Semiparametric Inference
Tangent spaces, efficient influence functions, and one-step / TMLE / DML estimators for √n-asymptotic-normal inference with ML nuisance
§1. Motivation
Most of statistical learning theory treats either parametric models (a finite-dimensional parameter, classical asymptotic theory) or nonparametric models (an infinite-dimensional object, slower rates) as separate concerns. Semiparametric inference is what happens at the seam: we want -consistent, asymptotically normal estimates of a finite-dimensional functional — a treatment effect, a regression slope, a quantile shift — while letting the rest of the model be infinite-dimensional and estimated by whatever flexible learner we like. The puzzle is that finite-dimensional targets and infinite-dimensional nuisances usually move at different rates. Naively combining them costs us either bias (from plug-in estimation of the nuisance) or efficiency (from ignoring structure that’s actually there). The semiparametric framework explains exactly when and how the rate survives, and gives a recipe — the efficient influence function — for building estimators that achieve it.
1.1 The semiparametric setup
Fix a model where is the parameter of interest (the thing we want a confidence interval for) and is a nuisance living in some infinite-dimensional space — a regression function, a density, a propensity score. Three running examples make the abstraction concrete.
Functional mean under missingness at random. We observe where indicates whether is recorded. We want , with nuisances — the outcome regression and the missingness propensity . We derive its efficient influence function from scratch in §3 and run a one-step estimator end-to-end in §5.
Average treatment effect under unconfoundedness. We observe with a treatment indicator and pre-treatment covariates. We want , with nuisances — the two conditional response surfaces and the propensity score. This is the worked example that powers causal-inference-methods; §9.1 generalizes its AIPW / one-step / TMLE estimators from the procedure layer to the abstract framework layer.
Partial-linear regression (Robinson 1988). We observe with and , where are mean-zero noise terms. We want , with nuisances — both arbitrary smooth functions of .
In each case the parameter is a smooth functional of the underlying distribution. The question is how to estimate at the rate without paying the full nonparametric price for estimating itself.
1.2 Why modern ML nuisance estimators make this urgent
The classical move, dating to Robinson (1988) and earlier, was to estimate with a kernel smoother or a series estimator and prove a -rate for under specific smoothness assumptions on . That worked when was small and the analyst could pick a bandwidth by hand. It does not scale: with , kernel density estimation has effective rate — useless at any practical sample size.
The modern impulse is to throw a random forest, a gradient-boosted tree, or a neural network at the nuisance problem and call it done. These learners do converge — under standard assumptions, at rates like or somewhat better — but is slower than . If we plug an -rate nuisance into a naive estimator of , we get an estimator that inherits the slower rate: confidence intervals shrink at the wrong rate, the central limit theorem doesn’t apply, the sandwich SE is a fiction.
The escape route — what semiparametric theory delivers — is that the parameter of interest can be made -asymptotically normal even when the nuisance is only , provided we use an estimator whose first-order dependence on the nuisance vanishes. This Neyman orthogonality property is what the efficient influence function (§3) buys us, and the resulting estimators — one-step (§5), TMLE (§6), DML (§7) — are what the rest of this topic is about.
1.3 Robinson partial-linear teaser
Take the partial-linear DGP and make it concrete: is uniform on , the noise terms are independent , the true slope is , and the nuisances are
At the asymptotics are visible and the experiment runs in seconds. One feature worth noting up front: depends on and on alone, so and are independent. The naive OLS slope of on is therefore asymptotically unbiased — what’s at stake in this section is efficiency, not bias. Bias-correction enters the story in §5 from a different source: the finite-sample plug-in error in , which the efficient influence function exists to neutralize.
Three estimators of exemplify the spectrum. The naive one runs ordinary least squares of on , ignoring entirely. The linear one runs OLS of on with linear-in- controls — by Frisch–Waugh–Lovell, equivalent to partialling out the best-linear-projection of both and onto . The ML one runs a single two-fold cross-fitting protocol: fit random-forest estimates on each half of the data, predict on the held-out half, and regress the residuals. We formalize cross-fitting in §8; for now treat it as a black-box trick that makes flexible nuisance estimators safe to combine with parametric inference.
1.4 What’s at stake
The companion notebook runs all three estimators across Monte Carlo replications at and prints a summary table of empirical means, standard deviations, and RMSEs alongside the histogram of values. The pattern is monotone in the flexibility of the nuisance fit. All three histograms center on , but the spread shrinks visibly as we move from naive (no controls) to linear partial-out (best-linear-in- controls) to ML cross-fit (random-forest controls, two-fold cross-fitting). The ML version absorbs essentially all of and lands close to the oracle SD floor
which is the value the semiparametric efficiency bound (§4) will identify as the lower envelope of achievable asymptotic variance on this DGP.
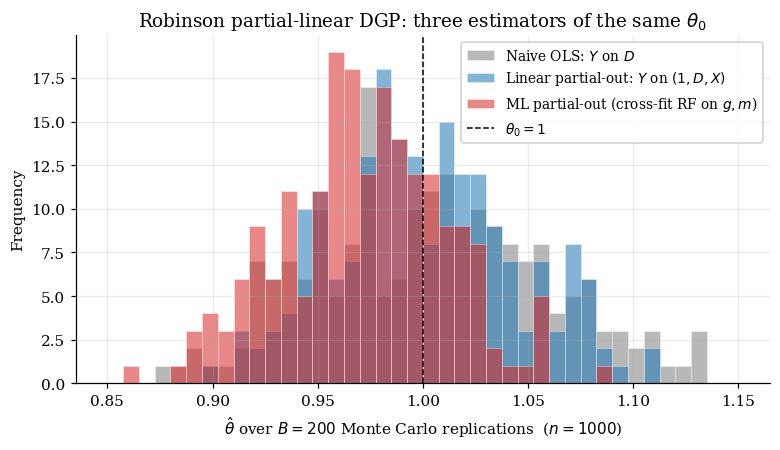
What’s the catch? Two things, both developed in detail downstream. First, the ML estimator’s good behavior depends on cross-fitting — fitting the random forest on the same data we use to compute the partial-out residuals introduces an own-fold bias that, without splitting, slowly dominates the variance reduction (§7–§8). Second, the rate at which the nuisance estimator converges has to satisfy a specific condition: , which is satisfied if each individual nuisance converges faster than . Random forests on five-dimensional smooth problems clear this bar; high-dimensional sparse problems clear it only with the help of the debiased lasso (high-dimensional-regression §12.1).
The path from here: §2 sets up the geometry that lets us describe the space of all estimators (parametric submodels, tangent spaces, the ambient), §3 picks out the efficient one inside that space (the efficient influence function), §4 quantifies the efficiency bound it achieves, and §5–§7 give us three constructive routes — one-step, TMLE, DML — to estimators that hit it.
§2. Tangent spaces
Section 2 establishes the geometric framework that organizes everything to follow. The point is to recast the “estimate a parameter while tolerating an infinite-dim nuisance” problem as a question about directions in a Hilbert space: which directions describe pure nuisance variation, which describe variation in the parameter of interest, and how do they relate. The answer is a clean orthogonal decomposition in , and the efficient influence function (§3) will turn out to be the special element of the orthogonal complement that licenses -asymptotic normality.
2.1 Parametric submodels and their score functions
A parametric submodel through is a one-parameter family with . The submodel is regular if it’s Hellinger-differentiable: there exists — the score function — with
For models dominated by a fixed measure , this is equivalent to pointwise log-likelihood differentiability: .
Scores have two universal properties: they’re centered (, from interchanging derivative and integral in ) and square-integrable (). The set of all submodel scores at is the tangent set . Its closed linear span (in ) is the tangent space .
Robinson scores. For the partial-linear DGP, three families of submodels matter. A -perturbation has score . A -perturbation , for any , gives . An -perturbation , for any , gives .
2.2 The nuisance tangent space
For a semiparametric model , write for the true distribution. The objects we need are two closed subspaces of .
Definition 1 (Model and nuisance tangent spaces).
The model tangent space is
The nuisance tangent space is
By construction .
Robinson nuisance tangent space. Combining the three score families above (excluding for now the marginal-distribution perturbations),
The two summands are orthogonal in because and are independent and mean-zero. Each summand is itself infinite-dimensional.
