Expander Graphs
Sparse graphs with paradoxically strong connectivity — from the Expander Mixing Lemma to Ramanujan optimality and O(log n) mixing
Overview & Motivation
The complete graph is well-connected in every sense: every pair of vertices shares an edge, every subset has a massive boundary, and a random walk mixes in a single step. But has edges — a quadratic cost that becomes prohibitive for large . Can we achieve the same qualitative connectivity with far fewer edges?
Expander graphs say yes. An expander is a graph that is simultaneously sparse (each vertex has bounded degree , independent of , so the total edge count is ) and well-connected (every vertex subset with has a boundary at least proportional to ). This combination sounds paradoxical: how can a graph with only edges avoid having bottlenecks? And yet expander families exist, can be constructed explicitly, and turn out to be optimal in a precise spectral sense.
Three equivalent perspectives capture the “no bottleneck” property:
-
Vertex expansion: Every set has many neighbors outside — the boundary is large relative to .
-
Edge expansion (the Cheeger constant): Every set has many edges crossing to the complement — the edge boundary is large relative to .
-
Spectral expansion: The second-largest eigenvalue of the adjacency matrix (in absolute value) is bounded away from the degree — the spectral gap is large.
Cheeger’s inequality links perspectives 2 and 3, showing they are quantitatively equivalent. The Expander Mixing Lemma makes expansion concrete: it controls the number of edges between any two vertex subsets in terms of , making the -expander formalism a workhorse for combinatorics and computer science. The Alon-Boppana bound establishes as a universal floor, and Ramanujan graphs — which achieve — are the provably optimal expanders.
These results connect directly to the spectral theory we developed in the prerequisite topics. In Graph Laplacians & Spectrum, Cheeger’s inequality linked the Fiedler value to the minimum edge cut. In Random Walks & Mixing, the spectral gap controlled the mixing time. Expanders are the graphs where both quantities are bounded away from zero uniformly in — the mixing time is regardless of the graph’s size, and the minimum cut grows linearly with the subset size.
Why should ML practitioners care? Expanders appear throughout theoretical computer science and increasingly in machine learning:
- Derandomization: The expander walk sampling theorem shows that a random walk on an expander produces nearly independent samples, reducing the randomness needed by algorithms from to bits.
- Error-correcting codes: Bipartite expanders yield linear-time decodable codes (Sipser-Spielman expander codes).
- Network design: Communication networks, sensor networks, and distributed systems benefit from expander-like connectivity.
- Graph neural networks: Expansion controls information flow in message-passing architectures — layers suffice to propagate information across the entire graph, but also cause over-smoothing.
Roadmap. We define the three expansion notions and compute them on named graphs (§1-2), prove their equivalence via Cheeger’s inequality (§3), derive the Expander Mixing Lemma with a full spectral proof (§4), establish the Alon-Boppana lower bound and define Ramanujan graphs (§5), construct explicit expanders from Cayley graphs and number theory (§6), prove the mixing time bound (§7), and survey applications to CS and ML (§8-9).
1. Three Notions of Expansion
The central idea of expansion is that every small-to-medium vertex subset has a large boundary. Different notions formalize “boundary” differently. We will define all three, compute them on familiar graphs, and then prove they are equivalent for families of regular graphs.
1.1 Vertex Expansion
The most direct notion counts how many new vertices a set can reach in one step.
Definition 1 (Vertex Expansion).
For a graph and a vertex subset , the vertex boundary of is , where is the neighborhood of . The vertex expansion ratio of is:
A graph has good vertex expansion if for some constant independent of . This means every set of size at most has at least neighbors outside — the graph has no isolated clusters.
1.2 Edge Expansion (the Cheeger Constant)
Instead of counting boundary vertices, we can count boundary edges.
Definition 2 (Edge Expansion (Cheeger Constant)).
For a -regular graph and a vertex subset , the edge boundary is . The edge expansion ratio (or Cheeger constant) is:
The Cheeger constant measures the minimum “surface-to-volume ratio” of any subset — a direct analogy with isoperimetric inequalities in geometry. A set with small edge boundary relative to its volume is a bottleneck: information (or random walkers) trapped inside must pass through a narrow gate to reach . Expanders are graphs with no such bottlenecks.
1.3 Spectral Expansion
The third perspective replaces the combinatorial min over subsets with a single algebraic quantity: the second-largest eigenvalue.
Definition 3 (Spectral Expansion and (n, d, λ)-Expanders).
Let be a -regular graph on vertices with adjacency matrix . Since is -regular, the largest eigenvalue is with eigenvector . The spectral expansion parameter is:
We call an -expander if it is -regular, has vertices, and .
The quantity is the largest eigenvalue in absolute value after the trivial eigenvalue . The smaller is, the better the expansion: the gap between and — the spectral gap — measures how far the graph’s spectrum deviates from the rank-1 pattern of the complete graph.
Why does the spectral gap control expansion? Recall from Graph Laplacians & Spectrum that the Laplacian eigenvalues of a -regular graph satisfy . So , and a large spectral gap in means a large Fiedler value — the graph is hard to cut. The connection to Random Walks & Mixing is equally direct: the transition matrix has eigenvalues , so the spectral gap of the walk is .
