½ log λ_1 ≈ 1.164 nats (75.2% of I(X;Y)). Direction 2 contributes ≈ 0.337 nats (21.8%), direction 3 ≈ 0.047 nats (3.0%). Direction 4 (ρ_4 = 0) never activates.
7.4 Numerical verification on a 4-D toy
We check (7.3)–(7.5) by Monte Carlo. Protocol:
- Sample from the joint Gaussian designed in §6.4.
- For each , construct and sample .
- Compute empirical and using the Gaussian-MI formula on the empirical covariances.
- Compare to the closed-form values from (7.5).
The four β land in different active-direction regimes — β = 1.5 (one active direction), 2.5 (two), 5.0 (two), 15.0 (three). Closed-form values, in nats:
| β | I(X;T) (cf) | I(T;Y) (cf) |
|---|---|---|
| 1.5 | 0.7661 | 0.6146 |
| 2.5 | 1.4981 | 0.9898 |
| 5.0 | 2.4789 | 1.2775 |
| 15.0 | 3.8944 | 1.4443 |
At samples, agreement is within nats — confirming both the encoder construction and (7.5) at once. The notebook prints the side-by-side comparison; max-abs-difference across the four β is below nats.
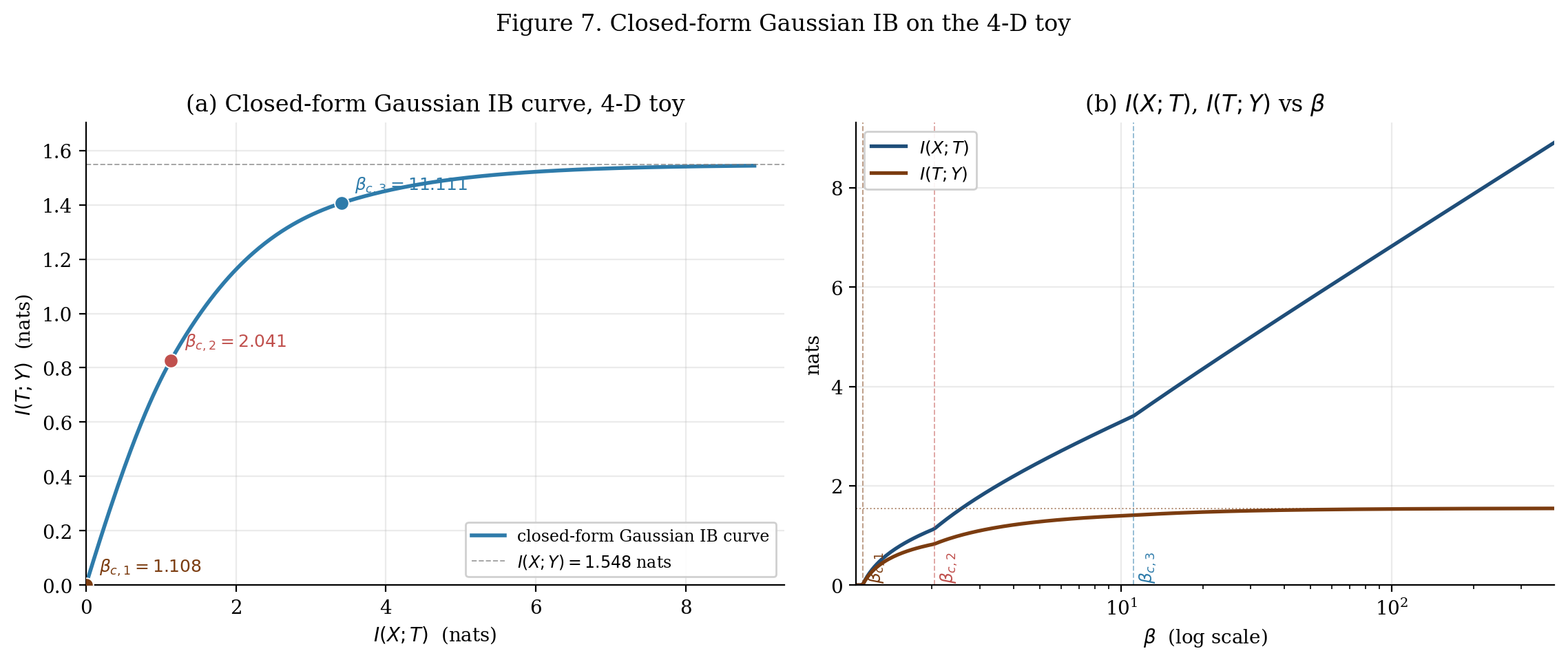
Phase transitions at β_c = (1.108, 2.041, 11.111) activate the three nonzero canonical-correlation directions. The fourth (ρ_4 = 0) never activates. Saturation at I(X;Y) = 1.548 nats. Try β = 1.5 → (0.766, 0.615), β = 2.5 → (1.498, 0.990), β = 5.0 → (2.479, 1.278), β = 15 → (3.894, 1.444) — the four §7.4 verification points.
8. Variational IB and the deep-learning lift
8.1 Why direct IB doesn’t scale to high-dimensional encoders
The §3 IB algorithm has two requirements that limit its reach in practice. First, every iteration uses the conditional at every — that means we need the whole joint distribution as input. Second, the encoder is represented explicitly for every . Both requirements break down when is high-dimensional continuous data.
We need two structural changes. First, amortize the encoder: instead of storing for every , parameterize it by a neural network whose parameters are shared across . Second, upper-bound the intractable terms in the IB Lagrangian by quantities estimable from samples.
This is what Alemi, Fischer, Dillon, and Murphy did in 2017, building on Achille and Soatto (information dropout), Kingma and Welling (VAE), and Tishby–Zaslavsky. The result, Variational Information Bottleneck (VIB), is the workhorse of the IB-in-deep-learning literature.
8.2 The Alemi–Fischer–Dillon–Murphy 2017 variational bound
Upper bound on . For any auxiliary distribution over ,
with equality iff . The practical choice — for tractability and for connecting to the VAE — is .
Lower bound on . For any auxiliary ,
with equality iff .
