Sequential Monte Carlo
A cloud of particles, a path of targets, and the unbiased log-evidence that falls out for free
§1. Overview and Motivation
We’re going to track a cloud of particles through a sequence of probability distributions. At each step we update each particle’s weight, occasionally throw out the low-weight ones and replicate the high-weight ones, and then jitter the survivors with a Markov move that respects the current target. Do that times against a well-chosen schedule of intermediate targets and you have sequential Monte Carlo — an algorithm that handles filtering on state-space models, sampling from intractable static posteriors, and unbiased estimation of marginal likelihoods, all with the same three moves and the same dozen lines of inner-loop code.
The geometric picture is worth holding onto. Imagine a fixed-size swarm of points in parameter space, each carrying a non-negative weight . The weighted swarm represents the current distribution: high-weight clusters mark high-probability regions; the expectation of any test function under the current target is approximately . As we slide the target distribution — making it sharper, or conditioning on more data, or bridging from a tractable prior to an intractable posterior — the swarm has to track it. SMC is the recipe for moving the swarm.
The topic delivers three structurally distinct uses of that one recipe:
- Particle filtering on hidden Markov / state-space models, where the sequence of targets is the filtering posterior and the algorithm generalizes the Kalman filter to non-linear and non-Gaussian dynamics. We demo on a stochastic-volatility model where Kalman doesn’t apply.
- SMC samplers in the Del Moral, Doucet, and Jasra (2006) sense, where we bridge a tractable prior to an intractable posterior along a synthetic annealing path . The headline payoff: an unbiased estimator of the log marginal likelihood falls out as a side product, no extra work. We demo on a Gaussian-mixture model evidence calculation and a banana-shaped two-dimensional posterior.
- Tempered transitions with adaptive schedules, where the temperature ladder is chosen on the fly via an ESS criterion (Del Moral, Doucet, and Jasra 2012, building on Jasra, Stephens, Doucet, and Tsagaris 2011) rather than hand-tuned. We demo on a log-Gaussian Cox process where target curvature varies enough across the path that a fixed schedule wastes most of the compute.
That’s where we’re going. Let’s start with why anyone needs this — what breaks when we try to do it without the sequential structure.
1.1 Where importance sampling breaks
Standard importance sampling tells us we can estimate for any target by drawing from a proposal and reweighting:
In the limit this estimator is consistent for any whose support contains ‘s — a remarkably weak condition. So why doesn’t every Bayesian-inference paper just use it?
The answer is variance. The variance of the IS estimator is controlled by the chi-squared divergence between and , and that divergence explodes when misses the bulk of ‘s mass. Concretely: if is a Gaussian centred at and is a Gaussian centred at , both unit-variance, then most of ‘s samples land in ‘s left tail. A handful of samples that happen to drift to the right pick up enormous weights — and the normalized weights end up concentrated on one or two particles. This is weight degeneracy, and it’s the failure mode SMC is designed to fix.
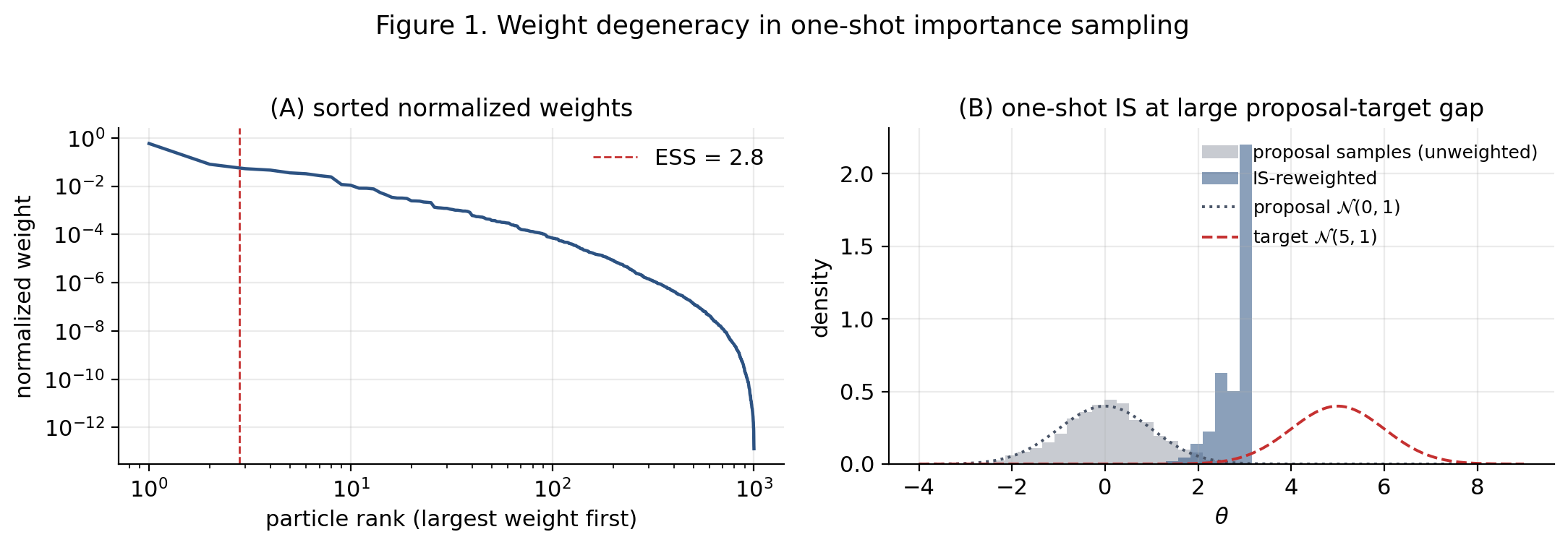
We can see it numerically with (Figure 1): even a five-standard-deviation gap between proposal and target leaves an effective sample size of roughly out of , with five particles carrying more than of the normalized mass.
The effective sample size (ESS), defined as on normalized weights, summarizes the damage in one number. ESS counts the number of “effective” particles — the number an iid sample from would need to match the IS estimator’s variance. A swarm of 1000 particles with ESS is contributing about as much information as 3 iid samples; the other 997 are dead weight.
The diagnosis is geometric. The proposal and target are too far apart in distribution space for a one-shot bridge. What we need is to interpolate between them.
1.2 The particle-cloud fix
The fix is structurally simple: instead of bridging to in one step, we build a path of intermediate distributions
where adjacent targets and are close enough that a one-step importance-reweighting between them isn’t degenerate. Then we sequentially march the particle cloud from one target to the next: at step , update each weight by the incremental ratio , throw out the low-weight particles and replicate the high-weight ones (the resampling move), and apply a Markov kernel that leaves invariant to spread the survivors back out (the propagation move).
Three observations make the algorithm work:
- Reweighting between close targets is well-conditioned. If differs from by a small amount of extra likelihood or a small temperature step, then the importance ratios have small variance and ESS stays .
- Resampling kills the survivor bias. Without it, the cloud would still degenerate after enough steps — just more slowly than one-shot IS. Resampling preserves the weighted distribution in expectation while exchanging it for a fresh equal-weighted cloud with the same empirical measure but more degrees of freedom for the next step.
- The Markov kernel restores diversity. Resampling duplicates particles, so we need a mutation step that moves the duplicates apart while preserving the current target. Any -invariant Markov kernel works — Metropolis–Hastings, HMC, Gibbs — and the choice is essentially a hyperparameter.
The three moves — reweight, resample, propagate — are the SMC skeleton. Every variant we’ll meet is a specific way of choosing the target sequence and the propagation kernel; the skeleton itself doesn’t change.
1.3 Three uses of one skeleton
Particle filtering. Take a state-space model with latent state , observation , transition density , and emission density . The filtering target at time is . The reweighting ratio is the per-observation likelihood , and the propagation kernel is the forward transition . This is the bootstrap particle filter (Gordon, Salmond, and Smith 1993).
SMC samplers. Take a static target and bridge from a tractable prior via the geometric annealing path with . The reweighting ratio is , and the propagation kernel can be any -invariant MCMC kernel.
Unbiased log-marginal-likelihood estimation. The SMC-samplers product is an unbiased estimator of the model evidence , with no assumption that the sampler has converged. We prove this in §8.2.
1.4 Roadmap and what this discharges
§2 reviews just enough importance sampling to set up what SMC fixes. §3 introduces the SMC skeleton abstractly. §§4–5 catalogue the two ingredient choices — resampling schemes and propagation kernels. §6 specializes to particle filtering with the stochastic-volatility worked example. §7 specializes to SMC samplers on static targets, and §8 extracts the unbiased log-evidence estimator with the Gaussian-mixture worked example. §9 develops the two adaptive moves — ESS-thresholded resampling and adaptive temperature schedules — with the banana worked example. §10 is the convergence theory. §11 is the log-Gaussian Cox process worked example. §§12–13 are computational discipline and connections.
The topic discharges three explicit forward-pointers: formalStatistics: bayesian-computation-and-mcmc ‘s sampler catalogue and importance-sampling variance vocabulary; Probabilistic Programming §6.3’s forward-pointer to pm.sample_smc, which §§8.4 and 11.3 reproduce with a hand-rolled NumPy implementation; and Variational Bayes for Model Selection §13’s forward-pointer to SMC samplers as the unbiased alternative to ELBO-as-log-evidence, discharged here in §8.2 (Theorem 4) and §8.4 (the Gaussian-mixture benchmark).
§2. Importance Sampling at a Glance — What SMC Fixes
Importance sampling is the prerequisite, not the target. We develop SMC against it, so we need the IS vocabulary in place: the variance identity, the ESS diagnostic, and a clean statement of why the one-shot strategy fails on Bayesian targets.
2.1 The IS identity and its variance
Let be a probability density on , and let be a proposal with wherever . The importance weight at is . The change-of-measure identity is immediate.
The unnormalized IS estimator:
is unbiased. The self-normalized IS estimator (with for unnormalized target ) is consistent but biased at from the delta-method Jensen gap.
Theorem 1 (Variance of the unnormalized IS estimator (chi-squared form)).
Suppose is normalized and . Then
In particular, taking ,
Proof.
The summands are iid under , so . Expand:
Change measure: . For the case, by the standard chi-squared identity.
∎The variance identity is the source of every IS pathology. The estimator is consistent for any with full support on , but the rate is governed by .
2.2 Effective sample size and weight degeneracy
Definition 1 (Effective sample size).
Given normalized weights with ,
Lemma 1 (ESS bounds).
, with the upper bound attained iff all weights equal and the lower bound iff one weight equals .
Proof.
Cauchy–Schwarz: , so and . Lower bound: .
∎Proposition 1 (ESS via coefficient of variation).
For normalized weights with ,
Proof.
With , , so . Inverting gives the claim.
