Reversible-Jump MCMC
Trans-dimensional MCMC for Bayesian model selection via the auxiliary-variable bijection and Jacobian-corrected acceptance ratio
§1. Overview and motivation
1.1 Where fixed-dimension MCMC stops working
Standard Metropolis–Hastings and Gibbs — the §26 catalog in formalStatistics: bayesian-computation-and-mcmc — presume a fixed parameter space . The chain is a random walk on this Euclidean (or product-of-Euclidean) ambient space. As long as the target density is well-defined on a fixed-dimensional support and the proposal density has a known closed form, the §26 framework gives us everything we need to construct a -invariant chain.
Model selection breaks this presumption at the root. We have a finite or countable collection of candidate models with parameter spaces — and the whole point of model selection is that in general. Model might be a five-parameter regression with three covariates; might be a twelve-parameter regression with ten. The Bayesian posterior we want to sample is the joint
which lives on the disjoint union
a state space whose dimension changes as the chain moves between models. No single Euclidean ambient space accommodates the chain; no fixed-dim proposal density even has a well-defined form when source and target live in different dimensions. The change-of-variables formula — the one piece of measure theory that makes the trans-dimensional move sensible — does not appear anywhere in the §26 catalog because nothing in that catalog ever changes dimension.
The naive workaround — fix the model at its largest plausible size and trust a continuous spike-and-slab prior to push unused coefficients toward zero — does work for moderate . That’s the sparse-bayesian-priors §12 setup, and it’s the lead-in this topic explicitly extends rather than re-derives. But the continuous spike-and-slab posterior concentrates mass near zero, not at zero, so we can never read off a posterior inclusion probability directly. For Bayes factors, posterior model probabilities, and predictive averaging — the BMA tasks of formalStatistics: bayesian-model-comparison-and-bma — we need as a discrete indicator the chain visits or doesn’t. That’s the gap RJ-MCMC fills.
1.2 Two motivating pictures
Two examples will recur §-by-§ throughout the topic. We introduce both here so that every later section can point back to one or the other for a concrete instance of whatever abstraction we’re unpacking.
The variable-selection lattice. Given candidate covariates, the model space is the power set: subset-models indexed by binary indicators , where iff covariate is included. Two models are neighbors if their vectors differ by exactly one coordinate — one variable added or one dropped. The model space inherits a natural graph structure: the -dimensional Boolean lattice, with layers indexed by cardinality and edges only between adjacent layers. Figure 1A draws the case (16 models, 32 edges) at scale; in §9’s worked example we run at (256 models), at which scale full enumeration is still tractable and we can validate posterior inclusion probabilities exactly against an enumeration-computed gold standard.
The mixture-order question. Given a univariate dataset, how many Gaussian components do we need? Each candidate model has parameters — a -dimensional space (the comes from the simplex constraint ). As grows, dimension grows by 3 per added component. RJ-MCMC moves between and by splitting one component into two (dimension up by 3) or merging two into one (dimension down by 3), with auxiliary variables that parameterize how the split-or-merge happens. Figure 1B shows the canonical Galaxy dataset (Roeder 1990, velocities in km/s × ) with , , candidate fits overlaid. Visually, underfits the central cluster, adds bumps with no real support, and or looks about right — but the principled posterior over requires the sampler we’re building. The numerical answer (Richardson–Green 1997 §6) is a posterior centered around to depending on prior hyperparameters, and §10 reproduces this.
1.3 Why Carlin–Chib and product-space samplers don’t suffice
Before Green (1995), the standard approach to trans-dimensional Bayesian computation was the Carlin–Chib (1995) product-space sampler. The construction: define an over-parameterized chain on the Cartesian product that always carries every model’s parameters simultaneously, plus a categorical model-index variable that selects which model’s parameters drive the likelihood at each iteration. Inactive models’ parameters are updated from “pseudo-priors” chosen by the user. Marginalizing the categorical variable recovers the posterior model probabilities; the standard Gibbs machinery handles the rest.
The construction is mathematically clean and historically important, but it has two crippling costs in practice. First, every iteration updates every model’s parameters even though only one is active, so per-iteration cost scales with the total dimension of all candidate models combined — exactly the scaling we wanted to avoid. Second, the pseudo-priors on inactive parameters have to be tuned per application to match the corresponding conditional posteriors closely enough that the categorical-variable mixing isn’t catastrophically slow; this tuning is itself a model-fitting exercise, sometimes harder than the original problem. For more than three or four candidate models, Carlin–Chib is unworkable.
Green (1995) keeps the disjoint-union state space and constructs each dimension-changing move as a deterministic measurable bijection on a padded common space, with auxiliary random variables drawn only on the source side. The bijection is reversible by construction (the inverse map is the reverse move), and the trans-dimensional MH acceptance ratio that results has one new ingredient compared to fixed-dim MH: a Jacobian determinant from the change-of-variables formula on the bijection. The acceptance ratio is computationally trivial to evaluate, the move catalog is hand-engineered per problem but transparent, and the chain genuinely lives on rather than on an inflated product space. RJ-MCMC subsumes Carlin–Chib and is uniformly more efficient. We mention Carlin–Chib once more, in §13’s tooling notes, and otherwise leave it to the references.
1.4 What this topic discharges
RJ-MCMC discharges three site-wide forward-pointers and closes one curriculum cluster:
- formalStatistics: bayesian-computation-and-mcmc §26.10 Rem 28 explicitly forward-pointed at RJ-MCMC as the trans-dimensional extension of the §26 MH/Gibbs catalog. §§4–7 of this topic discharge that pointer.
- formalStatistics: bayesian-model-comparison-and-bma forward-pointed at RJ-MCMC as the canonical sampler for the posterior model probabilities that BMA averages over. §§9–10 discharge that pointer with worked examples.
- sparse-bayesian-priors §12.6 named RJ-MCMC as the discrete spike-and-slab workhorse for the regime where Gibbs SSVS becomes prohibitive. §9 discharges that pointer by extending the continuous-spike-and-slab framework to the discrete case.
RJ-MCMC also closes the T5 specialized-sampler cluster. stochastic-gradient-mcmc handled noise-injected gradient samplers for big-data targets; riemann-manifold-hmc handled position-dependent Fisher mass matrices for pathological fixed-dim targets; sequential-monte-carlo handled annealed-target evidence estimation for hard posteriors. RJ-MCMC handles dimension-changing moves for model selection. After this topic, the T5 Bayesian-computation toolkit is structurally complete and the ML Methodology layer’s specialized-sampler cluster closes.
1.5 Roadmap
§2 names the Bayesian-model-selection target — what RJ-MCMC samples from and what it returns. §3 builds the trans-dimensional state space as a geometric object with two concrete pictures (the lattice from §1.2, the dimension-stair from §1.2). §4 cites the standard MH framework and pins down exactly where it stops short. §§5–7 are the load-bearing proof triplet: the auxiliary-variable bijection (§5), reversibility (§6), detailed balance with the Jacobian factor (§7). §8 catalogs the standard moves — birth/death, split/merge, within-model updates — and writes their Jacobians out. §§9–10 run the math on real data: linear-regression variable selection at (§9) and Galaxy-data mixture-order estimation up to (§10). §11 covers diagnostics specific to trans-dimensional chains. §§12–13 wrap with computational notes and connections to the rest of the site.
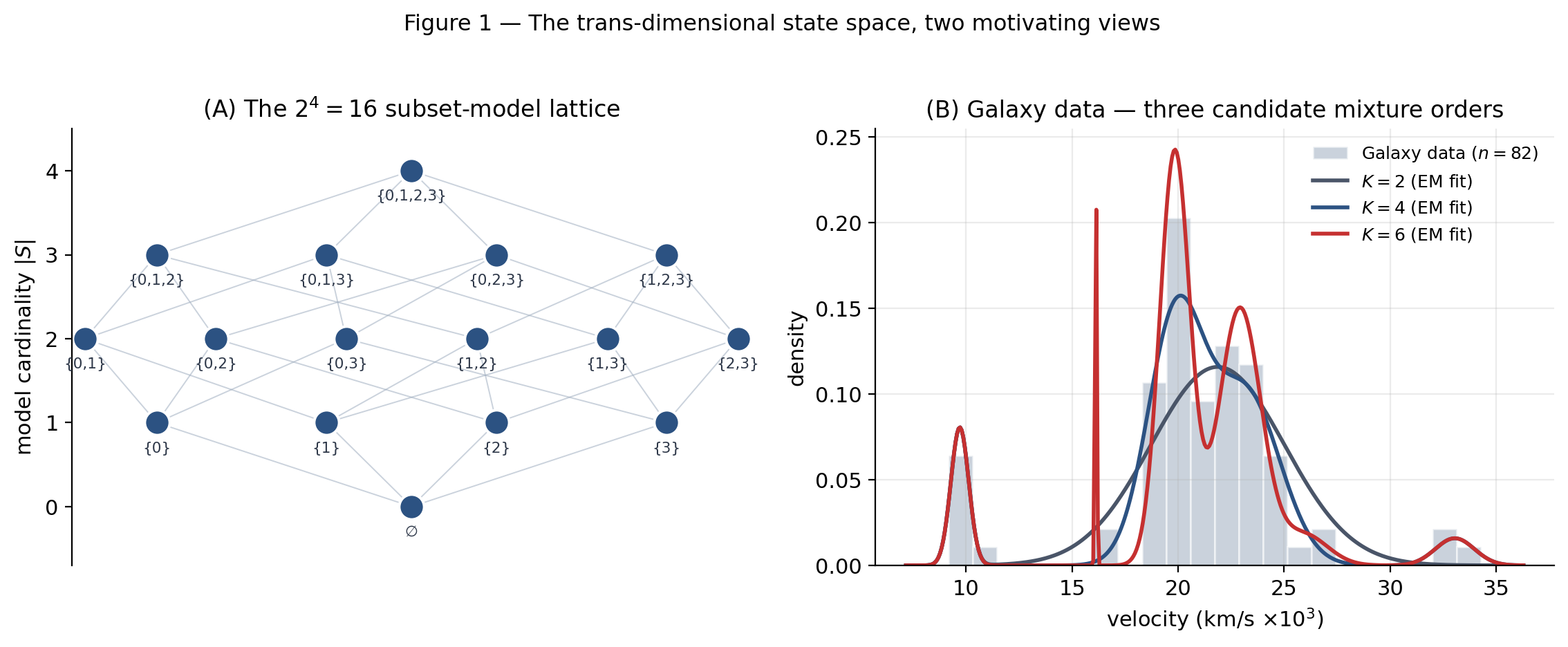
Try dragging the slider on the lattice or the slider on the Galaxy histogram below. Click a lattice node to highlight its Hamming-distance-one neighbors — the moves an RJ-MCMC add/drop catalog would propose from that state.
§2. Bayesian model selection at a glance — what RJ-MCMC computes
§2 names the target. RJ-MCMC is a sampler, and like every sampler it samples from something specific. The “something specific” is the trans-model posterior and its marginal , both well-known objects from formalStatistics: bayesian-model-comparison-and-bma . We re-state them here in the notation we’ll use for the rest of the topic and pin down what RJ-MCMC actually returns when a chain finishes running.
2.1 The trans-model posterior and the posterior model probability
Bayesian model selection starts from a collection of candidate models , each with its own parameter space , likelihood , and parameter prior . A separate model prior assigns probability to each candidate. Bayes’ rule applied to the full joint gives
with normalizer
— a sum over models, each summand an integral over that model’s parameter space. The normalizer is finite when each per-model marginal likelihood is finite and (the model prior is proper), which is the regularity setting throughout the topic.
Marginalizing out of the joint defines the posterior model probability
where is the marginal likelihood (or model evidence) for — the same object SMC §8 estimated unbiasedly via , here viewed one model at a time.
RJ-MCMC samples directly from the trans-model joint on the disjoint union . The estimator for posterior model probabilities is the time-fraction estimator:
This is the trans-dimensional analog of the fact that fixed-dim MCMC estimates a posterior mean by averaging the parameter trace — “fraction of post-burn-in time in state ” is just the Monte Carlo estimate of . We never compute any individual ; the sampler returns posterior model probabilities directly, and posterior summaries within each model (conditional means, credible intervals for ) come from averaging over only the iterations where . We’ll return to this within-model vs. across-model decomposition in §11.