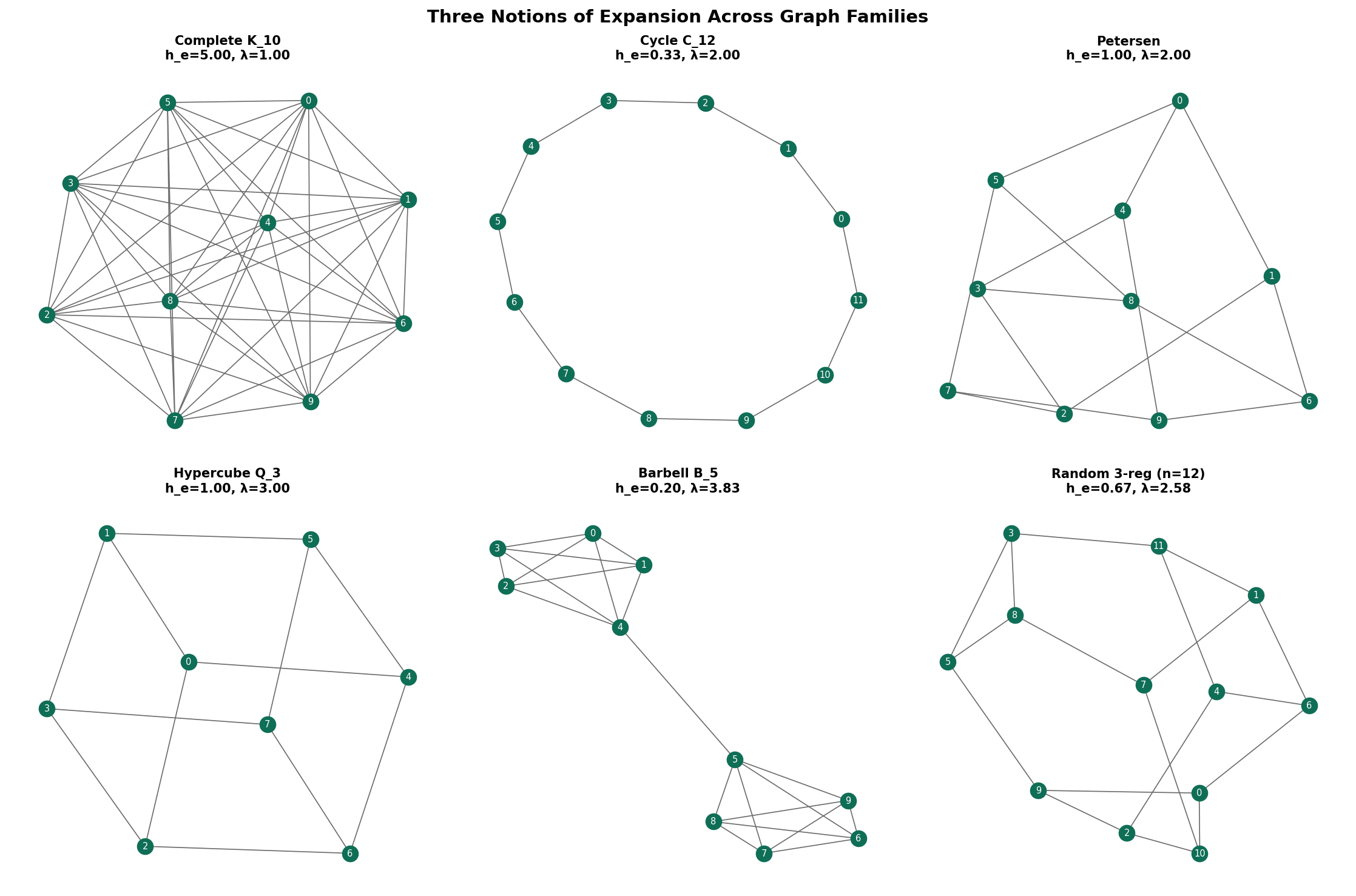
1.4 Examples: Expansion on Named Graphs
Let us compute all three expansion parameters for familiar graphs.
Complete graph (). Every vertex is adjacent to every other, so for any with :
- , giving .
- , giving .
- The adjacency eigenvalues are (once) and (with multiplicity ), so .
is an excellent expander spectrally (), but it is not sparse — the degree grows with .
Cycle (). The cycle is a 2-regular graph. Taking to be a contiguous arc of vertices:
- (the two endpoints of the arc), so .
- , so .
- The adjacency eigenvalues are for , so and .
The cycle is not an expander in any sense: all three parameters degrade as .
Petersen graph (, ). This remarkable 3-regular graph has:
- (every subset of size has at least as many external neighbors).
- (verified by exhaustive search over subsets).
- Adjacency eigenvalues: (once), (with multiplicity 5), (with multiplicity 4). So .
The Petersen graph is a good expander for its size. We will see shortly that actually meets the Ramanujan bound — it is a Ramanujan graph.
Hypercube (, ). The -dimensional hypercube has vertices with edges between strings differing in one bit. The adjacency eigenvalues are for , with multiplicity . So and .
The spectral gap is , which is constant — the hypercube is an expander family. Its edge expansion is (the edge-isoperimetric inequality for the cube), and the mixing time of a random walk is .
Barbell graph (, irregular). Two complete graphs joined by a single edge. The edge connecting them is a severe bottleneck: . The barbell is the canonical non-expander — a single edge cut isolates half the graph.
| Graph | Expander? | |||||
|---|---|---|---|---|---|---|
| Yes (not sparse) | ||||||
| No | ||||||
| Petersen | Yes | |||||
| Yes (degree grows) | ||||||
| Barbell | varies | No |
2. The Relationship Between Expansion Notions
Before proving the deep equivalence via Cheeger’s inequality, we establish a direct relationship between vertex and edge expansion.
Proposition 1 (Vertex vs. Edge Expansion).
For any -regular graph :
Proof.
Upper bound (). Let be any subset with . Every vertex in is connected to at least one vertex in by an edge, and each such edge contributes to . Therefore . Dividing both sides by and taking the minimum over gives .
Lower bound (). Each vertex in has degree , so it contributes at most edges to . (Some edges from a boundary vertex may go to other vertices in , but at most go anywhere.) Therefore . Dividing by and taking the minimum gives .
∎This tells us that vertex and edge expansion differ by at most a factor of . For constant-degree graphs (the setting we care about for expander families), the two notions are equivalent up to a constant.
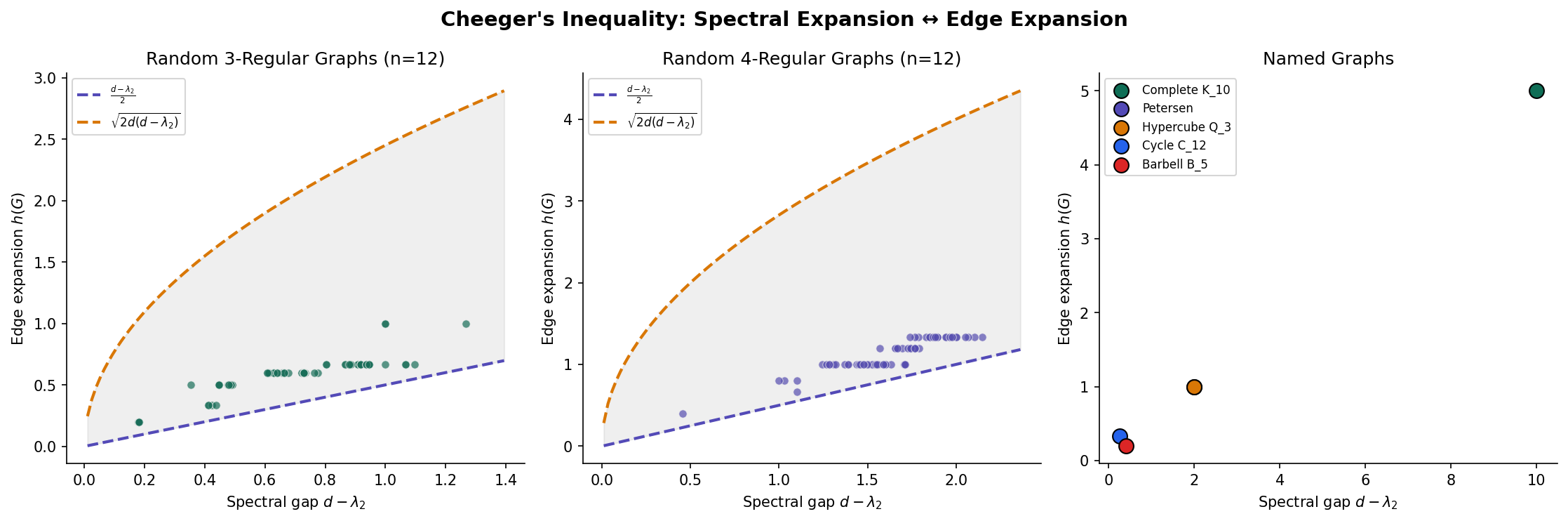
3. Cheeger’s Inequality: Linking Spectrum to Combinatorics
The crown jewel of spectral graph theory is Cheeger’s inequality, which asserts that the spectral gap and the Cheeger constant determine each other up to polynomial factors. We proved a version of this in Graph Laplacians & Spectrum; here we state and prove the version tailored to the adjacency matrix of regular graphs.
