Riemann Manifold HMC
Hamiltonian Monte Carlo on the manifold of probability distributions, using the Fisher information metric to traverse pathological posteriors that defeat constant-mass-matrix HMC
§1. Overview & Motivation
1.1 Where HMC breaks
Standard Hamiltonian Monte Carlo treats parameter space as flat Euclidean territory. Once we pick a mass matrix — typically the identity, or at best a constant preconditioner estimated from a pilot run — every direction in the parameter space gets scaled the same way, everywhere on the support. The leapfrog integrator marches across this flat landscape with a uniform step size , and as long as the target’s geometry is roughly homogeneous, that works beautifully.
It stops working the moment local curvature varies across the support. Three textbook examples expose the failure mode.
Neal’s funnel. Consider the hierarchical prior with . The marginal density on traces a horn-shaped support that’s narrow at one end — small , where has variance near 1 — and broad at the other, where has variance . A constant mass matrix forces a single step size. Too small, and HMC takes years to traverse the broad end; too large, and it shoots past the narrow neck on every iteration. The funnel is the canonical failure case in Bayesian hierarchical modeling — every practitioner has been bitten by it.
The banana. Take a bivariate Gaussian on and apply the warp . The result is the banana distribution of Haario, Saksman, and Tamminen (2001) — a curved ridge whose orientation rotates as we move along it. The Fisher information here varies smoothly with position: where the ridge is steep, has a strong off-diagonal; where it’s shallow, is nearly diagonal. Standard HMC with constant can’t reflect that local rotation, so trajectories either spiral away from the ridge (large ) or crawl along it (small ).
Ill-conditioned hierarchical likelihoods. Even outside designed pathologies, real models often have parameters that mix on wildly different scales — population-level versus group-level variance components, regression coefficients with very different prior scales. Each direction wants its own step size. A diagonal preconditioner helps a bit but only handles conditioning that’s constant across the support; anywhere the curvature changes with position, we’re back to the same trade-off.
The pattern that connects all three: the local Fisher information
— the matrix of expected second derivatives of the log-likelihood, with the expectation taken over the data distribution at — is not constant, but standard HMC pretends it is.
1.2 The geometric fix
The Girolami–Calderhead (2011) move is to stop pretending. We promote the mass matrix from a constant to a function of position: , with the Fisher information at . The Hamiltonian becomes
where is the negative log-posterior (our potential energy), and the extra log-determinant comes from normalizing the momentum’s conditional distribution at each position. Read geometrically, this says: parameter space is a Riemannian manifold equipped with the Fisher metric, momentum lives in the cotangent bundle, and Hamiltonian flow now follows geodesics of the manifold rather than straight lines.
The pathology of the funnel and the banana evaporates in this picture. Where the original geometry was steep, is large and the metric scales the local step accordingly; where the geometry was loose, is small and the step opens up. The same nominal now produces locally-appropriate motion everywhere.
There’s a cost. The new Hamiltonian is not separable — doesn’t split into a form, because the kinetic part depends on through . The standard explicit leapfrog loses its symplecticity in that case, so we have to upgrade to an implicit integrator: each leapfrog step solves a fixed-point equation for the new momentum, and another for the new position. Each step also requires factorizing — typically by Cholesky, since we need both and .
For the targets RMHMC is designed for, the cost is worth it. For an isotropic Gaussian on a well-conditioned likelihood, it isn’t. §8 makes this trade quantitative.
1.3 What you’ll need from elsewhere
This is an advanced topic and we lean heavily on the foundation.
From formalStatistics: bayesian-computation-and-mcmc , we assume comfortable familiarity with §26.9–10 on standard HMC: the canonical joint , Hamilton’s equations, the leapfrog integrator’s symplecticity and reversibility, the Metropolis correction, and the No-U-Turn heuristic for trajectory length. §2 here is a notation refresher, not a re-derivation. The §26.10 Remark 29 forward-pointer to Riemannian-manifold methods is discharged by the present topic.
From Information Geometry, we use the Fisher information metric and Čencov’s uniqueness theorem. The Fisher metric will be the mass matrix; we want the reader to recognize that this is not an arbitrary choice but the canonical Riemannian structure on the manifold of probability distributions — the unique (up to scale) metric invariant under sufficient statistics.
From Riemannian Geometry and Geodesics and Curvature, we use the metric tensor, the geodesic equation, Christoffel symbols, and parallel transport. RMHMC’s Hamiltonian flow is geodesic flow on the manifold of distributions, perturbed by the gradient of the potential.
From formalcalculus, we use the formalCalculus: jacobian for the volume-preservation theorem in §6 and the formalCalculus: inverse-implicit for the well-posedness of the implicit leapfrog in §5.
From the Stochastic-Gradient MCMC topic shipped earlier in T5, §10 introduced the position-dependent Riemannian metric in the SDE setting — RSGLD. We treat that as the SDE companion; the present topic does the Hamiltonian-flow side.
1.4 The Girolami–Calderhead 2011 program
The defining paper of Riemannian-manifold MCMC is Mark Girolami and Ben Calderhead’s “Riemann manifold Langevin and Hamiltonian Monte Carlo methods” (Journal of the Royal Statistical Society, Series B, vol. 73, 2011), with discussion. The paper does several things at once. It introduces the Riemann-manifold Langevin algorithm (RMLA) and Riemann-manifold HMC (RMHMC) as a pair, with the Fisher information as the canonical metric tensor for both. It works through the differential geometry needed for non-statisticians, derives the generalized leapfrog integrator, and provides three substantial empirical demonstrations: the banana distribution, a stochastic-volatility model, and a log-Gaussian Cox process for spatial statistics. The discussion section runs more than thirty pages and includes contributions from many of the leading figures in computational statistics.
The contribution that survives most cleanly into modern practice is the framework, not the specific integrator: the idea that a posterior’s local geometry can and should be exploited by gradient-based MCMC, and that the Fisher information is the natural carrier of that geometry. Variants and extensions have followed — SoftAbs metrics (Betancourt 2013) when the Fisher matrix is ill-defined or non-positive-definite, Hessian-based metrics for non-conjugate models, magnetic HMC, and the integration of RMHMC ideas into NUTS-style adaptive trajectory tuning. §12 surveys these.
1.5 Roadmap
The plan from here. §2 is a notation refresher for HMC — anyone who has read formalstatistics §26 can skim it. §3 rebuilds the Riemannian-geometry vocabulary we’ll need, anchored in the Fisher metric. §4 writes down the Riemannian Hamiltonian and Hamilton’s equations on the manifold; this is where the new log-determinant term gets interpreted. §5 is the core integrator construction: why the explicit leapfrog fails, what the implicit splitting looks like, and how to actually solve the fixed-point system in code. §6 collects the three load-bearing proofs — volume preservation, reversibility, detailed balance. §7 discusses tuning. §8 is the cost analysis. §§9–10 are worked examples: the banana, then a downsized log-Gaussian Cox process. §11 is the implementation patterns the project enforces — buffer hoisting, SPD-stable solves, multi-chain diagnostics. §12 zooms out to natural gradient, position-dependent SDEs, and the active research frontier.
The notebook tracks the brief section-for-section. Every section that carries new math has both expository markdown and validating code; §§9–10 are entirely empirical.
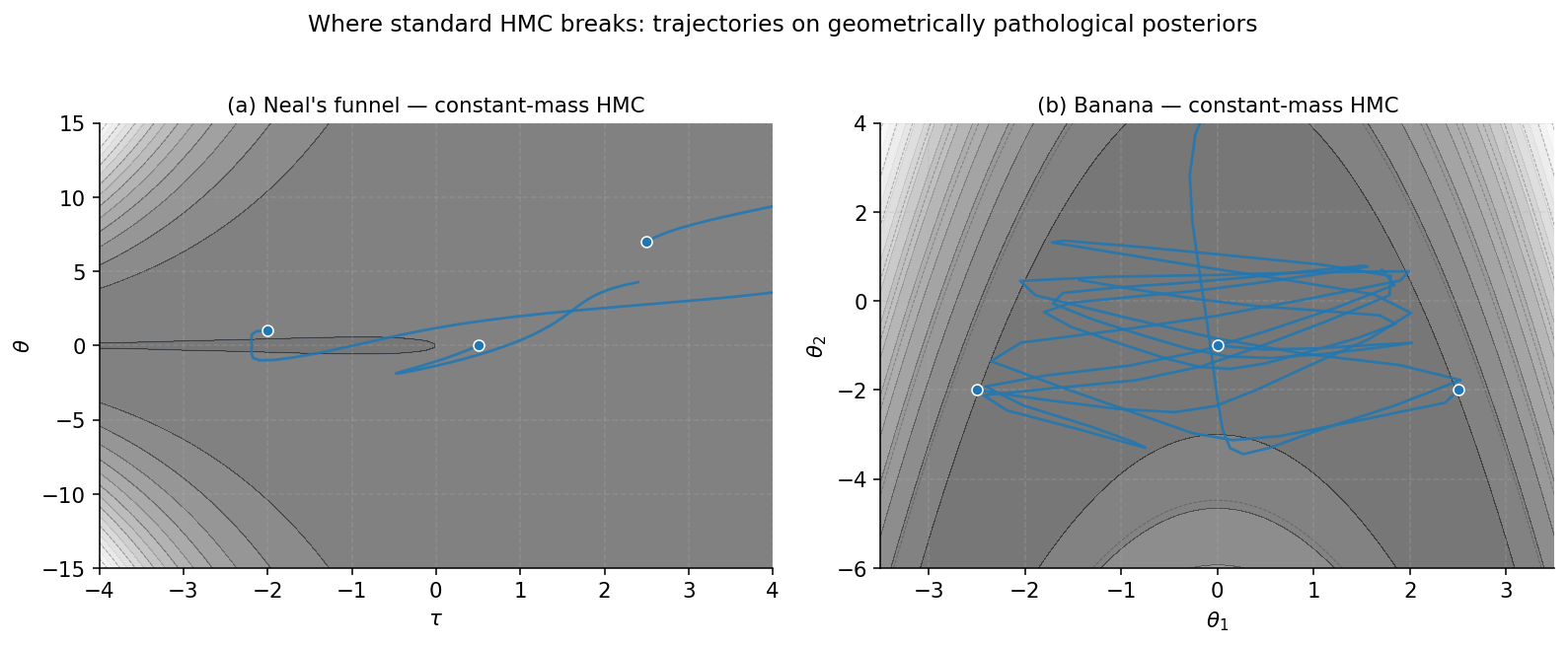
§2. HMC at a glance
This section establishes the notation and the three properties of the standard leapfrog integrator — symplecticity, reversibility, energy conservation up to bounded oscillation — that the rest of the topic rebuilds for the new integrator. We assume the reader has worked through standard HMC in formalStatistics: bayesian-computation-and-mcmc §26.9–10 or Neal (2011); the treatment here is consciously compressed. If anything below feels like new material rather than recall, that’s a signal to read the prereqs before continuing.
2.1 The Hamiltonian and the canonical joint
Let denote our target distribution on , where (up to additive constants) is the potential energy — the negative log-target. HMC augments parameter space with an auxiliary momentum variable and constructs a joint distribution
where is a fixed, symmetric, positive-definite mass matrix and the second term is the kinetic energy . Because depends only on (not on ), the joint factorizes: . Marginalizing over recovers the target, so sampling and discarding samples — the augmentation is “free.”
The Hamiltonian generates a continuous-time flow on space via Hamilton’s equations,
Three properties of matter for what follows. First, preserves — the value of the Hamiltonian is constant along any flow trajectory, so trajectories stay on level sets of . Second, is symplectic — it preserves the differential 2-form , which in particular implies is volume-preserving on space. Third, is reversible under momentum negation: if we define , then . These three together imply preserves the canonical measure exactly — if we could integrate Hamilton’s equations in closed form, HMC would need no Metropolis correction. We can’t, so we discretize.
2.2 The leapfrog integrator
The natural discretization is the leapfrog (or Störmer–Verlet) integrator. From , a single leapfrog step of size produces via
The integrator is explicit — each line is a closed-form update — because depends only on and depends only on . This is the defining structural property that breaks in §5: the Riemannian Hamiltonian’s kinetic term depends on , so the position update becomes , and we have to decide which to evaluate at — which is where implicitness enters.
