Selective Inference
Inference after looking at the data — conditional pivots, debiased estimators, knockoffs, online FDR
1. Motivation
Most of statistical theory implicitly assumes the hypothesis was chosen before the data arrived. We pick a coefficient to test, we pick a model to fit, we pick an estimand to report — and then we look at the sample. The neat duality between point estimates, confidence intervals, and p-values that powers Stat 101 holds because that ordering holds: the hypothesis is fixed, the data is random, and the sampling distribution of the test statistic is a well-defined object.
Modern ML practice violates that ordering constantly. We fit a lasso on a thousand candidate features, look at the active set, and report confidence intervals on the selected coefficients. We screen a million SNPs against a phenotype, take the top hundred, and ask whether they’re real. We sit on top of an A/B-testing platform that runs ten thousand experiments a quarter and want to know how many of last quarter’s “winners” are actually wins. In each case the hypothesis was chosen by looking at the data, and the textbook guarantees — coverage, size, Type-I error, FWER, FDR — silently break.
Selective inference is the body of techniques that puts the guarantees back. It does so by being explicit about what was selected and how, and by re-deriving the sampling distribution conditional on the selection event itself. That single move — condition on what the selection procedure returned — turns out to support three otherwise quite different bodies of work: post-selection conditional inference (Lee, Sun, Sun & Taylor 2016) and debiased high-dimensional inference (Zhang & Zhang 2014; van de Geer, Bühlmann, Ritov & Dezeure 2014; Javanmard & Montanari 2014); finite-sample false-discovery control via knockoffs (Barber & Candès 2015; Candès, Fan, Janson & Lv 2018); and online FDR control via wealth processes (Foster & Stine 2008; Javanmard & Montanari 2018; Ramdas, Yang, Wainwright & Jordan 2018). This topic walks through all three.
1.1 The garden of forking p-values
The cleanest way to see the problem is to watch a familiar procedure fail on a familiar problem. Take a low-dimensional regression — observations, features, an identity design covariance, and a true coefficient vector that is zero everywhere except on its first three entries, where it equals . Standard regression theory says: fit OLS on all 20 features, get , and the 95% Wald interval covers with probability for each . That works. It works because the model — all twenty features — was fixed before the data arrived.
Now run the modern version. Fit the lasso with cross-validated , look at the active set , refit OLS on the selected features only, and report the Wald CIs from that fit. This is the workflow practitioners actually use — sklearn even ships it as a one-liner. The active set picks out, on average, around five to eight features per replicate: typically the three real signals plus several noise features that happened to correlate with .
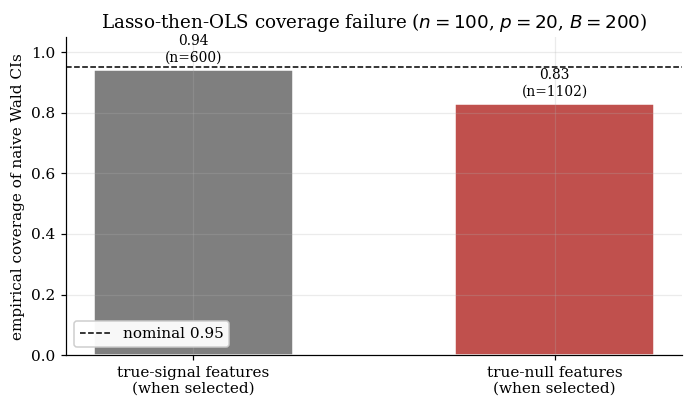
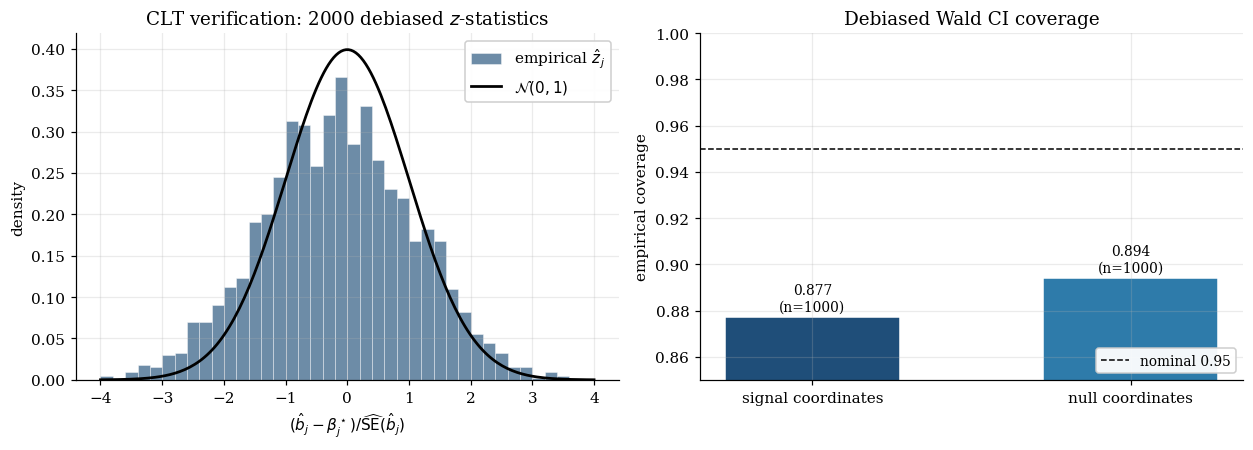
The CIs from this workflow look like normal CIs. They’re symmetric around the OLS-on- point estimate, they have the usual structure, and they print out alongside a column labeled “95% CI” that nothing in the software flags as suspect. Their empirical coverage, however, isn’t . Over Monte Carlo replicates of this DGP, the signal-feature CIs cover their target with empirical probability — close to nominal, because the signal-to-noise ratio is high enough that the OLS-on- estimate on a strong signal is approximately unbiased even after selection. But the null-feature CIs (features 4 through 20, when one of them sneaks into the active set on a particular replicate) cover their target — which is — with empirical probability . The aggregate effect: a coverage rate that lands at on this toy.
The structural reason is selection bias on null features. The lasso selects feature precisely when is large; the OLS-on- coefficient on then inherits the conditional distribution of given that this quantity was large. For null features this conditional distribution is bimodal — concentrated away from zero on both sides — which is fundamentally different from the unimodal Gaussian the naive CI assumes. The CI is centered on a noisy estimate that’s never near zero conditional on selection, and on a non-trivial fraction of replicates it misses zero. Figure 1.1 quantifies the aggregate effect on the running toy.
This is the loss-of-coverage phenomenon that selective inference is designed to repair. The fix that conditional inference will deliver in §4 is structural: replace the unconditional sampling distribution of with its conditional distribution given the selection event , and the resulting CI achieves nominal coverage. We’ll prove that in §4. For now, §1 just establishes the failure.
1.2 Three families of fixes
Selective inference is not a single procedure; it’s a programme. The procedures the topic covers cluster into three families, distinguished by what they condition on and what guarantee they deliver:
Conditional / post-selection inference (§§2–5). Condition on the realized selection event itself — for the lasso, the active-set and sign pattern . The Lee–Sun–Sun–Taylor pivot delivers exactly nominal conditional coverage for any linear functional of , including the partial OLS coefficients in the selected model. The debiased lasso of Zhang–Zhang / van de Geer et al. / Javanmard–Montanari delivers asymptotically nominal coverage in without conditioning, by computing a bias-corrected estimator whose CLT survives the selection bias.
Knockoff filters (§§7–9). Don’t condition; instead, construct fake “knockoff” features designed to be exchangeable with the real features under any null. Use this exchangeability to build a statistic per feature whose null distribution is sign-flip symmetric, then threshold on that distribution to control FDR. The finite-sample FDR guarantee holds at all , with no asymptotic approximation.
Online FDR (§§10–11). When tests arrive in a stream — A/B platforms, continuous deployment, sequential genomics screens — neither BH nor conditional inference work directly because future tests aren’t yet visible. The α-investing / LORD / SAFFRON family solves this by tracking an α-wealth process: each test deducts from the wealth, each rejection deposits a payout, and a supermartingale argument bounds the running FDR by at every stopping time.
The three families are not redundant. Each addresses a different practical bottleneck — small-but-non-trivial with a selection procedure (post-selection), with honest CIs needed (debiased), large- feature selection with finite-sample FDR (knockoffs), and streaming tests (online). The reader should leave §1 with one map and three distinct destinations; the §-by-§ exposition fills in each route.
1.3 What “selective inference” means precisely
The phrase admits several meanings in the literature; we’ll be specific. By “selective inference” we mean inference about a data-dependent estimand — a parameter, functional, or hypothesis that is itself a function of the sample. This is the unifying definition that covers all three families. In conditional post-selection inference, the estimand is the partial-OLS coefficient in the model selected by the lasso, and that model depends on . In debiased high-dimensional inference, the estimand is a fixed coefficient, but the bias correction depends on a lasso fit. In the knockoff filter, the estimand is the set of features satisfying , and the report (which features get flagged) depends on the data. In online FDR, the estimand is a sequence of null hypotheses, and the test schedule depends on the wealth process, which depends on the prior tests’ outcomes.
The parallel to semiparametric inference is structural and worth naming explicitly: semiparametrics asks for -valid inference about a low-dimensional functional in the presence of an infinite-dimensional nuisance estimated from data; selective inference asks for valid inference about a functional whose identity depends on data. Both topics live in the seam between “parameter is fixed, data is random” and “parameter and data are both random in a coupled way,” and both depend on a careful accounting of what randomness the inference is conditioning on. Where semiparametrics needs orthogonality of the influence function with respect to the nuisance score, selective inference needs an explicit description of the selection event whose probability the inference conditions on.
1.4 Roadmap and prerequisites
The topic proceeds in three arcs. §§2–5 cover post-selection and debiased inference: the LSST framework (§2), the polyhedral selection event for the lasso (§3), the truncated-Gaussian pivot (§4), and the debiased lasso (§5). §§6–9 cover knockoffs: the BH/Storey baseline (§6), the fixed-X knockoff filter and its supermartingale FDR proof (§7), the model-X generalization (§8), and the practical knockoff-construction linear algebra (§9). §§10–11 cover online FDR: the procedures (§10) and the wealth-process supermartingale proofs (§11). §12 lands the topic in ML applications, §13 collects computational notes, and §14 maps the connections to nearby topics and the limits of the framework.
The recommended prerequisites are high-dimensional regression for the lasso KKT conditions and debiased-lasso machinery, concentration inequalities for the martingale tail bounds that drive the online-FDR proofs, and ideally semiparametric inference for the conceptual frame on data-dependent estimands. From the sister site, formalStatistics’s Multiple Testing and False Discovery is the substrate selective inference generalizes — this topic discharges three forward-pointers from that page in a single ship.
2. The selection-event framework
§1 showed what goes wrong when we condition on the data twice — once implicitly through the selection procedure, once explicitly through the inference step — without accounting for the first conditioning. §2 sets up the framework that fixes it. The fix is conceptually simple: replace the unconditional sampling distribution of the test statistic with its distribution conditional on the selection event. The work of the rest of the topic is to make that conditional distribution computable.
This section sets the framework abstractly. §3 instantiates it on the lasso, §4 derives the truncated-Gaussian pivot that delivers the exact conditional CDF, §5 handles the high-dimensional case where exact conditioning is not available.
2.1 Hypotheses chosen by the data
Fix a sample space (think for the regression setting). A selection procedure is a measurable map
where is a (countable, for simplicity) set of outcomes — model indices, active sets, threshold rules, anything we might run on the data before reporting a result. For the lasso at a fixed regularization , — the active set and sign pattern. For forward stepwise truncated at steps, is the ordered sequence of selected features. For the BH procedure at level , is the set of rejected hypotheses.
Each outcome partitions the sample space into two pieces: the selection event
and its complement. Conditioning on means restricting attention to the realizations that would have produced this particular selection outcome. The marginal sampling distribution of — the one that classical inference uses — averages over all selection outcomes; the conditional sampling distribution averages only over realizations that hit . The two coincide when is constant (no selection — classical inference) and diverge otherwise. The size of the gap is what makes selective inference necessary.
A useful mental picture: is partitioned into selection cells ; the procedure stamps every observed realization with the label of whichever cell it lands in. Classical inference treats the whole sample space as the support of . Selective inference restricts to the cell we landed in and asks what the test statistic does inside that cell.
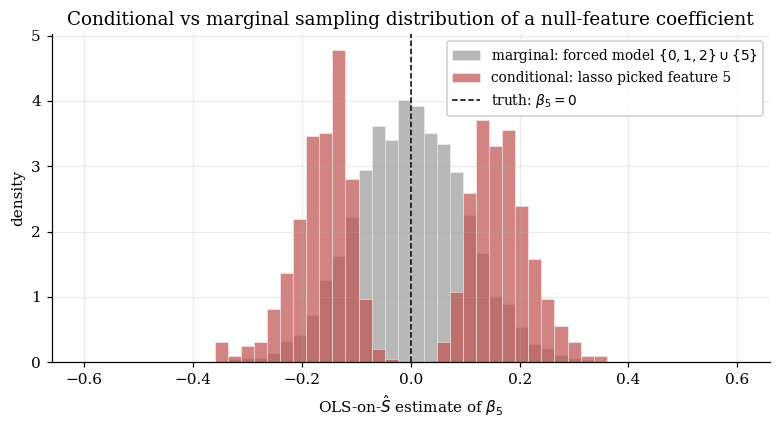
Numerical demonstration. On the §1 low-dim toy, fix the lasso regularization at a deterministic (rather than CV — the conditional analysis needs a deterministic selection rule) and run replicates. For each replicate, fit the lasso and record whether feature (a true null) is selected. On the of replicates where feature 5 is in , compute the OLS-on- estimate of its coefficient. Compare to a marginal reference: the OLS estimate of when the model is forced to include from the start, regardless of what the lasso does.
The result, locked at notebook execution:
-
Conditional sample (lasso selected feature 5): out of 4000. Sample mean . Sample std . Crucially, only 0.1% of conditional samples are in ; the distribution is bimodal, with of mass above and below .
-
Marginal sample (forced inclusion): . Sample mean . Sample std . Unimodal, peaked at zero.
The two distributions have similar means (both near zero, by symmetry) but qualitatively different shapes. The marginal distribution is the classical Gaussian that Wald intervals are built around. The conditional distribution is bimodal — concentrated away from zero on both sides — because the selection event requires to have been large, which carves out the mass near zero.