Theorem 1 (Cheeger's Inequality for Regular Graphs).
For a -regular graph with second-largest eigenvalue :
Proof.
We prove both directions.
Lower bound (“easy direction”): .
Let achieve the minimum in , so . Define the vector by:
This vector is orthogonal to the all-ones vector (the eigenvector for ):
By the Rayleigh quotient characterization of :
We compute each piece. For the denominator:
For the numerator, we use (summing over edges):
The difference is nonzero only when crosses the cut .
A more direct path uses the Laplacian quadratic form. Using the identity where , and recalling that :
since each cut edge contributes . Hence:
Rearranging:
where the last step uses , so . Dividing by :
Upper bound (“hard direction”): .
Let be the eigenvector of corresponding to , with and . We use to construct a “sweep cut.” Sort the vertices so that and consider the threshold sets for varying . We claim that at least one of these has .
Define for . For the sweep cut at threshold :
Using a Cauchy-Schwarz argument on the Rayleigh quotient:
The key insight is that by averaging over thresholds (a technique called the “sweep cut” analysis), we can show there exists a threshold such that:
The detailed argument proceeds as follows. For each edge with , the edge crosses the cut for all . By the Cauchy-Schwarz inequality:
and the integral of (counting vertices below ) relates to . Bounding the ratio of integrals and using the fact that is an eigenvector yields the claimed bound.
∎
Remark (Cheeger's Inequality is Tight).
Both sides of Cheeger’s inequality are achievable. The lower bound is tight for the complete bipartite graph , where , , and . The upper bound is tight for the cycle , where and up to constants.
Corollary 1 (Equivalence of Expansion Notions).
For a family of -regular graphs with fixed and , the following are equivalent:
- for some constant (vertex expansion).
- for some constant (edge expansion).
- for some constant (spectral expansion).
Specifically, any one of these conditions implies the other two, with the constants related by Cheeger’s inequality and Proposition 1.
Proof.
: If , then , so by the lower bound of Cheeger’s inequality, .
: By Proposition 1, .
: By Proposition 1, . (Actually, since each boundary vertex contributes at least one edge. Wait — we proved the bound , so .)
: If , then by the upper bound of Cheeger’s inequality, , so , giving , hence .
For the full spectral parameter , we need to also control . If the graph is non-bipartite (which it must be for edge expansion to be bounded away from 0 in a strong sense), then , and a similar argument using the set minimizing the Cheeger constant gives for some constant depending on .
∎This equivalence is why we can speak of “expander families” without specifying which notion of expansion — for constant-degree regular graphs, all three notions agree up to polynomial transformations of the expansion parameter.
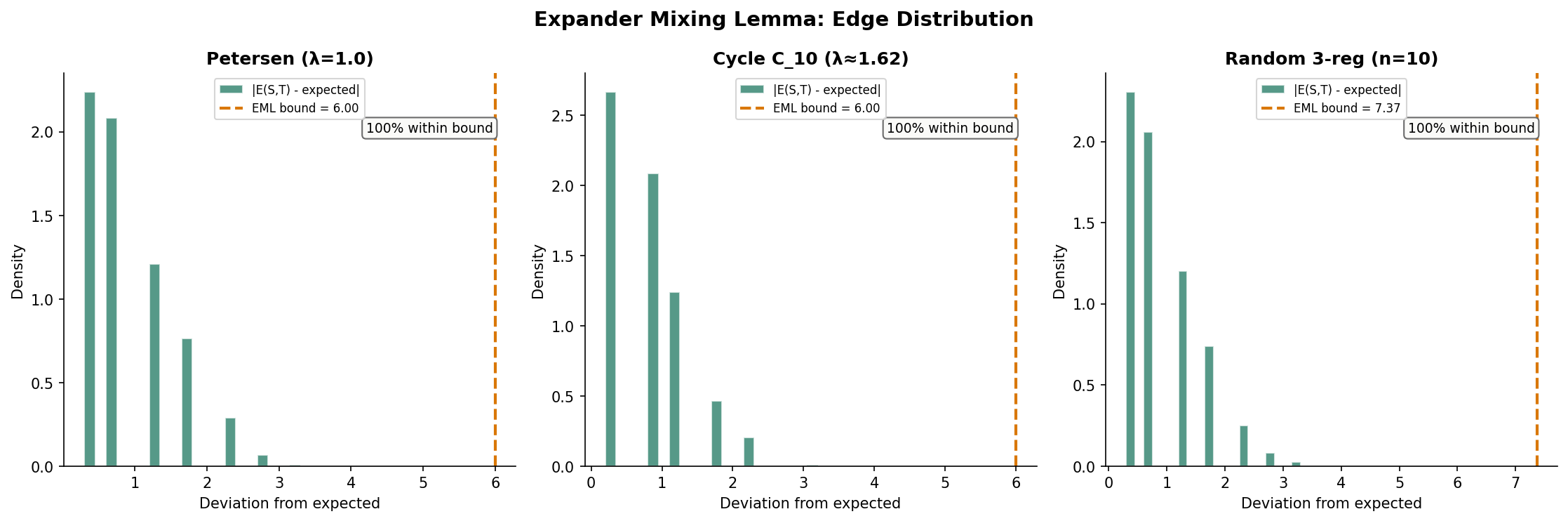
4. The Expander Mixing Lemma
The Expander Mixing Lemma (EML) is the most quantitatively useful consequence of spectral expansion. While the Cheeger constant controls cuts for the worst-case set , the EML controls the number of edges between any two sets and , making it a powerful tool for combinatorial arguments.
In a random -regular graph (or equivalently, in a -regular graph chosen uniformly from all edge configurations), the expected number of edges between two disjoint sets and is — each of the edge-endpoints in hits with probability roughly . The EML says that in an -expander, the actual count deviates from this expected value by at most .
Theorem 2 (Expander Mixing Lemma).
Let be an -expander. For any two vertex subsets :
where counts ordered pairs (so self-loops count once and edges within count twice).
Proof.
The proof decomposes the indicator vectors of and in the eigenbasis of and applies Cauchy-Schwarz. The Spectral Theorem guarantees that has an orthonormal eigenbasis with real eigenvalues .
Step 1: Set up the eigenbasis decomposition.
Since is -regular, and . Let and denote the indicator (characteristic) vectors of and . Expand them in the eigenbasis:
where and .