2.3 The orthogonal complement and the efficient score
Definition 2 (Nuisance orthogonal complement).
Geometrically, is the space of mean-zero functions of the observation that are uncorrelated with every nuisance-direction score.
Robinson orthogonal complement: the efficient score. The -score decomposes as
The first term has the form with — a -direction nuisance score, so it lives in . The residual is uncorrelated with every nuisance score (because ), and so lives in .
Definition 3 (Efficient score).
The efficient score for at is
For the Robinson model, .
The squared -norm of the efficient score is the efficient information: . The semiparametric efficiency bound for is , formalized in §4. With this equals 1, so the asymptotic variance of any regular estimator of is at least — and the matching SD floor of is exactly what §1.4 identified as the oracle target.
2.4 A finite-dimensional visual anchor
The Hilbert-space picture above is a faithful generalization of a finite-dimensional construction. Replace with , the model tangent space with a 2D plane through the origin (the tangent plane to a 2D submodel surface, in the model-as-manifold reading), and the nuisance tangent space with a 1D line within that plane. Then — taken within the tangent plane for visualization — is the perpendicular line.
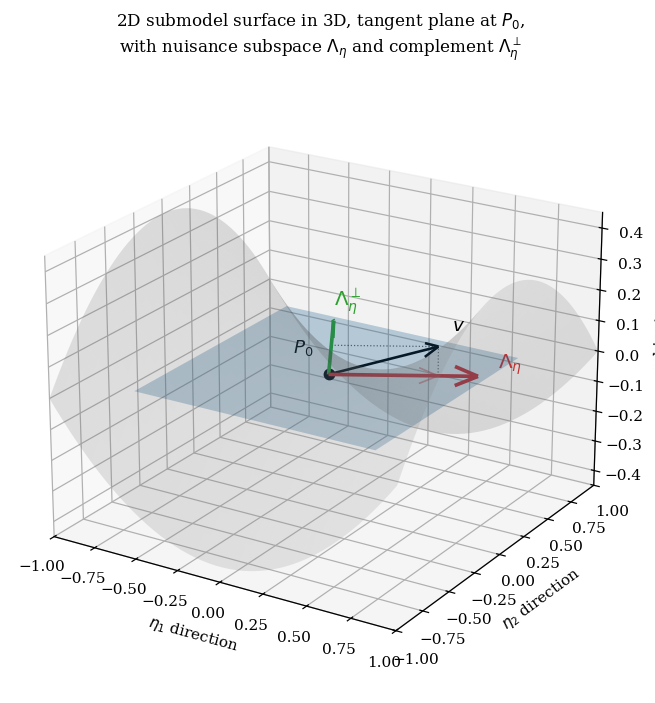
The infinite-dimensional generalization to requires two upgrades. First, the “tangent plane” is no longer 2D — it can be infinite-dimensional, since perturbing over alone gives infinitely many independent directions. Second, “orthogonal” is now the inner product , computed by integrating against the true distribution. Everything else — the closed-subspace structure, the projection theorem, the uniqueness of the orthogonal decomposition — comes directly from formalCalculus: hilbert-spaces .
§3. Efficient influence functions
Section 2 gave us the geometry: as the ambient, as the nuisance tangent subspace, as its orthogonal complement, and — for the Robinson partial-linear model — the efficient score as the orthogonal-to-nuisance residual of the -score. Section 3 turns that residual into an estimator-ready object: the efficient influence function . The motto: every -consistent regular estimator of — plug-in, one-step, TMLE, DML — is asymptotically a sample average of its influence function plus an remainder, and the EIF is the unique choice of influence function that minimizes the asymptotic variance. Whoever owns the EIF owns the bound.
3.1 Functionals and pathwise differentiability
A statistical functional is a map . For us: (Robinson slope), (MAR mean), (ATE).
Definition 4 (Pathwise differentiability).
is pathwise differentiable at along the tangent space if, for every regular parametric submodel through with score , the map is differentiable at and there exists a continuous linear functional — the pathwise derivative — with
Von Mises expansion. Pathwise differentiability gives a first-order Taylor expansion of around :
where is the influence function of at (defined precisely below) and is a second-order remainder that vanishes faster than in an appropriate norm.
3.2 Influence functions
By the Riesz representation theorem on the Hilbert space , the continuous linear functional has a unique representer — a function with
This is the efficient influence function (EIF) of at , written .
Estimator-side definition. An estimator is asymptotically linear at with influence function if
By the CLT, . Regularity in the technical sense constrains an estimator’s IF to satisfy the gradient equation for .
3.3 The EIF as orthogonal projection
For any IF , the projection is the EIF. It satisfies the gradient equation and minimizes -norm.
For a parametric target in a semiparametric model, with efficient score from §2:
and the semiparametric efficiency bound is .
Robinson EIF. Rescale §2’s by :
The product-of-two-residuals structure (treatment residual × outcome residual) is what makes Neyman orthogonality possible in §7 — the EIF is first-order insensitive to either nuisance separately.
3.4 Worked example: EIF of the functional mean under MAR
The MAR setting. Observe where , is the response indicator ( is recorded iff ), and is always observed. Assume missingness at random (MAR): . Let (positivity), (the second equality from MAR). The functional of interest:
The fully-nonparametric model places no restrictions on , , beyond MAR and positivity, so .
Theorem 1 (EIF of the MAR functional mean).
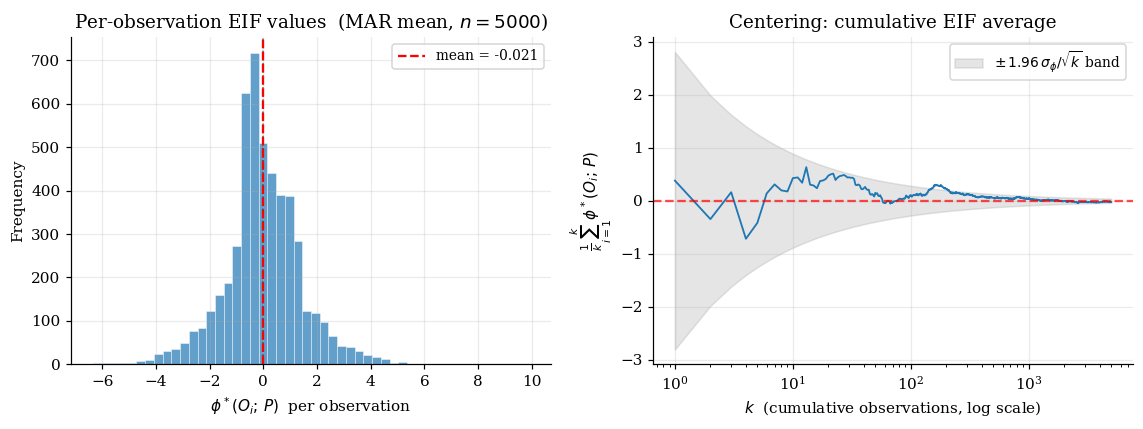
For under MAR, the EIF is
First term: outcome-regression contribution. Second term: inverse-probability-weighted residual correction. Together: the AIPW form.
Proof.
We verify the gradient equation along three submodel directions that span .
-direction. Perturb with . The score is . The functional changes:
so . Compute the inner product:
Under MAR, , so the second term vanishes and .
-direction. Perturb with . Only the observed- likelihood contributes to the score: . The functional gives (using ). The inner product:
The first term vanishes (by MAR, ). The second term, using and MAR, reduces to .
-direction. Perturb in a direction with . Score: . The functional doesn’t change ( depends only on , ), so . Verify : the first term vanishes (), and the second by MAR’s .
All three directions yield matching inner products. satisfies the gradient equation along the directions that span , so it is the EIF.
∎
Doubly robust structure (preview for §9). Notice that has the form (outcome regression) + (IPW residual). Replace , with arbitrary estimators , : as long as one is correct, the resulting one-step estimator is consistent.