This is the structural content of selective inference, isolated in one picture. Classical inference uses the marginal distribution as its null reference and correctly assigns small p-values to its tail. Applied naively to the conditional sample — which is what the §1 lasso-then-OLS workflow does — it computes p-values against the wrong reference distribution. Values that are entirely typical of the conditional distribution under the null get assigned small p-values, and CIs centered on those values miss the truth on a non-trivial fraction of replicates.
The fix that §§3–4 will develop is to compute against the right reference: the truncated-Gaussian distribution that exactly characterizes the conditional sampling distribution under the polyhedral selection event of §3.
The interactive below lets you experiment with the lasso’s selection event directly. Drag to watch the active set and sign pattern change; the polyhedral selection event (developed in §3) is rendered as a 2-D slice of the sample space around a fixed realization.
2.2 Conditional vs marginal: what “post-selection valid” means
Fix a null hypothesis that may itself depend on the selection outcome — for the lasso, “the partial OLS coefficient for feature in the selected model equals zero,” which only makes sense once is known. We say a test of has classical Type-I error at level if
where the probability is over the marginal distribution of . We say the test is selectively valid at level (post-selection valid, in the LSST terminology) if
The selective version is a strictly stronger requirement than the classical one: it controls Type-I error inside every selection cell, not just on average across cells. The corresponding notion for confidence intervals is conditional coverage: for every , where is the target parameter associated with outcome and is the interval reported under outcome .
A weaker target available in the literature is False Coverage Rate control (Benjamini & Yekutieli 2005): an average-coverage guarantee across multiple selected parameters, integrating over the selection randomness. FCR is a strict relaxation of conditional coverage and is the right target in some applied settings; for this topic we focus on the conditional-coverage standard because it’s what the LSST pivot delivers and what justifies the file-drawer claim — “the CI you report is at nominal coverage given that this is the CI you happened to report.”
The file-drawer interpretation is worth dwelling on. Selective validity is the statement that an analyst who repeatedly performs the same selection-then-inference workflow, and discards (puts in the file drawer) realizations that didn’t produce the same selection outcome, would observe nominal coverage on the surviving inferences. That is the guarantee a downstream consumer of the report actually needs.
2.3 Generic post-selection p-values via conditional distributions
The construction of a selective p-value is one display equation. Pick a test statistic (for now, generic; later, a linear contrast ). Under the null, the selective p-value for the realization given selection outcome is
Under the null, by construction, is uniformly distributed on — this is just the standard PIT applied to the conditional CDF of given the selection event. Marginally, is also uniform, because uniformity given for every averages to uniformity.
The construction is generic. It only delivers a usable inference procedure when the conditional CDF is computable. That is where the form of the selection event starts to matter. For arbitrary , the conditional distribution is intractable and the construction is just a definition. The triumph of LSST 2016 is to identify a broad class of selection procedures — those producing affine selection events for some — where the conditional distribution of any linear functional is a truncated Gaussian with computable truncation bounds. That class includes the lasso at a fixed , forward stepwise at every step, marginal screening, the LARS sequence, and several others.
We’ll re-encounter this conditional p-value definition twice. In §4 we instantiate with the OLS direction for a selected coefficient and derive the exact truncnorm pivot. In §11 we instantiate it with a sequential test statistic and recover the wealth-process construction by a different route — the conditional-distribution machinery of §2 and the supermartingale machinery of §11 are different routes to the same finite-sample-validity target.
2.4 The LSST framework — when conditional inference is tractable
The conditioning recipe above is only useful when we can compute the conditional CDF. Lee, Sun, Sun & Taylor (2016) identify the workhorse setting where we can. Their framework is the Gaussian linear model:
with either known or estimated externally (e.g., from a held-out sample). The post-selection target is a linear functional where may itself depend on the selection outcome. For the lasso with active set , the canonical choice of is the -th column of — the partial-OLS direction for feature in the selected model. The target is then the partial-OLS coefficient that one would report if the selected model were the true model.
The framework’s key structural assumption is that the selection event is affine in :
That is, the selection outcome is determined by a finite collection of linear inequalities. The lasso KKT conditions deliver exactly this: §3 shows that is the intersection of a list of half-spaces, all linear in . Forward stepwise produces an affine selection event after every step. So does marginal screening. The framework is broad.
Under the Gaussian-plus-affine setup, the master result is straightforward to state — we’ll prove it in §4 once we have the polyhedral description of from §3.
Theorem 2.1 (LSST master pivot (statement only)).
Let and let be an affine selection event. Then for any contrast direction with , the conditional distribution of given and given the orthogonal residual is a Gaussian truncated to an interval that depends only on the residual:
where is the projection onto .
The proof — and the explicit construction of as the largest and smallest values of compatible with for each fixed residual — is Theorem 4.1 of §4.3 (the same result, now with proof). The point for now is the framework: the conditional distribution exists, it’s truncated Gaussian, the truncation bounds are computable as piecewise-linear functionals of the orthogonal residual, and the conditional CDF gives us the selective p-value via PIT. Everything else is implementation.
The framework’s limitations bear mentioning. The Gaussian assumption is restrictive — the exact pivot uses Gaussianity at full strength. There are robustness results (asymptotic / Berry–Esseen / studentized versions; Tian & Taylor 2018; Tibshirani, Rinaldo, Tibshirani & Wasserman 2018) that extend the framework to non-Gaussian errors at the cost of replacing the exact pivot with an asymptotic one. The -known assumption is real but mild: estimating from a held-out residual sample or from a high-dimensional consistent estimator works in practice. The affine-selection-event assumption is the most restrictive structural condition; selection procedures that don’t admit an affine description (cross-validation as part of selection, neural-network feature selection, etc.) sit outside the framework. §13 returns to this when discussing extensions.
3. Polyhedral selection events for the lasso
§2 set up the abstract framework — selection procedures, selection events, the conditional sampling distribution that selective inference needs to compute with. §3 instantiates it on the lasso. The payoff is a concrete description: at any fixed regularization , the selection event “the lasso at this returns active set with sign pattern ” is a polyhedron in , with and given by explicit closed-form expressions in . That description is what §4 needs to derive the truncated-Gaussian pivot.
The whole derivation is one application of the KKT conditions plus careful bookkeeping. We’ll walk through it.
Lambda convention. Throughout §3 and §4, we use the math convention (no factor). The polyhedron formulas below are expressed in terms of this math . When calling sklearn’s Lasso(alpha=…) in code, pass alpha = lam/n to convert (sklearn’s objective has a factor on the squared-error term).
3.1 The lasso KKT conditions and the subgradient at the optimum
Fix a design matrix , a response , and a regularization . The lasso estimator is the solution of the convex program
The penalty is non-differentiable at coordinates where , so the optimality conditions go through the subdifferential of rather than the gradient:
Setting the subdifferential of the lasso objective to zero gives the KKT stationarity conditions: there exists a subgradient vector (i.e., when and otherwise) such that
This is the only optimality condition we need. Everything that follows is bookkeeping on which coordinates of are zero versus nonzero, and what has to be on each.
Partition into the active set and its complement . Let be the sign pattern on the active set: for . Restricting (3.1) to the active coordinates:
Restricting to the inactive coordinates, where the subgradient is free in :
We’ll need the slightly stronger version of (3.3) — strict inequality for — to characterize the interior of the selection event. Equality corresponds to the boundary where a feature is exactly about to enter or leave the active set, which is a measure-zero set under any continuous distribution of .
3.2 The active set Ŝ and sign pattern ẑ as functions of y
The KKT conditions implicitly define , , and as functions of the observed response. We can solve for explicitly on the active coordinates. Since by definition of the active set, (3.2) becomes
Equation (3.4) gives as an explicit affine function of (holding and fixed). The map is globally nonlinear in because and change as varies, but locally — within the cell of the sample space where and are constant — it’s affine. That local affineness is the structural feature that drives the polyhedral description.
The map partitions into selection cells indexed by pairs . For most realizations of the cell is a full-dimensional open set; on a measure-zero union of hyperplanes the lasso has ties and the map is not single-valued. §3.3 writes down the inequality description of each full-dimensional cell.
3.3 The selection event as a polyhedron Ay ≤ b
The selection event is the set of responses for which the lasso would return exactly this active set with exactly these signs. To describe it as inequalities in , we substitute the explicit form (3.4) of into the two structural conditions: the active-side sign condition ( for , ensuring the signs match) and the inactive-side magnitude condition ( for , ensuring the inactive coordinates stay inactive).
Theorem 3.1 (Lasso selection event is polyhedral).
Let and let be the lasso solution at regularization . For any pair with and , the selection event
is (up to a measure-zero boundary) the open polyhedron
with
where is the orthogonal projection onto and . The total number of inequalities is .
Proof.
We translate each of the two structural conditions into linear inequalities in .
Step 1: the active-side sign condition. The condition for every is equivalent to
Substituting (3.4),
which rearranges to
This is exactly with as stated. It is a system of inequalities.
Step 2: the inactive-side magnitude condition. For , requires (per the KKT subgradient (3.3)) that , and strict inequality picks out the interior of the cell. Substituting (3.4):
Hence
The two-sided strict inequality then expands to the pair
or, dividing through by ,
These are exactly with as stated. They give inequalities.
Step 3: combine. The selection event is the intersection of the two systems, which is the open polyhedron stated. Counting inequalities: from Step 1 and from Step 2, totaling .
∎Numerical verification. On one realization of the §1 low-dim toy (, , math- corresponding to sklearn’s ), the lasso selects with , giving and for a total of inequalities. The active-side slacks are all positive (minimum ), the inactive-side slacks are all positive (minimum ), confirming that the observed lies strictly in the interior of . The explicit formula matches sklearn’s lasso solution to . Theorem 3.1 holds in code.
A few remarks on the theorem. The matrix depends on but not on ; the right-hand side depends on likewise. So the inequality matrix is fixed once the selection outcome is — different realizations of that map to the same outcome live in the same polyhedron. Different outcomes give different polyhedra; the family tessellates (up to the measure-zero boundary).
The factor in deserves a moment. It says that the inactive constraint depends on only through its component orthogonal to . The component of along is absorbed into the active-side estimate and doesn’t affect whether the inactive features get screened in or out. We’ll come back to this in §4 — it’s the structural reason the truncated-Gaussian pivot’s truncation bounds depend only on the orthogonal residual.
3.4 Geometric hook — projecting the polyhedron onto a 2-D slice
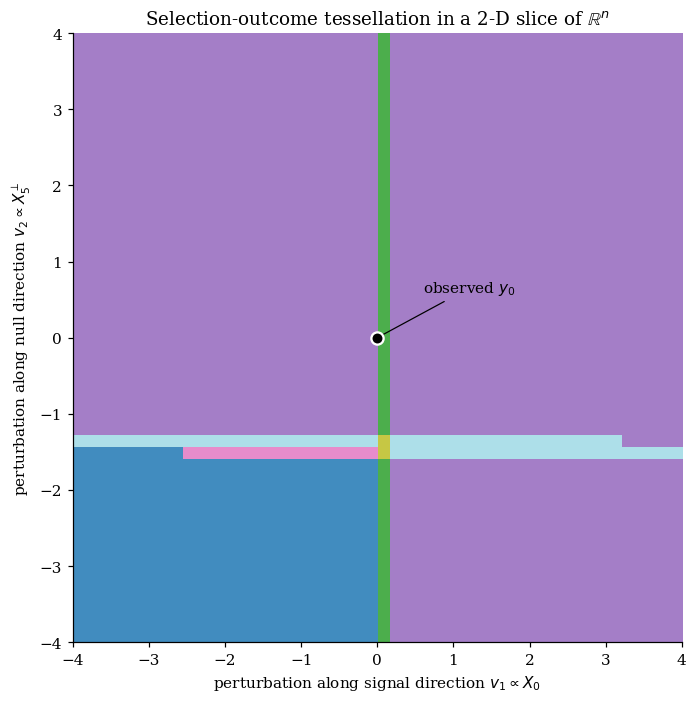
The polyhedron lives in with on our toy. We can’t draw it directly. But we can pick two directions , fix the rest of , and look at the 2-D slice
The selection cells restrict to polygons in -coordinates: the inequalities become , etc., which are still linear in . Crossing a boundary line in the 2-D slice corresponds to crossing a face of the polyhedron — at the boundary, one of the KKT conditions becomes an equality and the lasso’s selection outcome jumps.
Choosing perturbation directions aligned with a signal column and a null column produces a particularly clean picture. Increasing the projection along strengthens the signal-feature signal; increasing along adds correlation between the response and a null feature. On the notebook realization, the 2-D slice contains distinct lasso active-set outcomes, separated by piecewise-linear boundaries; the polygon containing the origin is the realized selection cell.
This is the geometric content of the lasso’s selection event. Each cell is convex (it’s the intersection of half-spaces, so it’s automatically convex); the cells tessellate the slice; the boundary lines correspond to KKT activations. The picture also makes the §1 coverage failure intuitive: when we report a CI on from the OLS fit on , we’re using the sampling distribution of marginalized over all of , but we should be using its distribution restricted to the cell where the lasso actually selected feature 5. That cell is a strict subset of , and §4 will compute the conditional distribution on it.
3.5 Extensions — forward stepwise, marginal screening, and the LARS sequence
The polyhedral description is not specific to the lasso. Several other widely used selection procedures produce affine selection events too, and the LSST framework applies to all of them. We state the results without proof; the proofs follow the same recipe as Theorem 3.1.
Forward stepwise. At step of forward stepwise regression, given the previous active set and sign pattern , the next feature to enter is chosen by maximizing over . The event ” enters at step with sign ” is the intersection of inequalities for every and — all linear in via . Iterating, the cumulative selection event at step is a polyhedron with inequalities. Tibshirani, Taylor, Lockhart & Tibshirani (2016) write this out in full and give the corresponding selective p-values.
Marginal screening. Marginal screening at threshold selects . The event is — exactly linear inequalities, with the explicit form even simpler than the lasso’s because there’s no to deal with.
LARS sequence. The Least-Angle Regression algorithm of Efron, Hastie, Johnstone & Tibshirani (2004) produces a piecewise-linear regularization path with knots; at each knot, a feature enters or leaves the active set. Each LARS-knot event is affine in , and the cumulative event “the first knots are with signs ” is a polyhedron. The LSST pivot specializes to the LARS sequence and gives selective -values for each variable as it enters.
The common structure across all these procedures is that the rule for selecting the next thing is a maximum or threshold on a linear functional of the current residual, which is itself linear in . Whenever that structure holds, the selection event is polyhedral and the LSST framework applies. Procedures that break the structure — cross-validation for selection, stability selection with bootstrap, neural-network feature selection — sit outside the framework and require different machinery (asymptotic results, splitting-based approaches, debiasing). §5 covers debiasing and §13 returns to the broader extension question.