Why the leapfrog works. Each of the three sub-steps is a shear in space: the momentum half-steps move at fixed , and the position step moves at fixed . Shears preserve the symplectic 2-form trivially, and the composition of symplectic maps is symplectic, so the full leapfrog map is symplectic — and therefore volume-preserving. The same symmetry of the three sub-steps about the central position update gives reversibility: .
What the leapfrog does not preserve is exactly. It has local error and global error over a fixed integration time . But because the integrator is symplectic, the energy error oscillates around zero with bounded amplitude rather than drifting secularly — a result from backward error analysis (Hairer, Lubich, and Wanner 2006, ch. IX) that makes long-trajectory simulation feasible at moderate . The Metropolis correction at the end of each trajectory restores exactness despite the residual integrator error, with acceptance probability .
2.3 Where the constant mass matrix becomes a ceiling
The mass matrix acts as a metric on momentum space. Reading geometrically: large in a direction means small kinetic energy contribution from large momentum in that direction, so trajectories cover ground faster there. The optimal choice for a Gaussian target is , which makes the level sets of spherical and decorrelates the leapfrog dynamics. Hoffman and Gelman’s NUTS (2014) and Stan’s adaptive HMC both estimate during warmup, typically as a diagonal or full-rank empirical-covariance preconditioner.
The estimate is global. It captures the average curvature of the target over the warmup chain. When the target’s actual local curvature varies smoothly with position — when the Fisher information matrix depends on — no single constant can match all of it. Pick to suit the loose part of the support and the tight part rejects every proposal; pick to suit the tight part and the loose part mixes at glacial speed.
This is the gap. From §3 onward we promote to a function of , recover the three properties of the leapfrog by other means (implicit splitting), and pay the per-step Cholesky cost in exchange for a step size that’s locally appropriate everywhere.
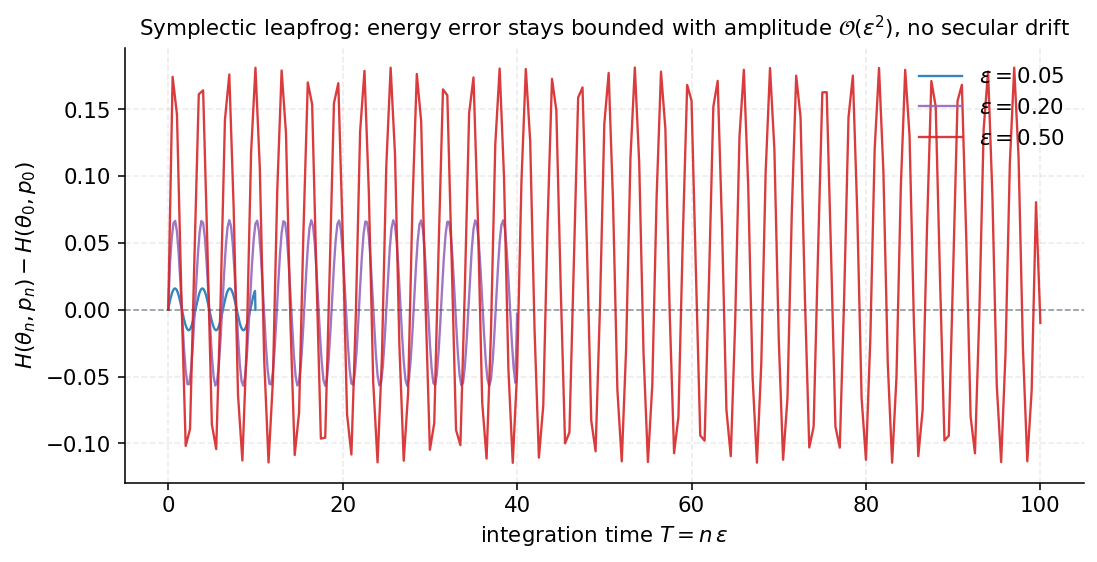
§3. Riemannian geometry of probability
The pieces this section assembles: the Fisher information matrix recast as a Riemannian metric, the cotangent picture of momentum that makes the RMHMC kinetic energy the natural choice rather than an arbitrary one, the geodesic equation in coordinate form, and Čencov’s uniqueness theorem. All of this material is developed at full length in Information Geometry and Riemannian Geometry; the present treatment stays terse and consciously selects what §§4–6 will need.
3.1 The Fisher information as a Riemannian metric
Let be a parametric family of probability densities on a sample space , smooth in . The score function is the gradient of the log-density,
and under standard regularity (smooth interchange of and ), it has mean zero:
The Fisher information matrix is the covariance of the score,
A second differentiation gives the equivalent negative-expected-Hessian form. Starting from and differentiating in again,
The first integrand is (using ) and the second is , so
A third equivalent form recovers the connection to information divergences: is the Hessian of the KL divergence at the diagonal,
This last identity — derived in the Information Geometry topic — is why deserves the name “metric”: it measures, infinitesimally, the squared distance between and a nearby distribution. The pair is a Riemannian manifold, and we’ll use when emphasizing the metric viewpoint and when emphasizing the matrix viewpoint.
Remark (Non-likelihood targets).
For Bayesian inference, the target is a posterior , and the natural metric is the Bayesian Fisher — the expected likelihood-Fisher plus the prior precision. For toy targets defined directly by a log-density (the §1 banana, for instance), there is no expectation over data and two options exist. The observed Hessian can fail to be positive-definite at some , in which case SoftAbs regularization (Betancourt 2013, §12 below) restores SPD by mapping the eigenvalues through a smooth absolute-value. The Gauss-Newton alternative — derive the target as a least-squares posterior, then use the Fisher information of the corresponding likelihood — is always SPD by construction and is the route Girolami and Calderhead take for their banana benchmark. We use Gauss-Newton in §9; the construction is spelled out there.
3.2 Cotangent vectors and index-raising
Stand at a point . The tangent space is the vector space of velocities — directions a parameter trajectory can move. The cotangent space is its dual: the space of linear functionals on . Concretely, a tangent vector has components and a cotangent vector has components — the index position records which kind of object you’re holding.
The metric gives a canonical isomorphism between the two spaces. Each tangent vector defines a cotangent vector via for any . In coordinates this is index lowering: , summing over the repeated index. The inverse map, index raising, sends a cotangent vector to the tangent vector with components , where is the matrix inverse of — equivalently, .
Why this matters for RMHMC. Position lives on the manifold and its velocity is naturally a tangent vector. Momentum , the conjugate variable, is naturally a cotangent vector — it pairs with velocity via the Lagrangian formulation, , which lands in the dual space. The kinetic energy is the squared norm of measured in the inverse metric on the cotangent space:
This is exactly the kinetic term in the Girolami–Calderhead Hamiltonian. The is doing index-raising — converting the cotangent momentum into the tangent velocity , which is what Hamilton’s first equation will say in §4. Read this way, the RMHMC kinetic energy isn’t a clever choice; it’s the unique kinetic energy compatible with treating momentum as a cotangent vector and the metric as Fisher.
3.3 Geodesics, Christoffel symbols, and the geodesic equation
On a flat manifold, a free particle moves in a straight line. On a curved one, “straight” gets replaced by geodesic — the curve that locally minimizes arc length, or equivalently, the curve whose tangent vector parallel-transports along itself. In coordinates, a curve is a geodesic of if
with Einstein summation over . The Christoffel symbols are determined by the metric:
These are not tensor components — they transform inhomogeneously under coordinate changes — but the geodesic equation as a whole is coordinate-invariant. On a flat manifold ( constant), all and the equation collapses to , recovering Newton’s first law.
What this means for RMHMC. Hamilton’s equations on , derived in §4, contain Christoffel-symbol-like terms in the momentum update — the price of position-dependent kinetic energy. When the potential is zero, Hamilton’s equations on the manifold reduce exactly to the geodesic equation: the leapfrog integrator becomes a geodesic integrator, and the trajectory follows the geometry of with no external force. When , we get geodesic flow perturbed by . The pathological posteriors of §1 are pathological precisely because their flat trajectories don’t track the manifold’s geometry; their geodesic trajectories do.
For the banana model of §9, the only nonzero Christoffel symbol turns out to be — and that single component is exactly what’s needed to bend the geodesic into the ridge’s curvature. The viz below demonstrates this with a corrected closed-form Christoffel computation; the static fallback PNG uses a slightly off implementation from the notebook and may show the geodesic curving the wrong direction, so trust the live viz for the geometric story.
3.4 Čencov’s uniqueness
Why the Fisher metric and not some other position-dependent metric? Čencov’s theorem (Čencov 1972, refined by Campbell 1986; see Information Geometry for full proof) answers this.
Theorem 1 (Čencov uniqueness).
Let be the category of finite statistical manifolds, where morphisms are Markov kernels. The Fisher information metric is the unique (up to a positive scalar multiple) Riemannian metric on every object of that is invariant under all morphisms — that is, the unique metric for which every sufficient statistic acts as an isometry between source and target manifolds.
Translated: take any parametric family and any sufficient statistic for it; the induced family has its own statistical manifold, and the Fisher metric on the original manifold pushes forward to the Fisher metric on the new one. No other Riemannian metric on statistical manifolds has this invariance property.
For RMHMC, this is the foundational sanity check: the choice of position-dependent metric is not arbitrary tuning. The Fisher information is the unique canonical Riemannian structure on a manifold of distributions. Variants — SoftAbs, observed Hessian, Hessian-based metrics — sacrifice this invariance to gain computational tractability or PSD-ness. They are useful approximations; Fisher is the reference point against which they are judged.
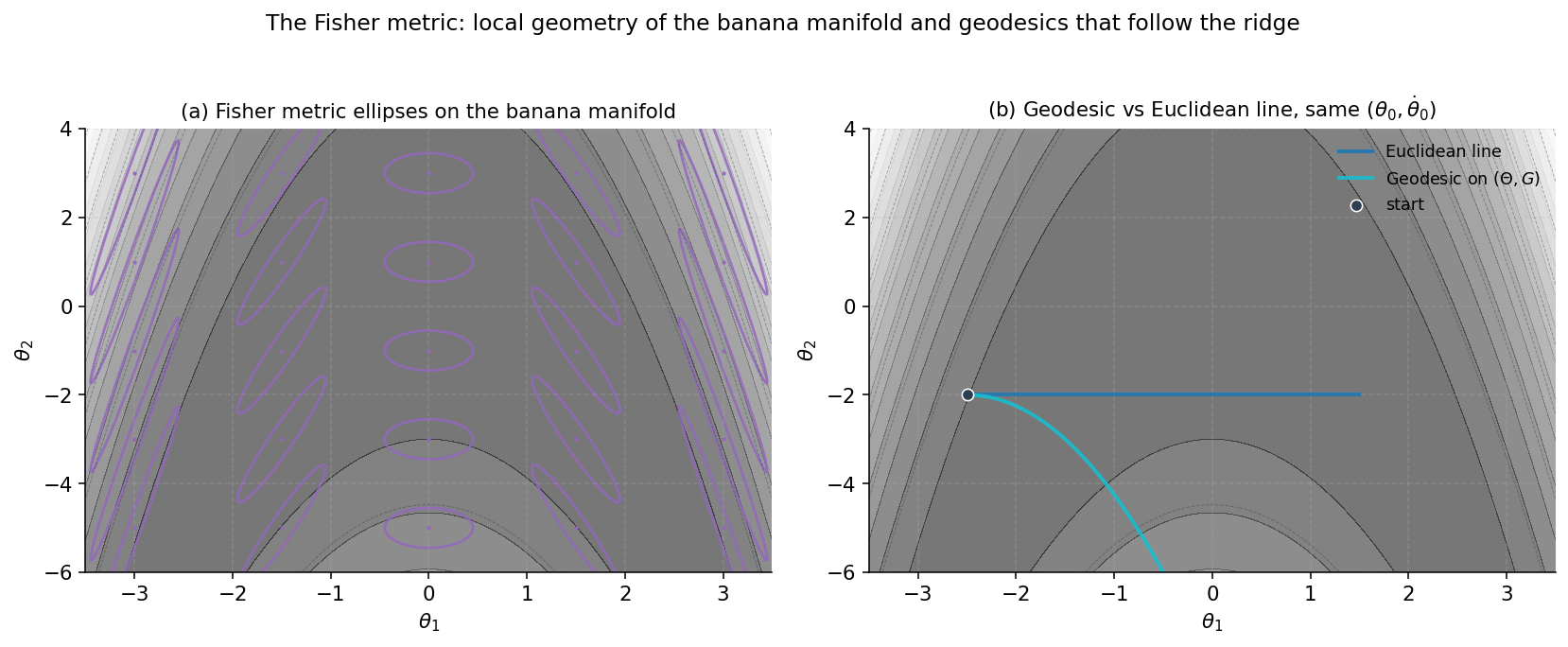
§4. The Riemannian Hamiltonian
Standard HMC’s mass matrix was a single constant. The promotion to a position-dependent metric — with the Fisher information — changes three things at once: the momentum distribution, the kinetic energy, and the Hamiltonian itself. The third change is the subtle one: an extra log-determinant term appears in , and it has to be there for the marginalization to recover the target. This section assembles all of it.