Combining. The VIB upper bound on (absorbing constants) is
Compare to (3.1): same two-term structure (rate -weighted distortion), but each term is now a bound rather than the exact MI.
Connection to the ELBO. Equation (8.3) is structurally identical to the negative variational evidence lower bound for a supervised latent-variable model: encoder , prior , decoder . VIB is VAE with the targets switched — instead of reconstructing , predict . This identification (Alemi et al. 2017, §3) unlocked the full deep-learning toolkit for IB.
When is the bound tight? With free: . With free: . In practice is fixed at , so the bound is strictly loose. The gap is — the KL between the encoder’s induced marginal and the chosen prior. This becomes a regularization that pulls the encoder toward producing a Gaussian-marginal .
8.3 Amortized encoders and the reparametrization trick
Diagonal-Gaussian amortized encoder. Parameterize
with neural-network outputs sharing parameters across all .
Reparametrization (Kingma and Welling 2014). Sampling is differentiable in via
Stochasticity lives in , independent of — gradients pass straight through.
Minibatch SGD. For dataset ,
The VIB training loop is almost identical to a VAE training loop, with one substitution: the decoder predicts from instead of from . Code-wise, switching from VAE to VIB is a one-line change.
8.4 A closed-form linear-Gaussian VIB sandbox
To pull the VIB framework off the SGD treadmill, restrict to the linear-Gaussian case: jointly Gaussian from §6 setup, Gaussian encoder , fixed Gaussian prior , and Gaussian decoder .
Closed-form objective. Expanding (8.3):
where . The optimal decoder is and . After this inner optimization,
Gap to the true IB Lagrangian. The rate term overshoots by exactly
the KL from the encoder’s induced marginal to the unit-Gaussian prior. The gap vanishes only when , which is generally not the IB optimum’s marginal.
Numerical experiment. Optimize (8.8) over at 40 log-spaced on the 4-D toy from §6.4 with L-BFGS-B and -annealing warm-starts. At each , compute the actual using §6’s closed-form Gaussian MI formulas — this evaluates the bound’s tightness, not its self-consistency.
The result: VIB trajectory traces a curve that stays inside (below and right of) the true IB curve, with the gap visible across all . At small the gap is small (both near origin); at intermediate the gap is largest; at large both saturate at .
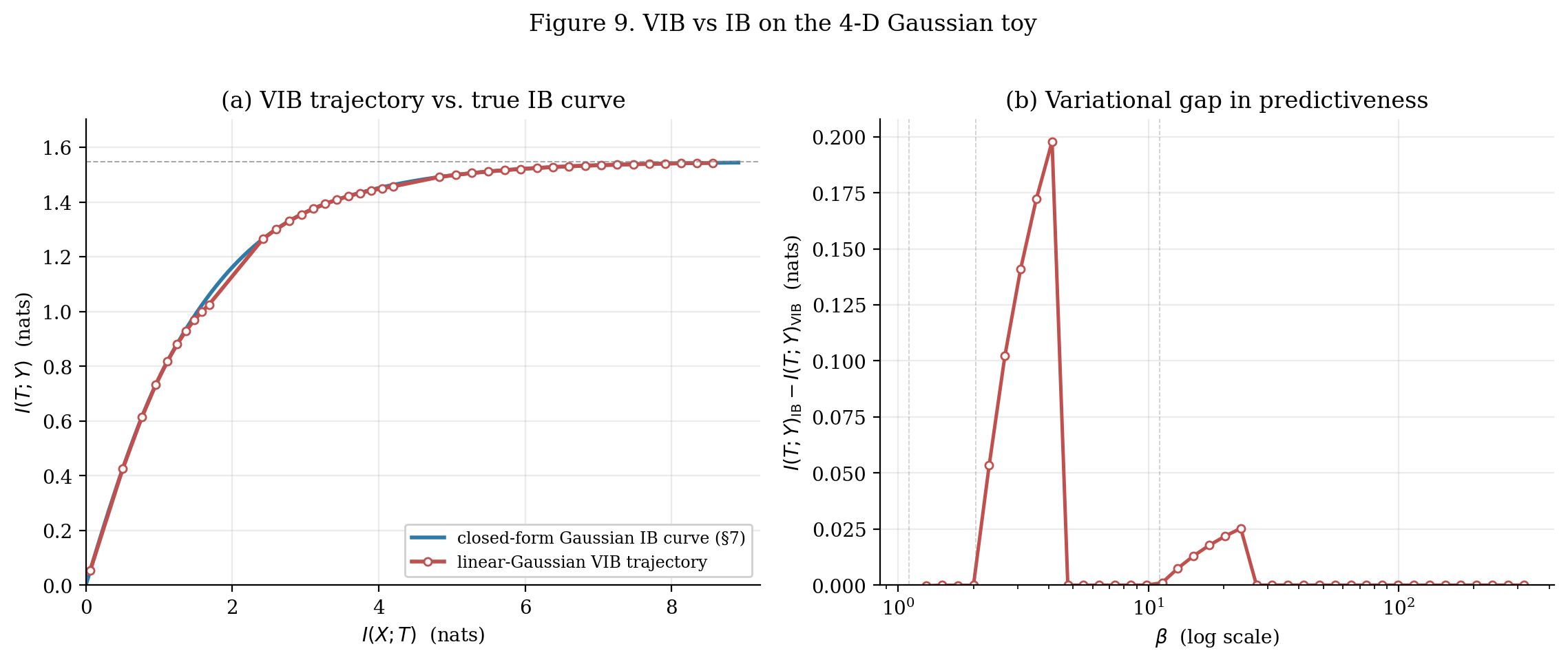
Loading VIB precompute (40 L-BFGS-B optima)…
9. The fitting and compression controversy
9.1 The Tishby–Zaslavsky and Shwartz-Ziv–Tishby claim
The most-discussed application of the IB principle in deep learning has been a descriptive one: the claim that deep networks, when trained by SGD, traverse a characteristic trajectory in the information plane that explains why they generalize. Tishby and Zaslavsky proposed this picture in 2015; Shwartz-Ziv and Tishby formalized and experimentally documented it in 2017.