Step 2: Compute the first coefficients.
The coefficient for is:
Step 3: Express in terms of eigenvalues.
The key observation: . Since and the eigenvectors are orthonormal:
Step 4: Separate the first term.
So the deviation from the expected value is:
Step 5: Apply the triangle inequality and Cauchy-Schwarz.
where . Now apply Cauchy-Schwarz:
Step 6: Bound the norms using Parseval’s identity.
By Parseval’s identity (since is orthonormal):
Therefore:
and similarly .
Step 7: Combine.
This completes the proof.
∎The EML is a multiplicative guarantee when and are not too small. If for some constant , the expected edge count is and the error bound is . The relative error is , which is — small when .
Remark (Tightness of the Expander Mixing Lemma).
The EML bound is tight. For any -expander, there exist sets and with . This is achieved by choosing and to be aligned with the eigenvector corresponding to (or in absolute value). In particular, bipartite Ramanujan graphs achieve equality with and as the two sides of the bipartition.
4.1 Consequences of the EML
The EML has immediate combinatorial consequences:
Edge density. Setting : the number of edges within satisfies . The term counts twice each edge inside , so the actual edge count is , and:
This says internal edge density is close to per vertex — nearly what you would expect from a random graph.
Independence number. An independent set has , so , giving:
For an -expander with small, the independence number is at most a fraction of . This is a non-trivial bound: it says expansion forces edges to spread evenly, making large independent sets impossible.
Chromatic number. Combining the independence number bound with a greedy coloring argument gives — expanders need many colors.
5. Ramanujan Graphs and the Alon-Boppana Bound
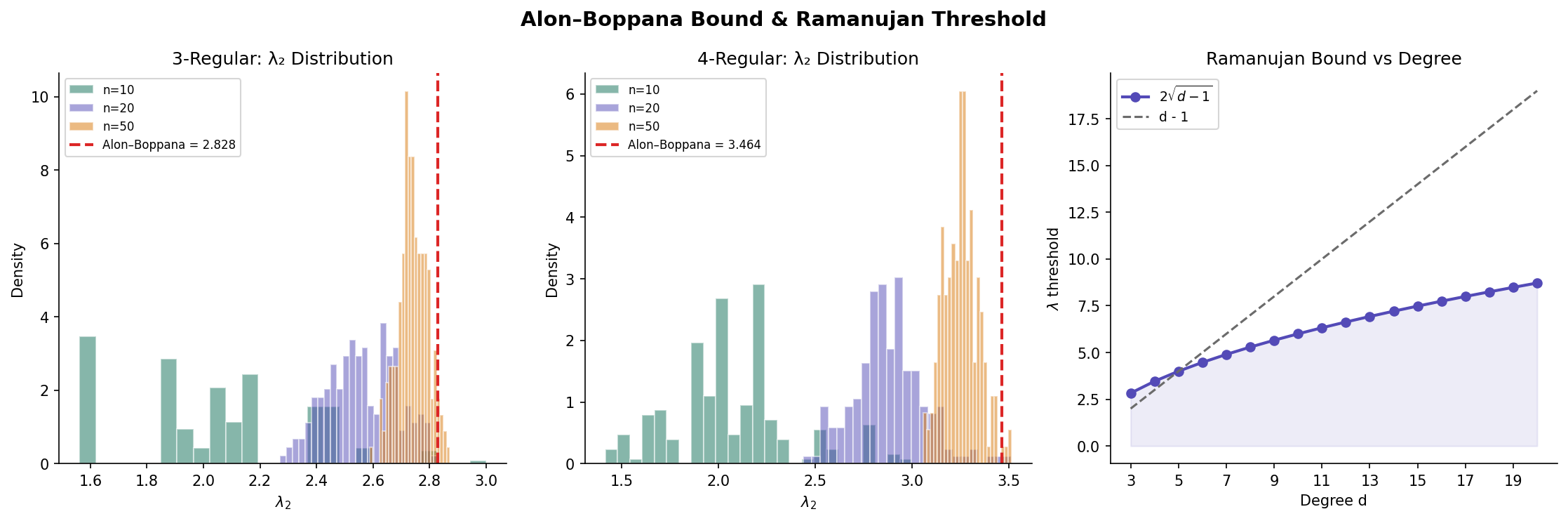
We now ask: how small can be for a -regular graph? A smaller means better expansion, tighter EML bounds, and faster mixing. Is there a limit?
5.1 The Alon-Boppana Lower Bound
The answer is yes: there is a universal floor that no infinite family of -regular graphs can beat.
Theorem 3 (Alon-Boppana Bound).
For any family of -regular graphs with :
More precisely, for any -regular graph on vertices:
Proof.
We give a proof sketch that captures the essential idea. The bound arises from the spectral theory of the infinite -regular tree , which is the “universal cover” of all -regular graphs.
The infinite tree as the limit. The -regular tree has spectrum (as a continuous spectrum, since is infinite). The key fact is that any finite -regular graph on vertices “looks locally like ” for vertices whose -neighborhood is a tree, where can be as large as .
Test vector construction. For a vertex , define a vector supported on the ball of radius around :
This vector mimics the eigenfunction of at the spectral edge . If the -ball around is a tree (which happens for ), then:
From Rayleigh quotient to eigenvalue. We need . Modifying to be orthogonal to changes the Rayleigh quotient by at most . Since we can take while keeping the support smaller than , the correction vanishes, and:
Taking gives .
For the full spectral parameter , the same argument applies to by considering the vector , which tests the bottom of the spectrum.
∎The Alon-Boppana bound tells us that is an impassable barrier: no family of -regular graphs can have for all but finitely many members. This leads to the definition of optimal expanders.
5.2 Ramanujan Graphs
Definition 4 (Ramanujan Graph).
A -regular graph is a Ramanujan graph if every eigenvalue of the adjacency matrix satisfying also satisfies:
Equivalently, .
Ramanujan graphs are the best possible expanders for their degree: they meet the Alon-Boppana bound with equality. The name honors the Indian mathematician Srinivasa Ramanujan, whose conjectures about modular forms (proved by Deligne) are the key ingredient in the original constructions.
5.3 Examples of Ramanujan Graphs
Petersen graph (, ). The eigenvalues are . We need . The Ramanujan bound is . Since , the Petersen graph is Ramanujan.
Complete graph (). The non-trivial eigenvalues are all , so . The Ramanujan bound is . For , we have , so every is Ramanujan. (This is expected — the complete graph is the best possible expander, but it is not sparse.)
Cycle (). The Ramanujan bound is . The second-largest eigenvalue is for , so every cycle is technically Ramanujan. This may seem surprising, but recall that the cycle is not a good expander — the Cheeger constant . Ramanujan-ness at is vacuous because , so the condition imposes no constraint beyond regularity.