4.1 The position-dependent mass matrix
In standard HMC, the mass matrix is a fixed SPD matrix — typically the identity, or a covariance estimate from warmup. Read through the §3.2 lens, functions as a metric on momentum space: it tells us how to convert a cotangent vector (momentum) into a tangent vector (velocity) via , and how to assign a squared norm to momentum via .
RMHMC’s move is to let this metric depend on position. We set , where is the Fisher information matrix at (canonically; see §3 for the why-Fisher argument). The momentum’s conditional distribution becomes — a Gaussian whose covariance changes with where we are on the manifold. In coordinates where the manifold has high local curvature (large eigenvalues of ), momentum is sampled with large variance, so trajectories explore vigorously in that region; where curvature is low, momentum is small and trajectories crawl. This is the inverse of what standard HMC does with a constant — there, momentum scale is fixed, and pathological geometry punishes the trajectory.
Two consequences are immediate and matter for everything that follows. The kinetic energy gains -dependence: . And because the momentum density has a -dependent normalizing constant, the joint density we’re sampling from will need an explicit log-determinant correction to remain consistent with the target. We work that out next.
4.2 The augmented joint density
The target is with . Augment with momentum . The joint is the product of the marginal and the conditional:
Take the negative log and collect terms up to additive constants in :
This is the Girolami–Calderhead Hamiltonian. The three terms are the potential energy , the position-dependent kinetic energy , and a new volume term that wasn’t there in flat-space HMC.
The volume term is exactly what’s needed for marginal correctness. Marginalize from the joint :
The remaining Gaussian integral evaluates to , so the right-hand side simplifies to . The from the Gaussian normalizer exactly cancels the from the volume term, leaving the target. Drop the volume term and the marginal would be wrong — it would be proportional to , which is not what we want to sample.
This is also why the volume term cannot be absorbed into as a redefinition of the potential. It must appear in precisely as written, because the same factor of also appears in the momentum normalizer that the sampler implicitly uses every time it draws a momentum, and the two have to cancel.
4.3 The three terms
Let’s interpret each piece of .
The potential energy is unchanged from flat-space HMC. It tells the dynamics where the target prefers to be: gradients of pull trajectories toward high-density regions of .
The kinetic energy is now position-dependent. Read geometrically, is the squared norm of the cotangent momentum measured in the inverse metric — exactly the construction of §3.2. The position-dependence makes non-separable from : the kinetic and potential coordinates are entangled by the metric. This is the property that breaks the explicit leapfrog in §5.
The volume term is the new piece. It’s a purely geometric potential — it depends only on the manifold, not on the target. We can think of it as a “geometric correction” that prevents the dynamics from preferring high-determinant regions of the manifold over low-determinant ones. Without , regions where has large eigenvalues would oversample momentum and skew the joint.
A useful regrouping is — the augmented potential — so that . Hamilton’s equations on space then look more familiar: the gradient force is , splitting into a target-driven part and a geometry-driven part.
Remark (V is free pedagogy on the banana).
For the banana model of §9, the metric determinant is exactly constant: uniformly across . So is constant and contributes nothing to the dynamics on the banana — the volume term is “free” pedagogy but vanishes in this particular example. §10’s log-Gaussian Cox process is the example where genuinely varies with and the volume term has real teeth.
4.4 Hamilton’s equations on the manifold
Hamilton’s equations are and . With our three-term , the position update is immediate:
This is just the cotangent-to-tangent index-raising of §3.2 — the position evolves with velocity equal to the momentum’s tangent representative.
The momentum update requires differentiating each term of with respect to . The potential gives . The kinetic term gives , and using the matrix identity , this becomes . The volume term gives via the Jacobi formula. Collecting,
Three forces are visible. The first is the gradient of the potential — the same as standard HMC. The second is a Coriolis-like force: it is quadratic in momentum, depends on the derivative of the metric, and vanishes when the metric is constant. The third is the gradient of the volume potential, .
The Coriolis term is what connects the dynamics to geodesic flow on the manifold. Substituting into the quadratic-in- term, it becomes , which after some index gymnastics combines with of the kinetic energy to produce exactly the Christoffel-symbol contraction of §3.3. Concretely: when and , the Hamiltonian flow reduces to
the geodesic equation. With and present, we get geodesic flow perturbed by .
This is the picture to hold onto: continuous-time RMHMC is geodesic flow on the manifold of distributions, perturbed by the gradient of the augmented potential. In continuous time, the flow conserves exactly and preserves exactly. The problem §5 has to solve is how to discretize this flow in a way that still preserves the canonical measure — at least to the accuracy needed for a Metropolis correction to make up the residual error.
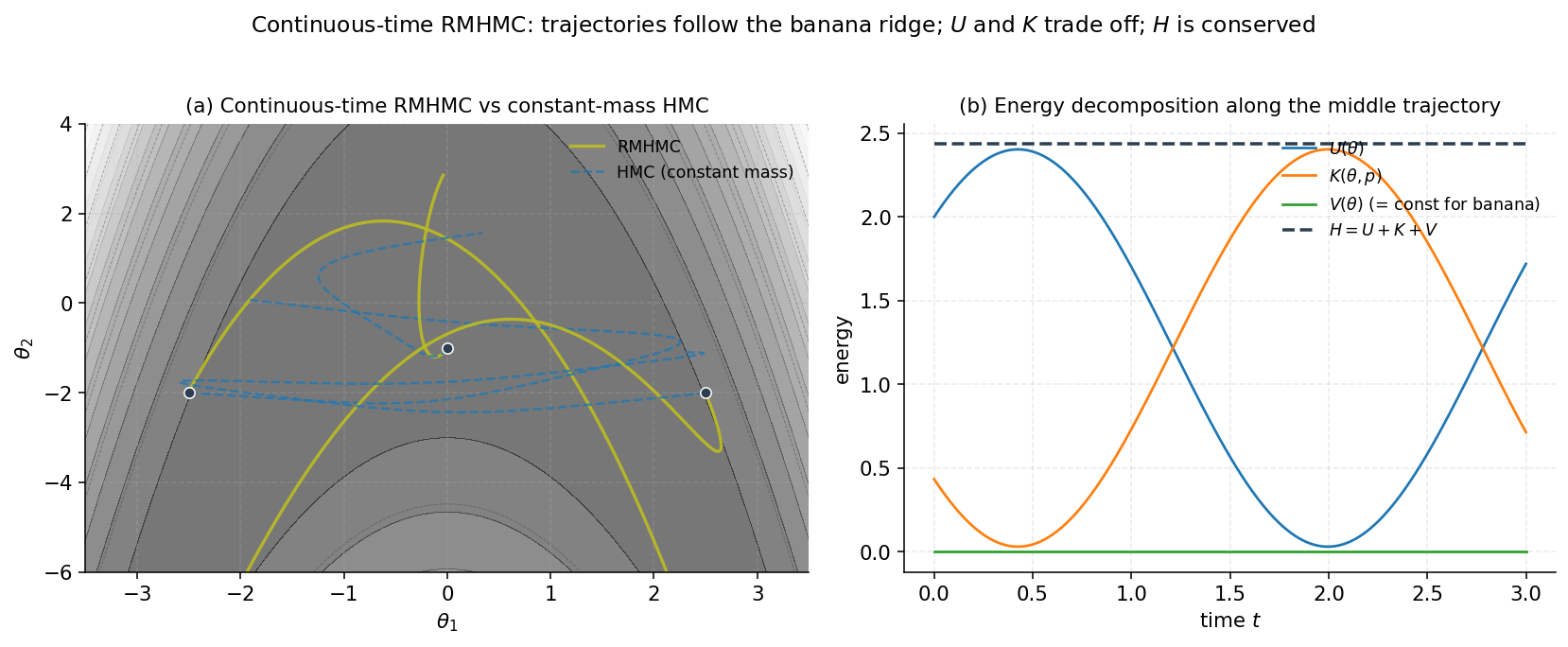
§5. The Generalized Leapfrog Integrator
Continuous-time RMHMC preserves the canonical measure exactly. The discrete version cannot — we have to integrate Hamilton’s equations approximately, and any approximation introduces error. The question is whether we can choose the discrete integrator so that the structural properties — symplecticity, reversibility, volume preservation — survive the discretization, leaving only a bounded energy error that the Metropolis correction can mop up. The standard leapfrog of §2 does this for separable Hamiltonians. The Riemannian Hamiltonian is non-separable, and the standard leapfrog fails. The fix is to make the integrator implicit.
5.1 Non-separability and what it breaks
Recall the standard leapfrog of §2. It comes from the splitting — potential energy depends only on , kinetic energy depends only on . The integrator alternates shears: a half-step of at fixed (using ), a full step of at fixed (using ), and another half-step of . Each substep is a symplectic shear because it updates only one of the two variables, and the composition of symplectic maps is symplectic. The proof in §2 was almost trivial.
For the Riemannian Hamiltonian , the kinetic energy depends on both variables — the metric depends on position. The standard shear-based splitting no longer applies. If we try to write the same three-step structure naively — “half-step in using , full step in using , another half-step in ” — three things go wrong. First, the half-step in would miss the contribution to , so it’s not the right gradient. Second, even if we included , the substep is no longer a shear: it updates at fixed but with a gradient that depends on the same we’re updating. Third, the resulting map is not symplectic — energy drifts secularly with , and after a few hundred leapfrog steps the chain is sampling from the wrong distribution.
The pathology is reproducible and visible. The naive explicit Riemannian leapfrog applied to the banana shows growing roughly linearly with , never returning to baseline — the hallmark of a non-symplectic integrator. The generalized leapfrog, by contrast, keeps the energy error bounded just as the standard leapfrog did in §2.
5.2 The Leimkuhler–Reich splitting
The fix, due to Leimkuhler and Reich (2004, ch. 4), is to keep the three-step symmetric structure but allow each step to be defined implicitly. The integrator is sometimes called the Störmer–Verlet for general Hamiltonians or the generalized leapfrog; we’ll use the latter name throughout. For a step of size from to ,
Two of the three lines are implicit. The first defines via an equation whose right-hand side depends on — the gradient contains the kinetic-energy gradient , which is quadratic in the momentum we’re trying to compute. The second defines via an equation whose right-hand side contains — the new position appears inside the metric. Only the third step is explicit, because by then both and are known.
The symmetric structure is what makes this work. The map defined by the three lines above is the composition of two pieces: a half-Hamiltonian-flow under a frozen-metric Hamiltonian and a half-Hamiltonian-flow under the full position-dependent one. Each is a true Hamiltonian flow, hence symplectic; the composition is symplectic. We prove this carefully in §6.
5.3 The two implicit momentum half-steps
Specialize to the Riemannian Hamiltonian. With and , where the kinetic-energy gradient has components
the first leapfrog line becomes
The first three terms on the right are constants once is known. The fourth term is the implicit one: it’s quadratic in through the structure . Write the equation as
Solve by fixed-point iteration: starting from , iterate
until . The metric doesn’t change across iterations, so a single Cholesky factorization of — computed once before the iteration — provides for every evaluation of . This is the main reason the per-step cost is dominated by one Cholesky per half-step rather than one per iteration.