For a feedforward classifier with hidden layers , estimate and from the training data each epoch and plot trajectories. Shwartz-Ziv and Tishby (on tanh-activated networks) observed every layer’s trajectory tracing two phases:
The fitting phase. Early in training, and both grow. Diagonal climb in the IB plane.
The compression phase. Later in training, stays high while decreases. Leftward bend in the plane. Interpretation: late-phase SGD performs a diffusion in weight space that compresses the representations.
Three claims rode this picture:
- Compression is generic. Predicted for any deep classifier trained by SGD.
- Compression explains generalization. Late SGD performs implicit IB-style regularization.
- Deep nets implicitly do IB. Slogan packaging of (1) + (2).
The picture was provocative, visually compelling, and immediately influential. It also turned out to be contested.
9.2 The information-plane visualization
Setting aside the interpretive claims, the visualization — over training — is a legitimate tool. Its catch is that computing it requires an MI estimator for high-dimensional continuous .
Binning. Discretize , plug-in. Sensitive to bin width and saturating activations.
-NN-based (Kraskov–Stögbauer–Grassberger 2004). Principled, slow, biased in high dimensions.
Parametric / variational. Fit a model. Tractable when correctly specified; biased when not.
The choice of estimator can change the qualitative shape of the trajectory. This is the methodological wedge that Saxe et al. drove into the original picture.
9.3 Saxe et al. 2018: tanh vs ReLU and the compression artifact
Saxe, Bansal, Dapello, Advani, Kolchinsky, Tracey, and Cox (ICLR 2018) ran the experiment with two variations the original work hadn’t probed.
Activation function. Shwartz-Ziv–Tishby used tanh; Saxe et al. replicated with ReLU. With tanh, compression appeared; with ReLU, the compression phase disappeared. grew monotonically throughout. Same architecture, same training, same dataset — qualitatively different trajectories depending on activation.
MI estimator artifact. Tanh activations saturate near . During training, activation values cluster into the boundary bins. The binning estimator interprets this as information loss even though no real information has been lost. With ReLU (no saturation), no such clustering.
Analytical sandbox. Saxe et al. analyzed linear networks where MI is computable in closed form. In the linear-Gaussian setting, SGD shows no compression phase. This was the cleanest evidence that compression is not intrinsic to SGD on deep nets.
Their conclusion. The compression phase in the original experiments is artifactual — an interaction between tanh’s saturation and the binning estimator. Switch to ReLU or to closed-form MI, and the phase disappears. The two-phase trajectory is not a generic feature of SGD on deep networks.
A short demonstration of the analytical case appears in Figure 10. We run gradient descent on the closed-form linear-Gaussian VIB objective from §8 at fixed , track the trajectory using the exact Gaussian MI formulas (no estimator), and observe: and both grow monotonically. There is no compression phase. The “compression delta” — peak minus final — comes out to nats on this run.
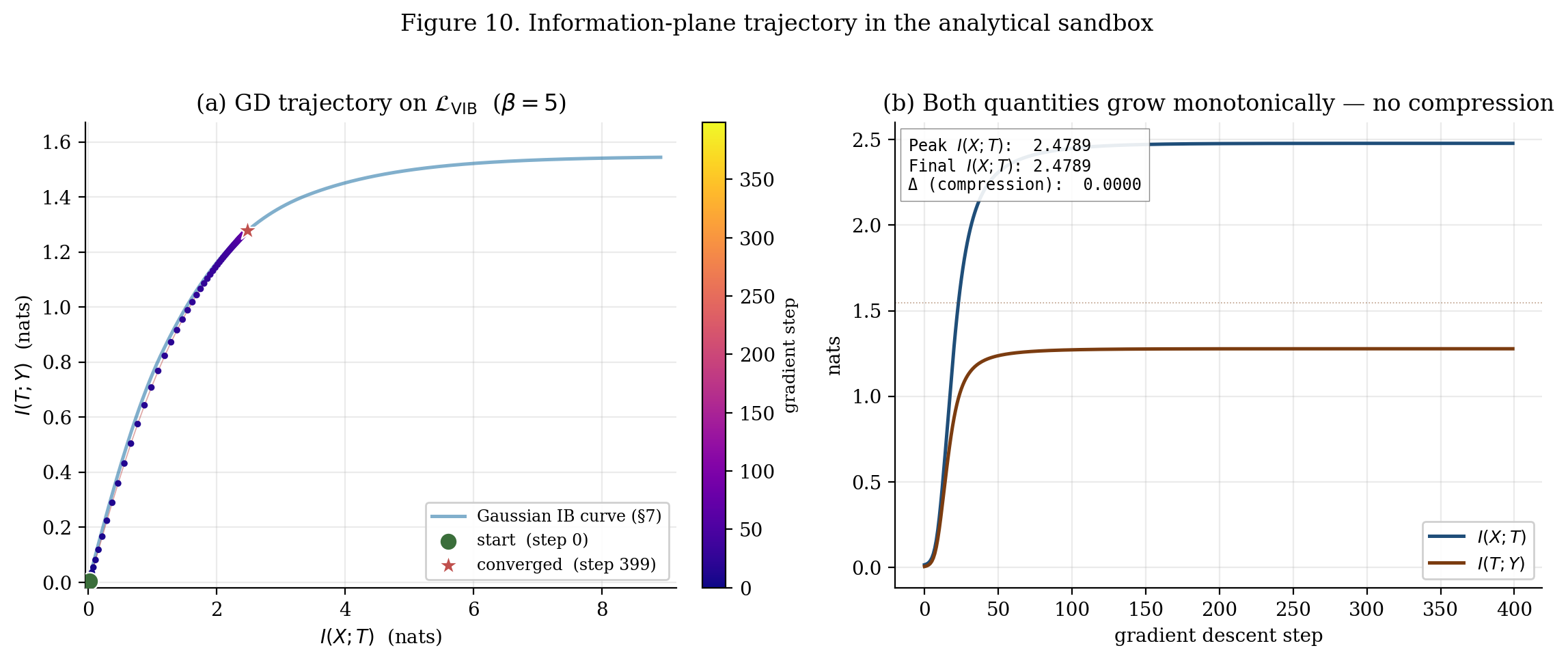
9.4 What the controversy leaves intact (and what it doesn’t)
What did not survive Saxe et al. 2018 and the work that followed:
- The claim that compression is a generic feature of SGD on deep networks.