Complete bipartite graph (). The eigenvalues are , (with multiplicity ), and . Here , which means . Under our definition, , so . However, the Ramanujan condition for bipartite graphs uses the nontrivial spectral parameter
which excludes both the trivial eigenvalues and . With this convention, , and is trivially Ramanujan (but again, not sparse). We use in the table below and in the Ramanujan check of the interactive visualizations.
| Graph | Ramanujan? | |||
|---|---|---|---|---|
| Petersen | 3 | 2 | 2.83 | Yes |
| 4 | 1 | 3.46 | Yes | |
| 5 | 1 | 4.00 | Yes | |
| 2 | 2 | Yes (vacuous) | ||
| Hypercube | 4 | 2 | 3.46 | Yes |
| Random 3-regular | 3 | 2.83 | Nearly |
Theorem 4 (Existence of Ramanujan Graphs (Lubotzky-Phillips-Sarnak)).
For every prime and every prime with , there exists an explicit family of -regular Ramanujan graphs on vertices (and other sizes in the family). These graphs are Cayley graphs of or with generators defined via quaternion arithmetic.
Remark (Friedman's Theorem and Random Regular Graphs).
While the LPS construction gives Ramanujan graphs for specific degrees, a beautiful result of Friedman (2008) shows that random -regular graphs are “nearly Ramanujan”: for every ,
So almost every large random -regular graph has close to the Alon-Boppana bound. The gap between and vanishes in the limit — random graphs are essentially optimal expanders. This was conjectured by Alon in 1986 and took over 20 years to prove.
More recently, Marcus, Spielman, and Srivastava (2015) proved that bipartite Ramanujan graphs of every degree exist, resolving a major open problem. Their proof used the method of interlacing families and connected the existence of Ramanujan graphs to the Kadison-Singer problem.
6. Explicit Constructions
One of the remarkable features of expander graphs is that they can be constructed explicitly — we do not need randomness to build them. This section describes two families of constructions: algebraic constructions from Cayley graphs and the number-theoretic LPS construction.
6.1 Cayley Graphs
Definition 5 (Cayley Graph).
Let be a finite group and a symmetric generating set (, ). The Cayley graph is the graph with vertex set and edges for all and . The graph is -regular.
Cayley graphs are a natural source of highly structured regular graphs. Their spectral properties are determined by the representation theory of the group — and for abelian groups, the eigenvalues have an explicit formula.
Proposition 2 (Spectrum of Abelian Cayley Graphs).
Let and be a symmetric generating set with . The eigenvalues of are:
with corresponding eigenvectors .
Proof.
The adjacency matrix of is a circulant matrix: if . Circulant matrices are diagonalized by the discrete Fourier transform. The DFT basis vectors are , and the eigenvalue corresponding to is:
Since is symmetric (), the imaginary parts cancel and:
The largest eigenvalue is (all cosines equal 1).
∎6.2 The Margulis-Gabber-Galil Construction
The first explicit expander family was constructed by Margulis (1973), with the spectral gap proved by Gabber and Galil (1981). It produces 8-regular graphs on vertices.
Construction. Let be any positive integer. Define the graph on the vertex set (so ) with edges from to each of:
where all arithmetic is modulo . Some of these eight neighbors may coincide, but in general the graph is 8-regular.
Why is this an expander? The generating set includes both “translation” moves (adding to a coordinate) and “shear” moves (adding one coordinate to the other). The translations provide local connectivity, while the shears — which act as hyperbolic rotations on — spread out any concentrated set of vertices rapidly. The spectral gap satisfies , so the spectral gap is bounded away from zero.
6.3 The LPS Construction
The Lubotzky-Phillips-Sarnak (LPS) construction produces -regular Ramanujan graphs for primes . The construction uses deep number theory — specifically, Jacobi’s four-square theorem and Ramanujan’s conjecture on modular forms (proved by Deligne).
Sketch of the construction. Fix two distinct odd primes and with . The LPS graph is the Cayley graph of — the projective general linear group of invertible matrices over the finite field — with generating set determined by the representations of as a sum of four squares:
where is odd and are even. Each representation yields a matrix in , and these matrices form a symmetric generating set of size .
The Ramanujan property follows from deep results: the non-trivial eigenvalues of the Cayley graph are expressed in terms of Hecke eigenvalues of automorphic forms on , and Ramanujan’s conjecture (now Deligne’s theorem) bounds these eigenvalues.
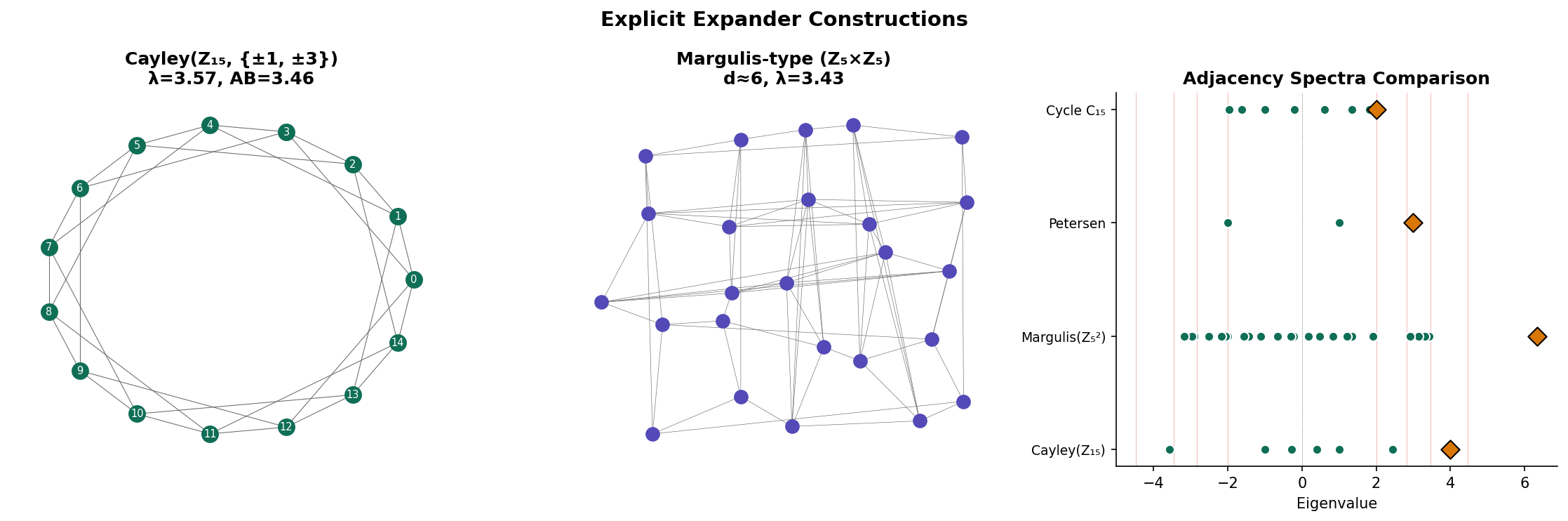
6.4 Constructing Cayley Graphs in Practice
Here is a Python implementation of Cayley graph construction for cyclic groups:
import numpy as np
from itertools import product
def cayley_graph_cyclic(n, generators):
"""
Build the adjacency matrix of Cay(Z_n, S)
where S = generators ∪ {-g mod n : g in generators}.