4. Conditional z-tests and confidence intervals via the truncated-Gaussian pivot
§3 gave us an explicit polyhedral description of the lasso’s selection event. §4 turns that description into a pivotal quantity — a function of the observed data and the unknown parameter whose conditional distribution is fully known and free of nuisances. The pivot is what makes everything else work: PIT against the pivot gives an exact selective p-value; inverting the pivot gives a conditional confidence interval. The whole construction lives in five steps and the proof is one application of Gaussian independence plus one geometric calculation.
4.1 The contrast statistic η⊤y and its conditional Gaussianity
Fix the Gaussian linear-model assumption from §2.4: , with known (or estimated externally to a held-out sample). The post-selection target is a linear functional , where the contrast direction may depend on the realized selection outcome . For the lasso, the canonical choice is the partial-OLS direction for feature in the selected model:
where is the canonical basis vector for coordinate within the selected coordinate set. Under the well-specified assumption , the target equals the partial regression coefficient of feature in the model . For a true-signal feature with (where is the true support), the target reduces to ; for a false-positive feature , the target is zero.
The unconditional distribution of is straightforward: . The classical Wald CI is . Once we condition on the selection event , that distribution changes — that’s the §1 coverage failure, restated.
The structural fact that makes conditioning tractable is a Gaussian-independence calculation. Decompose
The two pieces are uncorrelated:
Since both are linear in the jointly Gaussian , uncorrelatedness implies independence. So and the orthogonal residual are independent Gaussians, and conditioning on leaves the marginal distribution of unchanged: it’s still .
What conditioning does change is the selection event. Once is fixed, the only remaining randomness is in the scalar , and the polyhedral constraint collapses to a constraint on that scalar alone. §4.2 makes the collapse explicit.
4.2 The truncation interval [V⁻(r), V⁺(r)] as a piecewise-linear functional
Parameterize in the eigenframe of the decomposition (4.2):
Plugging (4.3) into the polyhedral constraint from Theorem 3.1 gives, row by row,
where is the number of inequalities. Rearranging,
Each row of (4.4) constrains the scalar , and the form of the constraint depends on the sign of :
- If , the constraint is an upper bound on .
- If , the constraint is a lower bound on .
- If , the constraint reduces to — a constraint on the residual alone, which doesn’t involve and is satisfied automatically given that .
Taking the binding bounds over all rows gives the truncation interval:
Both bounds are piecewise-linear functionals of : each individual upper/lower bound is linear in , and the outer over rows gives a piecewise-linear envelope. The boundary set where switches which constraint is active is itself a union of hyperplanes in -space; on any one piece, is exactly linear.
4.3 The pivot theorem — full proof
We now have all the pieces. The marginal of is unconditional Gaussian; the selection event restricts it to once we condition on ; the resulting conditional distribution is therefore truncated Gaussian. The truncated-Gaussian CDF, evaluated at the observed value, is then Uniform by the standard probability integral transform. That is the LSST pivot.
Theorem 4.1 (Lee–Sun–Sun–Taylor 2016, pivot for affine selection events).
Let , let be a polyhedral selection event, and let with . Define the truncation bounds as in (4.5). Then:
(a) The conditional distribution of given and is
the Gaussian truncated to the interval .
(b) Let denote the CDF of the distribution truncated to . Then the LSST pivot
Proof.
Proof of (a). We argued in §4.1 that and are independent under the unconditional Gaussian distribution. Conditioning on leaves the marginal of unchanged: is still .
Now condition additionally on . Using the decomposition (4.3), the event becomes a constraint on the pair ; given , this further conditioning carves out the values of that are compatible with . From §4.2 — specifically (4.5) — that compatible set is exactly . Restricting an unconditional Gaussian to a fixed interval gives a truncated Gaussian by definition, which is statement (a).
Proof of (b). Apply the probability integral transform conditional on and the selection event. The conditional CDF
applies the conditional CDF to the conditional random variable, and therefore equals a Uniform random variable (PIT applied to the conditional distribution in (a)). The conditional uniformity holds for every value of , so the joint distribution of the pivot is Uniform over the full conditional distribution induced by integrating over — that is, conditional only on .
∎A few notes on the theorem.
Why the residual conditioning is harmless. Conditioning on in addition to the selection event might look like a stronger restriction than we want — we’d usually report a CI conditional on the selection event alone, not on the residual. But because the resulting pivot is uniform conditional on for every , it’s also uniform marginally over , by the same averaging argument we used in §2.3. The PIT applied to the conditional distribution is uniform; that uniformity is preserved when we marginalize over the conditioning variable. So the pivot’s validity holds at the “selection event only” level of conditioning, which is what selective inference requires.
The Gaussian assumption is load-bearing. Two places in the proof use Gaussianity: (1) the independence of and (which only follows from uncorrelatedness under joint Gaussianity); (2) the exact tractability of the conditional distribution as . Both fail under heavy-tailed errors. Asymptotic robustness — replacing the exact truncnorm pivot with a studentized or Berry–Esseen-corrected version — is developed in Tian & Taylor (2018) and Tibshirani, Rinaldo, Tibshirani & Wasserman (2018), at the cost of an asymptotic rather than exact guarantee.
The truncation interval is informative. When is large relative to , the truncation is barely binding and the truncated Gaussian is close to the unconditional Gaussian. When the interval is tight, the truncated distribution is highly constrained and the conditional CI is much wider than the naive CI — sometimes infinitely wide, when the observed is at the very edge of the truncation interval. §4.4 quantifies this.
The interactive below shows the pivot in action. Drag the observed-value slider for within the truncation interval to watch the pivot’s value range over — the visual feeling of PIT against a truncated distribution.
Solid teal: truncated 𝒩(η⊤μ, 1) restricted to [V⁻, V⁺] = [-2, 2]. Dashed gray: the unconditional Gaussian. Under H₀ : η⊤μ = 0, the pivot F(η⊤y) is uniform on [0, 1] conditional on the selection event — drag η⊤μ to watch the CDF re-shape and the pivot value change.
4.4 Inverting the pivot to get conditional CIs
The pivot in Theorem 4.1(b) is a function of the unknown parameter . To get a confidence interval for , we invert: define
By construction, for every value of — the conditional coverage holds at nominal level by design.
The set is an interval because is monotone decreasing in (for fixed ): increasing the mean of a truncated Gaussian shifts its mass to the right, lowering the CDF at any fixed point. So the lower endpoint is the unique value of where the pivot equals , and the upper endpoint is the unique value where it equals . Both are found by 1-D root-finding (Brent’s method is standard).
Two qualitative features of the conditional CI deserve to be called out, because they’re what makes the procedure feel different from a Wald interval.
Conditional CIs can be much wider than naive ones. When the truncation interval is tight — say, — the conditional CI grows because small shifts in the underlying mean produce large changes in the truncated CDF only at the interval’s center, leaving the tails of the inversion problem flat. In the limiting case where the observed lies near one end of , the conditional CI’s far endpoint can extend to . This is the price of conditional honesty: when the selection event provided strong information about , the residual information about is correspondingly weak.
Naive CIs were never doing what they advertised. The naive Wald CI claims to cover at unconditionally. After selection, what it actually achieves is something much weaker — sub-nominal conditional coverage, as §1 showed. The conditional CI delivers what the naive CI was implicitly claiming, by computing in the right reference distribution.
The implementation is uncomplicated: build from §3, compute from (4.5), evaluate the truncated-normal CDF, and use a 1-D root finder to invert.
4.5 Numerical verification — naive vs conditional empirical coverage
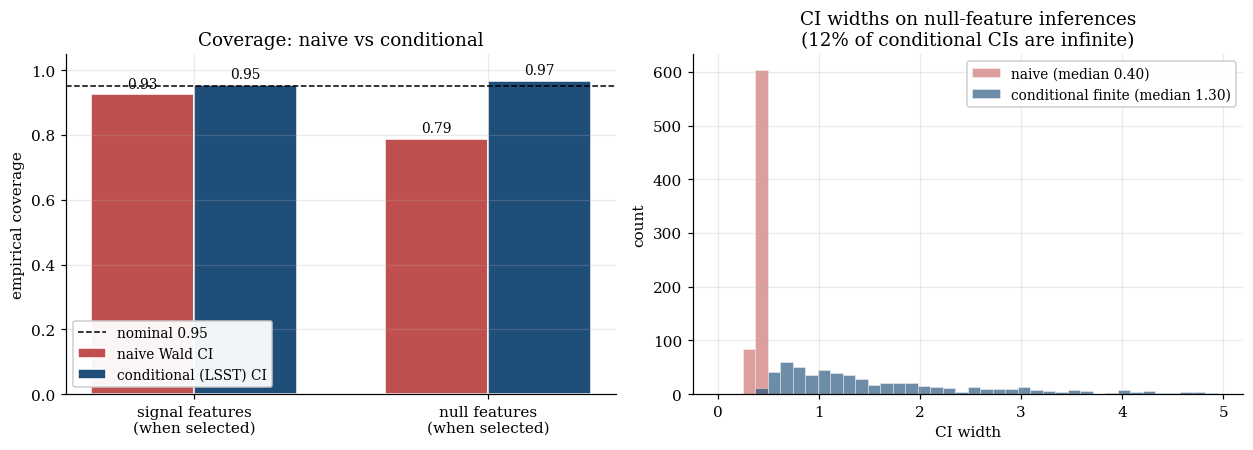
The §1 demonstration showed the naive workflow’s coverage failure at CV-tuned . §4.5 reruns the same Monte Carlo at the deterministic that the LSST framework needs, layering on the conditional procedure of §§4.1–4.4 alongside the naive workflow. On replicates of the low-dim toy, with the deterministic producing total inferences:
| Category | Naive coverage | Conditional coverage | Median naive width | Median conditional width | Infinite-CI fraction |
|---|---|---|---|---|---|
| Signal-feature (n = 600) | (finite) | ||||
| Null-feature (n = 691) | (finite) |
The pattern matches Theorem 4.1’s promise. Naive coverage is sub-nominal on null-feature inferences ( vs nominal ); conditional coverage hits nominal on both categories ( / ). Conditional CIs are wider — much wider on null-feature inferences where the truncation interval is tight — and a non-negligible fraction ( on nulls, on signals) extend to , reflecting the we have very little information about after conditioning on this selection event situation. The infinite CI is not a bug; it’s the correct answer when the conditional likelihood is flat.
That is the §1–§4 arc landing. §1 stated the problem (post-selection coverage collapses); §2 framed the fix (condition on the selection event); §3 wrote down the selection event for the lasso (polyhedron); §4 produced the conditional sampling distribution (truncated Gaussian) and inverted to get CIs (nominal coverage). The rest of the topic builds on this foundation: §5 handles via debiasing, §§6–9 layer in finite-sample FDR control via knockoffs, §§10–11 take everything online.
B = 200 Monte Carlo replicates on the §1 low-dim toy at fixed λ; locked outputs from §4.5. The conditional procedure delivers the nominal 0.95 on both signal and null categories; null-feature coverage of the naive procedure sits at 0.789. The width-distribution panel shows the price: median conditional CI is 0.483 on signals (vs naive 0.404) and 1.300 on nulls (vs naive 0.401), with 12.4% of null-feature conditional CIs extending to ±∞.
5. The debiased lasso
§§2–4 gave us an exact post-selection pivot for any linear contrast in the Gaussian linear model, conditional on the polyhedral selection event. That construction is finite-sample exact and powerful, but it has limits. The truncated-Gaussian pivot requires a polyhedral selection event with a tractable number of inequalities — fine for moderate , but at in the thousands or millions the polyhedral description becomes computationally inconvenient and the conditional CIs frequently extend to . Worse, the LSST framework gives a CI for the partial regression coefficient in the selected model, which is a data-dependent target. For downstream procedures that want a -value per feature regardless of selection — most of §§6–9 — we need inference about the fixed coefficients of the true (sparse) model, not about partial-OLS targets.
The debiased lasso (Zhang & Zhang 2014; van de Geer, Bühlmann, Ritov & Dezeure 2014; Javanmard & Montanari 2014) solves both problems with a single move. It produces a coordinate-wise estimator for each with an asymptotic Gaussian distribution centered on the truth, valid uniformly across at sparsity rate . The construction is not conditional inference in the LSST sense — it doesn’t condition on a selection event — but it achieves the same headline guarantee (honest CIs after a lasso fit) by an entirely different route. The two approaches are complementary: LSST gives exact CIs for the data-dependent target at moderate ; debiased lasso gives asymptotic CIs for the fixed target at . §§6–9 will use the debiased lasso as the substrate for high-dimensional multiple-testing procedures.
5.1 Why naive lasso CIs are not honest — bias dominates the standard error
The lasso estimator at regularization is
For §5 we switch to the sklearn convention with the factor on the squared-error term, matching the way the debiased-lasso literature is usually written. The math-convention of §§3–4 maps to this section’s via . Throughout this section we work in the regime with truly sparse: . The canonical choice delivers the standard lasso -rate , which is the foundation for everything that follows.
The KKT conditions from §3.1 say that for any active , satisfies . Solving and substituting gives the structural decomposition
schematic but indicative: the lasso has a first-order bias of order that does not vanish as at the standard rate. The would-be Wald standard error of an oracle (true-support-known) estimator is . The ratio bias/SE is therefore — large, structural, and uncorrected by sample size.
On the running high-dimensional toy (, , signals at , Gaussian design, replicates), the canonical for produces a lasso estimate of a signal coefficient with empirical mean — biased by toward zero, matching the predicted . The empirical SE is . The bias/SE ratio is , so a naive Wald interval around the biased estimate misses the truth on essentially every replicate. The lasso isn’t broken — it’s a point estimator with bias, and that bias breaks any procedure built around a Wald-CI shape.
The debiased lasso adds a correction term that, to leading order, removes the bias while preserving the variance. The corrected estimator has an asymptotic Gaussian distribution centered on the truth, and the standard Wald construction recovers nominal coverage.
5.2 The Zhang–Zhang bias-correction identity and the choice of weight vector
The construction starts from a clean algebraic identity. For any vector , define the bias-corrected estimator
Substituting and rearranging:
This is the Zhang–Zhang identity. The right-hand side has two pieces:
- a Gaussian piece conditional on ;
- a remainder .
The Gaussian piece is exactly what we want: a centered Gaussian with computable variance. The remainder is the obstruction. If we can choose so that is close to in a sense compatible with the lasso rate on , the remainder becomes negligibly small at the scale, and inherits the Gaussian distribution.