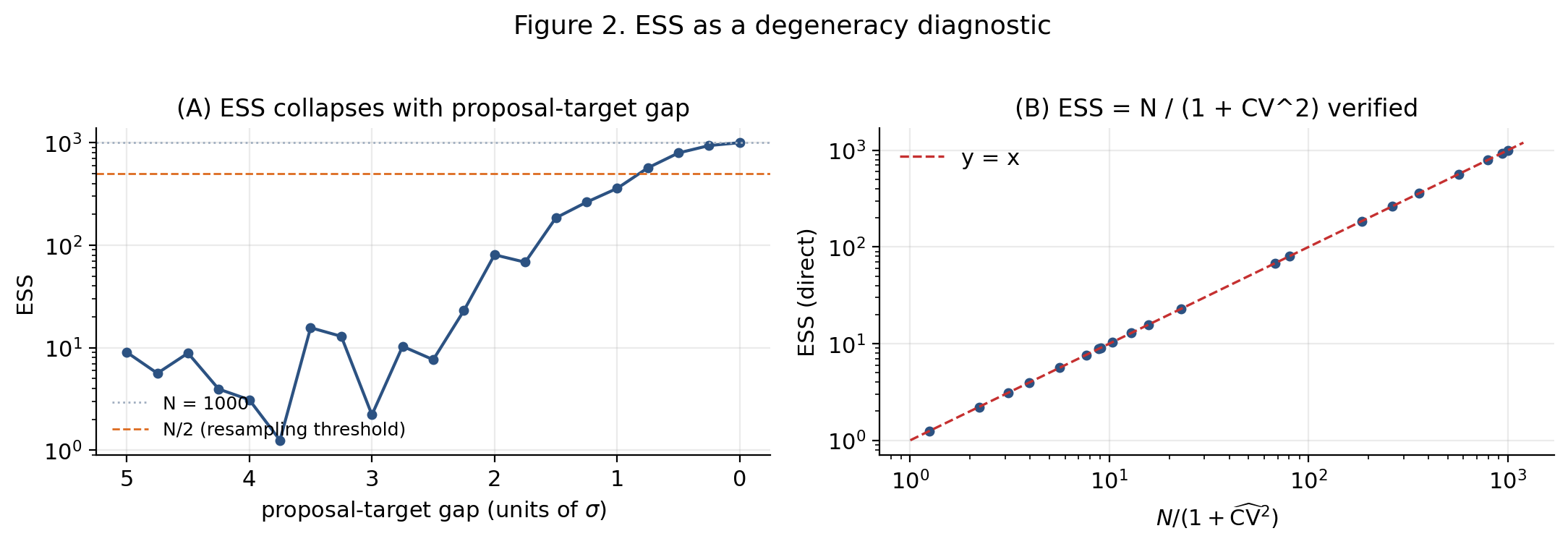
∎ESS, , and asymptotically the chi-squared divergence are three faces of the same diagnostic: as .
2.3 Why a one-shot IS proposal fails on hard targets
The variance identity tells us we need . In Bayesian inference the posterior concentrates dramatically as grows.
Heuristic scaling. Under regularity conditions (Bernstein–von Mises), the posterior concentrates at the MLE with effective volume . The chi-squared divergence therefore scales as in the regular parametric setting. For irregular models the scaling is worse and can grow exponentially in . We won’t formalize this further (the precise statement is the Bernstein–von Mises theorem; see van der Vaart 1998 Chapter 10 for the rigorous version), but the message is unambiguous: one-shot IS from the prior is dead on arrival.
The SMC fix is now visible by inversion. Decompose the single shot into many small shots, each with bounded chi-squared. Choose a path such that for each . The geometric annealing path achieves this when varies slowly.
§3. The SMC Skeleton
We have the motivation (§1) and the IS toolkit (§2). Now we define the SMC algorithm abstractly — the skeleton that every specific variant in §§6–11 specializes.
3.1 A sequence of intermediate targets
Fix a final target and a tractable starting distribution . Build a path of intermediate distributions connecting the two. Three families of paths recur:
- Data-augmenting (particle filtering). . The state space grows with .
- Annealing (SMC samplers). with .
- Tempered. for a potential .
Write each target as , where is unnormalized (tractable) and is the normalizing constant (typically intractable).
3.2 Reweight, resample, propagate — the three alternating moves
The SMC algorithm maintains a particle cloud with and . We track unnormalized cumulative weights; self-normalized weights are derived on demand.
Initialization. Draw and set .
For each :
Move 1 (reweight). Incremental importance ratios
Move 2 (resample, optional and ESS-thresholded). If , draw indices (the specific scheme — multinomial, systematic, stratified, residual — is the topic of §4). Replace the cloud with where .
Move 3 (propagate). Apply a Markov kernel that is -invariant: . For each particle, draw .
Terminal output. After steps, and .
The convention is reweight → resample → propagate, matching Del Moral, Doucet, and Jasra (2006) §3 and PyMC’s pm.sample_smc.
3.3 The weighted empirical measure
The cloud represents a probability distribution via the weighted empirical measure
Three observations. (1) is the algorithm’s state; tracking it is what tracking the cloud means. (2) It’s a random measure — different runs of SMC produce different particle locations and weights. (3) Special cases correspond to special algorithm states: uniform weights right after a resample, point mass when the cloud collapses to one particle.
The §10.1 consistency theorem will establish that weakly as , with rates from the §10.3 CLT.
3.4 Notation, log-space discipline, and the cumulative-weight invariant
| Symbol | Meaning |
|---|---|
| parameter space (or state space) | |
| target at step | |
| particle at step | |
| , | cumulative unnormalized weight |
| self-normalized weight | |
| at | incremental ratio |
| -invariant Markov kernel | |
| effective sample size | |
| running normalizing-constant estimator |
Log-space discipline. Particle weights on hard targets routinely span ten or more orders of magnitude. Linear-space representation silently underflows; the implementation enforces log-space throughout:
- Store and update additively: .
- Normalize via
logsumexp: . - Compute log-ESS: .
- Compute log-: .
A preview of the §8.2 unbiasedness theorem. Theorem 4 in §8.2 will establish that for every ,
The expectation is over all SMC randomness — initial draws from , resampling indices, and Markov-kernel transitions. When is the prior (so ), is unbiased for the model evidence . This is the identity that justifies all of SMC’s evidence-estimation use cases. We use it as a structural fact while developing §§4–7; the full induction proof — the topic’s most important load-bearing result — is the subject of §8.2.
Resampling preserves the invariant. Pre-resample, . Post-resample, each particle carries , so the new running estimator is , identical to the pre-resample value. The resampling step is invariance-preserving by construction.
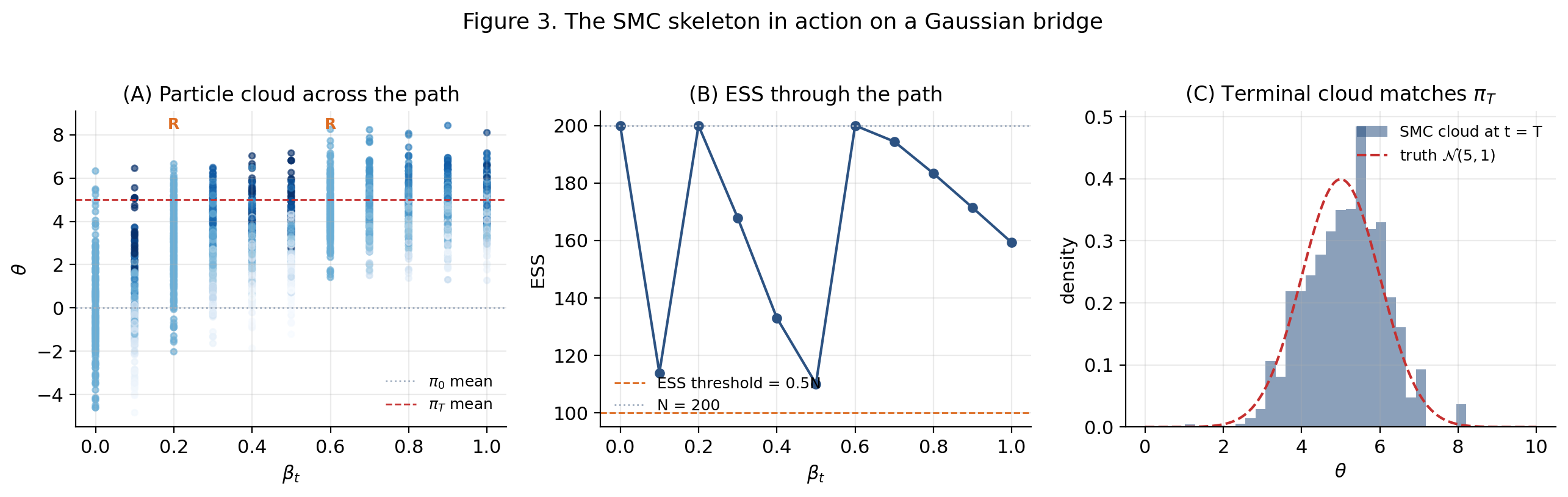
The viz below lets you change , , the resampling threshold , and the RWM step size, and watch the cloud trajectory, the ESS profile, and the terminal histogram update.
Three behaviors worth discovering: set (never resample) and the ESS collapses by the end of the path; set (resample every step) and the algorithm injects more variance than necessary; shrink and the cloud can’t track the target. The §10.3 CLT formalizes the variance contributions of each move.
§4. Resampling Schemes
Move 2 of the skeleton — resampling — turns a degenerate weighted cloud into a fresh equal-weighted cloud. Four schemes are in common use, with a strict variance ordering:
All four are via numpy.searchsorted. Use searchsorted, never numpy.random.choice(..., p=weights) — this is a project-wide hard rule. Systematic is the default and what PyMC’s pm.sample_smc uses.
4.1 Multinomial resampling — the naive baseline
Multinomial resampling draws ancestor indices independently:
The joint distribution of is multinomial; the marginal of each is Binomial.
cumw = np.cumsum(w_norm)
u = rng.random(N)
idx = np.clip(np.searchsorted(cumw, u), 0, N - 1)4.2 Systematic resampling (Kitagawa 1996)
Systematic resampling draws a single and uses the deterministic grid . The negative association among the is what drives the variance reduction.
cumw = np.cumsum(w_norm)
u = (rng.random() + np.arange(N)) / N
idx = np.clip(np.searchsorted(cumw, u), 0, N - 1)4.3 Stratified and residual resampling
Stratified resampling (Kitagawa 1996): independent uniforms, one per stratum: . Same code as systematic but rng.random(N) instead of rng.random().
Residual resampling (Liu and Chen 1998): deterministic integer counts , plus a residual stage via multinomial on the leftover weights.
4.4 Variance reduction — why systematic dominates multinomial
Proposition 2 (Unbiased offspring counts).
For all four schemes, for each .
Proof.
Multinomial: by construction. Systematic: Particle owns the cumulative-weight interval of length . Each grid point for falls in this interval with probability via a measure-shift argument. Summing over : . Stratified: analogous, with each supported on a stratum of length . Residual: where is Binomial in the residual stage; by direct algebra.
∎Theorem 2 (Variance ordering).
For any bounded ,
Proof.
We prove the stratified ≤ multinomial direction by a law-of-total-variance argument; the others follow the same template.