"""
# Symmetrize the generating set
S = set()
for g in generators:
S.add(g % n)
S.add((-g) % n)
S.discard(0) # Remove identity
A = np.zeros((n, n), dtype=int)
for v in range(n):
for s in S:
w = (v + s) % n
A[v, w] = 1
return A, sorted(S)
def margulis_gabber_galil(n):
"""
Build the Margulis–Gabber–Galil 8-regular expander on Z_n × Z_n.
Returns adjacency matrix of size n^2 × n^2.
"""
N = n * n
A = np.zeros((N, N), dtype=int)
def idx(x, y):
return (x % n) * n + (y % n)
for x in range(n):
for y in range(n):
i = idx(x, y)
neighbors = [
idx(x + 1, y), idx(x - 1, y),
idx(x, y + 1), idx(x, y - 1),
idx(x + y, y), idx(x - y, y),
idx(x, y + x), idx(x, y - x),
]
for j in neighbors:
A[i, j] = 1
return A7. Random Walks on Expanders
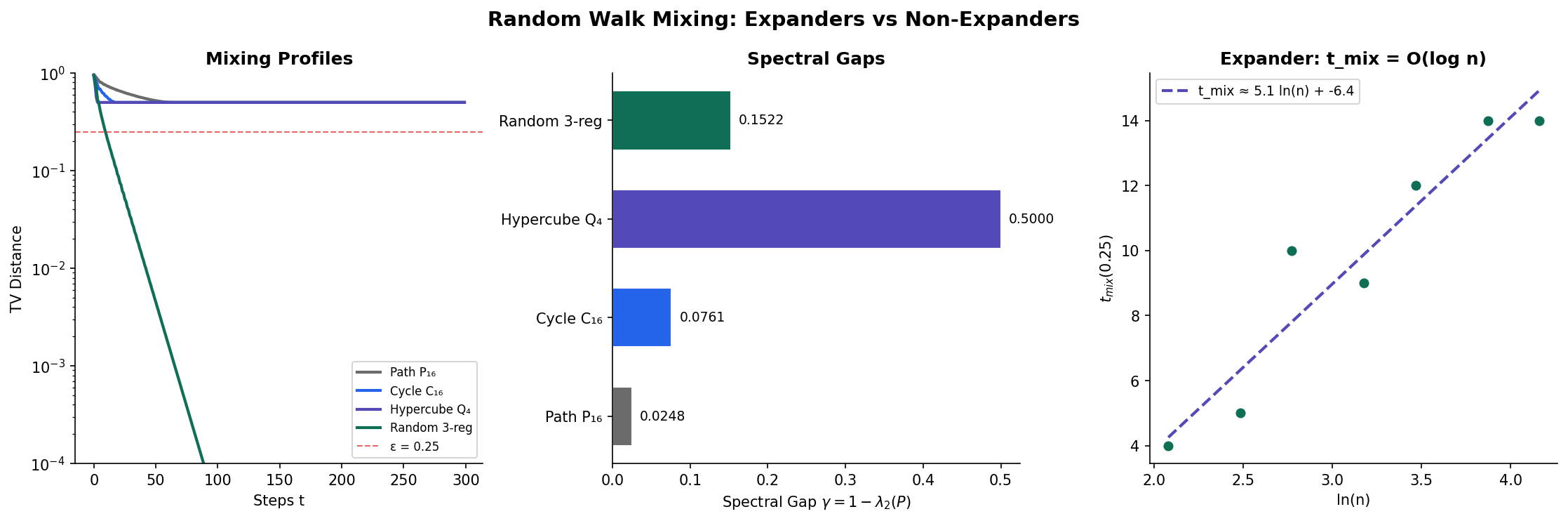
In Random Walks & Mixing, we proved that the mixing time of a random walk is controlled by the spectral gap: where . For expanders, is bounded away from zero, so the mixing time is — logarithmic in the number of vertices.
7.1 Mixing Time on Expanders
Theorem 5 (Mixing Time on Expanders).
Let be a connected, non-bipartite -expander. The random walk on has mixing time:
In particular, if for a constant , then .
Proof.
Since is -regular, the transition matrix is and the stationary distribution is uniform: . The eigenvalues of are , so for . Define (using non-bipartiteness and ).
Step 1: Spectral decomposition of .
By the spectral decomposition from Random Walks & Mixing:
where are the orthonormal eigenvectors of , and we used and .
Step 2: Total variation bound.
The total variation distance from stationarity is:
Using the spectral decomposition:
By Cauchy-Schwarz:
Summing over and using (orthonormality):
where we used . The sum is bounded by 1, since the eigenvectors form an orthonormal basis: the completeness identity gives at .
Working instead with the norm (which gives a cleaner bound):
where the second equality uses orthonormality of the (summing over ) and the inequality uses .
By Cauchy-Schwarz between the sum over and the constant function:
So:
Step 3: Solve for .
We want . It suffices to have:
Taking logarithms:
Using the inequality for , we have .
So suffices. For the standard formulation with :
(absorbing constants). When for a constant , this is .
∎7.2 Comparison of Mixing Times
The following table compares mixing times across graph families, highlighting how expansion controls convergence speed:
| Graph Family | Spectral Gap | ||||
|---|---|---|---|---|---|
| Path | 2 | ||||
| Cycle | 2 | ||||
| Hypercube | |||||
| -Expander | |||||
| Complete | 1 |
The path and cycle have vanishing spectral gap, so mixing takes polynomial time. The hypercube has a constant spectral gap (2) and mixes in where . Expanders achieve the optimal mixing for sparse graphs.
Corollary 2 (Rapid Mixing Implies Expansion).
If a family of -regular graphs has mixing time , then is an expander family (i.e., for some constant ).
Proof.
The mixing time satisfies where (this is the matching lower bound from Random Walks & Mixing). If , then:
for some constant . This gives , so the spectral gap is bounded below by a positive constant.
∎
8. Applications to Computer Science and Machine Learning
8.1 Expander Walk Sampling and Derandomization
The most celebrated application of expanders in theoretical computer science is derandomization: reducing the amount of randomness needed by a probabilistic algorithm. The key result is the expander walk sampling theorem.
Theorem 6 (Expander Walk Sampling Theorem).
Let be an -expander and let be a function with mean . Let be the vertices visited by a random walk of length starting from a uniformly random vertex . Then for any :
This is a Chernoff-type concentration bound for dependent samples. In a standard Chernoff bound for independent samples, the exponent is . The expander walk version has an extra factor of (the spectral gap of the walk) — a mild penalty for dependence.