2.2 Bayes factors, model priors, and the binomial multiplicity
The Bayes factor comparing to is the ratio of marginal likelihoods,
the multiplicative factor by which updates the prior odds of over . Bayes factors are prior-free in the parameters (the are integrated out) but not prior-free in the model — they depend on the parameter priors inside each marginal likelihood. This is the well-known Lindley–Bartlett sensitivity: a flat parameter prior over a wide range makes tiny relative to a prior concentrated near the true value, biasing the Bayes factor against the larger model. The conjugate -prior of Zellner (1986) and its hyper- refinements (Liang et al. 2008) are the standard fix in the regression setting and what §9 uses.
The model prior is rarely well-chosen as uniform-over-models in the variable-selection setting. With models indexed by , the uniform prior assigns probability to “the model has cardinality exactly ,” which is binomially concentrated around . For genuinely sparse problems (true cardinality ) this puts vanishing mass on the right neighborhood. The standard fix, the Scott–Berger (2010) multiplicity-correction prior, makes the model size uniform on :
The factor exactly cancels the multiplicity of models at each cardinality, so a posteriori the model size is driven by the data, not by the combinatorial geometry of the lattice. §9 uses Scott–Berger; you’ll see appear directly in the log-prior code via scipy.special.gammaln.
For the mixture-order setting (§10), the analog is much simpler: on , or a truncated Poisson with rate fit to elicited prior beliefs. Richardson–Green (1997) used truncated to , which puts most mass on — broad enough to let the Galaxy data drive the answer but with built-in Occam-style preference for parsimony.
2.3 Why we sample instead of integrate
At small — say , so — with conjugate priors that admit closed-form marginal likelihoods, full enumeration of is feasible. Every posterior model probability can be computed exactly, no sampling required. §9 exploits exactly this fact: it runs the variable-selection demo at a scale where the 256-model enumeration is the gold standard, and uses the enumerated posterior to validate RJ-MCMC’s output. Whenever enumeration is feasible, do it — RJ-MCMC then exists to convince yourself the sampler works, not to do new computation.
At , ; at , . Even at one marginal-likelihood evaluation per microsecond — roughly an OLS fit plus a log-Gamma normalization — enumeration at takes about 17 minutes and at takes about 35 years. Genomic-scale variable selection routinely sits at in the thousands; enumeration is hopeless. The exponential wall is visible in Figure 2A.
For the mixture-order problem the obstruction is different but converges to the same conclusion. Even at modest , the marginal likelihood is not closed-form under the weakly informative priors Richardson–Green (1997) recommend (those priors are deliberately non-conjugate to keep the prior data-independent). Each per- evidence then requires its own numerical-integration job — bridge sampling, AIS, SMC, or nested sampling — which is itself a substantial sampler-tuning exercise. Running 10 separate evidence estimators to compare 10 candidate values is wasteful when a single RJ-MCMC run on the trans-dimensional space estimates all 10 posterior probabilities simultaneously, with computation shared across model orders via the split/merge move catalog (§10).
The RJ-MCMC bargain. Instead of one numerical-integration job per model, one sampler over the trans-dimensional space that visits each model in proportion to its posterior probability. The acceptance ratio handles the per-step bookkeeping including the Jacobian determinant (§7); the time-fraction estimator handles the posterior model probabilities (§2.1). Sampler tuning is harder — auxiliary-variable proposals, move-catalog mixing, between-model jump acceptance rates — and §§8 and 11 will spend serious time on it. But the result is a single chain whose summary statistics give us everything the model-selection question asked for.
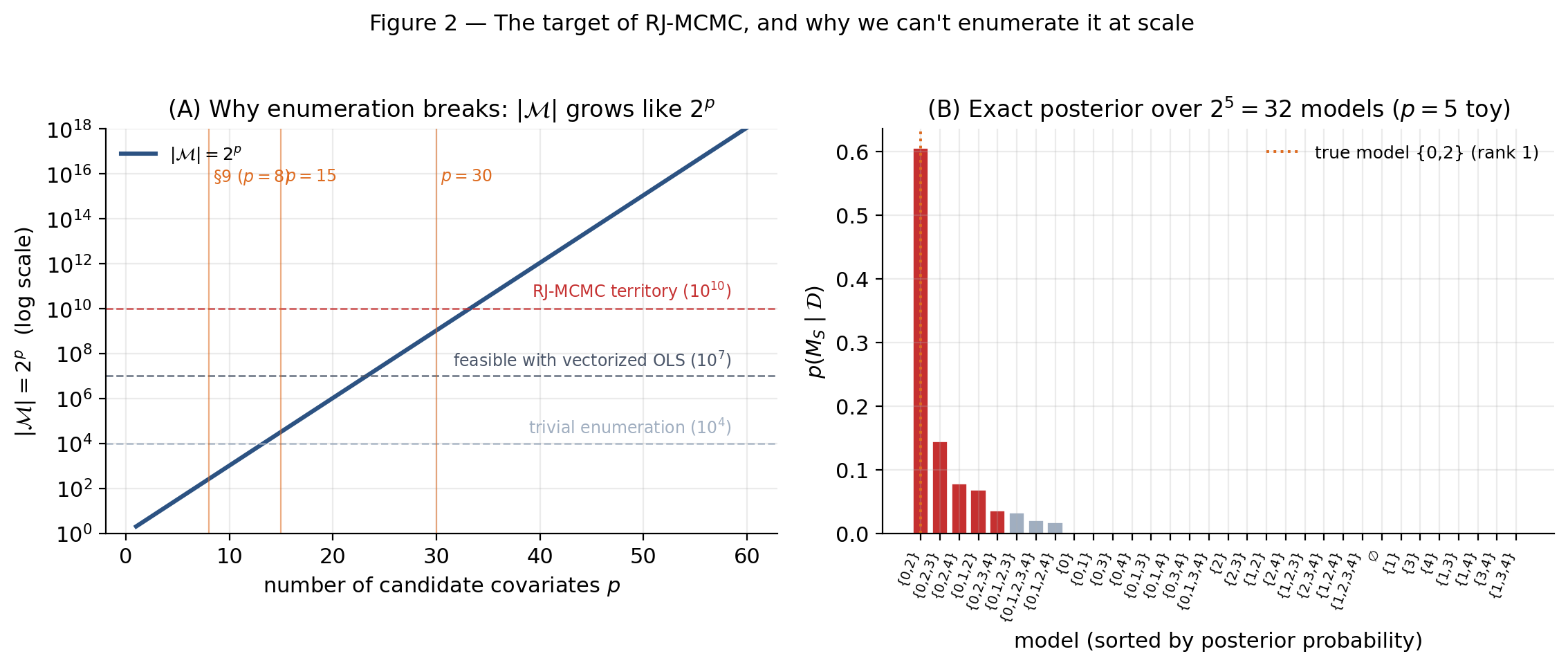
Drag the slider on the left panel to see how the enumeration wall scales; the right panel re-simulates a toy regression dataset at the chosen and re-enumerates its posterior.
§3. The trans-dimensional state space
Before we put a Markov chain on , we need to look at what actually is as a geometric and measure-theoretic object. The whole reason RJ-MCMC needs new machinery — auxiliary variables, Jacobian determinants, a re-derived detailed-balance condition — is that is not a single Euclidean space. It’s a disjoint union of pieces of different dimensions, glued together at their boundaries by the moves we’ll eventually let the chain take. §3 makes that geometric picture precise.
3.1 The disjoint union and its measure
Formally, the trans-dimensional state space is
where (or any countable index set) is the model index set and each is the parameter space of , with dimension . A point in is a pair : a model index and a parameter vector whose dimension depends on which model we’re in. Two points with different model indices are distinct points in even if their continuous coordinates look related — there is no canonical embedding of inside that lets us pretend they live in the same Euclidean space.
The natural sigma-algebra on is the disjoint sum of the per-fiber Borel sigma-algebras: a set is in iff for every , the slice is Borel in . This is exactly the sigma-algebra one would get by treating as the topological coproduct of the and taking the resulting Borel sets.
The natural reference measure on is the disjoint sum of (model prior × Lebesgue):
Here is Lebesgue measure on and is the model prior from §2.2. The trans-model posterior
is a density with respect to : the Radon–Nikodym derivative exists and is what RJ-MCMC’s acceptance ratio fundamentally evaluates ratios of. As long as each fiber’s marginal likelihood is finite and the model prior sums to 1, is sigma-finite and the Radon–Nikodym machinery applies without fuss.
We’ll work with this as the reference throughout. The deep machinery in §§5–7 builds out why a chain whose proposal density involves both a model-index move and a dimension-changing parameter move can still be made -symmetric.
3.2 Picture 1 — the subset-model lattice
The state space for variable selection has graph structure beyond its measure-theoretic skeleton. Each “node” — a model indexed by — is connected to its Hamming-distance-one neighbors: the models that differ from by exactly one variable. The full structure is the -dimensional Boolean lattice ordered by inclusion, with edges between and iff . Cardinality stratifies the lattice into layers, with layer holding nodes.
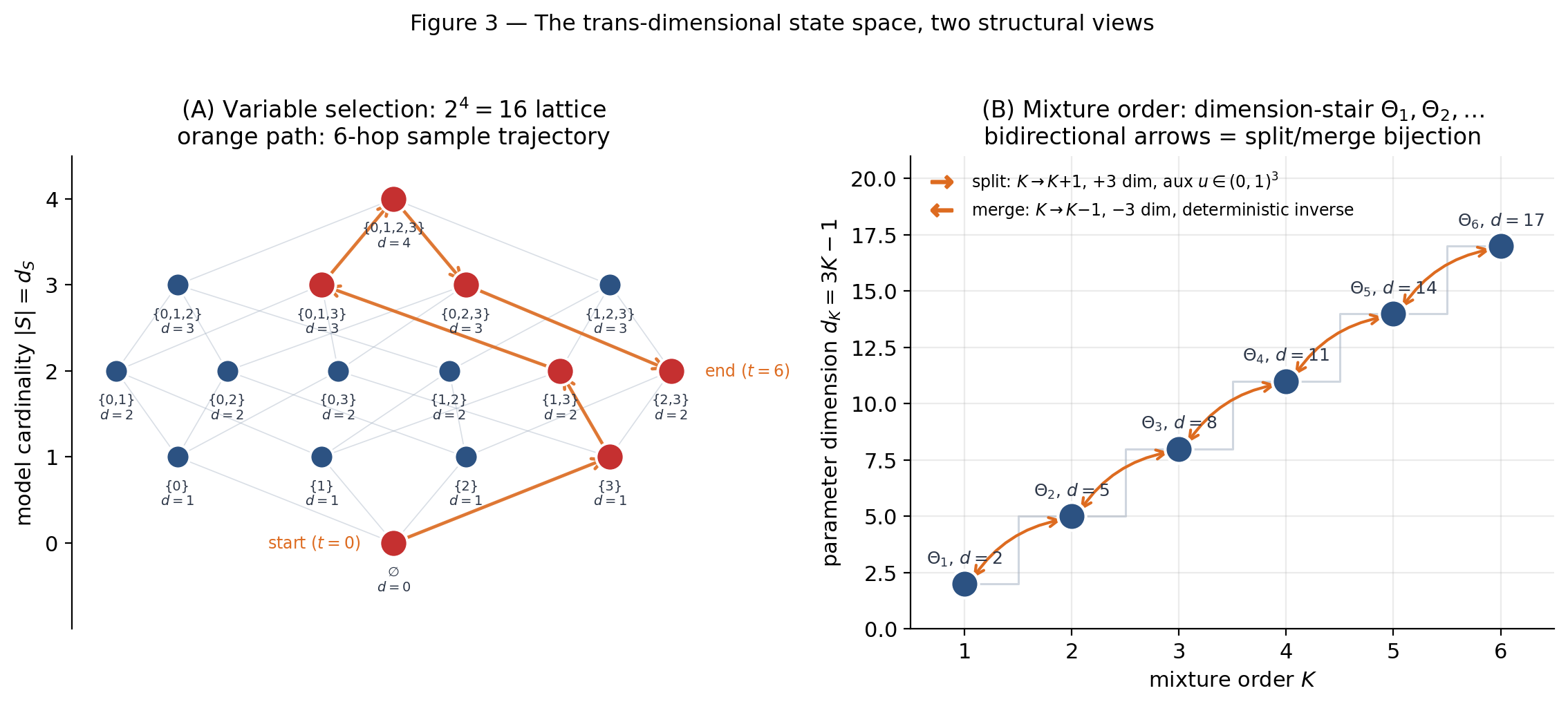
This graph structure is the natural substrate for RJ-MCMC’s move catalog. The standard add/drop catalog — propose one of the neighbors uniformly at random, accept or reject — walks along lattice edges. The chain’s state at iteration is the pair , where is the current discrete coordinate (which lattice node) and is the current continuous coordinate (the vector of coefficients for the included covariates). The discrete coordinate determines which fiber the continuous coordinate lives in. As the chain hops between lattice nodes, the dimension of changes — adding a covariate appends a dimension, dropping a covariate removes one. Figure 3A draws the case with a sample 6-hop trajectory overlaid, every node annotated with its dimension .