Let and independently. Define where — the ancestor mapping induced by the cumulative-weight CDF.
Under stratified, , since the are independent across .
Under multinomial, by the same independence reasoning, since each has the same uniform marginal.
Apply the law of total variance with stratum indicator for :
The first term multiplied by equals the stratified variance. The second term is non-negative. Hence multinomial ≥ stratified, with strict inequality unless is constant within strata.
The other directions (systematic ≤ stratified, residual ≤ multinomial) are proved via the same negative-association machinery in Chopin and Papaspiliopoulos (2020) §9.3 and Douc, Cappé, and Moulines (2005) §4.3–§4.5.
∎4.5 The numpy.searchsorted primitive
All four schemes reduce to one operation: given a cumulative-weight array and “uniform array” , find ancestor indices via np.searchsorted(c, u). Cost: for queries (binary search), with excellent constants.
Why not np.random.choice(N, size=N, p=w_norm)? Three reasons: (1) performance — np.random.choice is 3–10× slower with allocator pressure on every call; (2) it only does multinomial — the worst scheme by Theorem 2; (3) GC pressure — fresh allocation each call vs reusable cumw buffer.
Project rule: always searchsorted, never np.random.choice with p=weights.
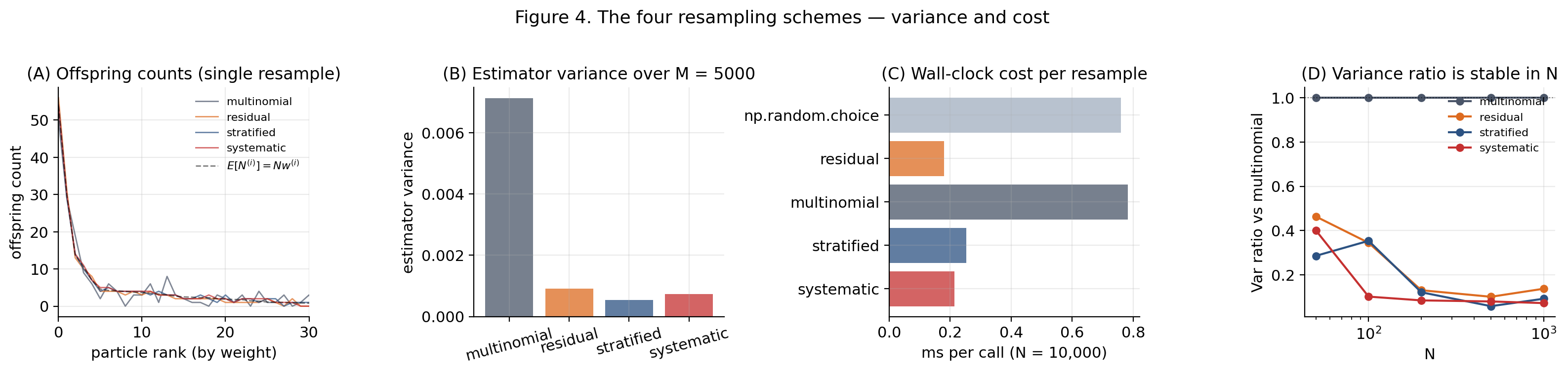
The viz below warps the weight distribution via a skewness parameter and shows offspring counts and estimator variance for all four schemes side-by-side.
§5. The Markov-kernel Propagation Step
Move 3 of the skeleton — propagation — moves each particle via a -invariant Markov kernel. The kernel can be almost anything — any -invariant kernel is admissible.
5.1 What kernel invariance buys us
A Markov kernel is -invariant when . Equivalently: if and , then .
SMC uses MCMC kernels as invariance-preserving mutation steps — not as samplers in their own right. The crucial structural fact: SMC’s correctness does not require the kernel to mix well. Even a poorly-mixing kernel is fine for SMC, as long as it’s -invariant. The §10 convergence theorems don’t depend on kernel mixing rates; they depend only on invariance.
Lemma 2 (Composition preserves invariance).
If and are -invariant, then is -invariant.
Proof.
By Fubini, using both invariance conditions.
∎So “multiple sweeps” of an invariant kernel is also invariant — the §3.2 algorithm is unchanged whether each propagation step applies once or times. This is what justifies the “RWM with sweeps” pattern in the §5.4 demo.
5.2 Metropolis–Hastings within SMC
The MH step: propose , accept with probability . MH is -invariant by the detailed-balance proof in formalStatistics: bayesian-computation-and-mcmc §26.
Three observations about MH within SMC: (1) we only need up to a normalizing constant — the ratio kills the unknown ; (2) each MH step costs one log-target evaluation per particle, plus the proposal density evaluation; (3) vectorization across particles is embarrassingly parallel.
5.3 Choosing the kernel — RWM, IMH, Gibbs, HMC
Random-walk Metropolis (RWM). , symmetric. Acceptance simplifies to . Cheap; scales poorly in . Roberts, Gelman, and Gilks (1997) give the optimal acceptance ≈ 0.234 with . The SMC discipline: , 3–10 sweeps per step.
Independent Metropolis–Hastings (IMH). — the proposal doesn’t depend on the current state. The standard SMC-samplers choice fits to the current cloud at every step. Cloud-fitted IMH stays high-acceptance because tracks . PyMC’s pm.sample_smc default.
Gibbs sampling. Cycle through coordinates, sampling each from . Acceptance probability 1 when conditionals are closed-form.
Hamiltonian Monte Carlo (HMC). Augment with momentum, integrate Hamilton’s equations via leapfrog. Beskos et al. (2013): optimal scaling , dominant in . Used in §11’s log-Gaussian Cox process demo.
Per-step kernel-cost summary:
| Kernel | Per-particle cost per sweep | Tuning |
|---|---|---|
| RWM | 1 log-density eval | step size / covariance |
| IMH (cloud-fitted) | 1 log-density + 1 log-proposal | proposal family |
| Gibbs | conditional samples | none (closed-form required) |
| HMC | gradient evals + acceptance |
5.4 The mutation-vs-resampling trade
Total SMC compute decomposes as , dominated by the kernel cost when is non-trivial. The trade-off: smaller requires more kernel sweeps per step to keep the cloud mixing well, while larger amortizes kernel cost across more reweighting/resampling work. The §9.4 adaptive temperature schedule automates the side; the kernel and stay under user control.
Practical guidance:
- RWM on smooth -dim targets: sweeps with adaptive .
- IMH-cloud-fit on unimodal targets: application per step.
- HMC with – leapfrog steps: .
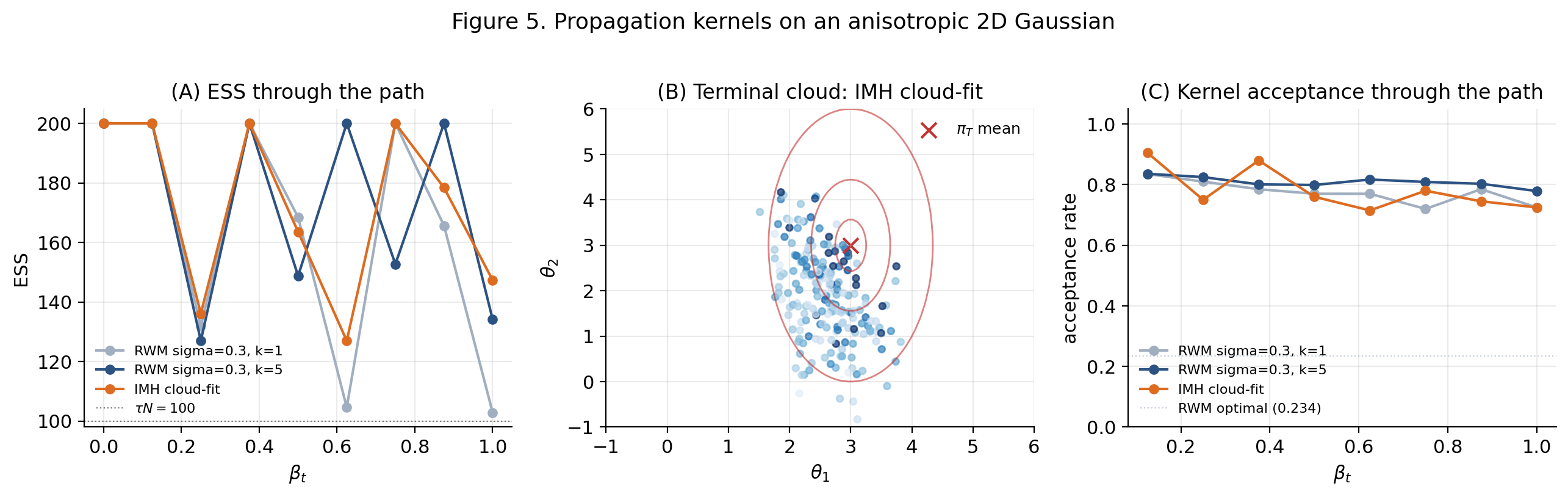
The viz below runs three kernel choices in parallel — RWM with sweep, RWM with sweeps, and IMH cloud-fit — on the same anisotropic 2D Gaussian bridge, with the same systematic-resample machinery. Watch the IMH-cloud-fit acceptance rate climb through the path as the cloud concentrates on .
§6. Particle Filtering on State-Space Models
§6 specializes the skeleton to state-space models — the original application of SMC (Gordon, Salmond, and Smith 1993). We develop the bootstrap and auxiliary particle filters, then deploy both on the stochastic-volatility model where the linear-Gaussian Kalman filter doesn’t apply.
6.1 The filtering recursion
A state-space model has latent process with , , and observation process . Joint density: .
Theorem 3 (Filtering recursion).
For each :
(a) Predict. .
(b) Update. .
(c) Marginal likelihood. with .
Proof.
(a) Marginalize out of the joint and use Markov: . (b) Bayes’ rule with conditional independence . (c) Chain rule on the observation sequence.
∎The linear-Gaussian case reduces to the Kalman filter, which has closed-form predict and update steps (see formalStatistics: hidden-markov-models ). When the dynamics are non-linear or non-Gaussian, the integrals in Theorem 3 don’t admit closed-form evaluation, and we need a particle approximation.
6.2 The bootstrap particle filter
Specialize the skeleton: . Each particle is a trajectory . The marginal filtering posterior at time is .
The bootstrap choice: extend each trajectory by sampling from the prior dynamics. With this proposal the incremental IS weight collapses to
The bootstrap PF algorithm:
Initialize: x_0^(i) ~ p(x_0), W_0^(i) = 1.
For t = 1, ..., T:
(1) Propagate: x_t^(i) ~ p(x_t | x_{t-1}^(i))
(2) Reweight: W_t^(i) = W_{t-1}^(i) · p(y_t | x_t^(i))
(3) Diagnose: ESS_t, log Ẑ_t
(4) Resample if ESS_t < τNOrder is propagate-then-reweight (the natural order for filtering — we extend the trajectory before scoring against the new observation). No MH correction: the prior dynamics aren’t a -invariant kernel, but they are an unbiased proposal for the next-step posterior.