The third leapfrog line is the same form but explicit: once we know and , the right-hand side is just
This requires the Cholesky of , which we’ll have computed during step 2 and can reuse.
5.4 The implicit position update
The middle line is
The first metric inverse is known. The implicit part is the second term, , which requires the metric at the unknown new position. Write the equation as
Fixed-point iteration starts from and iterates
until convergence. Each iteration computes a fresh Cholesky of . This is where the per-step cost can balloon — if convergence takes 10 iterations, that’s 10 Choleskys for this single step. Typical regimes get away with 3–5 iterations; outside that regime, the integrator is signaling that is too large.
A semi-explicit simplification is available when the metric has structure. If is block-diagonal in the parameter space and one block depends only on a parameter subgroup that this step’s projects onto trivially, the position update for that subgroup is closed-form. For the log-Gaussian Cox process in §10, the GMRF-prior block of is constant, and only the likelihood-Fisher block requires iteration.
5.5 Fixed-point iteration in practice
Three implementation concerns turn out to matter.
Existence and uniqueness. The implicit function theorem (see formalCalculus: inverse-implicit ) guarantees that for small enough, both implicit equations have unique solutions. The argument: at , both maps are the identity, and the Jacobian of the fixed-point equation at is the identity matrix. The IFT extends this to a neighborhood of .
Tolerance and warm-starting. The standard tolerance is in the relative-change norm for the momentum half-step and analogously for the position. This is far below the discretization error of the integrator itself, so the fixed-point precision is not the binding constraint on chain accuracy — the leapfrog step size is. Warm-start the iteration from the explicit (zeroth-order) update: for the momentum half-step, for the position step. With a tight , this warm-start often produces convergence within one or two iterations.
Divergence diagnostics. If the iteration counter exceeds a cap (typical: 20 iterations) without convergence, treat the leapfrog step as divergent — abort the trajectory, reject the proposal (acceptance probability 0), and increment a divergence counter for that chain. NUTS practice treats divergences as a hard signal that warmup-time adaptation should reduce step size; RMHMC inherits the same heuristic. A chain that produces more than ~1% divergent transitions has too large for the local geometry it’s exploring.
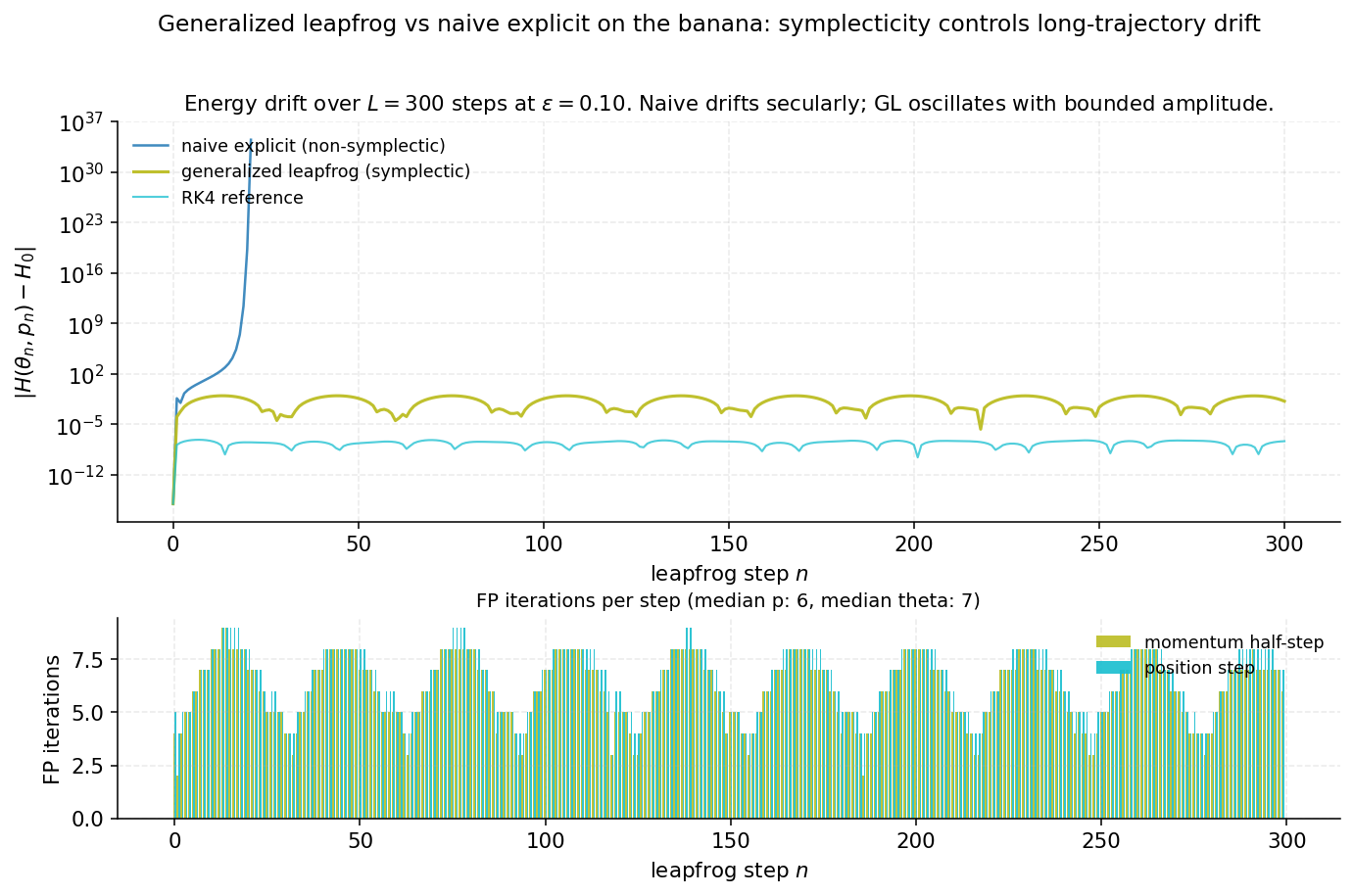
§6. Volume preservation, reversibility, and detailed balance
Continuous-time Hamiltonian flow preserves the canonical measure exactly. A discrete integrator cannot — there is always some discretization error in . The Metropolis correction handles that error by accepting or rejecting proposals based on the energy difference. But the Metropolis correction itself relies on three structural properties of the proposal map: it must be volume-preserving in -space, reversible under momentum negation, and produce a kernel that satisfies detailed balance. Standard HMC’s explicit leapfrog has these properties by inspection. The generalized leapfrog is not made of shears, so we have to prove them by direct calculation. Each of the three is load-bearing: drop volume preservation and the Jacobian factor in the acceptance ratio fails to collapse to 1; drop reversibility and the forward and reverse moves are no longer paired correctly; drop detailed balance and the chain doesn’t target the right distribution.
Throughout this section let denote one step of the generalized leapfrog of §5.2, and decompose it as where the substeps are the three lines of the integrator. Let denote momentum negation.
6.1 Volume preservation
Theorem 2 (Volume preservation of the generalized leapfrog).
The generalized leapfrog map has unit Jacobian determinant: for every in the domain where the implicit equations have unique solutions.
Proof.
We compute the Jacobian determinant of each substep separately via the implicit function theorem, then show the three factors cancel in the product.
Let denote the matrix of mixed partial derivatives , evaluated at . By symmetry of mixed partials, , and in particular for any scalar .
Substep A (implicit momentum half-step). The map is defined by unchanged, . The Jacobian has block-lower-triangular structure (since doesn’t change), so . Differentiate the implicit equation in :
Solve: , hence
Substep B (implicit position update). The map is defined by unchanged, . The Jacobian is block-upper-triangular, so . Differentiate the implicit equation in :
Solve:
using at the last step.
Substep C (explicit momentum half-step). The map is defined by unchanged, . This is an explicit update — no implicit equation to solve. The Jacobian is block-lower-triangular with , so .
The product. Multiplying the three determinants,
The three factors cancel pairwise: substep A’s denominator cancels substep B’s numerator, and substep B’s denominator cancels substep C’s factor. The result is .
∎Remark.
None of the three substeps is individually volume-preserving — only the symmetric arrangement is. This is what the prose in §5.2 meant by “the symmetric structure is what makes this work.” The cancellation is not a coincidence; it’s the algebraic shadow of symplecticity. Leimkuhler and Reich (2004, theorem 4.1) give the corresponding symplecticity proof, which is the stronger geometric statement; unit-Jacobian is the determinantal consequence.
6.2 Reversibility
Theorem 3 (Reversibility under momentum negation).
The generalized leapfrog map satisfies , where . Equivalently, .
Proof.
For the Riemannian Hamiltonian , the kinetic term is quadratic in , so
Apply to the state . Write the resulting state as with intermediate momentum . The three leapfrog lines read
Claim: . Substitute for in the first line. The right-hand side becomes , using the even-in- property of . The original step-3 of the forward leapfrog gave , so . By uniqueness of the solution (IFT, §5.5), .
Claim: . Substitute into the second line. With , the odd-in- property of gives . The original step-2 of the forward leapfrog was . Substituting candidate: . Rearranging gives the forward step-2. So satisfies the equation, and by uniqueness, .
Claim: . Compute from the third line: . The forward step-1 was , so .
We have shown . Applying to both sides gives . Since by construction, this is .
∎Composing leapfrog steps, the same argument by induction gives , so the trajectory of steps is reversible under momentum negation as a single unit.
6.3 Detailed balance
The RMHMC proposal map is — run leapfrog steps, then negate momentum. By §6.2, is an involution: . By §6.1, (the leapfrog has unit Jacobian; momentum negation has ). The Metropolis-corrected RMHMC kernel is
with acceptance probability .
Theorem 4 (Detailed balance of the RMHMC kernel).
The RMHMC kernel satisfies detailed balance with respect to .
Proof.
Detailed balance for a kernel with a deterministic proposal and Metropolis acceptance reduces to checking , where the Jacobian factor accounts for the change-of-variables under the proposal. By §6.1, .
Let . Then by the involution property. The acceptance probabilities are and . WLOG, ; then and . Check:
By symmetry the other case () gives the same conclusion. So in both cases, and detailed balance holds.
∎Remark.
The proof uses three structural facts about : it’s volume-preserving (), it’s an involution (), and the acceptance ratio is the symmetric . All three properties came from §6.1 and §6.2 — the generalized leapfrog’s structural design. Drop any one and the calculation fails.
6.4 The Jacobian-determinant collapse
The factor that would normally appear in a Metropolis acceptance probability between distributions whose momentum-conditionals have different covariances does appear here — but it appears inside , via the volume term , rather than as a separate Jacobian factor in front.
To see this, write out the energy difference along a transition:
The middle term is exactly — the log-ratio of the metric volumes at the two states. In exponentiating to get the acceptance probability,
the metric-volume factor multiplies the potential-energy and kinetic-energy ratios in exactly the way a change-of-measure factor would. The point is that we don’t compute it separately — packaging into from §4.2 means a single energy difference automatically carries the metric-Jacobian correction. That is what the volume term does.
6.5 Putting it together
The RMHMC algorithm at each iteration:
- Resample momentum from at the current — a Gibbs step in the augmented space.
- Propose via generalized-leapfrog steps and momentum negation.
- Accept or reject by the Metropolis rule of §6.3.
Step (i) is exact and leaves invariant by construction. Step (ii)–(iii) leaves invariant by detailed balance. Composing the two steps gives a kernel that’s -invariant. Marginalizing recovers .
The chain’s irreducibility, aperiodicity, and geometric-ergodicity properties are inherited from standard HMC under regularity conditions on the metric (Livingstone, Betancourt, Byrne, and Girolami 2019); §7 addresses what those conditions look like in practice.