The geometry is sparse in a useful way: every node has exactly neighbors (not ), so the move catalog at any given iteration is local in the lattice. This is what makes RJ-MCMC scale to large — proposals are cheap, even when the model space is enormous.
3.3 Picture 2 — the mixture-order dimension-stair
The mixture-order state space is even simpler topologically. Model index ranges over , and the parameter fiber has dimension
So the dimensions are , , , , , : a stair-step in rising by 3 per step. Figure 3B plots this stair.
The split/merge move catalog (Richardson–Green 1997 §3.2) connects consecutive layers. From a point in , splitting one component into two yields a point in : the dimension goes up by 3. Merging two components into one yields a point in : the dimension goes down by 3. The split is not deterministic from the source state — there’s a continuum of ways to split a Gaussian component into two — so the split move draws three auxiliary variables from Beta-distributed proposals to parameterize the split. The merge move is deterministic given which two components to combine. §10 makes this explicit; for now the picture is just dimension change ±3, plus auxiliary variables on the split side.
A complementary birth/death move catalog adds or removes an empty component, drawing the new component’s from a prior-like proposal. The dimension change is still ±3 per move, but the new component’s parameters don’t depend on any existing component. Mixing the two catalogs (random scan between split/merge and birth/death) gives the chain more degrees of freedom to navigate the dimension stair.
One geometric caveat: each has symmetric copies obtained by permuting component labels — the well-known label-switching identifiability issue. The likelihood is invariant under permutations, so the posterior on is -fold symmetric. RJ-MCMC typically samples one copy at a time (the chain rarely traverses between symmetric copies once it has settled), and we handle the symmetry post hoc when it matters for diagnostics. §11.3 returns to this.
3.4 The reference-measure problem
Here is the obstruction that motivates everything in §§5–7.
The reference measure from §3.1 puts Lebesgue on each fiber separately. Within a single fiber, Lebesgue measure is the natural one — it’s what lets us write a posterior density , evaluate it, and run standard fixed-dim MCMC on . The trouble starts when we try to construct a Markov transition kernel that moves between fibers of different dimensions.
A standard MH proposal kernel in fixed dimension is a density with respect to Lebesgue on the target space: is a probability measure on . When source and target have the same dimension this works fine. When source has dimension and target has dimension , there is no single Lebesgue measure that absorbs both: and live on spaces of different dimensions and have different “units” — multiplying a coordinate by a scalar scales by but by .
Concretely: if we propose moving from to with , the proposal must somehow produce the “extra” coordinates that don’t have analogs on the source side. The naive fix — draw from some density on directly — gives a proposal that’s not absolutely continuous with respect to any natural measure relating source and target, and the acceptance ratio that results is dimensionally inconsistent. Detailed balance then fails because we’re equating densities with respect to incompatible reference measures.
Green’s (1995) construction fixes this by working on a common higher-dimensional space. We draw auxiliary variables on — the source side gets padded up to match the target’s dimension — and then a deterministic bijection converts the padded source to the target. The proposal is now absolutely continuous on the padded space; the change-of-variables formula then relates measures on either side:
The Jacobian determinant is precisely the unit-conversion factor between the natural measures on either side of the bijection. The trans-dim MH acceptance ratio includes this Jacobian as a correction factor; the resulting kernel is -symmetric, detailed balance holds, and the chain genuinely samples the trans-dim posterior .
This is the conceptual answer to “why is the Jacobian in the acceptance ratio.” §5 builds the auxiliary-variable construction rigorously and gives the measurability conditions (Theorem 1). §6 proves the bijection’s reversibility (Theorem 2 — the involution shortcut that makes the move catalog hand-codable). §7 puts the pieces together and derives the master acceptance ratio with full detailed-balance proof (Theorem 3). §4, immediately next, is a brief refresher on where fixed-dim MH stops short — pinning down exactly which step of the standard MH proof breaks when source and target have different dimensions.
§4. Standard MH refresher and where it stops short
§4 names what we’re extending. The standard Metropolis–Hastings framework from formalStatistics: bayesian-computation-and-mcmc handles fixed-dimensional targets via detailed balance; §§4.1–4.2 recap just enough to fix notation. §4.3 then pins down exactly where the standard framework breaks when source and target have different dimensions — the measure-zero submanifold problem that motivates Green’s auxiliary-variable construction in §5.
4.1 The MH acceptance ratio in fixed dimension — one-line recap
For a target density on with respect to Lebesgue measure, the standard Metropolis–Hastings chain is constructed from a proposal density and the acceptance probability
The resulting transition kernel — accept the proposal with probability , otherwise stay at — has as its stationary distribution under the standard regularity conditions. We cite §§26.3–26.5 of the sister-site treatment rather than re-derive.
4.2 Detailed balance as the target-invariance condition
The proof that MH preserves rests on detailed balance. A Markov kernel with transition density with respect to Lebesgue is -symmetric iff
for -almost every pair . Integrating both sides over gives , confirming that is invariant under . The MH acceptance probability from §4.1 is exactly the rejection rate that makes the proposed kernel satisfy detailed balance.
The key technical ingredient — and the one that breaks in trans-dimensional MCMC — is that both sides of the detailed-balance equation are densities with respect to the same reference measure. Lebesgue measure on . The equation is an equality of densities on , and the standard machinery works because the densities live on the same ambient space with the same units. This is what allows us to divide both sides by , take the ratio , and call the resulting expression an acceptance probability.
4.3 Why the obvious “propose a model, propose its parameters” move violates detailed balance
Now try to extend MH to the trans-dimensional setting. The most efficiency-minded naive attempt: from the current state , propose moving to model with parameters computed deterministically from via some chosen map . The intuition is “reuse the current parameters; only the model index changes.” Some specific instances:
- Variable-selection add-move. Propose adding covariate by setting — augmenting the current parameter vector with a zero in the new slot.
- Mixture-order split-move. Propose splitting component at fixed offset by setting and keeping , .
- Generally: propose for some smooth injective map with .
The naive MH acceptance ratio would read
where is the model-index proposal probability. The expression looks fine — both -densities are with respect to the trans-model reference measure from §3.1, and the ratio is dimensionless. But the framework breaks for a deeper reason that only surfaces when we ask whether detailed balance actually holds.
The injective deterministic map sends bijectively onto the submanifold of dimension . Since , the image has Lebesgue measure zero in — it’s a -dimensional set inside a -dimensional ambient space, like a line inside a plane (Figure 4A draws exactly this case for , ). The reverse move is only defined when happens to lie on this image submanifold — and since the submanifold has Lebesgue measure zero in , the reverse-move proposal density is zero almost everywhere in .
Detailed balance demands equality between forward-rate forward-density and reverse-rate reverse-density at the same pair. With the reverse-proposal density being zero almost everywhere with respect to Lebesgue on , the equation is not an equality of well-defined densities — it’s an equality of mutually singular measures, and the standard MH acceptance derivation does not produce a valid kernel.
The fix is the auxiliary-variable construction. Instead of , Green (1995) proposes
where on is drawn from a known proposal density and (possibly empty) is whatever residual the move generates on the target side. The dimension-matching constraint is
so that is a smooth bijection between padded spaces of equal dimension. Its image is no longer a measure-zero submanifold — it’s a full-dimensional set in with non-degenerate density on either side. The change-of-variables formula then relates measures on either side via the Jacobian determinant , and detailed balance is recoverable. Figure 4B shows the simplest case: padding the 1D source with a single auxiliary yields a 2D joint that fills with non-degenerate density, evading the measure-zero obstruction entirely.
This is the gap §4 names. §5 builds the auxiliary-variable construction rigorously and gives the measurability conditions in Theorem 1; §6 proves the bijection’s reversibility (Theorem 2); §7 derives the master acceptance ratio with full detailed-balance proof (Theorem 3).
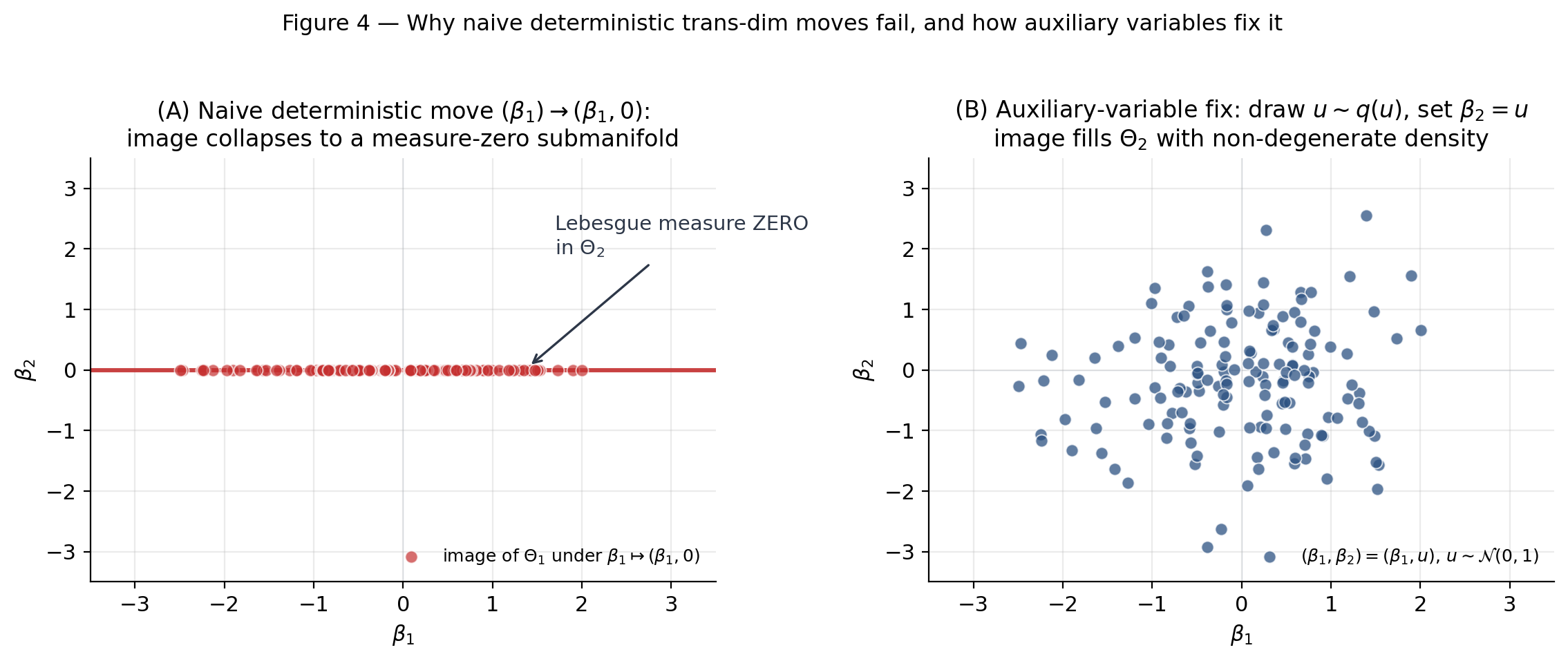
Try shrinking and watch the auxiliary cloud collapse back onto the measure-zero line.
§5. The dimension-matching auxiliary-variable construction
§5 is the first of the three load-bearing proofs and the conceptual centerpiece of the topic. §4 named the obstruction — the measure-zero submanifold problem. §5 builds the fix. The construction is Green’s (1995) central trick: instead of a deterministic move between fibers of different dimensions, draw an auxiliary random variable on the source side, define a deterministic bijection on padded spaces of equal dimension, and let the change-of-variables formula handle the rest. Theorem 1 establishes that this construction defines a well-formed proposal kernel with an explicit density on the target side, given by the source density divided by the Jacobian determinant of .