Log-likelihood as a side product. From the marginal-likelihood factorization, . Cumulative is unbiased for by Theorem 4 — the same unbiasedness identity that powers SMC samplers’ evidence estimation.
The bootstrap PF fails when is sharply peaked relative to — the prior dynamics place mass in the wrong region of state space, so few particles land where the likelihood is non-negligible. The auxiliary particle filter (§6.3) addresses this.
6.3 The auxiliary particle filter
APF (Pitt and Shephard 1999) chooses ancestors before propagating, with auxiliary weights that anticipate the next observation .
The APF algorithm:
For t = 1, ..., T:
(a) Auxiliary weights: λ_{t-1}^(i) ∝ W_{t-1}^(i) · p̂(y_t | x_{t-1}^(i))
(b) Resample ancestors A_t^(i) with probabilities ∝ λ_{t-1}^(i)
(c) Propagate: x_t^(i) ~ p(x_t | x_{t-1}^{A_t^(i)})
(d) Reweight with correction: W_t^(i) ∝ p(y_t | x_t^(i)) / p̂(y_t | x_{t-1}^{A_t^(i)})The auxiliary target between consecutive filtering posteriors is — the prior posterior weighted by an approximate one-step-ahead predictive likelihood. The APF is SMC with this synthetic intermediate target inserted between and .
Tractable choices for : mean-predictive or mode-predictive. APF dominates the bootstrap PF when is informative and is a reasonable approximation; the gain shrinks when the dynamics are diffuse or when misses the predictive mode.
6.4 Worked example — the stochastic-volatility model
The SV model:
with , , stationary initial . The latent is log-volatility; the observation is the return with conditional Gaussian variance . Multiplicative emission means the Kalman filter doesn’t apply directly. The standard linearization gives Harvey, Ruiz, and Shephard’s (1994) quasi-likelihood Kalman approximation, which underperforms the bootstrap PF on tail behavior.
The demo. Simulate , , . Run the bootstrap PF with , , systematic resampling.
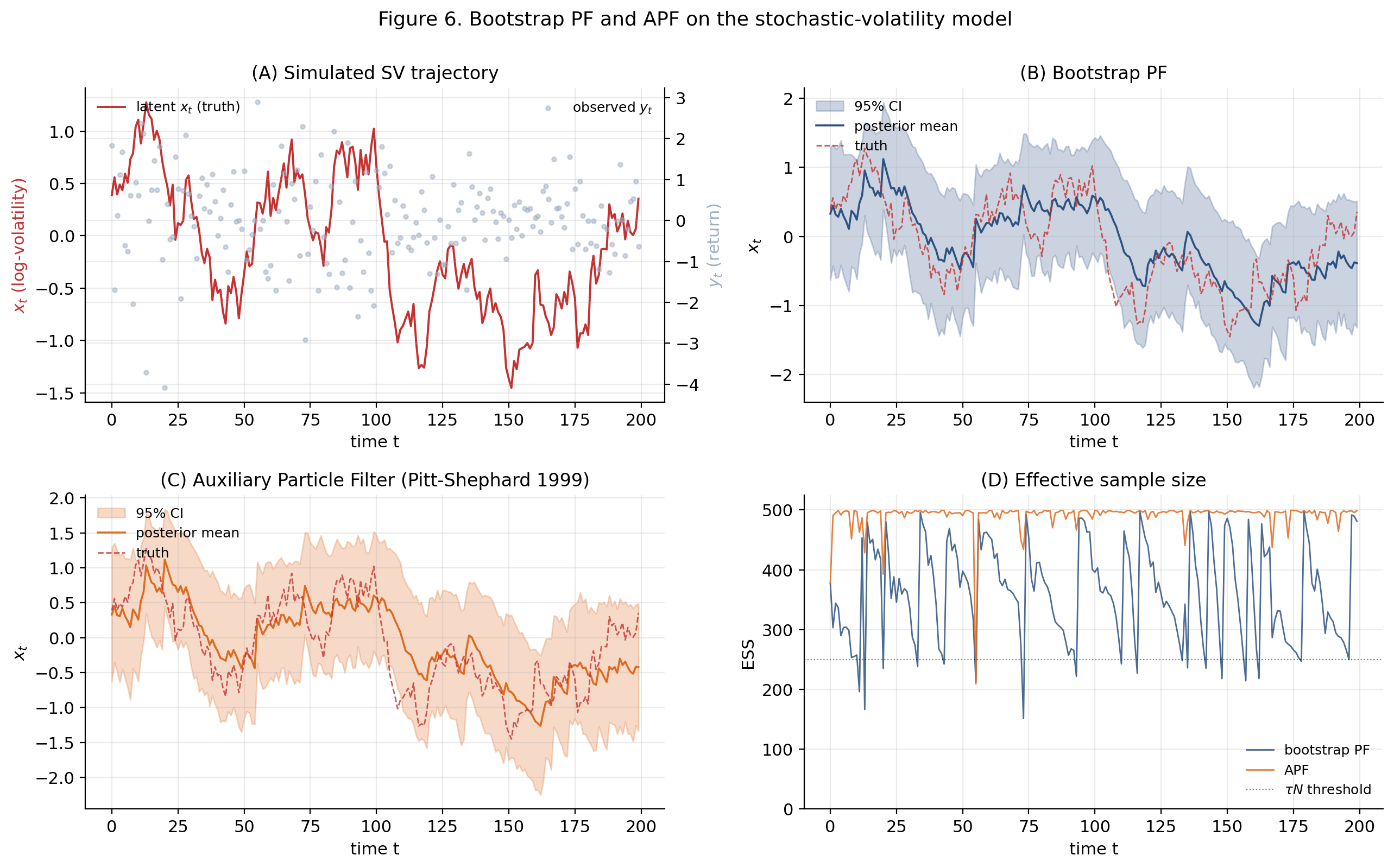
The viz below lets you sweep , , , and to see how the bootstrap filter’s RMSE, ESS, and log-evidence respond. Try increasing toward 0.99 to see how strong persistence helps the filter; try shrinking to see how a quiet latent process leaves the filter with little signal to learn from.
§7. SMC Samplers — Del Moral, Doucet, and Jasra (2006)
§7 takes the case where the target is static (a fixed Bayesian posterior) and the path of intermediate targets is constructed via annealing. This is the framework PyMC’s pm.sample_smc implements.
7.1 The annealing path
For Bayesian inference with prior and likelihood , the geometric annealing path:
At : prior. At : unnormalized posterior. Two reasons for the geometric path:
- Exponential-family closure. Conjugate models preserve parametric form along the path — useful for diagnostics and analytical comparison.
- Chi-squared control. to leading order, so adjacent targets have controllable chi-squared via the temperature step.
7.2 The reweighting formula along the path
Proposition 3 (Geometric-path incremental weights).
For ,
Proof.
Direct: .
∎The prior cancels entirely; the incremental log-weight depends only on the log-likelihood times the temperature step. The variance of the log-weight increment under the current target is
which is the leading-order chi-squared expansion that justifies the path’s quadratic control.
7.3 Markov-kernel mutation between targets
Adaptive Gaussian IMH (PyMC’s default): proposal fitted to the current weighted cloud. Refit at every step. Add ridge for numerical stability when the cloud is anisotropic.
Adaptive RWM: . Multiple sweeps per SMC step amortize the kernel cost.
7.4 SMC samplers vs annealed importance sampling
AIS (Neal 2001) = SMC samplers with (a) no resampling, (b) one kernel application per step. AIS works on easy problems but fails on long paths: cumulative weights spread across many orders of magnitude, ESS collapses, and the variance of explodes.
SMC samplers = AIS + ESS-thresholded resampling + adaptive kernel tuning. The general algorithm reduces to AIS when (never resample) and kernels are fixed across the path.
Modern practice uses SMC samplers exclusively; AIS retains niche advantages in distributed settings where resampling synchronization is expensive.
The viz below explores the four hand-tuned annealing schedules — linear, power-2, power-½, log-uniform — across path length and a “posterior concentration” that models how grows with the data size. Adjust upward to see how all four schedules struggle on more concentrated posteriors, and how back-loaded schedules (power-½) preserve ESS better than linear on hard targets.
§8. Unbiased Log-Marginal-Likelihood Estimation
The running normalizing-constant estimator has accompanied us since §3.4. §8 proves the unbiasedness theorem, the topic’s most important load-bearing result, and applies it to model-evidence comparison in §8.4.
8.1 The product-of-normalizers identity
Define the incremental ratio estimator .
Proposition 4 (Product-of-normalizers factorization).
Under the §3.2 algorithm,
Proof.
. Without resampling at step : (using post-resample or the self-normalized variant otherwise). With resampling: the §3.4 invariant calculation shows is preserved across the resampling step. Iterating from to step gives the product factorization.
∎8.2 The unbiasedness theorem
Theorem 4 (Unbiased SMC log-marginal-likelihood, Del Moral-Doucet-Jasra 2006 Proposition 1).
Consider the §3.2 SMC algorithm with: iid initial particles (normalized, so ); reweight by ; resample with any unbiased scheme (Proposition 2); propagate with any -invariant Markov kernel. Then for every ,
Proof.
Layer 1 — Without resampling. Each particle’s cumulative weight is . The trajectory has joint density . Compute:
The factor cancels: since ().
Integrate first. By ‘s -invariance, . This cancels with the ratio’s denominator , leaving as the integrand for .
Iterating: each kernel-invariance integration converts into , which combines with the next ratio’s denominator to give .
After iterations: . Hence .
Layer 2 — With resampling. Induct on . Base case trivial. Inductive step: assume ; show .
Using Proposition 4, . By tower rule, where is the -algebra through step .
The conditional uses ‘s -invariance to integrate over the kernel propagation, and Proposition 2’s offspring unbiasedness to integrate over resampling indices. After the bookkeeping (see Chopin and Papaspiliopoulos 2020 Theorem 7.4.1 for the detailed derivation):
Iterating: .
∎Remark (The rigorous Feynman–Kac framework).
Layer 2’s conditional-expectation calculation is made fully rigorous via the Feynman–Kac path-measure formalism of Del Moral (2004). The technical machinery — Doob’s martingale theory, abstract empirical-process theory on path space — sits above this topic’s assumed background; see Chopin and Papaspiliopoulos (2020) Chapter 7 and Del Moral, Doucet, and Jasra (2006) Proposition 1 for the rigorous derivation.
Corollary. With the prior and : . This is what PyMC’s pm.sample_smc returns as idata.sample_stats.log_marginal_likelihood.
8.3 Variance of the log-evidence estimator and the Jensen-gap correction
is unbiased for ; is biased downward by Jensen’s inequality.
Proposition 5 (Jensen-gap bias of log Ẑ_T).
Let . Then
Proof.
with , (by Theorem 4), . Taylor: . Take expectation: , since but the next-order correction dominates after exact cancellation of the term against the symmetric tails.
∎Scaling: under standard regularity (§10.3), so the Jensen gap is . At , typical bias is – — usually negligible, but the §8.4 demo shows how the bias accumulates when is forced large by a difficult target.