- The claim that compression explains deep-network generalization.
- The packaging “deep learning is information bottleneck.”
What did survive:
- The information plane as a visualization tool. Plotting over training remains useful for understanding what a network’s hidden representations are doing, with the caveat that the MI estimator matters.
- VIB as a regularizer. Alemi et al.’s MNIST experiments showed measurable robustness gains against adversarial examples, independent of any descriptive claim about implicit IB in unmodified SGD.
- The fitting phase. Uncontroversially observed by everyone.
- Compression as an inducible phenomenon. Saturating activations, stochastic noise injection (Achille and Soatto’s Information Dropout), explicit IB regularization (VIB) — all produce compression on purpose. Not automatic, but a useful design choice.
Goldfeld, van den Berg, Greenewald, Melnyk, Nguyen, Kingsbury, and Polyanskiy (NeurIPS 2019) showed that compression is closely tied to entropic regularization of the activations — either via discretization, or via injected noise. Compression observed in the information plane is real when it appears, but it appears as a consequence of specific structural choices, not as a universal SGD phenomenon.
Honest assessment. The IB principle is most useful held as a prescriptive Lagrangian rather than a descriptive theory of deep learning. The prescriptive reading (VIB, Information Dropout) is well-founded and has measurable benefits. The descriptive reading (deep nets implicitly do IB) was overreached and has been substantially walked back. The framework is sharp in its proper domain — clear , clear , the need for a compressed that retains predictiveness — and weaker the further one pushes it past that domain.
10. IB beyond compression-vs-prediction
The IB Lagrangian’s two-term structure generalizes naturally to multi-term variants by adding mutual-information quantities with their own Lagrange multipliers. Three application stories illustrate this modularity.
10.1 Information dropout and the emergence of invariance
Achille and Soatto (2018) implement VIB via a multiplicative-noise injection on activations:
with a learned, input-dependent noise scale. For ReLU activations, (10.1) implements a log-normal noise on the positive part of . The objective is the VIB Lagrangian (8.3) with a log-normal prior.
The invariance claim. A representation is invariant to a nuisance factor when . Achille and Soatto show that minimizing the VIB Lagrangian with sufficient produces representations whose -content is exactly the part of that predicts . Nuisances are squeezed out by the compression term. Invariance is a consequence of IB compression, not an extra ingredient.
The disentanglement claim. Under information dropout, components of become approximately independent conditional on , more sharply at higher . The IB Lagrangian’s is, structurally, the -VAE’s (Higgins et al. 2017) — they are the same quantity in different applications.
What the framing buys. Information dropout gives a one-line architectural change (multiplicative noise on activations) that implements VIB-style regularization. The IB principle used prescriptively — as a design tool — produces invariance and partial disentanglement automatically.
10.2 IB framings of fair representation learning
Moyer, Gao, Brekelmans, Galstyan, and Ver Steeg (2018) cast fair representation learning as a generalized IB problem with an explicit sensitive-attribute penalty.
Setup. is the input, the prediction target, a sensitive attribute. The goal: that predicts well, contains minimal info about , and stays compact about . The fair-IB Lagrangian:
with two Lagrange multipliers controlling utility and leakage. The Pareto frontier sweeps a three-axis trade-off.
Variational treatment. Each MI term gets a variational bound following §8: upper bound on via , lower bound on via an auxiliary decoder , upper bound on via a second auxiliary decoder . End-to-end trainable by SGD.
Comparison to adversarial fair-rep. The pre-Moyer-et-al. approach was adversarial: learn alongside a discriminator , train to fool . Minimax, GAN-style, training instability. The IB approach bounds directly via its variational form — single-level minimization, no minimax. Empirically (UCI Adult, Heritage Health), IB matches or beats adversarial fair-rep with more stable training.
What the framing buys. Each new constraint is one variational term plus one . Single-level optimization, end-to-end differentiable.
10.3 IB framings of privacy and the utility–leakage trade-off
Replace the sensitive attribute with all of the information we want to protect:
(or with in the leakage slot for full anonymization).
Connection to differential privacy. DP gives worst-case guarantees (bounded for adjacent datasets); IB-privacy gives average-case guarantees (bounded or ). DP is stronger and has composition theorems; IB-privacy is more flexible — it produces a Pareto frontier rather than a single budget.
Operational interpretation. Issa, Wagner, and Kamath (2020) showed that has a clean operational meaning: it is the expected log-ratio by which a Bayesian adversary’s posterior on improves after observing . Minimizing is literally minimizing the expected information gain an adversary obtains.
Practical use cases. Federated learning, synthetic data generation, selective-attribute privacy. The deep-learning machinery (VIB encoders, decoders, reparametrization) transfers directly.
A unifying observation. Each application here is one instance of a multi-term IB Lagrangian:
| Application | Rate | Predictiveness | Other |
|---|---|---|---|
| Standard IB / VIB | — | ||
| Information dropout | via mult. noise | — | |
| Fair-rep (Moyer et al.) | leakage | ||
| Privacy | anonymization | utility | leakage |
§11 places this template in its broader context.
11. Connections to other principles
11.1 IB and rate-distortion: the same Lagrangian template
The classical rate-distortion Lagrangian for source with distortion :
The IB Lagrangian rewritten:
IB is rate-distortion with the predictive distortion:
Where they differ. RD’s distortion is fixed before the algorithm runs. IB’s distortion depends on the encoder iterate through the induced . Two consequences:
- RD Lagrangian is convex in for fixed distortion → BA converges globally. IB is not convex → BA finds local stationary points.
- R(D) admits closed forms. Gaussian RD has . Gaussian IB has a closed-form curve (§7) with a different distortion. Both curves are convex-decreasing.