5.1 The auxiliary-variable pair and the dimension-matching constraint
A move type in RJ-MCMC is a tuple
specifying source model index , target model index , a deterministic map between padded spaces, and a probability density on the source-side auxiliary space with respect to Lebesgue. The target-side auxiliary space holds whatever residual the move generates on the target side.
The dimension-matching constraint is
ensuring has domain and codomain of the same total dimension.
Three standard regimes cover all the moves we’ll need:
- Dimension-up move (). The source side is padded with auxiliary variables; the target side has no residual, . Example: variable-selection add-move (§9), where becomes the new coefficient.
- Dimension-down move (). The target side has residual auxiliary variables; the source side has no padding, . The move is the inverse of some dimension-up move.
- Dimension-matched move (). Either (deterministic same-dimension move) or (auxiliary variables on both sides).
The mixture-order split-move (§10) is the canonical dimension-up move: from a state in with components, split one component into two to land in with components. The dimension change is , so auxiliary variables parameterize the split.
5.2 The proposal mechanism
At state , the full proposal mechanism is:
- Select a move type from the catalog with probability , where and the sum runs over moves with source .
- Move specifies the target model and the bijection .
- Draw auxiliary on .
- Compute .
- Accept the proposed state with probability (derived in §7); otherwise stay.
The move-type prior is the categorical distribution over moves available at the current state. It can be state-dependent — for instance, mixture-order birth/death-moves at disallow births and put all mass on death-moves and within-model updates. This state-dependence is benign as long as is Borel-measurable in .
The model-index proposal is the marginal probability that the next state’s model index is given the current state is . We keep the move type as the primitive throughout and let be derived.
5.3 Theorem 1 — the bijection as a measurable construction
Theorem 1 (Dimension-matching auxiliary-variable construction).
Let move have source model with parameter dimension , target model with dimension , source-side auxiliary space , target-side auxiliary space , and dimension-matching constraint . Suppose:
(i) is a diffeomorphism on its open domain.
(ii) is a Borel-measurable probability density on with respect to Lebesgue.
Then the proposal kernel — draw , apply — has push-forward density on given by
where is the unique source-side auxiliary value such that , and is the Jacobian matrix of . Equivalently,
evaluated at .
Proof.
Three steps.
Step 1: exists and is . By the dimension-matching constraint, maps between open subsets of . By hypothesis (i), is a diffeomorphism, so it has a well-defined inverse . The inverse function theorem (cited from formalcalculus/change-of-variables) gives
so , and both determinants are nonzero everywhere on the domain.
Step 2: The change-of-variables identity for push-forward measures. Let be a bounded Borel-measurable test function. The push-forward of the measure under is the measure defined by for Borel . Computing two ways and equating:
The right-hand integrand identifies the density of with respect to Lebesgue on the target side.
Step 3: Equivalent form via . Substituting from Step 1 gives the equivalent expression .
∎Remark.
On measurability. Hypothesis (ii)‘s Borel measurability of together with the assumption on ensure is Borel measurable. Promoting the move- proposal to a full Markov kernel measurable in also requires to be Borel measurable, which is given throughout.
On the necessity of dimension matching. Without it, cannot be a bijection between subsets of equal-dimensional Euclidean spaces, and the inverse function theorem doesn’t apply. Step 1 fails and the construction collapses.
5.4 The Jacobian determinant — what its rows and columns mean
The Jacobian matrix is the matrix of partial derivatives
square by dimension matching. Rows index target-side coordinates ; columns index source-side coordinates. The determinant is the signed volume-distortion factor under linearization of at .
Numerical computation. For the variable-selection add-move (§9), is the identity in coordinates, so and exactly. For the mixture-split move (§10), is the nonlinear Richardson–Green bijection and is a closed-form expression evaluated in log space via direct summation of elementary logarithms — no matrix needed. When the Jacobian has no closed form, numpy.linalg.slogdet is the right primitive (§12.2). The Jacobian determinant appears in the master acceptance ratio in §7 as the factor that makes the trans-dim Metropolis correction satisfy detailed balance.
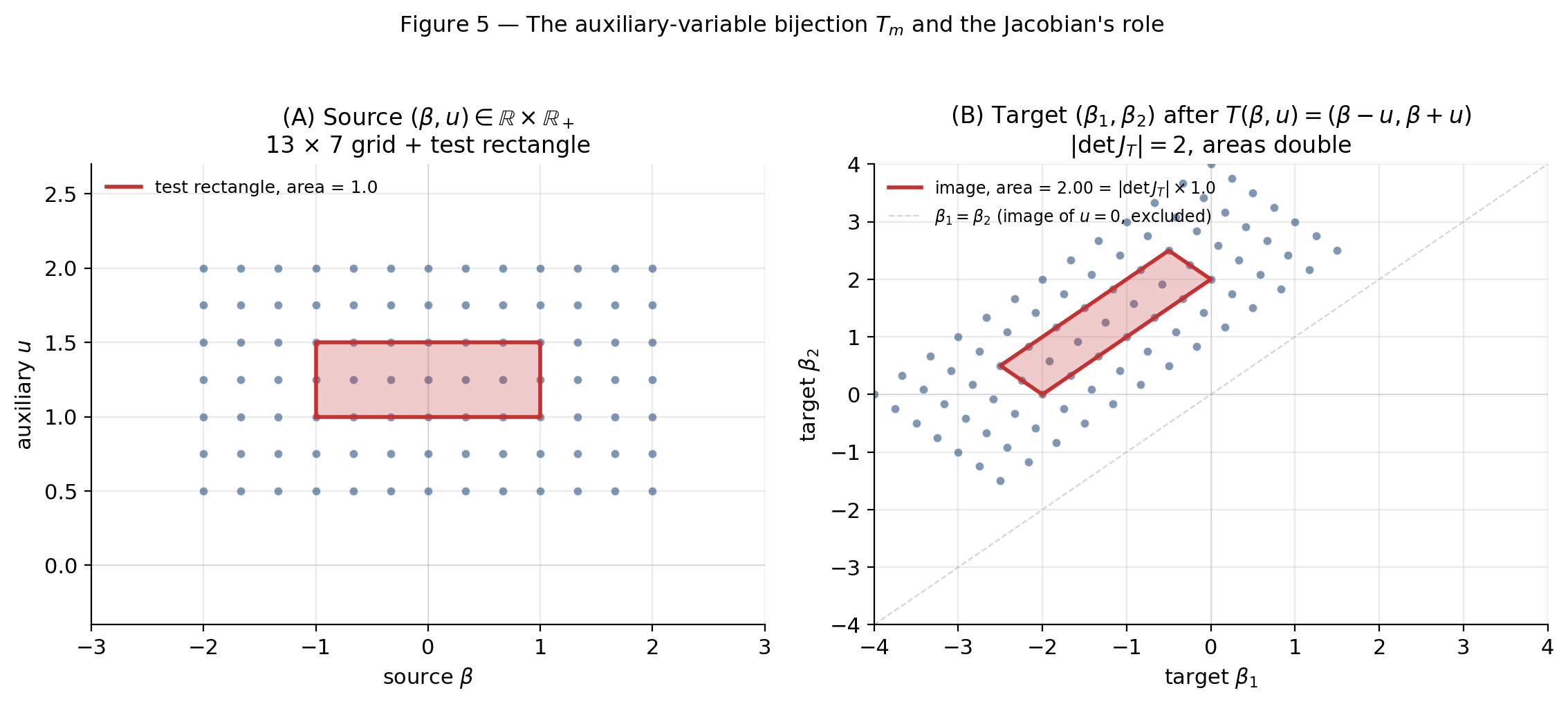
Drag to scale the split: tracks the parallelogram area. At the bijection degenerates to — a measure-zero line in the target.
§6. Reversibility of the bijection and the involution shortcut
§6 is the second load-bearing proof. §5 built the bijection; §6 shows every move comes with a paired reverse move whose Jacobian is the reciprocal. This involution structure makes the trans-dim Metropolis correction symmetric in the move pair, which drives §7’s detailed-balance proof. Practical content: we never write down a separate “merge” or “drop” or “death” implementation. We write the dim-up direction once and the dim-down direction is computed by inverting the bijection at runtime.
6.1 The reverse move as
The natural candidate for the reverse of move is the move that starts at and lands at by applying . Defining by swapping source/target/auxiliary spaces:
- Source model .
- Target model .
- Source-side auxiliary space .
- Target-side auxiliary space .
- Bijection .
The dimension-matching constraint for is exactly the constraint for rearranged. In the standard dim-changing setting where is a dim-up move with and , is a dim-down move with and : the dim-down move is deterministic given the source state.
6.2 Theorem 2 — reversibility and the involution structure
Theorem 2 (Reversibility and the involution structure).
Let move be defined as in §5 with diffeomorphism . Define the reverse move as in §6.1: source/target/auxiliary spaces swapped, . Then:
(a) [Involution] is itself a valid move type in the §5.1 sense, and the operation is an involution: . The bijections satisfy
(b) [Move-catalog reduction] Every move-pair is uniquely specified by either direction. In implementation, choose one — the natural dim-up direction — and the reverse direction comes free by inversion.
(c) [Jacobian product] For any with ,
Proof.
(a) Involution. is a diffeomorphism by §5 hypothesis (i), so its inverse exists and is . Define ; this is by construction a diffeomorphism, so satisfies §5 hypothesis (i). The dimension-matching constraint translates by swap. For : applying §6.1’s swapping rules to gives back . The composition identities are immediate from .
(b) Move-catalog reduction. Every datum of is determined by the datum of via swapping or inversion. The move catalog decomposes into pairs , and choosing one direction specifies the entire pair. In code: implement as a function; the reverse is either an analytic inverse or a numerical inverter.
(c) Jacobian product. By the inverse function theorem (Step 1 of Theorem 1’s proof), at matched coordinates. Taking determinants: . Substituting and taking absolute values gives the identity.
∎Remark.
On signs. The Jacobian can be negative (orientation-reversing); only the absolute value enters the acceptance ratio. The product-equals-1 identity holds for absolute values; for signed determinants the relation is .
On regularity. All moves in §§9–10 have either linear (Jacobian constant) or smooth nonlinear with explicit invertibility verified numerically via a round-trip test.
6.3 The involution trick in practice
The structural message is concrete: in the move catalogs we’ll use, every dim-changing operation is naturally paired with its inverse, and we implement only one direction per pair.
Split/merge (mixture order, §10). The forward direction is split: pick a component , draw , apply the Richardson–Green bijection. The reverse direction is merge: pick two adjacent components, deterministically combine them via . The merge move requires no random ingredient — given the two components to merge, produces both the merged component and the residual auxiliaries that would have generated the split.
Birth/death (mixture order, §10). Birth draws a new component from a prior-like proposal; death picks an existing component and removes it. Again the death move is deterministic given which component to remove.
Add/drop (variable selection, §9). Add draws the new coefficient ; drop is deterministic, with the dropped value serving as the recovered auxiliary.
In each case the implementation reduces to one function per move-pair: the §9 catalog fits in about 30 lines; the §10 catalog in about 80 lines including the closed-form Richardson–Green Jacobian.