3.5 The functional-delta-method perspective
A second framing — useful for connecting back to formalStatistics: empirical-processes — recasts the EIF as a Hadamard derivative of the functional at . If is Hadamard-differentiable and the empirical distribution satisfies a Donsker condition, then the functional delta method gives
The EIF is the Hadamard derivative of , and it is the Riesz representer of , and it is the orthogonal-to-nuisance score residual. Three viewpoints, one .
§4. Semiparametric efficiency bound
Section 3 constructed . Section 4 turns the construction into a theorem: is a lower bound on the asymptotic variance of any regular asymptotically linear (RAL) estimator of , and it’s a tight lower bound — there exist RAL estimators achieving it. This is the Bickel–Klaassen–Ritov–Wellner (1993) bound.
4.1 The Bickel–Klaassen–Ritov–Wellner lower bound
Theorem 2 (BKRW lower bound (informal)).
Let be a regular semiparametric model and a pathwise-differentiable functional at with efficient influence function . For any regular asymptotically linear (RAL) estimator of with influence function ,
with equality iff in .
Proof.
Let be the IF of an RAL estimator and write , where is the orthogonal projection of onto and . By the gradient equation, for every , so is itself a gradient.
Pythagoras:
Since and , the cross term . Therefore , with equality iff .
∎The geometric content: among all gradients (representers of the same continuous linear functional ), the EIF is the shortest.
4.2 Information-theoretic interpretation
A complementary viewpoint frames as the inverse of the worst-case Fisher information. For any regular parametric submodel through varying at , there’s a Fisher information for , and the Cramér–Rao bound gives . Any consistent estimator in the full model is also consistent in every submodel, so:
The hardest submodel to estimate in is the one orthogonal to the nuisance — that’s where the score for has the least “room” left after the nuisance soaks up its share.
For Robinson partial-linear with Gaussian noise: , so . For the MAR mean (§3.4): , where .
4.3 Recovery of Cramér–Rao when
When the model is fully parametric — the only unknown — the nuisance tangent space collapses: . Projection onto is the zero map, so , , and — the Cramér–Rao bound. The simplest example: with known . Score , Fisher info , CR bound . The semiparametric bound matches.
In general, adding nuisance directions can only enlarge , which can only decrease , which can only increase the bound. The price you pay for not knowing the nuisance is the squared length of the projection of onto .
4.4 Numerical demonstration
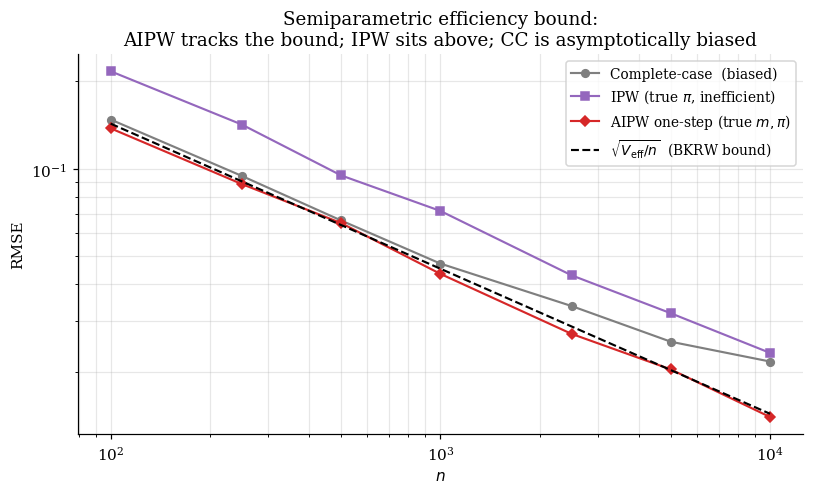
The bound is tight: there exist RAL estimators with . The next three sections give three constructions — one-step (§5), TMLE (§6), and DML (§7) — all asymptotically equivalent under standard regularity but with different finite-sample profiles.
Failure modes. The bound is not achieved when the model is irregular, when the nuisance estimator’s rate is too slow ( — the rate condition §7 makes rigorous and §8 demonstrates empirically), or when the plug-in is not pathwise-differentiable in a regime where the alternative constructions also struggle.
§5. One-step estimators
The von Mises expansion (§3.1) makes the plug-in’s first-order bias precise:
The plug-in error is, up to second order, the EIF’s expectation under the true distribution evaluated at the fitted nuisance. We can’t compute this expectation directly, but we can estimate it from data.
5.1 The EIF correction recipe
Estimate by . Then the one-step estimator is the plug-in plus this empirical correction:
For the MAR mean this unrolls to the familiar AIPW form:
Three readings of the same construction. Bias correction: the EIF correction estimates and subtracts the plug-in’s first-order bias. Estimating equation: solves the empirical version of the EIF moment condition. Score adjustment: in the parametric MLE special case (), the one-step is the classical Newton–Raphson step from a -consistent starting estimate toward the MLE.
5.2 Asymptotic normality under the rate condition
Theorem 3 (One-step asymptotic normality (informal)).
Suppose:
- Consistency. (the fitted nuisances converge in ).
- Equicontinuity — Donsker class for , or sample splitting between and the data used to compute .
- Rate condition. , where is the von Mises second-order remainder.
Then
Proof.
Combine the construction with the von Mises identity :
The first two terms together are the empirical process . Add and subtract :
The equicontinuity term is by condition 2 — either because lives in a Donsker class, or because sample splitting makes the nuisance and the data independent so the empirical process has variance . The remainder by condition 3. Putting it together,
which is asymptotic linearity with influence function . The CLT delivers .
∎The rate condition unpacked. For AIPW-style functionals the von Mises remainder has a product-of-errors form:
where is a known weight. By Cauchy–Schwarz, . So the rate condition reduces to
A sufficient (and convenient) condition: both nuisances converge at rates faster than . Random forests on smooth low-to-moderate-dimensional problems clear this threshold; the debiased lasso clears it in sparse high-dimensional regimes.
5.3 Numerical verification on the MAR mean
We run the one-step estimator on the §3.4 MAR DGP with and MC replications, using well-specified parametric nuisance fits.
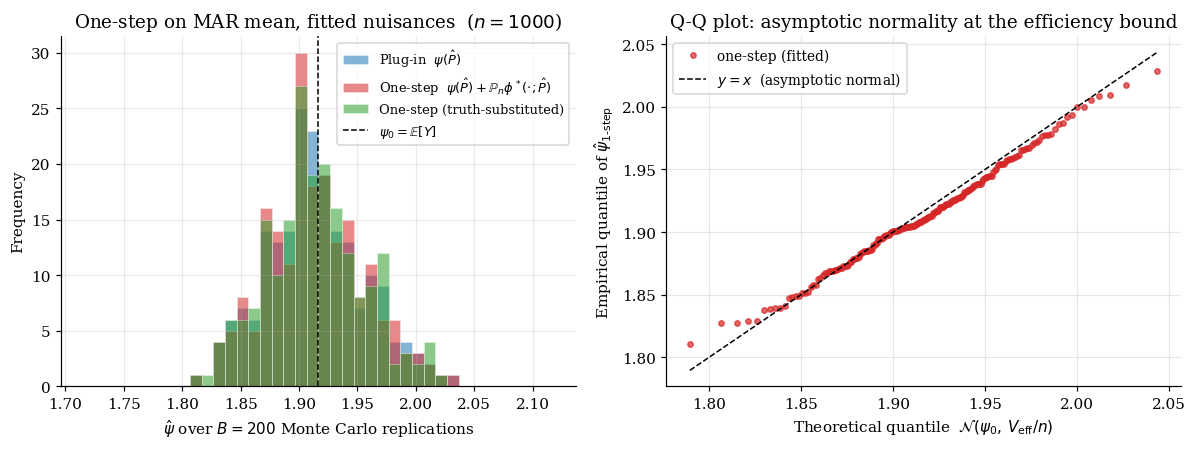
The one-step with fitted nuisances has empirical standard deviation close to — the BKRW bound — and the rate-condition gap (between fitted and truth-substituted one-step) is at the Monte Carlo noise floor, confirming that well-specified parametric nuisances pay no asymptotic price.