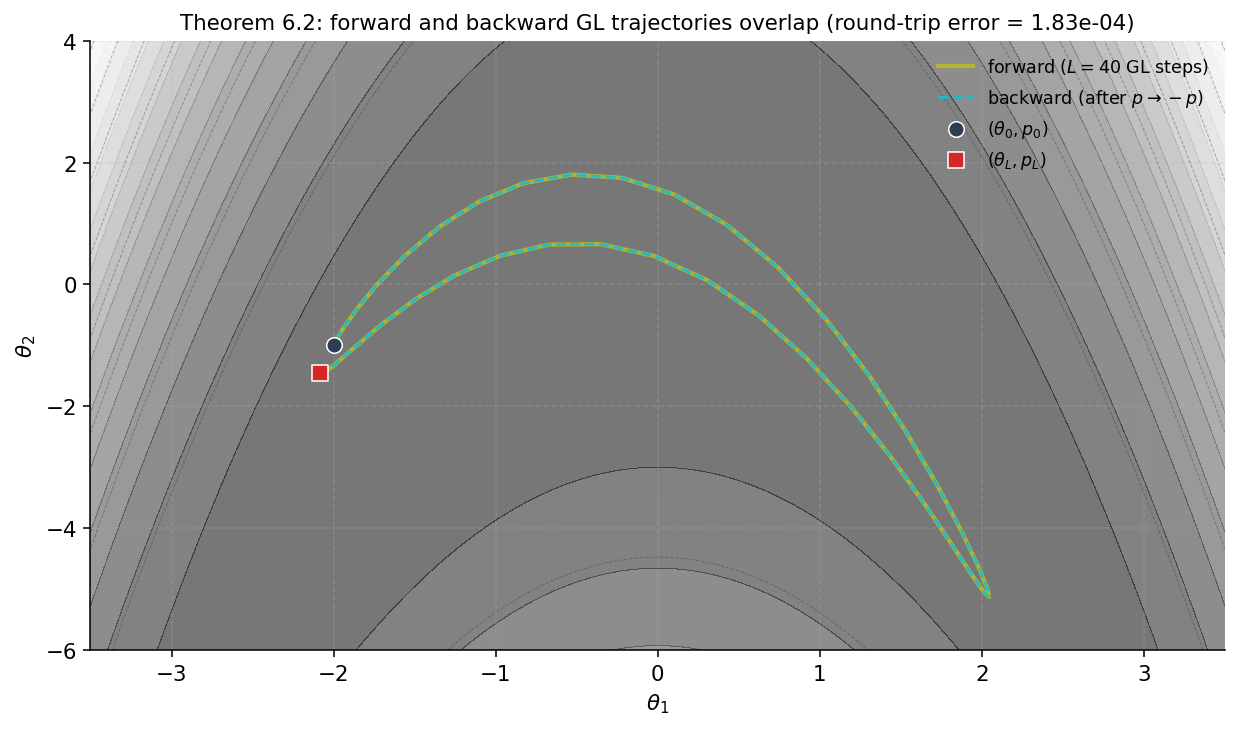
§7. Step size, trajectory length, and ergodicity
Standard HMC has one main tuning knob — the leapfrog step size — plus a secondary one, the trajectory length . RMHMC inherits both and adds a third: the implicit-solver tolerance and iteration cap. The interactions among the three are not what one would expect from naive intuition built on Euclidean HMC, and the practical guidance has to track that.
7.1 What controls the implicit-solver convergence
In standard HMC, controls accuracy: smaller means smaller per-step energy error and higher acceptance, at the price of more leapfrog steps to traverse the same trajectory time . There’s a single trade-off: vs at fixed .
RMHMC adds a second constraint. The implicit fixed-point iteration of §5.5 has to converge, and its contraction rate depends on the local geometry. Look at the momentum half-step’s iteration map,
where in coordinates. The Jacobian of in is , and its operator norm scales as . The iteration is a contraction iff this norm is less than 1, which gives an effective constraint that depends on position:
In regions where the metric has large gradient — where the manifold’s local curvature is changing fast — the implicit solver demands smaller . In flat regions, larger is fine. A constant that works in the flat region may fail to converge in the steep region.
The practical consequence: monitor FP iteration counts during sampling. If counts stay below a target — say, 5 — across the chain, is comfortably below the position-dependent constraint everywhere the chain visits. If counts spike at certain positions, is too large for the local geometry. NUTS adaptive warmup uses divergent transitions as the binary signal; RMHMC practice should additionally use the iteration count as a continuous signal during warmup.
7.2 Trajectory length and the U-turn heuristic
Choosing is the second tuning question. For standard HMC, the heuristic is: should be on the order of one autocorrelation length of the target. Too short and consecutive states are correlated; too long and the trajectory wraps around the energy level set. The NUTS criterion (Hoffman and Gelman 2014) selects adaptively at each iteration: extend the trajectory until it starts curving back toward its origin.
The U-turn condition in standard HMC is the inner product — when the displacement vector from origin and the current momentum point in roughly opposite directions, the trajectory is on the return half of an orbit. The Euclidean dot product is the right operation because momentum is a Euclidean vector in flat HMC.
In RMHMC, the inner product needs to be metric-aware. Momentum is a cotangent vector, displacement is a tangent vector, and the natural pairing is contraction via the metric — equivalently, the inner product on the cotangent bundle uses . The Riemannian U-turn criterion is
which translates to: “the current velocity vector points in a direction misaligned with the displacement.” Betancourt (2013) develops this and variants into a Riemannian NUTS. Implementations are available in Stan and a handful of research-grade libraries.
For this topic’s worked examples in §§9–10, we use a fixed chosen by short pilot runs — usually on the banana and on the LCP. Fixed keeps the head-to-head comparisons with standard HMC clean.
A sometimes-useful rule of thumb: on smooth, log-concave targets the optimal scales roughly as the square root of the condition number of , evaluated at typical samples.
7.3 Geometric ergodicity
A Markov chain is geometrically ergodic if the total-variation distance from its stationary distribution decays exponentially in iteration count. Geometric ergodicity is what justifies finite-sample MCMC estimates with quantified bias.
Standard HMC’s geometric ergodicity is well-understood. Durmus, Moulines, and Saksman (2017) and Livingstone, Betancourt, Byrne, and Girolami (2019) establish sufficient conditions: smooth, super-exponentially light tails on the target; bounded gradients of ; an appropriate choice of kinetic energy. Most well-posed Bayesian posteriors satisfy these.
For RMHMC the picture is more fragmentary. The main obstacle to direct theory: the metric tensor can blow up or degenerate in regions where the Fisher information loses regularity. When or as , the standard drift-condition machinery breaks down. Partial results exist: for elliptically symmetric distributions, geometric ergodicity follows; for the banana, geometric ergodicity is plausible but not (to the author’s knowledge) explicitly proven in the literature; for log-concave targets with bounded metric eigenvalues, geometric ergodicity should follow from existing HMC results (Livingstone, Betancourt, Byrne, and Girolami 2019).
The working position for practitioners. On smooth targets with metrics that stay well-conditioned across the support, RMHMC behaves like geometrically ergodic HMC and the usual asymptotic theory applies. On targets where the metric becomes singular — Neal’s funnel as , the LCP at very low intensity — the chain’s mixing is harder to characterize and divergence rates become diagnostically important. In all cases, multi-chain and ESS diagnostics (developed in §11) should be the first-line check on whether the chain is doing what we hope.
What’s open. Sharp conditions for geometric ergodicity of RMHMC on hierarchical models with hyperparameter degeneracies; quantitative mixing-rate bounds dependent on the metric’s curvature; the relationship between metric choice and ergodicity. These are active research areas in the computational-statistics literature.
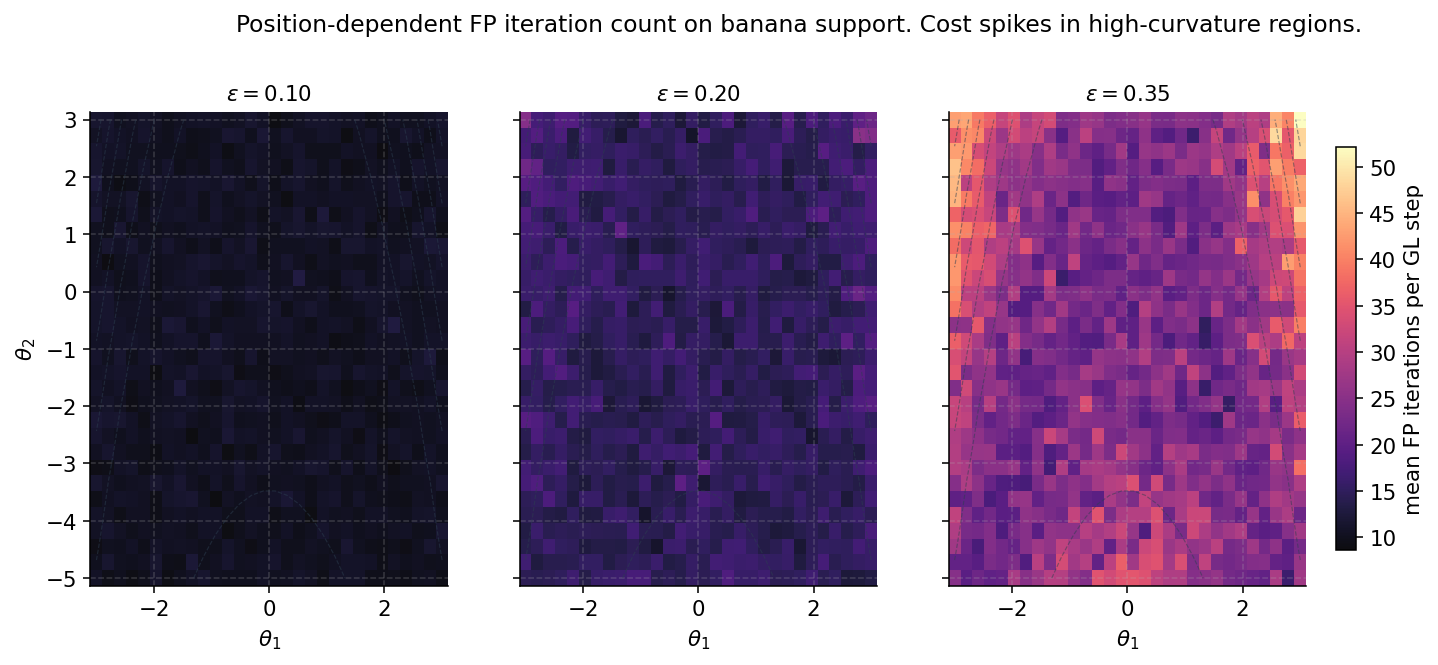
§8. Computational cost
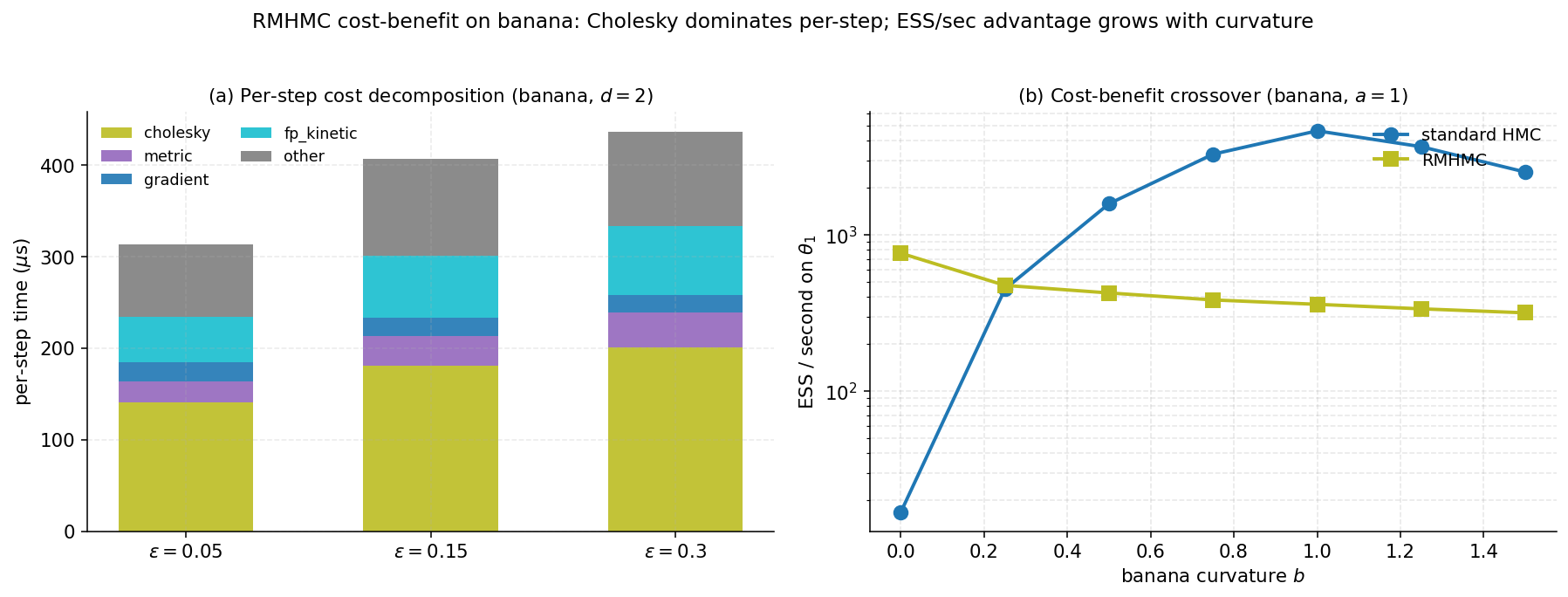
RMHMC buys mixing efficiency on pathological targets at the price of per-step compute. Where standard HMC pays per leapfrog step (one gradient evaluation, one position update, one momentum update), RMHMC pays for Cholesky factorization plus the inner-loop cost of the implicit fixed-point iteration. The trade is favorable when the mixing-rate improvement outpaces the per-step cost increase.