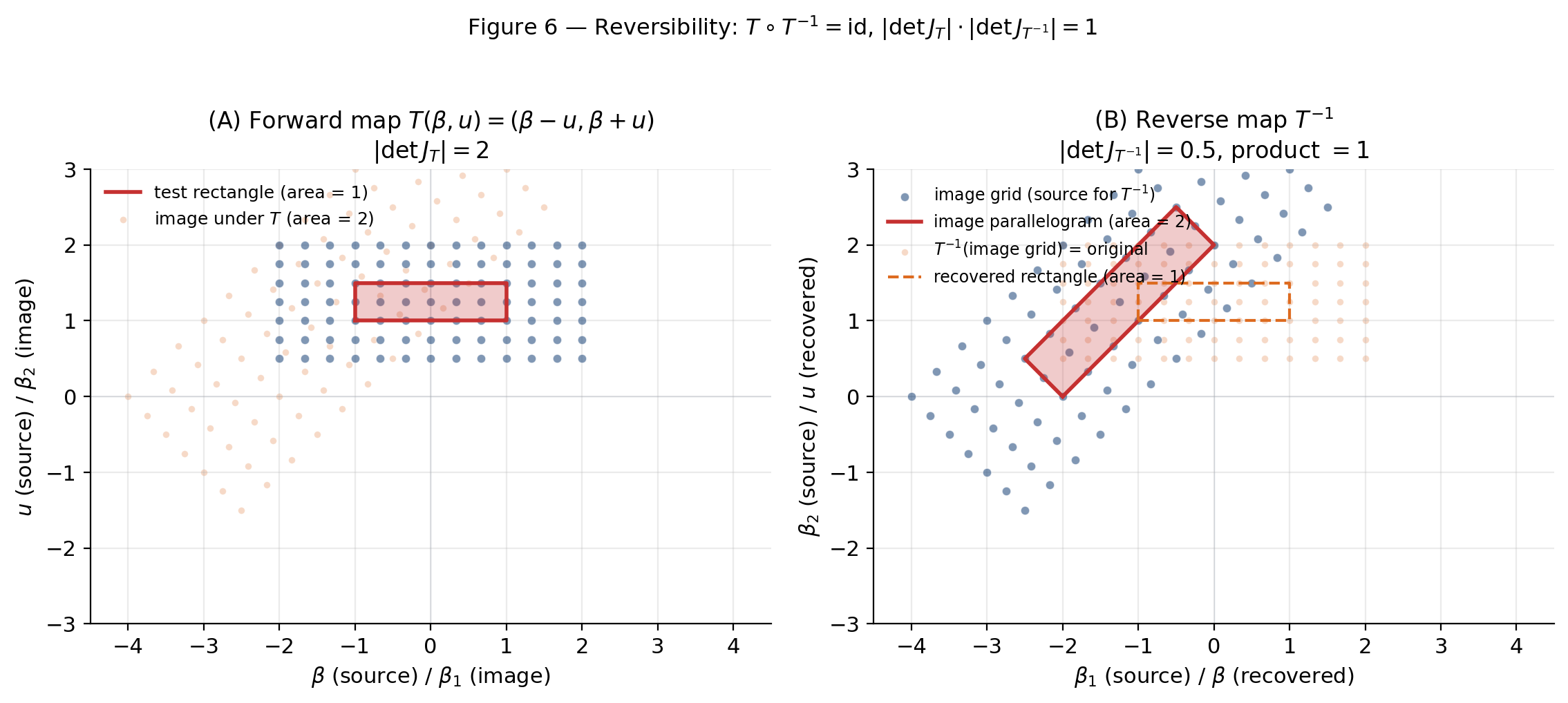
Toggle the round-trip overlay to confirm that applying then recovers every source point — the max deviation tracks float64 machine precision.
§7. Detailed balance with the Jacobian correction — the master acceptance ratio
§7 is the third load-bearing proof and the topic’s culminating equation. §5 built the auxiliary-variable bijection with its push-forward density (Theorem 1). §6 paired every move with its inverse and gave the Jacobian-product identity (Theorem 2). §7 assembles these into the trans-dimensional Metropolis–Hastings acceptance ratio and proves the resulting chain is -reversible. The equation we’ll derive,
is the master acceptance ratio.
7.1 The trans-dimensional detailed-balance equation
Detailed balance in the trans-dim setting: a Markov kernel on is -reversible iff for every pair of measurable sets ,
For the move- proposal kernel, this specializes to the pointwise equality
where the Jacobian factor on the right converts the target-side density into source-side coordinates via the change-of-variables formula. This is the trans-dim detailed-balance equation.
The new ingredient compared to fixed-dim MH (§4.1): the Jacobian factor . In fixed-dim MH, is the identity, , and we recover the standard MH detailed-balance equation.
7.2 Theorem 3 — detailed balance with the Jacobian factor
Theorem 3 (Master acceptance ratio for trans-dim MH).
Consider the trans-dim Markov chain on with move catalog and proposal mechanism from §5.2. Define the Metropolis ratio for move at state :
where . Take the acceptance probabilities
Then the resulting Markov chain is -reversible (and hence -invariant) on .
Proof.
Four steps.
Step 1: Pointwise detailed balance for move . From §7.1, the move- detailed-balance equation at matched coordinates with is
Step 2: Symmetry under the involution. Rearrange to isolate :
The reverse Metropolis ratio at matched coordinates is
By Theorem 2(c), . Substituting: . The forward and reverse Metropolis ratios are exact reciprocals at matched coordinates.
Step 3: The Metropolis lemma. The choice , satisfies with both values in . Verification by cases: if , , , ratio . If , , , ratio . Plugging back into confirms detailed balance.
Step 4: Summing over moves. Detailed balance for the full chain transition kernel follows by summing over all move types . Since at every state, the chain’s full transition kernel satisfies detailed balance with respect to . -invariance follows.
∎Remark.
On the trivial-Jacobian case. When is the identity in auxiliary-variable coordinates (the variable-selection add-move), and the master ratio reduces to the proposal-ratio form without an explicit Jacobian factor. This is the form §9 uses.
On the nontrivial-Jacobian case. For the mixture-split move (§10), is the nonlinear Richardson–Green map; depends nontrivially on the source state and auxiliaries. §12.2 explains why slogdet over det is mandatory.
7.3 Three special cases
Special case 1: Fixed-dim MH (, no auxiliary variables, Jacobian ). When the move keeps the model fixed and has no auxiliary variables, is the identity, , and the master ratio reduces to the standard MH acceptance ratio. RJ-MCMC contains fixed-dim MH as the no-model-change special case.
Special case 2: Identity bijection in coordinates (). The variable-selection add-move (§9): literally inserts at position of the coefficient vector. exactly. The master ratio becomes
No Jacobian appears explicitly, but the structure is genuinely trans-dim — the dimension of changes between iterations.
Special case 3: Dimension-matched move with shared auxiliary variables (, , nontrivial Jacobian). An exotic case: the move keeps the model fixed but uses auxiliary variables to update via a nonlinear transformation (e.g., a reflection move in HMC-style trans-dim proposals). The Jacobian is generally nontrivial. Not used in §§9–10, but a conceptual bridge: dimension-changing isn’t the only situation where the Jacobian factor matters.
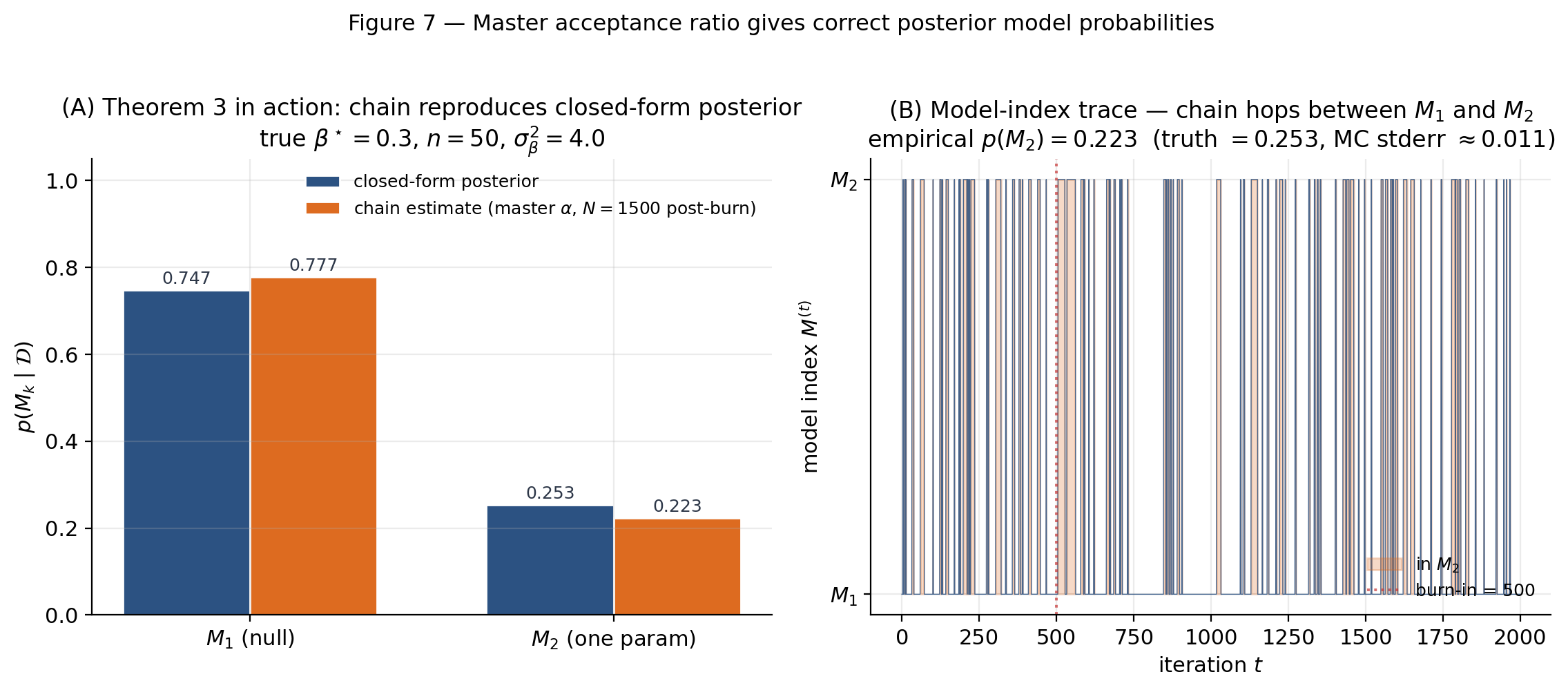
Drag rightward to see the chain’s climb toward 1; shrink to make the prior tighter and the Lindley–Bartlett bias against surface. The heavy chain recompute fires only on slider release.
§8. The move catalog — split/merge, birth/death, and RJ-MH
§§5–7 built the trans-dim machinery in the abstract. §8 specializes to the move catalog that actually gets implemented for the topic’s two worked examples. Each move type is fully specified by its bijection , its auxiliary proposal , and the Jacobian — all three of which we now write out in closed form.
8.1 Birth/death — the simplest dimension-changing pair
The birth move. From state , draw three auxiliary variables:
Typical proposals: , , (Richardson–Green 1997 §4 motivates this choice). The bijection takes the padded source to the target via:
- New component: .
- Existing components rescaled: for .
The rescaling preserves .
The Jacobian. The - and -blocks contribute determinant . The weight transformation: the -block has block-matrix structure that extends the rescaling to all free pre-birth weights, giving
Figure 8B plots this Jacobian for on a log -axis. At and , — within an order of magnitude of float64’s machine epsilon (), so direct det evaluation followed by log accumulates serious rounding error long before the value itself underflows. The computational notes (§12.2) explain why numpy.linalg.slogdet is mandatory.
The death move. From , pick uniformly and remove it. Deterministic inverse: , for . Reverse Jacobian ; the Theorem 2(c) product identity holds.
The acceptance ratio. Plugging into Theorem 3 and simplifying (the Beta weight proposal density’s term cancels the Jacobian):
The comes from the component-selection probability in the reverse death move () and the in .
8.2 Split/merge — Richardson–Green’s Jacobian for mixture components
The split move (Richardson–Green 1997 eq. 11). Pick component uniformly. Draw
Compute the two new components :
By construction, the new pair preserves the first and second moments of the source mixture component:
Derivation of . The Jacobian matrix has rows and columns . Reordering rows and columns to group “weight variables first, then mean/variance variables” puts the matrix in block-triangular form:
where the upper-right block is identically zero because the weight outputs depend only on . By the block-triangular determinant identity, .
The -block is
The -block has rows and columns . Computing each entry from the partial derivatives of the bijection equations: the -rows depend on but not . Cofactor expansion along the column reduces to a sum of two minors. Carrying out the algebra:
Combining with :
This is the Richardson–Green 1997 §3.2 eq. (11) result. The §8 notebook code cell verifies it against a finite-difference computation of the Jacobian at the test point to machine precision: closed-form value .
The merge move. Pick a pair of components adjacent in the mean-sorted ordering. Apply deterministically: , , , then from mean separation, from variance allocation, from second-moment conservation.
The acceptance ratio for split. With uniform random-scan move-type prior (), component-selection , merge-pair-selection :
The term is zero because has density 1. The Jacobian is computed in log space directly from the formula above — no matrix is constructed.
8.3 Update moves within a model — standard MH/Gibbs reuses without modification
When (model fixed), the trans-dim framework collapses to fixed-dim MH (§7.3 special case 1). Any standard MH or Gibbs update of is admissible.
For §9: conjugate Gaussian-Gibbs sample of from the closed-form posterior . For §10: four Gibbs conditionals — component assignments , weights , means , variances — all closed-form.