Why is this useful for derandomization? To sample independent vertices from , you need random bits. But a random walk of length on requires only bits (for the starting vertex) plus bits (for the neighbor choices), totaling . When is a constant and , this is — exponentially fewer random bits than independent sampling. The expander walk sampling theorem guarantees that the walk’s samples are “almost as good” as independent samples.
This principle underlies the Ajtai-Komlós-Szemerédi (AKS) sorting network, the Impagliazzo-Zuckerman extractor, and many other constructions in derandomization and pseudorandomness.
8.2 Error-Correcting Codes
Sipser and Spielman (1996) showed that bipartite expander graphs yield error-correcting codes with remarkable properties:
Construction. Start with a bipartite -regular expander where , . Each right vertex imposes a parity check: the bits indexed by must sum to 0 modulo 2. The resulting code has:
- Block length
- Rate (approaches for good expanders)
- Minimum distance proportional to (linear distance, from the expansion property)
- Linear-time decoding: the expansion guarantees a simple “flip” algorithm converges in steps
The expansion property is the key: if a codeword has errors for small enough , the erroneous bits have at least unsatisfied check nodes (by vertex expansion), which is more than the checks that could be satisfied by accident. The decoder identifies and corrects errors by examining local check violations.
8.3 Network Robustness
Expander graphs are optimally robust networks: removing a constant fraction of vertices or edges still leaves a connected graph (in fact, a graph that is itself an expander). Formally:
- Vertex robustness: Removing any vertices from an -expander leaves a connected graph, provided is smaller than a threshold depending on and .
- Edge robustness: Similarly, removing edges. The Cheeger constant lower bound guarantees that every cut has at least edges, so creating a disconnection requires removing edges.
These properties make expanders ideal for communication networks, peer-to-peer systems, and distributed hash tables, where robustness to node failures is essential.
8.4 Graph Neural Networks and Over-Smoothing
Remark (Expansion, GNNs, and Over-Smoothing).
In graph neural networks (GNNs), each message-passing layer aggregates information from a vertex’s neighbors — effectively performing one step of a (learned) random walk. After layers, vertex ‘s representation depends on its -hop neighborhood.
On an expander, layers suffice to propagate information from any vertex to any other — the “receptive field” covers the entire graph. This is the theoretical justification for using relatively few layers in GNN architectures.
However, rapid mixing is a double-edged sword. After layers, every vertex’s representation converges toward the graph’s global average — the over-smoothing phenomenon. On expanders, over-smoothing happens faster than on non-expanders, precisely because the spectral gap is large. This creates a tension: expander-like connectivity is needed for global information flow, but it accelerates the loss of local signal.
Recent work addresses this by adding skip connections, using attention mechanisms, or designing architectures that interpolate between local and global aggregation. The spectral gap provides a quantitative framework for understanding these trade-offs.
For more on message passing and its spectral interpretation, see Message Passing & GNNs.
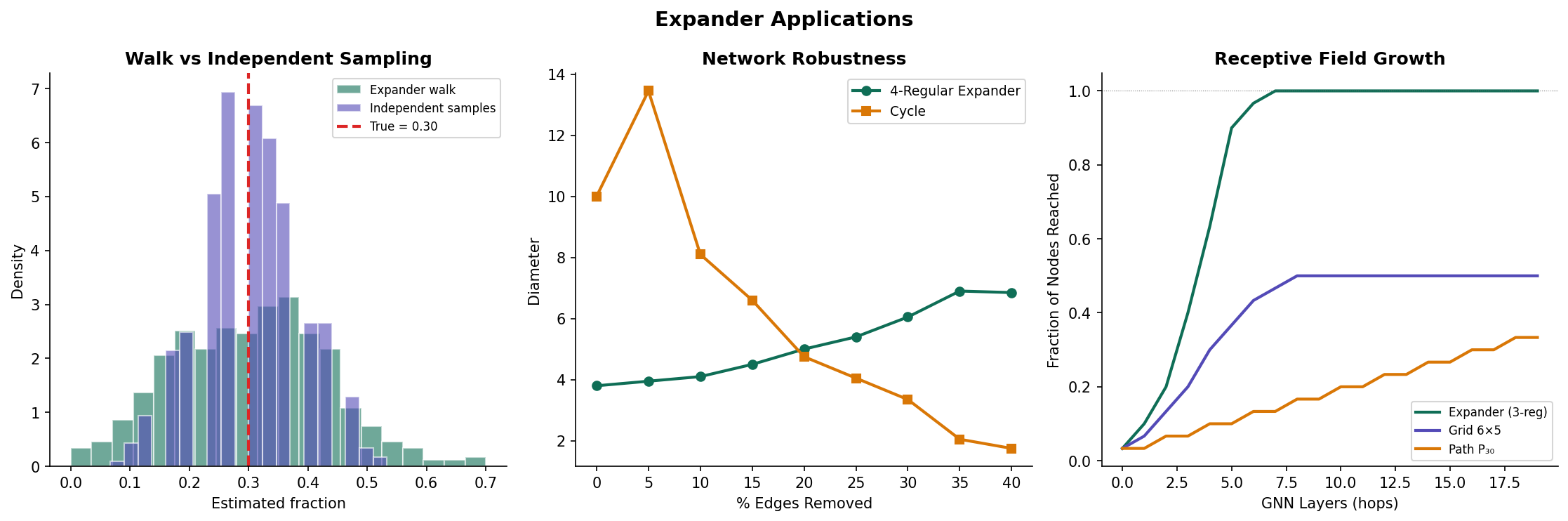
9. Computational Notes
9.1 Computing Expansion Metrics
Here is a complete implementation for computing spectral expansion metrics and checking the Ramanujan property:
import numpy as np
from scipy import linalg
def expansion_metrics(A):
"""
Compute spectral expansion metrics for a d-regular graph
with adjacency matrix A.
Returns a dictionary with degree, lambda (spectral expansion parameter),
spectral gap, Ramanujan bound, and whether the graph is Ramanujan.
"""
eigenvalues = np.sort(linalg.eigvalsh(A))[::-1]
d = eigenvalues[0]
# lambda = max |lambda_i| for i >= 2
# For non-bipartite graphs, also exclude lambda_n = -d
nontrivial = eigenvalues[1:]
if np.isclose(nontrivial[-1], -d, atol=1e-8):
# Bipartite: exclude -d as trivial
nontrivial = nontrivial[:-1]
lambda_val = np.max(np.abs(nontrivial))
ram_bound = 2 * np.sqrt(d - 1)
return {
'degree': d,
'lambda': lambda_val,
'spectral_gap': d - eigenvalues[1],
'ramanujan_bound': ram_bound,
'is_ramanujan': lambda_val <= ram_bound + 1e-10,
'eigenvalues': eigenvalues
}9.2 Verifying the Expander Mixing Lemma
def verify_eml(A, S_indices, T_indices):
"""
Verify the Expander Mixing Lemma for subsets S and T.
Returns the actual edge count E(S,T), the expected count d|S||T|/n,
the EML bound lambda * sqrt(|S||T|), and whether the bound holds.