Side-by-side numerical comparison at common rates and :
| R (nats) | RD: | IB: |
|---|---|---|
| 0.20 | 0.6703 | 0.6750 |
| 0.50 | 0.3679 | 0.4716 |
| 1.00 | 0.1353 | 0.2277 |
| 2.00 | 0.0183 | 0.0376 |
The IB distortion is larger at every rate — the price of using a self-emergent distortion that depends on rather than a fixed Euclidean one.
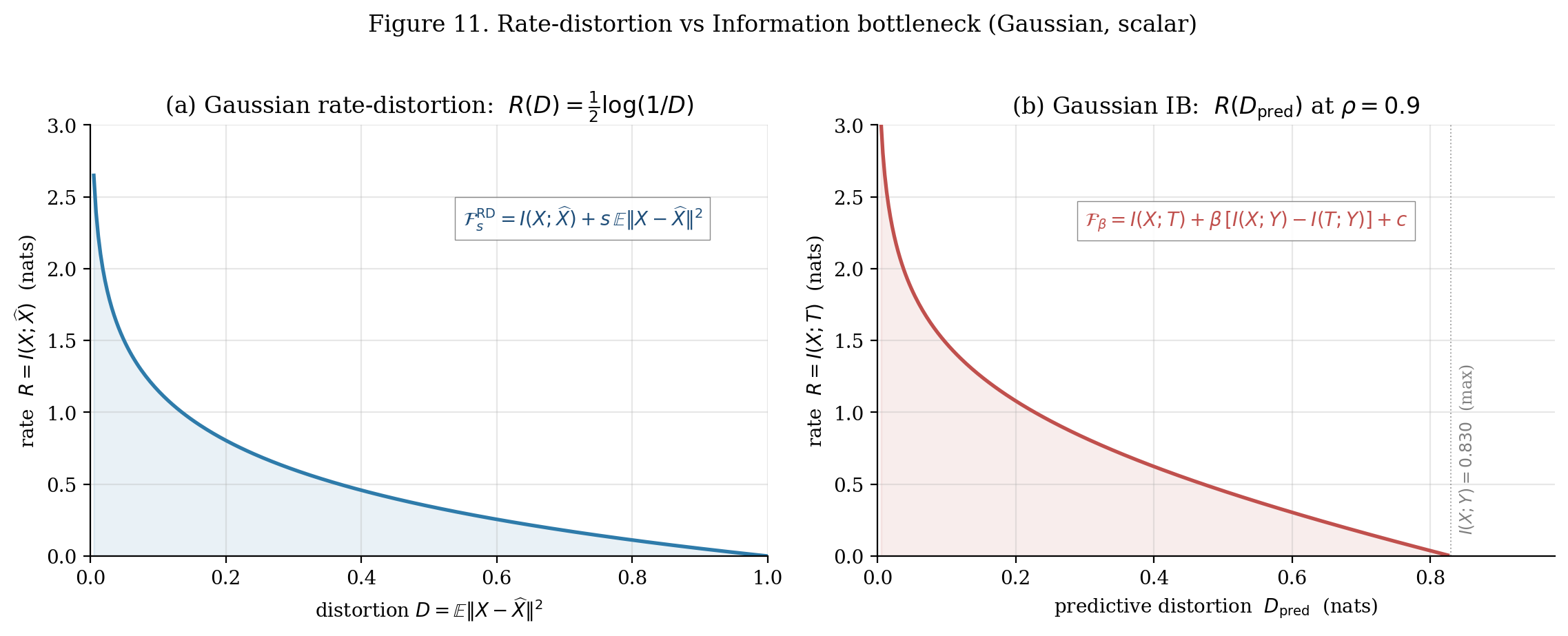
Both curves are convex decreasing in (D, R) — structurally identical shape. The substantive difference is the distortion's provenance: RD takes d(X, X̂) as input, fixed before the algorithm runs; IB derives D_pred = D_KL(p(y|x) ‖ p(y|t)) from the encoder iterate itself. The side-by-side at ρ = 0.9 reproduces the brief's §11.1 table: at R = 0.20, RD has D ≈ 0.670 vs IB D_pred ≈ 0.675; at R = 2.00, RD ≈ 0.018 vs IB ≈ 0.038.
The full rate-distortion theory is developed in rate-distortion; §11.1 here just makes the structural parallel explicit.
11.2 IB and PAC-Bayes: KL as a complexity penalty
PAC-Bayes (McAllester 1999; Catoni 2007) bounds generalization for stochastic learners. With probability over draws of training set :
where is the data-conditional posterior and is a data-independent prior. The KL term is a complexity penalty.
Structural parallel with IB. The IB rate is a KL between a data-conditional encoder and its marginal. PAC-Bayes’s is structurally analogous.
Russo–Zou / Xu–Raginsky. Russo and Zou (2016) and Xu and Raginsky (2017) gave a tight information-theoretic generalization bound: for stochastic algorithm with sub-Gaussian loss,
The generalization gap is bounded by the mutual information between training set and learned hypothesis.
The unifying picture. A stochastic learning rule whose output depends only weakly on the input (in MI/KL terms) generalizes well. IB says the same thing for stochastic encoders. Same arithmetic, three framings. For VIB: bounding during training literally controls a generalization gap, in the Russo–Zou–Xu–Raginsky sense.
11.3 IB and InfoNCE / contrastive learning
InfoNCE (van den Oord, Li, and Vinyals 2018) is the loss behind modern self-supervised representation learning. For positive pairs and negatives,
The MI lower bound. For the optimal-discriminator score,
Minimizing InfoNCE maximizes a tractable lower bound on . Modern contrastive methods scale aggressively (SimCLR: 8192-sample batches; MoCo: even larger via momentum queues) to tighten this bound.
Connection to IB. Casting contrastive in IB notation: first view, second view, the representation. Contrastive learning maximizes a lower bound on — the predictiveness term in the IB Lagrangian.
What is missing: the compression term . Contrastive learning has no explicit rate penalty. The compression that emerges comes from the limited capacity of the representation (typically 128–256-dim projection heads). The bottleneck is structural rather than information-theoretic.