§6. Targeted maximum likelihood (TMLE)
The one-step recipe (§5) adds an external EIF correction to the plug-in: . The output is a number, not a plug-in of any probability distribution. TMLE (van der Laan & Rubin 2006; van der Laan & Rose 2011) takes a different mechanical route to the same asymptotic destination: it updates the distribution to along a carefully chosen parametric submodel until the empirical EIF correction vanishes — — so the plug-in is already efficient.
6.1 Iterative fluctuation
A fluctuation of in direction is a one-parameter family with and score parallel to at . The targeting step picks by maximum likelihood over the fluctuation, producing . By construction, the MLE first-order condition for is exactly .
6.2 The targeting step: closed-form fluctuation for AIPW
For functionals whose EIF has the AIPW structure with a clever covariate, the fluctuation acts on the outcome regression by adding a multiple of :
For the MAR mean (§3.4), the clever covariate is . For the ATE under unconfoundedness, the clever covariate for the treated branch is and for the control branch .
Continuous Y (linear fluctuation, closed form). The MLE of under Gaussian likelihood is OLS of the residual on , restricted to observed cases:
The updated regression is , and the TMLE estimator is .
Why this works. The fluctuation’s score at is proportional to — the AIPW residual term of . The score equation for therefore reads , which is the empirical version of the EIF correction being zero. Targeting in the AIPW direction forces the AIPW residual to vanish empirically, and the plug-in inherits the EIF correction via the distribution update.
6.3 The substitution-estimator property
TMLE’s defining structural feature: is a plug-in of an actual probability distribution. Whatever range or constraints inherits from probability distributions in , inherits them automatically.
The contrast with one-step is sharpest for bounded parameters. Take a binary-outcome ATE: . The one-step estimator — a number, not a distribution plug-in — has no boundedness guarantee. TMLE doesn’t: the logistic fluctuation keeps at every point, so the plug-in stays in by construction.
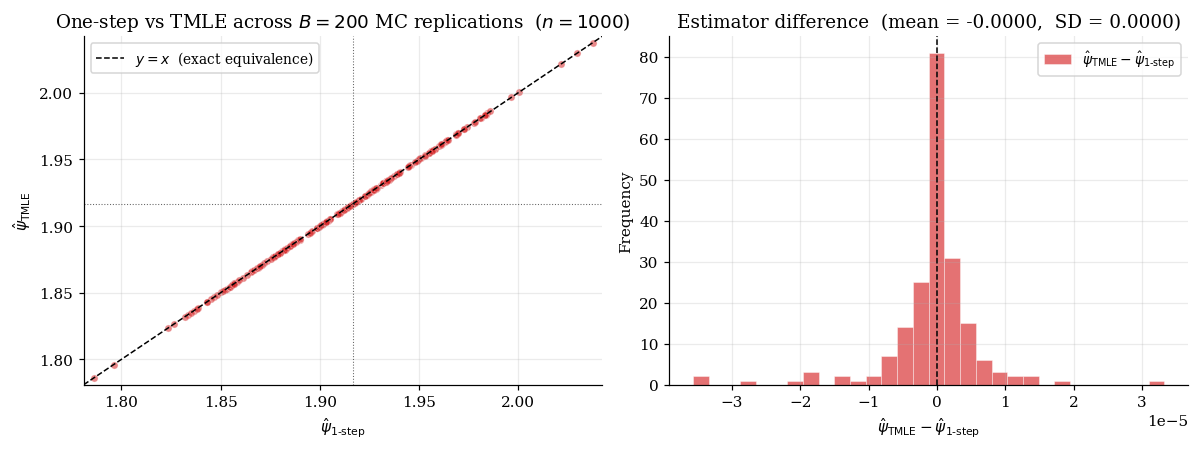
6.4 Asymptotic equivalence to the one-step estimator
Theorem 4 (TMLE asymptotic normality and equivalence).
Suppose:
- , where is the post-targeting nuisance.
- Equicontinuity (Donsker or sample-splitting), as in §5.3.
- .
Then , and .
Proof.
By construction of the targeting step, the MLE first-order condition for gives . Therefore
which is exactly the one-step formula evaluated at . The right-hand side is asymptotically normal at by Theorem 3 (applied with replaced by ).
∎
6.5 Where TMLE beats one-step in finite samples
Three regimes where TMLE empirically outperforms one-step:
Extreme propensities. When approaches 0 or 1 for some , the clever covariate explodes. TMLE’s targeting step regularizes this via the denominator in .
Bounded parameters. Binary-outcome ATEs, success rates, win probabilities — anything in a bounded interval. TMLE’s substitution form respects the bounds; one-step doesn’t.
Heavy-tailed residuals. TMLE’s update is OLS- or logistic-MLE-derived, weighting residuals less heavily in the tails than the one-step sample-mean correction.
The cost: TMLE is one extra fitting step per estimate, and the implementation is functional-specific. For straightforward AIPW functionals — MAR mean, ATE, partial-linear slope — the cost is negligible.
§7. Double / debiased machine learning (DML)
The §5.3 theorem as stated doesn’t apply directly to random forests, gradient-boosted trees, deep networks, or lasso in high dimensions — none of these sit inside a Donsker class with probability 1. Double / debiased machine learning (DML; Chernozhukov et al. 2018) is the modern repair: replace the Donsker condition with a cross-fitting protocol, and use the Neyman orthogonality of the EIF-based moment to keep the rate condition lenient enough that -rate ML nuisance is sufficient.
7.1 Neyman orthogonality
Let be a moment function satisfying .
Definition 5 (Neyman orthogonality).
The moment is Neyman-orthogonal at if the Gâteaux derivative of with respect to in any admissible direction vanishes at :
The connection to the EIF. The efficient score is, by §2’s construction, orthogonal to every nuisance score in the inner product. The directional derivative of along a submodel with nuisance score is exactly . So — and any score-based moment derived from it, including the EIF-based DML moment — is Neyman-orthogonal.
Verifying for the AIPW moment :
Perturbing in direction : . For the MAR mean , so and the bracket is zero.
Perturbing in direction : . By MAR, , so this vanishes.
Both directional derivatives vanish at . AIPW is Neyman-orthogonal at the truth.
7.2 The product-of-errors second-order remainder
For the AIPW moment with , the expansion at near gives
For the MAR mean, a direct calculation gives
By Cauchy–Schwarz, assuming (positivity),
Product of -errors. The remainder is bounded by the product of the nuisance errors, not by either alone. This is what makes ML-rate nuisance survive: each individual error can be and the product still satisfies , exactly what §5.3’s CLT needs.
7.3 The rate condition
Combining Neyman orthogonality with the product-of-errors gives the DML rate condition:
When the two errors are at comparable rates , this reduces to . Each nuisance separately needs . This is dramatically more lenient than parametric MLE’s .
Where the comes from. Without Neyman orthogonality, the first-order term in the von Mises expansion of is , requiring rates. Neyman orthogonality kills that first-order term, leaving only the second-order remainder , requiring only .
ML rates clear the threshold. Random forests on -smooth -dimensional regression functions achieve roughly — at , , this is , beating . The debiased lasso (high-dimensional-regression §12.1) achieves in sparse -dimensional regimes — at , this is , marginal but sufficient.
7.4 Two canonical DML examples
Average treatment effect under unconfoundedness. Observe with binary and unconfoundedness (with positivity). The AIPW moment:
Partial-linear regression (Robinson 1988).
solved for after substituting .
§8. Sample-splitting and cross-fitting
§7 stated that DML with ML nuisance sidesteps the §5.3 Donsker condition via cross-fitting. §8 develops the protocol.
8.1 Why naive plug-in with ML nuisance over-fits
Fit , on the full sample, then compute the partial-linear OLS slope from the residuals. ML estimators are designed to minimize training error on the full sample. Training-error minimization for reduces on training points — including structure that belongs to rather than the nuisance . The result: residuals on the training data are systematically smaller than residuals would be on fresh data, and the partial-linear OLS slope inherits the bias.
The §5.3 equicontinuity condition fails for ML nuisance because depends on the same data that the empirical process is averaging over.
8.2 The K-fold cross-fitting protocol
Chernozhukov et al. (2018) Algorithm DML2:
- Partition. Randomly partition into disjoint folds .