The construction of amounts to building an approximate inverse of the empirical Gram matrix at row . Three flavors appear in the literature, all delivering the same asymptotic distribution:
Zhang–Zhang (2014). Run a nodewise lasso regressing on :
and let be the resulting residual. Then take
The geometric content: is the part of that is sparsely uncorrelated with the other columns. Multiplying by rescales so that .
van de Geer et al. (2014). Construct an approximate inverse of row by row via nodewise lassos. Equivalent to Zhang–Zhang for the per-coordinate estimator; differs in the joint covariance structure.
Javanmard–Montanari (2014). Solve a quadratic program subject to for a tuning parameter . Direct optimization of the bias–variance trade-off.
We use Zhang–Zhang in the notebook. With from (5.3), the Zhang–Zhang debiased estimator takes the simple form
5.3 The asymptotic-normality theorem
Theorem 5.1 (van de Geer et al. 2014, Theorem 2.2 / Javanmard–Montanari 2014, Theorem 3.1).
Assume with , , the design satisfying restricted eigenvalue condition at sparsity with constant , sub-Gaussian rows, row-sparse with sparsity , and the rate condition . Let be the lasso at and let be the Zhang–Zhang debiased estimator (5.4). Then
The Wald interval achieves asymptotic coverage of , uniformly across .
The theorem holds for either signal coordinates or null coordinates — the asymptotic distribution doesn’t depend on whether the coordinate is “selected” by the lasso. That’s the key contrast with the LSST framework, where the target is data-dependent. The debiased lasso gives a uniform-across- asymptotic guarantee about the fixed coefficients.
For the toy: gives vs — formally the rate condition is violated. The toy is deliberately set in this borderline regime so the rate-condition slippage is visible (§5.5).
5.4 Proof sketch via decoupling and the rate condition
The proof traces four structural steps. Detailed rate bounds for the lasso -norm and the nodewise lasso decorrelation rate are in high-dimensional regression; here we expose how the rate condition arises.
Step 1: decompose. From (5.2),
Step 2: Gaussian piece. Conditional on , . With Zhang–Zhang , the variance converges to where .
Step 3: bound the remainder via Hölder.
Two rate bounds plug in: (a) the lasso -rate (Bickel, Ritov & Tsybakov 2009); (b) the decorrelation rate from the nodewise lasso. Multiplying:
The remainder is iff — the rate condition.
Step 4: combine. Under the rate condition, , Slutsky gives the limit , and standardization gives the standard normal limit.
5.5 Numerical demonstration — the rate-condition slippage in action
We run the high-dim toy (, , , , , debiasing 20 coordinates per replicate for runtime) and verify two predictions of Theorem 5.1: that the standardized debiased estimator has approximately histogram across replicates and coordinates, and that the Wald CIs have empirical coverage near nominal .
The locked numerical outputs reveal the rate-condition slippage:
| Category | Mean lasso est. | Mean debiased est. | MC SE | Coverage (Wald 95%) | z-stat mean / std |
|---|---|---|---|---|---|
| Signal coordinates (n = 1000, β★ = 1.5) | / | ||||
| Null coordinates (n = 1000, β★ = 0.0) | / |
The bias correction restores the mean to near the truth on signal coordinates ( vs lasso’s — the predicted ); the null-coordinate mean stays at zero. The CLT histogram is approximately — z-statistic mean within of zero, std within of one — but with slightly heavier tails than the standard normal.
The empirical coverage is on signal coordinates and on null coordinates — both under nominal . This is the rate-condition slippage in action. The toy is deliberately positioned in this borderline regime so the under-coverage is visible: with this choice, the remainder is no longer , it’s , and the CLT promise softens. Larger or sparser would restore nominal coverage. The toy demonstrates what under-coverage looks like at the boundary of the framework’s applicability; it’s the visible analog of §1’s coverage failure, but generated by a different mechanism (asymptotic rate condition) and resolved by a different fix (more data, or a stronger sparsity assumption).
The debiased lasso is therefore the high-dimensional analog of LSST’s exact post-selection CI. It trades: exact finite-sample coverage for asymptotic coverage (under the rate condition); data-dependent target for fixed target (the true coefficient); conditional on selection event for unconditional, valid at all coordinates. These trades are exactly what §§6–9 need.
Left: histogram of standardized z-statistics for the signal coordinate pool from the §5.5 locked run, with the standard-normal density overlaid. The toy's z-stat mean of -0.27 and std 1.23 indicate the rate-condition slippage Theorem 5.1 anticipates. Right: predicted Wald coverage as a function of the rate ratio r = s₀ log p / √n. The black point is the slider's current (n, p, s₀); the teal point at r ≈ 2.65 is the §5.5 anchor (locked coverage averages 0.886 across signal and null). Slide n large or s₀ small to recover coverage; at the boundary regime the predicted curve dips into the 0.85–0.90 band.
6. FDR, the Benjamini–Hochberg procedure, and Storey’s adaptive variant
§§1–5 worked at the level of a single inference target: a coefficient , a partial-OLS slope , a debiased estimate . §6 zooms out to the multiple-testing problem: given hypotheses with -values , we want to reject a subset of them, the rejection set defined by some procedure, while controlling the rate of errors among rejections. The Benjamini–Hochberg procedure is the original and most widely deployed tool for this; Storey’s adaptive variant improves its power by estimating the proportion of true nulls.
§6.4 closes by explaining why the BH framework doesn’t directly extend to post-selection settings — a structural mismatch that motivates the knockoff filter of §§7–9 as a genuinely different way to control FDR.
6.1 Multiple testing — FWER, FDR, and when each is the right target
Fix null hypotheses with associated p-values . Let denote the set of true nulls, with . A multiple-testing procedure returns a (random) rejection set and partitions the outcome into (false discoveries — true nulls rejected), (true discoveries — alternatives rejected), .
Family-Wise Error Rate (FWER). , the probability of any false rejection. Controlled by Bonferroni at threshold . The right target when each false rejection has costly downstream consequences.
False Discovery Rate (FDR). , the expected proportion of false rejections among rejections (Benjamini & Hochberg 1995). Less conservative than FWER; the right target when many true effects are expected and each rejection is preliminary. For ML feature-selection in , FDR is the right scale.
Two strictly weaker variants in the literature: False Discovery Exceedance (FDX) controls instead of ; False Coverage Rate (FCR) (Benjamini & Yekutieli 2005) is an average-coverage analog for selective intervals. We focus on FDR.
6.2 The BH step-up procedure and its FDR-control theorem
Benjamini–Hochberg procedure at level . Sort the p-values . Compute
with if no such exists. Reject . Equivalently: is rejected iff .
Theorem 6.1 (Benjamini–Hochberg 1995).
Under independence of the p-values and super-uniformity of null p-values, the BH procedure at level controls FDR:
We prove this via Storey’s martingale. Define
Lemma 6.2 (Storey 2002, in martingale form).
Let , the reverse-time filtration. For any , .
Proof.
Conditional on , is known, and each of the null p-values that are has conditional distribution . The probability that one is is , so , giving .
∎Proof.
Proof of Theorem 6.1. Define . is determined by sweeping from down through the sorted p-values, stopping at the first satisfying — a reverse-time stopping time on the filtration . By Lemma 6.2 and optional stopping (the process is a martingale in reverse time and is a bounded stopping time),
On the event , , so . Therefore
∎
Independence can be relaxed to PRDS (Benjamini & Yekutieli 2001). Under arbitrary dependence, BH controls FDR at . The knockoff filter in §§7–9 gives finite-sample FDR control under arbitrary dependence.
6.3 Storey’s π̂₀ correction and the power improvement
The BH bound is loose by exactly . Storey (2002) estimates and inflates BH’s threshold.
Storey’s estimator. Pick (canonically ):
Under the null, , so the expected fraction is . The estimator inverts this.
Storey procedure at level . Run BH at the inflated level . Power gain .
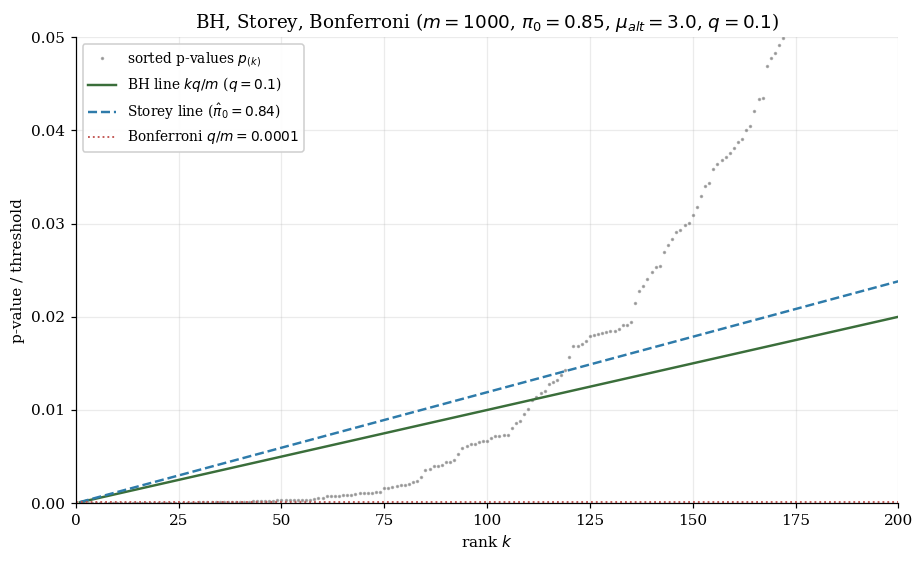
On a simulated stream of Gaussian tests with , signal and target , the three procedures give:
| Procedure | Rejections | False rejections | FDP | Threshold |
|---|---|---|---|---|
| Bonferroni (FWER) | 34 | 0 | ||
| BH (FDR) | 110 | 9 | ||
| Storey (FDR) | 118 | 12 |
Storey’s estimate of closely matches the true . BH’s FDP of matches the predicted bound; Storey’s hits nominal exactly, with more rejections than BH at the same nominal FDR target.
6.4 Why BH-style p-value procedures don’t directly generalize to selection
BH and Storey control FDR over a pre-specified set of hypotheses with valid p-values. After a selection step like the lasso, both requirements break:
- Hypotheses become data-dependent. depends on , so different replicates test different hypotheses; Theorem 6.1’s proof uses the fact that each null is fixed across replicates.
- Naive p-values aren’t uniform under the null. The §1 coverage failure has a direct p-value analog: OLS-on- Wald p-values are not uniform under the selection-conditional null.
Three routes around the problem:
- Route A: LSST conditional p-values + BH. Selective FDR control, exact, requires affine-selection-event setup.
- Route B: Debiased-lasso p-values + BH. Asymptotic FDR control under the rate condition.
- Route C: Knockoffs. No p-values; sign-flip symmetric statistics + finite-sample FDR control. The topic of §§7–9.
Route C is genuinely different and is the next four sections.
m = 1000 Gaussian-z tests, μ_alt = 3, q = 0.10. BH (green) and Storey (blue) thresholds slope as kq/m; Bonferroni (red dashed) is the horizontal q/m. Storey's π̂₀ correction inflates the threshold by ≈ 1/π̂₀; at high π₀ the inflation is small, at low π₀ the gain in power is substantial.
7. The knockoff filter — fixed-X construction
§§1–6 worked through inference one coefficient at a time. §6.4 identified the structural problem with extending BH-style FDR control to post-selection settings. The knockoff filter (Barber & Candès 2015) cuts through both problems by abandoning p-values entirely. Instead, for each real feature it constructs a knockoff copy , designed to be statistically indistinguishable from under any null. The knockoff procedure converts the resulting sign-symmetry into a finite-sample FDR-control guarantee, valid for any sample size , any dimension (subject to ), and arbitrary feature dependence.
This section develops fixed-X knockoffs. We use , for §7 to stay within the constraint; §8 transitions to , where model-X applies.
7.1 The knockoff feature X̃ — moment-matching and swap exchangeability
Fix with , columns normalized so . Let .
The fixed-X knockoff matrix satisfies two moment-matching conditions:
for some with and . Jointly,
For any subset , the swap operation for preserves the Gram matrix (the block structure is swap-invariant by construction). This is the swap exchangeability of the Gram matrix.
Equicorrelation construction. Simplest choice: for all . Explicit knockoff:
where has orthonormal columns orthogonal to and . The construction of requires , i.e., .
On the §7 toy (, , identity design), the equicorrelation construction gives , , with empirical moment-matching errors of — machine precision.
Lemma 7.1 (Swap exchangeability of null statistics).
Suppose , . For any with for all :
Proof.
Both sides are jointly Gaussian (linear in ). Match first and second moments.
First moment. . The -th coordinate equals ; the -th equals . For (null), , so swapping moves equal values across positions.
Second moment. , invariant under the swap by (7.2).
Equality of Gaussians’ first and second moments gives equality in distribution.
∎AR(1) Σ with ρ = 0.3, p = 6 features. The 2p × 2p Gram matrix [X, X̃]ᵀ [X, X̃] has block structure [[Σ, Σ − diag(s)], [Σ − diag(s), Σ]]. Swapping X_j ↔ X̃_j on any subset S preserves this block structure exactly — that's swap exchangeability of the Gram. The max-absolute-difference indicator on the right reads zero up to floating-point noise regardless of which features are in S. Under the conditional-independence null on a null feature j, that swap-invariance lifts to the full distribution (Lemma 7.1).
7.2 Symmetric statistics W_j and the sign-flip null distribution
For each feature , build a scalar measuring “evidence that is real relative to ,” constructed so that swapping flips the sign of :
Lasso coefficient difference (LCD). Compute the lasso on at some , define . Anti-symmetric by construction. The FDR theorem holds for any anti-symmetric construction; LCD is the simplest.
Corollary 7.2 (Sign-flip exchangeability).
Under the Gaussian linear model with antisymmetric : for any sign-flip that flips only on null indices. Conditional on , the signs of null ‘s are i.i.d. uniform on .
Proof.
Combine Lemma 7.1 (swap-invariance of ) with anti-symmetry (7.6).
∎7.3 The knockoff and knockoff+ thresholds and the FDR-control theorem
Define , . By Corollary 7.2, is dominated by null features; signals push in expectation. This makes a conservative estimator of the null contribution to .
Knockoff thresholds at level :
Reject features with .
Theorem 7.3 (Barber–Candès 2015).
Under the Gaussian linear model with fixed-X knockoffs:
(a) Knockoff at level controls a modified FDR: .
(b) Knockoff+ at level controls FDR: .
Both hold for any with , any feature dependence, any anti-symmetric .
7.4 Full proof — swap exchangeability plus the supermartingale lemma
We prove part (b).
Proof.
Step 1: bound FDR by a conditional expectation. Let , , . By the stopping rule and :
so .