8.4 Mixing the move catalog — random scan vs. deterministic cycle
Random scan. Select move with state-dependent probability . Theoretical advantage: detailed balance holds move-by-move.
Deterministic cycle. Cycle through moves in fixed order. Per-cycle reversibility; sweep-by-sweep convergence analysis.
§§9–10 use random scan throughout.
Boundary conditions. At (no merge available) or (no split available), the move-type prior must zero out unavailable moves and renormalize. The acceptance ratio in §§8.1 and 8.2 involves both on the source side and on the target side — when depends on state through boundary masking, getting the per-state values right is a common implementation bug. §10’s code makes the state-dependent boundary handling explicit.
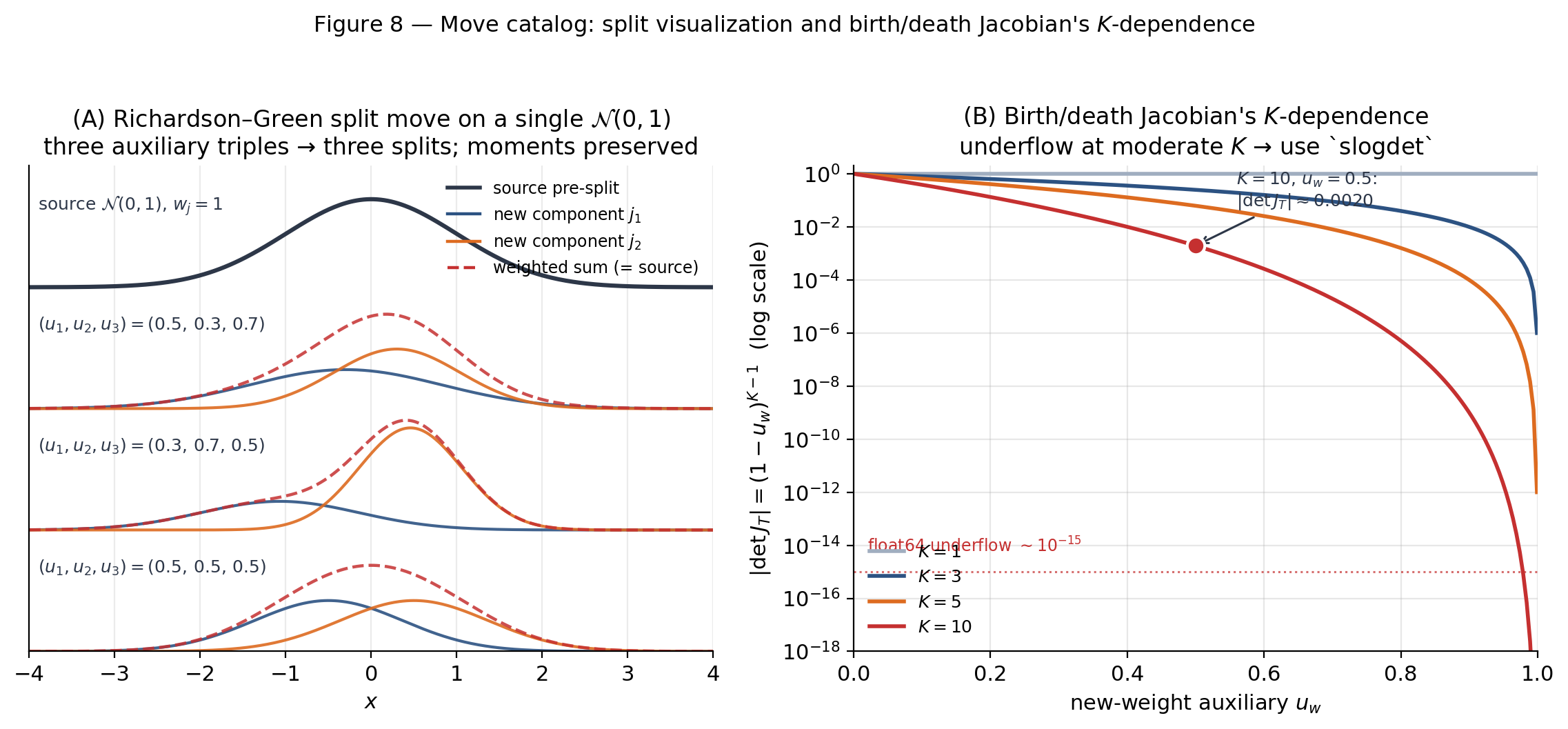
Drag to see how the auxiliaries control width imbalance (), mean separation (), and variance allocation (). The right panel shows why the birth/death Jacobian crosses float64’s rounding-loss horizon (combined with other small terms in the acceptance ratio) at .
§9. Worked example A — Linear-regression variable selection (Kuo–Mallick)
§9 runs the topic’s first complete RJ-MCMC chain. The problem — linear-regression variable selection at — is small enough that every posterior model probability can be computed exactly by enumerating all subset-models, so we have a gold-standard reference to validate the chain against.
§9 discharges sparse-bayesian-priors §12.6’s forward-pointer to RJ-MCMC as the discrete-spike-and-slab workhorse, and establishes the validation pattern — “RJ-MCMC vs closed-form gold standard” — that §10’s mixture-order demo relies on by extension.
9.1 The model — Gaussian likelihood, -prior, Scott–Berger model prior
Likelihood. , , with . Design matrix treated as fixed (and centered).
Inclusion indicators. : iff covariate is included. Active set with cardinality .
-prior on active coefficients.
with (unit-information). is given a flat prior on log scale and marginalized analytically.
Scott–Berger model prior. , making model size uniform on .
Target. .
9.2 The add/drop move — single Gaussian auxiliary, Jacobian
At each iteration: pick a covariate uniformly and propose to flip .
Add move (). Draw . Bijection — identity bijection (permutation). exactly.
Drop move. Deterministic: (the dropped coefficient).
The master acceptance ratio. With and , Theorem 3’s master ratio reduces to
9.3 The closed-form marginal likelihood and the marginalization shortcut
Under the conjugate -prior, can be analytically integrated out. The marginal likelihood is the Liang et al. 2008 eq. (5):
with the OLS coefficient of determination of on . The constant cancels in posterior model probability ratios.
The marginalization shortcut. Because can be integrated out, the chain doesn’t have to sample it explicitly. The trans-dim machinery reduces to a Metropolis–Hastings chain on alone with
Conceptually the chain is RJ-MCMC; implementationally it’s MH on with one-bit-flip proposals. Approach 1 (sample jointly) and approach 2 (sample alone with the marginal likelihood) produce identical -marginal posteriors at the same MC sample size. We use approach 2 in §9’s code for efficiency.
9.4 Numerical results — posterior inclusion probabilities and top-model recovery
Setup. , . True coefficients — three active covariates at indices . Noise . Hyperparameters: , Scott–Berger prior.
Enumeration baseline. All 256 subset-models enumerated. Posterior inclusion probabilities for each and model-size posterior computed exactly.
RJ-MCMC chain. 5000 iterations, burn 1000. The log-marginal-likelihood for each visited is cached in a dictionary keyed by the indicator-vector bitstring.
Results. The chain recovers the enumeration posterior to a maximum inclusion-probability deviation of (covariate 7 — a noise covariate). All three true-active covariates have exactly under both enumeration and the chain. The top model carries posterior mass under enumeration; the chain returns . The top-5 model rankings agree with one transposition between ranks 3 and 4. Chain acceptance rate ; unique models visited — the chain concentrates rapidly on the high-posterior region without exhausting the model space.
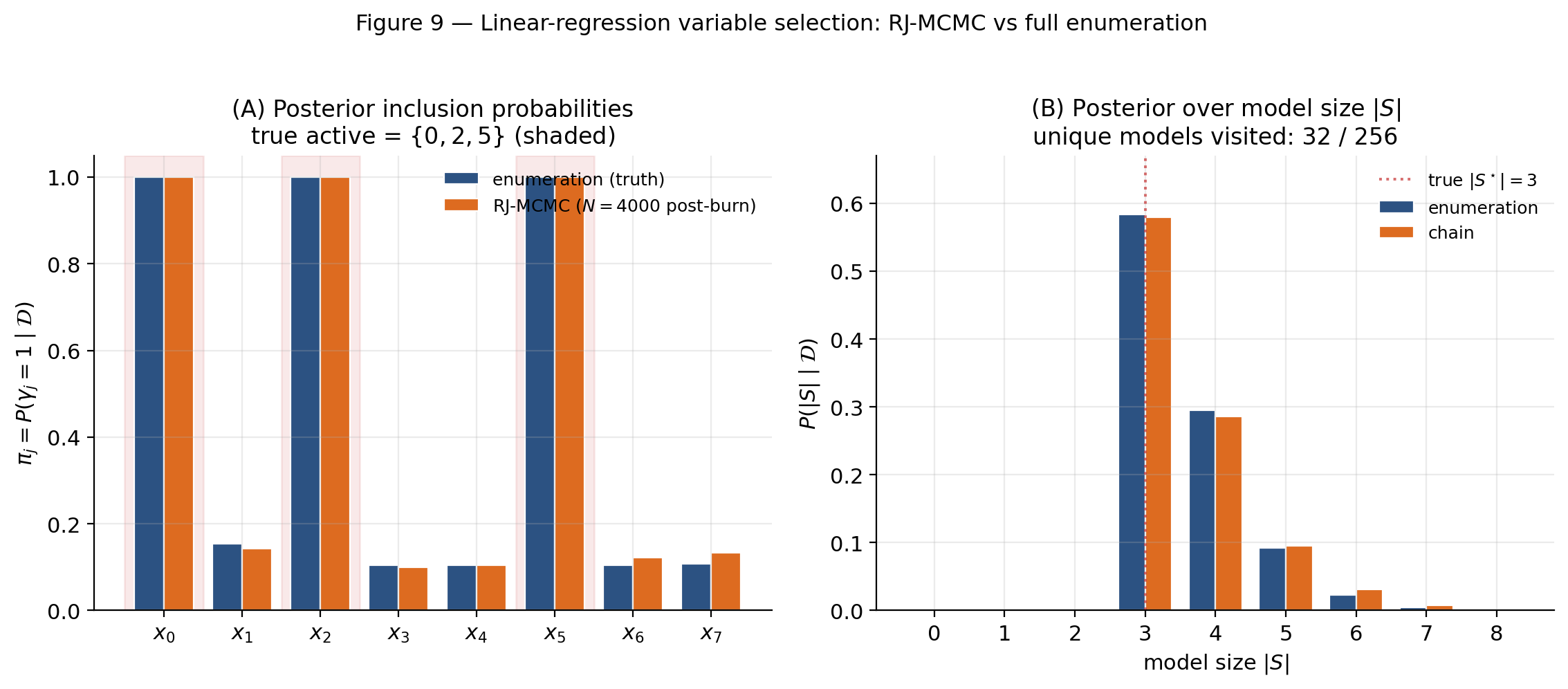
Drop SNR to make the noise covariates indistinguishable from the active ones and watch both posteriors blur together. The chain rerun fires only on slider release; the enumeration baseline always recomputes (256 OLS fits is fast).
§10. Worked example B — Univariate Gaussian-mixture order estimation (Richardson–Green on Galaxy data)
§10 runs the canonical RJ-MCMC demo: Richardson–Green (1997) on the Galaxy dataset. The chain combines four trans-dim moves (split, merge, birth, death) with a within-model Gibbs sweep, and samples the joint posterior over .
Unlike §9, enumeration is not feasible — the parameter space is continuous and the marginal likelihood has no closed form. §9’s validation against enumeration is what makes §10’s posteriors trustworthy by extension.
10.1 The model — finite Gaussian mixture, conjugate priors,
Data. Galaxy velocity observations (Roeder 1990), embedded in the notebook’s setup cell.
Mixture model. , .
Parameter priors. , , .
Hyperparameters (data-driven, Richardson–Green style). , where , , , . On the Galaxy data: , , .
Model prior on . Uniform on with .
10.2 The split move — Richardson–Green’s bijection, applied component-wise
From §8.2, the split move’s bijection and Jacobian are fully characterized. The closed-form Jacobian:
The merge move picks an adjacent pair in the mean-sorted ordering and applies deterministically.
The acceptance ratio for split. With uniform random-scan move-type prior:
The Richardson–Green Jacobian is computed in log space directly from the formula.