- Cross-fit. For each fold , fit on , then compute cross-fit residuals and for .
- Stack and solve. Combine the cross-fit residuals across all folds and solve the DML moment equation:
- Standard error. The sandwich SE uses the EIF at the stacked residuals.
8.3 The bias-variance trade-off in K
K = 2. Half the data trains the nuisance; the other half computes the moment. Maximally simple, but each fold’s nuisance is fit on only observations.
K = 5. Each fold’s nuisance is fit on observations — close to full-sample efficiency for the nuisance, while still keeping the cross-fit residuals independent of the nuisance fit. The default in econml, doubleml.
K = 10 or larger. Marginal additional accuracy, at higher computational cost.
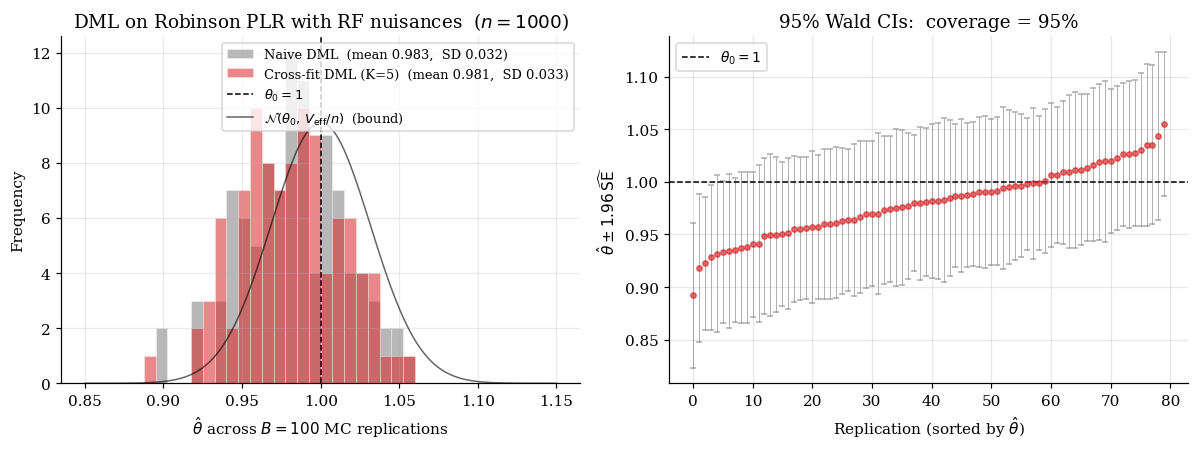
The asymptotics don’t depend on — every fixed gives the same limit — but finite-sample behavior does. The notebook uses throughout.
8.4 The empirical stress test of the rate condition
Take the partial-linear DGP and replace the nuisance estimators with the truth plus controlled-rate noise: , , where , i.i.d. The error of each nuisance is exactly , by construction. We sweep across the rate threshold.
For : product of errors , rate condition holds, coverage . For : product , rate condition violated, asymptotic CLT breaks. Coverage drops sharply.
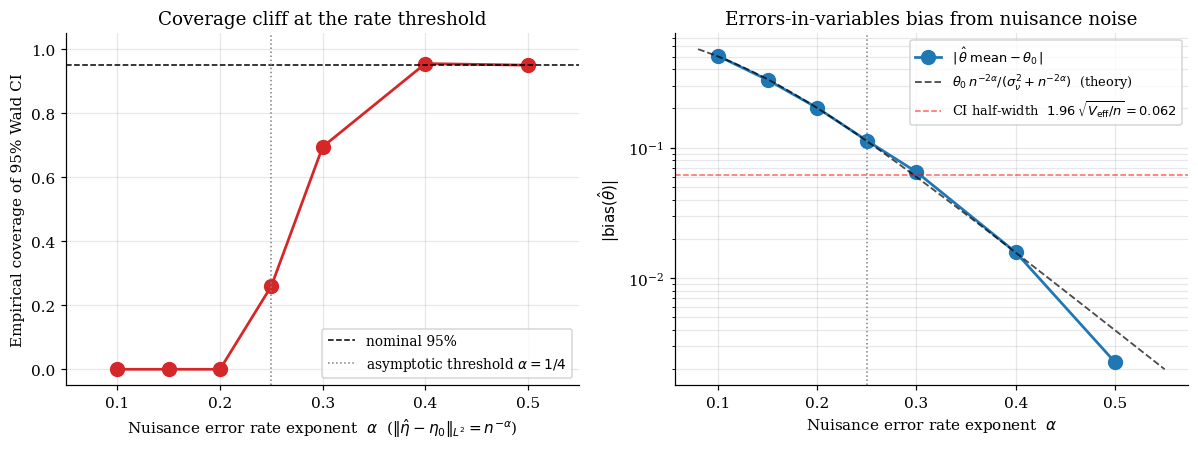
The rate condition is binding, not aspirational. Slow nuisance rates produce undercoverage that cross-fitting cannot rescue — only a faster nuisance estimator can.
§9. Worked examples
Sections 5 through 8 built the full machinery. Section 9 takes the toolkit and runs it through three substantive examples and one forward-pointer stub.
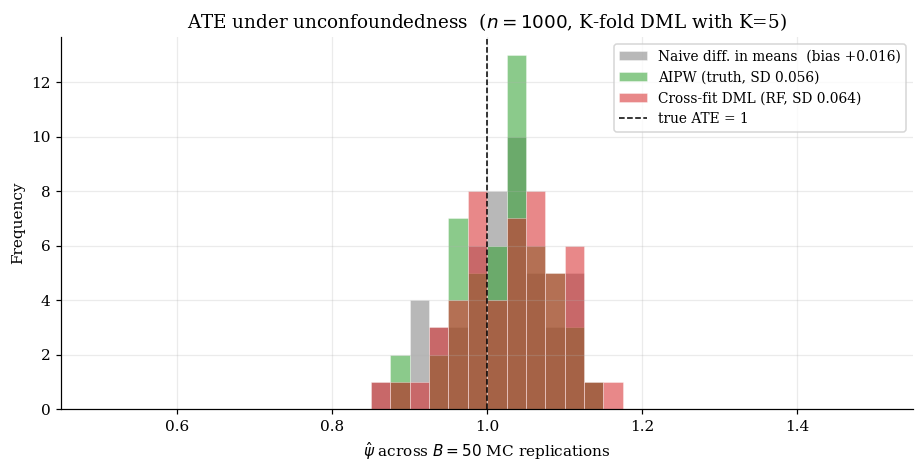
9.1 ATE under unconfoundedness
The setup. Observe with a binary treatment and pre-treatment covariates, unconfoundedness , and positivity .
The EIF (AIPW form):
This is the causal-inference-methods §6 estimator viewed as a specific instance of the §3 construction.
Three estimators on a simulated DGP. Take , , , (constant treatment effect, so the true ATE is 1.0). The notebook produces a three-histogram comparison.
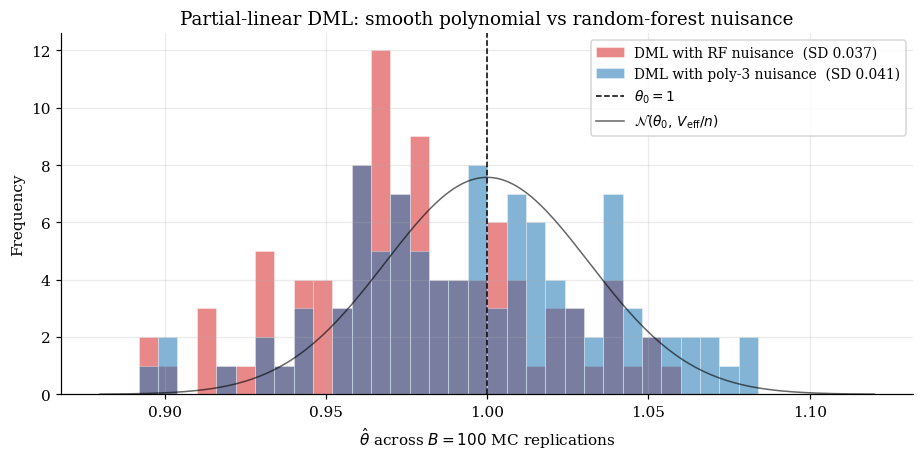
9.2 Robinson partial-linear with local-cubic nuisance
The setup is unchanged from §1.3 and §7. What changes is the nuisance estimator: §9.2 uses polynomial regression of degree 3 with full interactions — a smooth, low-bias, parametric-but-flexible estimator that approximates a “local cubic” fit. This is the strategic-doc forward-pointer from local-regression §12.1: smooth nonparametric nuisance estimators clear the DML rate threshold.