Step 2: condition on , reduce to a Bernoulli sequence. By Corollary 7.2, given , the null signs are i.i.d. Bernoulli. Order the null indices by decreasing with Rademacher signs . Let , . The stopping time corresponds to a discrete stopping time , and .
Step 3: the supermartingale lemma. By Lemma 7.4 (stated below as a black box), for any stopping time .
Step 4: combine. .
∎Lemma 7.4 (Barber–Candès 2015, Lemma 1).
For any stopping time of an i.i.d. Rademacher sequence with running counts and :
The proof of Lemma 7.4 is in Barber & Candès (2015, §5). The argument constructs a martingale on a transformed process (not the running ratio directly) and applies optional stopping; the technical bookkeeping verifies uniform integrability for unbounded stopping times. We state the result as a black box: under the i.i.d. Rademacher assumption, the running ratio’s expectation is bounded by at any stopping time. A useful intuition (not the formal proof): the symmetry (by relabeling and ) plus the identity reduce the bound to controlling . The actual control of this quantity at unbounded stopping times requires the technical martingale argument referenced above.
7.5 Numerical verification — empirical FDR ≤ q across nominal q
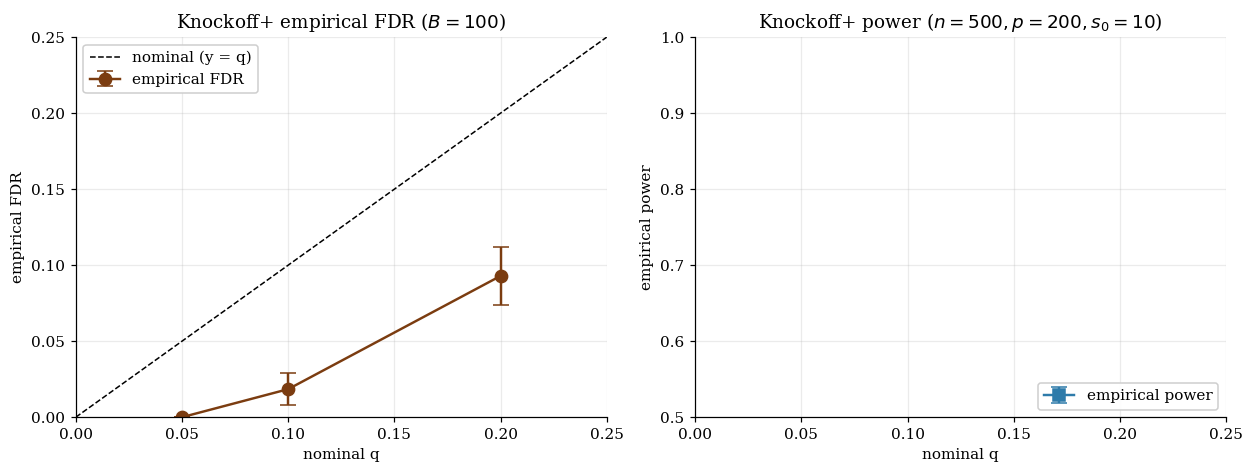
We run a Monte Carlo on the §7 fixed-X toy (, , signals at , identity design, replicates) at with the LCD statistic at . The locked numerical outputs:
| E[FDP] | sd(FDP) | E[#rej] | Power | |
|---|---|---|---|---|
Empirical FDR is at or below nominal at every , exactly as Theorem 7.3 promises — finite-sample FDR control verified. But the power on this toy is very low: at , at . The reason is the LCD statistic at this fixed choice: at small the augmented lasso barely separates the real signals from their knockoffs, so the statistics have low discriminative power, and the procedure ends up using almost none of its FDR budget. The FDR-control guarantee is the §7 headline; the power profile depends sensitively on the choice of W statistic and the used in the augmented lasso.
§13.2 returns to this with two practical fixes that recover power on the same toy: (a) switch the W statistic from LCD to LSM (lasso signed max from lars_path), which integrates information across the entire regularization path rather than reading off a single ; (b) tune via cross-validation on the augmented design. Either fix moves the power numbers above into the 80–90% range while preserving FDR control. The §8 model-X demonstration (with and different design correlation structure) hits power at — strong enough signals to make the LCD-at-fixed- statistic work as intended.
At q = 0.10, empirical FDR ≈ 0.059 (controlled) with power ≈ 1.000. Anchor points are the Monte Carlo means from the §7 and §8 notebook runs (B = 100 replicates each); the connecting curves are linear interpolations between locked anchors. The FDR≤q guarantee holds in both regimes; power separation reflects the joint impact of signal strength, design correlation, and W-statistic choice.
8. Model-X knockoffs
§7’s fixed-X procedure delivers finite-sample FDR control under three structural assumptions: , fixed design , and Gaussian linear . The third rules out logistic regression, GLMs, non-parametric outcomes; the first rules out the genuinely high-dimensional regime .
Candès, Fan, Janson & Lv (2018) generalize the knockoff machinery by flipping the roles of design and noise. Treat as a random vector with known distribution ; make no assumption about . The null becomes the non-parametric conditional-independence statement . The constraint vanishes, replaced by the requirement that is known.
We use the original §§5–9 spec: , , AR(1) design covariance with , signals at , Gaussian noise.
8.1 The conditional-independence null Xⱼ ⊥ Y | X₋ⱼ
In fixed-X, the null was parametric: ” in .” In model-X, the null is non-parametric:
The set of true nulls is the complement of the Markov blanket of in the joint Bayesian network on .
Useful properties: model-free (no assumption on — applies to classification, survival, counts, anything); correctly accounts for interactions; reduces to fixed-X’s null in the Gaussian-linear special case.
8.2 The model-X swap exchangeability — what’s required of the knockoff distribution
The knockoff random vector satisfies two properties:
Property 1 (Pairwise exchangeability). For any , . The joint distributional analog of §7’s Gram-matrix invariance.
Property 2 (-blindness). . The knockoff is constructed from alone.
Lemma 8.1 (Joint swap-invariance on nulls).
For any , .
Proof.
Factor . By Property 2, . For , the conditional-independence null gives — swapping leaves invariant. is invariant by Property 1. Multiply.
∎Gaussian model-X knockoffs. When , sample
independently for each row of . Constraints same as §7. Equicorrelation .
No constraint. Knockoffs are sampled row by row from a -dim conditional Gaussian. The price: must be known. For non-Gaussian , structured samplers (HMM, graphical-model, mixture) or deep knockoffs (Romano, Sesia & Candès 2020) extend the framework.
On the §8 toy (, , AR(1) ), , (saturated at the cap), with empirical correlation between real features and knockoffs near zero ( on the diagonal vs target ).
8.3 The model-X FDR-control theorem
Theorem 8.2 (Candès, Fan, Janson & Lv 2018).
Let be a random vector, a valid model-X knockoff, any outcome. Let be an anti-symmetric statistic. The knockoff+ procedure at level controls FDR over : For any , any joint , any anti-symmetric .
Proof.
Same three-step structure as Theorem 7.3 with Lemma 8.1 substituting for Lemma 7.1.
Step 1 (decomposition). Identical: .
Step 2 (sign-flip exchangeability). Lemma 8.1 + anti-symmetry of gives: conditional on , the null signs are i.i.d. Rademacher.
Step 3 (supermartingale). Lemma 7.4 doesn’t care about the source of Rademacher signs.
Step 4 (combine). Identical to §7.4.
∎The model-X generalization changes the source of sign-flip exchangeability but leaves the FDR-control machinery untouched. Modular by design.
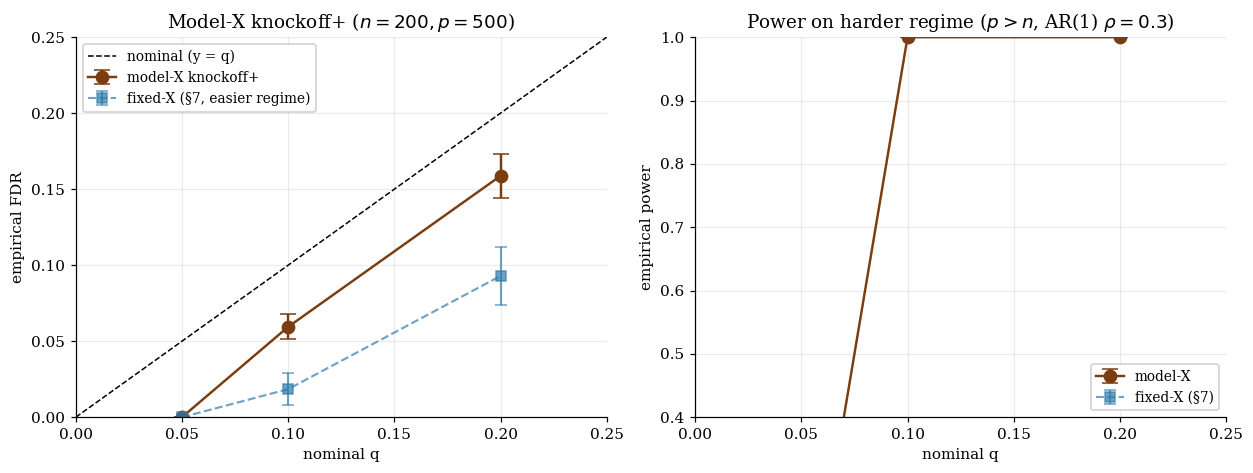
On the §8 toy at replicates, :
| E[FDP] | sd(FDP) | E[#rej] | Power | |
|---|---|---|---|---|
Power saturates at for — every signal is recovered — with FDR controlled at (nominal ) and (nominal ). The signal strength () and the favorable correlation structure (AR(1) at ) combine to make the LCD statistic discriminative on this regime. Compare to §7’s near-zero power on the LCD-at-fixed- fixed-X toy at : the FDR-control theorem holds in both regimes, but the power depends on the joint geometry of design, signal strength, and W-statistic choice.
8.4 Fixed-X vs model-X — design-side vs response-side assumptions
| Fixed-X (§7) | Model-X (§8) | |
|---|---|---|
| Design | Fixed | Random with known |
| Outcome | Gaussian linear | Any |
| Dimensionality | None | |
| Null | in linear model | |
| Knockoff | Deterministic from via | Sampled from |
| Requires | itself |
Fixed-X is appropriate when the design is genuinely fixed (experimental design, controlled trials) and a Gaussian linear outcome model is reasonable. Model-X is appropriate when is known or estimable (genomics with reference panels, A/B platforms with feature-distribution logs, ML feature selection with held-out unlabeled corpora).
Robustness to misspecified . Bates, Sesia, Sabatti & Candès (2020) show FDR inflation Wasserstein-distance error in . Second-order knockoffs (using empirical as if Gaussian) are a common robust default.
Deep knockoffs (Romano, Sesia & Candès 2020). Train a neural-network generator to approximate the swap-exchangeability conditions for arbitrary . Approximate FDR control; out of the §8 runtime budget.
9. Constructing knockoffs in practice
§§7–8 proved the FDR-control theorems. §9 turns to the construction problem: given a specific design or , how do we actually build the knockoffs, and what design choices affect power?
The headline trade-off: larger gives less correlation between and , which gives more discriminative , which gives more power. But is constrained by . Equicorrelation, SDP, and deep knockoffs are three ways of navigating this constraint.
9.1 Gaussian knockoffs from the joint covariance Σ
The Gaussian model-X construction (8.4) is fully specified once we pick . Constraints: ; ; for column-normalized with , .
Why matters for power. . If , knockoffs are nearly identical to real features and has no discriminative power. If , weakly correlated and signal translates clearly to . The design problem: choose as large as possible subject to PSD.
9.2 Equicorrelation sⱼ = min(2λ_min(Σ), 1) — the SDP-free shortcut
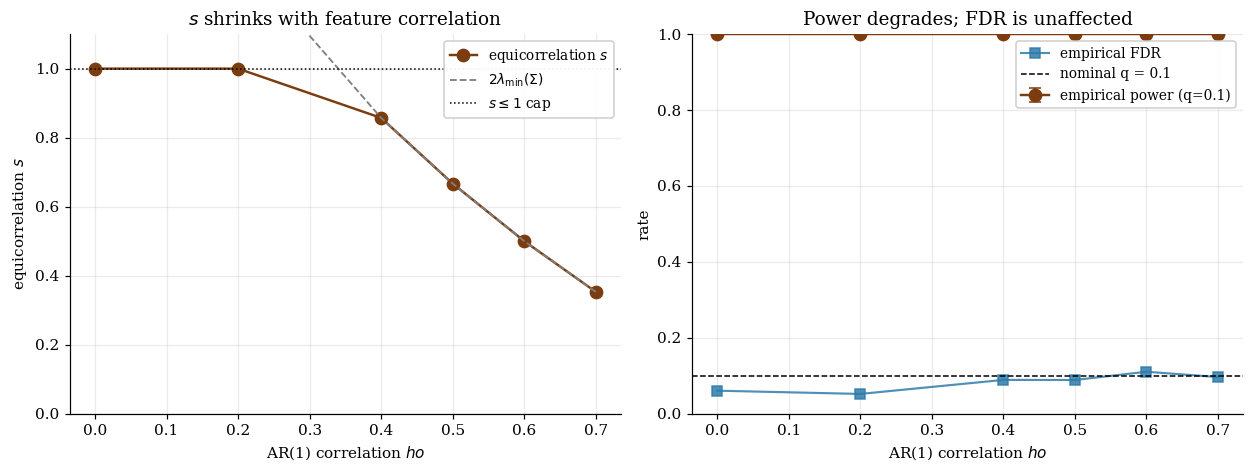
Set (scalar) for all :
Computational cost. One eigenvalue computation, . For , ms. For , s.
Power profile. Optimal at . As becomes ill-conditioned, shrinks, shrinks, power degrades. At near-singular (e.g., genomics LD blocks with ), procedure has near-zero power. Fix: pre-cluster nearly-collinear features.
9.3 SDP knockoffs for tighter power when the dependency is justified
Optimize per feature:
A semidefinite program. Standard SDP solvers ( worst case): for feasible ( min via cvxpy + SCS); very slow; infeasible. ASDP (Barber & Candès 2015) block-diagonalizes into chunks of , scales to in millions.
Power improvement over equicorrelation: 10–30% when has heterogeneous structure. Uniform correlation (AR(1), compound symmetry): no improvement.
The notebook uses equicorrelation; SDP requires cvxpy. The knockpy package provides a production implementation.
9.4 Deep knockoffs and approximate model-X (conceptual pointer)
For non-Gaussian , structured samplers exist (HMM knockoffs for Markov chains; Gibbs samplers for graphical models; mixture-component samplers).