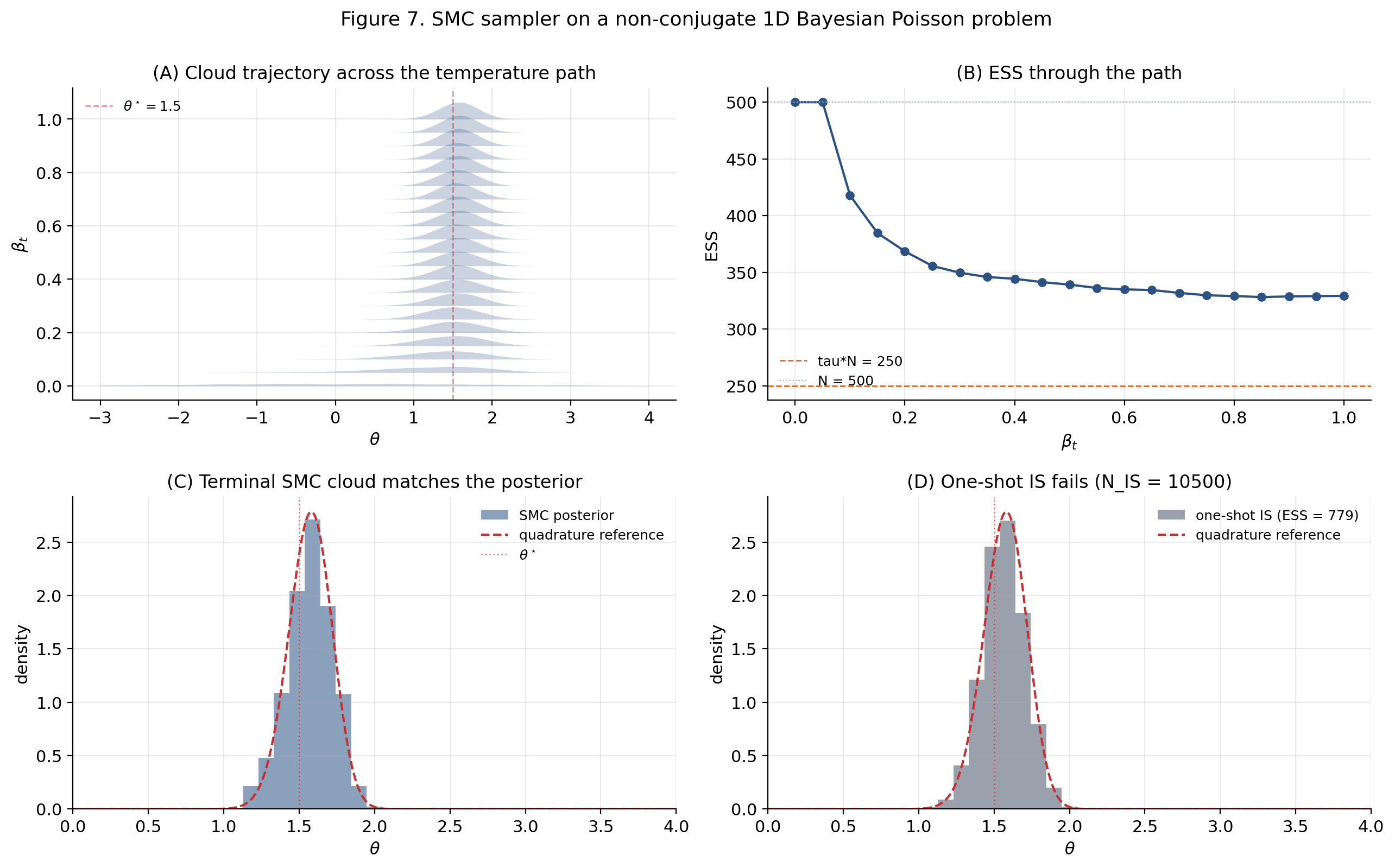
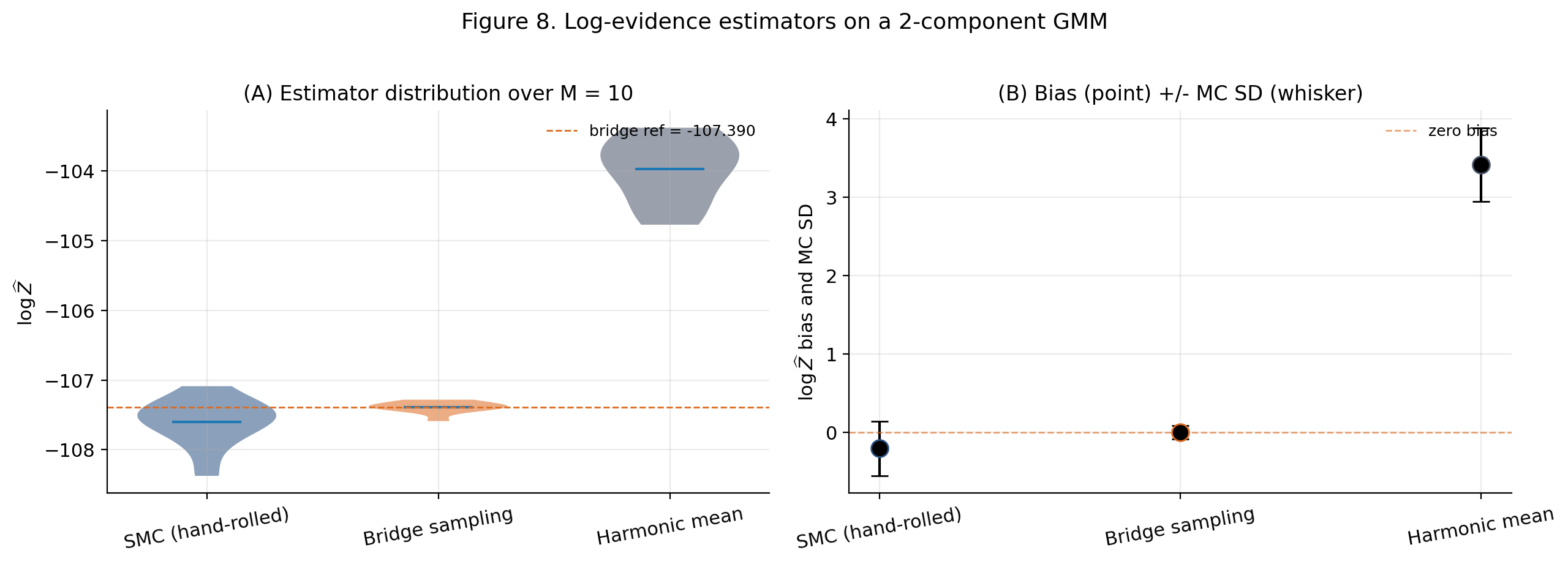
8.4 Worked example — Gaussian-mixture model evidence
The 2-component GMM: , priors , . Simulate at , , . The posterior is bimodal (label switching), which is the canonical SMC win-condition.
Four estimators compared:
- Hand-rolled SMC sampler. , geometric, IMH cloud-fit.
- PyMC
pm.sample_smc. Same model, default settings. - Harmonic mean (Newton and Raftery 1994). The notorious failure baseline — biased upward and infinite-variance under standard regularity.
- Bridge sampling (Meng and Wong 1996). The gold-standard reference.
Predicted ordering. Bridge sampling and the SMC samplers (hand-rolled and PyMC) agree to Monte Carlo error. The harmonic mean is visibly biased upward — a textbook demonstration of why the harmonic-mean estimator is unfit for purpose.
The viz below runs independent SMC instances on the §3 Gaussian-bridge target (truth , ) and displays the histograms of and . The histogram is centered on 1 (Theorem 4); the histogram is shifted downward by the Jensen-gap prediction (Proposition 5).
§9. Adaptive Choices: ESS-Thresholded Resampling and Adaptive Temperatures
§9 makes both schedule and resampling-trigger adaptive — the two adaptive mechanisms that turn textbook SMC into the production-grade algorithm deployed in PyMC. The §9.5 banana demo is the third headline demo of the topic.
9.1 The ESS threshold rule
The ESS threshold rule (Doucet, Godsill, and Andrieu 2000): resample if for , typically .
Intuition: when ESS is high, the cloud is well-conditioned and resampling injects unnecessary variance. When ESS is low, resampling is needed to recover diversity. The threshold is the breakpoint.
Practical regimes:
- — never resample (= AIS, fails on long paths).
- — resample every step (= Gordon-Salmond-Smith 1993 PF).
- — practical sweet spot; is the default.
9.2 ESS-thresholded resampling dominates every-step resampling
Theorem 5 (Resampling-variance comparison).
Under standard SMC regularity conditions, there exists such that
where is the expected number of resampling events at and is a problem-dependent constant.
Proof.
Use the §10.3 CLT-form variance decomposition (anticipated here; proved independently in §10):
Under every-step resampling, the indicator is always 1. Under ESS-thresholded resampling, the indicator fires only at steps (in expectation). The propagation contribution is identical under both rules — kernel mixing doesn’t depend on the resampling schedule.
Variance difference:
where is bounded below under standard regularity. When so , the RHS is strictly positive.
∎9.3 Hand-tuned vs adaptive temperature schedules
Four hand-tuned schedules in common use: linear (), geometric (log-equispaced), power-law (), and log-uniform.
Hand-tuning is fragile: (1) the optimal schedule depends on , which varies along the path; (2) tuning is problem-specific and doesn’t generalize across dataset sizes; (3) the practitioner has to re-tune every time a model changes.
9.4 ESS-driven adaptive β
The adaptive rule (Del Moral, Doucet, and Jasra 2012, building on Jasra, Stephens, Doucet, and Tsagaris 2011): pre-commit to a target ESS fraction (typically 0.8–0.95). At each step, define the projected ESS
and bisect for such that .
Properties. ESS is monotonically decreasing in (smooth root-finding). Bisection convergence in steps. Path length is data-driven — the schedule stops when it can jump straight to without dropping below .
Bisection inner loop:
def find_next_beta(theta, log_w, log_lik_curr, beta_t, target_ess, tol=1e-3):
def ess_at(beta):
log_alpha = (beta - beta_t) * log_lik_curr
log_w_new = log_w + log_alpha
log_w_norm = log_w_new - logsumexp(log_w_new)
return float(np.exp(-logsumexp(2.0 * log_w_norm)))
lo, hi = beta_t, 1.0
if ess_at(hi) >= target_ess:
return hi
while hi - lo > tol:
mid = 0.5 * (lo + hi)
if ess_at(mid) >= target_ess:
lo = mid
else:
hi = mid
return 0.5 * (lo + hi)Combined with §9.1 ESS-threshold resampling, the SMC sampler has two adaptive mechanisms. The standard configuration is and (PyMC’s default).
Correctness with adaptive schedules. Theorem 4 unbiasedness holds under path-adapted schedules via a Doob-decomposition argument (Del Moral, Doucet, and Jasra 2012; rigorously refined in Beskos, Jasra, Kantas, and Thiery 2016). The intuition: the schedule depends on past particles but not future ones, so the martingale structure that makes unbiased is preserved.