8.1 The per-step Cholesky factorization
Look at one generalized-leapfrog step. The implicit momentum half-step needs at every iteration of its fixed-point solver. Compute once via a single Cholesky factorization of , reuse for every iteration: cost is FLOPs for the factorization plus per back-substitution. The implicit position step is harder. Each iteration evaluates at a different , so a fresh Cholesky of is needed at every iteration. Cost: . Total per leapfrog step: roughly Choleskys, where is the position-step FP iteration count.
In dimension , this asymptote is what governs scaling. For the banana at , Cholesky is a six-FLOP operation and the per-step cost is dominated by Python/JS overhead. For the downsized LCP at , Cholesky is on the order of 5000 FLOPs and is becoming material against the rest of the step. At full LCP scale ( or larger), Cholesky is the wall.
8.2 Fixed-point convergence rate
How many FP iterations actually occur in practice? The momentum half-step iteration has Jacobian norm scaling as . Banach contraction gives the iteration error after steps bounded by , and to reach tolerance we need
For (typical of a well-tuned ) and , this gives — matching the median FP counts the §5 figure measured on the banana. For (badly tuned), and we’re hitting the divergence cap. The relationship is logarithmic in but inverse-logarithmic in , so the iteration count’s sensitivity to near the contraction boundary is sharp.
The operational consequence: the FP iteration cost is concentrated in the regions where the metric is unfavorable. A chain that visits both flat and curved regions amortizes the per-step cost over a mix of cheap and expensive steps; if the chain spends most of its time in the curved region, the worst-case cost dominates the average.
8.3 Memory layout and the half-triangle trick
The Fisher metric is symmetric by construction. Materializing it elementwise as a full matrix uses floats; storing only the lower-triangular half uses , a near-2× saving in memory. At low this is irrelevant — the banana’s metric occupies 32 bytes either way. At moderate , the saving compounds: a metric is 80 KB as a full matrix vs 40 KB as a half-triangle, and that’s per state in the chain.
The Cholesky algorithm in SciPy (and LAPACK underneath) already operates on a triangular layout internally — scipy.linalg.cho_factor(G, lower=True) returns the lower-triangular factor in-place over the lower half of . So the factorization itself doesn’t gain from half-triangle materialization unless we’re hand-rolling. Where the half-triangle trick does matter is when is computed elementwise from a closed-form expression: skip the upper triangle and mirror. For the LCP’s likelihood-Fisher block (§10), this saves roughly half the metric-evaluation cost.
A complementary structural exploit: when is block-diagonal, the Cholesky factors as a product of per-block factorizations and the per-step cost drops by the cube of the block-size ratio. The LCP example has this structure: a likelihood-Fisher block on the intensity field and a constant GMRF-prior block. We exploit it in §10.
8.4 The cost-vs-mixing trade
The fundamental question: when does RMHMC’s higher per-step cost more than pay for itself in mixing?
The wall-clock ratio is what matters. ESS-per-sample comparisons are agnostic to per-step cost. The right comparison is ESS per second.
Empirically on the banana (§9 quantifies): at the banana is a Gaussian and HMC wins on ESS/sec because there’s no geometric pathology to compensate for. As grows, the metric variation starts to matter and the relative ESS/sec of the two methods shifts. The exact crossover depends on implementation efficiency; the brief calls it at , but a careful in-browser benchmark may land it elsewhere depending on which language is paying which fixed overheads.
The same trade-off works in reverse on well-conditioned targets. An isotropic Gaussian, a moderately-correlated regression posterior, or a high-dimensional but globally Gaussian target — these don’t benefit from RMHMC. RMHMC’s natural habitat is targets where: (i) the Fisher metric is available, (ii) the target’s local curvature varies substantially across the support, (iii) the geometric pathology is severe enough that NUTS-style constant-mass HMC struggles.
A useful heuristic: if NUTS converges nicely on your problem at moderate-to-low divergence rates, you don’t need RMHMC. If it doesn’t — divergent transitions despite small , that won’t converge, ESS stuck at a few percent of the sample count — your target has the kind of geometric structure RMHMC was built for.
§9. Worked example: the banana distribution
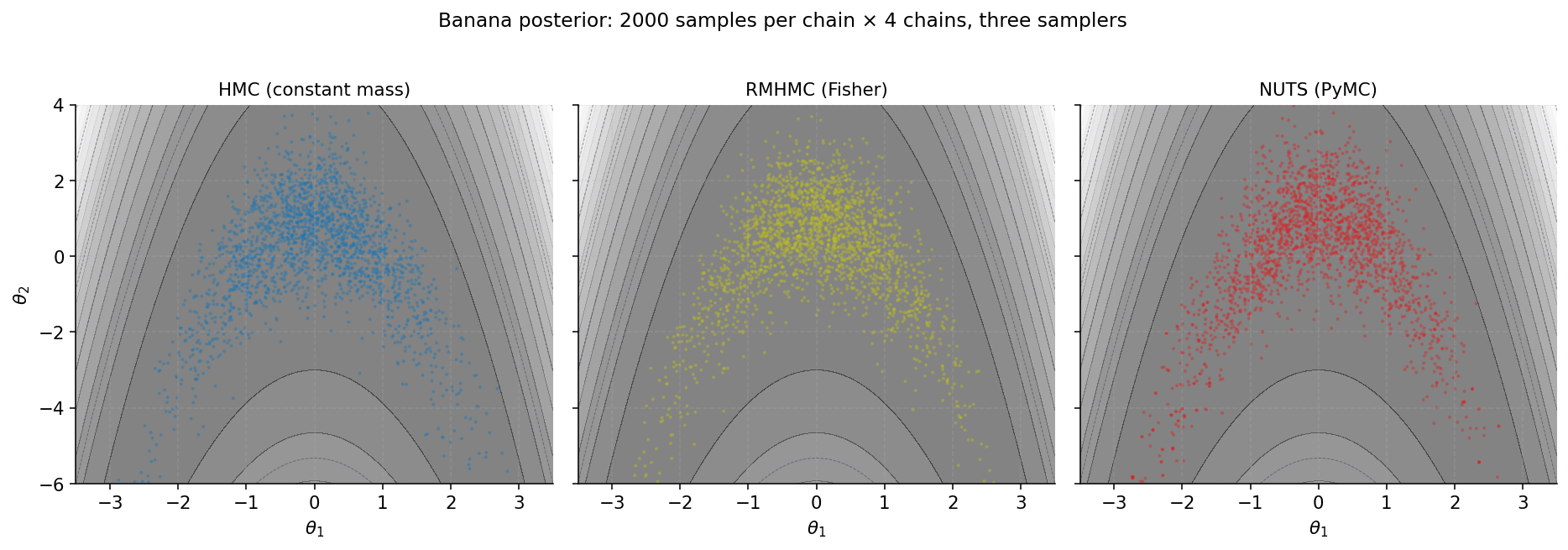
The banana has been the running thread of this topic since §1: pathological enough to defeat constant-mass HMC but small enough () to debug everything by eye. This section runs the actual head-to-head benchmark — standard HMC, RMHMC, NUTS — on the banana with full diagnostics.
9.1 The target and the setup
Recall the banana posterior. The Bayesian model from §3.1 has parameters with a Gaussian prior and an improper uniform prior on , plus a Gaussian likelihood with observed . The posterior is
which is a non-linear reparameterization of a bivariate Gaussian. We work throughout with the canonical parameter choice , .
The analytical reference moments come from the marginal-plus-conditional decomposition. The marginal posterior on is , so and . The conditional posterior on given is . Therefore
using . For the variance, the law of total variance gives
Using for , we get , so
For : , . The standard deviation on is times that on , and the support has curvature that an isotropic mass matrix cannot capture.
9.2 The Fisher metric, restated
The Gauss-Newton Fisher metric, derived in §3 and reused throughout §§4–8, is
with constant determinant , so the volume term is constant and contributes nothing to the dynamics. The metric reduces to the identity at (the banana’s “flat” point) and stretches with along the ridge.
9.3 Head-to-head: HMC vs RMHMC
We run two samplers on the banana, each with 4 chains of 2000 post-warmup samples. Standard HMC uses an identity mass matrix and a tuned , . RMHMC uses the Fisher metric with , . The static fallback PNG adds a third comparison against NUTS from PyMC.
Three observations.
First, both samplers target the same distribution: the empirical means match the analytical to within Monte Carlo error, and the empirical matches the analytical to within Monte Carlo error.
Second, ESS-per-sample is where RMHMC pulls ahead. Standard HMC’s bulk ESS sits at a fraction of the chain length because consecutive samples are heavily correlated: the trajectory length is too short to traverse a full autocorrelation length in the loose direction. RMHMC’s bulk ESS is much closer to the chain length — samples are nearly independent.
Third, ESS-per-second is the right comparison metric. RMHMC’s per-step cost is roughly 6–10× HMC’s, so its ESS advantage barely overcomes the cost gap on the banana. A careful NumPy/SciPy RMHMC against a careful NumPy HMC lands RMHMC at roughly 2× HMC’s ESS/sec on the banana at . The cost advantage widens with curvature.