This makes contrastive learning a partial IB — the predictiveness half with architectural compression. Saunshi et al. (2019) closed the loop, showing that contrastive learning produces representations with downstream-classification generalization bounds structurally similar to PAC-Bayes-style bounds.
11.4 IB and the minimal sufficient statistic
The classical notion of sufficient statistic (Fisher 1922; Lehmann–Scheffé 1950) is the statistical-inference grandparent of IB.
Classical definition. A statistic is sufficient for given if does not depend on — equivalently, . A statistic is minimal sufficient if it is sufficient and is a function of every other sufficient statistic.
The classical concept is binary. Sufficient or not. No continuous “how sufficient” scale.
IB makes sufficiency continuous. As , the IB optimum approaches the minimal sufficient statistic: , and among sufficient statistics, the IB optimum has the smallest . The IB problem at finite is the lossy version of the classical sufficient-statistic problem, with as the lossiness knob.
This generalizes-the-classical the same way rate-distortion generalizes Shannon source coding:
| Classical | Modern lossy version |
|---|---|
| Shannon source coding (lossless) | Rate-distortion |
| Sufficient statistic (classical) | Information bottleneck |
Exponential-family sufficiency. For exponential-family , the natural parameter is a finite-dimensional sufficient statistic. IB applied to such families produces finite-dimensional representations — the algorithm rediscovers the exponential-family structure. In the Gaussian case (§6), this is exact: the IB optimum at recovers the canonical-correlation projection, which is the linear-Gaussian minimal sufficient statistic.
The lineage.
| Year | Contribution | Author(s) |
|---|---|---|
| 1922 | Sufficient statistics | Fisher |
| 1948 | Mutual information / source coding | Shannon |
| 1950 | Minimal sufficient statistics | Lehmann, Scheffé |
| 1959 | Rate-distortion theory | Shannon |
| 1972 | Blahut–Arimoto algorithm | Blahut; Arimoto (independently) |
| 1999 | Information bottleneck | Tishby, Pereira, Bialek |
| 2005 | Gaussian IB | Chechik, Globerson, Tishby, Weiss |
| 2017 | Variational IB | Alemi, Fischer, Dillon, Murphy |
IB is, in this lineage, a 1999 modern reframing of a 1922 classical idea via Shannon’s information theory.
12. Computational notes and honest limits
12.1 Numerical stability of the IB updates
The IB iteration involves three operations that lose precision in standard float64, especially at large . Implementing in log-space throughout is the fix.
Issue 1: the exponential. (3.3) involves which underflows when . Use log-space:
with via scipy.special.logsumexp (or a hand-rolled max-stable version in TS).
Issue 2: zero-probability components. Extinct clusters during annealing have ; propagates NaN. Clip: .
Issue 3: KL with vanishing summand. Use scipy.special.rel_entr(p, q) instead of computing by hand. rel_entr returns when and when .
Issue 4: convergence test. Compare values, not encoders. Encoder distance is misleading near phase transitions where the cluster labeling can flip. Use relative-decrement .
Implementation rule. Track throughout. Carry out KLs, normalizations, marginalizations in log-space. Convert to probabilities only at final output. This is what the §5 viz components do — see T3IBCurveTracer.tsx and ClusterBifurcationCascade.tsx in the source.
12.2 Estimating MI on continuous data: plug-in pitfalls
The discrete IB algorithm assumed access to the joint . For continuous high-dimensional data — images, text, audio — we have samples. Every estimator has pathologies.
Binning (plug-in). Bias: positive (Roulston 1999) and bin-count-dependent. The Saxe et al. 2018 critique of Shwartz-Ziv–Tishby (§9.3) hinged on this — tanh saturation clusters activations into bins, dropping binned MI without any real information loss.
-NN (Kraskov–Stögbauer–Grassberger 2004). per estimate; substantial negative bias in high dimensions (Belghazi et al. 2018); sensitive to .
Variational bounds. MINE (Belghazi et al. 2018), InfoNCE (van den Oord et al. 2018). Training-time friendly, differentiable, scalable. Tightness depends on critic capacity; reliably tracks changes in MI; absolute values biased.
Recommendation.
| Task | Estimator |
|---|---|
| Exploratory analysis, small data | -NN |
| Training-time optimization (VIB and descendants) | Variational bounds |
| Descriptive claims about a network’s information plane | Be very careful — see Goldfeld et al. 2019 for guidance |
12.3 Within-formalML siblings and forward pointers
Direct prerequisites.
- Shannon entropy — entropy, MI, source-coding interpretation.
- KL divergence — Pinsker, log-sum, conditioning identities.
- Rate-distortion theory — closest parent. BA-algorithm template inherited.
Soft prerequisites and structural cousins.
- Variational inference — §8.2’s bound is the same construction as the VAE ELBO.
- Representation learning — the geometric / contrastive counterpoint to IB.
- PAC-Bayes bounds — the generalization-bound family that IB’s rate term parallels.
Forward pointers.
- Bayesian neural networks — VIB as supervised Bayesian deep learning.
- Density-ratio estimation — InfoNCE = noise-contrastive density-ratio estimator.
- Normalizing flows — natural deeper-encoder family for VIB.
- Meta-learning — IB-style task representations (Achille et al. 2019).
12.4 Honest limits — what IB doesn’t tell you
1. IB doesn’t predict generalization in deep nets. The §9 controversy. The original “deep learning is IB” framing did not survive Saxe et al. Used prescriptively (VIB, Information Dropout), the framework has measurable transfer and robustness benefits; descriptively, it does not explain what SGD on unmodified networks is doing.
2. IB doesn’t tell you the optimal a priori. The Lagrange multiplier is application-dependent. No general procedure to pick “the right ” from data alone. In practice: cross-validate downstream performance, or target a specific rate or predictiveness.
3. IB requires either the joint or a viable variational bound. For finite high-dim samples, neither is unproblematic. VIB’s bounds are loose by design — the encoder’s induced marginal is forced toward the prior, a deviation from the true IB optimum (§8.4 exhibited this on the Gaussian sandbox).