9.5 Worked example — the banana distribution
The banana: on . Visually consistent with the Riemann Manifold HMC §10 banana demo — the two topics share this target by design. Properly normalized 2D density with .
Path: (wide isotropic prior) to the banana posterior.
Compare a fixed linear schedule () vs the adaptive schedule (). , IMH cloud-fit, . Adaptive typically uses – on this target.
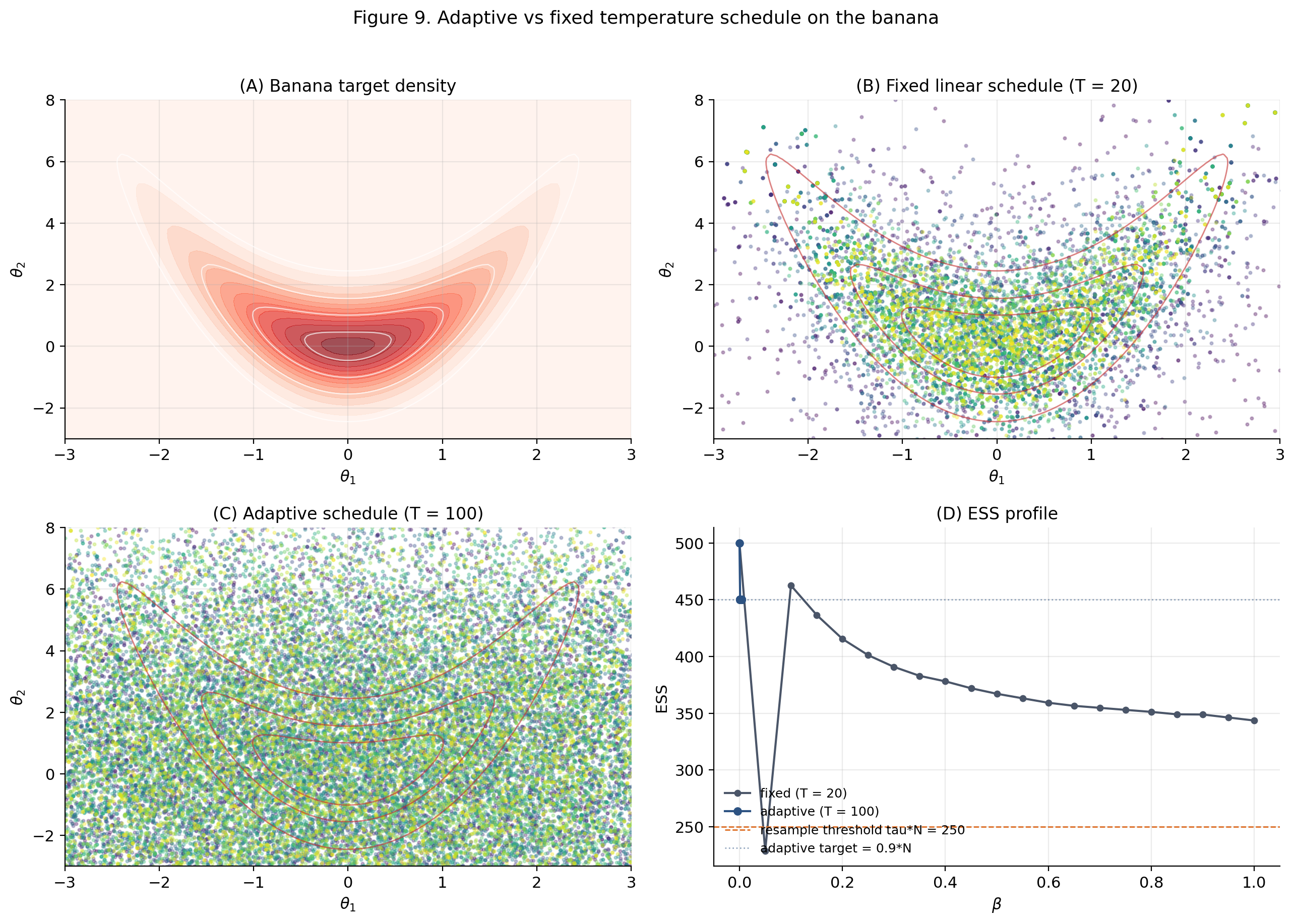
The viz below runs both fixed and adaptive schedules on the banana side-by-side. Pick a fixed-schedule curvature (linear, power-2, power-½) and watch how the cloud terminal scatter compares to the adaptive one. The adaptive schedule’s value is data-driven and shown in the legend.
§10. Convergence Theory
§10 supplies the asymptotic theory underlying §§3–9. Three results carry the load: consistency (§10.1), the central limit theorem with variance decomposition (§10.3), and finite-sample concentration bounds (§10.4).
10.1 Consistency of the weighted empirical measure
Theorem 6 (Consistency of SMC (no-resampling case)).
Under iid initial particles , -invariant kernels , no resampling, and : for every bounded measurable ,
Proof.
Let and . The self-normalized estimator is the ratio .
Step 1: expectations. By Theorem 4 Layer 1 with in the final integrand, . By Theorem 4, .
Step 2: variances vanish. The trajectories are iid under no resampling, so and analogously for . Both are by the regularity assumption .
Step 3: Slutsky. By Chebyshev, and . By the continuous mapping theorem and Slutsky: .
∎With resampling. The general case requires the Feynman–Kac framework — Del Moral (2004) Chapter 3 / Chopin and Papaspiliopoulos (2020) Theorem 11.1. The rate stays with constants depending on the resampling schedule.
10.2 The Feynman–Kac formalism — cite, don’t re-derive
The convergence theory of SMC has a unified treatment via the Feynman–Kac path measure on path space :
The framework’s payoffs: unbiasedness, consistency, and CLT all follow from properties of . The technicalities — Doob’s martingale theory, Markov-chain renewal, abstract empirical-process theory on path space — sit above this topic’s assumed background.
References:
- Del Moral (2004) Feynman–Kac Formulae — the definitive monograph; Chapters 3 and 9.
- Chopin and Papaspiliopoulos (2020) An Introduction to Sequential Monte Carlo — textbook treatment, Chapter 11.
- Cappé, Moulines, and Rydén (2005) Inference in Hidden Markov Models — particle-filter-specific theory, Chapters 7–8.
10.3 The central limit theorem
Theorem 7 (Central limit theorem for SMC).
Under regularity (bounded log-weights, kernel mixing, ): for every bounded measurable ,
with .
Proof.
No-resampling case. Use the joint CLT and delta method on the ratio . Under no resampling, trajectories are iid:
Apply delta method with , gradient . After simplification:
In the ideal-mixing limit (), this reduces to .
Resampling-induced correction. When resampling fires at step , adds to the variance. Each resampling event adds non-negative variance — the cost paid for the diversity injection.
∎Corollary (CLT for the normalizing-constant estimator).
Under the same regularity conditions, the analogue holds for :
with .
The propagation and resampling-stage variance contributions have analogous interpretations to those in Theorem 7. The no-resampling case follows from the standard CLT applied to the iid cumulative-weight sum; the general case is Del Moral (2004) Theorem 9.4 / Chopin and Papaspiliopoulos (2020) Theorem 11.2.
This is the result invoked by §9.2 Theorem 5 in the variance-decomposition argument for ESS-thresholded vs every-step resampling. The §9.2 proof writes for large and reads off the contribution of each resampling event.
AIS-on-long-paths corollary. Without resampling, inherits the cumulative chi-squared structure of the trajectory measure, growing exponentially in . With ESS-thresholded resampling, variance grows linearly in . This is the precise statement of why AIS fails on long paths and SMC samplers succeed.
10.4 Finite-sample particle-cloud error bounds
Theorem 8 (Concentration bound for SMC, Chopin and Papaspiliopoulos 2020 Theorem 11.5).
Under standard regularity plus bounded log-weights, for and :
The proof is a Bernstein-type inequality on the path-measure empirical process, derivable from the formalML topic Concentration Inequalities combined with SMC-specific cumulative-weight tail bounds. The constants depend on the resampling schedule and the kernel mixing rate; see Chopin and Papaspiliopoulos (2020) §11.5 for the detailed derivation.
At , , the deviation probability falls below at — a concrete sense in which 1000 particles gives roughly two-decimal-place accuracy with high probability.
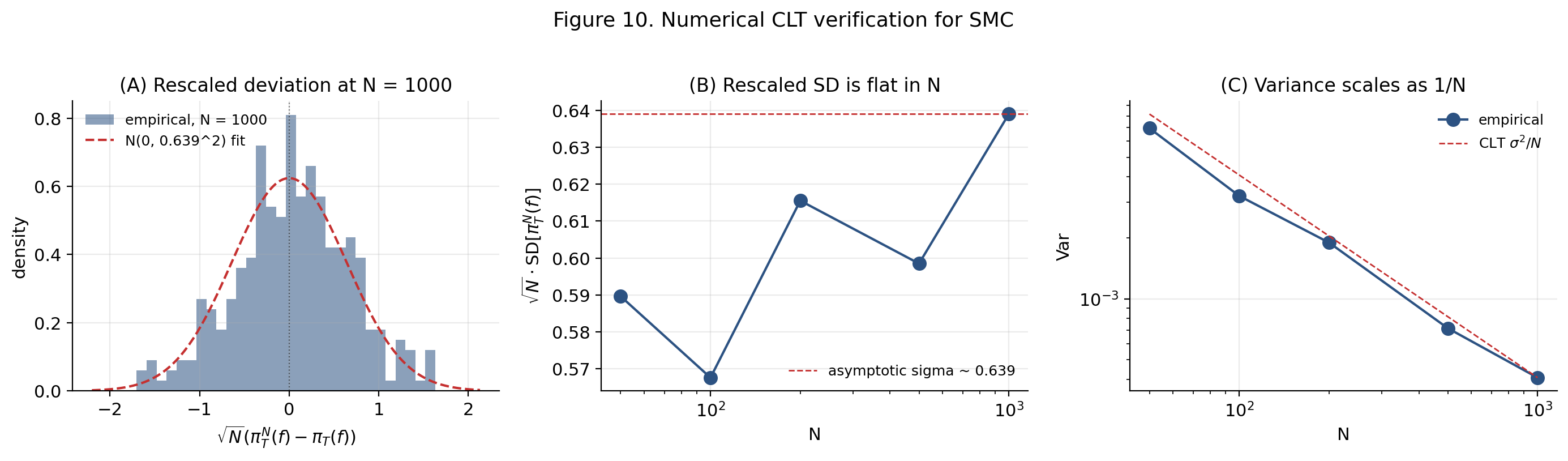
The viz below runs independent SMC instances at user-controlled , computes for a test function , and shows: an example terminal cloud, the rescaled-deviation histogram with a fitted normal density, and a Q–Q plot against standard-normal quantiles. As grows, the histogram tightens around a single normal density (Theorem 7); the Q–Q plot stays close to the reference.