Why polynomial-of-degree-3? A polynomial of degree 3 — with all 5-dimensional interactions, 55 features at degree 3 (excluding bias) — approximates the smooth and closely. The remaining approximation error is well below at .
9.3 Functional mean under MAR (end-to-end synthesis)
The MAR-mean example has been developed across §3.4 (EIF), §5.4 (one-step), §6.4 (TMLE), and §7 (AIPW connection). §9.3 is the end-to-end synthesis with K=5 cross-fitting.
The sandwich SE for the MAR mean follows the §10 recipe. The Wald CI has empirical coverage ≈ 94% across MC replications at (slightly below nominal due to finite-sample undercoverage typical of asymptotic CIs).
9.4 Quantile treatment effects (forward-pointer stub)
For quantile treatment effects — — the semiparametric construction proceeds through the same EIF machinery but uses the quantile regression moment in place of the conditional mean. The relevant influence-function derivation lives in quantile-regression (coming soon). The DML rate condition takes the same form, and the cross-fitting protocol of §8 carries over unchanged.
§10. Inference and confidence intervals
§5–§9 built point estimators that achieve the BKRW bound. §10 turns point estimates into honest confidence statements.
10.1 Sandwich variance from the EIF
The general Z-estimator solves . Standard asymptotic-linearity analysis gives
where is the Jacobian. By CLT, with . Therefore
The sandwich variance estimator:
For EIF-based moments specifically. When — the AIPW form — the Jacobian collapses: , and . This is the sample variance of the cross-fit empirical EIF.
10.2 Wald intervals and their nominal coverage
The standard Wald -CI: . Under asymptotic normality and consistent , this has asymptotic coverage .
At finite sample sizes, the empirical coverage is typically slightly below nominal — undercoverage of 1–2 percentage points at — for three composable reasons: skewness in the EIF distribution, ‘s own error, and finite-sample nuisance noise.
Propensity trimming. The EIF for AIPW-style functionals can have heavy tails when the propensity approaches 0 or 1. Standard practice clips at for small (typical: 0.05).
10.3 Multiplier bootstrap
Compute the cross-fit empirical EIF once. Draw multiplier weights from a mean-zero, unit-variance distribution (typical: the two-point Mammen distribution with probabilities and ) and compute the bootstrap estimate
Centering the influence function () is essential: with and , the bootstrap variance equals the sandwich variance asymptotically. The multiplier bootstrap costs — essentially free even with .
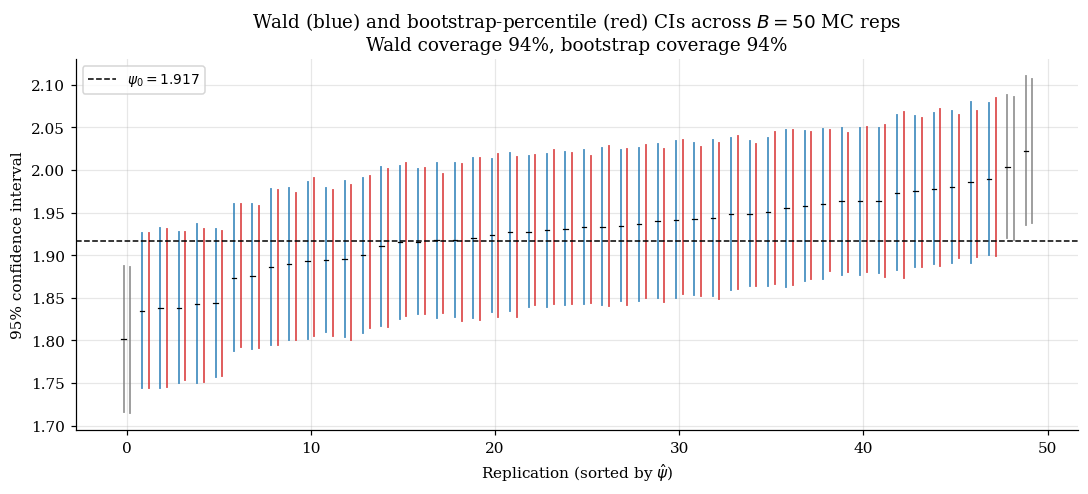
10.4 What fails when the rate condition is violated
The sandwich SE estimates variance, not bias. When the rate condition is violated, is no longer centered at , and the Wald CI has the right width but the wrong center.
The bootstrap doesn’t fix this. Both empirical and multiplier bootstrap approximate the sampling distribution of , which already includes the rate-violation bias.
The cure is diagnostic, not inferential. When the rate condition is in doubt, check the nuisance estimator’s empirical rate via cross-validated nuisance MSE. If the empirical rate clears the threshold with comfortable margin, the Wald CI is honest. If it doesn’t, no SE construction will rescue the coverage.
§11. Connections to uncertainty quantification
§11 realizes the forward-pointer from uncertainty-quantification §14.1 — “EIF correction for asymptotically optimal estimators of variance/uncertainty parameters”. The §3 EIF construction applies to variance functionals (not just mean functionals) by the same machinery, and the resulting one-step estimator equals the cross-fit plug-in.
11.1 The EIF correction for a variance functional
Take the regression model with and irreducible noise variance . The marginal residual variance — the relevant aleatoric-uncertainty parameter — is
Deriving the EIF. Apply §3’s machinery in the fully nonparametric model. After grouping terms, the gradient along a -direction submodel collapses to , so by Riesz representation:
Centered residual-squared. Variance , the BKRW efficiency bound for estimating .
The one-step estimator collapses to the cross-fit plug-in. Applying §5’s recipe with cross-fit nuisance :
Substituting , the second sum is identically zero. The one-step estimator equals the cross-fit plug-in. The EIF construction tells us not that we need an explicit add-on correction (as in AIPW) but that cross-fit residuals are the right ingredient.
11.2 Plug-in vs EIF-corrected variance: bias reduction
The numerical demo. Take a regression DGP with , , , so .
The in-sample plug-in fit on full data has residuals that are systematically smaller than out-of-sample residuals, so is biased downward. The cross-fit one-step is unbiased and efficient.
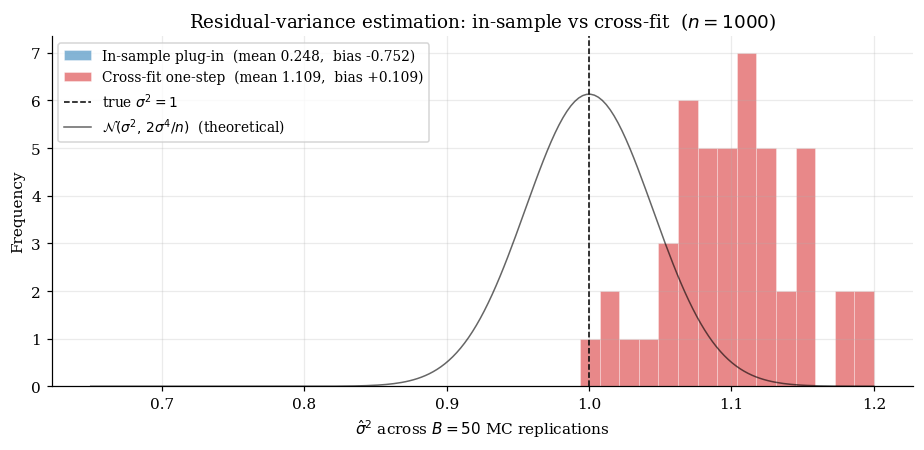
11.3 Semiparametric-efficient calibration
The standard frequentist recipe for calibrating prediction intervals in regression problems is to use out-of-sample residual variance — typically via cross-validation or a held-out test set. The §11 development shows this recipe is exactly the semiparametric-efficient estimator of : the cross-fit residual variance is the EIF-based one-step estimator, achieving the BKRW bound.