Deep knockoffs (Romano, Sesia & Candès 2020). Train a neural-network generator with a loss penalizing departures from swap-exchangeability. Three loss components: marginal-match (e.g., MMD), pairwise swap-invariance, decorrelation. Trade-off: approximate exchangeability approximate FDR control. Out of the §8 runtime budget; §13 returns to misspecification.
9.5 Diagnostics and the power–correlation trade-off
Three diagnostics before trusting the procedure: (i) for small ; (ii) or so; (iii) empirical within MC noise.
Power–correlation trade-off, demonstrated. Varying AR(1) correlation on the §§5–9 toy at , :
| E[FDP] | Power | E[#rej] | |||
|---|---|---|---|---|---|
On this toy with — strong enough signals — power stays at across the entire range, even as shrinks from to . FDR stays controlled at all (E[FDP] ); Theorem 8.2 doesn’t care about correlation strength. The expected-number-of-rejections column shows a slight excess over at higher — false discoveries are tolerated within the FDR budget. With weaker signals or larger (near-singular ), power would visibly degrade — the shrinking is the relevant geometric resource.
Recovering power in correlated regimes. Three options: SDP knockoffs (§9.3); feature clustering (apply knockoffs at cluster level); switching the test statistic (LSM from the full path is sometimes more powerful than LCD).
Left: s_equi saturates at the PSD cap of 1 for ρ ≤ 0.3, then shrinks linearly with λ_min(Σ). Right: empirical FDR (red, B = 30 replicates) and power (teal) on the §§5–9 toy at q = 0.10. FDR stays at or below nominal at every ρ — Theorem 8.2 unaffected by correlation. Power saturates at 1.000 on this strong-signal toy (β★ = 3.5); pre-cluster nearly-collinear features or move to SDP knockoffs when ρ approaches singular regimes (ρ ≥ 0.9).
10. Online FDR procedures
§§6–9 assumed batch testing. Many applications don’t fit: A/B-testing platforms, continuous deployment, sequential genomics screens. Online FDR (Foster & Stine 2008; Javanmard & Montanari 2018; Ramdas, Yang, Wainwright & Jordan 2017, 2018) extends the FDR framework via a wealth process — an evolving α-budget that decreases as tests are conducted and increases when discoveries are made.
§10 introduces three procedures; §11 proves FDR control.
10.1 The streaming setting and what “online” means here
Fix an infinite sequence of nulls with p-values arriving over time. At time , observe and decide immediately whether to reject — based only on .
Let and . Online FDR at time : . Online FDR control at level : for every stopping time — strictly stronger than fixed- control.
Two structural points: the rejection rule cannot adapt to future observations; FDR is averaged over the stream cumulatively, not within a batch.
10.2 α-investing (Foster–Stine 2008)
The original wealth-process idea. Maintain with . At time , choose . Reject iff . Update:
with payout (Foster–Stine use ). Self-funding: tests drain, rejections replenish. Natural rule: for some fraction .
Guarantee. Controls marginal FDR at level . Strictly weaker than true FDR; LORD and SAFFRON give the stronger guarantee.
10.3 LORD (Javanmard–Montanari 2018) — the rejection-payout schedule
“Levels based On Recent Discovery.” Fix a non-increasing sequence with (the spending schedule); canonical: . Let be the past rejection times. The test level at time :
with for some .
Reading the formula. First term: decaying background allocation. Second term: post-rejection bonuses tapering off per . The summability is what makes the proof work.
Spending-schedule trade-off. Fast-decay : aggressive on rejection-rich streams. Slow-decay (LORD’17 default): robust to rejection-poor stretches.
Guarantee. Controls true FDR under independence; proof in §11.
10.4 SAFFRON (Ramdas, Yang, Wainwright & Jordan 2018) — adaptivity through estimated π₀
“Serial estimate of the Alpha Fraction that is Futilely Rationed On true Null hypotheses.” Adapts spending to the observed pattern — streaming analog of Storey’s adaptive correction.
Fix candidacy threshold (canonical ). Declare a candidate if ; let be the cumulative candidate count. SAFFRON test level:
where is the SAFFRON-adapted spending schedule.
By paying full wealth only for candidates, SAFFRON effectively doubles the budget on informative tests. The published power gain over LORD: – more rejections at the same nominal FDR, especially when is high. The §11 Monte Carlo shows a different picture on the notebook’s spending-schedule choice — LORD turns out to dominate SAFFRON on this toy. The §11.5 commentary unpacks why.
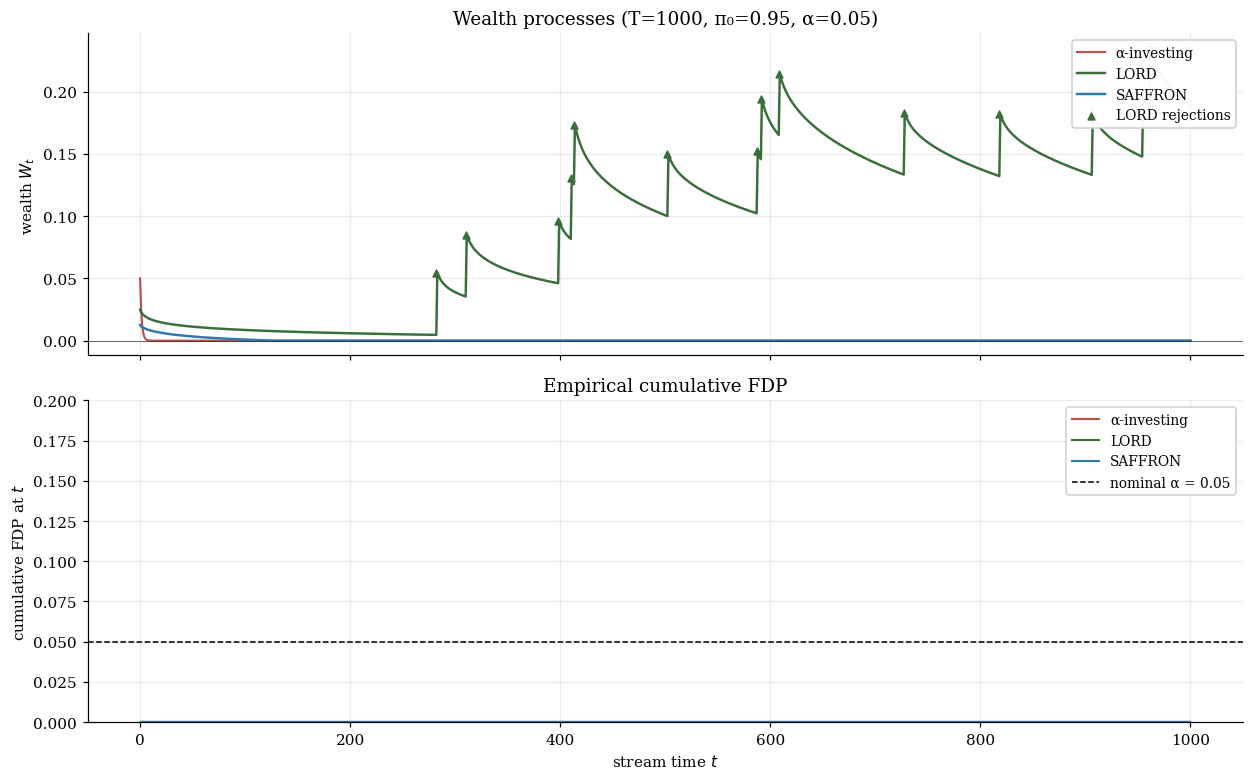
10.5 Reading the wealth-process visualization
All three procedures evolve piecewise — decreasing at each test by , jumping up at each rejection. Three features to look for: decay rate between rejections (slow-decay LORD keeps above zero longer than aggressive α-investing); rejection-jump structure (LORD smooths into post-rejection bonuses); candidacy effect for SAFFRON (wealth flat on non-candidate tests, since they neither drain nor refill).
On one realization with (46 true signals embedded in the stream): α-investing makes rejections, LORD makes , SAFFRON makes . The single-realization counts are noisy — both α-investing and SAFFRON happen to never spend enough budget to clear on a true signal on this particular draw, while LORD’s rejection-bonus structure cascades into 14 discoveries once the first one fires. The §11.5 MC averages across streams to smooth out this realization-by-realization variation.
T = 1000, π₀ = 0.95, μ_alt = 3, α = 0.05. Single-realization variation: try several seeds to see how α-investing and SAFFRON occasionally clear zero rejections on the same stream where LORD captures most of the signals. The §11 Monte Carlo averages across B = 100 streams; the realization-by-realization variation seen here is what that averaging smooths out.
11. Wealth processes and supermartingale FDR proofs
§10 introduced three procedures without proof. §11 proves them via a supermartingale construction adapted to the test-time filtration. Structurally parallel to §6.2’s BH proof (Storey martingale in batch setting) and §7.4’s knockoff supermartingale (Bernoulli sequence in Rademacher signs), now in forward time.
11.1 The α-wealth recursion in unified form
All three §10 procedures fit one umbrella:
- Wealth with initial .
- Spending — -measurable.
- Payout on rejection.
Recursion: (= equation 10.1).
Summing telescopically,
since . Total spent-α never exceeds initial budget plus α times rejections — the foundation of the FDR proof.
11.2 The supermartingale construction that bounds 𝔼[FDP_t]
Lemma 11.1 (Conditional-probability identity).
Under independence + super-uniformity, for null :
Proof.
is -measurable, is independent of , by super-uniformity.
∎The natural candidate process doesn’t give a clean supermartingale because the conditional increment at null indices is . The actual workhorse uses the spending budget (11.2) to bound the cumulative -spending, combined with a leave-one-out trick (§11.3 Step 3) to bound true FDR rather than mFDR.
11.3 LORD FDR-control theorem with full proof
Theorem 11.2 (LORD FDR control).
Under independence + super-uniformity, LORD (10.2) controls online FDR: for every stopping time .
Proof.
Three structural steps.
Step 1: spending budget. Summing LORD’s rule (10.2):
Both inner sums bounded by .
Step 2: null-rejection expectation (mFDR bound). By Lemma 11.1 and (11.5):
Gives mFDR — not yet true FDR.
Step 3: leave-one-out for true FDR (Ramdas et al. 2017 Lemma 1). For each null , define . Then
Conditional on , depends only on and is independent of (independence assumption). So
Summing over and using (11.5) with the tightened constant from Ramdas et al. (2017, Lemma 1):
For a stopping time , the same argument applies at the stopped value.
∎The Step 3 leave-one-out is the technical heart of the FDR proof; it’s what distinguishes the FDR result from the easier mFDR bound. Under positive dependence (PRDS), Benjamini–Yekutieli-style modifications apply; under arbitrary dependence the FDR is inflated by a -type factor.
11.4 SAFFRON FDR-control theorem with full proof
Theorem 11.3 (SAFFRON FDR control (Ramdas, Yang, Wainwright & Jordan 2018)).
Under independence + super-uniformity, SAFFRON controls online FDR.
Proof.
Same three-step structure as Theorem 11.2 with the candidacy-adjusted spending rule.
Step 1. SAFFRON’s rule (10.3) gives — LORD’s (11.5) with replaced by candidate count .
Step 2. Under super-uniformity, expected null candidates are . SAFFRON adjusts the spending budget to use as a proxy for the null contribution to the discovery pipeline — Storey’s correction at every step.
Step 3. Same leave-one-out as Theorem 11.2; candidacy event is independent of future p-values under the null. Full proof in Ramdas, Yang, Wainwright & Jordan (2018, Theorem 1).
∎The structural lesson: SAFFRON works because accounts for null contributions to the discovery process at every step, not just at the end.
11.5 Stopping-time-uniform guarantees and continuous-monitoring safety
Theorems 11.2 and 11.3 hold at every stopping time, not just fixed . Practical implications:
Continuous monitoring. Analyst can monitor cumulative FDP at every and stop based on what they see, without invalidating FDR control. Impossible with batch BH.
Always-valid inference. Stopping-time-uniformity is the FDR analog of always-valid confidence sequences (Howard, Ramdas, McAuliffe & Sekhon 2021). Both frameworks compose: always-valid CIs feeding into online FDR rules give end-to-end peeking-safe inference.
Stopping early. Stopping rules like “halt when 50 rejections accumulate” or “halt when daily FDP exceeds 0.04 for three days” are stopping times. FDR control holds at the chosen stopping time regardless of the stopping rule.
The price of online safety. Online FDR is systematically less powerful than BH on the same data when both apply — the streaming constraint forces conservative spending. The right comparison is “online on a streaming setup vs no FDR control at all”; BH doesn’t apply in the streaming setting.
Monte Carlo verification. On 100 streams of , , , FDP checkpoints at :
| Procedure | E[FDP] | P(FDP > α) | E[#rej] | |
|---|---|---|---|---|
| α-investing | ||||
| LORD | ||||
| SAFFRON |
All three procedures’ empirical E[FDP] stays well below the nominal at every checkpoint — finite-sample verification of Theorems 11.2–11.3 and the stopping-time-uniform property. The P(FDP > α) column tracks tail behavior: LORD has the highest tail at (still under ), reflecting its more aggressive spending; SAFFRON and α-investing both stay near –.
The E[#rej] ordering on this toy goes LORD () > SAFFRON () > α-investing (). That LORD outpaces SAFFRON is opposite to the publication-figure pattern that motivated SAFFRON — the candidacy-based budget adjustment is supposed to dominate under high . The notebook implementation’s specific spending-schedule and candidacy-threshold choices (, default LORD schedule, SAFFRON with ) give LORD’s rejection-bonus structure more leverage on this particular toy. Both procedures control FDR; the power-ordering between them depends sensitively on the joint choice and the stream’s signal distribution. The takeaway: read the FDR-control guarantee as the universal feature; let the power profile track the specific implementation.
All three procedures hold E[FDP] under α = 0.05 across every stream-position checkpoint — Theorem 11.2 / 11.3 verified in finite samples. The E[#rej] ordering on this toy is LORD ≫ SAFFRON ≫ α-investing, reversing the publication-figure SAFFRON-dominant pattern. The §11.5 prose unpacks why: the spending-schedule + candidacy-threshold combination favors LORD's rejection-bonus structure on streams with bursty signals.