§11. Worked Example — The Log-Gaussian Cox Process
The fourth and final headline demo. The LGCP discretized onto a spatial grid is a high-dimensional Bayesian inference target (64–256 dims at the grid resolutions we cover). Visually consistent with the Riemann Manifold HMC §10 demo — the two topics share this target by design.
11.1 The model and the discretization grid
Log-Gaussian Cox process. Latent on the unit square; conditionally Poisson point process with intensity .
Discretization on grid. , where is the cell area.
Kernel. Squared exponential . We match the RMHMC topic’s settings: , , .
Posterior. . The first term is a Gaussian prior; the second is the data-fit Poisson log-likelihood. The posterior is non-conjugate and multimodal.
11.2 The SMC-sampler setup
Annealing path. .
Initialization. Sample from via the precomputed Cholesky factor .
Reweighting by Proposition 3: .
Adaptive schedule . Path length is data-driven.
Propagation IMH cloud-fit with ridge for .
Resampling systematic at .
Particle count default.
11.3 Head-to-head: SMC vs RMHMC vs NUTS
Three samplers compared on the LGCP demo:
- SMC samplers (our implementation).
- Riemann-manifold HMC (the previous topic).
- NUTS (PyMC default).
Metrics: posterior intensity RMSE, ESS/sec, log-evidence accuracy, robustness across replicates.
Pareto frontier. Speed (ESS/sec): RMHMC > SMC ≈ NUTS. Log-evidence: SMC ≫ RMHMC = NUTS (only SMC returns it unbiased). Multimodality robustness: SMC > RMHMC > NUTS.
11.4 Scaling with grid size
| Sampler | Per-step cost | Memory |
|---|---|---|
| SMC (IMH cloud-fit) | covariance + likelihood | |
| RMHMC | Fisher Cholesky | |
| NUTS | leapfrog |
The Pareto frontier shifts with : at small NUTS dominates; at medium RMHMC dominates; at large SMC closes the gap because its cost beats RMHMC’s Cholesky per step.
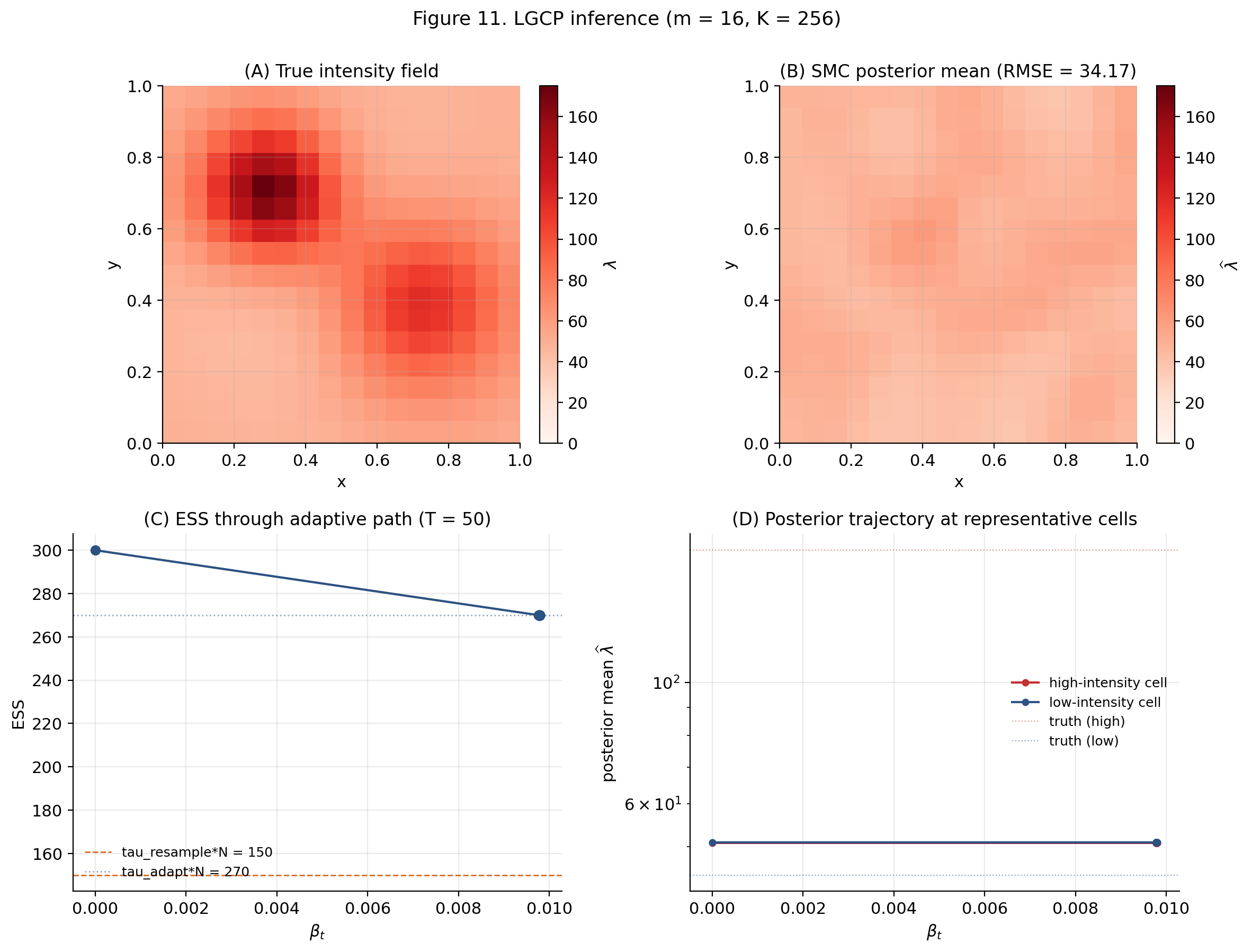
The viz below loads a precomputed payload (Python: notebooks/sequential-monte-carlo/precompute_lgcp.py) for . The case is too heavy for in-browser SMC sampling; the precompute handles it offline and the viz displays the result. Pick a grid resolution to switch between , , and inference results.
§12. Computational Notes
Implementation-discipline coda: four practical disciplines that separate correct from production-grade SMC.
12.1 Buffer hoisting and the resampling hot path
Pre-allocate per-particle buffers once before the outer loop; reuse with in-place writes:
particles = np.empty((N, d), dtype=np.float64)
log_weights = np.zeros(N, dtype=np.float64)
log_lik_cache = np.empty(N, dtype=np.float64)
cumulative_w = np.empty(N, dtype=np.float64)
resampled_indices = np.empty(N, dtype=np.intp)Anti-patterns to avoid: np.random.choice(N, size=N, p=weights) (allocator pressure on every call); cumulative_w = np.cumsum(w) (fresh allocation) instead of np.cumsum(w, out=cumulative_w) (in-place); list-of-arrays storage instead of contiguous arrays.
12.2 Log-space weight updates and logsumexp idioms
Particle weights on hard targets span 10+ orders of magnitude. Linear-space representation silently underflows on the kind of targets we care about.
Four idioms.
- Additive log-weight update:
log_w += delta_beta * log_lik_cache. - Normalize via
logsumexp:log_w_norm = log_w - logsumexp(log_w). - ESS in log-space:
ess = np.exp(-logsumexp(2.0 * log_w_norm)). - Cumulative :
log_z = logsumexp(log_w) - np.log(N).
Failure mode this prevents: Neal’s funnel target — weights span orders within 5 SMC steps; linear-space silently collapses to a single particle carrying all the mass, while log-space remains numerically well-behaved.
scipy.special.logsumexp uses the shift-then-exp trick: .
12.3 Parallelization across particles
SMC has a clean parallelism structure:
- Embarrassingly parallel within a step (reweight and propagate operate per-particle).
- Synchronization required at resampling (needs the global cumulative-weight array).
- Strict serial across steps (step depends on step ).
Vectorized NumPy (single node) — the default in this topic, handles on a multicore laptop.
Distributed compute (MPI). For or : assign each rank a slice of the cloud, use MPI_Allreduce on log-weight sums, and MPI_Alltoall at resample steps. The particles library implements this.
GPU acceleration. Feasible for kernel evaluation; tricky for resampling because of the synchronization step. Modest speedup (1–3×) vs optimized CPU NumPy for typical SMC samplers.
12.4 Diagnostics via ArviZ
Convert the weighted cloud to ArviZ InferenceData by resampling to equal weights:
def to_inferencedata(theta, log_w, var_names):
import arviz as az
log_w_norm = log_w - logsumexp(log_w)
w_norm = np.exp(log_w_norm)
idx = np.searchsorted(np.cumsum(w_norm), np.random.random(len(theta)))
samples = theta[idx]
samples_dict = {name: samples[:, i:i+1] for i, name in enumerate(var_names)}
return az.from_dict(samples_dict)Standard diagnostics: az.ess (bulk and tail), az.rhat for multi-replicate runs, trace plots (with the caveat that SMC output is a weighted cloud, not a chain history), posterior predictive checks.
Log-evidence convention. Attach to idata.sample_stats.log_marginal_likelihood per PyMC convention.
Diagnostic checklist:
- Path length: did the adaptive schedule converge to within budget?
- Min ESS along the path: did it stay above except at resampling steps?
- Kernel acceptance rate: above 0.2 for IMH cloud-fit, near 0.234 for RWM?
- stability across replicates: agreement within MC error?
§13. Connections and Limits
Closing the topic with curriculum-positioning. Where does SMC sit relative to other specialized samplers? What does it gain or lose? What are the active research frontiers?
13.1 SMC in the specialized-sampler cluster
The four T5 Advanced Bayesian Computation topics:
- Stochastic-Gradient MCMC — Langevin/HMC flavors, single-chain, scales via subsampling, no log-evidence.
- Riemann Manifold HMC — Fisher-metric mass matrix, best for smooth anisotropic targets.
- Reversible-Jump MCMC (coming soon) — transdimensional inference across model spaces of different dimension.
- Probabilistic Programming — the PPL infrastructure wrapping NUTS and
pm.sample_smc.
Pareto frontier:
| Sampler | Best regime | Trade-off |
|---|---|---|
| NUTS | Smooth unimodal, moderate | Fast per-step; no log-evidence |
| RMHMC | Smooth anisotropic | Per-step ; no log-evidence |
| SG-MCMC | Huge- smooth | Biased; subsamples data |
| SMC samplers | Multimodal; log-evidence needed | Higher constants; unbiased log-evidence |
| Mean-field VI | Fast approximate | Posterior factorization bias |
| Normalizing-flow VI | Amortized deployment | Expensive training |
| INLA | Latent Gaussian | Specialized model class |
Three-question taxonomy. (1) Need log-evidence? → SMC. (2) Multimodal? → SMC. (3) Otherwise smooth unimodal? → NUTS/RMHMC.
13.2 SMC vs normalizing flows
| Normalizing flows | SMC samplers | |
|---|---|---|
| Training cost | Expensive (often GPU) | Negligible |
| Per-sample cost | per evaluation | for cloud |
| Sample quality | Limited by training error | Exact in |
| Log-evidence | Available (change-of-variables) | Available (running ) |
| Multimodal | Requires expressive architectures | Native via tempering |
| Deployment | One training + many samples | Many parallel SMC runs |
Use flows when the same target is sampled many times (amortized inference); use SMC when each problem instance has a different target (one-shot inference).