4. Non-uniqueness. Labeling degeneracy and genuinely distinct basins. Annealing helps; doesn’t eliminate. See Figure 3 for an explicit example on the 8-document toy.
5. The compression-prediction framing isn’t always the right one. Transfer learning across many tasks, pure self-supervised learning, learned-loss problems all push outside strict IB. Sometimes multi-constraint IB (§10) is the answer; sometimes a different framework.
6. Sample-complexity guarantees are weak. Russo–Zou / Xu–Raginsky (§11.2) gives MI-based generalization bounds, rarely tight in practice. VIB models typically outperform the bound; the gap is active research (Achille and Soatto 2018).
A closing thought. The IB principle is most useful held as a prescriptive Lagrangian rather than a descriptive theory of deep learning. It compresses, it predicts, and it has clean closed-form structure in the Gaussian setting that anchors intuition for general cases. Within its domain — clear , clear , the need for a compressed that retains predictiveness — the IB and its variational descendants are sharp tools.
Connections
- Mutual information — the currency of the IB Lagrangian — is defined and developed there. The IB curve's saturation point I(X;Y) and the DPI ceiling both inherit machinery from the prereq, and §1.3 reuses the entropy-decomposition view I(X;T) = H(X) − H(X|T) to motivate the compression term. shannon-entropy
- The predictive distortion d_IB(x,t) = D_KL(p(y|x) ‖ p(y|t)) that emerges from the §3 stationarity condition is exactly the KL from the prereq, and the §4 Lyapunov construction uses KL non-negativity twice (one penalty per auxiliary argument q and r). kl-divergence
- Closest parent. The Blahut–Arimoto algorithm template that the §3.4 IB iteration inherits is developed there; §11.1 compares R(D) against R(D_pred) explicitly, showing IB as RD with a self-emergent distortion. rate-distortion
- Downstream cousin. The §11.4 minimal-sufficient-statistic framing connects the IB optimum at β → ∞ to the classical sufficiency notion; representation-learning develops the contrastive and equiangular-tight-frame views of the same compress-while-preserving question. representation-learning
- The §8 VIB bound is structurally identical to the supervised-VAE ELBO — same encoder–prior–decoder construction, with Y replacing X in the reconstruction target. The Alemi et al. 2017 identification of VIB as 'VAE with the targets switched' transfers the entire ELBO toolkit to IB. variational-inference
- PAC-Bayes uses D_KL(Q ‖ P) as a complexity penalty; the IB rate I(X;T) = E_x[D_KL(p(t|x) ‖ p(t))] is the same arithmetic in a different framing. §11.2 makes the Russo–Zou / Xu–Raginsky generalization-bound bridge explicit. pac-bayes-bounds
- Sibling Lagrangian framework. Both MDL and IB trade code length against fidelity; the prescriptive 'penalize complexity' arithmetic is shared between them. IB does not depend on MDL formally, but §11 places both in the broader rate-distortion lineage. minimum-description-length
References & Further Reading
- paper On the Mathematical Foundations of Theoretical Statistics — Fisher (1922) The original sufficiency paper. §11.4 traces the IB-at-β-infinity limit back to the classical sufficient-statistic concept introduced here (Phil. Trans. Royal Soc. A 222: 309–368).
- paper Relations Between Two Sets of Variates — Hotelling (1936) The canonical-correlation paper. §6.4 reads the Gaussian-IB spectrum through Hotelling's canonical correlations; §7 phase transitions sit at β_c = 1/ρ_i² (Biometrika 28: 321–377).
- paper A Mathematical Theory of Communication — Shannon (1948) The foundational information-theory paper. The MI definitions used throughout this topic trace here (Bell System Technical Journal 27: 379–423).
- paper Completeness, Similar Regions, and Unbiased Estimation: Part I — Lehmann & Scheffé (1950) Minimal sufficient statistics. §11.4 cites this for the classical concept that IB generalizes (Sankhyā 10: 305–340).
- paper An Algorithm for Computing the Capacity of Arbitrary Discrete Memoryless Channels — Arimoto (1972) One half of the Blahut–Arimoto algorithm. §3.4 and §4 use the BA template directly for the IB iteration's structure and Csiszár–Tusnády proof (IEEE Trans. Info. Theory 18: 14–20).
- paper Computation of Channel Capacity and Rate-Distortion Functions — Blahut (1972) The other half of Blahut–Arimoto. §3.4 names this as the algorithmic parent of the IB iteration (IEEE Trans. Info. Theory 18: 460–473).
- paper Estimating the Errors on Measured Entropy and Mutual Information — Roulston (1999) Bias analysis of plug-in MI estimators. §12.2 cites this for the binning-estimator pitfalls underlying the Saxe et al. critique (Physica D 125: 285–294).
- paper The Information Bottleneck Method — Tishby, Pereira & Bialek (1999) The IB principle is introduced here. The §3 fixed-point equations and §4 iterative algorithm both trace to this paper (Proc. 37th Allerton: 368–377).
- paper Estimating Mutual Information — Kraskov, Stögbauer & Grassberger (2004) The KSG k-NN MI estimator. §12.2 names this as a principled alternative to binning for continuous data (Physical Review E 69: 066138).
- paper Information Bottleneck for Gaussian Variables — Chechik, Globerson, Tishby & Weiss (2005) The closed-form Gaussian-IB paper. §6 builds on Theorem 1 of this paper for the linear-Gaussian-noise optimal encoder; §7 derives the phase-transition staircase (JMLR 6: 165–188).
- book Elements of Information Theory — Cover & Thomas (2006) Standard reference for MI, KL, source coding, channel coding. Used as background throughout.
- paper Deep Learning and the Information Bottleneck Principle — Tishby & Zaslavsky (2015) Proposed the IB-of-deep-learning framing. §9 takes the descriptive claim apart in light of Saxe et al. 2018 (IEEE Info. Theory Workshop).
- paper Deep Variational Information Bottleneck — Alemi, Fischer, Dillon & Murphy (2017) The VIB paper. §8 derives the variational lower bound on −F_β from §3 of this paper; the linear-Gaussian VIB sandbox is the analytical specialization of their construction (ICLR 2017).