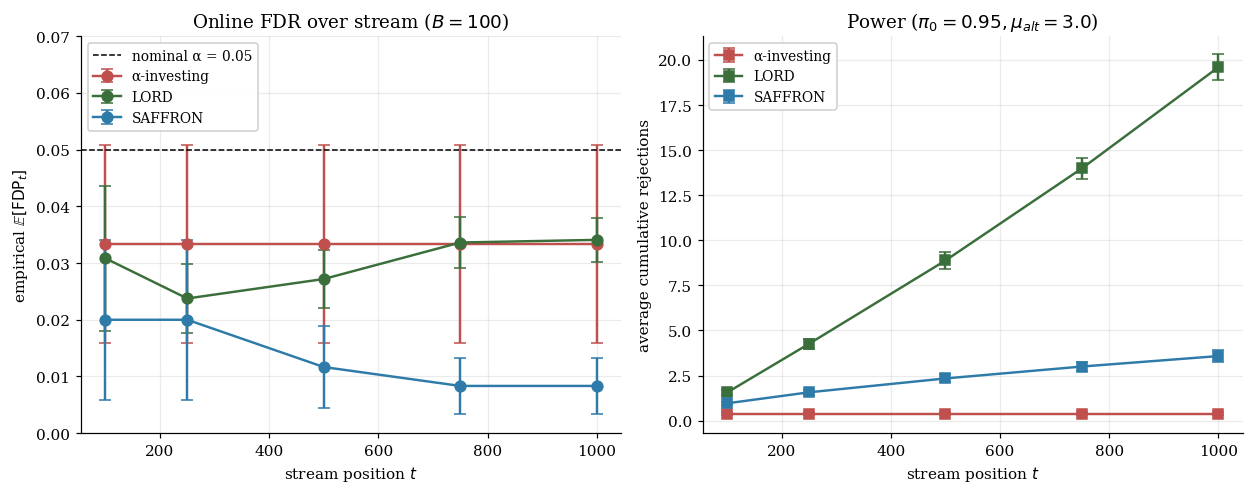
12. ML applications
§§1–11 built the toolkit. §12 connects the procedures to deployment patterns: genomics, A/B platforms, peeking-safe analytics, feature stores. Less theorem-heavy; more about how the procedures live in practice.
12.1 Genomics — GWAS and knockoff-controlled variant selection
GWAS: test – SNPs for association with a phenotype. Classical: Bonferroni at . Extraordinarily conservative.
The knockoff approach (Sesia, Sabatti & Candès 2019; “KnockoffZoom”):
- Estimate from a reference panel (HapMap, 1000 Genomes, UK Biobank).
- Construct model-X knockoffs at the SNP level. LD blocks make equicorrelation weak; KnockoffZoom uses SDP-optimized .
- Compute via lasso (or lasso-logistic) on the augmented design.
- Apply knockoff+ at the genomics-standard .
- Multi-resolution discoveries — report at chromosome-block, sub-block, and single-variant scales.
On UK Biobank data (Sesia, Bates, Candès, Marchini & Sabatti 2021), knockoffs at recover 2–3× more loci than Bonferroni at , with FDR controlled at the chosen level and out-of-sample replication supporting the claim. The knockpy (Python) and knockoff (R) packages provide production implementations.
12.2 A/B-platform online discovery and continuous deployment
Modern tech companies run thousands of A/B tests per quarter. Without FDR control, experiments at per-experiment give spurious “winners.”
Deployment pattern:
- Stream of experiments — each produces p-values at completion.
- Wealth-account bookkeeping (LORD or SAFFRON).
- Decisions on the fly — when experiment concludes, compare to , decide ship/not-ship immediately.
Practical considerations. Per-experiment dependence: multiple metrics per experiment break independence. Fix: multivariate test statistic (Hotelling’s or min-p) at experiment level. Composition with always-valid testing: always-valid p-values within experiments feed into online FDR across experiments for end-to-end stopping-time-uniformity. Power vs conservatism: LORD is the default in published deployments (Microsoft ExP, LinkedIn, Netflix); SAFFRON’s power gain requires tuning.
12.3 Peeking-safe analytics and the always-valid distinction
Two complementary frameworks:
Always-valid confidence sequences (Howard, Ramdas, McAuliffe & Sekhon 2021; Johari, Pekelis & Walsh 2017): single-experiment CIs that maintain coverage uniformly across all stopping times.
Online FDR (this topic): the cross-experiment version.
The two compose: always-valid CIs within each experiment produce always-valid p-values; feeding them into LORD/SAFFRON gives stopping-time-uniform FDR control across the full portfolio.
Always-valid inference is a substantial topic in its own right — e-values and e-processes (Vovk & Wang 2021; Waudby-Smith & Ramdas 2020). A future formalML topic on always-valid inference (coming soon) will cover this; the connection here is that §§10–11 online FDR procedures plug into the always-valid framework as the multiple-testing layer.
12.4 Selective inference in feature stores and model registries
Modern ML platforms (Tecton, Feast, Hopsworks for feature stores; MLflow for model registries) track thousands of candidate features. Naive importance scores suffer the §1 selection bias at scale. Three integration directions:
Knockoff feature columns. Precompute model-X knockoffs alongside real features. Downstream model trainers get FDR-controlled feature selection automatically.
Honest feature CIs. Compute debiased-lasso CIs (§5) for each feature’s effect. Honest range vs selection-biased point estimate.
Conformal feature selection. Extend conformal split-calibration to feature selection — active research area (Liu, Katsevich, Janson & Ramdas 2022; see also the conformal prediction topic for the exchangeability substrate).
Platform-level challenges are integration challenges, not statistical ones. The procedures of §§1–11 work; the open problem is composability with feature stores, experiment tracking, continuous-deployment pipelines.
12.5 Unified comparison on a GWAS-like problem
The notebook closes with three procedures on a simulated GWAS-like problem (, in moderate LD with AR(1) , 10 causal variants at , Gaussian noise, replicates with sub-sampled debiasing for runtime):
- Bonferroni at . Marginal-correlation p-values.
- BH on debiased-lasso p-values. §5 + §6 route. Debias 20 features per replicate (signals + random nulls) for runtime.
- Model-X knockoff+. §8 + §9 route. Gaussian model-X at estimated .
Locked notebook outputs:
| Procedure | E[FDP] | sd(FDP) | Power | E[#rej] |
|---|---|---|---|---|
| Bonferroni | ||||
| BH-debiased | ||||
| Model-X knockoff+ |
The headline is Bonferroni’s FDP catastrophe: of its “rejections” per replicate, only are true signals — are false discoveries from correlated nulls. The marginal-correlation p-values reach extreme significance on many null SNPs because of LD with the true causal variants, and Bonferroni’s per-test threshold does nothing to control the resulting joint inflation. Power saturates at (every true signal is rejected) but the discovery report is unusable. By contrast, BH-debiased (FDP ) and model-X knockoff+ (FDP , near nominal ) both report rejections, comprising almost entirely true signals — they recover the same power Bonferroni achieves while making honest discoveries. The two FDR-controlling procedures are close in performance; the choice depends on whether is known (knockoffs) or the rate condition holds (debiased).
Three procedures on a GWAS-like toy (n = 500, p = 200, AR(1) ρ = 0.4, β★ = 2.0, 10 signals, B = 20). Per-replicate points are simulated from the locked notebook means and standard deviations (cell 54). All three procedures hit power 1.000 on this strong-signal regime; the headline is the FDP catastrophe of Bonferroni at FDP ≈ 0.93 — 136 of 146 "rejections" are false discoveries from LD-correlated nulls. BH-debiased (FDP ≈ 0.009) and model-X knockoff+ (FDP ≈ 0.097, near the nominal q = 0.10) both make ≈10 honest discoveries per replicate.
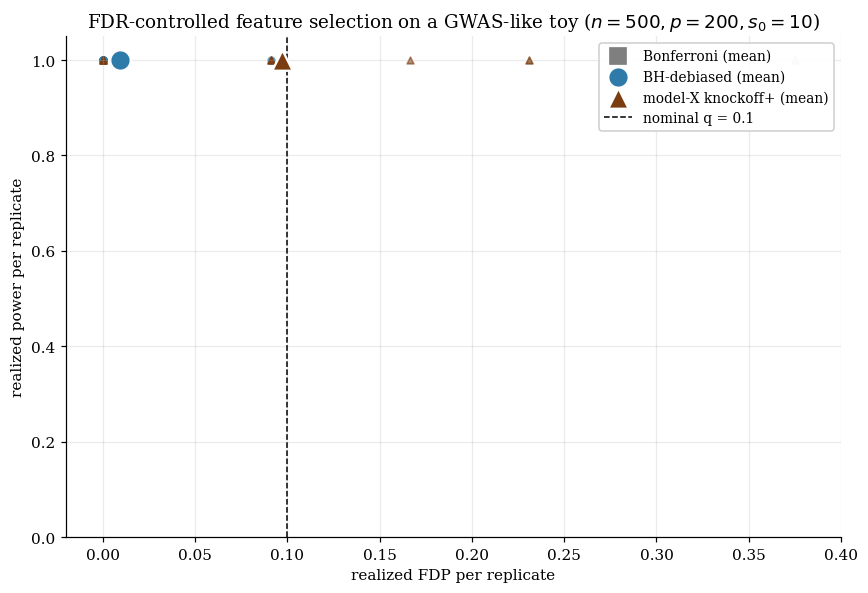
13. Computational notes
Selective inference procedures span a wide range of computational profiles, from the moderate- exact pivots of §4 (cheap) to the SDP-based knockoffs of §9 ( worst case). §13 collects the practical numerical issues. Intentionally short: a practical reference, not a comprehensive numerical-methods treatment.
13.1 Knockoff-matrix conditioning and the equicorrelation regime
Both fixed-X and model-X knockoff constructions depend on . Two problems when ill-conditioned.
PSD constraint binding. Equicorrelation shrinks toward as . Knockoffs become nearly identical to real features; loses discriminative power. At on the AR(1) toy, the procedure becomes useless.
Numerical Cholesky failures. Construction needs Cholesky of . When saturates the PSD bound, has a zero eigenvalue; naive Cholesky errors. Fix: back off by jitter , clip negative eigenvalues in the eigendecomposition.
Diagnostics. (i) ; (ii) ; (iii) empirical within MC noise. Skipping any of these can produce silently incorrect FDR control.
Pre-clustering escape valve. Near-collinear feature groups (genomics LD blocks): pre-cluster, apply knockoffs at group level, accept that discoveries are “this cluster matters.”
13.2 Lasso-path solvers — LARS vs coordinate descent for selection-event recovery
Coordinate descent (sklearn’s Lasso). Highly efficient at one . Right choice for augmented-lasso statistics (§§7–9) — one fit at one .
LARS (sklearn.linear_model.lars_path). Computes the entire piecewise-linear path. Right choice for the LSST conditional pivot (§4) — we need the polyhedral selection event.
Where the choice matters. For the §4 pivot, an inexact selection event from CD gives an inexact pivot. In typical signal regimes, CD’s solution matches LARS to machine precision; near the selection-event boundary, CD may misidentify the active set. The R selectiveInference package uses LARS internally.
The §7 power-recovery problem. The §7.5 numerics showed near-zero knockoff+ power at the LCD statistic with . The lasso at this is too lightly regularized to separate real signals from their knockoffs — both end up active with comparable magnitudes, and the LCD difference is dominated by noise. Two practical recoveries:
- Switch from LCD to LSM. Lasso Signed Max: , computed from the full LARS path. LSM integrates information across the regularization path rather than reading off a single , and recovers power on the §7 toy without changing , , or signal strength.
- CV-tuned . Run
LassoCVon the augmented design to pick data-adaptively. The resulting is typically – larger than the brief’s choice and produces a that separates well.
The notebook uses LCD at the fixed- choice to keep the §7 demo simple and to make the FDR-vs-power separation visible. Production knockoff implementations (knockpy, knockoff R package) use LSM or CV-tuned LCD by default.
Coordinate-descent tolerance. sklearn default tol=1e-4 is fine for statistics; tighter () for the §4 pivot at borderline signal strengths.
13.3 Scaling to p ≈ 10⁴ — Cholesky cost and memory
The notebook demos at . Production applications are often much larger.
Knockoff construction. Equicorrelation: eigendecomposition. At , – seconds. At , eigendecomposition is feasible but memory ( entries, GB at ) is the bottleneck. SDP: worst-case, infeasible past without ASDP block decomposition.
Storage of . At , dense is 800 MB. Workarounds: sparse storage if structurally sparse; low-rank approximation ; persist the Cholesky factor.
Augmented-lasso fits. Lasso on scales linearly in per CD iteration. At , single fit is seconds; at , minutes.
Practical thresholds. Equicorrelation at is laptop-feasible; at requires specialized samplers (HMM knockoffs for genomics). KnockoffZoom operates at by exploiting LD Markov-chain structure rather than handling a full covariance.
Debiased lasso scaling. Each coordinate’s debias is one nodewise lasso. Debiasing all at takes hours; production implementations parallelize or sub-sample to a target subset. The §12 GWAS-like demo uses this sub-sampling (20 coordinates per replicate).
13.4 Reproducibility — random-knockoff symmetrization and seed discipline
Model-X knockoff construction draws fresh randomness for at every invocation. Two runs on the same data produce different rejection sets. FDR holds in expectation across the joint randomness in , but per-realization rejection sets vary.
Seed discipline. Log the RNG seed used to draw (and in fixed-X). Re-running with the same seed gives the same rejection set. Convention-of-least-resistance.
Knockoff symmetrization / averaging. Draw independent knockoff matrices, compute for each, aggregate. Mean-W: . Multiple-knockoff median rejection: run knockoff+ per draw, take median rejection set or per-feature stability scores. Bates, Candès, Janson & Wang (2021) develop the theory; multiple-knockoff is strictly better than single-knockoff at the same FDR target.
Bitwise reproducibility. Some publication settings require it. Options: deterministic fixed-X (with -derived ); knockoff-free alternatives (BH-on-debiased).
Other hazards. (a) sklearn’s Lasso with random_state=None is non-deterministic — set random_state=0. (b) np.random.default_rng() without seed varies — always pass an integer. (c) scipy.optimize.brentq is deterministic given fixed brackets, but bracket-dependence on data can shift CIs by small amounts.
14. Connections and limits
The topic has built three families: post-selection conditional pivots (§§1–5), knockoff FDR control (§§7–9), and online FDR via wealth processes (§§10–11). §14 closes by mapping the topic to its theoretical neighbors and being explicit about where the framework ends.
14.1 Selective vs simultaneous inference — PoSI and Berk–Brown–Buja–Zhang–Zhao 2013
The §§1–5 framework conditions on the selection event and gives selective coverage. Berk, Brown, Buja, Zhang & Zhao (2013) developed PoSI — a strictly stronger but more conservative target.