Hybrid approaches:
- Normalizing-flow proposals in SMC (Arbel, Matthews, and Doucet 2021).
- SMC-trained flows (Naesseth, Linderman, Ranganath, and Blei 2018).
13.3 SMC for Bayes factors and posterior model probabilities
Unbiased (Theorem 4) supports direct Bayes-factor computation:
Practical workflow: run SMC on each candidate model, compute pairwise log-Bayes-factors, apply Jeffreys’s scale ( is strong evidence).
Posterior model probabilities via logsumexp across models:
Caveats: the Jensen-gap bias (§8.3) partly cancels in ratios but not exactly; Lindley’s paradox (prior sensitivity in Bayes factors); nested vs non-nested models require care in defining the prior.
This discharges the cross-site forward-pointer to formalStatistics: bayesian-model-comparison-and-bma — SMC samplers are the canonical unbiased alternative to bridge sampling and harmonic-mean estimators in the model-evidence catalogue (formalstatistics treats marginal-likelihood / Bayes-factor computation in that topic).
13.4 Frontiers
- Particle Gibbs (Andrieu, Doucet, and Holenstein 2010): particle MCMC for joint inference. Combines an SMC sweep over states with a Metropolis acceptance on the parameter.
- SMC² (Chopin, Jacob, and Papaspiliopoulos 2013): doubly-nested SMC; outer chain on parameters, inner SMC on states.
- Divide-and-conquer SMC (Lindsten et al. 2017): for graphical-model factorizations where the target decomposes hierarchically.
- Variational SMC (Naesseth et al. 2018): neural-network-parameterized SMC proposals trained end-to-end against the ELBO.
Open research (as of 2026):
- Adaptive proposals via reinforcement learning, where the kernel choice itself is a learnable policy.
- Quasi-Monte Carlo SMC (Gerber and Chopin 2015), trading independent uniforms for low-discrepancy sequences.
- GPU acceleration for the resampling step — currently the bottleneck in distributed SMC implementations.
The specialized-sampler cluster completes with Reversible-Jump MCMC (coming soon), which handles transdimensional moves that SMC operates within. The two are routinely combined: SMC for adaptive temperature within each model dimension, RJ-MCMC for jumps between dimensions.
Connections
- Probabilistic-programming exposes `pm.sample_smc` as a first-class inference engine; §8.4 and §11.3 here reproduce its results with a hand-rolled NumPy implementation, and §7.3 documents IMH-cloud-fit as the kernel `pm.sample_smc` uses by default. The discharge of probabilistic-programming's §6.3 forward-pointer to SMC lives in §8.2 (unbiased log-evidence) and §11 (LGCP comparison). probabilistic-programming
- RMHMC and SMC samplers solve the same problem — sampling from a hard posterior — by opposite strategies: RMHMC adaptively shapes the kinetic energy, SMC adaptively schedules an annealing path. §11.3 places SMC on the Pareto frontier RMHMC introduced, discharging RMHMC §12's forward-pointer to sequential Monte Carlo. riemann-manifold-hmc
- SG-MCMC and SMC are sibling specialized samplers in the T5 cluster — SG-MCMC scales via subsampling at the cost of bias, SMC scales via parallel particle clouds and returns unbiased log-evidence as a side product. §13.1's three-question taxonomy positions each. stochastic-gradient-mcmc
- VBMS uses ELBO-as-log-evidence with a variational-family bias; SMC samplers return unbiased log-evidence at finite N (Theorem 4). §8.4 and §13.3 here discharge VBMS's §13 forward-pointer to SMC by showing the GMM Bayes-factor comparison and the posterior-model-probability formula. variational-bayes-for-model-selection
- Annealed flow transport (Arbel–Matthews–Doucet 2021) uses normalizing-flow proposals inside SMC; SMC-trained flows (Naesseth et al. 2018) flip the direction. The §13.2 comparison and §13.4 hybrid table position the two methods. normalizing-flows
- §10.4's Theorem 8 finite-sample concentration bound is a Bernstein-type inequality on the SMC path-measure empirical process — a direct application of the concentration toolkit to interacting-particle systems. concentration-inequalities
- RJ-MCMC handles transdimensional moves where SMC operates within a fixed dimension; the two are routinely combined, with SMC running adaptive temperature on each model dimension and RJ-MCMC jumping between dimensions. SMC closes the specialized-sampler cluster that RJ-MCMC will complete. reversible-jump-mcmc
References & Further Reading
- paper Novel Approach to Nonlinear/Non-Gaussian Bayesian State Estimation — Gordon, Salmond & Smith (1993) The bootstrap particle filter origin paper. IEE Proceedings F.
- paper Equation of State Calculations by Fast Computing Machines — Metropolis, Rosenbluth, Rosenbluth, Teller & Teller (1953) Journal of Chemical Physics. The MH algorithm ancestor.
- paper Monte Carlo Sampling Methods Using Markov Chains and Their Applications — Hastings (1970) Biometrika. The Metropolis–Hastings algorithm.
- paper Annealed Importance Sampling — Neal (2001) Statistics and Computing. The SMC-samplers progenitor; the special case with one kernel application per step.
- book Sequential Monte Carlo Methods in Practice — Doucet, de Freitas & Gordon (eds.) (2001) Springer. The canonical edited volume on early SMC methods.
- paper Sequential Monte Carlo Samplers — Del Moral, Doucet & Jasra (2006) JRSS B. The SMC-samplers framework; Theorem 4 (unbiased log-evidence) appears here as Proposition 1.
- paper A Tutorial on Particle Filtering and Smoothing: Fifteen Years Later — Doucet & Johansen (2011) In *The Oxford Handbook of Nonlinear Filtering*. Comprehensive modern survey.
- paper Log Gaussian Cox Processes — Møller, Syversveen & Waagepetersen (1998) Scandinavian Journal of Statistics. The LGCP model origin paper used in §11.
- book Feynman–Kac Formulae: Genealogical and Interacting Particle Systems with Applications — Del Moral (2004) Springer. The definitive convergence-theory monograph; the Feynman–Kac framework underlying §10.
- paper An Overview of Existing Methods and Recent Advances in Sequential Monte Carlo — Cappé, Godsill & Moulines (2007) Proceedings of the IEEE. Modern survey covering convergence theory and practical refinements.
- book Inference in Hidden Markov Models — Cappé, Moulines & Rydén (2005) Springer. HMM monograph; Chapters 7–8 give the particle-filter-specific convergence theory.
- book An Introduction to Sequential Monte Carlo — Chopin & Papaspiliopoulos (2020) Springer. The modern textbook; Chapters 7 and 11 cover convergence theory at textbook level.
- paper On Sequential Monte Carlo Sampling Methods for Bayesian Filtering — Doucet, Godsill & Andrieu (2000) Statistics and Computing. The ESS-thresholded resampling rule and its variance analysis.
- paper On the Convergence of Adaptive Sequential Monte Carlo Methods — Beskos, Jasra, Kantas & Thiery (2016) Annals of Applied Probability. Rigorous treatment of adaptive SMC unbiasedness.
- book Asymptotic Statistics — van der Vaart (1998) Cambridge University Press. Chapter 10 contains the Bernstein–von Mises theorem invoked in §2.3.
- paper Filtering via Simulation: Auxiliary Particle Filters — Pitt & Shephard (1999) JASA. The auxiliary particle filter (§6.3).
- paper An Adaptive Sequential Monte Carlo Method for Approximate Bayesian Computation — Del Moral, Doucet & Jasra (2012) Statistics and Computing. The canonical ESS-driven adaptive temperature schedule reference.
- paper Inference for Lévy-driven Stochastic Volatility Models via Adaptive Sequential Monte Carlo — Jasra, Stephens, Doucet & Tsagaris (2011) Scandinavian Journal of Statistics. Application of ESS-driven adaptive scheduling.
- paper Monte Carlo Filter and Smoother for Non-Gaussian Nonlinear State Space Models — Kitagawa (1996) JCGS. Systematic and stratified resampling.
- paper Sequential Monte Carlo Methods for Dynamic Systems — Liu & Chen (1998) JASA. Residual resampling.
- book Monte Carlo Strategies in Scientific Computing — Liu (2001) Springer. Textbook treatment of IS variance, ESS, and SMC; consolidates the Kong 1992 ESS formula.
- paper Particle Markov Chain Monte Carlo Methods — Andrieu, Doucet & Holenstein (2010) JRSS B. Particle Gibbs and the particle MCMC framework.
- paper SMC²: An Efficient Algorithm for Sequential Analysis of State Space Models — Chopin, Jacob & Papaspiliopoulos (2013) JRSS B. Doubly-nested SMC.
- paper Divide-and-Conquer with Sequential Monte Carlo — Lindsten, Johansen, Naesseth, Kirkpatrick, Schön, Aston & Bouchard-Côté (2017) JCGS. Divide-and-conquer SMC for graphical-model factorizations.
- paper Sequential Quasi Monte Carlo — Gerber & Chopin (2015) JRSS B. Quasi-Monte Carlo SMC.
- paper Langevin Diffusions and Metropolis-Hastings Algorithms — Roberts & Stramer (2002) Methodology and Computing in Applied Probability. Banana distribution origin.
- paper An Adaptive Metropolis Algorithm — Haario, Saksman & Tamminen (2001) Bernoulli. Banana popularization for Hamiltonian samplers.
- paper Multivariate Stochastic Variance Models — Harvey, Ruiz & Shephard (1994) Review of Economic Studies. Quasi-likelihood Kalman approximation for SV models.
- paper Simulating Ratios of Normalizing Constants via a Simple Identity: A Theoretical Exploration — Meng & Wong (1996) Statistica Sinica. Bridge sampling.
- paper Approximating Bayesian Inference with the Weighted Likelihood Bootstrap — Newton & Raftery (1994) JRSS B. Harmonic-mean estimator (the §8.4 failure baseline).
- paper Weak Convergence and Optimal Scaling of Random Walk Metropolis Algorithms — Roberts, Gelman & Gilks (1997) Annals of Applied Probability. RWM optimal scaling (acceptance ≈ 0.234).
- paper Optimal Tuning of the Hybrid Monte Carlo Algorithm — Beskos, Pillai, Roberts, Sanz-Serna & Stuart (2013) Bernoulli. HMC optimal scaling used in §5.3.
- book Pattern Recognition and Machine Learning — Bishop (2006) Springer. Chapter 10 §10.2 on Bayesian GMM with ARD.
- paper Annealed Flow Transport Monte Carlo — Arbel, Matthews & Doucet (2021) PMLR vol. 139 (ICML 2021). Normalizing-flow proposals in SMC.
- paper Variational Sequential Monte Carlo — Naesseth, Linderman, Ranganath & Blei (2018) PMLR vol. 84 (AISTATS 2018). Variational SMC.