10.3 The Jacobian determinant in practice — log-space arithmetic and precision guards
The Richardson–Green Jacobian has potential numerical pitfalls: vanishing denominator at or ; vanishing or at extreme weight splits. Beta makes these limits exponentially rare. The closed-form is a sum of elementary logarithms — no matrix needed.
10.4 Birth/death moves and the random-scan catalog
Birth/death is the second trans-dim move pair (§8.1). After the Beta / Jacobian cancellation:
Why two trans-dim move catalogs? Split/merge moves by reshaping an existing component (good at fine-tuning when components are reasonably balanced); birth/death moves by adding/removing an independent component (good at adding genuinely new components). Together they explore the model space from different directions.
Random-scan catalog. At each iteration, draw uniformly from — five moves with prior each. Invalid moves (split or birth at ; merge or death at ) automatically rejected.
10.5 Numerical results on the Galaxy data — posterior over , posterior predictive density
Setup. Galaxy velocity observations. Hyperparameters as in §10.1. . Initial state .
Chain. 5000 iterations, burn 1000.
Posterior over .
| 3 | 0.374 |
| 4 | 0.335 |
| 5 | 0.222 |
| 6 | 0.070 |
Posterior mean . The posterior mode lands at , matching Richardson–Green (1997) §6’s reported result; significant mass on reflects the data’s ambiguity between three sharp components and four blurry ones.
Per-move acceptance rates. Split , merge , birth , death , Gibbs (always accepted). All four trans-dim move rates sit in the “Goldilocks zone” of – that §11.4 discusses. Between- jump rate .
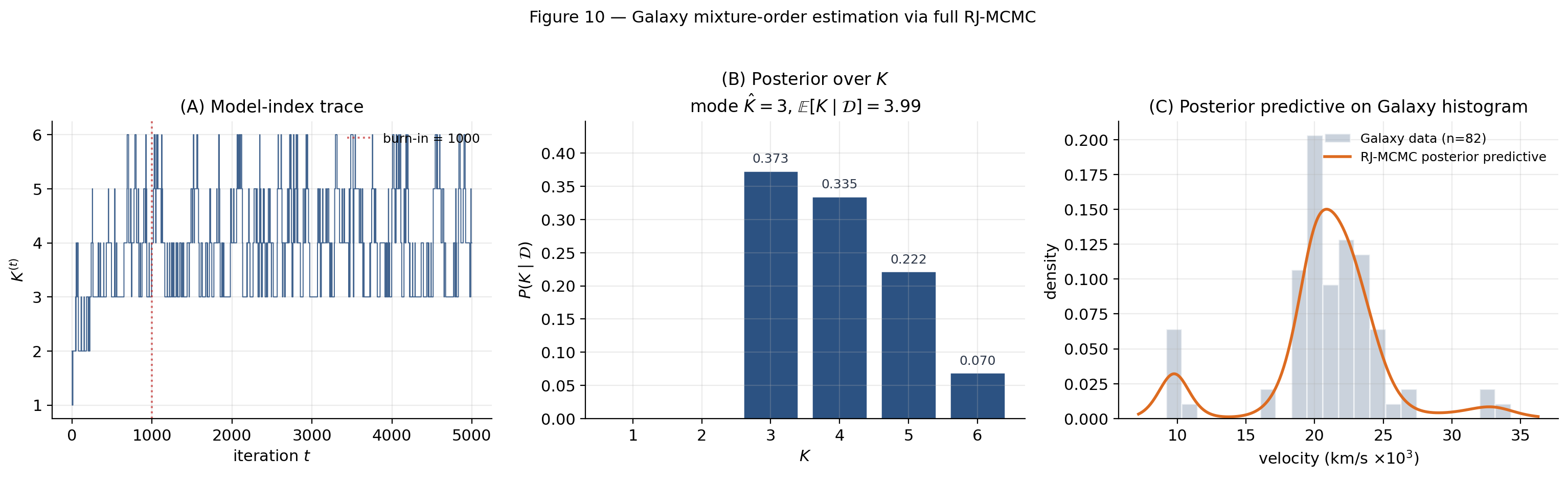
Raise to see whether the posterior chain visits the new high- models, and widen to weaken the prior on component means. The chain rerun fires on slider release.
§11. Diagnostics for trans-dimensional chains
§11 covers what to look at after the chain has run. Standard MCMC diagnostics (, ESS, autocorrelation, trace plots) presume a fixed-dimensional parameter space and a single chain trajectory through it; trans-dim chains break both assumptions.
11.1 Within-model vs across-model diagnostics — the natural decomposition
A trans-dim chain has two sources of variability. The model-index sub-chain visits each with limiting frequency . The within-model sub-chains , one per model, explore with limiting distribution .
Standard MCMC diagnostics apply to each within-model sub-chain restricted to the iterations where the chain is in that model. The model-index sub-chain is genuinely new — a discrete-valued time series whose convergence requires diagnostics specifically designed for discrete-state Markov chains.
For Galaxy at : one model-index sub-chain on ; up to six within-model sub-chains on -dim parameter spaces.
11.2 Convergence of — running fractions and the multinomial CLT band
Three tools diagnose the convergence of .
Tool 1: Model-index trace plot. vs . The chain should hop between values stationarily — no long monotonic trends.
Tool 2: Running fraction plot. vs . At convergence, the curves stabilize near .
Tool 3: Multinomial CLT confidence band. . A band gives expected fluctuations around the limit. Inflated by under autocorrelation.
For the §10 Galaxy chain at post-burn samples:
| 3 | 0.374 | |
| 4 | 0.335 | |
| 5 | 0.222 | |
| 6 | 0.070 |
Between- jump rate. Fraction of iterations with . Target: – for well-mixing trans-dim chains. The Galaxy chain hits .
11.3 Within-model ESS — using only the iterations the chain spent in model
Extract the sub-series where , then compute ESS on this sub-series using standard fixed-dim formulas.
Caveats.
- Re-entry effects. When the chain leaves and re-enters , the within- sub-series is interrupted; after re-entry, may not be drawn from the within- stationary distribution.
- Snapshot-irregularity caveat. The §10 snapshots are saved every 4th post-burn iteration unconditionally; the filtered within- subseries is therefore irregularly spaced in iteration time. The IAT
SNAPSHOT_THINconversion in §11’s code assumes uniform spacing within-, which is only approximate. Bias is typically for chains with between- jump rate per iteration (the Galaxy chain’s regime). - Label switching. To compute ESS of a per-component parameter, identify components by sorting (e.g., ).
For the §10 Galaxy chain at the dominant : snapshots out of 1000 total; integrated autocorrelation time iterations; within-model ESS for the smallest-mean component — enough for crude summaries.
11.4 Between-model jump acceptance rates — the dimension-changing-move-specific diagnostic
Per-move acceptance rates flag specific tuning problems:
- : auxiliary proposals too informative; tighten.
- –: well-tuned.
- : auxiliary proposals too conservative; broaden.
For the §10 chain, observed rates: split , merge , birth , death — all four trans-dim moves sit in the Goldilocks zone. The Gibbs move accepts at by construction (closed-form conjugate updates).
The asymmetry between birth/death rates would be expected if the chain prefers reshaping (split/merge) over independent additions (birth/death); on the Galaxy data the rates are similar, which is consistent with the data supporting multiple genuinely different mixture configurations.
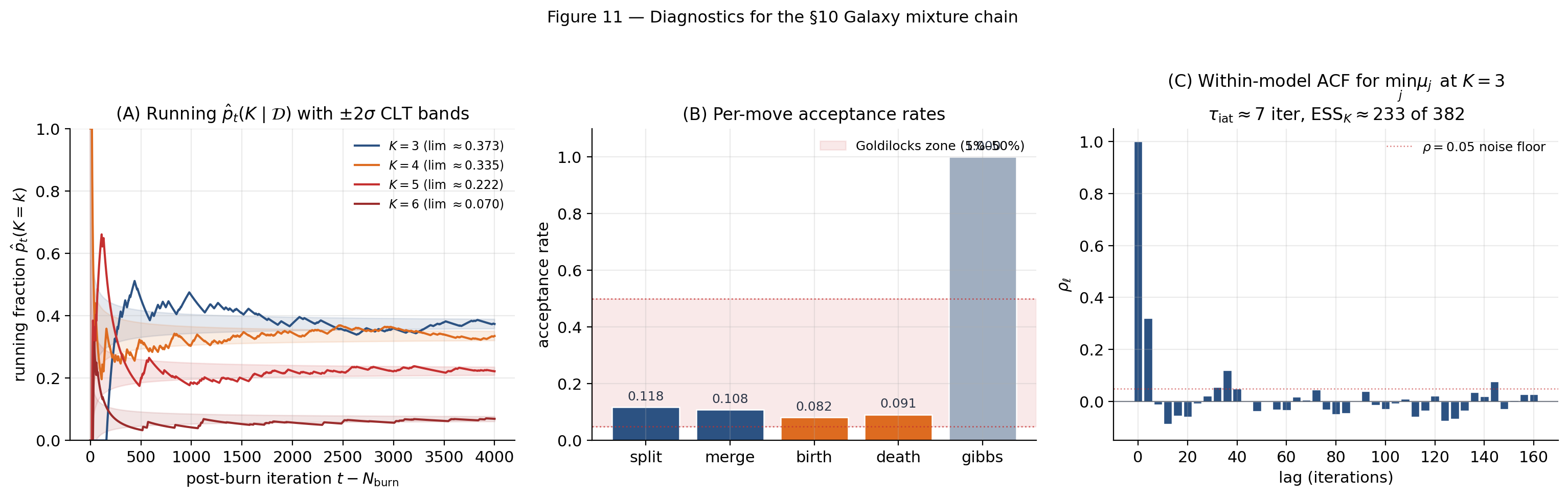
Extend the chain length to watch the running-fraction bands narrow as , the per-move bars stabilize, and the within- ACF tighten.
§12. Computational notes
§12 is the implementation-discipline section. It captures the engineering decisions that make §§9–10’s chains run inside the 60-second total budget and keep the on-site implementations responsive.
12.1 Buffer hoisting and the variable-length state vector
Trans-dimensional chains have a variable-length state vector: have length , which changes between iterations. The naive implementation calls np.concatenate, np.append, or list-to-array conversions inside the inner loop — each allocates a fresh array. At 5000 iterations, this adds – to total runtime.
The hoisting fix. Pre-allocate one fixed-size buffer per state component at the maximum dimension , plus an integer K_cur tracking the active prefix:
mu_buf = np.empty(K_MAX, dtype=np.float64)
s2_buf = np.empty(K_MAX, dtype=np.float64)
w_buf = np.empty(K_MAX, dtype=np.float64)
K_cur = 2Move functions perform in-place writes on the active prefix.
For §9 (variable selection): no hoisting needed — is fixed-length, is marginalized.
For §10 (Galaxy mixture): the notebook code uses np.concatenate in the move functions for clarity; the on-site live-implementation rewrite hoists into pre-allocated buffers. Notebook prioritizes pedagogical clarity; production prioritizes performance. Same RNG seed produces identical chain output either way.
12.2 slogdet over det — the rounding-loss case
The Jacobian determinant appears in every trans-dim acceptance ratio. For nontrivial bijections at moderate dimension, evaluating via det and then taking is numerically unsafe — long before the determinant itself underflows to zero, rounding error in the product accumulates and the final log is wrong by several digits.
Precision trajectory for the birth/death Jacobian at (float64 machine epsilon ; smallest normal ):
| Status | ||
|---|---|---|
| 1 | safe | |
| 10 | safe | |
| 30 | representable; precision becoming lossy when multiplied | |
| 50 | within ~ — det-then-log accumulates several digits of error | |
| 60 | still representable as a double, but products with other small acceptance-ratio terms round to 0 |
True float64 underflow on this particular Jacobian only happens at — well past any practically interesting setting. The numerical hazard at – is rounding loss, not underflow per se; the slogdet idiom (or summing elementary logs directly, §8.2) sidesteps both. The Richardson–Green split Jacobian has the same scaling problem at extreme weight splits.
The slogdet idiom. numpy.linalg.slogdet(J) returns directly:
sign_J, log_abs_det_J = np.linalg.slogdet(J_matrix)log_abs_det_J is well-defined for any in float64’s exponent range.
For closed-form Jacobians (§8, §10), we sum elementary logarithms directly — never construct the matrix. The slogdet idiom is for cases where the Jacobian has no closed form.