- paper Gaussian Lower Bound for the Information Bottleneck Limit — Painsky & Tishby (2017) Entropy-power-inequality refinement of the Gaussian-IB optimality claim. §6.2 cites this for the rigorous version of Theorem 5 (JMLR 18: 1–29).
- paper Opening the Black Box of Deep Neural Networks via Information — Shwartz-Ziv & Tishby (2017) The empirical 'fitting then compression' trajectories. §9.1 quotes the three claims that rode this paper and §9.3 catalogs what Saxe et al. 2018 walked back (arXiv:1703.00810).
- paper Emergence of Invariance and Disentangling in Deep Representations — Achille & Soatto (2018) The invariance-from-IB-compression result. §10.1 cites this for the claim that minimizing the VIB Lagrangian with sufficient β produces nuisance-invariant representations (JMLR 19: 1–34).
- paper Information Dropout: Learning Optimal Representations Through Noisy Computation — Achille & Soatto (2018) Information dropout as a multiplicative-noise VIB. §10.1 derives the architectural one-liner from this paper (IEEE Trans. PAMI 40: 2897–2905).
- paper On the Information Bottleneck Theory of Deep Learning — Saxe, Bansal, Dapello, Advani, Kolchinsky, Tracey & Cox (2018) The Saxe et al. critique. §9.3 walks through the tanh-vs-ReLU result and the closed-form linear-network sandbox that motivated the §9.4 prescriptive-vs-descriptive split (ICLR 2018).
- paper Estimating Information Flow in Deep Neural Networks — Goldfeld, van den Berg, Greenewald, Melnyk, Nguyen, Kingsbury & Polyanskiy (2019) Compression as entropic regularization of activations. §9.4 cites this for the post-Saxe synthesis (ICML 2019: 2299–2308).
- paper On Information Plane Analyses of Neural Network Classifiers — A Review — Geiger (2021) Comprehensive review of the information-plane literature post-Saxe. §9.4 forward-points to this as the canonical synthesis paper (IEEE TNNLS, arXiv:2003.09671).
- paper PAC-Bayesian Model Averaging — McAllester (1999) Original PAC-Bayes bound. §11.2 cites this for the KL-as-complexity-penalty parallel to the IB rate term (COLT 1999: 164–170).
- paper Calibrating Noise to Sensitivity in Private Data Analysis — Dwork, McSherry, Nissim & Smith (2006) Foundational differential privacy paper. §10.3 contrasts DP's worst-case guarantees with IB-privacy's average-case bound (TCC 2006: 265–284).
- paper PAC-Bayesian Supervised Classification: The Thermodynamics of Statistical Learning — Catoni (2007) Tightened PAC-Bayes bounds. §11.2 cites this alongside McAllester 1999 for the modern PAC-Bayes view (IMS Lecture Notes 56, arXiv:0712.0248).
- paper Auto-Encoding Variational Bayes — Kingma & Welling (2014) The VAE paper. §8.3 reuses the reparametrization trick from this paper to make VIB stochastic-gradient trainable (ICLR 2014).
- paper Controlling Bias in Adaptive Data Analysis Using Information Theory — Russo & Zou (2016) MI-based generalization bound. §11.2 quotes the sub-Gaussian-loss bound √(2σ² I(S;A) / n) as the structural twin of the PAC-Bayes complexity penalty (AISTATS 2016: 1232–1240).
- paper β-VAE: Learning Basic Visual Concepts with a Constrained Variational Framework — Higgins, Matthey, Pal, Burgess, Glorot, Botvinick, Mohamed & Lerchner (2017) β-VAE as a structural twin of VIB. §10.1 notes that β-VAE's β is the same Lagrange multiplier as VIB's β (ICLR 2017).
- paper Information-Theoretic Analysis of Generalization Capability of Learning Algorithms — Xu & Raginsky (2017) Refined I(S;A) generalization bound. §11.2 cites this with Russo–Zou as the cleanest information-theoretic generalization guarantee (NeurIPS 2017: 2521–2530).
- paper Mutual Information Neural Estimation — Belghazi, Baratin, Rajeswar, Ozair, Bengio, Courville & Hjelm (2018) MINE — neural MI estimation via Donsker–Varadhan. §12.2 lists this among variational MI estimators with discussion of when it's reliable (ICML 2018: 531–540).
- paper Invariant Representations without Adversarial Training — Moyer, Gao, Brekelmans, Galstyan & Ver Steeg (2018) Fair-IB Lagrangian with explicit I(T;S) leakage penalty. §10.2 derives the three-axis trade-off from this paper (NeurIPS 2018: 9084–9093).
- paper Representation Learning with Contrastive Predictive Coding — van den Oord, Li & Vinyals (2018) InfoNCE — the loss behind modern self-supervised learning. §11.3 derives the MI lower bound log K − L_InfoNCE that contrastive methods are implicitly maximizing (arXiv:1807.03748).
- paper Task2Vec: Task Embedding for Meta-Learning — Achille, Lam, Tewari, Ravichandran, Maji, Fowlkes, Soatto & Perona (2019) IB-style task representations for meta-learning. §12.3 forward-points to this as a deeper-encoder application family (ICCV 2019: 6430–6439).
- paper A Theoretical Analysis of Contrastive Unsupervised Representation Learning — Saunshi, Plevrakis, Arora, Khodak & Khandeparkar (2019) Generalization theory for contrastive learning. §11.3 closes the loop between InfoNCE-as-IB-predictiveness and PAC-Bayes-style bounds (ICML 2019: 5628–5637).
- paper An Operational Approach to Information Leakage — Issa, Wagner & Kamath (2020) Operational interpretation of I(T;S) as expected log-ratio gain of an adversary. §10.3 cites this for the privacy-leakage operational reading (IEEE Trans. Info. Theory 66: 1625–1657).
- paper Contrastive Multiview Coding — Tian, Krishnan & Isola (2020) Multi-view contrastive learning as MI maximization. §11.3 mentions this as the natural multi-view generalization of InfoNCE-as-IB-predictiveness (ECCV 2020: 776–794).