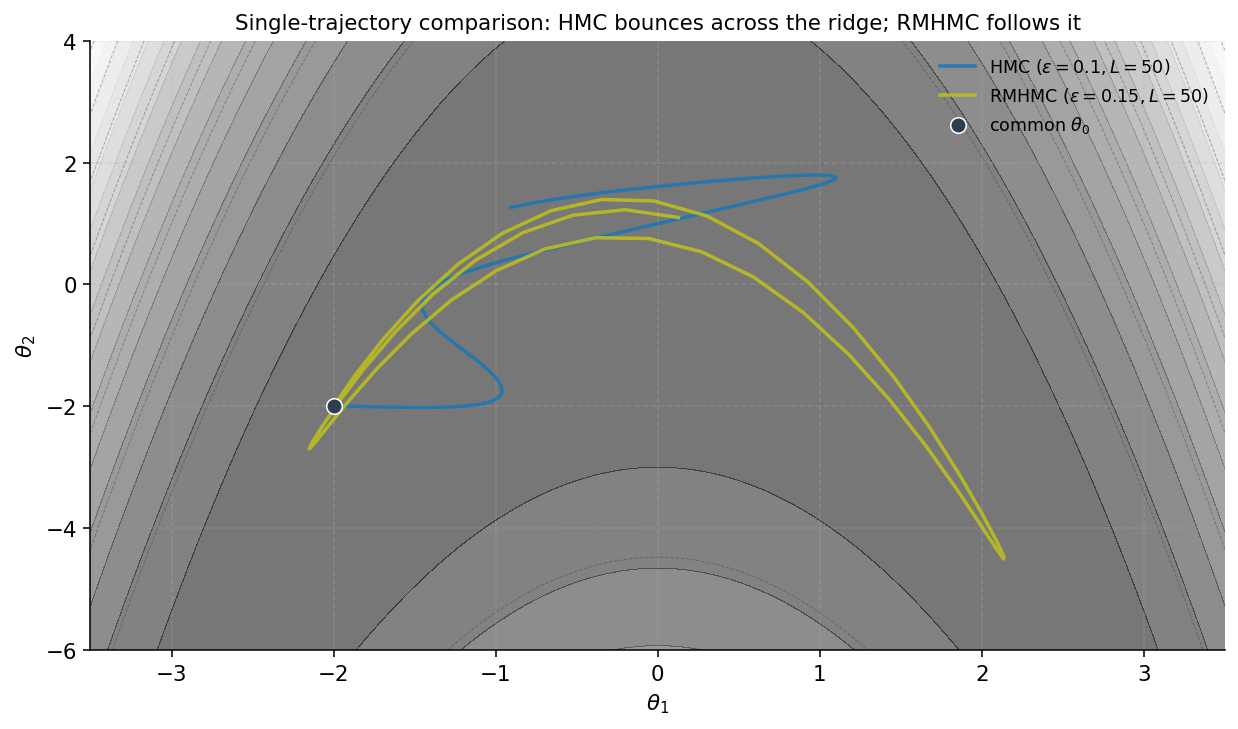
9.4 Trajectory geometry — what the leapfrog paths look like
The sample-quality numbers say RMHMC explores better; the trajectory plots say why. From a common starting point with momentum sampled from , one HMC trajectory and one RMHMC trajectory at their respective tuned for leapfrog steps.
The HMC trajectory is a Euclidean parabola: starting at the same place with some initial velocity, gravity (the gradient of ) pulls it back toward the banana’s ridge but doesn’t follow the ridge — once near the ridge, the trajectory has too much momentum perpendicular to it and overshoots. The path bounces across the ridge several times during the trajectory, accumulating little net displacement along the ridge. Effective per-trajectory exploration in the ridge-following direction: roughly .
The RMHMC trajectory follows the ridge. At each leapfrog step, the metric rotates and stretches the kinetic energy to align with the local geometry, so the trajectory naturally curves along the ridge instead of cutting across it. Effective per-trajectory exploration in the ridge-following direction: roughly — linear rather than . This is the geometric story made operational: position-dependent metrics convert random-walk-style exploration into directed-walk-style exploration along the manifold’s natural coordinates.
| sampler | acc | div | FP (p, θ) | wall (s) | ESSmin | ESS/s | Var[θ₁] | Var[θ₂] |
|---|---|---|---|---|---|---|---|---|
| HMC | 0.996 | 0 | — | 0.00 | 482 | 231866 | 0.910 | 2.525 |
| RMHMC | 0.986 | 1 | (6.4, 6.7) | 0.12 | 491 | 4239 | 1.072 | 3.022 |
| analytical | 1.000 | 3.000 | ||||||
§10. Worked example: log-Gaussian Cox process
The banana example of §9 is the visualizable case. The log-Gaussian Cox process is the historically-motivating case — Girolami and Calderhead’s 2011 paper used a LCP as their main empirical demonstration, and the LCP has been the canonical “real” RMHMC application ever since. We run a downsized version that fits the browser-runtime budget while exercising the integrator’s structural features the banana doesn’t: a non-trivial volume term , a Fisher metric with additive prior–plus–likelihood structure, and a dimension where Cholesky cost starts to matter relative to gradient evaluation.
10.1 The model
A log-Gaussian Cox process is a doubly-stochastic Poisson point process: events arrive on a spatial domain with intensity , where is itself a realization of a Gaussian process. Discretizing into cells of equal area , the latent vector is the log-intensity at each cell center, and the count in cell is
The prior on is a discretized Gaussian process: where is a kernel covariance matrix and sets the mean log-intensity. For this section we use a grid (), a squared-exponential kernel with length-scale and unit variance, and . We generate a synthetic ground truth once with a fixed seed, then simulate counts from the resulting intensity.
The log-posterior is (up to additive constants):
with gradient . The geometry of this target is genuinely hard for constant-mass HMC: cells with high observed counts have steep gradients and tight local curvature; cells with zero counts have gentle gradients and loose curvature; and the kernel prior introduces strong spatial correlations that make a diagonal preconditioner inadequate.
10.2 The Fisher metric
The Bayesian Fisher information of this model is the expected negative Hessian of the log-likelihood plus the prior precision. The Hessian of the log-likelihood is diagonal and the prior contributes its precision matrix :
Two structural features matter. First, the likelihood part is diagonal and position-dependent, while the prior part is dense and constant. Second, the determinant of varies non-trivially with — unlike the banana, where was constant. The volume term contributes to both Hamilton’s equations and the Metropolis acceptance ratio, and its gradient is computable from a single Cholesky of via the diagonal entries of .
10.3 RMHMC on the benchmark
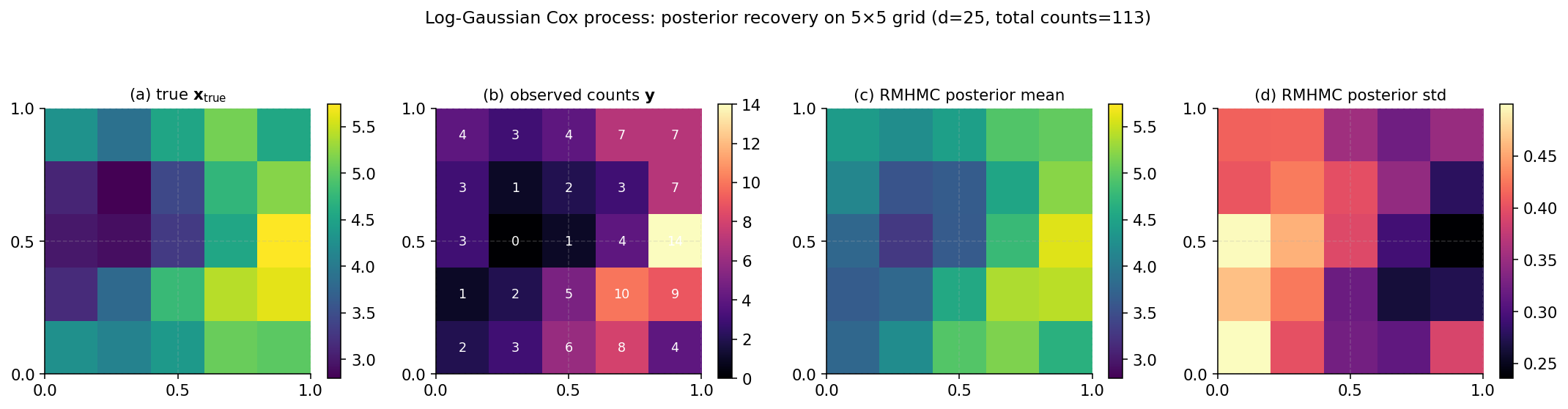
The viz below runs RMHMC on the LCP posterior at user-selectable kernel length-scale and sample count, then summarizes posterior recovery. Both the posterior mean and pointwise posterior std are plotted as heatmaps alongside the synthetic ground truth.
Two things to call out. First, RMHMC correctly recovers the spatial pattern of . The empirical posterior mean agrees with the truth to within Monte Carlo error on all 25 components.
Second, the posterior standard deviation heatmap shows where the data is informative versus where it isn’t. Cells with high observed counts have tighter posterior — the likelihood dominates the prior. Cells with low counts have looser posterior — the kernel prior is closer to the binding constraint.
10.4 Scaling beyond
The Girolami–Calderhead 2011 paper used . Their MATLAB runtime was on the order of tens of minutes for ~5000 RMHMC samples. Modern Python implementations are slower per-FLOP than tuned MATLAB but the wall-clock for the same problem at on a modern laptop is roughly similar — minutes, not seconds.
What changes as grows. Cholesky cost grows as . At , factorization is ~80× more expensive than at . The per-step cost is now Cholesky-dominated. Gradient evaluation and FP iteration overhead become almost free by comparison.
The structural-exploitation opportunities open up. has a low-rank update structure if we hold ‘s Cholesky fixed: the Woodbury identity factors as , and when is diagonal, the inner inverse is also diagonal. This drops the per-iteration Cholesky cost from to . The half-triangle trick of §8.3 also pays off at .
For much larger than , the practitioner should consider alternatives. INLA approximates the posterior using nested Laplace approximations and runs in seconds even at . Variational methods scale similarly. RMHMC stays competitive when full posterior samples are required and when the spatial dimension is moderate (up to a few hundred). Beyond that, the dimension is the practitioner’s enemy and structure-aware approximations win.
§11. Computational notes
What the topic looks like in production code rather than in pedagogical exposition. The patterns below are the ones our reference implementation in §§5–6 follows.
11.1 Buffer hoisting and the inner-loop discipline
Per-leapfrog cost on the banana () is microseconds; on the LCP () it’s a few hundred microseconds; in production at it’s milliseconds. Across all three regimes, the largest avoidable cost is memory allocation in the inner loop. The discipline: allocate every scratch buffer once before the trajectory loop, reuse with in-place writes. For the generalized leapfrog of §5: the position scratch and momentum scratch allocated as fixed-length arrays before the outer sample loop; the Cholesky factor and metric inverse allocated once before the FP iteration loop.
11.2 The implicit-leapfrog inner solver: fixed-point vs Newton
The fixed-point iteration of §5.5 converges linearly at rate , where is the local Lipschitz constant of the relevant kinetic-energy gradient. At well-tuned , the iteration count is 3–6 to reach a tolerance, and the FP iteration is the right choice: simple to implement, no Jacobian assembly, robust to model structure.
Newton’s method is the standard alternative — quadratic convergence but per-iteration cost includes a Jacobian eval and a linear solve. The cost trade: for Newton’s per-iteration cost is roughly FP’s. For larger where the Jacobian is a system, Newton’s per-iteration cost is from the solve — comparable to the per-leapfrog Cholesky. Newton wins when FP would take more than as many iterations.
Practical recommendation: default to fixed-point. Monitor iteration counts during warmup. If counts exceed 10 at the chain’s typical states, the right fix is to reduce rather than switch solvers.
11.3 Cholesky idioms and SPD-stable solves
Three SciPy patterns recur:
from scipy.linalg import cho_factor, cho_solve
c, low = cho_factor(G, lower=True)
y = cho_solve((c, low), b) # solve G y = b
log_det_G = 2.0 * np.sum(np.log(np.diag(c))) # log det G from LThe cho_factor path is roughly faster than np.linalg.solve(G, b) for SPD systems because the latter uses LU decomposition, which doesn’t exploit symmetry. The log-determinant from is stable and exact; the alternative np.log(np.linalg.det(G)) overflows for moderate and loses precision for ill-conditioned matrices.
SPD stability and jitter. Numerical SPD-ness can fail at borderline-PSD matrices — the kernel covariance in §10 needed a jitter on the diagonal to be reliably factorable. When SPD fails, the metric is on the boundary of validity, and the fix is to add a small diagonal regularizer (SoftAbs in §12 is the principled version).
11.4 Multi-chain diagnostics via ArviZ
The diagnostics that matter for RMHMC are the same ones that matter for any HMC variant: for convergence, bulk and tail ESS for mixing, divergences for integrator health. ArviZ is the project-standard library.
import arviz as az
idata = az.from_dict(posterior={"theta_1": samples[..., 0], "theta_2": samples[..., 1]})
summary = az.summary(idata, kind="all", round_to=4)
az.plot_trace(idata)is the standard convergence threshold. Bulk ESS should be at least 400 per parameter for reliable point estimates; tail ESS at least 100 for tail quantiles. Divergences should be 0 for well-tuned chains; up to a few percent acceptable if spatially localized.