The rule. Never call numpy.linalg.det in the acceptance-ratio hot path.
12.3 Log-space acceptance-ratio composition
Every component of the master acceptance ratio is computed in log space and summed:
The acceptance criterion in log space:
if np.log(rng.uniform()) < log_alpha:
# acceptThis is preferable to if rng.uniform() < np.exp(log_alpha) because np.exp overflows for .
For logsumexp operations (mixture-likelihood and model-evidence normalizer): use scipy.special.logsumexp for numerical stability.
The rule. Every density evaluation that feeds into the acceptance ratio returns a log-density. np.exp is called at most once per iteration (at the comparison against log U).
12.4 The outer sampling loop is serial — vectorize the inner linear algebra only
MCMC is intrinsically serial in the iteration dimension. The chain cannot be vectorized across iterations.
Can vectorize: per-iteration linear algebra (proposal densities, log-likelihood, Jacobian, responsibility matrix). The §10 mixture likelihood uses a single broadcast (y[:, None] - mu[None, :]).
Cannot vectorize: outer iteration loop, move-type selection, acceptance decision, state update.
Multi-chain parallelism. Run independent chains in parallel via multiprocessing.Pool or joblib.Parallel. Each chain still serial; embarrassingly parallel across chains.
§13. Connections and limits
§13 closes the topic with five subsections placing RJ-MCMC in the formalML landscape and the broader Bayesian-computation ecosystem.
13.1 RJ-MCMC closes the specialized-sampler cluster
The T5 Bayesian Computation track has a four-topic specialized-sampler cluster:
- stochastic-gradient-mcmc (SGLD / SGHMC) — noise-injected gradient updates for big-data targets.
- riemann-manifold-hmc (RMHMC) — position-dependent Fisher information mass matrix for pathological fixed-dim targets.
- sequential-monte-carlo (SMC) — particle filters for sequential targets; annealed SMC samplers for evidence estimation.
reversible-jump-mcmc(this topic) — dimension-changing moves for sampling over a union of model spaces.
RJ-MCMC’s distinctive feature: it’s the only sampler in the cluster that genuinely changes dimension between iterations. After this topic, the specialized-sampler cluster is structurally complete.
13.2 RJ-MCMC vs. variational Bayes for model selection — the bias–variance trade-off
Variational Bayes for Model Selection (coming soon) and RJ-MCMC answer the same question — what is the posterior over models? — with different methods.
VBMS — deterministic, biased. Fit a variational approximation to each candidate posterior, compute the evidence lower bound , use ELBO as the model-comparison score.
Properties:
- Biased. By Jensen’s inequality, , with the inequality saturated only when matches the true posterior exactly. The gap , so the bias is downward — ELBO systematically under-estimates the log-evidence by the variational KL gap.
- Fast. One variational optimization per model.
- Limited variational family. The bias depends on the expressiveness of .
RJ-MCMC — stochastic, unbiased. Sample directly from ; time-fraction estimator for posterior model probabilities.
Properties:
- Unbiased asymptotically. Under standard MCMC regularity.
- MC error. .
- Tuning cost. Auxiliary-variable proposals and move-catalog rates need to be tuned per problem.
The practitioner’s choice. Use VBMS for fast scoping; use RJ-MCMC when exact posterior probabilities matter. Often complementary.
13.3 RJ-MCMC vs. SMC samplers
SMC samplers — per-model evidence, then aggregate. Run a separate SMC sampler for each ; combine via Bayes’ rule. See sequential-monte-carlo §8 for the unbiased log-evidence guarantee.
RJ-MCMC — joint trans-dim sampling. Single chain on the union space; time-fraction estimator.
When SMC wins: small (2–8 models), per-model evidence is the primary goal, models categorically different.
When RJ-MCMC wins: large ( models, for variable selection at ), models share structure (lattice or dimension stair), joint posterior over (model, parameters) is the goal.
Hybrid workflows use SMC for short-listing and RJ-MCMC for refinement.
13.4 Parametric only — Bayesian nonparametrics is a separate machine
RJ-MCMC’s state space is a countable union of finite-dimensional parameter spaces. Bayesian nonparametric models — DPM, infinite HMMs, IBP, GP, Beta process — have state spaces of unbounded dimension; their samplers exploit the prior process’s special structure (stick-breaking, marginal Pólya urn) and are not RJ-MCMC.
The line: if has a finite upper bound, use RJ-MCMC. If is unbounded and the prior process is what defines the model, use a Bayesian nonparametric sampler (Neal 2000’s Algorithm 8 is the canonical reference for Dirichlet process mixtures).
13.5 Tooling notes
PyMC. pm.Mixture handles fixed- mixtures via marginalization. PyMC does not directly support trans-dim sampling. Standard workflow for model selection: separate per- models plus pm.sample_smc.
NIMBLE. Supports explicit RJ-MCMC via nimbleMCMC. Recommended starting point for new RJ workflows.
BayesX. Older R package for structured additive regression with RJ-MCMC variable selection. Implements the Lang–Brezger (2004) Bayesian P-spline framework for selecting linear vs nonlinear covariates within a generalized additive model.
Stan. Does not support trans-dim sampling — fundamentally fixed-dim HMC. For variable selection in Stan, marginalize or run per- + WAIC/LOO.
JAGS / OpenBUGS. Historical RJ-MCMC support via plugin packages, no longer maintained for this feature.
Carlin–Chib product-space samplers. RJ-MCMC subsumes them. Still in some textbooks for pedagogical accessibility; not recommended in new code.
Recommendation. NIMBLE for explicit RJ; PyMC + per- SMC for marginalized mixtures; custom NumPy/JAX for educational purposes.
13.6 Further reading
The references below are listed in full in the bibliography; we annotate the key entry points here.
The foundational triad. Green (1995) is the original construction; Richardson & Green (1997) is the canonical mixture-order worked example; Hastie & Green (2012) is the modern review with consolidated notation. Start with these three for the historical and methodological arc.
Proposal-construction recipes. Brooks, Giudici & Roberts (2003) give centering and second-order matching techniques for high-acceptance trans-dim moves — the standard reference when the canonical move catalog underperforms.
Variable selection specifics. Kuo & Mallick (1998) for the indicator-variable formulation; Liang et al. (2008) for the hyper- marginal-likelihood; Scott & Berger (2010) for the multiplicity-correction model prior; O’Hara & Sillanpää (2009) for a comprehensive review of competing approaches.
Handbook and textbook. Brooks, Gelman, Jones & Meng (2011) is the canonical Handbook of Markov Chain Monte Carlo; the Green & Hastie chapter therein is the textbook entry point for RJ-MCMC. Gelman et al. (2013), Bayesian Data Analysis 3rd ed., is the standard graduate textbook with Chapter 11 covering model comparison.
Connections
- Sparse Bayesian priors §12.6 forward-pointed at RJ-MCMC as the discrete-spike-and-slab workhorse for the regime where continuous-relaxation Gibbs SSVS becomes prohibitive. §9 here discharges that pointer by extending the continuous spike-and-slab framework to the discrete case with full enumeration validation at p=8. sparse-bayesian-priors
- SMC and RJ-MCMC are sibling specialized samplers — SMC adaptively schedules an annealing path within fixed dimension and returns unbiased log-evidence; RJ-MCMC samples directly across dimensions. §13.3 places the two on the cost–quality Pareto frontier; hybrid workflows use SMC for short-listing model orders and RJ-MCMC for refinement. sequential-monte-carlo
- RMHMC adaptively shapes the kinetic energy via a position-dependent Fisher mass matrix for pathological fixed-dim targets; RJ-MCMC handles the orthogonal challenge of varying dimension. The two share the §13's three-question taxonomy that closes the T5 specialized-sampler cluster. riemann-manifold-hmc
- SG-MCMC scales fixed-dim Bayesian computation via subsampling at the cost of bias; RJ-MCMC handles trans-dimensional unbiased sampling at the cost of move-catalog hand-engineering. The §13.1 taxonomy positions both within the four-topic specialized-sampler cluster. stochastic-gradient-mcmc
- VBMS and RJ-MCMC answer the same question — what is the posterior over models — by opposite strategies: VBMS optimizes a deterministic ELBO with downward-biased evidence approximation, RJ-MCMC samples a stochastic unbiased chain. §13.2 compares the two; practitioners use VBMS for fast scoping and RJ-MCMC when exact posterior probabilities matter. variational-bayes-for-model-selection
References & Further Reading
- paper Reversible Jump Markov Chain Monte Carlo Computation and Bayesian Model Determination — Green (1995) Biometrika 82(4). The original RJ-MCMC paper; §§1.3, 4.3, 5.1, 5.3, 6.2, 7.2 build directly on Green's construction.
- paper Bayesian Model Choice via Markov Chain Monte Carlo Methods — Carlin & Chib (1995) JRSSB 57(3). The product-space sampler that RJ-MCMC subsumed; cited in §1.3.
- paper On Bayesian Analysis of Mixtures with an Unknown Number of Components — Richardson & Green (1997) JRSSB 59(4). The canonical mixture-order RJ-MCMC paper; §§8.2, 10.1, 10.2 implement their split/merge move catalog.
- paper Efficient Construction of Reversible Jump Markov Chain Monte Carlo Proposal Distributions — Brooks, Giudici & Roberts (2003) JRSSB 65(1). Centering and second-order matching recipes for high-acceptance trans-dim moves; cited in §8.4.
- paper Model Choice Using Reversible Jump Markov Chain Monte Carlo — Hastie & Green (2012) Statistica Neerlandica 66(3). Modern review of RJ-MCMC with consolidated notation.
- paper Practical Markov Chain Monte Carlo — Geyer (1992) Statistical Science 7(4). Standard reference for MCMC diagnostics; §11.3 uses the initial-positive-sequence estimator.
- paper Sequential Monte Carlo Samplers — Del Moral, Doucet & Jasra (2006) JRSSB 68(3). SMC samplers framework; cited in §13.3 as the trans-model alternative to RJ-MCMC.
- paper Density Estimation with Confidence Sets Exemplified by Superclusters and Voids in the Galaxies — Roeder (1990) JASA 85(411). Source of the n=82 Galaxy velocity dataset used throughout §10.
- book On Assessing Prior Distributions and Bayesian Regression Analysis with g-Prior Distributions — Zellner (1986) In Goel & Zellner (eds.), Bayesian Inference and Decision Techniques: Essays in Honor of Bruno de Finetti, North-Holland. The original g-prior.
- paper Variable Selection for Regression Models — Kuo & Mallick (1998) Sankhyā B 60(1). The indicator-variable formulation for Bayesian variable selection used in §9.
- paper Mixtures of g Priors for Bayesian Variable Selection — Liang, Paulo, Molina, Clyde & Berger (2008) JASA 103(481). Hyper-g refinement and closed-form marginal-likelihood formula (Eq. 5) used in §§2 and 9.
- paper A Review of Bayesian Variable Selection Methods: What, How and Which — O'Hara & Sillanpää (2009) Bayesian Analysis 4(1). Comprehensive review of Bayesian variable-selection priors.
- paper Bayes and Empirical-Bayes Multiplicity Adjustment in the Variable-Selection Problem — Scott & Berger (2010) Annals of Statistics 38(5). The multiplicity-correction model prior used throughout §§2 and 9.
- book Handbook of Markov Chain Monte Carlo — Brooks, Gelman, Jones & Meng (eds.) (2011) Chapman & Hall/CRC. Canonical handbook of modern MCMC.
- book Reversible Jump MCMC — Green & Hastie (2011) Chapter in Brooks et al. (eds.), Handbook of Markov Chain Monte Carlo. The handbook chapter on RJ-MCMC.
- book Introduction to Markov Chain Monte Carlo — Geyer (2011) Chapter in Brooks et al. (eds.), Handbook of Markov Chain Monte Carlo, 3–48. General MCMC framing.
- paper Markov Chain Sampling Methods for Dirichlet Process Mixture Models — Neal (2000) JCGS 9(2). Algorithm 8 reference for Bayesian nonparametric mixture sampling; cited in §13.4.
- book Bayesian Data Analysis — Gelman, Carlin, Stern, Dunson, Vehtari & Rubin (2013) 3rd ed., Chapman & Hall/CRC. Standard graduate textbook on Bayesian inference.
- paper Bayesian P-Splines — Lang & Brezger (2004) JCGS 13(1). The foundational paper for the structured-additive-regression RJ-MCMC framework that BayesX implements; cited in §13.5.