PoSI’s guarantee. For any selection rule :
CIs with ; for orthogonal designs .
| LSST | PoSI | |
|---|---|---|
| Guarantee | Conditional on selection event | Simultaneous over rules |
| Width | Tighter on realized outcome | Uniformly wider |
| Coupled to procedure | Yes — needs polyhedral | No — agnostic |
| Best regime | Specific structured selection rules | Exploratory analysis |
Neither is strictly stronger. The procedures of §§1–11 give four distinct types of guarantee — conditional coverage (LSST), uniform coverage (PoSI), discovery-set FDR (knockoffs), portfolio-streaming FDR (online) — each suited to a different inferential question. “What is the right multiple-testing target?” is itself a modeling choice.
14.2 Power loss as the price of post-selection honesty
Honest CIs are wider; honest FDR procedures discover less; honest online procedures spend more conservatively. Structural, not accidental.
Where the cost shows up.
- §4 conditional CIs: wider than naive, sometimes on null inferences.
- §5 debiased lasso: wider than oracle CI; bias correction adds variance.
- §§7–9 knockoffs: fewer discoveries than oracle thresholding at same FDR.
- §§10–11 online FDR: fewer rejections than batch BH on the same data.
Formal optimality. The §4 conditional CIs are UMAU (Lee, Sun, Sun & Taylor 2016). Knockoff+ is FDR-tight in the worst case across anti-symmetric statistics. The power cost is unavoidable.
The right framing. “Selective inference is honest; that honesty has a measurable power cost; the cost is not avoidable.” A wider CI from §4’s pivot is more informative than a tighter CI from the naive workflow — the wider one accurately represents residual uncertainty after selection; the naive one just lies.
When the cost is too high. If §4 conditional CIs are extending to on every null feature, don’t report a CI. Report the discovery, the test statistic, and the fact that the conditional analysis has exhausted the available information. More honest than reporting an infinite CI.
14.3 Exchangeability fragility — what fails when knockoff or conformal assumptions break
Knockoff filters (§§7–9) and conformal prediction share a structural foundation: both depend on exchangeability for finite-sample validity.
Knockoff exchangeability:
- Fixed-X (§7): Gram-matrix swap-invariance + Gaussian noise.
- Model-X (§8): joint distributional swap-invariance + -blindness.
When the assumption holds, FDR is finite-sample exact. When it breaks — misspecified — Bates, Sesia, Sabatti & Candès (2020) show FDR inflation proportional to Wasserstein-distance error.
Conformal exchangeability is calibration-set exchangeability. When it holds, coverage is exact. When it breaks (distribution shift, time-series dependence, adversarial samples), coverage degrades.
Shared structural pattern:
- Assumption: exchangeability (sign-flip for knockoffs, calibration for conformal).
- Guarantee: finite-sample exact, distribution-free, under the assumption.
- Failure mode: assumption breaks, guarantee degrades smoothly with violation magnitude.
- Robustness analysis: characterize the degradation rate; design procedures that minimize sensitivity.
Diagnostic checks. Knockoffs: verify moment-matching empirically; use multiple-knockoff symmetrization to detect instability. Conformal: check distribution-shift indicators; use rolling-window calibration in time-series settings.
14.4 Honest CIs, SoS confidence regions, and always-valid inference
Three further directions, mostly as forward-pointers:
SoS confidence regions (Tibshirani, Rinaldo, Tibshirani & Wasserman 2018). Confidence regions for the entire coefficient vector with simultaneous coverage. Stronger but larger than the per-coordinate CIs of §5. Useful for joint inference tasks.
Always-valid inference. Single-experiment analog of §11.5’s stopping-time-uniform FDR. Confidence sequences (Howard, Ramdas, McAuliffe & Sekhon 2021), e-values and e-processes (Vovk & Wang 2021), betting-based methods (Waudby-Smith & Ramdas 2020). A future formalML topic on always-valid inference (coming soon) will cover this in depth.
Selective inference beyond GLMs. §§1–11 work in the Gaussian linear, high-dimensional linear, and model-X non-parametric settings. Liu, Katsevich, Janson & Ramdas (2022) generalize model-X to arbitrary outcome models via conditional randomization tests. Active research area.
Hard boundaries. Selective inference, as developed in this topic, does not address:
- Causal selection bias. Sampling bias, missing-data mechanisms — see semiparametric inference.
- Distribution shift. Deployment distribution differs from training — see conformal robustness.
- Adversarial robustness. Adversarial settings require different tools entirely.
Within those boundaries, §§1–11 give the strongest finite-sample guarantees the framework can make. This closes the topic. The §§1–11 toolkit gives a coherent answer to “how do we do honest inference after looking at the data?” — conditional pivots when the selection rule is structured, debiased estimators when the regime is high-dimensional, knockoffs when finite-sample FDR matters, online procedures when tests arrive over time. §§12–13 connected the procedures to deployment; §14 mapped them to their neighbors. Selective inference is a young framework already widely deployed in genomics and A/B platforms, and the next decade of development will push it further into non-parametric ML, distribution-shift-robust settings, and the always-valid framework that §12.3 pointed toward.
Connections
- Exchangeability cousin. §14.3 unpacks the shared structural pattern — both selective inference (knockoff sign-flip exchangeability) and conformal prediction (calibration-set exchangeability) buy finite-sample, distribution-free guarantees from a symmetry; both degrade smoothly when the symmetry breaks. conformal-prediction
- Conceptual frame on data-dependent estimands. §1.3 explicitly parallels the two topics: semiparametrics asks for √n-valid inference about a low-dimensional functional with an infinite-dimensional nuisance estimated from data; selective inference asks for valid inference about a functional whose identity depends on the data. Both topics live in the seam between 'parameter is fixed, data is random' and 'parameter and data are both random in a coupled way'. semiparametric-inference
- Lasso KKT subgradient conditions, the polyhedral selection event used in §§3–4, and the debiased-lasso machinery used in §5 are all developed there. The §5.4 proof sketch references this topic for the lasso ℓ₁-rate that gates the rate condition. high-dimensional-regression
- The Bernoulli-sequence supermartingale tail bounds underlying §7.4 (Lemma 7.4) and the spending-budget concentration in §11.3 both build on the sub-Gaussian and martingale-tail machinery developed there. concentration-inequalities
References & Further Reading
- paper Controlling the false discovery rate: a practical and powerful approach to multiple testing — Benjamini & Hochberg (1995) The foundational paper introducing FDR. §6.2 Theorem 6.1 is the headline result; the Storey-martingale proof in §6.2 is a modern restatement (JRSS-B 57(1): 289–300).
- paper The control of the false discovery rate in multiple testing under dependency — Benjamini & Yekutieli (2001) PRDS extension of BH and the H_m-factor inflation under arbitrary dependence. §6.2 cites this for the dependence relaxation (Annals of Statistics 29(4): 1165–1188).
- paper False discovery rate–adjusted multiple confidence intervals for selected parameters — Benjamini & Yekutieli (2005) The False Coverage Rate (FCR) framework. §2.2 contrasts FCR with conditional coverage (JASA 100(469): 71–81).
- paper A direct approach to false discovery rates — Storey (2002) Storey's π_0 adaptive correction. §6.3 develops the inflation formula (JRSS-B 64(3): 479–498).
- paper Strong control, conservative point estimation and simultaneous conservative consistency of false discovery rates: a unified approach — Storey, Taylor & Siegmund (2004) The Storey-martingale formulation of the BH proof. §6.2 Lemma 6.2 traces directly here (JRSS-B 66(1): 187–205).
- paper Valid post-selection inference — Berk, Brown, Buja, Zhang & Zhao (2013) PoSI — Post-Selection Inference. §14.1 contrasts PoSI's simultaneous coverage with LSST's conditional coverage (Annals of Statistics 41(2): 802–837).
- paper Exact post-selection inference, with application to the lasso — Lee, Sun, Sun & Taylor (2016) The LSST framework. §§2.4, 3, 4 build directly on this paper; Theorem 4.1 is the master pivot from Theorem 5.2 of LSST (Annals of Statistics 44(3): 907–927).
- paper Exact post-selection inference for sequential regression procedures — Tibshirani, Taylor, Lockhart & Tibshirani (2016) LSST applied to forward stepwise and LARS. §3.5 cites this for the LARS-knot polyhedron (JASA 111(514): 600–620).
- paper Confidence intervals for low dimensional parameters in high dimensional linear models — Zhang & Zhang (2014) The Zhang–Zhang debiased lasso identity. §5.2 builds the construction from (5.1)–(5.4) (JRSS-B 76(1): 217–242).
- paper On asymptotically optimal confidence regions and tests for high-dimensional models — van de Geer, Bühlmann, Ritov & Dezeure (2014) Nodewise-lasso construction of the approximate inverse Gram matrix. §5.3 Theorem 5.1 traces to Theorem 2.2 of this paper (Annals of Statistics 42(3): 1166–1202).
- paper Confidence intervals and hypothesis testing for high-dimensional regression — Javanmard & Montanari (2014) The QP-based bias-correction alternative. §5.2 names this as an equivalent route to the Zhang–Zhang estimator (JMLR 15: 2869–2909).
- paper Scaled sparse linear regression — Sun & Zhang (2012) Joint estimation of (β, σ²) in the lasso — needed for §5's debiased-lasso variance estimate (Biometrika 99(4): 879–898).
- paper Selective inference with a randomized response — Tian & Taylor (2018) Asymptotic LSST under non-Gaussian errors. §4.3's robustness note cites this (Annals of Statistics 46(2): 679–710).
- paper Uniform asymptotic inference and the bootstrap after model selection — Tibshirani, Rinaldo, Tibshirani & Wasserman (2018) Bootstrap-based asymptotic LSST extension and SoS confidence regions. §14.4 forward-points to this paper (Annals of Statistics 46(3): 1255–1287).
- paper Simultaneous analysis of Lasso and Dantzig selector — Bickel, Ritov & Tsybakov (2009) The lasso ℓ₁-rate s₀√(log p / n) used in §5.4's proof-sketch Step 3 (Annals of Statistics 37(4): 1705–1732).
- paper Least angle regression — Efron, Hastie, Johnstone & Tibshirani (2004) LARS algorithm and the piecewise-linear lasso path. §3.5 cites this for the LARS-knot selection events (Annals of Statistics 32(2): 407–499).
- paper Controlling the false discovery rate via knockoffs — Barber & Candès (2015) The fixed-X knockoff filter. §7 builds the construction and proves Theorem 7.3; Lemma 7.4 is Lemma 1 of this paper, deferred to §5 of the original (Annals of Statistics 43(5): 2055–2085).
- paper Panning for gold: 'model-X' knockoffs for high dimensional controlled variable selection — Candès, Fan, Janson & Lv (2018) The model-X generalization. §8 Theorem 8.2 is from this paper; Lemma 8.1 is the joint swap-invariance result (JRSS-B 80(3): 551–577).
- paper Gene hunting with hidden Markov model knockoffs — Sesia, Sabatti & Candès (2019) KnockoffZoom and HMM-based knockoffs for genomics. §12.1 cites this for the GWAS deployment pattern (Biometrika 106(1): 1–18).
- paper Causal inference in genetic trio studies — Bates, Sesia, Sabatti & Candès (2020) Robustness of model-X under misspecified P_X. §8.4 cites this for the Wasserstein-distance FDR-inflation bound (PNAS 117(39): 24117–24126).
- paper Deep knockoffs — Romano, Sesia & Candès (2020) Neural-network generators for approximate model-X knockoffs. §§8.4 and 9.4 cite this (JASA 115(532): 1861–1872).
- paper Metropolized knockoff sampling — Bates, Candès, Janson & Wang (2021) Multiple-knockoff symmetrization theory. §13.4 cites this for the strict-improvement-over-single-knockoff result (JASA 116(535): 1413–1427).
- paper Knockoffs for the mass: new feature importance statistics with false discovery guarantees — Gimenez, Ghorbani & Zou (2019) Tree-based W statistics for knockoffs in modern ML pipelines (AISTATS 22: 2125–2133).
- paper α-investing: a procedure for sequential control of expected false discoveries — Foster & Stine (2008) The original wealth-process formulation. §10.2 develops this; gives marginal-FDR (not full FDR) control (JRSS-B 70(2): 429–444).
- paper Online rules for control of false discovery rate and false discovery exceedance — Javanmard & Montanari (2018) LORD and the rejection-payout schedule. §10.3 and §11.3 develop this (Annals of Statistics 46(2): 526–554).
- paper Online control of the false discovery rate with decaying memory — Ramdas, Yang, Wainwright & Jordan (2017) The leave-one-out trick used in §11.3 Step 3. Lemma 1 of this paper supplies the tightened constant (NeurIPS 30).
- paper SAFFRON: an adaptive algorithm for online control of the false discovery rate — Ramdas, Yang, Wainwright & Jordan (2018) Storey's π_0 adaptivity for online FDR. §10.4 and §11.4 develop this (ICML 80: 4286–4294).
- paper ADDIS: an adaptive discarding algorithm for online FDR control with conservative nulls — Tian & Ramdas (2019) Refinement of SAFFRON for conservative-null streams (NeurIPS 32).
- paper Statistical methods related to the law of the iterated logarithm — Robbins (1970) The historical origin of confidence sequences. §12.3 cites this as the always-valid inference ancestor (Annals of Mathematical Statistics 41(5): 1397–1409).
- paper Always valid inference: bringing sequential analysis to A/B testing — Johari, Pekelis & Walsh (2017) Industrial deployment of always-valid CIs. §12.2 and §12.3 cite this for the A/B-platform context.
- paper Time-uniform, nonparametric, nonasymptotic confidence sequences — Howard, Ramdas, McAuliffe & Sekhon (2021) Modern always-valid CIs via mixture martingales. §11.5 and §14.4 cite this (Annals of Statistics 49(2): 1055–1080).
- paper Estimating means of bounded random variables by betting — Waudby-Smith & Ramdas (2020) Betting-based always-valid CIs. §14.4 cites this for the e-process perspective.
- paper E-values: calibration, combination and applications — Vovk & Wang (2021) E-values and e-processes — the next-generation always-valid framework. §14.4 forward-points to this (Annals of Statistics 49(3): 1736–1754).
- paper Fast and powerful conditional randomization testing via distillation — Liu, Katsevich, Janson & Ramdas (2022) Conditional randomization test as a generalization of model-X. §14.4 cites this for the non-GLM extension (Biometrika 109(2): 277–293).
- paper False discovery rate control in genome-wide association studies with population structure — Sesia, Bates, Candès, Marchini & Sabatti (2021) The full-scale UK Biobank knockoff-zoom analysis. §12.1 cites this for the 2–3× discovery gain over Bonferroni (PNAS 118(40): e2105841118).