"""
n = A.shape[0]
metrics = expansion_metrics(A)
d = metrics['degree']
lam = metrics['lambda']
# Count edges from S to T (ordered pairs)
E_ST = sum(A[i, j] for i in S_indices for j in T_indices)
expected = d * len(S_indices) * len(T_indices) / n
bound = lam * np.sqrt(len(S_indices) * len(T_indices))
deviation = abs(E_ST - expected)
return {
'E_ST': E_ST,
'expected': expected,
'deviation': deviation,
'eml_bound': bound,
'bound_holds': deviation <= bound + 1e-10
}
# Example: Petersen graph
def petersen_adjacency():
"""Return the 10x10 adjacency matrix of the Petersen graph."""
edges = [
(0,1),(0,4),(0,5), (1,2),(1,6), (2,3),(2,7),
(3,4),(3,8), (4,9), (5,7),(5,8), (6,8),(6,9), (7,9)
]
A = np.zeros((10, 10), dtype=int)
for i, j in edges:
A[i, j] = A[j, i] = 1
return A
A = petersen_adjacency()
metrics = expansion_metrics(A)
print(f"Petersen: d={metrics['degree']:.0f}, "
f"λ={metrics['lambda']:.4f}, "
f"Ramanujan bound={metrics['ramanujan_bound']:.4f}, "
f"Ramanujan={metrics['is_ramanujan']}")
# Output: Petersen: d=3, λ=2.0000, Ramanujan bound=2.8284, Ramanujan=True
# Verify EML for S = {0,1,2}, T = {5,6,7,8,9}
result = verify_eml(A, [0,1,2], [5,6,7,8,9])
print(f"E(S,T)={result['E_ST']}, expected={result['expected']:.2f}, "
f"deviation={result['deviation']:.2f}, bound={result['eml_bound']:.2f}, "
f"holds={result['bound_holds']}")9.3 Building and Analyzing Margulis-Gabber-Galil Expanders
def analyze_mgg_family(n_values):
"""
Analyze the Margulis–Gabber–Galil expander family
for several values of n, verifying the spectral gap
stays bounded away from zero.
"""
results = []
for n in n_values:
A = margulis_gabber_galil(n)
metrics = expansion_metrics(A)
results.append({
'n': n,
'vertices': n * n,
'degree': metrics['degree'],
'lambda': metrics['lambda'],
'spectral_gap': metrics['spectral_gap'],
'is_ramanujan': metrics['is_ramanujan']
})
print(f"MGG(n={n}): {n*n} vertices, d={metrics['degree']:.0f}, "
f"λ={metrics['lambda']:.2f}, gap={metrics['spectral_gap']:.2f}")
return results
# Example output (approximate):
# MGG(n=5): 25 vertices, d=8, λ=6.47, gap=1.53
# MGG(n=7): 49 vertices, d=8, λ=6.83, gap=1.17
# MGG(n=11): 121 vertices, d=8, λ=7.02, gap=0.98For the full interactive analysis with additional graph families and larger experiments, see the companion notebook.
10. Connections and Further Reading
10.1 Connections to Other Topics
| Topic | Connection |
|---|---|
| Graph Laplacians & Spectrum | Cheeger’s inequality links the Laplacian spectral gap to edge expansion. The Fiedler vector provides a spectral approximation to the minimum cut, and expanders are precisely the graphs where this cut is large for every subset. |
| Random Walks & Mixing | The mixing time of a random walk on an expander is , because the spectral gap is bounded away from zero. The expander walk sampling theorem extends this to a Chernoff bound for dependent samples. |
| Spectral Theorem | The EML proof decomposes indicator vectors in the eigenbasis of . The Spectral Theorem guarantees orthonormality of this basis — the Cauchy-Schwarz step relies on this structure. |
| Concentration Inequalities | The expander walk sampling theorem is a Chernoff bound where the spectral gap replaces independence. Correlations between consecutive walk samples decay exponentially in the gap. |
| Shannon Entropy | The entropy rate of a random walk on a -regular expander approaches — maximum entropy. Expansion ensures the walk explores the graph uniformly. |
| Message Passing & GNNs | Message passing is iterated Laplacian smoothing. On expanders, layers suffice for global information flow but cause over-smoothing. The spectral gap quantifies this trade-off. |
10.2 Notation Summary
| Symbol | Meaning |
|---|---|
| Graph with vertex set and edge set | |
| Number of vertices | |
| Degree (for regular graphs) | |
| Adjacency matrix | |
| -th eigenvalue of (ordered ) | |
| Spectral expansion parameter: | |
| Cheeger constant (edge expansion) | |
| Vertex expansion ratio | |
| Random walk transition matrix | |
| Spectral gap of the random walk | |
| Mixing time in total variation | |
| Number of (ordered) edges from to | |
| Vertex boundary: | |
| Alon-Boppana / Ramanujan bound |
Connections
- Cheeger's inequality links the Laplacian spectral gap to edge expansion — the same quantity that defines expanders. The Fiedler vector provides a spectral approximation to the minimum cut, and expanders are precisely the graphs where this cut is large for every subset. graph-laplacians
- The mixing time of a random walk on an expander is O(log n), because the spectral gap γ = 1 − λ/d is bounded away from zero. Expander walk sampling extends this: consecutive walk vertices are nearly independent samples, enabling derandomization. random-walks
- The Expander Mixing Lemma proof decomposes indicator vectors in the eigenbasis of the adjacency matrix. The Spectral Theorem guarantees orthonormality of this basis — the Cauchy-Schwarz step in the EML relies on this structure. spectral-theorem
- The expander walk sampling theorem is a Chernoff bound for dependent samples on a Markov chain. The spectral gap replaces independence: a walk on an expander produces samples whose correlations decay exponentially. concentration-inequalities
- The entropy rate of a random walk on a d-regular expander approaches log d — maximum entropy. Expansion ensures the walk explores the graph uniformly, maximizing the information content of the trajectory. shannon-entropy
References & Further Reading
- paper Expander Graphs and their Applications — Hoory, Linial & Wigderson (2006) The definitive survey — covers all three expansion notions, the EML, Ramanujan graphs, and applications to CS
- paper Ramanujan Graphs — Lubotzky, Phillips & Sarnak (1988) The original explicit construction of (p+1)-regular Ramanujan graphs via quaternion algebras
- paper A Proof of Alon's Second Eigenvalue Conjecture and Related Problems — Friedman (2008) Random d-regular graphs are nearly Ramanujan — λ₂ ≤ 2√(d-1) + ε with high probability
- paper Interlacing Families II: Mixed Characteristic Polynomials and the Kadison–Singer Problem — Marcus, Spielman & Srivastava (2015) Existence of bipartite Ramanujan graphs of every degree — resolved a major open problem
- book Spectral Graph Theory — Chung (1997) Standard reference for the normalized Laplacian perspective on expansion and mixing
- paper Expander Codes — Sipser & Spielman (1996) Linear-time decodable codes from bipartite expanders — expansion ensures error correction