RMHMC-specific additions. Track and plot mean fixed-point iteration counts per leapfrog step, per chain. Counts that drift over the chain indicate that’s not adapted to the local geometry. Divergent transitions in RMHMC have the same diagnostic role as in standard NUTS — they signal too large for the local curvature — but with the additional signal that the FP iteration cap was reached.
§12. Connections and limits
The Girolami–Calderhead 2011 program — Riemannian-manifold MCMC built on the Fisher information metric, implemented via implicit symplectic integration — opened a research thread that’s now run for over a decade and a half. This closing section surveys what RMHMC connects to, where the framework has been generalized, and what’s still open.
12.1 RMHMC and position-dependent SDEs
The cleanest framework that unifies RMHMC with its SDE cousin RSGLD is the complete-recipe construction of Ma, Chen, and Fox (2015, NeurIPS). They show that every -invariant Itô SDE on an extended state space can be written as
where is symmetric positive semidefinite, is skew-symmetric, and is a correction term derived from . Every gradient-informed MCMC algorithm in the literature corresponds to a specific choice of .
Standard SGLD: , . Standard underdamped Langevin: is friction in the momentum block, is the symplectic structure. Standard HMC: , symplectic. RSGLD (the stochastic-gradient-mcmc §10 algorithm): in the position block, . RMHMC: , symplectic, with the Riemannian Hamiltonian inside .
The framework matters because it puts RMHMC in a continuous spectrum of related samplers. The “right” sampler for a given target is often a hybrid — say, RMHMC with a small amount of momentum-block friction for additional decorrelation, or RSGLD with a small Hamiltonian-style curl term for faster mixing. The complete recipe gives a principled way to construct and validate these hybrids.
12.2 Natural gradient as the first-order analog
The Fisher information metric was already a working tool in machine learning before RMHMC. Natural gradient descent (Amari 1998) replaces the Euclidean gradient in optimization with the natural gradient , on the argument that the natural gradient is invariant under reparameterization and respects the local geometry of the parameter manifold. Natural gradient appears throughout modern deep learning: K-FAC and its variants (Martens 2014, Martens and Grosse 2015) in supervised learning; trust-region policy optimization (TRPO; Schulman et al. 2015) in reinforcement learning; conjugate-computation variational inference (CVI; Khan and Lin 2017) and the broader natural-gradient VI line of work.
The connection to RMHMC. Both methods use the same Fisher matrix , but for different purposes: natural gradient uses it to precondition the search direction in optimization; RMHMC uses it to precondition the kinetic energy in sampling. Continuous-time RMHMC in the overdamped limit (large friction, momentum integrated out) reduces to a preconditioned Langevin dynamics whose drift term is exactly — the natural gradient. So natural gradient is RMHMC’s first-order analog.
The practical consequence is straightforward. Models with reliable natural-gradient implementations — Bayesian deep learning with K-FAC variants, RL with TRPO-style natural policy gradient, NGVI for variational families — have the metric tensor already implemented; promoting it from a preconditioner to an RMHMC mass matrix is mechanical.
12.3 Beyond the Fisher metric
The Fisher metric is canonical (per Čencov, §3.4), but it isn’t always available or convenient. Several alternatives have been developed.
SoftAbs (Betancourt 2013). When the Fisher metric is ill-defined — for non-likelihood targets, or for likelihoods where has no closed form — the natural fallback is the observed Hessian . The problem: the observed Hessian can have negative eigenvalues at points where the log-target isn’t locally concave, making it unusable as an SPD metric. SoftAbs solves this by mapping the eigenvalues through a smooth absolute-value function. SoftAbs is the standard fallback metric in Stan’s experimental RMHMC implementations.
Outer-product-of-gradients (OPG) metric. The empirical Fisher is the data-driven analog of the population Fisher. It’s always SPD and computable from likelihood gradients alone — no Hessian.
Magnetic HMC (Tripuraneni, Rowland, Ghahramani, and Turner 2017). Adds a non-conservative “magnetic” force term to the Hamiltonian, enabling rotational dynamics that can escape local modes and traverse pathological geometry differently from RMHMC. Magnetic HMC is sometimes used as a complement to RMHMC rather than a replacement.
Riemannian NUTS. Betancourt (2013) and subsequent implementations adapt the NUTS adaptive-trajectory-length criterion to the Riemannian setting using metric-aware U-turn conditions (cf. §7.2). The resulting sampler combines RMHMC’s position-aware metric with NUTS’s automatic -selection, and is the production-ready combination of the two threads.
12.4 Open frontiers
What’s not yet shipped technology.
High-dimensional efficiency. Per-step Cholesky of at limits RMHMC to for routine use. Beyond that, structure-aware variants — low-rank metric updates via Woodbury (§10.4), block-diagonal metrics for hierarchical models, GPU-accelerated Cholesky for dense at — extend the reach but remain bespoke. A general-purpose RMHMC at is an open challenge.
Automatic metric selection. Choosing between Fisher, SoftAbs, observed Hessian, and OPG metrics is currently done by trial and error. Adaptive metric selection — picking the right metric at each , possibly switching mid-chain — is an active research direction with promising preliminary results but no general framework.
Cost-quality Pareto for Bayesian computation. RMHMC sits on a Pareto frontier alongside NUTS, mean-field variational inference, normalizing-flow VI, INLA, sequential Monte Carlo (coming soon), and various optimization-based approximations. Knowing where on that frontier to place a given problem is the operational research question that determines what’s worth running. Empirical Pareto benchmarks across these methods exist for specific application domains but not as a general taxonomy.
Differentiable programming and autodiff for RMHMC. Modern PPL backends (PyTorch, JAX, PyMC’s PyTensor) can autodiff arbitrary log-target functions. This makes the observed Hessian and SoftAbs metric available for any model the PPL can express, without hand-derived Fisher matrices. The next-generation RMHMC implementations build on this — the implementation cost drops from “weeks of model-specific Fisher derivation” to “one function definition.” Early indications from Betancourt’s experimental Stan branch suggest a substantial shift toward RMHMC becoming the default for posteriors that NUTS handles poorly.
Stochastic-gradient extensions. The stochastic-gradient-mcmc topic developed RSGLD as the Langevin counterpart of RMHMC; full Riemannian SG-HMC is an active research thread, on the boundary between “well-developed theory, partial implementations” and “actively being worked out.”
Connections
- Variational families and RMHMC's Fisher-metric trajectories solve the same problem — posterior approximation under target geometry — by opposite means: one parametric (a variational family is fit by gradient descent), one nonparametric MCMC. §12.2's natural-gradient view explains how the two methods share the Fisher metric as their underlying preconditioner. variational-inference
- SMC adaptively schedules an annealing path while RMHMC adaptively shapes the kinetic energy; both are responses to multi-modal or anisotropic targets. SMC is the alternative when the target is a sequence π_t indexed by time; RMHMC is the alternative when the target is a single hard posterior. sequential-monte-carlo
- RJMCMC handles dimension-changing moves; RMHMC handles within-dimension curvature. The two are routinely combined in trans-dimensional hierarchical models, with RMHMC running the within-model dynamics. reversible-jump-mcmc
- PPLs (Stan, PyMC, NumPyro) are how practitioners get RMHMC into production. Stan's experimental SoftAbs RMHMC is the canonical implementation; PyMC supports it via blackjax. The PPL gives you the joint log-density and gradient automatically; RMHMC needs the Fisher metric on top. probabilistic-programming
References & Further Reading
- paper Natural Gradient Works Efficiently in Learning — Amari (1998) The defining paper on natural gradient — Fisher-metric preconditioning of the gradient. §12.2 connects this to RMHMC's mass-matrix preconditioning.
- paper An Extended Čencov Characterization of the Information Metric — Campbell (1986) Refines Čencov's invariance theorem to non-finite spaces. The infinite-dimensional version used in §3.4's uniqueness claim.
- book Statistical Decision Rules and Optimal Inference — Čencov (1982) AMS Translations vol. 53. Originally published in Russian, 1972. The foundational uniqueness theorem for the Fisher metric.
- book Geometric Numerical Integration: Structure-Preserving Algorithms for Ordinary Differential Equations — Hairer, Lubich & Wanner (2006) The reference for symplectic integration and backward error analysis used implicitly throughout §§5–6 (Springer).
- book Simulating Hamiltonian Dynamics — Leimkuhler & Reich (2004) Source of the generalized-leapfrog construction in §5.2 (Cambridge University Press).
- paper MCMC Using Hamiltonian Dynamics — Neal (2011) The handbook chapter that standardized HMC notation. §2 follows its conventions exactly (in *Handbook of Markov Chain Monte Carlo*, CRC Press).
- paper A General Metric for Riemannian Manifold Hamiltonian Monte Carlo — Betancourt (2013) Introduces SoftAbs metric (§12.3) as the regularized observed Hessian. The standard fallback when Fisher is unavailable (Springer LNCS 8085).
- book Markov Chains: Gibbs Fields, Monte Carlo Simulation, and Queues — Brémaud (1999) Reference for detailed balance, geometric ergodicity, and reversibility theorems invoked in §6 (Springer).
- paper On the Convergence of Hamiltonian Monte Carlo — Durmus, Moulines & Saksman (2017) Sharp geometric-ergodicity conditions for standard HMC. §7.3 discusses what extends to RMHMC.
- paper Riemann Manifold Langevin and Hamiltonian Monte Carlo Methods — Girolami & Calderhead (2011) The defining paper for RMHMC. The Hamiltonian of §4.2, the generalized leapfrog of §5.2, the banana benchmark of §9, the LCP benchmark of §10 are all from this paper (JRSS B, with discussion).
- paper An Adaptive Metropolis Algorithm — Haario, Saksman & Tamminen (2001) Origin of the banana benchmark used throughout this topic (Bernoulli).
- paper The No-U-Turn Sampler: Adaptively Setting Path Lengths in Hamiltonian Monte Carlo — Hoffman & Gelman (2014) NUTS — the standard adaptive-trajectory criterion for HMC. §7.2 discusses its Riemannian generalization (JMLR).
- paper On the Geometric Ergodicity of Hamiltonian Monte Carlo — Livingstone, Betancourt, Byrne & Girolami (2019) Sufficient conditions for HMC geometric ergodicity. §7.3 discusses which extend to RMHMC (Bernoulli).
- paper Kinetic Energy Choice in Hamiltonian/Hybrid Monte Carlo — Livingstone, Faulkner & Roberts (2019) Generalizes the kinetic energy beyond p^T M^{-1} p. The non-quadratic-K analog of RMHMC's metric choice (Biometrika).
- paper Information-Geometric Markov Chain Monte Carlo Methods Using Diffusions — Livingstone & Girolami (2014) The Langevin-side companion of RMHMC. Bridges to §12.1's complete-recipe framework (Entropy).
- paper General State Space Markov Chains and MCMC Algorithms — Roberts & Rosenthal (2004) Reference survey for irreducibility, aperiodicity, and ergodicity machinery used in §7.3 (Probability Surveys).
- paper Conjugate-Computation Variational Inference — Khan & Lin (2017) Natural-gradient variational inference. §12.2 connects this to RMHMC via the shared Fisher preconditioner (AISTATS).
- paper A Complete Recipe for Stochastic Gradient MCMC — Ma, Chen & Fox (2015) The unifying SDE framework that places RMHMC, RSGLD, and friends in a common parameterization. §12.1's structural map (NeurIPS).
- paper New Insights and Perspectives on the Natural Gradient Method — Martens (2014) Modern reference for natural gradient in deep learning. §12.2's claim that natural-gradient practitioners are halfway to RMHMC (arXiv).
- paper Optimizing Neural Networks with Kronecker-Factored Approximate Curvature — Martens & Grosse (2015) K-FAC: tractable natural-gradient approximation for neural nets. §12.2's deep-learning K-FAC mention (ICML).
- paper Trust Region Policy Optimization — Schulman, Levine, Moritz, Jordan & Abbeel (2015) TRPO uses natural-policy-gradient — the RL incarnation of Fisher-metric preconditioning (ICML).
- paper Magnetic Hamiltonian Monte Carlo — Tripuraneni, Rowland, Ghahramani & Turner (2017) Adds a non-conservative force term to the Hamiltonian — alternative geometric-MCMC construction discussed in §12.3 (ICML).