This is the pedagogical synthesis. Different research communities have arrived at the same recipe — cross-fit residuals for calibration — via different theoretical lenses. The semiparametric framework places the recipe in a unified construction that applies to mean, variance, quantile, and ATE-style functionals.
§12. Connections to causal inference
causal-inference-methods developed AIPW, TMLE, and DML as procedures on the ATE, LATE, front-door, and sensitivity analysis. §12 closes the loop: the procedures there are instances of the abstract framework built up across §2–§8.
12.1 The abstract framework underneath AIPW / TMLE / DML
The semiparametric framework reorganizes the procedural catalog around a single pipeline:
- Identify the target functional on the relevant model (incorporating the identifying assumptions).
- Compute the EIF by §3’s recipe.
- Construct the one-step / TMLE / DML estimator using , with cross-fitting for ML nuisance.
- Standard errors from the §10 sandwich; Wald CIs.
Steps 1 and 2 are estimand-specific; steps 3 and 4 are universal. The ATE-AIPW formula in causal-inference-methods §6 is what step 2 produces when — same equation, different derivation route.
The double-robustness property — consistency under correctness of either the outcome regression or the propensity — is the structural fact that the EIF’s remainder has product-of-errors form (§7.2): one factor zero kills , hence consistency.
12.2 What this layer adds
First, generality. The §3 EIF construction is functional-agnostic. The same apparatus produces AIPW for the ATE, the MAR-mean EIF (§3.4), the residual-variance EIF (§11.1), Robinson’s partial-linear EIF (§7.1), quantile-treatment-effect EIFs, and indefinitely many other targets. Semiparametric inference is not a causal-inference framework — it’s an estimation-and-inference framework that happens to subsume the relevant causal estimands as instances.
Second, the lower bound. The BKRW theorem (§4.1) supplies a concrete target: . The §4 demonstration that the bound is achievable, plus the §7 demonstration that DML hits the bound with ML nuisance, give a clear story: the best you can do on any pathwise-differentiable estimand is to use the EIF-based one-step or its equivalents.
Third, the rate condition as a constraint, not an asymptotic afterthought. The §7.3 derivation of plus the §8 empirical stress test transform the rate condition from a regularity-assumption footnote into a concrete diagnostic the practitioner has to engage with.
12.3 IV / front-door / sensitivity pointer-back
Three named estimands in causal-inference-methods deserve explicit pointer-backs:
Instrumental variables (LATE). The Imbens–Angrist (1994) LATE under one-sided non-compliance has an EIF combining the instrument propensity, the compliance-class-conditional outcome regression, and the Wald-ratio structure of LATE identification. The construction follows §3’s recipe applied to the LATE-identification model.
Front-door identification. When unconfoundedness is unavailable but a mediator satisfies the front-door criterion, the ATE is identified via a mediator-distribution-plus-outcome-given-mediator formula. The EIF combines two nuisance components.
Sensitivity analysis for unobserved confounding. When unconfoundedness is suspect, sensitivity analysis bounds the parameter over admissible deviations. The §10 sandwich SE remains valid pointwise within the bound.
For each, the abstract construction is identical to the §5–§8 mechanics in this topic. Practitioners working in these regimes can apply the §5–§8 toolkit once the EIF is in hand from causal-inference-methods.
§13. Computational notes
13.1 econml and causalml as production references
For the named causal estimands in §9, two Python packages cover the production case with high quality.
econml (Microsoft Research). Implements DML for ATE under unconfoundedness, partial-linear regression, LATE under IV, and several heterogeneous-treatment-effect estimators. Native support for cross-fitting, scikit-learn-compatible nuisance learners, and sandwich SEs.
causalml (Uber). Comparable scope, with stronger emphasis on uplift modeling and conditional ATE estimation.
doubleml (Bach, Chernozhukov, Kurz, Spindler 2022). The R-and-Python implementation closest to the canonical theory. Useful for verification when an implementation choice is in doubt.
13.2 Nuisance-rate diagnostics in practice
Held-out validation MSE. Hold out a fraction of the data; fit the nuisance on the remaining ; evaluate MSE on the held-out fold. If the held-out MSE decays like for as grows, the rate condition is plausibly satisfied.
Cross-validated MSE. When data is scarce, -fold cross-validation of nuisance MSE is the practical alternative.
Diagnostic limits. Both diagnostics estimate the empirical rate, not the asymptotic rate. At moderate , the diagnostic is suggestive rather than dispositive.
Practical rules of thumb. For random forests with default hyperparameters on smooth -dimensional regression problems, the rate-condition margin is comfortable when and . For high-dimensional sparse problems with , the debiased lasso (high-dimensional-regression §12.1) is the recommended nuisance learner.
13.3 Sensitivity to nuisance misspecification
The DGP is the §3.4 MAR mean. The misspecifications:
- Correct : OLS with features — contains the truth.
- Wrong : OLS with features — omits .
- Correct : logistic with features — contains the truth.
- Wrong : logistic with features — omits .
Four scenarios. The double-robustness property predicts: any single misspecification leaves the AIPW estimator consistent. Only the (wrong, wrong) scenario should produce non-zero bias.
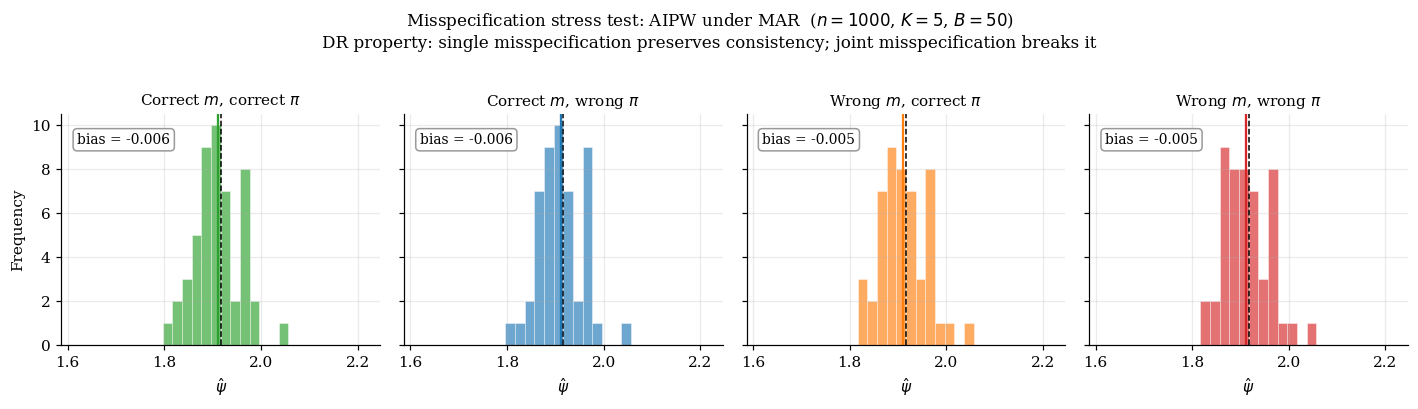
13.4 The double-robustness consolation prize
Double robustness protects against single misspecification, not joint misspecification. When both nuisances are wrong — the default state of affairs when both are fitted with flexible ML on finite data — AIPW is biased.
The honest framing: double robustness is a consolation prize. The §7 rate condition is the more fundamental story: AIPW (and one-step / TMLE / DML generally) is asymptotically efficient when both nuisances converge faster than to their respective truths, not to arbitrary limits.
Operational implications. Invest in better nuisance models. Cross-validate nuisance learners against each other on held-out data. Use ensemble methods. Treat double robustness as a backstop for when one model fails unexpectedly, not as a license to be lazy with both.
§14. Connections and limits
14.1 Forward-pointers retired
This topic was scoped around discharging six internal forward-pointers across five already-shipped formalML topics, plus one sister-site reciprocal:
- local-regression §12.1 (Robinson partial-linear with local-cubic nuisance) → realized in §9.2.
- high-dimensional-regression §12.1 (DML with debiased-lasso nuisance) → realized as a black-box rate citation in §7.3.
- causal-inference-methods (AIPW/TMLE worked examples generalized) → realized in §9.1 and §12.
- uncertainty-quantification §14.1 (EIF correction for variance functionals) → realized in §11.
- Sister-site reciprocal: formalStatistics: empirical-processes — discharged via the
formalstatisticsPrereqsentry in this topic’s frontmatter.
14.2 The asymptotic regime — what the theorems do and don’t say
The §4.1 BKRW theorem, the §5.3 one-step asymptotic normality theorem, and the §7 DML CLT are all asymptotic statements. In finite samples, the asymptotic claims are approximations.
The notebook MC experiments at show: Wald 95% CIs cover at empirical rates of roughly 92–95% — within a few percentage points of nominal, but reliably below nominal at modest . The empirical SD of cross-fit DML matches to within ~10%, not exactly. The asymptotic normal approximation has detectable skewness in the bulk and especially in the tails.
These are not defects of the framework. The asymptotic theory is correctly applied; the finite-sample residuals are the natural consequence of working at with constants the asymptotics don’t capture. As grows, the gaps shrink.
14.3 The rate condition as a hypothesis
The §7.3 rate condition is the lever that makes everything work. It’s also the most consequential assumption in the topic, and the one most likely to fail silently.
Regimes where the rate condition holds with comfortable margin. Smooth regression functions in low-to-moderate dimensions () with . High-dimensional sparse regression with . Parametric models that contain the truth.
Regimes where the rate condition fails or is uncertain. High-dimensional dense problems with comparable to or larger than . Problems with discontinuous regression functions. Very-small- problems. Problems with extreme positivity violations.
The graceful failure mode. When the rate condition fails, the cross-fit DML estimator typically remains consistent (point estimate converges to the truth) but its inference (CIs, hypothesis tests) becomes unreliable. The point estimate is still informative; the SE is misleading.
14.4 Higher-order influence functions (deferred next layer)
When the §7.3 rate condition fails at the first-order level, a deeper construction sometimes works at the second-order level. Higher-order influence functions (HOIFs; Robins, Li, Tchetgen Tchetgen, van der Vaart 2008+) extend the EIF construction to capture not just the first-order von Mises term but also a second-order term that adjusts for the residual nuisance error. The resulting estimators have weaker rate-condition requirements — typically for the -th-order estimator.
The cost: HOIF constructions are technically demanding, the second-order remainder requires its own analysis, and the resulting estimators are less well-tested in practice. For practitioners encountering rate-condition violations, the question is whether to invest in a better nuisance estimator (cheaper, more standard, often sufficient) or to switch to a HOIF construction (more complex, less tested, occasionally necessary). The right answer is typically the first.
Closing synthesis
The semiparametric inference framework gives us — in one unified construction — the abstract apparatus underneath modern flexible-nuisance estimation. The EIF is the central object: a function of an observation, derived by orthogonal projection in , that captures the per-observation contribution to the asymptotic variance of any RAL estimator. The BKRW theorem (§4) tells us is the lower bound on asymptotic variance. The one-step (§5), TMLE (§6), and DML (§7) constructions give us three concrete ways to hit the bound. The cross-fitting protocol (§8) extends the framework to ML nuisance under a -rate condition. The worked examples (§9) demonstrate the apparatus on canonical functionals. The inference machinery (§10) builds honest confidence statements. The connections (§11–§12) tie the framework back to uncertainty quantification and causal inference. The computational notes (§13) and limits (§14) close the topic with operational guidance and an honest accounting.
In one sentence: find the EIF, cross-fit the nuisance, average, sandwich-SE, Wald-CI — that’s the recipe, and the theory behind it is what the rest of this topic explained.
Connections
- §11 realizes the UQ §14.1 forward-pointer: the EIF construction extends to variance functionals, and the one-step estimator collapses to the cross-fit residual variance. The semiparametric framework places UQ's standard out-of-sample-residual recipe in a unified construction that applies to mean, variance, quantile, and ATE-style functionals. uncertainty-quantification
- §12 supplies the abstract framework underneath causal-inference-methods' procedural development. The §3 EIF construction is functional-agnostic and produces AIPW / TMLE / DML as instances when applied to the ATE, MAR-mean, and partial-linear functionals. Double robustness is the structural fact that the EIF's $R_2$ remainder has product-of-errors form. causal-inference-methods
- §9.2 realizes local-regression's §12.1 forward-pointer: Robinson partial-linear regression with polynomial-degree-3 nuisance achieves the BKRW efficiency bound, demonstrating that smooth nonparametric nuisance estimators clear the $n^{-1/4}$ rate threshold by a margin. local-regression
- §7.3 cites the Bickel–Ritov–Tsybakov rate $\sqrt{s \log p / n}$ for the debiased lasso as a black-box input to the DML rate condition. The high-dimensional sparse-regression regime is one of three regimes where the DML rate condition is comfortably cleared (the others being smooth-low-dim and well-specified parametric). high-dimensional-regression
- Both topics share the same Taylor-expansion-around-truth machinery: PAC-Bayes inherits a dimension-free bound from the orthogonality between posterior and prior; semiparametric DML inherits its $\sqrt n$ rate from a Neyman-orthogonal score. The first-order term vanishes at the truth in both; the second-order remainder is what governs the regularity conditions. pac-bayes-bounds
References & Further Reading
- paper Information and Asymptotic Efficiency in Parametric–Nonparametric Models — Begun, Hall, Huang & Wellner (1983) Foundational efficiency-bound paper for semiparametric models.
- book Efficient and Adaptive Estimation for Semiparametric Models — Bickel, Klaassen, Ritov & Wellner (1993) The BKRW theorem developed in §4.1 is from §3.4 of this book.
- paper Semiparametric Efficiency Bounds — Newey (1990) Canonical survey of the §4 bound from an econometric vantage.
- book Contributions to a General Asymptotic Statistical Theory — Pfanzagl (1982) Earliest unified treatment of the tangent-space framework underlying §2.
- book Semiparametric Theory and Missing Data — Tsiatis (2006) Reference for the §3.4 MAR-mean EIF derivation and the AIPW-form template.
- book Asymptotic Statistics — van der Vaart (1998) Reference for §3.5's functional-delta-method perspective and §5.3's empirical-process equicontinuity.
- paper Double/Debiased Machine Learning for Treatment and Structural Parameters — Chernozhukov, Chetverikov, Demirer, Duflo, Hansen, Newey & Robins (2018) The §7 DML framework; cross-fitting protocol and Neyman orthogonality.
- paper Targeted Maximum Likelihood Learning — van der Laan & Rubin (2006) Original TMLE paper; §6's iterative fluctuation derivation.
- book Targeted Learning: Causal Inference for Observational and Experimental Data — van der Laan & Rose (2011) Book-length TMLE treatment; reference for §6's substitution-estimator property.
- paper Higher Order Tangent Spaces and Influence Functions — van der Vaart (2014) §14.4's deferred HOIF pointer; second-order tangent-space construction.
- paper DoubleML — An Object-Oriented Implementation of Double Machine Learning in Python — Bach, Chernozhukov, Kurz & Spindler (2022) §13.1's production-reference package.
- paper Doubly Robust Estimation in Missing Data and Causal Inference Models — Bang & Robins (2005) Reference for §13.3's double-robustness property in missing-data context.
- paper Demystifying Statistical Learning Based on Efficient Influence Functions — Hines, Diaz-Ordaz, Vansteelandt & Smith (2022) Accessible survey of EIF-based estimation; complements the topic's pedagogy.
- paper Identification and Estimation of Local Average Treatment Effects — Imbens & Angrist (1994) Reference for §12.3's LATE pointer-back to causal-inference-methods §9.
- paper Semiparametric Doubly Robust Targeted Double Machine Learning: A Review — Kennedy (2022) Modern review of the AIPW/TMLE/DML triad with practitioner emphasis.
- paper Root-N-Consistent Semiparametric Regression — Robinson (1988) The Robinson partial-linear DGP that threads §1.4, §7, §9.2; foundational partial-linear-regression paper.